腾讯优图重磅发布:20亿参数小模型如何击败80亿大模型?
腾讯优图发布Youtu-LLM轻量级大语言模型,仅20亿参数却超越80亿参数模型的性能表现。该研究通过创新架构设计释放了轻量级模型的潜力,在保持高效推理的同时实现了更强的任务处理能力。论文已在arXiv发布,相关代码和模型权重已在GitHub和Hugging Face开源。这一突破为边缘计算场景下的高效AI部署提供了新思路。
腾讯优图重磅发布:20亿参数小模型如何击败80亿大模型?Youtu-LLM深度解读
❝论文标题:Youtu-LLM: Unlocking the Native Agentic Potential for Lightweight Large Language Models
论文链接:https://arxiv.org/abs/2512.24618
开源代码:https://github.com/TencentCloudADP/youtu-tip/youtu-llm
模型下载:https://huggingface.co/collections/tencent/youtu
引言:小模型的逆袭时代来临
在大语言模型(LLM)领域,一个长期存在的"共识"是:模型越大,能力越强。从GPT-3的1750亿参数,到GPT-4的万亿级参数,再到各种开源模型的"参数军备竞赛",似乎只有不断堆叠参数才能获得更强的智能。
但腾讯优图实验室最新发布的Youtu-LLM彻底打破了这一认知。这个仅有19.6亿参数的"小"模型,在多项智能体(Agent)任务上不仅超越了同等规模的竞品,甚至击败了参数量是其4倍的大模型!
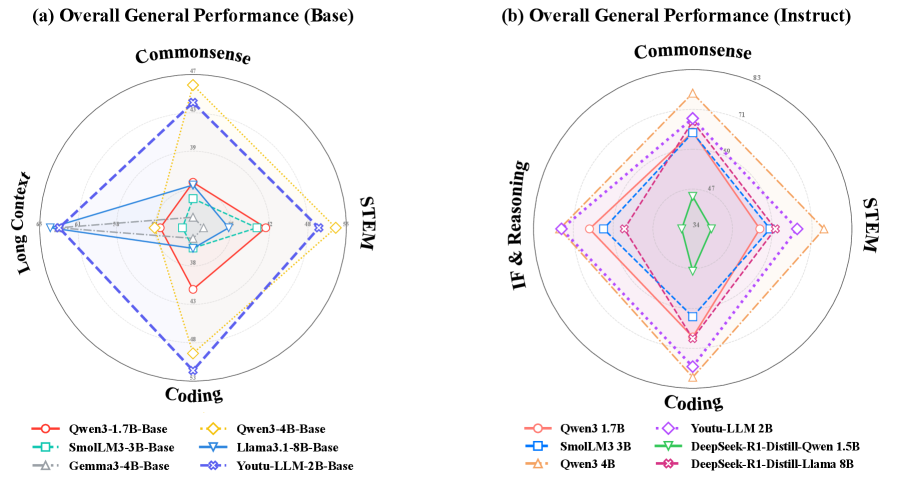
图1:参数-性能缩放图。横轴为模型参数量,纵轴为智能体任务平均得分。Youtu-LLM以最小的参数量实现了最优的智能体性能,趋势线清晰展示了其"以小博大"的惊人效率。
从上图可以清晰看到:Youtu-LLM 2B(红色星标)位于所有模型的最左上角,这意味着它用最少的参数实现了最高的智能体任务性能。相比之下,即使是8B参数的Llama3.1,在智能体任务上的表现也不如这个2B的小模型。
这究竟是怎么做到的?让我们深入解读这篇重磅论文。
一、核心问题:为什么轻量级模型需要"原生"智能体能力?
1.1 什么是智能体能力?
在AI领域,智能体(Agent)指的是能够自主感知环境、制定计划、执行行动并根据反馈调整策略的智能系统。与传统的"问答式"AI不同,智能体需要具备以下核心能力:
-
规划能力(Planning):将复杂任务分解为可执行的子步骤 -
工具使用(Tool Use):调用外部API、搜索引擎、代码执行器等工具 -
反思能力(Reflection):评估行动结果,发现并纠正错误 -
长程推理(Long-horizon Reasoning):在多轮交互中保持目标一致性
1.2 现有方法的局限
目前主流的智能体构建方法主要有两种:
方法一:后增强(Post-Enhancement)
-
在已训练好的基础模型上,通过提示工程(Prompt Engineering)或微调(Fine-tuning)添加智能体能力 -
问题:智能体能力是"外挂"的,与模型的核心能力脱节
方法二:蒸馏(Distillation)
-
从大模型(如GPT-4、Claude)中蒸馏智能体行为到小模型 -
问题:小模型只是"模仿"大模型的行为,缺乏真正的理解
Youtu-LLM团队提出了一个关键洞察:智能体能力应该在预训练阶段就"原生"培养,而不是事后添加。这就像是让一个孩子从小就学习解决问题的方法论,而不是长大后才临时抱佛脚。
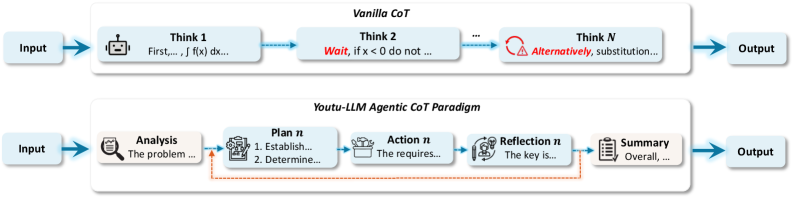
图2:类似规模模型的多领域通用能力对比雷达图。Youtu-LLM(红色区域)在各个维度上展现出均衡且具竞争力的性能,尤其在编程和数学推理方面表现突出。
二、技术创新:从分词器到训练策略的全方位优化
2.1 智能分词器:为推理而生
分词器(Tokenizer)是LLM的"眼睛",决定了模型如何"看"文本。Youtu-LLM设计了一个专门为STEM(科学、技术、工程、数学)任务优化的分词器:
三阶段训练策略:
| 阶段 | 目标 | 词汇量 |
|---|---|---|
| 第一阶段 | 从o200k词汇表提取纯ASCII基础词汇,移除受污染的中文token | 101k |
| 第二阶段 | 使用多领域中文语料扩展,抑制法律、专利等领域术语干扰 | 121k |
| 第三阶段 | 针对数学/代码场景增加专用token | 128,256 |
关键优化:
-
中文、日文、韩文等CJK字符独立分割,避免跨语义单元合并 -
数学符号保留原子单位(0-9单独编码) -
相比Qwen3和Llama3分词器,通用数据压缩率提升5%,推理数据提升10%
2.2 密集MLA架构:效率与性能的平衡
Youtu-LLM采用了多潜在注意力(Multi-Latent Attention, MLA)架构,这是一种比传统GQA(分组查询注意力)更高效的设计:
| 配置项 | 数值 |
|---|---|
| 总参数量 | 1.96B |
| 层数 | 32 |
| 隐藏维度 | 2048 |
| KV LoRA秩 | 512 |
| Q LoRA秩 | 1536 |
| 最大上下文长度 | 131,072 tokens (128K) |
MLA的核心思想是通过低秩压缩减少KV缓存的内存占用,同时使用更大的投影矩阵保持表达能力。这使得Youtu-LLM能够在有限的参数预算下支持128K的超长上下文——这对智能体任务至关重要,因为智能体需要处理大量的历史交互信息。
2.3 四阶段预训练:渐进式能力培养
Youtu-LLM的预训练遵循"常识→STEM→智能体"的课程设计,分四个阶段渐进进行:

图11:Youtu-LLM的完整预训练方案。上半部分展示四个阶段的数据配比变化,下半部分展示学习率调度策略。
阶段一:常识预训练(8.16T tokens)
-
数据组成:75%网页和百科数据 -
序列长度:8K -
目标:建立基础语言理解能力
阶段二:STEM/代码预训练
-
STEM和代码数据占比提升至60% -
保持峰值学习率(4e-4) -
目标:强化数学和编程基础
阶段三:通用中期训练
-
上下文长度扩展:8K → 32K → 128K -
学习率衰减至4e-5 -
目标:培养长上下文处理能力
阶段四:智能体中期训练(200B tokens)
-
智能体轨迹数据占比60% -
学习率衰减至1e-7 -
目标:注入原生智能体能力
这种渐进式训练策略的关键在于:先打好基础,再培养高级能力。就像学习数学,必须先掌握加减乘除,才能学习微积分。
三、核心创新:Agentic-CoT——结构化的智能体思维范式
3.1 传统CoT的问题
链式思维(Chain-of-Thought, CoT)是提升LLM推理能力的经典方法,但传统的"长链思维"存在明显问题:
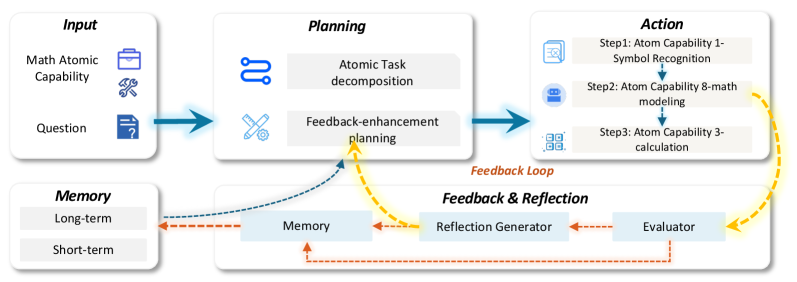
图3:传统长链思维(上)vs Agentic-CoT(下)的对比。传统方法容易出现过度思考和重复表达,而Agentic-CoT通过结构化的五阶段引导,使推理过程更加清晰高效。
传统CoT的问题:
-
过度思考(Over-thinking):模型在简单问题上也会产生冗长的推理链 -
重复表达(Repetitive Expression):同一个观点反复阐述 -
缺乏结构(Lack of Structure):推理过程杂乱无章
3.2 Agentic-CoT的五阶段范式
Youtu-LLM提出的Agentic-CoT将推理过程结构化为五个明确的阶段:
<analysis>
分析问题的本质和约束条件
</analysis>
<plan>
制定解决问题的步骤计划
</plan>
<action>
执行具体的操作或计算
</action>
<reflection>
评估行动结果,检查是否有错误
</reflection>
<summary>
总结关键发现,给出最终答案
</summary>
这种结构化的思维范式有几个显著优势:
-
可解释性强:每个阶段的目的明确,便于理解和调试 -
避免冗余:明确的阶段划分减少了重复思考 -
培养智能体能力:规划、行动、反思正是智能体的核心能力
3.3 Agentic-CoT数据的构建
为了让模型学会这种结构化思维,研究团队构建了25B tokens的Agentic-CoT训练数据:
构建流程:
-
LLM推理:使用强大的教师模型生成初始推理链 -
人工校验:专家审核推理的正确性和逻辑性 -
片段提取:将冗长的推理链分解为五个阶段 -
合成组装:使用XML标签封装,形成结构化训练样本
四、智能体轨迹数据:四大领域的系统化构建
Youtu-LLM的一大创新是构建了200B tokens的高质量智能体轨迹数据,覆盖数学、代码、深度研究和工具使用四大领域。
4.1 数学轨迹:111项原子能力的精细分解
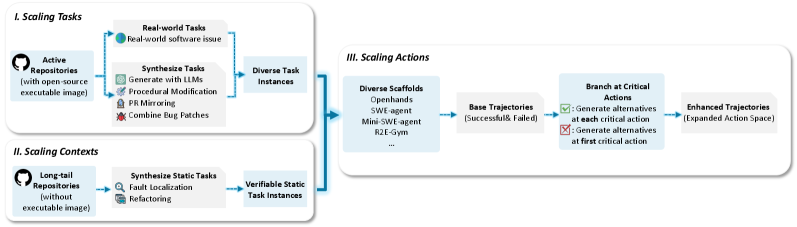
图4:用于数学轨迹构建的智能体框架。基于111项原子能力设计,每个能力都映射到具体的智能体模块。
研究团队将数学推理分解为111项原子能力,包括:
-
符号识别(Symbol Recognition) -
定理应用(Theorem Application) -
公式变换(Formula Transformation) -
数值计算(Numerical Computation) -
逻辑推导(Logical Deduction) -
...
每项原子能力都对应一个智能体模块,通过"规划-行动-反馈"循环生成可验证的数学轨迹。最终构建了138万条高质量数学轨迹,共20B tokens。
4.2 代码轨迹:端到端的软件工程能力
代码智能体需要具备完整的软件工程能力,从理解需求到编写代码再到调试测试。Youtu-LLM构建了70B tokens的代码轨迹数据。
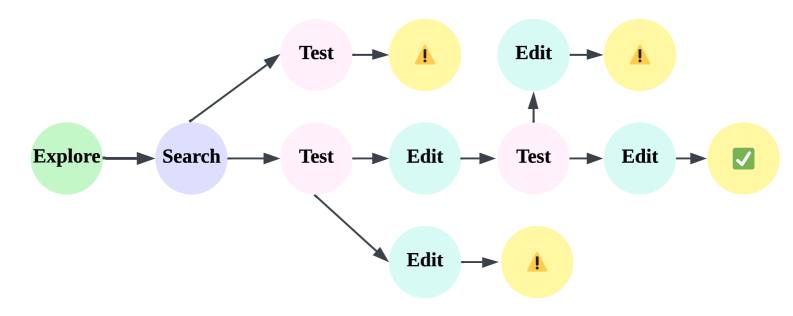
图5:代码轨迹的综合构建流程。从任务扩展到上下文生成再到动作分支,形成完整的端到端数据合成管道。
三维扩展策略:
-
任务扩展:
-
多环境支持(SWE-gym、SWE-smith) -
新任务自动合成
-
-
上下文扩展:
-
静态任务替代动态测试 -
覆盖长尾代码库
-
-
动作扩展:
-
关键动作(编辑、测试)的分支策略
-
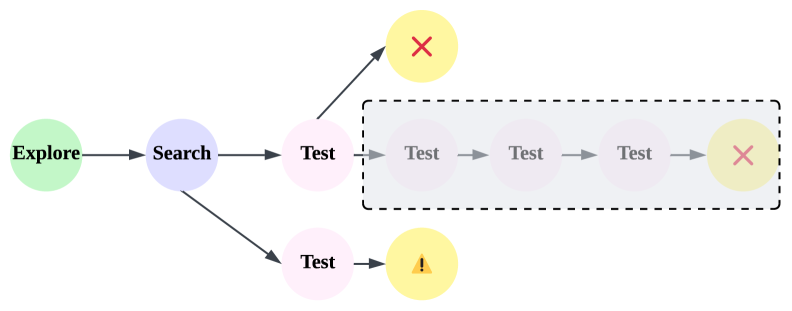
图6:代码智能体轨迹的分支策略。左侧展示成功轨迹的多分支扩展,右侧展示失败轨迹的单步分支策略,有效复用数据的同时避免错误传播。
分支策略的精妙之处:
-
成功轨迹:在关键决策点进行多分支扩展,生成多样化的解决方案 -
失败轨迹:仅保留单步分支,避免错误在后续步骤中传播
4.3 深度研究轨迹:从问答到报告生成
深度研究(Deep Research)是智能体的高级应用场景,需要模型能够自主搜索信息、整合知识并生成结构化报告。

图7:封闭式深度研究的轨迹合成流程。从QA生成到轨迹多样化,包含扰动搜索结果和失败轨迹分析。
两类深度研究任务:
封闭式任务(Closed-ended):
-
有明确答案的多跳问答 -
扰动搜索结果增加难度 -
分析失败轨迹学习避错
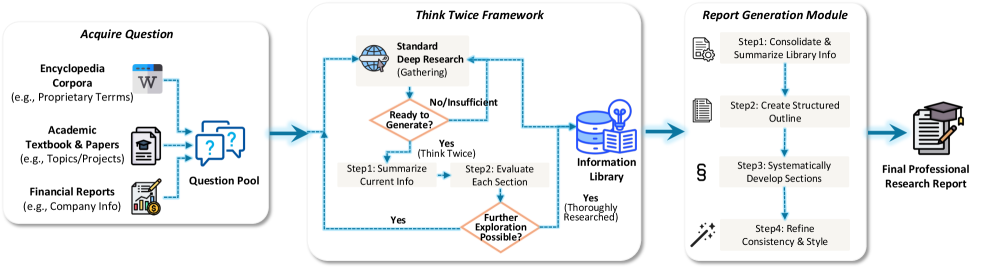
图8:开放式深度研究报告生成的轨迹合成流程。采用"思考两次"机制,包括信息汇总、分块验证和报告生成三个阶段。
开放式任务(Open-ended):
-
需要生成完整研究报告 -
"思考两次"(Think Twice)机制: -
第一次思考:信息汇总 -
第二次思考:分块验证 -
最终输出:结构化报告
-
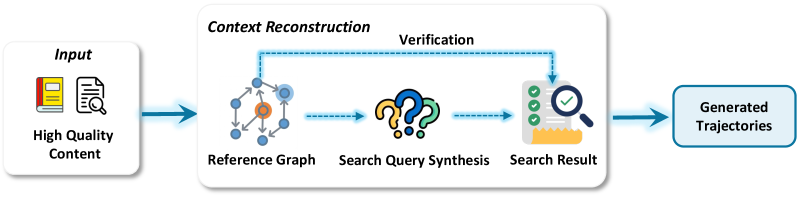
图9:开放式深度研究的逆向轨迹合成流程。基于学术论文和法律判决的引用关系,重建研究轨迹。
逆向合成的创新思路:
-
从已有的高质量报告(学术论文、法律判决)出发 -
根据引用关系反向重建研究过程 -
生成"如何得出这个结论"的轨迹数据
4.4 工具使用轨迹:构建工具图谱
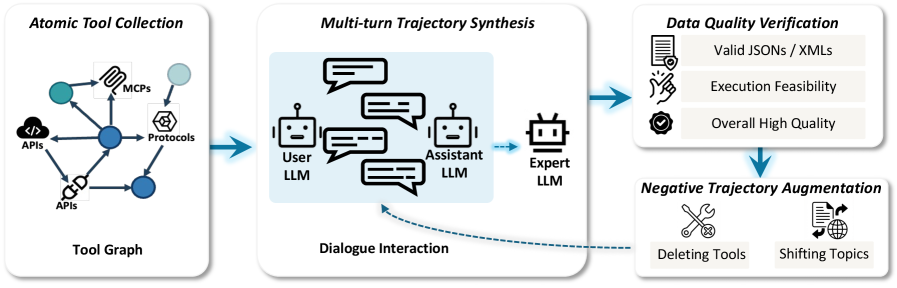
图10:工具使用和规划数据的轨迹构建策略。包括原子工具收集、多轮轨迹合成、质量验证和负样本增强四个步骤。
工具使用是智能体的核心能力之一。研究团队构建了一个包含数千种工具的工具图谱:
构建流程:
-
原子工具收集:API、MCP协议、各类接口 -
工具图构建:保留工具间的依赖关系 -
轨迹合成:工具图随机游走 → 对抗生成 → 质量验证 -
负样本增强:学习"什么时候不该用工具"
五、后训练:从SFT到RL的精细打磨
5.1 两阶段监督微调(SFT)
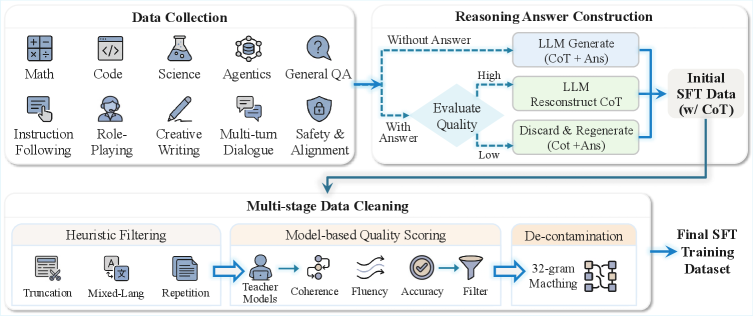
图12:高质量监督微调的数据工程工作流程。涵盖数据收集、推理答案构建和多阶段数据清洗。
Stage I:推理SFT
| 数据类型 | 占比 |
|---|---|
| 数学推理 | 40% |
| 代码生成 | 30% |
| 科学推理 | 20% |
| 智能体任务 | 10% |
目标:强化逻辑推理能力
Stage II:通用SFT
-
全量数据混合训练 -
保留Stage I数据防止遗忘 -
引入"思考/非思考"双模式控制
5.2 强化学习(RL)优化
任务设计:
-
数学任务:结构化答案验证 -
代码任务:执行环境验证 -
复杂指令:规则 + LLM评分 -
安全任务:对抗性红队测试

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 25
25 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)