Ollama 下载安装教程(2025 最新版):本地运行大模型的快速上手指南
Ollama本地AI模型部署指南(2025最新版) Ollama作为当前最受欢迎的轻量化本地大模型运行平台,支持在Windows、Mac和Linux系统上快速部署ChatGPT、LLaMA等主流AI模型。本文提供完整安装教程,包含: 安全下载路径与一键安装流程 命令行运行模型的详细步骤 性能优化技巧与常见问题解决方案 优势特点: 零配置安装,自动解决依赖问题 支持多种开源模型格式 完全离线运行保障
一、前言
随着人工智能大模型技术的持续演进,大多数用户已经不再满足于仅通过在线服务或API来体验AI能力。越来越多的人希望能在自己的电脑上直接运行ChatGPT、LLaMA、Mistral等主流AI模型,从而获得更高的隐私性、更快的响应速度和更多个性化的控制空间。
在众多本地部署解决方案中,Ollama 几乎成为最受欢迎的选择之一。它以轻量级架构、即装即用、模型兼容性强等特点,成功吸引了大量开发者和AI爱好者的关注。无论是想在笔记本电脑上体验本地GPT模型,还是为新项目构建离线AI助手,Ollama 都能提供高效、稳定的运行环境。
本文将为你带来一份详尽的 Ollama 下载安装教程(2025最新版),帮助新手与开发者在最短时间内完成环境搭建与模型运行。你将在本文中获得:
- ✅ 安全稳定的 Ollama 下载与安装路径
- ✅ 图文并茂的安装与配置步骤
- ✅ 本地模型运行及调试示例
- ✅ 常见问题与运行优化技巧
无论你是AI初学者还是专业开发者,这份教程都能让你快速掌握Ollama的完整安装流程与实际应用方法。

可以通过以下链接下载(经过毒霸安全认证):
ollama最新下载官方免费版![]() https://dubapkg.cmcmcdn.com/cs/257def/ollama.exe
https://dubapkg.cmcmcdn.com/cs/257def/ollama.exe
二、Ollama 简介:为什么值得选择它?
Ollama 是一个轻量化的本地大模型运行平台,旨在让用户无需复杂配置即可在本地运行各种主流开源语言模型(LLMs)。它支持 Mac、Windows 及 Linux 系统,并提供命令行工具与API接口,可直接调用模型进行自然语言处理、代码生成或内容创作任务。
与其他部署方案相比,Ollama 有以下优势:
- 零配置安装:仅需下载并运行一个安装包,即可自动配置环境,无需手动安装CUDA、Python或模型依赖库。
- 兼容多种模型格式:原生支持 LLaMA、Mistral、Gemma 等主流开源模型,用户可自由加载或切换不同的模型实例。
- 离线运行:安装完成后即可脱离网络独立使用,保障模型数据的隐私与安全。
- 资源占用低:针对本地硬件进行优化,可在中端GPU或高性能CPU上流畅运行。
- 开放扩展性:支持与前端或应用系统进行API集成,方便开发者进行二次开发。
正因如此,Ollama 已逐渐成为“个人级大模型运行”领域的代表性工具之一。
三、Ollama 下载安装教程(Windows & Mac 全流程)
1. 下载 Ollama 安装包
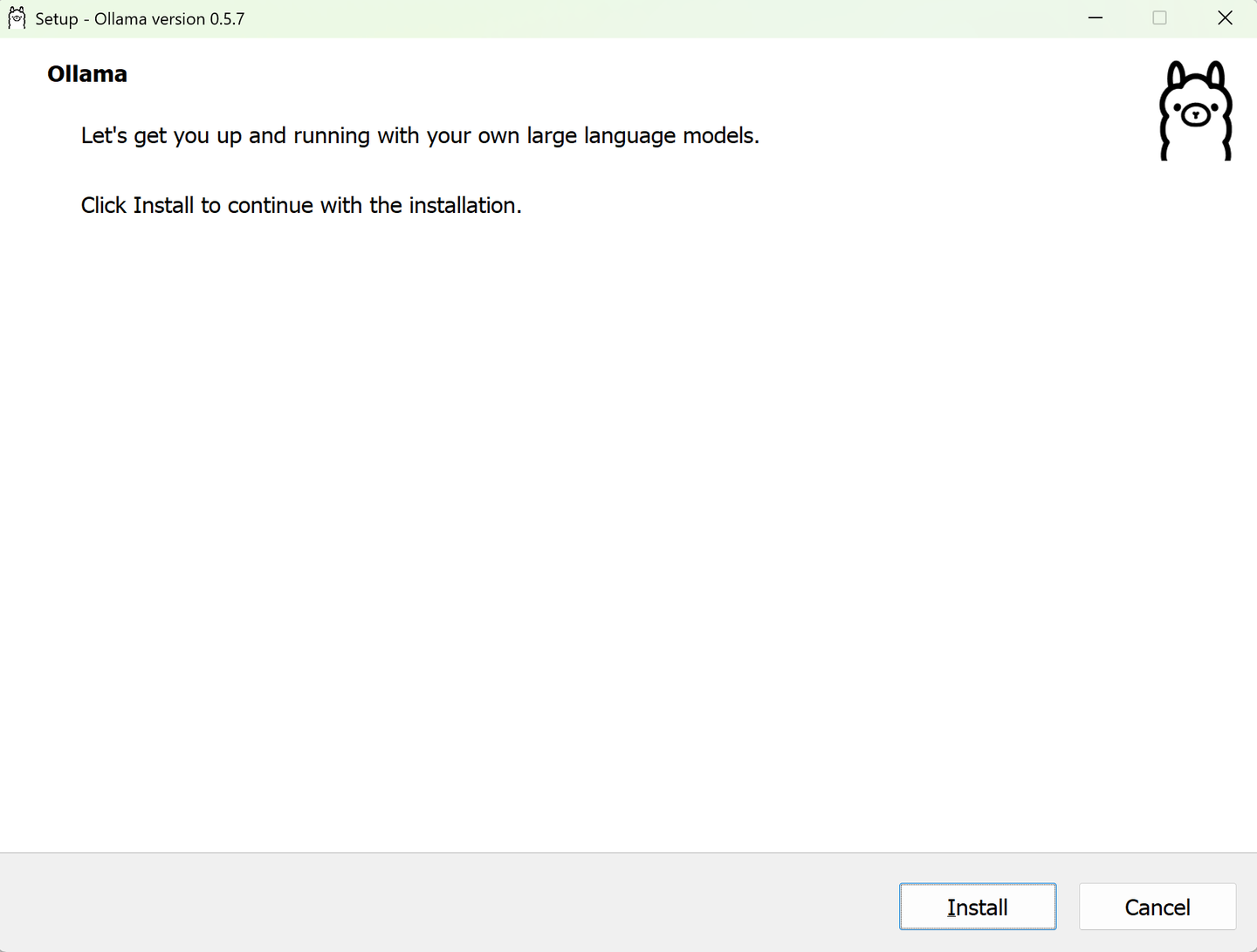
首先,前往 Ollama 官网或镜像资源中心,选择与你系统版本匹配的安装包。目前 Ollama 已提供:
- Windows 版安装包 (.exe)
- macOS 版安装包 (.pkg)
- Linux 安装脚本 (.sh)
推荐直接在浏览器中访问主项目页面,通过安全链接下载对应版本。例如在 Windows 系统中,保存文件后建议将安装包放置于 Downloads 文件夹,便于后续统一管理。
建议通过以下链接下载(经过毒霸安全认证):
ollama最新下载官方免费版![]() https://dubapkg.cmcmcdn.com/cs/257def/ollama.exe
https://dubapkg.cmcmcdn.com/cs/257def/ollama.exe
提示:请确保下载过程中网络稳定,避免由于下载中断而导致文件损坏或安装异常。
2. 安装 Ollama 客户端
双击安装包后,根据系统提示完成以下步骤:
- 阅读许可协议并点击“继续”;
- 选择安装路径(建议保留默认目录);
- 等待文件释放与依赖安装完成;
- 安装结束后,系统会提示 “Ollama has been successfully installed”。
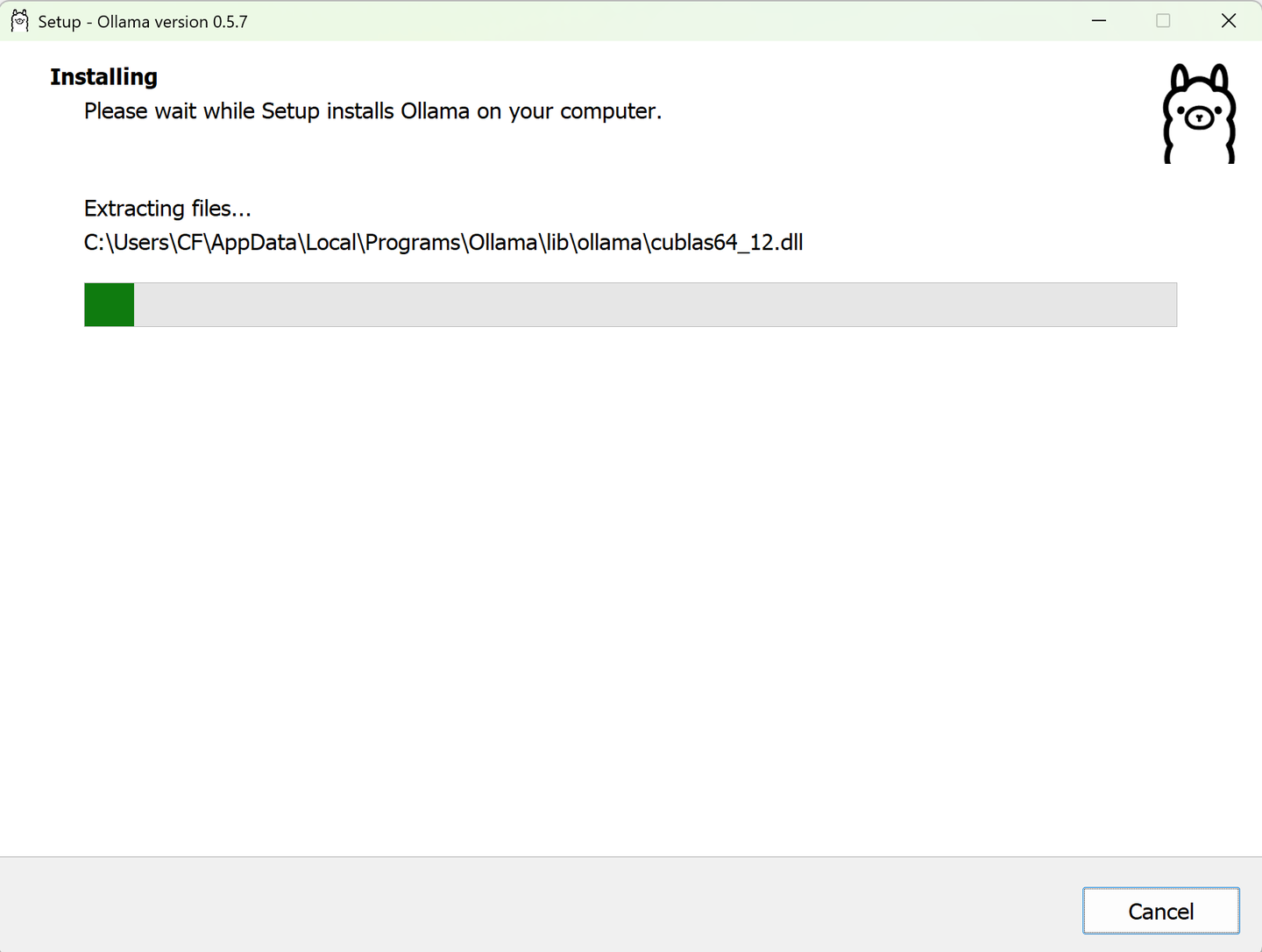
安装完成后,你可以在命令行或终端中直接输入以下命令检测是否安装成功:
ollama --version
若能正常输出版本号信息,则表示 Ollama 已成功部署到本地系统。
3. 启动并运行第一个模型
Ollama 提供了模型快速加载机制,你可以直接从内置仓库中获取常用AI模型。例如要运行 LLaMA 模型,只需输入以下命令:
ollama run llama2
系统会自动从模型源同步必要文件,下载完成后即可交互式运行。首次加载速度取决于网络与硬件性能,之后的运行将显著加快。
运行示例:
> ollama run llama2
Welcome to LLaMA 2 on Ollama!
You: 你好,请帮我写一段自我介绍。
AI: 你好,我是一款运行在你本地的语言模型,可以帮助你生成文本、翻译、总结内容等。
通过命令行界面即可实现问答、写作、编程等多种任务,无需借助浏览器或云端接口。
四、Ollama 的进阶使用与配置优化
安装完成后,若你希望更深入地配置使用,可参考以下优化建议:
1. 调整模型缓存路径
对磁盘空间较有限的用户,可将模型缓存目录移动至大容量硬盘,以防止占满系统盘:
ollama set path D:\OllamaCache
此命令会将后续模型文件保存至自定义路径,有助于提升加载性能。
2. 自定义模型与参数
Ollama 支持通过配置文件加载本地自定义模型,仅需在 ~/.ollama/models 目录下创建模型文件夹,并在其中放置 .gguf 模型权重。
例如,在命令行中运行:
ollama run ./models/mymodel.gguf
即可直接载入个人训练模型,非常适合有开发或微调需求的用户。
3. 调整运行性能
对于GPU用户,可使用命令行参数指定显存占用与线程并行:
ollama run llama2 --gpu --threads 8
此命令可大幅提升推理速度,同时保持系统流畅度。
五、常见问题与解决方案
(1)安装后无法运行命令?
确认安装路径已加入系统环境变量,若未自动配置,可手动添加 Ollama 安装目录至 PATH。
(2)终端提示“model not found”怎么办?
检查模型名称是否正确,或使用 ollama list 查看本地已安装模型;若无模型,可重新执行 ollama pull <模型名> 下载。
(3)占用内存过大?
部分模型体积较大,可尝试加载体积更小的版本(如 mini 或 7B 级模型),在中低端设备上更为适配。
(4)如何更新 Ollama?
直接重新下载并安装最新版本即可,程序会自动覆盖旧文件并保留你的模型数据。
六、总结:让 AI 真正跑在你电脑上
本文完整介绍了 Ollama 下载安装 的全过程,从下载安装包、运行环境检测,到模型加载与性能优化,覆盖了新手入门到进阶使用的所有核心环节。
与传统云端调用不同,Ollama 让AI模型运行彻底本地化,无需申请API密钥、无需联网依赖,也不受网络延迟影响。在隐私、安全与可控性方面,它为个人用户和开发者都提供了新的选择。
通过本文的步骤,你可以轻松实现:
- 完整安装并运行 Ollama 客户端;
- 快速加载并体验主流大模型;
- 结合配置命令实现性能优化与个性化部署。
如今,越来越多的创作者、程序员乃至研究人员,正在转向本地AI运行方案。Ollama 凭借极简部署与强兼容性,成为多数用户实现「AI 本地化」的首选工具。如果你也想拥有一个离线、高效、安全的AI环境,那么立即开始本教程中的 Ollama 下载安装 吧——你的电脑,从此也能成为强大的AI工作站。
最后附上下载链接(经过毒霸安全认证):
ollama最新下载官方免费版![]() https://dubapkg.cmcmcdn.com/cs/257def/ollama.exe
https://dubapkg.cmcmcdn.com/cs/257def/ollama.exe

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 17
17 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)