手把手教你用 RAG 打造专属知识库问答系统
无论你是开发者、AI 爱好者,还是企业技术决策者,这篇干货都能帮你快速掌握 RAG 落地的核心能力!
大模型能力强大,却受限于静态知识库,还容易“一本正经地胡说八道”。RAG(检索增强生成)正是破局关键!本文深入浅出讲解 RAG 的核心原理——通过实时检索外部知识库,为生成模型注入最新、最准的上下文信息,显著提升回答的准确性、专业性与可解释性。
带你从零搭建本地 RAG 系统:使用 PyPDF2 解析 PDF、DashScope 嵌入模型向量化、Faiss 构建高效检索库,并通过 LangChain 调用 DeepSeek 大模型实现智能问答。全流程覆盖数据预处理、索引构建到问答生成,附关键技术细节与工程实践建议。
无论你是开发者、AI 爱好者,还是企业技术决策者,这篇干货都能帮你快速掌握 RAG 落地的核心能力!
一、RAG简介
1.什么是RAG?
RAG(Retrieval-Augmented Generation):
检索增强生成,是一种结合信息检索(Retrieval)和文本生成(Generation)的技术。
RAG技术通过实时检索相关文档或信息,并将其作为上下文输入到生成模型中,从而提高生成结果的时效性和准确性。
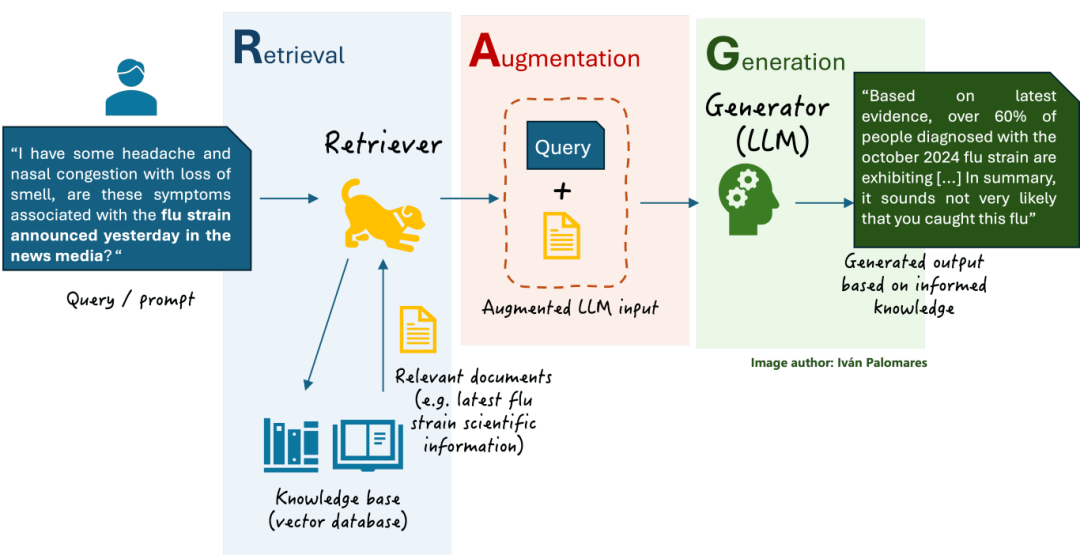
2.RAG的优势是什么?
- 解决知识时效性问题
大模型的训练数据通常是静态的,无法涵盖最新信息,而RAG可以检索外部知识库实时更新信息。
-
减少模型幻觉
通过引入外部知识,RAG能够减少模型生成虚假或不准确内容的可能性。
-
提升专业领域回答质量
RAG能够结合垂直领域的专业知识库,生成更具专业深度的回答。
-
生成内容的溯源(可解释性)
3.RAG 的核心原理与流程

步骤1:数据预处理,构建索引库
-
知识库构建:
收集并整理文档、网页、数据库等多源数据,构建外部知识库。
-
文档分块:
将文档切分为适当大小的片段(chunks),以便后续检索。分块策略需要在语义完整性与检索效率之间取得平衡。
-
向量化处理
使用嵌入模型(如BGE、M3E、ChineseAlpaca2等)将文本块转换为向量,并存储在向量数据库中
步骤2:检索阶段
-
查询处理
将用户输入的问题转换为向量,并在向量数据库中进行相似度检索,找到最相关的文本片段。
-
重排序
对检索结果进行相关性排序,选择最相关的片段作为生成阶段的输入。
步骤3:检索阶段
-
上下文组装
将用户输入的问题转换为向量,并在向量数据库中进行相似度检索,找到最相关的文本片段。
-
生成回答
对检索结果进行相关性排序,选择最相关的片段作为生成阶段的输入。
划重点:RAG本质上就是重构了一个新的 Prompt!
4.NativeRAG
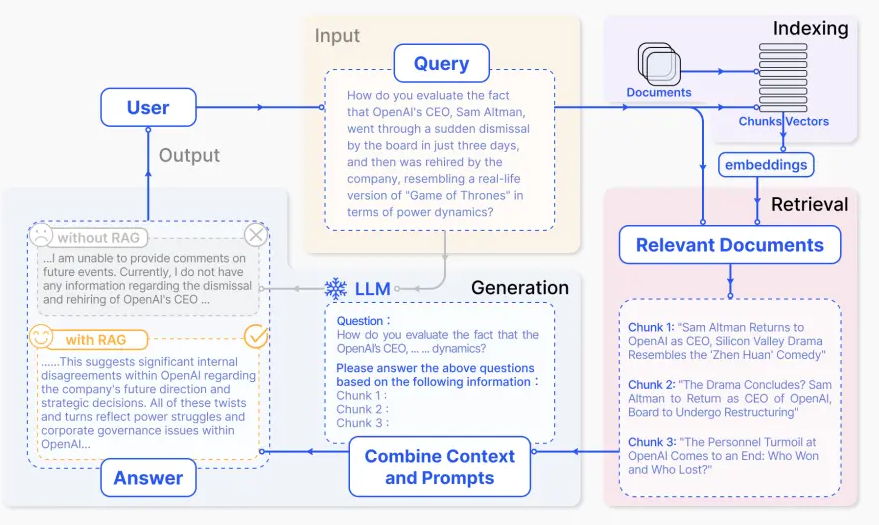
NativeRAG的步骤:
-
Indexing
如何更好地把知识存起来。
-
Retrieval
如何在大量的知识中,找到一小部分有用的,给到模型参考。
-
Generation
如何结合用户的提问和检索到的知识,让模型生成有用的答案。
上面三个步骤虽然看似简单,但在 RAG 应用从构建到落地实施的整个过程中,涉及较多复杂的工作内容!
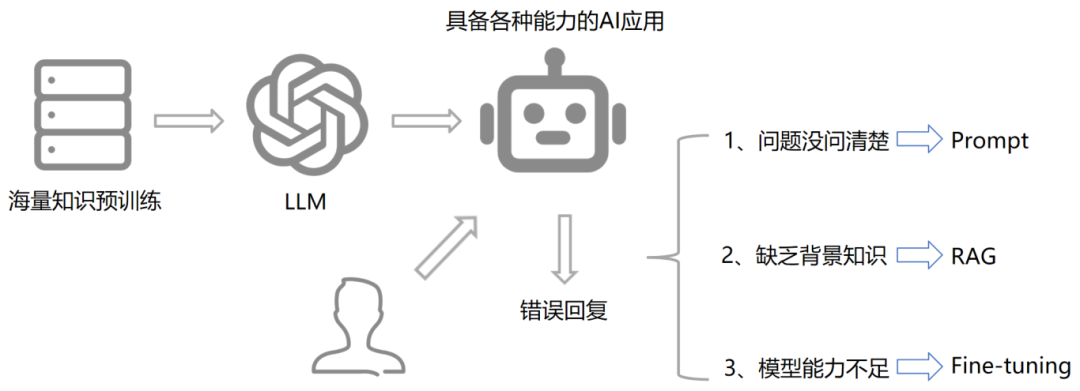
5.Prompt vs RAG vs Fine-tuning 什么时候使用?
二、Embedding模型选择
1.通用文本嵌入模型
BGE-M3(智源研究院)
特点:支持100+语言,输入长度达8192tokens,融合密集、稀疏、多向量混合检索,适合跨语言长文档检索。
适用场景:跨语言长文档检索、高精度RAG应用。
文件大小:2.3G
text-embedding-3-large(OpenAI)
特点:向量维度3072维,长文本语义捕捉能力强,英文表现优秀。
适用场景:英文内容优先的全球化应用。
jina-embedding-v2-small(Jina AI)
特点:参数量仅35M,支持实时推理(RT<50ms),适合轻量化部署。
适用场景:轻量级文本处理、实时推理任务。
2.中文嵌入模型
M3E-Base
特点:针对中文优化的轻量模型,适合本地化部署。
适用场景:中文法律、医疗领域检索任务。
文件大小:0.4G
xiaobu-embedding-v2
特点:针对中文语义优化,语义理解能力强。
适用场景:中文文本分类、语义检索。
stella-mrl-large-zh-v3.5-1792
特点:处理大规模中文数据能力强,捕捉细微语义关系。
适用场景:中文文本高级语义分析、自然语言处理任务。
3.指令驱动与复杂任务模型
gte-Qwen2-7B-instruct(阿里巴巴)
特点:基于Qwen大模型微调,支持代码与文本跨模态检索。
适用场景:复杂指令驱动任务、智能问答系统。
E5-mistral-7B(Microsoft)
特点:基于Microsoft架构,Zero-shot任务表现优异。
适用场景:动态调整语义密度的复杂系统。
4.企业级与复杂系统
BGE-M3(智源研究院)
特点:适合企业级部署,支持混合检索。
适用场景:企业级语义检索、复杂RAG应用。
E5-mistral-7B(Microsoft)
特点:适合企业级部署,支持指令微调。
适用场景:需要动态调整语义密度的复杂系统。
5.CASE-BGE-M3使用
模型下载
from FlagEmbedding import BGEM3FlagModel
model = BGEM3FlagModel('/root/models/BAAI/bge-m3',
use_fp16=True)
示例代码
from FlagEmbedding import BGEM3FlagModel
model = BGEM3FlagModel('/root/models/BAAI/bge-m3',
use_fp16=True)
sentences_1 = ["什么是 BGE M3?", "BM25 的定义"]
sentences_2 = ["BGE M3 是一种嵌入模型,支持稠密检索、词汇匹配和多向量交互。",
"BM25 是一种基于词袋的检索函数,根据查询词在每个文档中出现的情况对文档集合进行排序。"]
embeddings_1 = model.encode(sentences_1,
batch_size=12,
max_length=8192, # 如果不需要这么长的长度,可以设置一个较小的值以加快编码速度。
)['dense_vecs']
embeddings_2 = model.encode(sentences_2)['dense_vecs']
similarity = embeddings_1 @ embeddings_2.T
print(similarity)
# [[0.6265, 0.3477], [0.3499, 0.678 ]]
代码解释
- similarity = embeddings_1 @ embeddings_2.T
计算两组嵌入向量(embeddings)之间的相似度矩阵。
embeddings_1包含了第一组句子(sentences_1)的嵌入向量,形状为[sentences_1的数量,嵌入维度]
embeddings_2包含了第二组句子(sentences_2)的嵌入向量,形状为[sentences_2的数量,嵌入维度]
embeddings_2.T是对embeddings_2进行转置操作,形态变为[嵌入维度,sentences_2的数量]
- @符号在Python中表示矩阵乘法运算
通过矩阵乘法计算了两组句子之间的余弦相似度矩阵。结果similarity形状是[sentences_1的数量,sentences_2的数量]
6.gte-qwen2使用
模型下载
from sentence_transformers import SentenceTransformer
model_dir = "/root/models/iic/gte_Qwen2-1___5B-instruct"
model = SentenceTransformer(model_dir, trust_remote_code=True)
示例代码
from sentence_transformers import SentenceTransformer
model_dir = "/root/models/iic/gte_Qwen2-1___5B-instruct"
model = SentenceTransformer(model_dir, trust_remote_code=True)
model.max_seq_length = 8192
queries = [ "女性每天应该摄入多少蛋白质?", "“summit”的定义是什么?",]
documents = [ "根据一般指南,美国疾控中心(CDC)建议19至70岁女性每日平均蛋白质摄入量为46克。但如下面图表所示,如果你正在备孕或备战马拉松,就需要增加摄入量。请查看下方图表,了解你每天应摄入多少蛋白质。", "“summit”对英语学习者的定义:1. 山的最高点;山顶。2. 最高水平。3. 两个或多个国家领导人之间的会议或系列会议。",]
document_embeddings = model.encode(documents)
print(scores.tolist())
三、RAG实战
基于LangChain,采用DeepSeek+Faiss快速搭建本地知识库检索。
3.1 环境准备
1)本地安装好Conda环境
2)推荐使用阿里大模型平台百炼:
https://bailian.console.aliyun.com/
3)百炼平台使用:注册登录、申请api key。
3.2 技术选型
-
向量数据库:Faiss作为高效的向量检索
-
嵌入模型:阿里云DashScope的text-embedding-v1
-
大语言模型:deepseek-v3
-
文档处理:PyPDF2用于PDF文本提取
3.3 程序逻辑结构介绍
步骤1:文档预处理
PDF文件->文本提取->文本分割-页码映射;
1)PDF文本提取
- 逐页提取文本内容
- 记录每行文本对应的页码信息
- 处理空页和异常情况
2)文本分割策略
- 使用递归字符分割器
- 分割参数:chunk_size=1000,chunk_overlap=200
- 分割优先级:段落->句子->空格->字符
3)页面映射处理
- 基于字符位置计算每个文本块的页面
- 使用众数统计确定文本块的主要来源页码
- 建立文本块与页码的映射关系
步骤2:知识库构建
文本块->嵌入向量->Faiss索引->本地持久化
1)向量数据库构建
- 使用DashScope嵌入模型生成向量
- 将向量存储到Faiss索引结构
2)数据持久化
- 保存Faiss索引文件(.faiss)
- 保存元数据信息(.pkl)
- 保存页码映射关系(page_info.pkl)
步骤3:问答查询
用户问题->向量检索->文档组合->LLM生成->答案输出
1)相似度检索
- 将用户问题转换为向量
- 在Faiss中搜索最相似的文档块,返回Top-K相关文档
2)问答链处理
- 使用LangChain的load_qa_chain
- 采用stuff策略组合文档
- 将组合后的上下文和问题发送给LLM
3)答案生成与展示
3.4代码实例
安装依赖的包
!pip install pypdf2
!pip install dashscope
!pip install langchain
!pip install langchain-openai
!pip install langchain-community
!pip install faiss-cpu
导入依赖的包
from PyPDF2 import PdfReader
from langchain.chains.question_answering import load_qa_chain
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_community.vectorstores import FAISS
from typing import List, Tuple
import os
import pickle
从PDF中提取文本并记录每个字符对应的页码
def extract_text_with_page_numbers(pdf) -> Tuple[str, List[Tuple[str, int]]]:
"""
从PDF中提取文本并记录每个字符对应的页码
参数:
pdf: PDF文件对象
返回:
text: 提取的文本内容
char_page_mapping: 每个字符对应的页码列表
"""
text = ""
char_page_mapping = []
for page_number, page in enumerate(pdf.pages, start=1):
extracted_text = page.extract_text()
if extracted_text:
text += extracted_text
# 为当前页面的每个字符记录页码
char_page_mapping.extend([page_number] * len(extracted_text))
else:
print(f"No text found on page {page_number}.")
return text, char_page_mapping
处理文本并创建向量存储
def process_text_with_splitter(text: str, char_page_mapping: List[int], save_path: str = None) -> FAISS:
"""
处理文本并创建向量存储
参数:
text: 提取的文本内容
char_page_mapping: 每个字符对应的页码列表
save_path: 可选,保存向量数据库的路径
返回:
knowledgeBase: 基于FAISS的向量存储对象
"""
# 创建文本分割器,用于将长文本分割成小块
text_splitter = RecursiveCharacterTextSplitter(
separators=["\n\n", "\n", ".", " ", ""],
chunk_size=1000,
chunk_overlap=200,
length_function=len,
)
# 分割文本
chunks = text_splitter.split_text(text)
print(f"文本被分割成 {len(chunks)} 个块。")
# 创建嵌入模型
embeddings = DashScopeEmbeddings(
model="text-embedding-v1",
dashscope_api_key=DASHSCOPE_API_KEY,
)
# 从文本块创建知识库
knowledgeBase = FAISS.from_texts(chunks, embeddings)
print("已从文本块创建知识库。")
# 为每个文本块找到对应的页码信息
page_info = {}
current_pos = 0
for chunk in chunks:
chunk_start = current_pos
chunk_end = current_pos + len(chunk)
# 找到这个文本块中字符对应的页码
chunk_pages = char_page_mapping[chunk_start:chunk_end]
# 取页码的众数(出现最多的页码)作为该块的页码
if chunk_pages:
# 统计每个页码出现的次数
page_counts = {}
for page in chunk_pages:
page_counts[page] = page_counts.get(page, 0) + 1
# 找到出现次数最多的页码
most_common_page = max(page_counts, key=page_counts.get)
page_info[chunk] = most_common_page
else:
page_info[chunk] = 1 # 默认页码
current_pos = chunk_end
knowledgeBase.page_info = page_info
print(f'页码映射完成,共 {len(page_info)} 个文本块')
# 如果提供了保存路径,则保存向量数据库和页码信息
if save_path:
# 确保目录存在
os.makedirs(save_path, exist_ok=True)
# 保存FAISS向量数据库
knowledgeBase.save_local(save_path)
print(f"向量数据库已保存到: {save_path}")
# 保存页码信息到同一目录
with open(os.path.join(save_path, "page_info.pkl"), "wb") as f:
pickle.dump(page_info, f)
print(f"页码信息已保存到: {os.path.join(save_path, 'page_info.pkl')}")
return knowledgeBase
从磁盘加载向量数据库和页码信息
def load_knowledge_base(load_path: str, embeddings = None) -> FAISS:
"""
从磁盘加载向量数据库和页码信息
参数:
load_path: 向量数据库的保存路径
embeddings: 可选,嵌入模型。如果为None,将创建一个新的DashScopeEmbeddings实例
返回:
knowledgeBase: 加载的FAISS向量数据库对象
"""
# 如果没有提供嵌入模型,则创建一个新的
if embeddings is None:
embeddings = DashScopeEmbeddings(
model="text-embedding-v1",
dashscope_api_key=DASHSCOPE_API_KEY,
)
# 加载FAISS向量数据库,添加allow_dangerous_deserialization=True参数以允许反序列化
knowledgeBase = FAISS.load_local(load_path, embeddings, allow_dangerous_deserialization=True)
print(f"向量数据库已从 {load_path} 加载。")
# 加载页码信息
page_info_path = os.path.join(load_path, "page_info.pkl")
if os.path.exists(page_info_path):
with open(page_info_path, "rb") as f:
page_info = pickle.load(f)
knowledgeBase.page_info = page_info
print("页码信息已加载。")
else:
print("警告: 未找到页码信息文件。")
return knowledgeBase
读取PDF文件,并写入到知识库
# 读取PDF文件
pdf_reader = PdfReader('./考核办法.pdf')
# 提取文本和页码信息
text, char_page_mapping = extract_text_with_page_numbers(pdf_reader)
#print('page_numbers=',page_numbers)
print(f"提取的文本长度: {len(text)} 个字符。")
# 处理文本并创建知识库,同时保存到磁盘
save_dir = "./vector_db"
knowledgeBase = process_text_with_splitter(text, char_page_mapping, save_path=save_dir)
如何加载已保存的向量数据库
# 创建嵌入模型
embeddings = DashScopeEmbeddings(
model="text-embedding-v1",
dashscope_api_key=DASHSCOPE_API_KEY,
)
# 从磁盘加载向量数据库
loaded_knowledgeBase = load_knowledge_base("./vector_db", embeddings)
# 使用加载的知识库进行查询
docs = loaded_knowledgeBase.similarity_search("客户经理每年评聘申报时间是怎样的?")
# 直接使用FAISS.load_local方法加载(替代方法)
# loaded_knowledgeBase = FAISS.load_local("./vector_db", embeddings, allow_dangerous_deserialization=True)
# 注意:使用这种方法加载时,需要手动加载页码信息
对话调用
from langchain_community.llms import Tongyi
llm = Tongyi(model_name="deepseek-v3", dashscope_api_key=DASHSCOPE_API_KEY) # qwen-turbo
# 设置查询问题
query = "客户经理被投诉了,投诉一次扣多少分"
#query = "客户经理每年评聘申报时间是怎样的?"
if query:
# 执行相似度搜索,找到与查询相关的文档
docs = knowledgeBase.similarity_search(query,k=10)
# 加载问答链
chain = load_qa_chain(llm, chain_type="stuff")
# 准备输入数据
input_data = {"input_documents": docs, "question": query}
# 执行问答链
response = chain.invoke(input=input_data)
print(response["output_text"])
print("来源:")
# 记录唯一的页码
unique_pages = set()
# 显示每个文档块的来源页码
for doc in docs:
#print('doc=',doc)
text_content = getattr(doc, "page_content", "")
source_page = knowledgeBase.page_info.get(
text_content.strip(), "未知"
)
if source_page not in unique_pages:
unique_pages.add(source_page)
print(f"文本块页码: {source_page}")
3.5 示例总结
- PDF文本提取与处理
- 使用PyPDF2库的PdfReader从PDF文件中提取文本在提取过程中记录每行文本对应的页码,便于后续溯源。
- 使用RecursiveCharacterTextSplitter将长文本分割成小块,便于向量化处理。
- 向量数据库构建
- 使用OpenAIEmbeddings / DashScopeEmbeddings将文本块转换为向量表示。
- 使用FAISS向量数据库存储文本向量,支持高效的相似度搜索为每个文本块保存对应的页码信息,实现查询结果溯源。
- 语义搜索与问答链
- 基于用户查询,使用similarity_search在向量数据库中检索相关文本块。
- 使用文本语言模型和load_qa_chain构建问答链将检索到的文档和用户问题作为输入,生成回答。
- 成本跟踪与结果展示
- 使用get_openai_callback跟踪API调用成本。
- 展示问答结果和来源页码,方便用户验证信息。
四、LangChain中的问答链
在LangChain问答链中,有4种chain\_type,chain\_type参数决定了RAG流程中,如何将检索到的多个相关文档块与用户的问题组合起来,发送给大模型以生成最终答案。需要根据应用场景,选择不同的chain\_type,以保证在效果、成本和速度上的权衡。
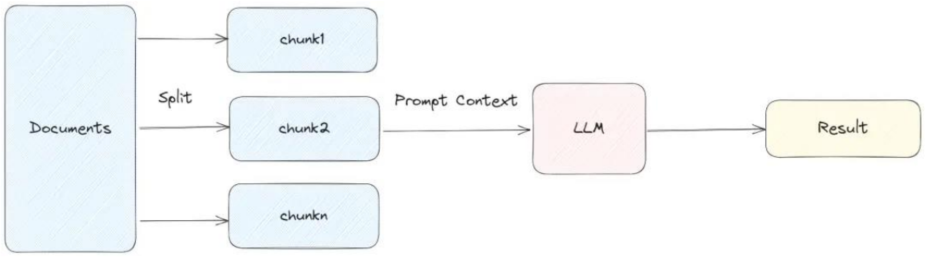
1.stuff(堆叠式)
工作原理:
将所有检索到的文档片段直接拼接成一个长上下文,与问题一起构造 Prompt,单次调用 LLM 生成答案。
优点:
实现最简单、延迟最低;
单次LLM调用,成本最低;
所有信息同时可见,利于全局理解。
缺点:
受限于LLM的最大上下文长度,文档过多或过长时会截断;
若检索结果包含噪声,可能干扰生成质量。
适用场景:
检索返回的文档数量少、内容精炼(如chunk_size较小);
对响应速度和成本敏感的轻量级应用。
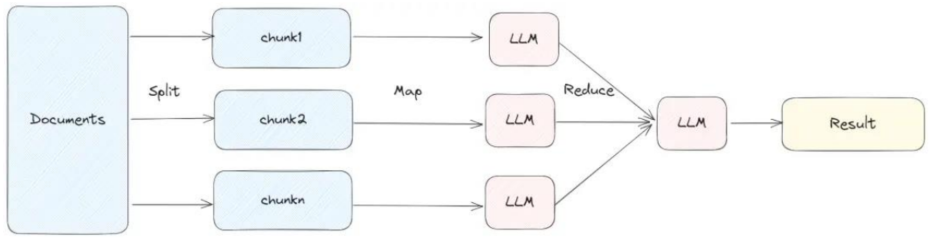
2.map_reduce(映射-归约)
工作原理:
Map阶段:对每个文档(chunk)独立构造Prompt,分别调用LLM生成中间摘要或回答。
Reduce阶段:将所有中间结果合并,再次调用LLM生成最终答案。
优点:
可处理超长文档集合,不受单次上下文长度限制;
Map阶段可并行执行,提升吞吐率;
适合信息分散在多个片段中的场景。
缺点:
至少需要N+1次LLM调用(N为文档数),成本高,延迟大;
各文档独立处理,缺乏文档上下文关联。
适用场景:
检索结果较多且分散;
需要对大量文档进行综合归纳(如报告生成,多源信息整合)。
3.refine(迭代细化)
在第一个chunk上做prompt得到结果,然后再合并下一个文件再输出结果
工作原理:
先用第一个文档和问题生成初步答案;
依次将后续文档与当前答案合并,逐步“细化”输出,每次更新答案。
优点:
能在一定程度上保留跨文档上下文信息;
每次只处理一个新文档 + 当前答案,Token使用较为可控;
最终答案融合了所有文档的信息流。
缺点:
必须串行处理,无法并行,延迟较高;
早期错误可能被累积放大;
适用场景:
文档间存在逻辑递进或补充关系;
需要在有限上下文窗口内处理中等数量文档;
对答案连续性要求较高。

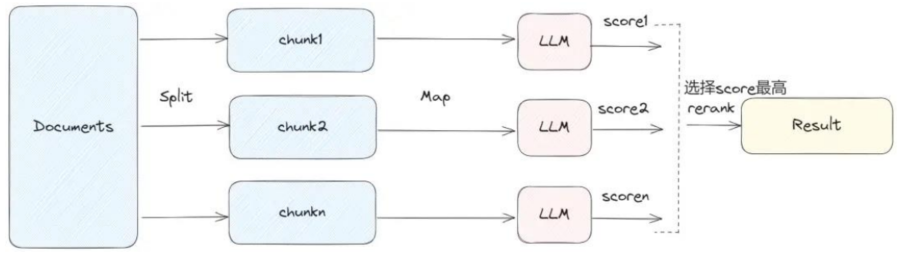
4.map_rerank(映射重排序)
对每个chunk做prompt,然后打个分,然后根据分数返回最好的文档中的结果。
会大量地调用LLM,每个document之间是独立处理。
工作原理:
对每个文档独立构造Prompt,要求LLM输出一个答案+置信度分数;
根据分数排序,返回得分最高的答案(通常只取Top-1).
优点:
能有效过滤低质量或无关文档;
返回的答案来自最相关片段,精准度高。
缺点:
每个文档都需要调用一次LLM,成本高;
不副合多文档信息,仅返回单个最佳答案,可能丢失互补信息;
依赖LLM对“打分”的一致性,部分模型不擅长此任务。
适用场景:
检索结果中存在明显“最佳匹配”文档;
任务为事实型问答(如“XX 的定义是什么?”);
需要高置信度、简洁答案,而非综合归纳。
5.总结
| 特性 | stuff | map_reduce | refine | map_rerank |
|---|---|---|---|---|
| LLM调用次数 | 1 | N + 1 | N | N |
| 速度 | 最快 | 中等 | 最慢 | 慢 |
| Token 消耗 | 低 | 高 | 高 | 高 |
| 处理长文档能力 | 差 | 好 | 好 | 好 |
| 答案质量 | 高 (上下文完整) | 中等 (可能丢失关联) | 最高 (迭代细化) | 取决于最佳块 |
| 适用场景 | 默认选择,文档短 | 文档多,需平衡 | 文档多,要求高精度 | 事实型问题,答案在单块中 |
五、如果LLM可以处理无限上下文,RAG还有意义吗?
-
效率成本
LLM处理上下文时计算资源消耗大,响应时间增加。RAG通过检索相关片段,减少输入长度。
-
知识更新
LLM的知识截止于训练数据,无法实时更新。RAG可以连接外部知识库,增强时效性。
-
可解释性
RAG的检索过程透明,用户可查看来源,增强信任。LLM的生成过程则较难追溯。
-
定制化
RAG可针对特定领域定制检索系统,提供更精准的结果,而LLM的通用性可能无法满足特定需求。
-
数据隐私
RAG允许在本地或私有数据源上检索,避免敏感数据上传云端,适合隐私要求高的场景。
结合LLM的生成能力和RAG的检索能力,可以提升整体性能,提供更全面、准确的回答。
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:
- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 19
19 0
0- 0



 已为社区贡献559条内容
已为社区贡献559条内容

所有评论(0)