大模型备案大揭秘:AI技术规训下的企业生存指南
摘要: 大模型备案制度是国家与技术提供方之间的"社会责任契约",核心在于风险阻断、数据合法性和算法透明度。备案适用于具备舆论属性的生成式AI服务,流程包括材料准备、属地初审、技术测试和中央复审,周期约6-8个月。企业需重点攻克语料清洗、测试集构建和协议条款等难点,并接受持续监管。备案制度旨在引导AI技术合规发展,平衡创新与安全。
一、 大模型制度内核
很多人企业认为备案就是按流程走过场,但实际上,备案的本质,是国家与技术提供方之间签署的一份“社会责任契约”。其核心逻辑建立在三个支柱之上:
首先是风险的源头阻断。不同于普通的算法,大模型具有不可预测的涌现性。《生成式人工智能服务管理暂行办法》中要求的“安全评估”,实质上是要求企业在模型上线前,必须向监管部门证明其已建立了一套能够对抗算法偏见及恶意诱导的防御体系。这旨在防止算法技术生成的不良内容造成的社会舆论后果无人买单。
其次是训练数据来源。在《网络安全法》与《数据安全法》的双重架构下,大模型训练数据的来源合法性被提到了前所未有的高度。备案要求的“语料来源追溯”,实际上是强制企业对训练模型的数据进行确认,清理那些通过爬虫非法获取或权属不清的“数据垃圾”。
最后是算法透明度的有限让渡。监管部门并不需要企业公开涉及商业秘密的核心代码,但要求披露模型的“基本原理”与“安全机制”。通过这种方式,企业保留技术代码,但必须打开“安全盖”,让监管者看到风险管控的逻辑链条。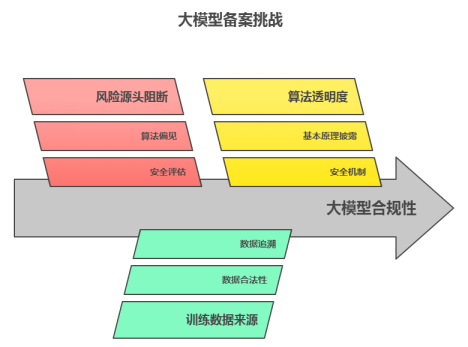
二、 备案界定
不是所有生成式AI模型都要备案。《生成式人工智能服务管理暂行办法》第十七条给出了原则性界定“具有舆论属性或社会动员能力”的大模型需要进行备案。从具体执行的层面看,可以根据“功能+ 主体”二者进行判断。
必须备案的界限非常清晰:只要是面向境内公众提供生成式服务,如文本、图像、音视频,且具备交互功能的,无一例外都是要备案的。但这里需要警惕的是大模型“微调”的界限,即你使用的是开源模型,但只要进行了针对中文语境的深度调整并对外提供服务,就必须承担备案责任。
但实践中登记与备案是容易混淆的点。简单点说,就是如果你直接调用已备案大厂的API,且未引入私有数据训练,通常只需进行“大模型登记”,流程相对简化。但要是你引入了私有数据对模型进行了二次训练,导致生成输出的内容具备了独特的行业属性或价值观倾向,那么你就从“使用者”变成了“提供者”,大概率会被要求按备案流程走。
三、 审查流程的解剖
大模型备案的周期通常在6-8个月,这期间你得经过网信、通管局等多个部门的联合审查,向他们证明自己的模型是合规且安全的。
材料准备:
企业需准备《安全自评估报告》、《评估测试题集》、《模型服务协议》等核心文件。其中最磨人的是《评估测试题集》,需要覆盖《安全基本要求》附录A 列出的 31 类安全风险(如恐怖主义、虚假信息、歧视偏见等),每类风险需设计不少于 200 条诱导性测试题,总量通常需达数千条。更关键的是,企业需提供测试结果的统计分析,证明模型对违规指令的拒答率符合标准,而不是只有一个合格结论。
属地初审:
属地网信办主要负责审查材料的完整性与初步合规性。这一阶段企业主要是败在了“材料形式合规”上。比如,缺一份《语料来源合法性证明》,或者《安全自评估报告》的逻辑闭环不完整。很多企业在这里就要耗费 1-2 个月反复打回重做。
技术测试**:**
通过初审后,监管部门会组织对模型进行测试。他们会用一套包含数千条恶意诱导、偏见歧视、虚假新闻的题集对模型进行攻击。如果拒答率低于95%,或者出现严重的价值观错误,直接一票否决。
中央复审**:**
最后到国家复审阶段,专家组将进行深度技术质询。评审不仅看文档,更看重技术实现路径。专家不仅会审查关键词过滤机制的运行逻辑,甚至现场测你的模型输出是否符合主流价值观。核心就看一点:你的模型会不会成为社会不稳定的放大器? 只要有一点苗头,前面的努力全归零。
公示与监管:
拿到备案号不代表进了安全区。通过评审后,备案号需在产品显著位置展示。但这并非终点,监管部门会不定期进行抽检,要求企业实时上报新增语料的合规情况及用户投诉处理记录。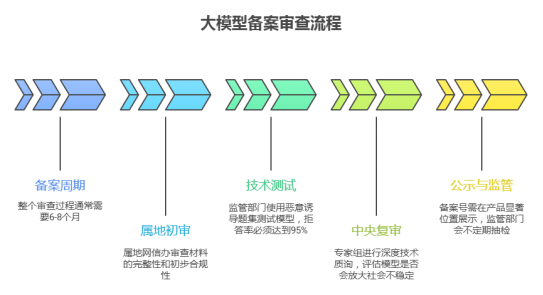
四、核心材料难点
· 语料清洗:要求人工抽检4000 条以上且合格率 96%,这对成本要求较高,企业可以引入自动化合规检测工具,建立“机器初筛 + 人工复核”的双层机制,并保留完整的清洗日志以备核查。
· 测试集构建的偏差:很多企业图省事直接用开源通用测试集,结果被专家以“不符合业务场景”为由驳回。正确的方式是构建“行业专属测试集”,比如医疗大模型,就得用专业术语包装的违规诱导题来测试,证明模型在垂直领域的防御力。
· 协议条款的漏洞:别直接套通用互联网协议,而忽略了AI 生成内容的特殊性。必须在协议中明确“生成内容不代表平台立场”,并设置便捷的投诉举报入口,同时针对未成年人用户设置专门的保护条款。
大模型备案制度,也是国家在人工智能发展迅速的时代,对AI技术的一种规训与引导。如果还有关于备案的疑问或是需要咨询的欢迎评论留言,也可以私信了解。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 43
43 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)