04-ai-agent项目的一些简单笔记-初窥门径
一个片段可能信息不全多个角度理解更全面避免检索偏差。
内容比较粗糙 主要是记录一些让我干净醍醐灌顶的清醒点
point1:
简单的接口调用
输入:


输出:



因此引出来了下一个阶段:具有历史记忆的大模型对话
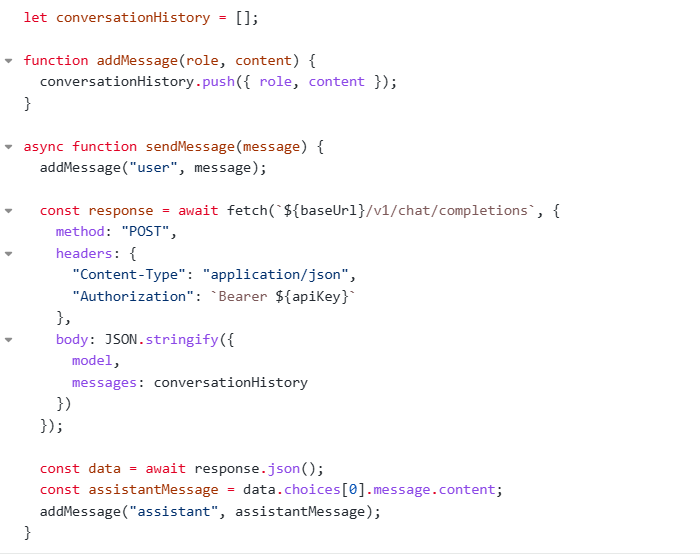 通过代码就能知道多轮对话的记忆来自于系统对messages朴素的管理 每次整理好之后再次发送给模型进行处理
通过代码就能知道多轮对话的记忆来自于系统对messages朴素的管理 每次整理好之后再次发送给模型进行处理
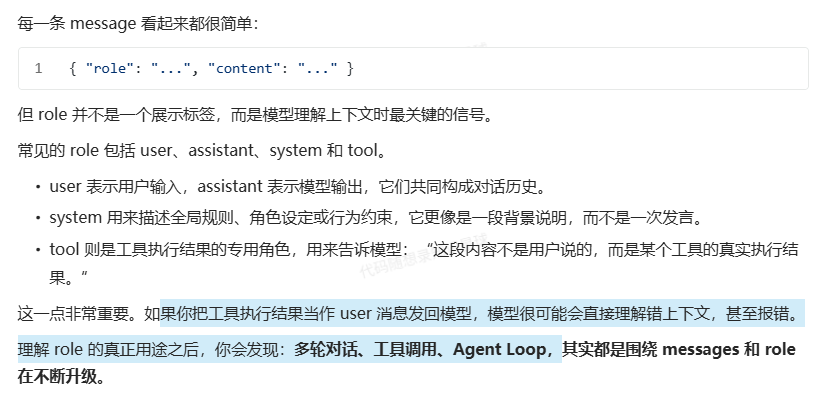 然后让模型具有行动力的tool也是围绕messages进行的
然后让模型具有行动力的tool也是围绕messages进行的
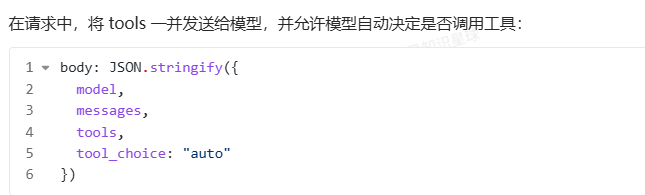

 如果你回头看整个流程,会发现一件非常关键的事情:
如果你回头看整个流程,会发现一件非常关键的事情:
.模型从头到尾都没有"直接做事"
.它只是不断判断:现在还缺什么信息
.每一步缺失的信息,都由系统通过工具补齐这正是工具调用的本质协作方式:
模型负责决策,系统负责执行,而messages记录全过程。
当系统中不止有一次模型调用、不止一个Agent、不止一个模型时,我们该如何把模型能力接入系统,并让它成为一种可配置、可切换、可扩展的基础设施?

我觉得这更是一种思考模型的思维框架
首先,通过BOM管理版本,避免依赖冲突--->然后,根据不同的厂商,引入不同的starter--->最后,在 application.yaml 中配置模型参数--->到这里,模型已经被SpringAI自动装配成了ChatModel Bean--->在Agent系统中,我们约定,每一个可用的模型,对应一个ChatClient对象。ChatClient是对"模型能力"的封装,它屏蔽了模型调用的细节,只暴露统一的对话接口。
当系统中存在多个ChatClient后,下一个问题自然出现了,在运行时,如何根据Agent的配置,选择正确的模型?
一个小的agent需要哪些最基本的东西?

从代码的角度来看 :
.ChatClient:模型能力的入口.
ChatMemory:会话上下文
systemPrompt:系统提示词
sessionld:会话ID.
agentstate:当前Agent的状态
所以引出他的三个最基本的点:系统来帮他记录上下文信息 初始化的系统提示词 初始化的agent状态
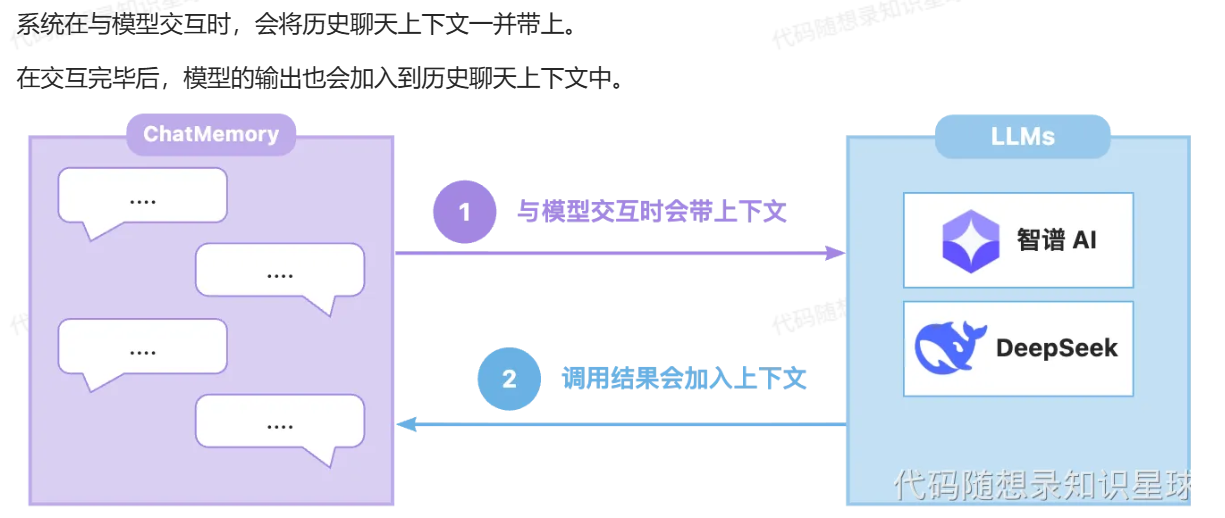

当模型面临只能分析说话但是无法执行行动的时候 我们引入了agent loop来赋予他行动的能力




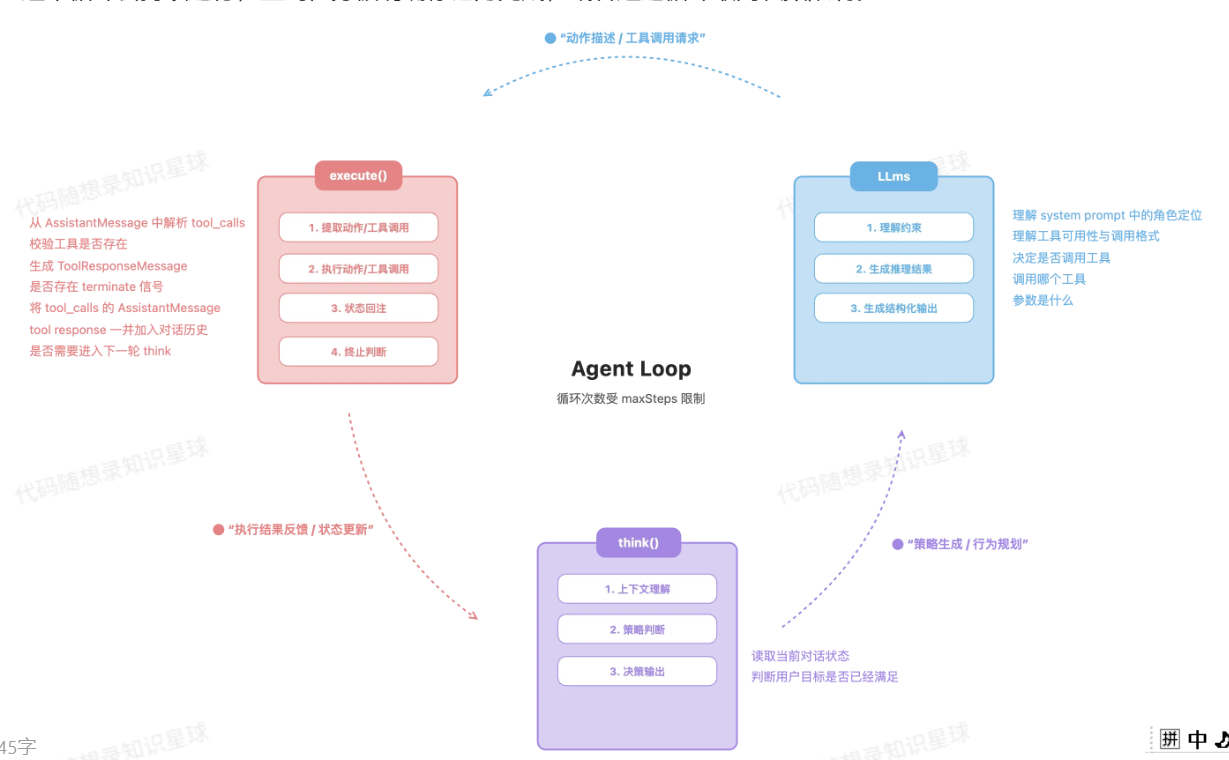


所以很自然的就引入了下一个话题:RAG
- 如何把内容放进知识库
- 如何进行知识库的检索
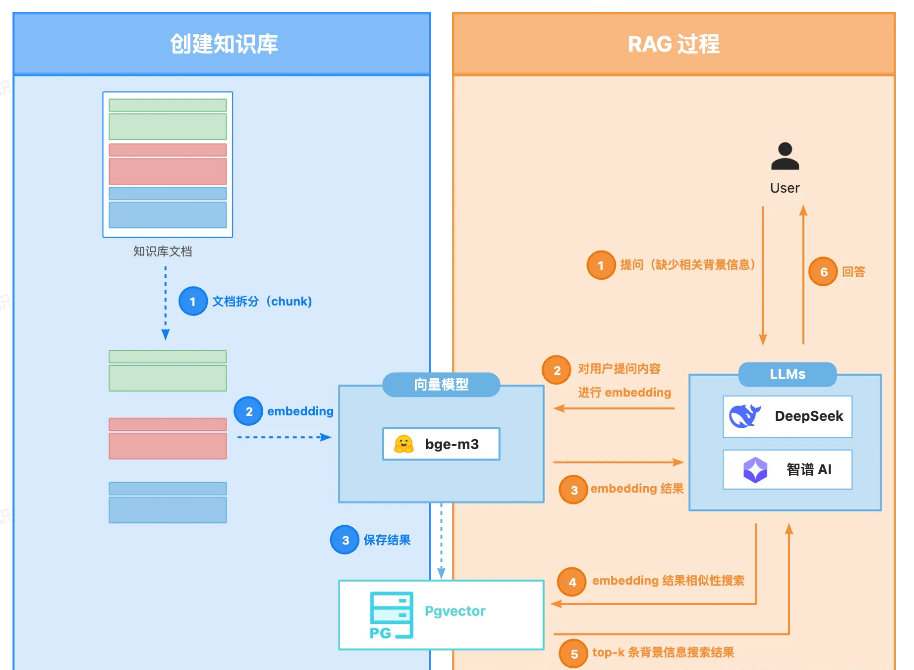
这张图真的可以说封神 画的很有逻辑 知识的美感

然后进行相关前置知识的学习补充 :
文档拆分 (Chunk):
技术解释:
-
Chunk(分块):将长文本切成语义连贯的小片段
-
为什么需要拆分?
-
大语言模型有上下文长度限制(比如只能“看”8000个词)
-
精确检索:查找时只返回最相关的那几段,而不是整本书
-
效率:小文本块处理更快
-
-
分块策略的学问
-
def smart_chunking(document, strategy="semantic"): """ 不同的分块策略影响检索质量 """ if strategy == "fixed_size": # 固定大小:简单但可能切断完整句子 return split_by_length(document, chunk_size=500) elif strategy == "sentence": # 按句子:保持语义完整 sentences = nltk.sent_tokenize(document) return group_sentences(sentences, max_length=500) elif strategy == "recursive": # 递归分块:先按段落,太大再按句子 return recursive_split(document) elif strategy == "semantic": # 语义分块:使用模型判断边界 return semantic_split(document) elif strategy == "overlap": # 重叠分块:相邻块有部分重叠,避免边界信息丢失 chunks = split_by_length(document, chunk_size=500) overlapping_chunks = [] for i in range(len(chunks)-1): # 每块尾部与下一块头部重叠50词 overlap = chunks[i][-50:] + chunks[i+1][:50] overlapping_chunks.append(overlap) return overlapping_chunks
-
Embedding(向量化)
就像:给每张索引卡片贴上一个独特的数字编码,编码相似的卡片内容也相似
技术解释:
-
Embedding(嵌入/向量化):将文本转换为固定长度的数值向量
-
向量维度:通常是768、1024或1536维
-
神奇之处:语义相似的文本,其向量在数学空间中也“距离近”
-
Embedding模型的选择
-
# 选择考虑因素: # 1. 语言:英文、中文或多语言 # 2. 维度:越高越准,但也越耗资源 # 3. 速度:本地模型快,但质量可能稍低 # 4. 成本:API调用 vs 本地部署
-
-
# 三种主要相似度计算方法 def calculate_similarity(vec1, vec2, method="cosine"): if method == "cosine": # 余弦相似度:最常用,关注向量方向 dot = np.dot(vec1, vec2) norm = np.linalg.norm(vec1) * np.linalg.norm(vec2) return dot / norm elif method == "euclidean": # 欧氏距离:关注绝对距离 return np.linalg.norm(vec1 - vec2) elif method == "dot_product": # 点积:简单快速 return np.dot(vec1, vec2) elif method == "manhattan": # 曼哈顿距离:各维度差值的绝对值和 return np.sum(np.abs(vec1 - vec2))# 没有索引:线性扫描(慢) # 有索引:近似最近邻搜索(快) # 常见向量索引算法: INDEX_ALGORITHMS = { "IVF_FLAT": "倒排文件 + 精确搜索", # 平衡 "HNSW": "层次可导航小世界", # 快,内存大 "PQ": "乘积量化", # 内存小 "SCANN": "谷歌的Scalable ANN", # 大规模 } # 在Milvus中的示例 from pymilvus import Collection, utility # 创建带索引的集合 collection.create_index( field_name="embedding", index_params={ "metric_type": "IP", # 内积 "index_type": "IVF_FLAT", "params": {"nlist": 128} } )
PG(向量数据库)
就像:一个特殊的卡片柜,能根据数字编码快速找到相似卡片
技术解释:
-
PG = PostgreSQL,关系型数据库
-
pgvector扩展:让PostgreSQL能存储和查询向量
-
替代方案:Pinecone、Chroma、Weaviate、Milvus等专用向量数据库
Top-K条背景信息搜索结果
技术解释:
-
Top-K:返回相似度最高的K个结果(通常K=3-10)
-
为什么是Top-K而不是Top-1?
-
一个片段可能信息不全
-
多个角度理解更全面
-
避免检索偏差
-


整个项目的终极问题:当用户在前端输入一句话之后,系统内部究竟发生了什么?
我再高呼一遍 知识之美 卡哥牛逼
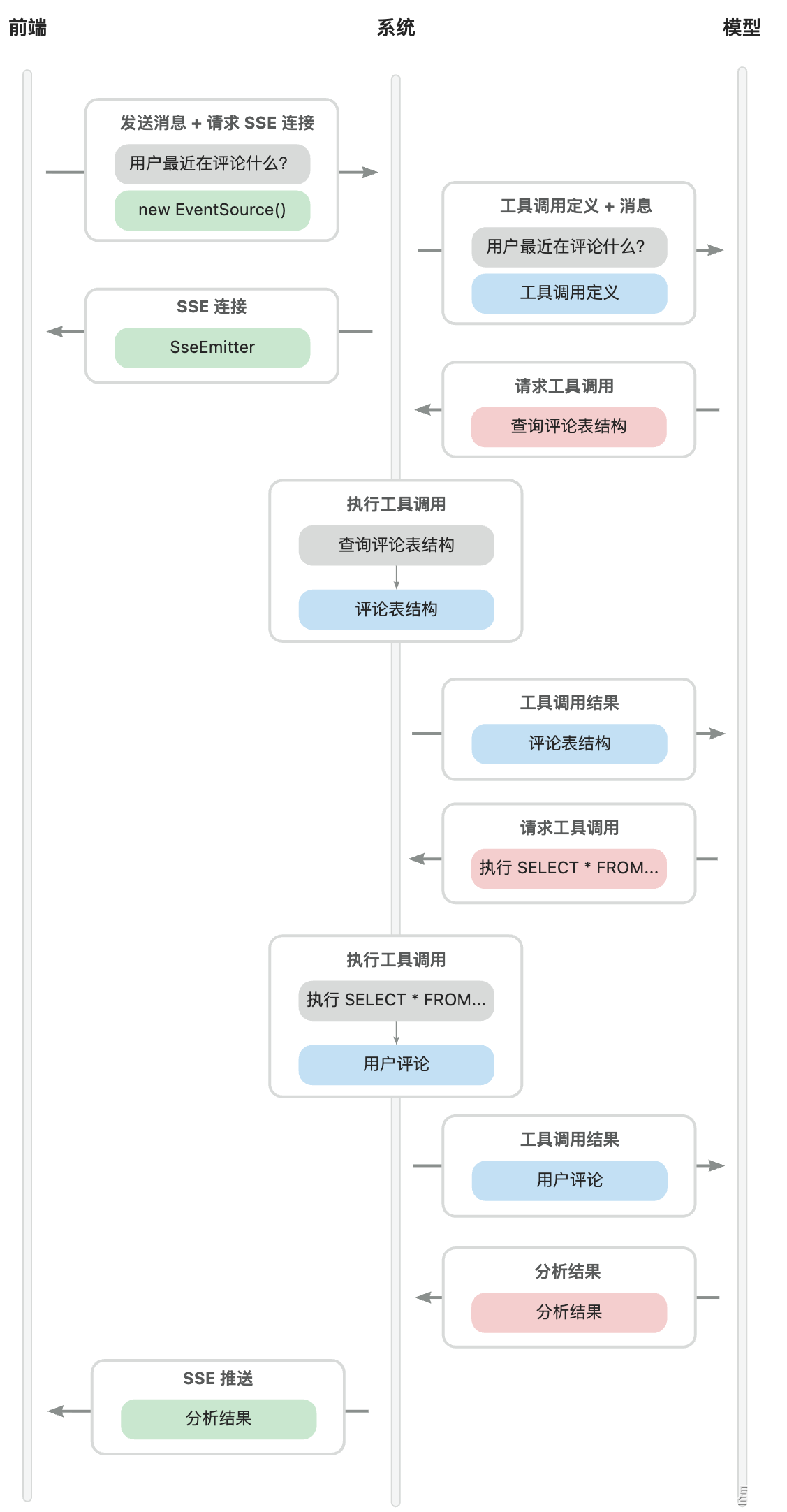
这个项目真的很好 后面还需要细细打磨 二次 三次 多次学习 今日就先囫囵吞枣了
向全世界推荐代码随想录 !

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)