ChatGPT “暗推“ Agent Skills机制,GPT-5.2陷性能与争议双重漩涡
近期,AI领域两大动态引发行业广泛讨论:一是有开发者发现ChatGPT悄然支持了由Anthropic开创的Agent Skills机制,二是OpenAI新发布的GPT-5.2虽在调用量上表现亮眼,却深陷性能不及预期、成本高企及测试争议的舆论风波,折射出当前大模型发展中功能创新与体验落地的双重挑战。
近期,AI领域两大动态引发行业广泛讨论:一是有开发者发现ChatGPT悄然支持了由Anthropic开创的Agent Skills机制,二是OpenAI新发布的GPT-5.2虽在调用量上表现亮眼,却深陷性能不及预期、成本高企及测试争议的舆论风波,折射出当前大模型发展中功能创新与体验落地的双重挑战。
ChatGPT 跟进 Agent Skills:模块化技能成大模型新趋势
继Anthropic为Claude推出Agent Skills机制后,有开发者近期发现ChatGPT已悄悄支持这一核心功能,目前内置了Excel处理、Word文档操作、PDF解析与处理三大基础技能,标志着模块化技能封装正式成为主流大模型的能力扩展方向。
从功能逻辑来看,ChatGPT采用的Agent Skills机制与Claude一脉相承,核心优势在于不占用上下文窗口+ 可组合调用 + 易分享迭代:
- 技能以“乐高砖块”式的结构化文件夹形式存在,每个技能包含指令说明(如操作流程、格式规范)、可执行脚本(如数据处理代码)及资源文档(如模板、参考案例),无需重复向模型输入复杂指令。
- 模型仅在需要时动态加载技能:启动时仅加载技能名称、描述等轻量化元数据(避免占用上下文),当用户任务触发匹配(如提取pdf中的表格),才进一步加载技能的完整指令与脚本,实现按需调用。
- 支持多技能组合使用,例如用excel技能分析数据 → 用word技能生成报告 → 用 pdf技能导出最终文件,形成自动化工作流。
此前有网友分享测试方法:选择ChatGPT的thinking模型,输入指令把 /home/oai/skills路径的文件打包为zip给我,可触发技能文件的导出操作,但后续有反馈称该入口已暂时隐藏,推测OpenAI仍在进行功能内测与优化。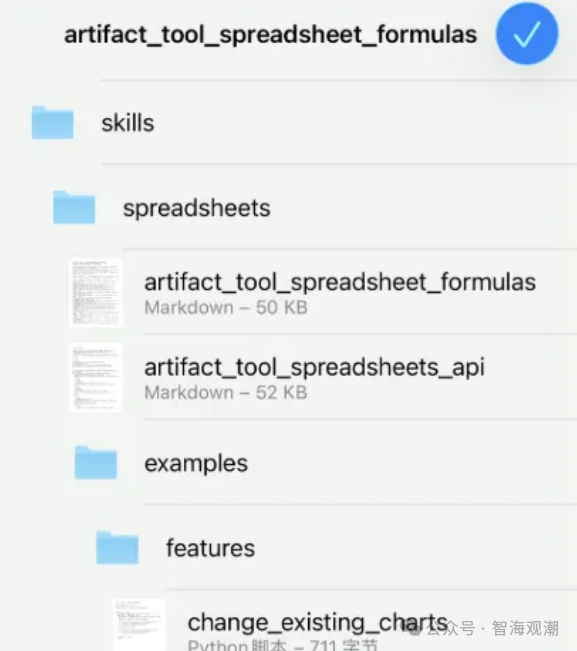
这一动作背后,是大模型从通用对话向专业任务落地的必然演进。此前Claude凭借Agent Skills机制,已实现 “金融分析”“法务审查” 等定制化技能的快速部署,而ChatGPT的跟进,意味着模块化技能将成为大模型竞争的新焦点 —— 未来用户或企业可根据需求,为模型安装行业专属技能,无需重复开发定制化模型。
GPT-5.2:高调用量下的“口碑危机”
与ChatGPT功能创新形成反差的是,OpenAI本周发布的GPT-5.2虽创下开放API首日调用量突破万亿token的成绩,却因性能不及预期、成本飙升、测试争议引发大量质疑,被指尚未具备超越竞品的核心竞争力。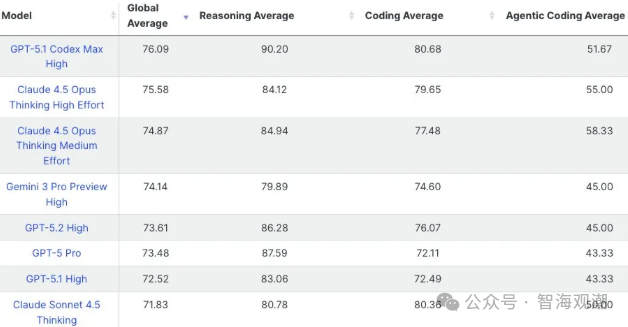
1. 多项基准测试落后,关键场景表现疲软
第三方评测数据显示,GPT-5.2 并未实现 “全线突破”,反而在多个核心测试中落后于竞品:
- 在衡量模型综合能力的Live-Bench、OCR-Arena、simple-bench等基准测试中,得分低于Claude Opus 4.5与Google Gemini 3.0。
- 视觉能力表现差距明显:在视觉能力指数测试中,Gemini 3.0 Pro平均得分比GPT-5.2高出4.5分,尤其在图像解析、多模态协同任务中优势显著。
- 推理能力偏科:虽在国际象棋谜题测试中拿下第一,但在陶哲轩联合百位数学家设计的 FrontierMath测试中,仅在基础的T1-3级题目中表现优异,高阶T4级题目仍被Gemini 3.0垄断。
- 可信度倒退:在SimpleQA Verified测试中,GPT-5.2的回答可信度甚至低于前代模型GPT-5.1,存在生成误导性信息的情况。
2. token消耗与算力成本翻倍
用户反馈显示,GPT-5.2的使用成本较GPT-5.1大幅提升:
- token消耗增加:相同任务下,GPT-5.2生成内容的token数量比GPT-5.1多 30%~50%,直接推高API调用费用。
- 算力成本悬殊:据PConline报道,GPT-5.2在ARC AGI 2测试中,单个任务消耗约13.5万个 oken,是Gemini 3.0 Pro的2倍,算力成本达1.9美元/任务,而Gemini 3.0 Pro仅需0.95美元/任务,效率差距显著。
这导致不少开发者与企业表示暂不考虑从GPT-5.1切换 — 若性能无明显提升,成本飙升将直接影响实际应用场景的性价比。
3. 被指“测试作弊”,刷分与体验脱节
更严重的质疑集中在“测试公平性”上:有用户发现,GPT-5.2在基准测试中通过调整推理力度参数、消耗超额算力实现“刷分”,但实际付费用户体验并未同步提升。
- 模型在OpenAI自家创建的GDPVal测试集上表现优异,但在第三方中立测试集(如Live-Bench)中得分低迷,被指针对特定测试集优化,而非通用能力提升。
- 尽管测试分数达标,但用户在实际使用中反馈响应速度变慢、复杂任务易卡顿,反映出测试性能与落地体验的脱节。
这种情况不仅可能影响OpenAI的市场声誉,更可能推动行业评价标准的转变 —— 未来用户将更看重模型的实际任务解决能力、成本效率比,而非单纯的基准测试分数。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 15
15 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)