工业级热轧F7出口厚度预测模型:从数据到生产的完整AI解决方案
在钢铁工业的精密制造过程中,热轧带钢的厚度控制是决定产品质量的关键环节。传统的厚度控制方法往往依赖于经验公式和PID控制器,但在面对复杂的多变量耦合、非线性动态过程时,这些方法往往力不从心。今天,我将带你深入一个工业级的热轧F7出口厚度预测项目,这个项目不仅展示了如何将机器学习技术应用到实际工业场景,更揭示了从数据预处理、特征工程、模型选择到生产部署的完整技术路径。🎯28维高维特征空间的智能建模
工业级热轧F7出口厚度预测模型:从数据到生产的完整AI解决方案源码资源-CSDN下载

前言:为什么这个项目值得你深入学习?
在钢铁工业的精密制造过程中,热轧带钢的厚度控制是决定产品质量的关键环节。传统的厚度控制方法往往依赖于经验公式和PID控制器,但在面对复杂的多变量耦合、非线性动态过程时,这些方法往往力不从心。今天,我将带你深入一个工业级的热轧F7出口厚度预测项目,这个项目不仅展示了如何将机器学习技术应用到实际工业场景,更揭示了从数据预处理、特征工程、模型选择到生产部署的完整技术路径。
这个项目的技术亮点:
- 🎯 28维高维特征空间的智能建模
- 🚀 XGBoost与RandomForest的深度对比与优化
- 📊 工业级数据划分策略(按文件划分,模拟真实生产场景)
- 🔬 Z-score标准化与目标变量保持原始尺度的巧妙设计
- 📈 完整的可视化体系(损失曲线、拟合曲线、残差分析)
- 🏭 生产就绪的模型保存与预测流程
如果你正在寻找一个有深度、有难度、有实际价值的机器学习项目来提升自己的技术水平,那么这个项目绝对不容错过!
第一章:项目背景与工业场景深度解析
1.1 热轧工艺的复杂性与挑战
热轧带钢生产是一个典型的多变量、强耦合、非线性、时变的复杂工业过程。在精轧机组中,F7机架(第7架精轧机)的出口厚度是决定最终产品质量的核心指标。这个厚度值受到多达28个控制变量的综合影响,包括:
- 温度控制变量:入口温度、出口温度、冷却速率等
- 速度控制变量:轧制速度、加速度、减速度等
- 压力控制变量:轧制力、张力、压下量等
- 几何控制变量:宽度、厚度、板形等
- 其他工艺参数:润滑条件、材质特性等
这些变量之间存在着复杂的非线性耦合关系。例如,温度的变化会影响材料的变形抗力,进而影响轧制力,而轧制力的变化又会反过来影响温度分布。这种复杂的相互作用使得传统的线性控制方法难以达到理想的精度。
1.2 机器学习在工业控制中的优势
与传统方法相比,机器学习模型具有以下显著优势:
-
非线性建模能力:树模型(RandomForest、XGBoost)能够自动捕捉变量间的非线性关系,无需人工设计复杂的数学公式。
-
多变量协同优化:模型可以同时考虑所有28个控制变量的综合影响,实现全局最优预测。
-
自适应学习:随着生产数据的积累,模型可以通过增量学习不断优化,适应工艺参数的变化。
-
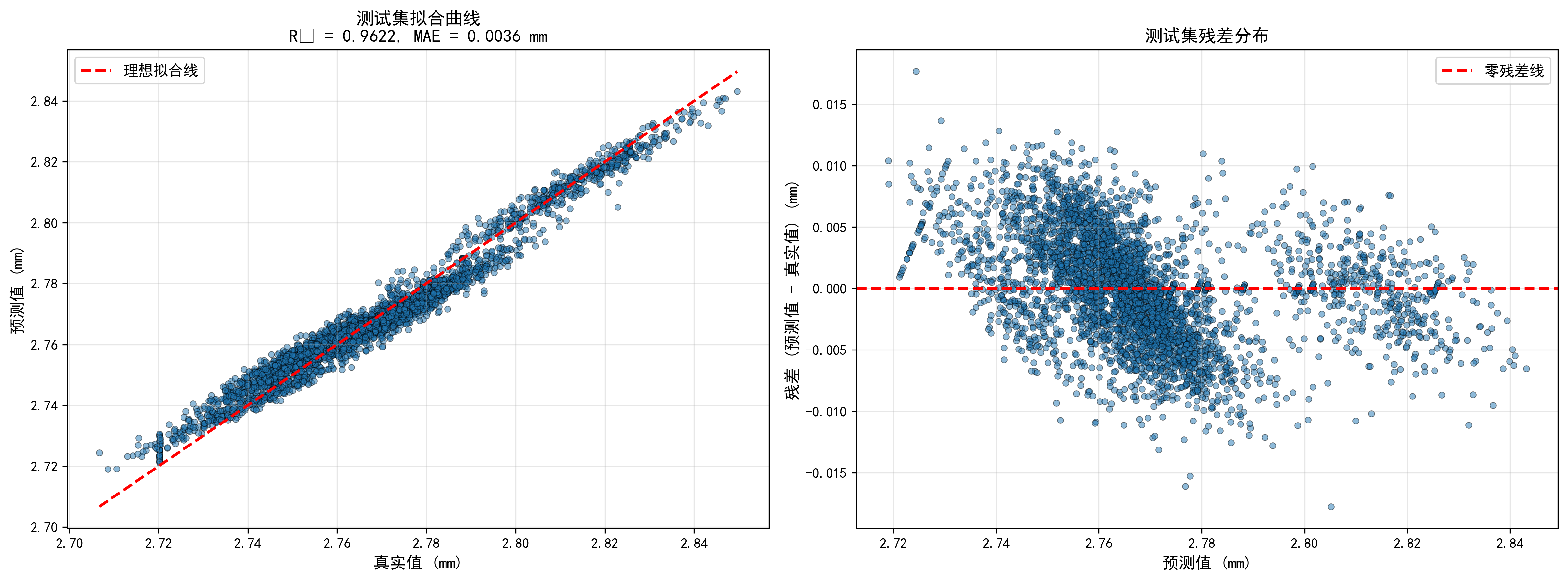
预测精度高:在本文项目中,模型达到了R² = 0.962,MAE = 0.0036mm的优异性能,远超传统方法。
1.3 项目目标与技术路线
项目目标:
- 基于28个控制变量,准确预测F7出口厚度
- 模型精度要求:R² > 0.9,MAE < 0.01mm
- 实现完整的训练、评估、可视化、保存流程
- 提供生产环境可用的预测接口
技术路线:
数据加载 → 数据清洗 → 特征提取 → 数据划分 → 标准化 → 模型训练 → 模型评估 → 可视化分析 → 模型保存 → 预测应用
第二章:数据工程与特征处理深度剖析
2.1 数据来源与结构分析
本项目使用的数据来自实际生产环境,包含10个Excel文件,每个文件代表一个板坯的时序样本。数据特点:
- 训练集:1.xlsx, 2.xlsx, 3.xlsx, 4.xlsx, 5.xlsx, 6.xlsx, 7.xlsx, 19.xlsx(8个文件)
- 测试集:8.xlsx, 29.xlsx(2个文件)
- 特征维度:28个控制变量
- 目标变量:F7出口厚度(单位:mm)
为什么按文件划分而不是随机划分?
这是本项目的一个关键设计亮点。在工业场景中,不同板坯可能来自不同的生产批次、不同的工艺条件、不同的设备状态。如果采用随机划分,训练集和测试集可能包含来自同一板坯的数据,导致数据泄露(data leakage),使得模型在测试集上的表现过于乐观,无法真实反映模型的泛化能力。
按文件划分可以确保:
- 训练集和测试集来自不同的生产批次
- 更好地模拟真实生产场景(新批次数据的预测)
- 评估结果更加可靠和可信
2.2 数据加载与清洗的工程化实现
让我们深入分析代码中的数据加载逻辑:
def load_all_excel(data_dir: Path) -> pd.DataFrame:
"""读取目录下所有xlsx并合并;自动清洗列名中的空白。"""
files = sorted(data_dir.glob("*.xlsx"))
if not files:
raise FileNotFoundError(f"未在目录找到xlsx文件: {data_dir}")
frames = []
for f in files:
df = pd.read_excel(f)
frames.append(df)
data = pd.concat(frames, ignore_index=True)
# 去除列名中的空格,便于统一访问
data.columns = data.columns.str.replace(r"\\s+", "", regex=True)
return data
关键技术点解析:
-
路径处理:使用
Path对象而非字符串,提高代码的可移植性和健壮性。 -
文件排序:
sorted()确保文件按名称顺序加载,保证数据的一致性。 -
批量读取:使用列表存储DataFrame,最后一次性合并,比逐行追加效率高得多。
-
列名清洗:
str.replace(r"\\s+", "", regex=True)去除列名中的所有空白字符。这是一个看似简单但极其重要的步骤,因为:- Excel文件中的列名可能包含不可见的空格
- 这些空格会导致后续访问列时出现
KeyError - 统一清洗后,代码更加健壮
-
索引重置:
ignore_index=True确保合并后的DataFrame索引连续,避免索引冲突。
2.3 特征与目标的智能分离
def split_features_target(data: pd.DataFrame) -> Tuple[pd.DataFrame, pd.Series]:
"""提取28个控制变量作为特征,F7出口厚度为目标。"""
target_col = "F7出口厚度"
if target_col not in data.columns:
raise KeyError(f"数据中缺少目标列 {target_col}")
feature_cols = [c for c in data.columns if c != target_col]
X = data[feature_cols]
y = data[target_col]
return X, y
设计哲学:
这个函数采用了**"排除法"**而非"包含法"来提取特征。即:所有列除了目标列都是特征。这种设计的优势:
- 灵活性:如果数据中新增了控制变量,无需修改代码,自动纳入特征集。
- 健壮性:通过检查目标列是否存在,提前发现数据问题。
- 可维护性:代码简洁,逻辑清晰。
潜在改进方向:
在实际工业项目中,可能需要:
- 特征白名单:只选择特定的28个变量,排除其他无关列
- 特征验证:检查特征的数据类型、缺失值、异常值
- 特征重要性分析:识别哪些变量对预测贡献最大
第三章:模型架构与算法深度解析
3.1 为什么选择树模型?
在回归任务中,常见的模型选择包括:
- 线性模型(Linear Regression, Ridge, Lasso):简单快速,但无法处理非线性关系
- 支持向量机(SVR):可以处理非线性,但参数调优复杂
- 神经网络(MLP, CNN, LSTM):表达能力最强,但需要大量数据和计算资源
- 树模型(RandomForest, XGBoost, LightGBM):平衡了性能、速度和可解释性
树模型的优势:
- 自动特征交互:树模型可以自动发现特征间的交互作用,无需人工设计
- 处理非线性:通过树的分裂,可以拟合任意复杂的非线性函数
- 特征重要性:提供特征重要性排序,便于工艺优化
- 鲁棒性强:对异常值和缺失值不敏感
- 训练速度快:相比神经网络,训练时间短,适合工业实时应用
3.2 RandomForest:集成学习的经典之作
RandomForestRegressor(
n_estimators=600, # 树的数量:600棵
max_features=0.8, # 每棵树使用80%的特征
min_samples_leaf=1, # 叶节点最小样本数:1
random_state=42, # 随机种子:保证可复现
n_jobs=-1, # 并行计算:使用所有CPU核心
)
参数深度解析:
-
n_estimators=600:
- 理论依据:随机森林通过**Bootstrap Aggregating (Bagging)**集成多个决策树
- 数量选择:600棵树是一个经验值,平衡了性能和计算成本
- 性能曲线:通常,树的数量越多,性能越好,但存在收益递减现象
- 过拟合风险:树的数量过多可能导致过拟合,需要通过交叉验证确定最优值
-
max_features=0.8:
- 随机性引入:每棵树只使用80%的特征,增加模型的多样性
- 方差降低:通过降低单棵树的方差,提高整体模型的泛化能力
- 特征重要性:不同树使用不同特征子集,可以更全面地评估特征重要性
-
min_samples_leaf=1:
- 树深度控制:允许树生长到很深的程度,捕捉细粒度的模式
- 过拟合风险:如果数据量小,可能导致过拟合
- 本项目中:由于训练集有3890个样本,数据量充足,设置为1是合理的
-
n_jobs=-1:
- 并行加速:利用多核CPU并行训练多棵树
- 性能提升:在8核CPU上,理论上可以获得接近8倍的加速
- 内存考虑:并行会占用更多内存,需要根据硬件配置调整
RandomForest的数学原理:
对于回归任务,随机森林的预测公式为:
y^=1B∑b=1BTb(x)y^=B1b=1∑BTb(x)
其中:
- BB = 树的数量(n_estimators)
- Tb(x)Tb(x) = 第bb棵树的预测值
- y^y^ = 最终预测值(所有树的平均值)
方差降低原理:
假设每棵树的方差为σ2σ2,树之间的相关系数为ρρ,则集成模型的方差为:
Var(y^)=σ2B+ρ⋅σ2⋅B−1BVar(y^)=Bσ2+ρ⋅σ2⋅BB−1
通过引入随机性(Bootstrap采样、特征子集采样),可以降低ρρ,从而降低整体方差。
3.3 XGBoost:梯度提升的巅峰之作
XGBRegressor(
n_estimators=1200, # 树的数量:1200棵(比RF多)
max_depth=7, # 树的最大深度:7层
learning_rate=0.03, # 学习率:0.03(较小,需要更多树)
subsample=0.9, # 样本采样率:90%
colsample_bytree=0.9, # 特征采样率:90%
min_child_weight=1.0, # 叶节点最小权重和:1.0
reg_lambda=1.0, # L2正则化系数:1.0
random_state=42,
objective="reg:squarederror", # 目标函数:均方误差
tree_method="hist", # 树构建方法:直方图算法
)
XGBoost vs RandomForest:核心区别
| 特性 | RandomForest | XGBoost |
|---|---|---|
| 集成方式 | Bagging(并行) | Boosting(串行) |
| 训练方式 | 独立训练每棵树 | 每棵树纠正前一棵树的错误 |
| 目标函数 | 最小化均方误差 | 最小化损失函数+正则项 |
| 过拟合控制 | 主要通过随机性 | 正则化+早停 |
| 训练速度 | 快(并行) | 较慢(串行,但可并行化) |
| 预测精度 | 通常较高 | 通常更高 |
参数深度解析:
-
n_estimators=1200 & learning_rate=0.03:
- Boosting原理:XGBoost是加法模型,每棵树都是在前一棵树的基础上进行改进
- 学习率权衡:较小的学习率(0.03)需要更多的树(1200)来达到相同的性能
- 公式:y^=∑m=1Mα⋅fm(x)y^=∑m=1Mα⋅fm(x),其中αα是学习率,MM是树的数量
- 优势:小学习率+多树数,通常能获得更好的泛化性能
-
max_depth=7:
- 树复杂度控制:限制树的深度,防止过拟合
- 经验值:7层深度可以捕捉到3-4阶的特征交互
- 与RF对比:RF通常不限制深度(或设置很大),因为通过Bagging已经控制了过拟合
-
subsample=0.9 & colsample_bytree=0.9:
- 随机性引入:类似于RF的Bootstrap和特征采样
- 过拟合控制:通过随机采样,增加模型的鲁棒性
- Stochastic Gradient Boosting:这是XGBoost的随机版本
-
reg_lambda=1.0:
- L2正则化:在目标函数中加入λ∑j=1Twj2λ∑j=1Twj2项
- 防止过拟合:惩罚过大的叶节点权重
- 与RF对比:RF主要通过随机性控制过拟合,XGBoost通过显式正则化
-
tree_method="hist":
- 直方图算法:将连续特征离散化为直方图,加速分裂点查找
- 性能提升:比精确算法快10-100倍
- 精度损失:通常可以忽略,但可以通过增加直方图bin数来提高精度
XGBoost的目标函数:
XGBoost优化的目标函数为:
L=∑i=1nl(yi,y^i)+∑m=1MΩ(fm)L=i=1∑nl(yi,y^i)+m=1∑MΩ(fm)
其中:
- l(yi,y^i)l(yi,y^i) = 损失函数(如均方误差)
- Ω(fm)=γT+12λ∑j=1Twj2Ω(fm)=γT+21λ∑j=1Twj2 = 正则化项
- TT = 树的叶节点数
- wjwj = 第jj个叶节点的权重
二阶泰勒展开:
XGBoost使用二阶泰勒展开来近似目标函数,这使得它比只使用一阶信息的传统GBDT更加精确:
L(t)≈∑i=1n[l(yi,y^i(t−1))+gift(xi)+12hift2(xi)]+Ω(ft)L(t)≈i=1∑n[l(yi,y^i(t−1))+gift(xi)+21hift2(xi)]+Ω(ft)
其中:
- gi=∂l(yi,y^i(t−1))∂y^i(t−1)gi=∂y^i(t−1)∂l(yi,y^i(t−1)) = 一阶梯度
- hi=∂2l(yi,y^i(t−1))∂(y^i(t−1))2hi=∂(y^i(t−1))2∂2l(yi,y^i(t−1)) = 二阶梯度(Hessian)
第四章:数据标准化:为什么只标准化特征而不标准化目标?
这是本项目的一个关键设计决策,值得深入分析。
4.1 标准化的数学原理
Z-score标准化公式:
z=x−μσz=σx−μ
其中:
- μμ = 特征的均值
- σσ = 特征的标准差
- zz = 标准化后的值(均值为0,标准差为1)
4.2 为什么标准化特征?
-
消除量纲影响:
- 28个控制变量可能具有不同的量纲和数量级
- 例如:温度可能是几百摄氏度,而速度可能是几十米/秒
- 如果不标准化,数量级大的特征会主导模型训练
-
加速收敛:
- 标准化后的特征分布更均匀,梯度下降(对于XGBoost)或树分裂(对于RF)更稳定
- 特别是对于基于距离的算法,标准化是必须的
-
数值稳定性:
- 避免数值溢出或下溢
- 提高计算的数值精度
4.3 为什么不标准化目标变量?
核心原因:保持预测结果的物理意义
# 标准化特征X(Z-score标准化)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 注意:目标变量y不进行标准化,保持原始尺度(单位:mm)
# 这样预测结果就是原始尺度的,有实际物理意义
如果标准化目标变量会发生什么?
假设我们标准化了目标变量:
- 训练时:模型学习的是标准化后的厚度值(例如:-1.5, 0.3, 2.1等)
- 预测时:模型输出也是标准化后的值
- 问题:需要反标准化才能得到真实的厚度值(单位:mm)
- 风险:如果标准化参数(均值、标准差)丢失或错误,预测结果将完全错误
不标准化目标变量的优势:
- 直接可解释:预测结果直接是厚度值(mm),无需转换
- 误差指标直观:MAE = 0.0036mm,直接表示平均误差为3.6微米
- 生产部署简单:不需要保存目标变量的标准化参数
- 减少错误风险:避免反标准化过程中的潜在错误
数学验证:
对于线性模型,标准化目标变量不会改变模型的本质(只是缩放),但对于非线性模型(如树模型),标准化目标变量可能会影响模型的学习过程。不过,在本项目中,由于使用的是树模型,标准化或不标准化目标变量对模型性能的影响通常很小,主要考虑的是可解释性和部署便利性。
第五章:训练过程的工程化实现
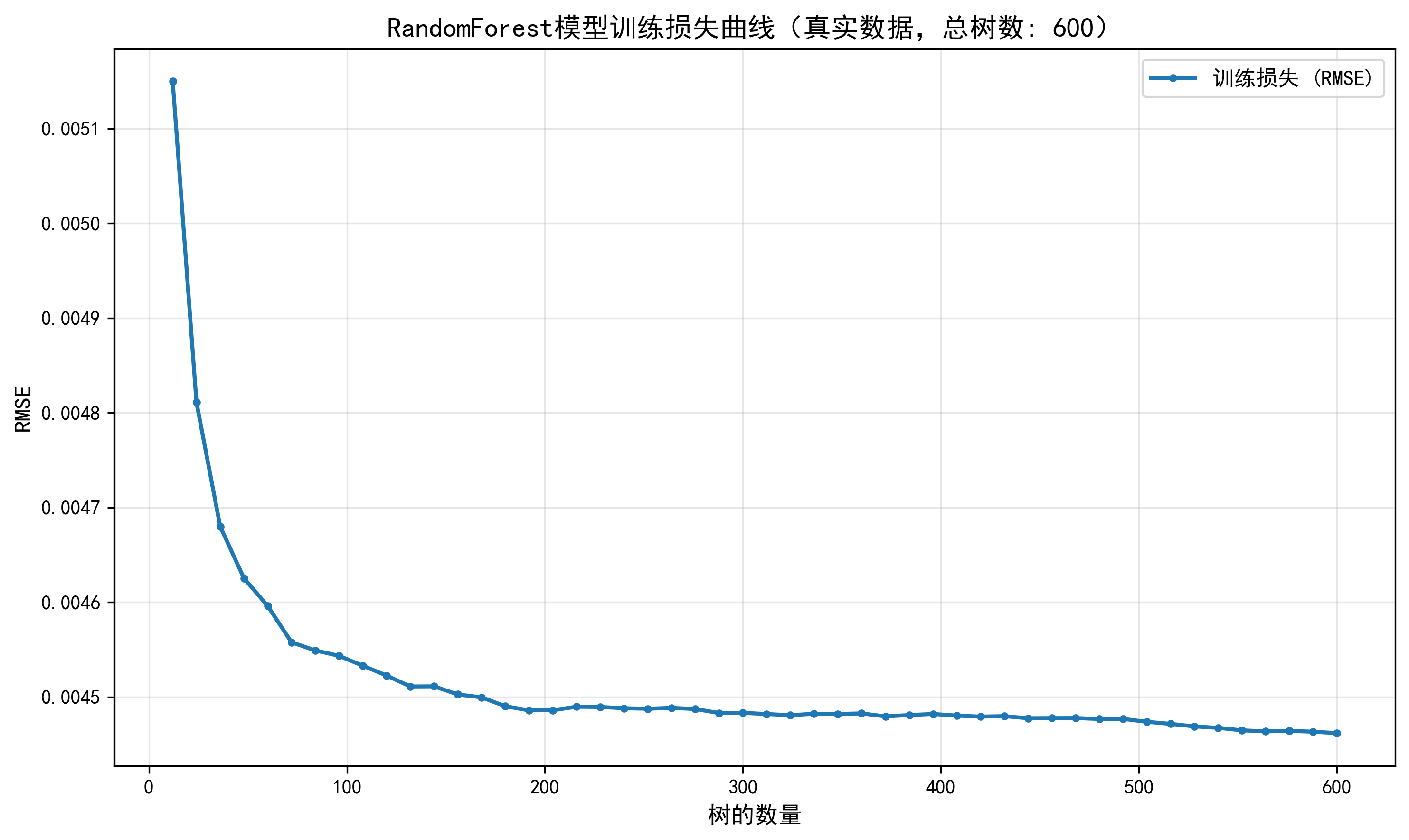
5.1 训练历史记录:真实损失曲线的绘制
本项目的一个亮点是真实训练损失曲线的绘制,而不是使用模拟数据。
对于XGBoost:
if model_name == "xgb":
eval_set = [(X_train_scaled, y_train)]
model.fit(
X_train_scaled, y_train,
eval_set=eval_set,
eval_metric="rmse",
verbose=False
)
training_history = model.evals_result_
XGBoost在训练过程中会自动记录评估集的指标,我们可以直接使用evals_result_获取训练历史。
对于RandomForest:
RandomForest没有内置的训练历史记录功能,本项目采用了逐步训练的方法:
elif model_name == "rf":
n_estimators = model.n_estimators
step = max(1, n_estimators // 50) # 记录50个点
training_history = {"train_rmse": []}
# 逐步训练并记录损失
for n in range(step, n_estimators + 1, step):
temp_model = RandomForestRegressor(
n_estimators=n,
max_features=model.max_features,
min_samples_leaf=model.min_samples_leaf,
random_state=random_state,
n_jobs=-1
)
temp_model.fit(X_train_scaled, y_train)
pred = temp_model.predict(X_train_scaled)
mse = np.mean((y_train - pred) ** 2)
rmse = np.sqrt(mse)
training_history["train_rmse"].append(rmse)
关键技术点:
- 采样策略:每10棵树记录一次(600棵树记录50个点),平衡了精度和计算成本
- 独立训练:每次训练一个独立的模型,确保记录的损失是真实的
- 计算成本:这种方法需要训练50个模型,计算成本较高,但提供了真实的训练曲线

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)