技术纵深分析:从对抗训练视角,解构“快降重”在AIGC攻防中的有效性
要理解一个防御工具(降重)是否有效,首先要明确进攻方(AIGC检测器)的武器原理。当前主流检测系统(如Turnitin AI、知网AIGC)的底层逻辑,可归纳为两类:统计特征分类器:基于海量人类与AI文本,训练模型识别诸如词频分布(n-gram)、词性序列、句法树复杂度、文本困惑度(Perplexity)等统计层面的“机器指纹”。神经水印探测器:部分高级生成模型会在输出中嵌入难以察觉的特定模式(水
当AIGC检测从一种风控手段演变为标准流程,一场围绕“生成”与“检测”的算法暗战已悄然升级。本文试图跳出简单的工具评测,从NLP对抗训练的视角,剖析以 快降重 为代表的专用降重工具,为何能成为这场博弈中更有效的“防御方”。
01 战场定义:AIGC检测的“矛”与降重的“盾”
要理解一个防御工具(降重)是否有效,首先要明确进攻方(AIGC检测器)的武器原理。当前主流检测系统(如Turnitin AI、知网AIGC)的底层逻辑,可归纳为两类:
-
统计特征分类器:基于海量人类与AI文本,训练模型识别诸如词频分布(n-gram)、词性序列、句法树复杂度、文本困惑度(Perplexity)等统计层面的“机器指纹”。
-
神经水印探测器:部分高级生成模型会在输出中嵌入难以察觉的特定模式(水印),检测器通过解码这些模式来溯源。
因此,有效的“盾”必须能系统性破坏这些“指纹”或“水印”,而非进行表面修饰。
02现有防御方案的技术层级与缺陷分析
我们可将现有降重方案按技术深度分为三层,其防御能力逐级增强:
| 防御层级 | 技术原理 | 典型手段 | 对抗检测的能力 | 主要缺陷 |
| L1: 词法干扰层 | 同义词替换、语序局部调整 | 传统降重软件、翻译回译法 | 极弱 | 完全无法改变句法树、n-gram概率等深层统计特征,易被检测。 |
| L2: 通用语义润色层 | 调用通用大模型(如GPT)进行“重述” | 多数AI改写助手 | 中等但不稳定 | 可能引入新的、符合该通用模型特征的统计模式,导致“去AI化”不彻底,甚至被反向标记。 |
| L3: 定向对抗重构层 | 针对特定检测模型的对抗性训练与风格迁移 | 快降重等垂直工具 | 强 | 高度依赖其训练数据与优化目标的对齐度。 |
03 核心推演:为什么“快降重”可能运行在L3层级?
尽管无法获得其商业模型的完整架构,但基于其公开效果和行业常识,我们可以进行技术推演。快降重 极有可能采用或部分采用了以下一种或多种高阶防御策略:
-
对抗性训练(Adversarial Training):这是最直接有效的路径。在其训练循环中,不仅有一个生成器(G) 负责改写文本,还有一个甚至多个判别器(D)。这个判别器可以直接是(或高度模拟)主流的AIGC检测模型(如训练好的Turnitin AI分类器)。生成器的目标就是生成能让判别器“判断为人类写作”的文本,二者不断博弈,最终生成器学会精准绕过特定检测逻辑。
- 风格迁移与控制生成:模型被明确训练为,在保留原文语义内容(Content) 和专业术语(Term) 两个“控制维度”的前提下,将文本的写作风格(Style) 从“AI通用风格”迁移到“特定学术领域的人类风格”。这需要其训练语料是纯净、高质量的人类学术文本库。
-
基于检测模型梯度的攻击(白盒/灰盒假设):在更理想的情况下,如果工具方能对某些开源或可查询的检测模型进行“白盒”分析,它甚至可以计算检测模型的梯度,从而知道如何微小地扰动输入文本,就能最大程度地降低其“AI概率得分”。虽然对商业闭源检测器实现纯白盒攻击不现实,但基于代理模型(Surrogate Model)的迁移攻击是可能的。

04 实验复现:一个简化的对抗性验证思路
作为技术研究者,我们可以设计一个小实验来间接验证其防御强度:
-
准备样本:生成一批不同主题的AI文本(样本集S_ai),并收集一批人类撰写的学术摘要(样本集S_human)。
-
构建基线检测器:使用S_ai和S_human训练一个简单的文本分类模型(如基于BERT微调),作为我们的“模拟检测器D_base”。
-
发起攻击:将S_ai分别用以下工具处理:传统工具(L1)、GPT-4重述(L2)、快降重(L3),得到三个处理后的样本集:S_l1, S_l2, S_l3。
-
评估防御效果:用D_base对S_l1, S_l2, S_l3进行分类。如果快降重处理的文本被D_base判定为“人类”的比例显著且稳定地高于其他两种方法,则可在一定程度上印证其对抗性防御的有效性。
(注:此实验仅为概念验证,真实商业检测系统远为复杂。)
05 工程化启示与伦理边界
将 快降重 视为一个“针对AIGC检测的对抗性防御服务”来集成,为我们提供了清晰的工程界面:
-
定位:它是文本安全合规流水线上的一个专用加扰/加密模块,输入是“带AI风险的明文”,输出是“可通过检测的安全密文”。
-
集成点:应置于通用AI生成之后,最终人工润色之前。流程为:
[构思] -> [通用AI生成初稿] -> [快降重对抗性防御] -> [人工深度校验与逻辑增强] -> [官方检测]。
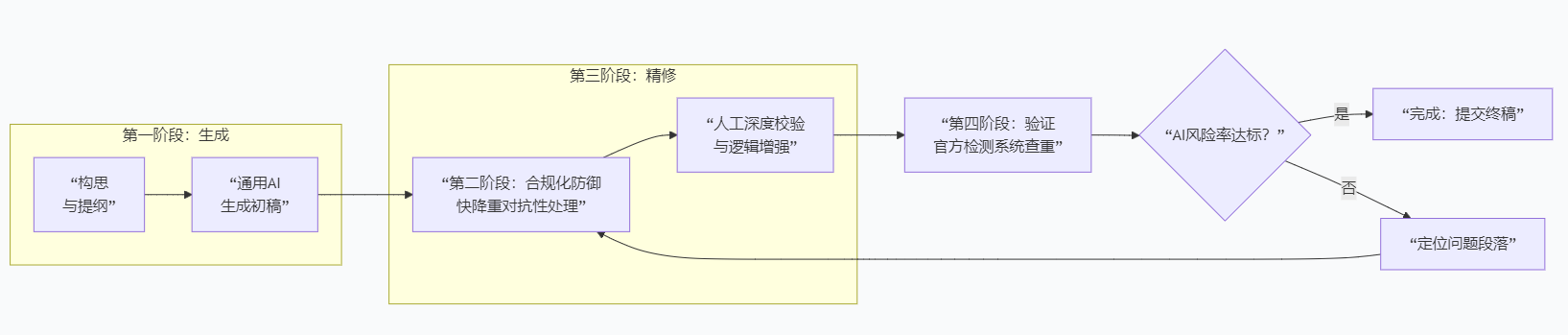
-
伦理警示:技术是中立的,但应用有边界。此类工具的使用必须严格服务于合规化表达的目的,即“将AI辅助生成的、但思想属于自己的内容,转化为符合学术规范的形式”。它绝不能用于掩盖抄袭、伪造数据或窃取他人观点。
总之,在AIGC攻防的技术前沿,此类免费工具通过可能的对抗训练、深度风格迁移等L3层技术,提供了一个当前阶段高效、专业的防御解决方案。对于研究者而言,理解其背后的“攻防”逻辑,远比单纯将其视为“神奇按钮”更有价值,这能让我们更负责任、更明智地使用技术。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 6
6 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)