无监督ReRank pointwise, listwise, pairwise举例
本文探讨了三种基于大语言模型(LLM)的零样本文档重排方法。pointwise方法通过优化提示词ρ*来最大化查询生成概率,采用判别器引导的条件生成策略;listwise方法利用滑动窗口技术处理长文档列表,逐步提升相关文档排名;pairwise方法(PRP)通过输入顺序变换确保排序稳定性,当两次结果矛盾时视文档得分相同。这些方法均无需训练数据,通过精心设计的提示策略有效提升了LLM在信息检索任务中的
pointwise
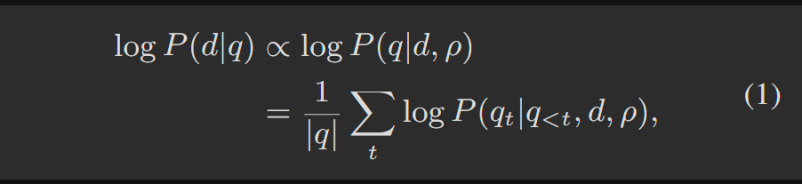 其中 |q| 表示查询 q 的 token 长度,而 ρ 是引导 LLM 生成查询 q 的自然语言提示。
其中 |q| 表示查询 q 的 token 长度,而 ρ 是引导 LLM 生成查询 q 的自然语言提示。
第一行是说左侧的文档相关性得分与右侧的查询生成得分之间存在直接的单调关系。
第二行第一个是归一化因子,避免较长查询的对数概率总和天然较高的问题。第二个是在给定文档,提示以及查询中前t-1个token的情况下,生成查询q的第t个token的对数概率。
由于提示 ρ 是公式 1 中唯一可控的变量,因此寻找最佳提示是提高 LLM 性能的一种简单而有效的方法。因此,在这项工作中,我们专注于提示优化策略。
定义ρ*作为指导LLM生成最接近于用户query的prompt,是最大化查询生成分数的提示:
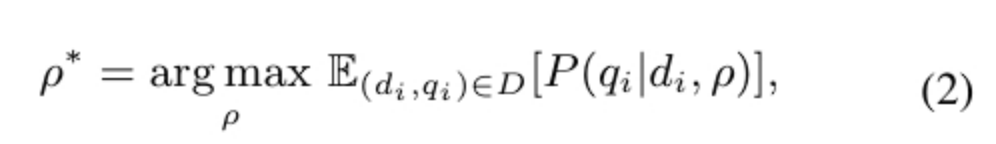 为了解决寻找最优prompt的问题,本文用基于判别器的条件生成方法解决,该方法遵循贝叶斯公式,这个公式描述了在判别器引导的受限生成过程中,生成下一个提示token的概率。将生成下一个token的概率分解为判别器和生成器两部分的贡献。
为了解决寻找最优prompt的问题,本文用基于判别器的条件生成方法解决,该方法遵循贝叶斯公式,这个公式描述了在判别器引导的受限生成过程中,生成下一个提示token的概率。将生成下一个token的概率分解为判别器和生成器两部分的贡献。
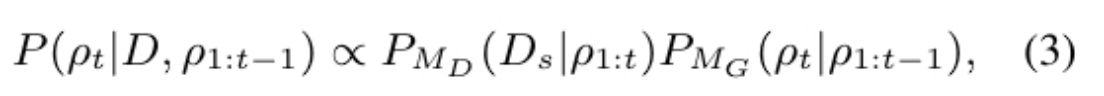
公式左侧表示在给定数据集和已生成的先前提示序列的条件下,生成当前提示的概率
中间表示成正比
其中MD是zero-shot的重排器作为判别器,在给定当前正在构建的完整提示序列的条件下,评估采样数据集的似然
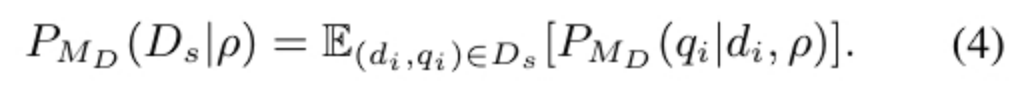
MG作为decoder-only的大模型作为生成器,为数据集D的子集,表示在给定先前提示序列的条件下,生成当前提示的概率。生成器MG只从判别器衡量过的prompt进行采样。
Discrete Prompt Optimization via Constrained Generation for Zero-shot Re-ranker
listwise
作者提出使用如下prompt来让LLM实现document的重排,方括号后生成一系列按相关性重新排序后的passage id。为了解决输入长度的限制,作者采用滑动窗口的方法。
滑动窗口
具体而言,假设模型能够一次对m个文档进行重排序,为了对长度为n > m的列表进行排序,我们首先对列表中的最后m个文档进行排序。然后,我们将排序窗口向列表的头部移动m/2并进行重排序。重复此操作,直到窗口到达列表的头部。理想情况下,这种策略应该能够在一个回合中将m/2个最相关的文档“提升”到列表的头部。请注意,此策略无法完全重新排序整个候选列表,但我们证明了它在改进排名靠前的结果方面的有效性。

Zero-Shot Listwise Document Reranking with a Large Language Model
pairwise
本文提出的pairwise ranking prompting (PRP)支持生成式和打分式的输出,但是生成式可能生成无关内容,所以主要讨论生成式。PRP输入为u(q,d1,d2) 的三元组形式,并且利用LLM对输入顺序敏感的特点,同一个三元组会变换顺序输入到模型两次,若两次结果相反,则认为两个document得分一样。
Large Language Models are Effective Text Rankers with Pairwise Ranking Prompting

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 11
11 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)