灵巧世界模型
25年12月来自韩国首尔大学和RLWRLD.AI的论文“Dexterous World Models”。近年来,3D重建技术的进步使得从日常环境中创建逼真的数字孪生变得更加容易。然而,目前的数字孪生模型大多是静态的——仅限于导航和视图合成,缺乏具身交互能力。为了弥合这一差距,引入灵巧世界模型(Dexterous World Model,DWM),这是一个基于场景-动作条件的视频扩散框架,用于建模灵
25年12月来自韩国首尔大学和RLWRLD.AI的论文“Dexterous World Models”。
近年来,3D重建技术的进步使得从日常环境中创建逼真的数字孪生变得更加容易。然而,目前的数字孪生模型大多是静态的——仅限于导航和视图合成,缺乏具身交互能力。为了弥合这一差距,引入灵巧世界模型(Dexterous World Model,DWM),这是一个基于场景-动作条件的视频扩散框架,用于建模灵巧的人类动作如何引起静态3D场景的动态变化。给定静态3D场景渲染图和以自我为中心的双手运动序列,DWM可以生成时间上连贯的视频,描绘逼真的人机交互过程。该方法将视频生成过程基于以下两个条件:(1)遵循指定相机轨迹的静态场景渲染图,以确保空间一致性;(2)以自我为中心的双手网格渲染图,该渲染图在以自我为中心的视角下编码几何和运动信息,从而直接建模动作条件下的动态变化。为了训练DWM,构建一个混合交互视频数据集:合成的以自我为中心的交互数据为关节运动-操作学习提供完全对齐的监督信息,而固定摄像头的真实世界视频则提供多样化且逼真的物体动态信息。实验表明,DWM能够实现逼真且符合物理规律的交互,例如抓取、打开或移动物体,同时保持相机和场景的一致性。
世界模型 [13] 旨在捕捉环境的底层结构和动态变化,以便智能系统能够有效地进行推理、规划和行动。对动态结果和因果关系进行建模是世界建模的核心,这使得预测由各种动作引起的环境变化成为可能。值得注意的是,许多最重要和最复杂的动态变化是由人与环境的交互驱动的,人类会操纵物体并主动改变世界的状态。因此,一个实用的世界模型必须:(1) 维护场景静态组件的一致表示,(2) 接受能够引起动态变化的动作规范(例如,灵巧的手部操作),以及 (3) 生成由此产生的动态变化,同时忠实地保留未改变的区域。
虽然视频生成模型 [53] 为世界建模提供一个有前景的基础,但它们仍然不足以作为忠实的世界模型。这些模型通常试图合成整个场景,包括静态和动态区域,这使得难以专注于由动作输入引起的特定动态变化。此外,大多数视频模型仅接受文本指令作为“动作输入”。然而,文本描述本质上是不精确的,因为它们无法准确地指定人类动作,例如手部姿势、精细的时间控制,而这两者对于建模逼真的人类操作至关重要。许多现有的世界模型通常将摄像机运动视为动作输入 [5, 64]。然而,摄像机运动并非世界动态变化的主要驱动因素。日常环境中最重要的变化来源是灵巧的手部交互,例如抓取和物体操纵,而这些在现有方法中是缺失的。
本文提出灵巧世界模型(Dexterous World Models,DWM),这是一种世界建模方法,它以静态场景和灵巧的人手运动作为输入,并预测由这些动作引起的动态变化(如图所示)。与需要模型合成整个场景(包括静态和动态部分)的现有方法不同,明确地将静态环境的渲染图以及从第一人称视角捕获的灵巧手部轨迹,作为输入。这种设计反映一种更自然的环境,因为人类在采取行动之前也会感知并内化静态世界,从而促使模型专注于由人类动作引起的世界动态变化,同时保留其他部分。以自我为中心的表述方式进一步为交互提供内在基础,因为它能够自然地捕捉用户在操作过程中的注意焦点和手部运动轨迹。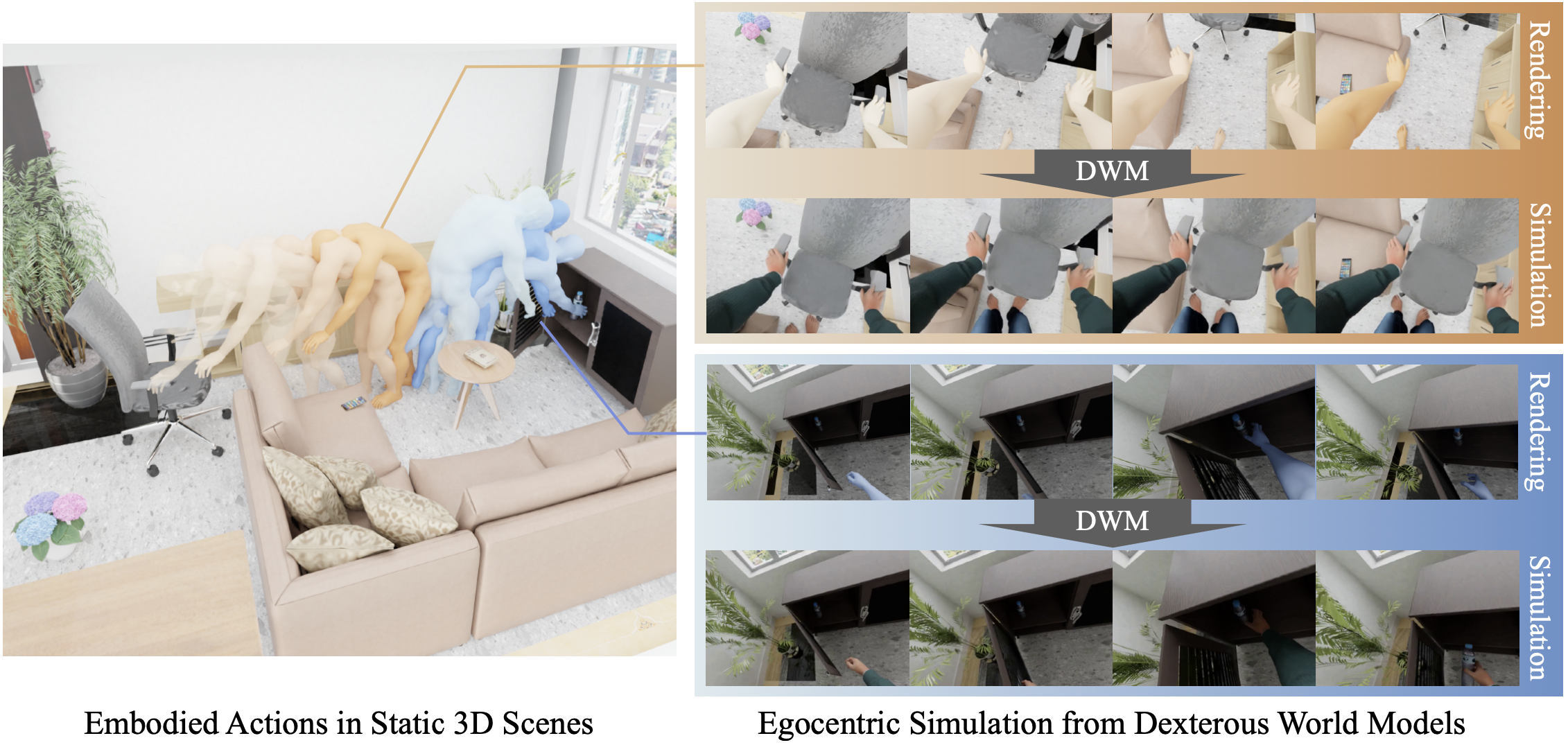
灵巧世界模型的构建
世界模型[13]旨在预测动作如何改变周围环境,从而使智体能够模拟或预测未来结果。世界模型的一般公式可以写成:
p_θ (S_1:F |S_0, A_1:F) = p_θ ((S_0+∆S_t)_t=1:F | S_0, A_1:F),
其中,S_0 表示初始场景环境,A_1:F 表示应用于世界的一系列动作。S_1:F 是动作后的环境状态。为了强调动态特性,将每个未来状态表示为 S_t = S_0 + ∆S_t,其中 ∆S_t 表示相对于初始静态场景的动作引起的残余变化。
现有的仅用于导航的视觉世界模型[5, 64]主要关注大规模导航和新视图预测,其中动作A_1:F主要对应于相机运动C_1:F,即p_θ (V_1:F | I_0, C_1:F)。V_1:F表示未来的视觉观测,I_0是初始帧,提供底层静态场景S_0的部分二维观测。这些模型旨在预测未见过视图V_t = Π(S_0; C_t),其中Π是相机视图C_t下的渲染函数。这种公式通常假设环境是静态的,没有状态变化,表示为∆S = ∅。
另一方面,最近的研究[4, 43]尝试将人类动作融入动态场景建模中,方法是扩展A_1:F = {C_1:F, H_1:F},其中H表示人类动作。然而,这种公式对于动态建模而言仍然不够理想,因为模型必须将场景外观和动态变化综合为一个纠缠的表示。更正式地说,这类模型可以写成 p_θ (V_1:F | I_0, A_1:F = {C1:F , H_1:F}),并且可以通过对潜静态场景 S_0 和动作引起的动态 ∆S_1:F 进行边际化来分解。
pd_θ 是动力学模型,它根据动作 A_1:F = {C, H}_1:F 对场景和动作引起的改变 (S_0, ∆S_1:F) 进行采样,而 po_θ 是观测模型,它将潜世界状态映射到视觉帧 V_1:F。观测模型可以简化为 po_θ (V_1:F | S_0, ∆S_1:F, C_1:F),因为在已知动力学 ∆S_1:F 和整个静态场景 S_0 的情况下,视觉结果 V_1:F 与动作输入 {H}_1:F 和图像观测 I_0 条件独立。类似地,在动力学模型中,可以忽略相机运动,因为它不影响世界动力学:pd_θ (S_0, ∆S_1:F | I_0, H_1:F)。然而,由于该动力学模型仍然需要生成 S_0 作为输出的一部分(以动作序列为条件),因此它容易改变静态世界,而不是专注于所需的动态状态变化 ∆S_1:F。这种场景生成和动力学的耦合破坏因果一致性,使得准确的动态建模变得困难。
在DWM 公式中,以 S_0 为条件,明确地将静态世界 S_0 与其动力学分离开来。因此,灵巧世界模型需要学习:
p_θ(V_1:F | S_0, A_1:F) = p_θ(V1:F | S_0, {C_1:F, H_1:F}),
其中 S_0 保持固定,只有其状态根据应用的动作而演变。通过引入时间场景动力学 ∆S_1:F 作为潜变量并对其进行边缘化。
与先前建模不同,动力学模型 pd_θ 仅生成以动作输入 H_1:F 为条件的动态变化 ∆S_1:F。观测模型 po_θ 将由 (S_0, ∆S_1:F) 描述的不断变化世界转化为沿相机轨迹 C_1:F 观察的一系列视觉帧,这与观测模型本身是一致的。这种结构定义一个清晰的因果过程:操作驱动世界状态的转变,而相机轨迹决定这些变化在视觉上如何呈现。
场景-动作条件视频扩散
基于公式表述,将框架实例化为一个以自我视角为中心、场景-动作条件下的视频扩散模型。给定静态 3D 场景 S_0 和一系列具身动作 A_1:F,该模型生成一个时间上连贯的视频,该视频可视化合理的人机交互以及动态场景变化。还对模型施加文本提示 T 的条件,该提示为视频扩散过程提供语义指导。为了将这种生成过程根植于具身感知,将 A_1:F = {C_1:F , H_1:F } 分解为相机轨迹 C_1:F 和手部操作轨迹 H_1:F,并假设条件独立结构,使得视觉序列 V_1:F 仅通过其自我视角渲染依赖于静态世界 S_0 和动作 A_1:F:
p(V_1:F | S_0, A_1:F ,T ) ≈ p(V_1:F | Π(S_0; C_1:F ), Π(H_1:F ;C_1:F ),T ),
其中 Π(·; C_1:F ) 表示沿自我视角相机轨迹 C1:F 观察的 2D 视图。这种近似将动态过程根植于具身感知,强制建立因果关系,即操作改变场景的视觉状态,而相机轨迹决定如何观察这些变化。重要的是,将生成过程实例化为一个潜视频扩散模型 [39],该模型以两个自我视角信号为条件:(1)静态场景视频 Π(S_0; C_1:F),它强制沿指定相机轨迹的空间一致性;(2)自我视角手部网格渲染视频 [35, 40],Π(H_1:F ; C_1:F),它编码驱动动态场景变化的操作动作。然后,模型在相同的相机视图下模拟由手部动作输入引起的最终环境状态,V_1:F = Π(S_0 + ∆S_1:F ; C_1:F )。如图所示框架的概述: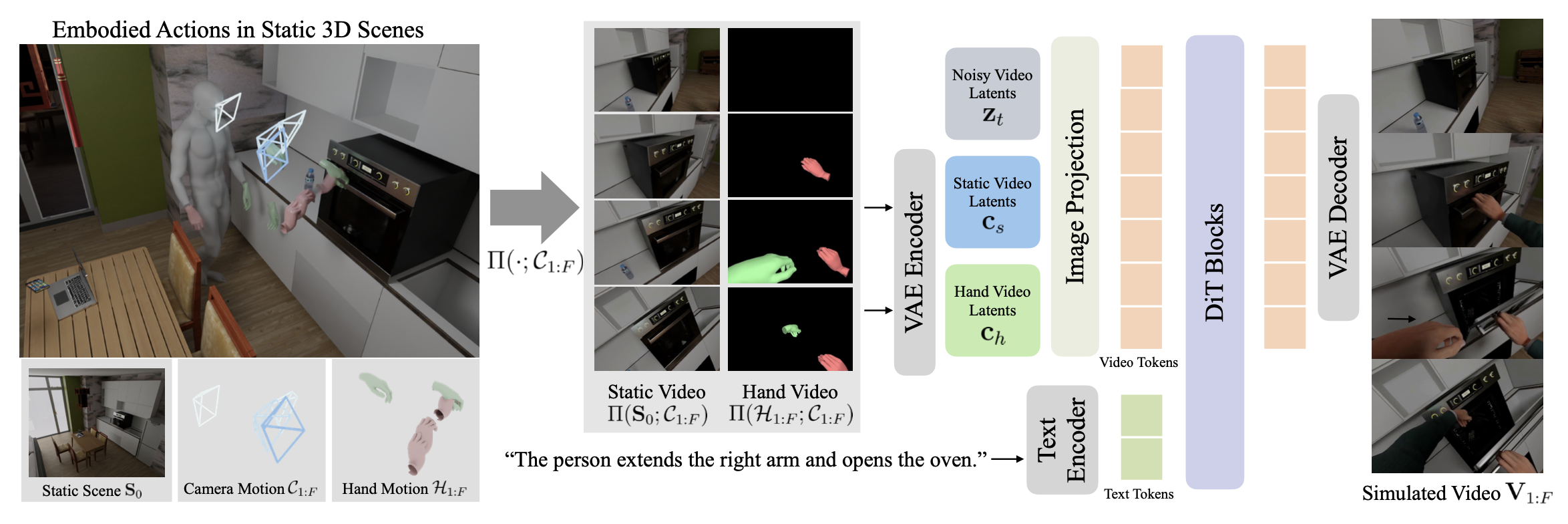
用于残差动力学学习的图像修复先验。将生成任务表述为学习手部操作动作引起的残差视觉变化,而不是从头开始重建整个视频。给定目标分布 p(V_1:F | Π(S_0; C_1:F ), Π(H_1:F; C_1:F )),将其分解为:
V_1:F = Π(S_0 +∆S_1:F; C_1:F)) = Π(S_0; C_1:F)+∆V_1:F,
其中 ∆V_1:F 表示在二维渲染空间中由动作引起的残差动力学。值得注意的是,当 ∆S_t 仅影响一小部分区域或引起微小变化时,相应的 ∆V_t 也同样很小,并且生成的帧与静态渲染 Π(S_0 ; C_1:F ) 保持接近。因此,针对此任务的有效模型应该结合用于保留静态区域的恒等映射能力和用于建模动态变化区域的强大生成先验。
受此观察的启发,将预训练的视频图像修复扩散模型 [1] 重新解释为具有生成先验的恒等函数,并将其用作灵巧世界模型的初始化。图像修复模型经过训练,可以在可见上下文的条件下重建被掩码的区域。当掩码设置为 m = 1(所有像素已知)时,该模型表现为近似恒等算子,能够忠实地重现输入视频。至关重要的是,这并非简单的恒等映射:预训练的图像修复网络 ε_θ_0 已经学会恢复空间结构、时间平滑性和外观连续性,即使在完全观察的输入下也具有强大的生成先验。通过使用这样的图像修复模型初始化 DWM,鼓励扩散过程保留静态场景外观和相机运动,同时学习仅生成由交互引起的残差动力学 ∆V_1:F。这种公式化方法利用图像修复模型的恒等保持特性来稳定训练,同时学习由交互引起的残差动力学。
训练。该模型在预训练视频变分自编码器 (VAE) [22, 53] 的潜空间中运行,该编码器根据其时空压缩比将输入视频编码为潜张量 z_0。在每个扩散时间步 t,扩散 Transformer (DiT) [37] ε_θ 根据静态场景和手部网格的潜表示 (c_s, c_h) 预测噪声潜表示 z_t 中的噪声分量。训练目标遵循标准的潜扩散损失 [39]:
L_LDM = E_z_0,t,ε ||ε−ε_θ(z_t, t | c_s, c_h)||^2
条件潜表示与 z_t 沿通道维度拼接后,再由 ε_θ 进行处理。在推理阶段,模型迭代地对 z_t 进行去噪,得到 zˆ_0,然后由 VAE 将其解码为逼真的交互视频。
配对交互视频数据集构建
训练模型需要成对的数据,包括 (i) 沿相机轨迹渲染的静态场景视频,(ii) 以第一人称视角拍摄的手部网格视频,以及 (iii) 相应的交互视频,该视频描绘动作引起的场景变化。在现实环境中收集这样的三元组数据在实践中极具挑战性,因为它需要在一个完美对齐的第一人称视角相机轨迹下同时捕捉静态场景和动态的人机交互。这种对齐对于学习人类动作如何改变静态场景同时保持空间一致性至关重要。由于在现实世界中难以在动态的第一人称视角下获取此类成对数据,构建一个混合训练数据集。具体来说,将提供精确对齐的合成第一人称视角交互视频对与提供逼真物理动态的固定相机真实世界交互视频相结合。此外,为了评估模型在动态视角下的真实世界场景中的泛化能力,开发一种专门的数据构建协议来收集用于评估的真实世界数据集。
合成交互-静态场景视频对。利用合成 3D 人体-场景交互数据集 TRUMANS [20],该数据集可以完全控制人体动作、场景状态和摄像机轨迹,从而实现静态序列和交互序列之间的精确对齐。人体模型使用 SMPL-X [35] 进行参数化,该模型提供全身姿态控制。将虚拟摄像机放置在标准姿态下两眼之间的中点,并使其与头部的前进轴对齐,且牢固地连接到头部关节,以模拟以自我为中心的视角。对于 TRUMANS 中的每个预先录制的动作序列,渲染三个同步输出:(1)交互视频捕捉从移动的以自我为中心的摄像机视角下完整的人体-场景交互;(2)静态场景视频是通过在静态环境中重放相同的摄像机轨迹而渲染的,不应用任何对象状态变化;(3)手部网格视频是通过沿相同轨迹仅渲染从全身网格中分割出来的手部表面而获得的。这种设置确保所有视频在时空上的对齐,为学习操作引起的视觉动态提供了精确的监督信号。
固定-摄像机真实世界交互视频。虽然合成数据提供精确的对齐,但它缺乏真实世界中观察的复杂物理效应,例如流体动力学、材料变形和细微的视觉变化。为了纳入这些效应,额外使用从固定摄像机拍摄的真实世界人机交互视频 [59],其中对于所有 t ∈ 1:F,C_t = C_0。在这种设置下,静态场景的自我中心渲染是时间不变的:
Π(S_0; C_t) = Π(S_0; C_0) = V_0, ∀t ∈ {1,…,F}
因此,通过简单地将第一帧 V0 重复 F 帧,可以构建一个静态场景视频,该视频在视角上与交互视频完全对齐。结合通过 HaMeR [36] 获得的预测手部网格渲染 Π(H_1:F ; C_1:F),这能够构建训练三元组 (V_1:F , Π(S_0; C_1:F ), Π(H_1:F ; C_1:F))。值得注意的是,现有的自我中心数据集 [7, 10, 16, 59] 没有明确提供在共享相机运动下对齐的此类对。构建利用固定摄像机设置来近似这种配对,从而无需单独的静态捕获或 3D 场景重建即可实现监督。这使得灵巧世界建模能够扩展到真实世界数据,同时保持与观测模型兼容。
用于评估的真实世界捕获。尽管大规模获取动态自我中心视角下的真实世界配对数据不切实际,但评估其在这些设置下的泛化能力对于验证世界模型至关重要。为此,开发一种专门的数据构建协议,用于收集用于动态视角评估的真实世界数据集。用 Aria 眼镜,它通过内置 SLAM [9] 提供毫米级相机轨迹估计。在捕获过程中,操作员首先探索场景,然后再进行交互,从而能够从预动作帧重建静态场景的 3D 高斯表示 [21, 54]。然后,在交互过程中,沿着记录的相机轨迹渲染重建的场景,生成与相应真实交互序列对齐的成对静态场景视频。使用此协议,在动态第一人称视角下收集 60 对真实世界样本,涵盖广泛的交互类型,包括简单和复杂的抓取放置、铰接体操作(例如,打开洗衣机、折叠椅子)以及反事实动力学(例如,按下电梯按钮门打开,打开水龙头水流出)。
使用 DWM 进行动作评估
给定静态 3D 场景 S0 和一组动作候选 {A(i)},用公式描述的 DWM 模拟它们的视觉结果,生成视频 {V(i)_1:F}。然后,根据预测的视觉结果与给定目标的匹配程度对动作进行排名,目标可以指定为语言指令或图像。对于基于语言的目标,用预训练的 VideoCLIP 模型 [45] 计算每个生成的视频 V(i)_1:F 与目标文本 g_text 之间的语义相似度:
s(i)_text = sim_VC (V(i)_1:F, g_text),
其中 sim_VC (·, ·) 表示视频和文本嵌入之间的余弦相似度。对于基于图像的目标,用 LPIPS 感知度量 [58] 将每次模拟的最后一帧 I(i)_F = V(i)_F 与目标图像 I_goal 进行比较:
s(i)_img = −LPIPS(I(i)_F, I_goal),
其中较低的 LPIPS 值表示较高的感知相似度。
最佳动作被选择为得分最高的动作:
A∗ = argmax_A(i) s(i)_text 或 A∗ = argmax_A(i) s(i)_img,
具体取决于给定目标的类型。这种公式化方法可以通过仿真实现目标驱动的动作选择,而无需显式的奖励函数或真实世界试验。
数据集。构建一个包含 144 个样本的基准数据集,每个样本都包含一段静态场景视频、一段手部网格视频和一段真实交互视频。为了确保全面评估,该基准数据集包含合成数据和真实世界数据。对于合成子集(Synthetic Dynamic),从 TRUMANS [20] 数据集中抽取 48 个序列,这些序列未用于训练。真实世界子集包含 96 个视频,涵盖静态和动态相机设置。在静态相机设置下(Real-World Static),用 TASTE-Rob [59] 数据集中 48 个未用于训练的样本。在动态相机设置下(Real-World Dynamic),通过 Aria Glasses 采集的自定义数据集中的 48 个样本。
基线方法和评估指标。将方法与两种可以直接使用静态场景视频作为条件输入的基线方法进行比较。首先,用 SDEdit [31] 对静态视频进行处理,并使用描述目标动作和由此产生的场景变化的文本提示进行引导(CVX SDEdit)。SDEdit 首先向输入视频添加噪声,然后通过基于文本条件的随机微分方程 (SDE) 先验模型对视频进行去噪,从而实现视频编辑。用 CogVideoX [53] 进行去噪,并将噪声强度设置为 0.75,推理步数为 50。其次,评估基础模型 CogVideoX-Fun [1] 的微调版(CVX-Fun Fine-tuned)。CogVideoX-Fun 是一种基于图像修复的视频扩散模型,它接收输入视频、指定修复区域的二值掩码序列以及文本提示,以生成修复后的视频。将掩码设置为全 1,并使用数据集对模型进行微调,但不使用手部网格视频作为条件。对于静态相机设置,还与 InterDyn [2] 进行比较,InterDyn 使用 ControlNet [57] 将手部掩码视频注入到扩散过程中,从而从初始帧合成手部与物体交互的视频。
用感知指标和像素级指标对生成的视频与真实视频进行评估。具体而言,报告 LPIPS [58] 和 DreamSim [11] 分数来衡量感知相似度,并报告 PSNR 和 SSIM 来衡量像素级质量。对于基准测试中的每个样本,用不同的随机种子生成三个视频,并报告平均结果。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 8
8 0
0- 0



 已为社区贡献164条内容
已为社区贡献164条内容

所有评论(0)