给CANoe测试人员的礼物:基于RAG技术(pandawiki框架)的Vector专属知识库,拒绝AI瞎编
本文介绍了一款专为车载测试人员开发的AI工具,旨在解决Vector系列工具(如CANoe)使用中的专业问题。作者通过RAG技术架构构建了一个垂直知识库,爬取并索引了Vector官方文档,确保回答基于真实资料且可溯源。该工具具备三大优势:提供准确可靠的解决方案、本地存储实现快速查询、支持原文跳转验证。目前该网站免费开放,作者邀请同行试用并提出改进建议,希望能帮助行业同仁提升工作效率。
01. 前言:为什么要做这个工具?
作为一名在车载行业摸爬滚打多年的测试人员,大家对 Vector 系列工具(CANoe, CANalyzer, vTESTstudio 等)肯定爱恨交加。 它们强大、专业,是行业标准;但同时,它们的使用门槛极高,报错隐晦。
自从 ChatGPT 等大模型火了之后,各行各业都在用 AI 提效。隔壁做 Java 的,做 Python 的,甚至写文档的,都有了各种 Copilot。 但我们车载测试呢?
当你试图问通用大模型一个专业的 CAPL 脚本问题,或者一个具体的 CANoe 硬件配置报错时,得到的回答往往是:
- 泛泛而谈: 给你讲一堆通信原理,就是不解决具体报错。
- 代码幻觉: 写出来的 CAPL 代码混杂了 C++ 和 Python 的语法,放进 Compiler 里全是红线。
- 无据可查: 你问它这解决方案哪来的,它编不出来。
痛点很明确: 通用大模型没有吃透 Vector 那些封闭在官网 Knowledge Base (KB) 里的专业文档。
于是,我萌生了一个想法: 既然通用 AI 不懂,那我就搭建一个专门懂 Vector 的垂直 AI 知识库。
02. 技术实现:我是怎么部署的?
为了解决“AI 瞎编”的问题,我采用了目前最流行的 RAG(检索增强生成) 技术架构。与其让 AI 凭空回忆,不如让 AI 像考试做“阅读理解”一样,看着书回答问题。
大致的构建流程如下:
- 数据获取(Data Ingestion): 我编写了脚本,对 Vector 官方支持网站(support.vector.com)进行了全量数据的爬取与清洗。重点是中文说明。
- 建立索引(Vector Embedding): 将这些成百上千篇文档切片,通过 Embedding 模型转化为向量数据,存入向量数据库。这就相当于给成千上万页的说明书做了极速目录。
- 构建 RAG 引擎: 当用户提问时,系统不直接问 LLM,而是先去向量数据库里搜出最相关的几篇文档片段,然后把这些片段 + 用户的问题,一起打包喂给大模型。
- 持续集成: Vector 官网更新了,我的库也要更新。我设计了定期同步机制,确保知识库尽可能贴合最新的官方文档。
最终成果: 一个专门针对 Vector 产品的、数据源纯净的、可溯源的 AI 问答网站。
03. 使用体验:它不仅仅是聊天
经过一段时间的开发和调试,这个网站终于上线了。相比于直接用 ChatGPT,它有几个针对我们行业的体验:
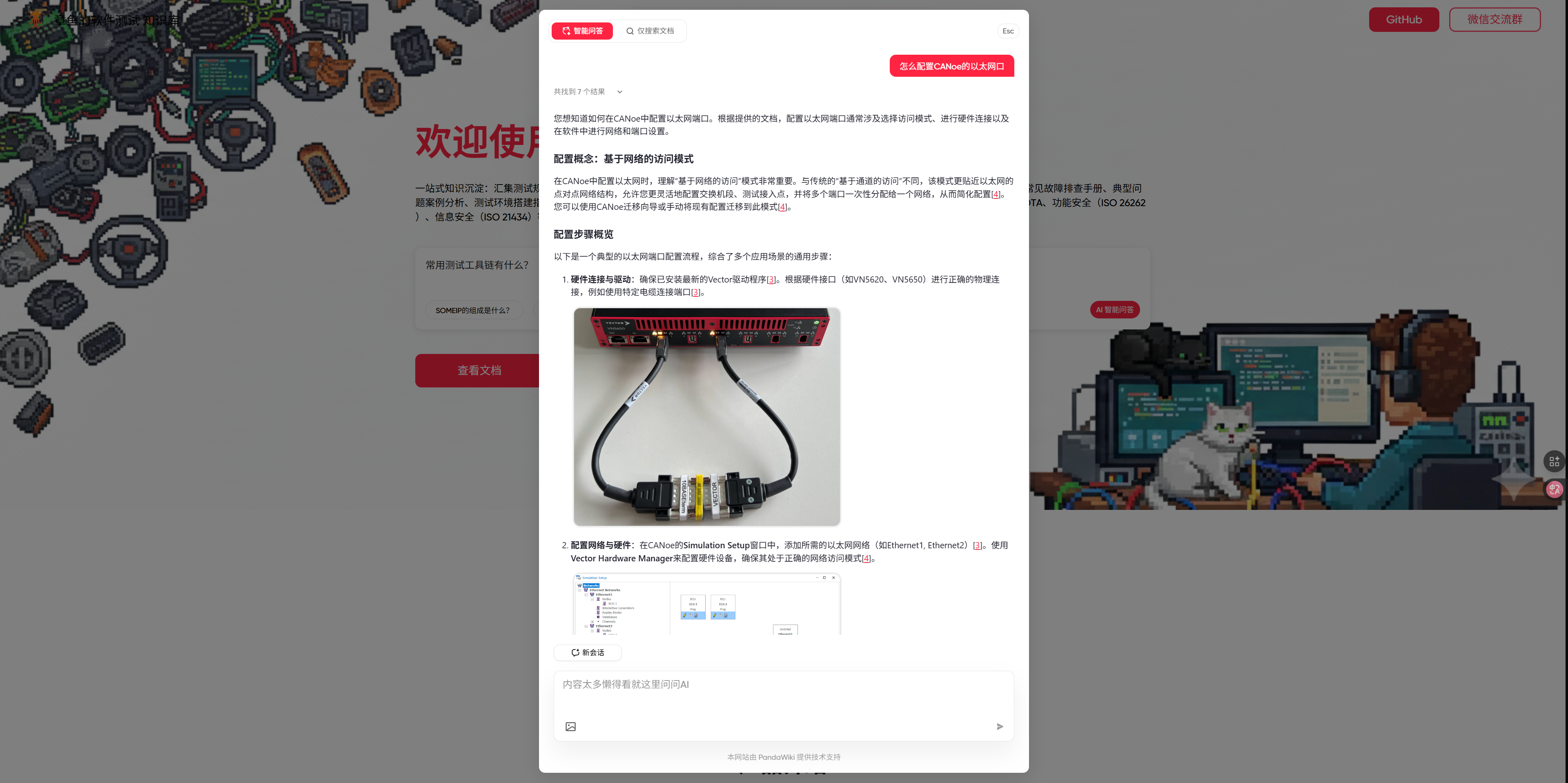
✅ 特性一:拒绝幻觉,有理有据 AI 的每一次回答,都是基于库里真实存在的 Vector 官方文档生成的。它会提取文档中的关键步骤、示例代码,整理成通俗易懂的语言反馈给你。
✅ 特性二:全量本地存储,极速查阅 有时候官网访问慢,或者搜索功能不好用。本站本地存储了全部文档。 在搜 Error Code,或是搜 CAPL 函数用法,都能减少很大程度的响应时间。
✅ 特性三:原文跳转(Traceability) 这是最核心的功能! 做测试讲究“溯源”。在 AI 回答完你的问题后,下方会直接列出参考的原始文档链接(网站本地)。
- 觉得 AI 总结得不够细?
- 想看原文档里的拓扑图截图?
- 想确认一下这是针对哪个版本的 CANoe? 点击链接,直接在本站跳转阅读完整的原文。 左边问答,右边查阅,彻底告别黑盒模式。
04. 实际案例演示
05. 免费开放,欢迎来“找茬”
做这个工具的初衷,是因为我自己淋过雨,所以想给同行们撑把伞。 目前网站完全免费开放给所有车载行业的测试人员、开发人员使用。
🔗 传送门:https://www.wxjneq.top/
虽然它已经学习了成千上万篇文档,但肯定还有不完美的地方:
- 如果你发现有最新的文档没收录;
- 如果你发现回答的逻辑有瑕疵;
- 或者你有更好的功能建议;
欢迎在评论区或者网站反馈入口告诉我!我会持续维护更新,争取把它打造成我们车载人手边最趁手的兵器。
希望这个小礼物,能帮你少加点班,多一点时间享受生活!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 20
20 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)