UAE:让AI的“理解“与“创作“相互成就的统一多模态框架
UAE(Unified Auto-Encoder)框架首次证明:AI的"看图说话"能力和"文字作画"能力不仅可以共存,更能相互促进——理解越强,生成越好;生成越好,理解越强!看图说话(理解能力):看一张照片,告诉你"这是一只橘猫正在阳台上晒太阳"文字作画(生成能力):听你说"画一只橘猫在阳台上晒太阳",然后画出来这种同时具备"理解"和"生成"能力的AI,就叫做统一多模态模型(Unified Mul
UAE:让AI的"理解"与"创作"相互成就的统一多模态框架
论文标题:Unified Multimodal Model as Auto-Encoder
副标题:Can Understanding and Generation Truly Benefit Together — or Just Coexist?
论文链接:arXiv:2509.09666
代码仓库:GitHub - PKU-YuanGroup/UAE
作者团队:北京大学袁粒课题组、微软亚洲研究院等
发布时间:2025年9月
Hugging Face热度:34+ 点赞,GitHub 151+ Stars
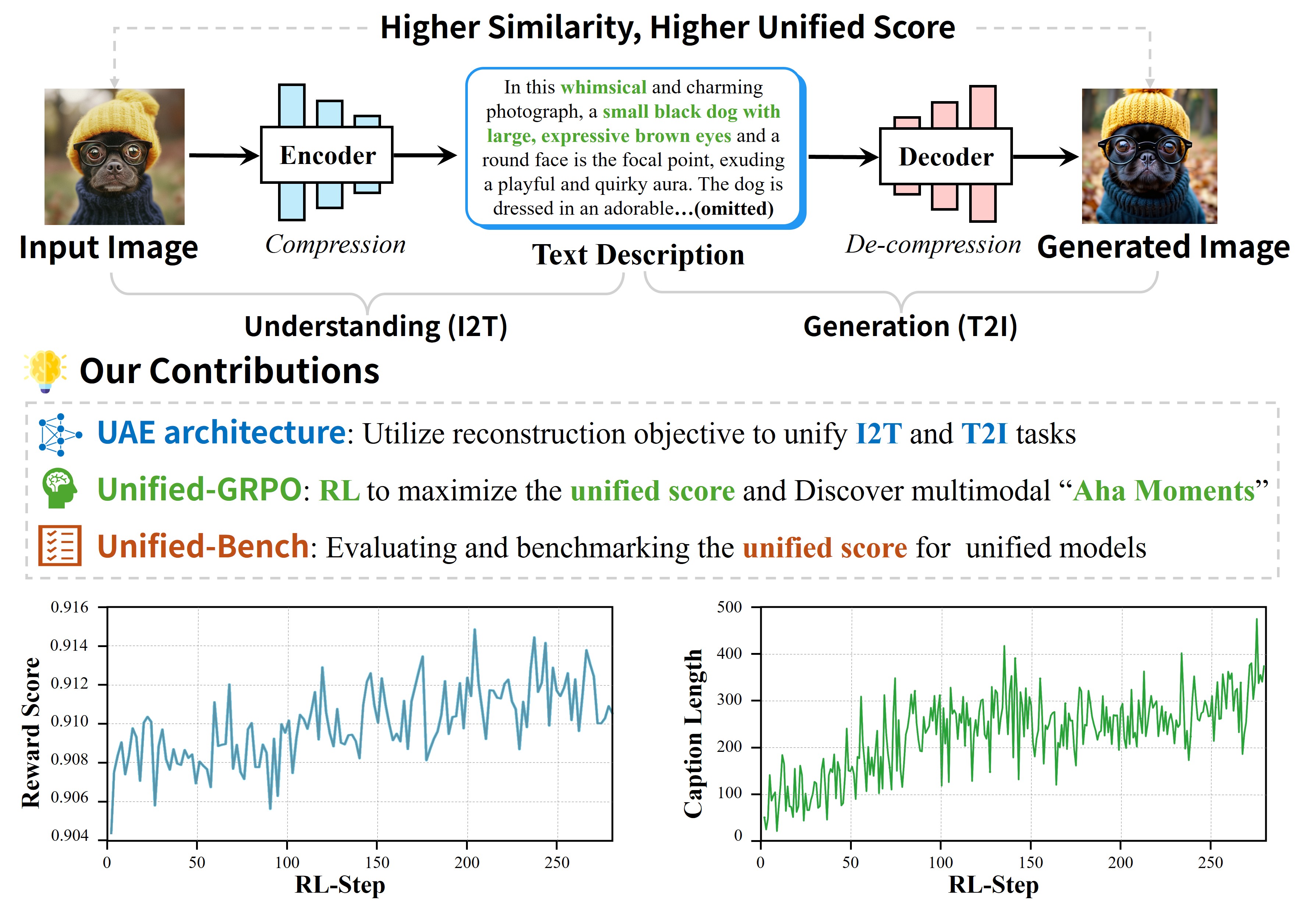
🎯 一句话总结
UAE(Unified Auto-Encoder)框架首次证明:AI的"看图说话"能力和"文字作画"能力不仅可以共存,更能相互促进——理解越强,生成越好;生成越好,理解越强!
📖 研究背景:多模态AI的"分裂症"
什么是多模态模型?
想象一下,你有一个AI助手,它既能:
- 看图说话(理解能力):看一张照片,告诉你"这是一只橘猫正在阳台上晒太阳"
- 文字作画(生成能力):听你说"画一只橘猫在阳台上晒太阳",然后画出来
这种同时具备"理解"和"生成"能力的AI,就叫做统一多模态模型(Unified Multimodal Model, UMM)。
当前的困境:各干各的
目前大多数多模态模型存在一个尴尬的问题——理解和生成是"分家"的:
- 理解模块 (I2T):图像 → 文字描述,目标是准确描述,但不关心生成质量
- 生成模块 (T2I):文字描述 → 图像,目标是美观生成,但不关心理解准确
- 两个模块各干各的,互不相干
问题在哪?
- 理解模块只管"说得准",不管生成模块能不能根据描述画出来
- 生成模块只管"画得美",不管理解模块能不能准确描述
- 两个模块没有形成闭环,无法相互促进
一个生动的比喻
这就像一个翻译团队:
- 翻译A(理解):把中文翻译成英文
- 翻译B(生成):把英文翻译回中文
如果A和B各干各的,不互相校对,翻译质量就很难保证。但如果让A翻译完,B再翻回来,然后对比原文——这就形成了一个闭环,可以不断改进!
UAE的核心思想就是:把理解和生成连成一个闭环,让它们相互促进!
🧠 核心创新:自编码器视角
什么是自编码器(Auto-Encoder)?
自编码器是深度学习中的经典概念:原始数据 X → [编码器] → 压缩表示 Z → [解码器] → 重建数据 X’
目标是让 X’ 尽可能接近 X。例如图片压缩(原图 → 压缩码 → 还原图)、语音编码(声音 → 数字信号 → 还原声音)。
关键洞察:如果重建得越好,说明编码器保留的信息越完整,解码器的还原能力越强!
UAE的天才类比
UAE的作者发现:多模态理解和生成,天然就是一对编码器-解码器!
- 原始图像 → [理解模块I2T/编码器] → 文字描述(~250词) → [生成模块T2I/解码器] → 重建图像
- 评估指标:重建图像与原始图像的相似度
- 相似度越高 → 理解越准确 + 生成越精确
这个视角的妙处:
- 统一的优化目标:不再是"理解准确"和"生成美观"两个独立目标,而是统一为"重建相似度"
- 自动形成闭环:理解的输出是生成的输入,生成的输出可以和原图对比
- 相互促进:要提高重建质量,必须同时提升理解和生成能力
🏗️ UAE框架详解
整体架构
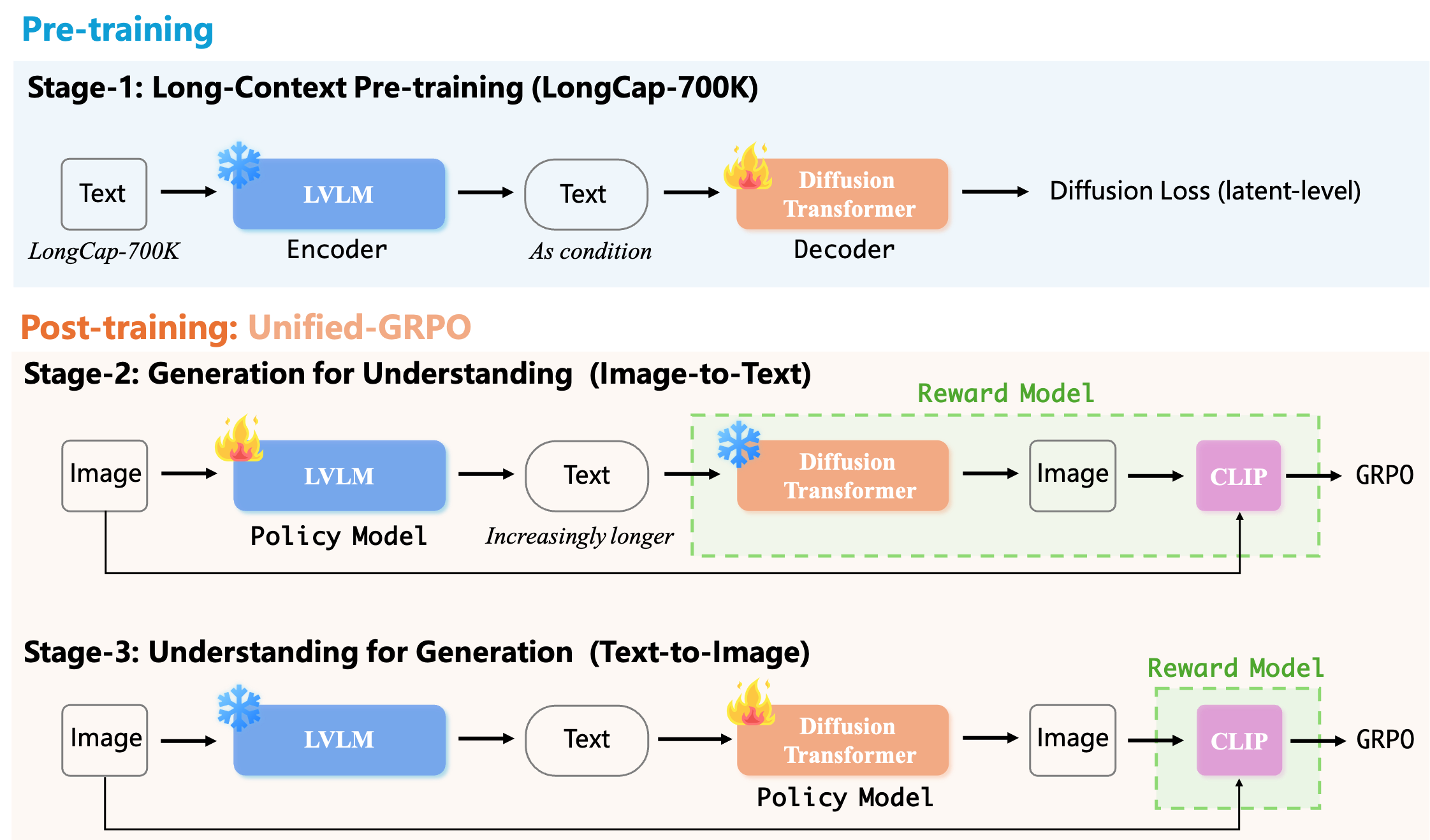
UAE框架分为两个主要阶段:
- 阶段1: 预训练 - 使用700K长描述数据集训练编码器(Qwen2.5-VL 3B)和解码器(SD3.5-large)
- 阶段2: Unified-GRPO强化学习 - 包含两个子阶段:
- Stage 2a: Generation for Understanding(生成促进理解)- 训练编码器生成更丰富的描述
- Stage 2b: Understanding for Generation(理解促进生成)- 训练解码器更好地理解描述
核心组件详解
1. 编码器:图像到文本(I2T)
模型选择:Qwen2.5-VL 3B(阿里巴巴的视觉语言模型)
关键创新:生成超长描述(平均250词),而不是传统的短标题
传统描述 vs UAE长描述对比:
- 传统短描述:“一只橘猫在阳台上”
- UAE长描述:“这是一只成年的橘色虎斑猫,正懒洋洋地躺在一个阳光充足的阳台上。猫咪的毛色是温暖的橙黄色,带有深色的条纹花纹。它的眼睛是琥珀色的,半闭着享受阳光。阳台的地面是灰色的水泥地,旁边有一盆绿色的多肉植物。背景可以看到蓝天和几朵白云。整体氛围温馨惬意,光线柔和,呈现出午后慵懒的感觉。猫咪的姿态放松,前爪微微蜷缩,尾巴自然垂放…”
为什么要长描述?
- ✓ 包含更多细节信息(颜色、纹理、姿态、环境等)
- ✓ 生成模块可以根据详细描述重建更准确的图像
- ✓ 信息损失更少,重建质量更高
2. 解码器:文本到图像(T2I)
模型选择:Stable Diffusion 3.5 Large(最先进的开源图像生成模型)
特点:
- 支持1024×1024高分辨率生成
- 能够理解复杂的长文本描述
- 生成质量接近商业模型
3. LongCap-700K数据集
为了训练编码器生成高质量的长描述,研究者构建了一个大规模数据集:
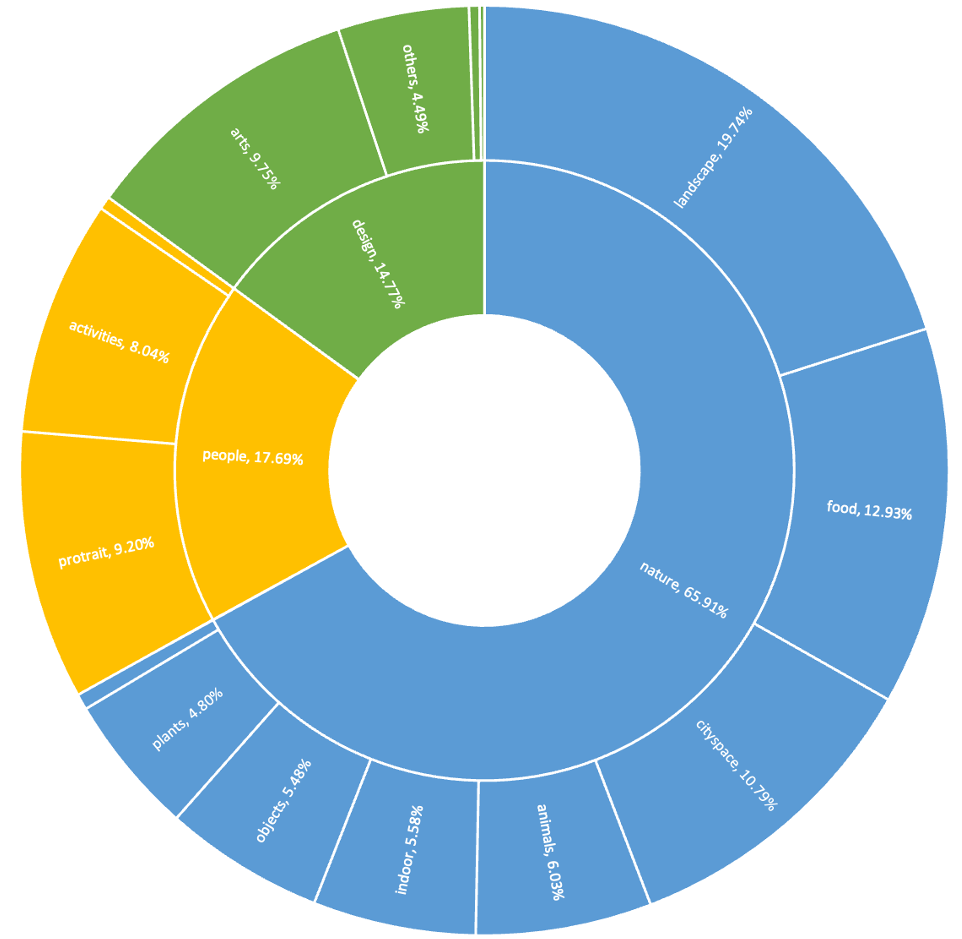
数据集详情:
- 数据规模: 700,000 张高质量图像-长描述对
- 图像来源: 高分辨率图像(1024×1024),多样化场景(自然、人物、艺术、建筑等)
- 描述生成: 使用 InternVL-78B 生成初始描述,使用 GPT-4o 进行质量蒸馏和优化
- 平均描述长度: ~250词
- 质量控制: 人工审核关键样本,自动过滤低质量描述
长描述数据集示例:

🔧 Unified-GRPO:核心训练算法
什么是GRPO?
**GRPO(Group Relative Policy Optimization)**是DeepSeek团队提出的强化学习算法,专门用于训练大语言模型。
核心思想:不需要额外的"评判模型",而是通过组内比较来优化策略。
GRPO工作原理:
- 步骤1: 对同一个输入,采样多个输出(如对一张猫的照片生成多个描述)
- 步骤2: 计算每个输出的奖励(重建相似度)
- 步骤3: 组内比较,计算相对优势(高于平均的正向强化,低于平均的负向反馈)
- 步骤4: 更新模型,让它更倾向于生成高奖励的输出
Unified-GRPO的创新
UAE将GRPO扩展为双向优化的Unified-GRPO:
Stage 2a: Generation for Understanding(生成促进理解)
目标:训练编码器(I2T)生成更好的描述
奖励信号:生成的描述能否让解码器重建出与原图相似的图像
数学表示:
奖励 R = Similarity(原始图像, 重建图像)
= CLIP_score + DINO_score + LongCLIP_score
直觉理解:
- 如果你的描述足够详细准确,画家(生成模块)就能画出和原图很像的画
- 描述越好 → 重建越像 → 奖励越高 → 模型学会生成更好的描述
Stage 2b: Understanding for Generation(理解促进生成)
目标:训练解码器(T2I)更好地理解描述并生成图像
奖励信号:根据描述生成的图像与原图的相似度
直觉理解:
- 即使描述很详细,如果画家理解能力不够,也画不好
- 训练画家更好地理解描述中的每个细节
奖励函数设计
总奖励 R = α₁ × CLIP + α₂ × LongCLIP + α₃ × DINO-v2
各指标含义:
- CLIP: 语义级别相似度(“这是一只猫”)
- LongCLIP: 长文本语义相似度(处理250词的长描述)
- DINO-v2: 视觉特征相似度(颜色、纹理、形状等)
为什么用多个指标?
- CLIP: 确保语义正确(不会把猫描述成狗)
- LongCLIP: 确保长描述的语义完整性
- DINO: 确保视觉细节准确(颜色、纹理等)
- 综合起来 = 既要语义对,又要细节准
🧪 实验设置
评估基准:Unified-Bench
UAE提出了首个专门评估"统一程度"的基准测试:
测试流程:
- 给模型一张原始图像
- 模型生成文字描述(编码)
- 模型根据描述生成图像(解码)
- 计算重建图像与原图的相似度
评估指标:
- CLIP Score: 语义相似度
- LongCLIP Score: 长文本语义相似度
- DINO-v2 Score: 自监督视觉特征相似度
- DINO-v3 Score: 增强版视觉特征相似度
- Overall: 综合得分
测试数据: 100张精选高质量图像
对比方法
| 方法 | 类型 | 描述 |
|---|---|---|
| GPT-4o-Image | 商业模型 | OpenAI最新的多模态模型 |
| BAGEL | 开源模型 | 字节跳动的统一多模态模型 |
| Janus-Pro | 开源模型 | DeepSeek的统一多模态模型 |
| UAE (本文) | 开源模型 | 北大提出的自编码器框架 |
训练配置
硬件配置:
- 8个节点 × 8张 NVIDIA H800 GPU = 64张GPU
- 总训练时间: 约1周
预训练阶段:
- 数据: LongCap-700K
- 分辨率: 512×512 (10K步) → 1024×1024 (5K步)
- 批大小: 256
强化学习阶段:
- 数据: 1K精选高质量图像
- 方法: LoRA微调(参数高效)
- KL正则化: β = 0.01
- 学习率: 1e-6
模型规模:
- 编码器: Qwen2.5-VL 3B
- 解码器: SD3.5-large
📊 实验结果
主要结果:Unified-Bench评估
表1: Unified-Bench 统一性评估结果
| 方法 | CLIP | LongCLIP | DINO-v2 | DINO-v3 | Overall |
|---|---|---|---|---|---|
| GPT-4o-Image | 90.42 | 94.37 | 81.74 | 77.27 | 85.95 |
| BAGEL | 88.97 | 93.35 | 78.55 | 73.05 | 83.48 |
| Janus-Pro | 87.23 | 92.18 | 76.42 | 71.89 | 81.93 |
| UAE (本文) | 90.50 | 94.35 | 81.98 | 77.54 | 86.09 |
关键发现:
- ✓ UAE在Overall得分上超越GPT-4o-Image(86.09 vs 85.95)
- ✓ 在视觉特征相似度(DINO)上优势明显
- ✓ 作为开源模型,首次达到商业模型水平
生成能力评估:GenEval
GenEval是评估文本到图像生成能力的标准基准:
表2: GenEval 生成能力对比
| 方法 | Single Object | Two Object | Counting | Colors | Position | Overall |
|---|---|---|---|---|---|---|
| DALL-E 3 | 0.96 | 0.87 | 0.47 | 0.83 | 0.43 | 0.67 |
| SD3 | 0.98 | 0.83 | 0.59 | 0.80 | 0.55 | 0.74 |
| Janus-Pro | 0.99 | 0.89 | 0.59 | 0.90 | 0.56 | 0.79 |
| UAE | 1.00 | 0.89 | 0.84 | 0.90 | 0.71 | 0.86 |
| UAE† | 1.00 | 0.97 | 0.82 | 0.95 | 0.73 | 0.89 |
指标说明:
- Single Object: 生成单个物体的准确性
- Two Object: 生成两个物体的准确性
- Counting: 数量准确性(如"3个苹果")
- Colors: 颜色属性准确性
- Position: 位置关系准确性
关键发现:
- ✓ UAE在Counting任务上大幅领先(0.84 vs 0.59)
- ✓ Overall得分达到0.86,超越所有基线
- ✓ UAE†版本进一步提升至0.89
UAE生成效果可视化:

复杂组合任务:GenEval++
GenEval++测试更复杂的组合生成能力:

表3: GenEval++ 复杂组合任务评估
| 方法 | Color | Count | Color/Count | Pos/Count | Overall |
|---|---|---|---|---|---|
| DALL-E 3 | 0.375 | 0.300 | 0.275 | 0.200 | 0.275 |
| SD3 | 0.425 | 0.350 | 0.325 | 0.225 | 0.325 |
| Janus-Pro | 0.500 | 0.425 | 0.400 | 0.300 | 0.400 |
| UAE | 0.550 (+10%) | 0.525 (+24%) | 0.550 (+38%) | 0.450 (+50%) | 0.475 (+19%) |
任务示例:
- Color/Count: “生成3个红色苹果和2个绿色苹果”
- Pos/Count: “左边2只猫,右边3只狗”
关键发现:
- ✓ UAE在所有复杂组合任务上都取得最佳成绩
- ✓ 在Pos/Count任务上提升50%
- ✓ 证明了理解能力对生成的促进作用
理解能力评估:MMT-Bench
表4: MMT-Bench 理解能力提升
| 任务类型 | 基线模型 | UAE | 提升幅度 |
|---|---|---|---|
| 小物体检测 | 0.05 | 0.45 | +800% |
| 行人重识别 | 0.20 | 0.80 | +300% |
| 颜色识别 | 0.65 | 0.85 | +31% |
| 纹理识别 | 0.55 | 0.75 | +36% |
| 空间关系理解 | 0.50 | 0.70 | +40% |
关键发现:
- ✓ 细粒度视觉感知能力大幅提升
- ✓ 小物体检测从5%提升到45%
- ✓ 证明了生成能力对理解的促进作用
描述质量评估
研究者使用多个商业LLM评估UAE生成的描述质量:
表5: 描述质量LLM评估
| 评估模型 | UAE胜率 | 平局率 | 基线胜率 |
|---|---|---|---|
| Claude-4.1 | 68% | 12% | 20% |
| GPT-4o | 65% | 15% | 20% |
| Gemini-2.0 | 62% | 18% | 20% |
| 平均 | 65% | 15% | 20% |
评估标准:
- 描述的完整性
- 描述的准确性
- 描述对重建的有用性
关键发现:
- ✓ UAE的描述在65%的情况下被认为更好
- ✓ 描述更有利于图像重建
🔬 消融实验与深入分析
多模态"顿悟时刻"
研究者发现了一个有趣的现象——多模态顿悟时刻(Multimodal Aha Moment):

训练过程中的变化:
- 描述变短了(250词 → ~100词)
- 但重建质量反而提高了(0.76 → 0.92)
- 模型学会了"说重点",而不是"说废话"
这意味着什么?
模型通过强化学习,自动发现了:
- 不是描述越长越好,而是要包含关键信息
- 学会了筛选重要特征,忽略无关细节
- 描述变得更"高效"——用更少的词传达更多有用信息
各组件贡献分析
消融实验:各组件贡献
| 配置 | Overall Score | 相对基线 |
|---|---|---|
| 基线 (无RL) | 82.35 | - |
| + Stage 2a (生成促进理解) | 84.21 | +1.86 |
| + Stage 2b (理解促进生成) | 85.47 | +3.12 |
| + 两阶段联合 (完整UAE) | 86.09 | +3.74 |
结论:
- ✓ 两个阶段都有贡献
- ✓ 联合训练效果 > 单独训练之和(有协同效应)
💡 实际应用场景
场景1:图像编辑与重建
应用场景:智能图像编辑
传统方法:
- 用户: “把这张照片里的猫换成狗”
- AI: 直接修改图像(可能破坏整体协调性)
UAE方法:
- 编码: 图像 → 详细文字描述
- 编辑: 在描述中把"猫"改成"狗"
- 解码: 修改后的描述 → 新图像
优势:
- ✓ 保持整体风格和环境一致
- ✓ 可以进行更复杂的语义编辑
- ✓ 编辑过程可解释、可控制
场景2:图像压缩与传输
应用场景:语义图像压缩
传统压缩: JPEG/PNG → 压缩像素数据,高压缩比 = 图像质量损失
UAE语义压缩:
- 图像 → 文字描述(几百字节)→ 重建图像
- 极高压缩比(1000:1以上)
- 保留语义信息,细节可重建
适用场景:
- 低带宽环境的图像传输
- 图像数据库的语义存储
- 跨模态检索和索引
场景3:多模态内容创作
应用场景:AI辅助创作
工作流程:
- 用户上传参考图像
- UAE生成详细描述
- 用户修改描述(调整风格、元素等)
- UAE根据修改后的描述生成新图像
- 迭代优化直到满意
优势:
- ✓ 保留参考图像的核心特征
- ✓ 通过文字精确控制修改
- ✓ 创作过程透明可控
重建效果展示
以下是UAE在图像重建任务上的实际效果:


⚠️ 局限性与未来方向
当前局限性
-
文本渲染能力不足
- 生成模型在渲染文字(如招牌、文档)时表现不佳
- 影响了编码器在OCR相关任务上的性能
-
计算资源需求高
- 需要同时运行理解和生成两个大模型
- 训练需要64张H800 GPU
-
长描述的冗余
- 虽然发现了"顿悟时刻",但最优描述长度仍需探索
- 不同类型图像可能需要不同长度的描述
-
评估指标的局限
- 当前指标主要关注视觉相似度
- 可能忽略一些语义层面的细微差异
未来研究方向
| 方向 | 描述 |
|---|---|
| 文本渲染增强 | 改进生成模型对文字的精确重建能力 |
| 效率优化 | 探索更轻量级的架构,降低计算成本 |
| 多语言支持 | 扩展到中文等其他语言的描述生成 |
| 视频扩展 | 将框架扩展到视频理解和生成 |
| 交互式优化 | 支持用户反馈的在线学习 |
🔗 与相关工作的对比
UAE vs Janus-Pro (DeepSeek)
| 维度 | Janus-Pro | UAE |
|---|---|---|
| 架构 | 双编码器解耦 | 自编码器闭环 |
| 训练方式 | 三阶段监督学习 | 预训练+强化学习 |
| 统一程度 | 共享LLM骨干 | 端到端优化 |
| 相互促进 | 有限 | 显式设计 |
UAE vs BAGEL (字节跳动)
| 维度 | BAGEL | UAE |
|---|---|---|
| 核心思想 | 多任务学习 | 自编码器重建 |
| 优化目标 | 多个独立目标 | 统一重建目标 |
| 闭环设计 | 无 | 有 |
UAE vs GPT-4o (OpenAI)
| 维度 | GPT-4o | UAE |
|---|---|---|
| 开源性 | 闭源商业 | 开源 |
| 统一性得分 | 85.95 | 86.09 |
| 可复现性 | 不可 | 完全可复现 |
📝 总结
UAE框架代表了多模态AI研究的一个重要突破:首次证明理解和生成可以真正相互促进,而不仅仅是共存。
核心贡献
- ✅ 自编码器视角:将多模态理解和生成统一为编码-解码过程
- ✅ Unified-GRPO:首个双向优化的强化学习方案
- ✅ Unified-Bench:首个评估统一程度的基准测试
- ✅ 多模态顿悟时刻:发现了训练过程中的有趣现象
实验成果
| 指标 | 成就 |
|---|---|
| Unified-Bench | 86.09(超越GPT-4o) |
| GenEval | 0.86(SOTA) |
| GenEval++ | 0.475(+19%) |
| 细粒度感知 | +300%~800% |
核心价值
UAE的核心价值在于:打破了理解和生成的壁垒,让AI真正实现"看得懂就能画,画得好就能看"的良性循环。
正如论文标题所问:“理解和生成能否真正相互促进——还是仅仅共存?”
UAE给出了肯定的答案:它们不仅能共存,更能相互成就!
🤔 思考题
读完这篇论文解读,你可以思考以下问题:
-
自编码器视角的局限:是否所有多模态任务都适合用自编码器框架?什么情况下不适用?
-
描述长度的权衡:如何自动确定最优的描述长度?是否可以根据图像复杂度动态调整?
-
跨模态泛化:UAE的思想能否扩展到其他模态(如音频、视频)?
-
人类认知的启示:人类的理解和创作能力是否也存在类似的相互促进关系?
欢迎在评论区分享你的想法!
📚 参考资料
- 论文原文:arXiv:2509.09666
- 论文PDF:下载链接
- GitHub代码:PKU-YuanGroup/UAE
- Hugging Face模型:zhiyuanyan1/UAE
- Hugging Face论文页:huggingface.co/papers/2509.09666
相关论文推荐
| 论文 | 主题 | 链接 |
|---|---|---|
| Janus-Pro | DeepSeek统一多模态模型 | arXiv |
| BAGEL | 字节跳动统一多模态模型 | 字节跳动研究 |
| Qwen2.5-VL | 阿里视觉语言模型 | GitHub |
| SD3.5 | Stable Diffusion 3.5 | Stability AI |
如果觉得有帮助,欢迎点赞、转发、在看三连! 👍

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 8
8 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)