[MIA 2025] 拒绝“一刀切”!JHU 新型无监督空间自适应正则化解决医学图像配准中的滑动边界难题
直击痛点: 巧妙地解决了医学图像中常见的“局部形变差异”和“滑动边界”问题,且无需任何手动标签(Label-free)。高可解释性: 输出的权重图λpλp充当了不确定性图(Uncertainty Map)。低λ\lambdaλ表示复杂的形变或模型不确定性,提供了额外的诊断信息。工程友好: 作为即插即用模块,可以轻松添加到 VoxelMorph 或 Swin-UNet 等其他架构中。
[MIA 2025] 拒绝“一刀切”!JHU 新型无监督空间自适应正则化解决医学图像配准中的滑动边界难题
论文题目: Unsupervised learning of spatially varying regularization for diffeomorphic image registration
发表期刊: Medical Image Analysis (MIA), 2025
作者团队: Junyu Chen, Shuwen Wei, et al. (Johns Hopkins University, Vanderbilt University, NVIDIA)
关键词: 可变形图像配准, 空间变化正则化, 贝叶斯优化, 深度学习
1. 🚀 速读 (TL;DR)
传统的深度学习配准方法(如 VoxelMorph)通常使用一个全局正则化(Global Regularization)权重。这在处理滑动边界(Sliding Boundaries)(如肺部运动)或复杂形变(如心室扩张)时会陷入两难:一个全局权重无法同时满足平滑区域和剧烈形变区域的需求。本文提出了一种分层概率模型框架,用于无监督学习,使网络能够自适应地学习体素级的正则化权重图。作为一种即插即用的模块,结合贝叶斯超参数优化,该方法在脑部、心脏、全身 CT 和肺部 4DCT 数据集上显著优于 TransMorph 和 HyperMorph。值得注意的是,它在保持微分同胚性质的同时,完美捕捉了器官间的不连续滑动运动。
2. 🧐 动机与痛点 (Motivation)
现有问题:“鱼与熊掌不可兼得”的困境
在可变形图像配准(DIR)中,我们通常优化以下目标函数:
L=Lsim(F,M∘ϕ)+λLreg(ϕ) \mathcal{L} = \mathcal{L}_{sim}(F, M \circ \phi) + \lambda \mathcal{L}_{reg}(\phi) L=Lsim(F,M∘ϕ)+λLreg(ϕ)
其中 Lreg\mathcal{L}_{reg}Lreg 确保形变场的平滑性以防止非物理折叠。然而,目前大多数 SOTA 方法(包括 VoxelMorph, TransMorph 等)都假设 λ\lambdaλ 是一个空间不变的常数。
传统方法的局限性
这种“一刀切”的策略在处理复杂的解剖结构时会失效:
- 解剖异质性:在脑部,脑室可能需要大变形,而白质区域则相对稳定。强全局正则化会限制脑室对齐,而弱正则化会导致白质区域出现噪声形变。
- 滑动运动(Sliding Motion):这是最大的痛点。例如,呼吸过程中,肺部与胸壁(肋骨)之间会发生剧烈的相对滑动。物理上,这里应该有一个“运动不连续面”,但全局平滑正则化会强制平滑这个边界,导致精度下降和生理上的不准确。
本文方案
作者没有引入额外的解剖标签图(Label Maps)来强制边界,而是从概率角度出发,将正则化强度本身视为一个随机变量。通过设计一个分层概率模型,网络在无监督训练过程中学习哪里该平滑,哪里该“放手”。
3. 💡 方法论 (Methodology)
核心思想是将正则化权重 λ\lambdaλ 建模为空间变化图 λ(p)\lambda(\mathbf{p})λ(p),并通过最大后验概率(MAP)估计来求解。
3.1 整体架构
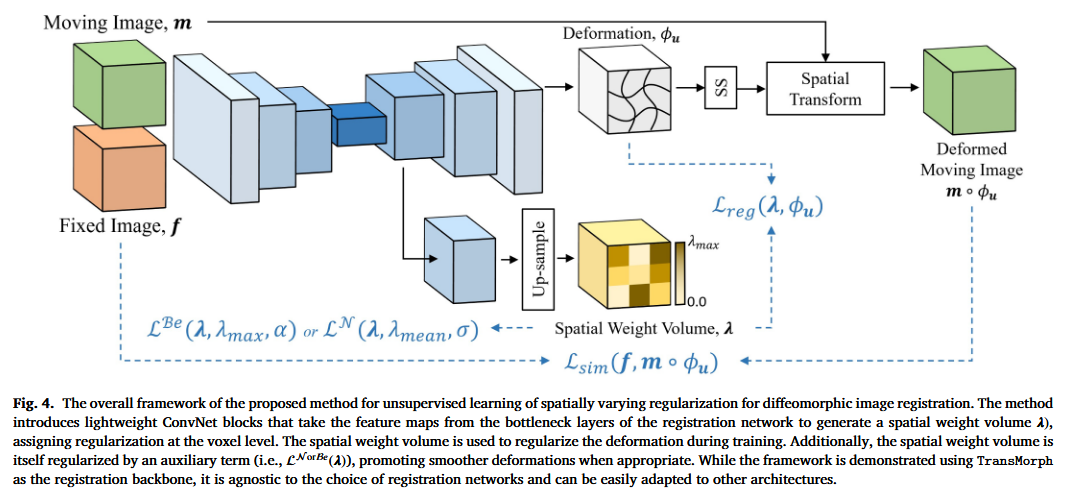
模型使用 TransMorph 作为骨干网络,但在解码器中增加了一个轻量级的 ConvNet Block。
- 输入: 移动图像 MMM 和固定图像 FFF。
- 输出:
- 形变场 ϕ\phiϕ: 用于配准。
- 空间权重体 λ(p)\lambda(\mathbf{p})λ(p): 与图像尺寸相同的图,每个像素值代表该位置的正则化强度。
3.2 关键模块
A. 分层概率模型与损失函数
作者构建了一个分层贝叶斯模型。不仅对形变场 uuu 进行建模,还为正则化权重 Λ\LambdaΛ(λ\lambdaλ 的矩阵形式)引入了超先验(Hyperprior)。
推导出的损失函数由三部分组成:
L=Lsim+∑pλ(p)∣∇u(p)∣2−logp(λ) \mathcal{L} = \mathcal{L}_{sim} + \sum_{\mathbf{p}} \lambda(\mathbf{p}) |\nabla u(\mathbf{p})|^2 - \log p(\lambda) L=Lsim+p∑λ(p)∣∇u(p)∣2−logp(λ)
- 相似性损失: 标准的 NCC Loss。
- 空间自适应正则化: 注意 λ(p)\lambda(\mathbf{p})λ(p) 是逐像素相乘的。在平坦区域,λ\lambdaλ 增大以抑制噪声;在边缘处,λ\lambdaλ 减小以允许剧烈形变。
- 超先验损失: 这对于防止 λ\lambdaλ 坍缩为 0(即完全没有正则化)至关重要。
B. 两种先验分布 (Beta vs. Gaussian)
作者提出了两种 λ\lambdaλ 的先验假设:
- 高斯先验 (Gaussian Prior): 假设 λ\lambdaλ 服从正态分布。
- Beta 先验 (Beta Prior): 推荐使用。它将 λ\lambdaλ 约束在 [0,λmax][0, \lambda_{max}][0,λmax] 之间。通过调整 Beta 分布的形状参数 α\alphaα,鼓励网络输出接近 0 或 λmax\lambda_{max}λmax 的权重,这对于捕捉器官边界极其有效。
C. 贝叶斯超参数优化
由于引入了新的超参数(如 Beta 分布的 α\alphaα 和 λmax\lambda_{max}λmax),手动调参非常耗时。作者使用 树状结构 Parzen 估计器 (TPE) 进行自动贝叶斯优化,这比网格搜索(Grid Search)效率高得多,能自动为不同数据集找到最佳配置。
4. 📊 实验与结果
数据集
- IXI (脑部 MRI): 脑部配准。
- ACDC & M&Ms (心脏 MRI): 多时相心脏配准。
- autoPET (全身 CT): 大规模全身配准。
- 4DCT (肺部 CT): 极具挑战性的呼吸运动配准。
对比方法
对比了 SyN (传统方法), VoxelMorph, TransMorph, 以及 HyperMorph (一种学习超参数但仍使用全局正则化的方法)。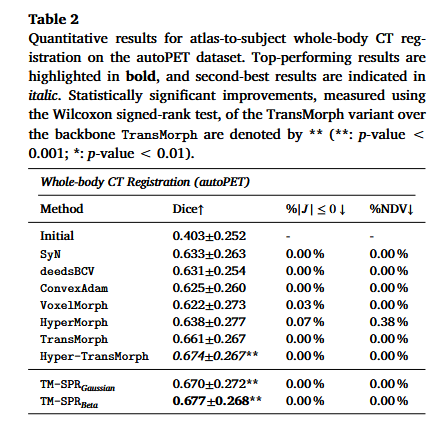
核心结论:
- 全面 SOTA: 提出的 TM-SPR (Spatially Varying Regularization) 在所有数据集上均取得了最高的 Dice 分数。
- 超越 HyperMorph: 虽然 HyperMorph 可以调节 λ\lambdaλ,但它是全局调节。TM-SPR 的体素级调节明显更优。
可视化:捕捉滑动边界
这是本文的亮点。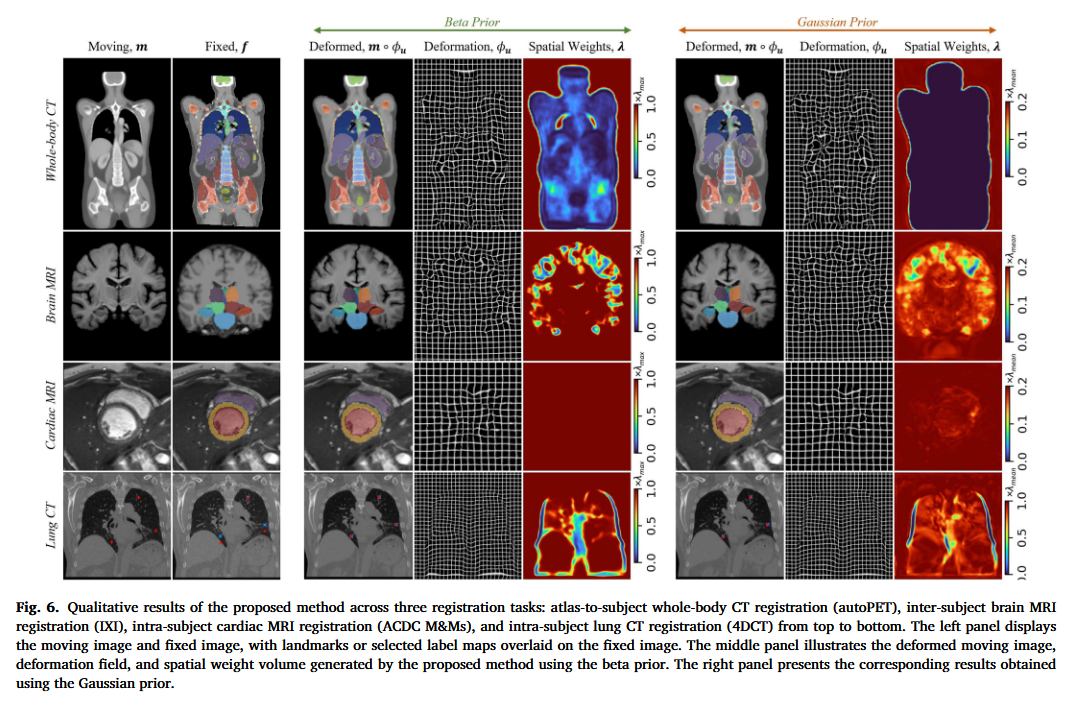
- 现象: 在肺部 4DCT 配准中,肺叶收缩而肋骨保持静止。
- 结果:
- 基线 (TransMorph): 肺部边界模糊,肋骨被错误地拉扯。
- TM-SPR (Ours): 学习到的权重图 λ(p)\lambda(\mathbf{p})λ(p) 在肺部边界处几乎为 0(深蓝色),而在肺内部和肋骨处较高。这意味着网络“自动发现”了这里需要断开联系,实现了完美的滑动运动模拟,且没有发生非物理折叠(得益于微分同胚框架)。
5. 🧠 总结与思考
优点 (Pros)
- 直击痛点: 巧妙地解决了医学图像中常见的“局部形变差异”和“滑动边界”问题,且无需任何手动标签(Label-free)。
- 高可解释性: 输出的权重图 λ(p)\lambda(\mathbf{p})λ(p) 充当了不确定性图(Uncertainty Map)。低 λ\lambdaλ 表示复杂的形变或模型不确定性,提供了额外的诊断信息。
- 工程友好: 作为即插即用模块,可以轻松添加到 VoxelMorph 或 Swin-UNet 等其他架构中。
局限性 (Limitations)
- 计算成本: 虽然推理成本可以忽略不计(仅增加一个轻量级头),但训练涉及贝叶斯优化,比训练固定参数模型成本更高。
- 超参数敏感性: 虽然使用了自动优化,但先验的选择(Beta vs. Gaussian)会影响结果,可能需要根据任务特性进行选择(例如肺部推荐 Beta Prior)。
未来展望
本文为无监督配准开辟了一条新路径:正则化不应是一个常数,而应是一个数据驱动的场。这一概念可以扩展到图像修复或病灶检测(利用正则化权重异常值来定位病灶)等其他领域。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)