Parser输出解析器
LangChain输出解析器介绍:输出解析器是将语言模型返回的字符串转换为结构化数据的关键组件,支持JSON、列表等多种格式。主要功能包括格式转换、数据校验和错误处理。常用解析器包括StrOutputParser(字符串)、JsonOutputParser(JSON)、ListOutputParser(列表)等。JsonOutputParser可通过提示词或get_format_instructi
文章目录
输出解析器介绍
为什么需要输出解析器
语言模型返回的内容通常都是字符串的格式(文本格式),但在实际AI应用开发过程中,往往希望 model可以返回更直观、更格式化的内容,以确保应用能够顺利进行后续的逻辑处理。此时,LangChain提供的输出解析器就派上用场了。
输出解析器(Output Parser)负责获取 model 的输出并将其转换为更合适的格式。这在应用开发中极其重要。
LangChain 输出解析器可参考文档:https://reference.langchain.com/python/langchain_core/output_parsers/
什么是输出解析器
输出解析器是LangChain框架中的重要组件,它的作用是将大语言模型的原始输出内容解析为如JSON、XML、YAML等结构化数据。在LangChain中,输出解析器位于模型和最终数据输出之间,作为数据处理的中间层。通过输出解析器,可以实现如下目的:
- 指定格式输出:将模型的文本输出转换指定格式
- 数据校验:确保输出内容符合预期的格式和类型
- 错误处理:当解析失败时,进行错误修复和重试
- 输出格式提示词:生成对应格式要求的提示词,如要生成JSON的具体描述,可以通过提示词传递给大模型,达到返回特定格式数据的目的
输出解析器分类
LangChain提供了多种输出解析器,以下是常见的输出解析器及使用场景:
| 解析器类型 | 适用场景 | 输出格式 |
|---|---|---|
| StrOutputParser | 简单文本输出 | 字符串 |
| JsonOutputParser | JSON格式数据 | 字典/列表 |
| PydanticOutputParser | 复杂结构化数据 | Pydantic模型对象 |
| ListOutputParser | 列表数据 | Python列表 |
| DatetimeOutputParser | 时间日期数据 | datetime对象 |
| BooleanOutputParser | 布尔值输出 | True/False |
输出解析器方法
parse:将大模型输出的内容,格式化成指定的格式返回。
format_instructions:它会返回一段清晰的格式说明字符串,告诉 model 希望输出成什么格式(比如 JSON,或者特定格式)。
输出解析器类继承关系
分析LangChain源码可知,在 LangChain 的类结构中,顶层基类是 BaseLLMOutputParser,用于定义所有 LLM 输出解析器的抽象父类。而BaseTransformOutputParser是一个泛型类,用于“对模型输出进行转换”,我们常用的 StrOutputParser、ListOutputParser等均继承自 BaseTransformOutputParser。
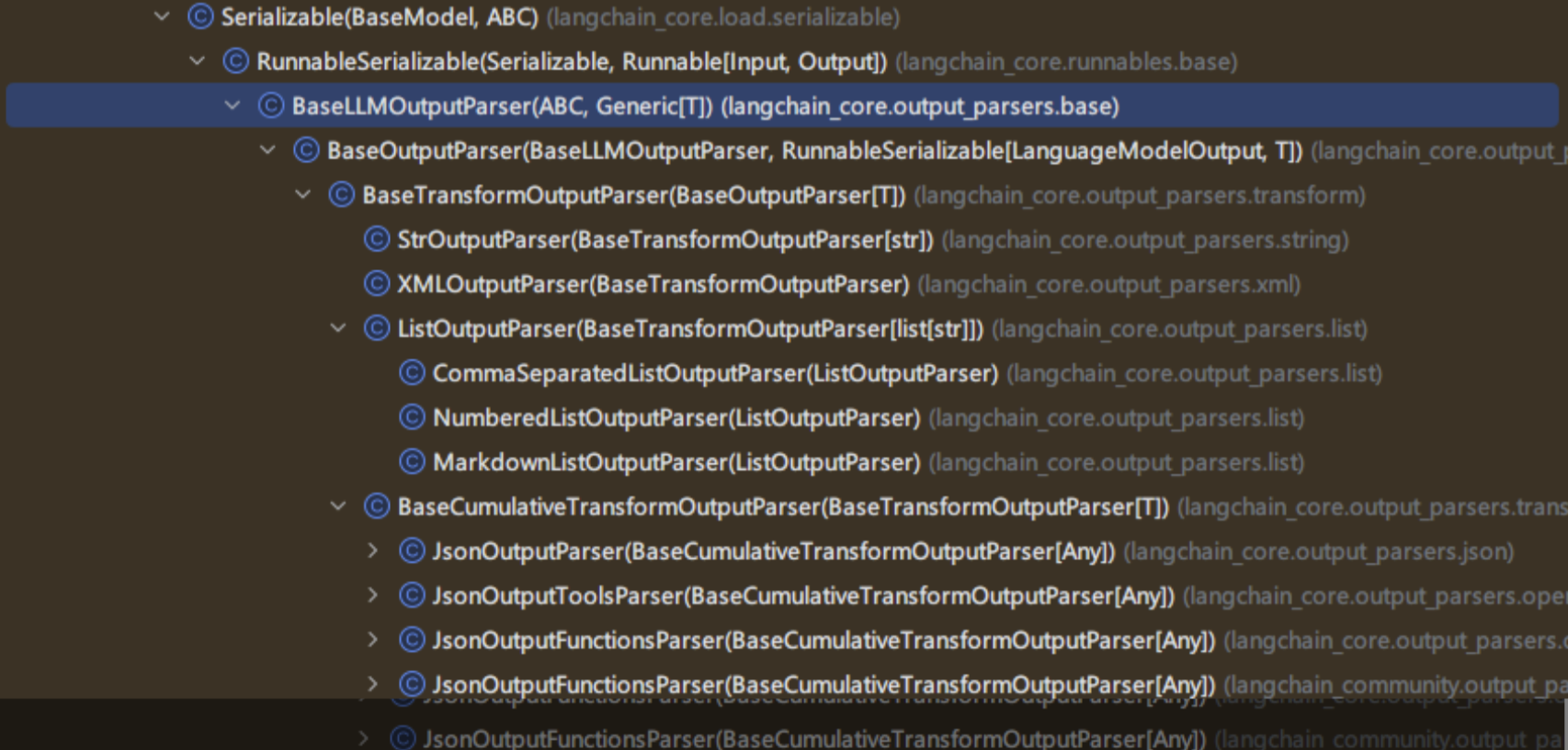
常用输出解析器用法
字符串解析器
StrOutputParser是LangChain中最简单的输出解析器,它可以简单地将任何输入转换为字符串。从结果中提取content字段转换为字符串输出。
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_ollama import ChatOllama
from loguru import logger
# 创建聊天提示模板,包含系统角色设定和用户问题输入
chat_prompt = ChatPromptTemplate.from_messages([
("system", "你是一个{role},请简短回答我提出的问题"),
("human", "请回答:{question}")
])
# 使用指定的角色和问题生成具体的提示内容
prompt = chat_prompt.invoke({"role": "AI助手", "question": "什么是LangChain"})
logger.info(prompt)
# 初始化Ollama聊天模型,使用qwen3:14b模型并关闭推理模式
model = ChatOllama(model="qwen3:14b", reasoning=False)
# 调用模型获取回答结果
result = model.invoke(prompt)
logger.info(f"模型原始输出:\n{result}")
# 创建字符串输出解析器,用于解析模型返回的结果
parser = StrOutputParser ()
# 打印解析后的结构化结果
response = parser.invoke(result)
logger.info(f"解析后的结构化结果:\n{response}")
# 打印类型
logger.info(f"结果类型: {type(response)}")
Json 解析器
JsonOutputParser,即JSON输出解析器,是一种用于将大模型的自由文本输出转换为结构化JSON数据的工具。
适合场景:特别适用于需要严格结构化输出的场景,比如 API 调用、数据存储或下游任务处理。
实现方式:
- 用户自己通过提示词指明返回Json格式
- 借助JsonOutputParser的get_format_instructions() ,生成格式说明,指导模型输出JSON 结构
指定提示词指明返回 json 格式
from langchain_core.output_parsers import StrOutputParser, JsonOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_ollama import ChatOllama
from loguru import logger
# 创建聊天提示模板,包含系统角色设定和用户问题输入
chat_prompt = ChatPromptTemplate.from_messages([
("system", "你是一个{role},请简短回答我提出的问题,结果返回json格式,q字段表示问题,a字段表示答案。"),
("human", "请回答:{question}")
])
# 使用指定的角色和问题生成具体的提示内容
prompt = chat_prompt.invoke({"role": "AI助手", "question": "什么是LangChain"})
logger.info(prompt)
# 初始化Ollama聊天模型,使用qwen3:14b模型并关闭推理模式
model = ChatOllama(model="qwen3:14b", reasoning=False)
# 调用模型获取回答结果
result = model.invoke(prompt)
logger.info(f"模型原始输出:\n{result}")
# 创建JSON输出解析器实例
parser = JsonOutputParser()
# 调用解析器处理结果数据,将输入转换为JSON格式的响应
response = parser.invoke(result)
logger.info(f"解析后的结构化结果:\n{response}")
# 打印类型
logger.info(f"结果类型: {type(response)}")
使用get_format_instructions 生成格式说明。
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_ollama import ChatOllama
from loguru import logger
from pydantic import BaseModel, Field
class Person(BaseModel):
"""
定义一个新闻结构化的数据模型类
属性:
time (str): 新闻发生的时间
person (str): 新闻涉及的人物
event (str): 发生的具体事件
"""
time: str = Field(description="时间")
person: str = Field(description="人物")
event: str = Field(description="事件")
# 创建JSON输出解析器,用于将model输出解析为Person对象
parser = JsonOutputParser(pydantic_object=Person)
# 获取格式化指令,告诉model如何输出符合要求的JSON格式
format_instructions = parser.get_format_instructions()
# 创建聊天提示模板,定义系统角色和用户输入格式
chat_prompt = ChatPromptTemplate.from_messages([
("system", "你是一个AI助手,你只能输出结构化JSON数据。"),
("human", "请生成一个关于{topic}的新闻。{format_instructions}")
])
# 格式化提示词,填入具体主题和格式化指令
prompt = chat_prompt.format_messages(topic="小米", format_instructions=format_instructions)
# 记录格式化后的提示词信息
logger.info(prompt)
# 初始化ChatOllama大语言模型实例
model = ChatOllama(model="qwen3:14b", reasoning=False)
# 调用大语言模型获取响应结果
result = model.invoke(prompt)
# 记录模型返回的结果
logger.info(f"模型原始输出:\n{result}")
# 使用解析器将模型输出解析为结构化数据
response = parser.invoke(result)
logger.info(f"解析后的结构化结果:\n{response}")
# 打印类型
logger.info(f"结果类型: {type(response)}")
列表解析器
利用CommaSeparatedListOutputParser解析器,可以将模型的文本响应转换为一个用逗号分隔的列表(List[str])
from langchain_core.output_parsers import CommaSeparatedListOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_ollama import ChatOllama
from loguru import logger
# 创建逗号分隔列表输出解析器实例
parser = CommaSeparatedListOutputParser()
# 获取格式化指令,用于指导模型输出格式
format_instructions = parser.get_format_instructions()
# 创建聊天提示模板,包含系统消息和人类消息
# 系统消息定义了AI助手的行为规范和输出格式要求
# 人类消息定义了具体的任务请求,使用占位符{topic}表示主题
chat_prompt = ChatPromptTemplate.from_messages([
("system", f"你是一个AI助手,你只能输出结构化列表数据。{format_instructions}"),
("human", "请生成5个关于{topic}的内容")
])
# 格式化聊天提示消息,将占位符替换为实际值
prompt = chat_prompt.format_messages(topic="小米", format_instructions=format_instructions)
# 记录格式化后的提示消息
logger.info(prompt)
# 创建ChatOllama模型实例,指定使用的模型名称和推理模式
model = ChatOllama(model="qwen3:14b", reasoning=False)
# 调用模型执行推理,传入格式化的提示消息
result = model.invoke(prompt)
# 记录模型返回的原始结果
logger.info(f"模型原始输出:\n{result}")
# 使用解析器处理模型返回的结果,将其转换为结构化列表
response = parser.invoke(result)
logger.info(f"解析后的结构化结果:\n{response}")
# 打印类型
logger.info(f"结果类型: {type(response)}")
XML 解析器
XMLOutputParser,将模型的自由文本输出转换为可编程处理的 XML 数据。
注意:XMLOutputParser 不会直接将模型的输出保持为原始XML字符串,而是会解析XML并转换成Python字典(或类似结构化的数据)。目的是为了方便程序后续处理数据,而不是单纯保留XML格式。
代码如下:
from langchain_core.output_parsers import XMLOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_ollama import ChatOllama
from loguru import logger
# 创建 XML 输出解析器实例
parser = XMLOutputParser()
# 获取格式化指令(这会告诉模型如何以 XML 格式输出)
format_instructions = parser.get_format_instructions()
# 创建提示模板
chat_prompt = ChatPromptTemplate.from_messages([
("system", f"你是一个AI助手,只能输出XML格式的结构化数据。{format_instructions}"),
("human", "请生成5个关于{topic}的内容,每个内容包含<name>和<description>两个字段")
])
# 格式化提示,将 {topic} 替换为实际主题
prompt = chat_prompt.format_messages(topic="小米", format_instructions=format_instructions)
# 打印提示消息
logger.info(prompt)
# 创建 ChatOllama 模型实例
model = ChatOllama(model="qwen3:14b", reasoning=False)
# 执行推理
result = model.invoke(prompt)
# 记录模型原始输出
logger.info(f"模型原始输出:\n{result.content}")
# 解析 XML 输出为结构化 Python 对象(例如字典或列表)
response = parser.invoke(result)
# 打印解析后的结构化结果
logger.info(f"解析后的结构化结果:\n{response}")
# 打印类型
logger.info(f"结果类型: {type(response)}")
解析器进阶用法
Pydantic解析器
PydanticOutputParser 是 LangChain 输出解析器体系中最常用、最强大的结构化解析器之一。
它与 JsonOutputParser 类似,但功能更强 —— 能直接基于 Pydantic 模型 定义输出结构,并利用其类型校验与自动文档能力。 对于结构更复杂、具有强类型约束的需求,PydanticOutputParser 则是最佳选择。它结合了Pydantic模型的强大功能,提供了类型验证、数据转换等高级功能,使用示例如下:
from langchain_core.output_parsers import PydanticOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_ollama import ChatOllama
from loguru import logger
from pydantic import BaseModel, Field, field_validator
class Product(BaseModel):
"""
产品信息模型类,用于定义产品的结构化数据格式
属性:
name (str): 产品名称
category (str): 产品类别
description (str): 产品简介,长度必须大于等于10个字符
"""
name: str = Field(description="产品名称")
category: str = Field(description="产品类别")
description: str = Field(description="产品简介")
@field_validator("description")
def validate_description(cls, value):
"""
验证产品简介字段的长度
参数:
value (str): 待验证的产品简介文本
返回:
str: 验证通过的产品简介文本
异常:
ValueError: 当产品简介长度小于10个字符时抛出
"""
if len(value) < 10:
raise ValueError('产品简介长度必须大于等于10')
return value
# 创建Pydantic输出解析器实例,用于解析模型输出为Product对象
parser = PydanticOutputParser(pydantic_object=Product)
# 获取格式化指令,用于指导模型输出符合Product模型的JSON格式
format_instructions = parser.get_format_instructions()
# 创建聊天提示模板,包含系统消息和人类消息
prompt_template = ChatPromptTemplate.from_messages([
("system", "你是一个AI助手,你只能输出结构化的json数据\n{format_instructions}"),
("human", "请你输出标题为:{topic}的新闻内容")
])
# 格式化提示消息,填充主题和格式化指令
prompt = prompt_template.format_messages(topic="小米", format_instructions=format_instructions)
# 记录格式化后的提示消息
logger.info(prompt)
# 创建ChatOllama模型实例,使用qwen3:14b模型
model = ChatOllama(model="qwen3:14b", reasoning=False)
# 调用模型获取结果
result = model.invoke(prompt)
# 记录模型返回的结果
logger.info(f"模型原始输出:\n{result.content}")
# 使用解析器将模型结果解析为Product对象
response = parser.invoke(result)
# 打印解析后的结构化结果
logger.info(f"解析后的结构化结果:\n{response}")
# 打印类型
logger.info(f"结果类型: {type(response)}")
自定义输出解析器在某些情况下,LangChain提供的内置的解析器无法满足业务的要求,这时我们可以创建自定义的输出解析器,如下示例,定义Answer数据模型,规定回答内容和标签格式,并使用自定义解析器将JSON数组标签转为《》格式。
import re
from langchain_core.output_parsers import PydanticOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_ollama import ChatOllama
from loguru import logger
from pydantic import BaseModel, Field
# 定义数据模型
class Answer(BaseModel):
content: str = Field(description="回答内容")
tags: str = Field(description="标签,格式为《标签1》《标签2》")
# 自定义解析器
class CustomPydanticOutputParser(PydanticOutputParser):
def parse(self, text: str) -> Answer:
# 将数组格式转换为《》格式
tags_match = re.search(r'"tags"\s*:\s*\[(.*?)\]', text, re.DOTALL)
if tags_match:
tags_list = re.findall(r'"([^"]+)"', tags_match.group(1))
tags_string = "".join([f"《{tag}》" for tag in tags_list])
text = re.sub(r'"tags"\s*:\s*\[.*?\]', f'"tags": "{tags_string}"', text, flags=re.DOTALL)
return super().parse(text)
# 创建解析器
parser = CustomPydanticOutputParser(pydantic_object=Answer)
# 创建提示模板
chat_prompt = ChatPromptTemplate.from_messages([
("system", "你是AI助手,请按JSON格式简短回答\n{format_instructions}"),
("human", "{question}")
])
# 生成提示
prompt = chat_prompt.invoke({
"question": "什么是LangChain",
"format_instructions": parser.get_format_instructions()
})
# 调用模型
model = ChatOllama(model="qwen3:14b", reasoning=False)
result = model.invoke(prompt)
# 解析结果
response = parser.invoke(result)
logger.info(f"回答: {response.content}")
logger.info(f"标签: {response.tags}")

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 12
12 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)