LangChain 学习 - Langchain Model IO(环境安装、大模型应用开发、模型分类、模型消息)
LangChain 学习 - Langchain Model IO(环境安装、大模型应用开发、模型分类、模型消息)
- 出处:尚硅谷 LangChain 教程
https://www.bilibili.com/video/BV1ZppNzHEY4/
一、前置知识
1、Python 基础语法
-
变量、函数、类、装饰器、上下文管理器
-
模块导入、包管理(推荐用使用 pip 或 conda)
2、大语言模型基础
- 了解什么是 LLM、Token、Prompt、Embedding
1. LLM 是大语言模型的缩写
2. Token 是 LLM 理解和生成文本的基本单位,它不完全等同于一个英文单词或一个汉字,LLM 在处理文本时,会先将输入文本切分成更小的片段,这些片段就是 Token
3. Prompt 就是给 LLM 的指令或问题
4. Embedding 是将文字(或其它数据)转换成一系列数字(即向量)的技术,这个数字序列代表了该文字在语义空间中的位置
-
OpenAI API 或其他模型提供商,例如,Anthropic、阿里云百炼、DeepSeek 等
-
通过浏览器或 APP 使用过大语言模型,例如,豆包、DeepSeek 等
二、环境安装
-
LangChain 基于 Python 开发,因此需确保系统中安装了 Python
-
直接下载 Python 安装包,推荐版本为 Python 3.10 及以上,也可以使用 PyCharm 的虚拟环境
-
Python 官网:
https://www.python.org/ -
查看 Python 版本:
python --version -
安装 LangChain 包(最新版):
pip install langchain
import sys
import langchain
print(sys.version)
print(langchain.__version__)
# 输出结果
3.10.2 (tags/v3.10.2:a58ebcc, Jan 17 2022, 14:12:15) [MSC v.1929 64 bit (AMD64)]
0.3.27
三、大模型应用开发
1、基于 RAG 架构的开发
(1)背景
- 大模型的知识冻结
1. 指的是一个大模型在完成训练后,其内部所蕴含的知识就被固定在了训练截止的那个时间点
2. 它无法自动学习或获取训练数据之后出现的新信息、新事件、新知识
3. 例如,你问大模型“谁是 2024 年诺贝尔奖得主?”,而它的训练数据只到 2023 年,它要么回答不知道,要么会根据过时的信息进行猜测(这可能引发幻觉)
- 大模型幻觉
1. 指的是大模型生成的内容看似流畅、合理,但实际上是错误的、虚构的、与事实不符的
2. 这些内容并非来自其训练数据,而是模型基于其学到的语言模式和概率分布捏造出来的
3. 简答来说,就是一本正经的胡说八道
- 而 RAG 就可以非常精准的解决这两个问题
(2)举例说明
-
LLM 在考试的时候面对陌生的领域,答复能力有限,然后就准备放飞自我了
-
而此时RAG给了一些提示和思路,让 LLM 懂了开始往这个提示的方向做,最终考试的正确率从 60% 到了 90%
(3)RAG
- RAG 全称 Retrieval-Augmented Generation,即检索增强生成
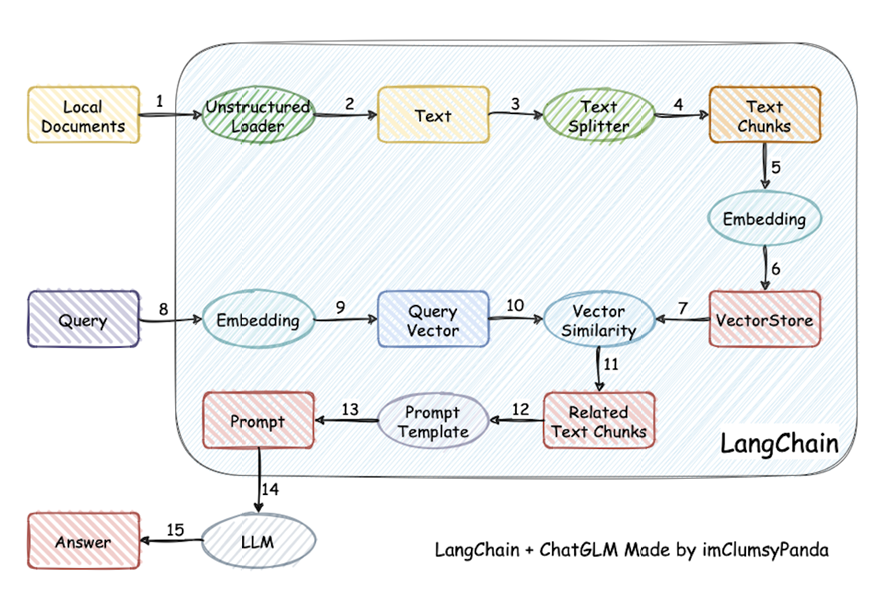
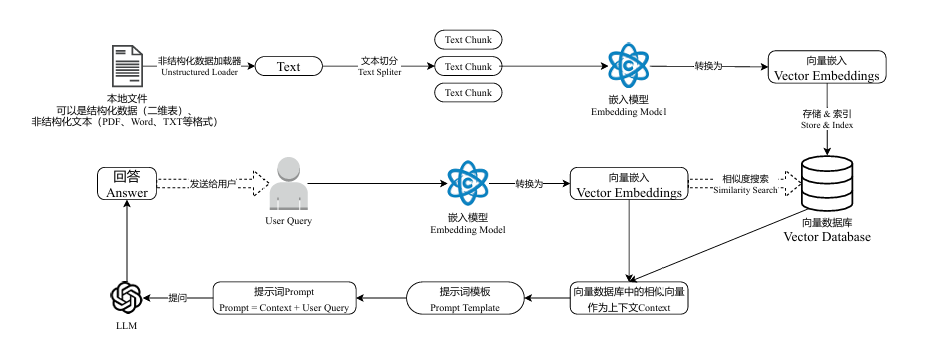
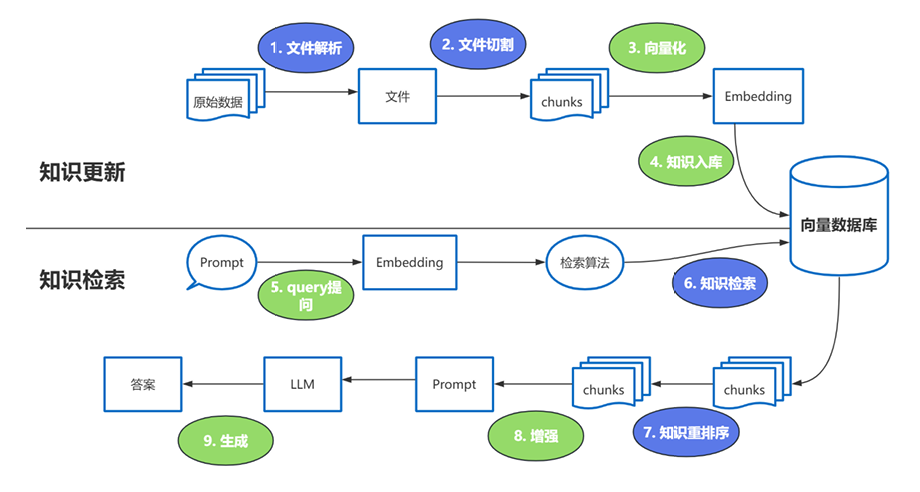
- 这些过程中的难点
-
文件解析
-
文件切割
-
知识检索
-
知识重排序
- 知识重排序的使用场景
-
适合:追求回答高精度和高相关性的场景,例如,专业知识库、客服系统等应用
-
不适合:引入知识重排序会增加召回时间,增加检索延迟,服务对响应时间要求高时,使用知识重排序可能不合适
- 这里有 3 个位置涉及到大模型的使用
-
第 3 步向量化时,需要使用 EmbeddingModels
-
第 7 步重排序时,需要使用 RerankModels
-
第 9 步生成答案时,需要使用 LLM
四、模型分类
1、概述
(1)按照模型功能的不同
-
非对话模型(LLMs、Text Model)
-
对话模型(Chat Models)
-
嵌入模型(Embedding Models)
(2)模型调用时,几个重要参数的书写位置的不同
-
硬编码,写在代码文件中
-
使用环境变量
-
使用配置文件
(3)具体调用的 API
-
OpenAI 提供的 API
-
其它大模型自家提供的 API
-
LangChain 的统一方式调用 API
补充
-
OpenAI 的 GPT 系列模型影响了⼤模型技术发展的开发范式和标准
-
⽆论是 Qwen、ChatGLM 等模型,它们的使⽤⽅法和函数调⽤逻辑基本遵循 OpenAI 定义的规范,没有太⼤差异
-
这就使得大部分的开源项⽬能够通过⼀个较为通⽤的接口来接⼊和使⽤不同的模型
2、模型功能的不同
(1)非对话模型
-
输入:接受文本字符串或 PromptValue 对象
-
输出:总是返回文本字符
-
适用场景:仅需单次文本生成任务(例如,摘要生成、翻译、代码生成、单次问答)或对接不支持消息结构的旧模型(例如,部分本地部署模型)
-
不支持多轮对话上下文,每次调用独立处理输入,无法自动关联历史对话(需手动拼接历史文本)
-
局限性:无法处理角色分工或复杂对话逻辑
from langchain_openai import ChatOpenAI
from dotenv import load_dotenv
import os
load_dotenv()
chat = ChatOpenAI(
api_key=os.getenv("API_KEY"),
base_url=os.getenv("BASE_URL"),
model=os.getenv("MODEL")
)
response = chat.invoke("写一首关于春天的诗")
print(response.content)
(2)对话模型
-
输入:接收消息列表
List[BaseMessage]或 PromptValue ,每条消息需指定角色,例如,SystemMessage、HumanMessage、AIMessage -
输出:总是返回带角色的消息对象(BaseMessage 子类),通常是 AIMessage
-
原生支持多轮对话,通过消息列表维护上下文(例如,
[SystemMessage, HumanMessage, AIMessage, ...]),模型可基于完整对话历史生成回复 -
适用场景:对话系统,例如,客服机器人、长期交互的 AI 助手
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, SystemMessage
from dotenv import load_dotenv
import os
load_dotenv()
chat = ChatOpenAI(
api_key=os.getenv("API_KEY"),
base_url=os.getenv("BASE_URL"),
model=os.getenv("MODEL")
)
messages = [
SystemMessage(content="You are a helpful assistant."),
HumanMessage(content="你是谁?")
]
response = chat.invoke(messages)
print(type(response))
print(response.content)
(3)嵌入模型
- 嵌入模型将文本作为输入并返回 Embedding,即浮点数列表
import os
from dotenv import load_dotenv
from langchain_community.embeddings import DashScopeEmbeddings
load_dotenv()
embeddings = DashScopeEmbeddings(
model="text-embedding-v4",
dashscope_api_key=os.getenv("API_KEY"),
)
result = embeddings.embed_query("这是一段关于春天的诗词")
print(result)
五、模型消息
| 消息类型 | 说明 |
|---|---|
| 消息类型 | 说明 |
| — | — |
| AIMessage | 来自 AI 的消息 |
| HumanMessage | 来自用户的消息 |
| SystemMessage | 用于引导 AI 行为的消息 |
| ChatMessage | 可以自定义角色的通用消息类型 |
| FunctionMessage / ToolMessage | 用于将执行工具的结果传回给模型的消息 |

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 30
30 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)