西工大张伟伟等:强化学习如何练就近距空战制胜法则?| 航空学报CJA
西北工业大学航空学院“大树之家”团队由国家级领军人才张伟伟教授领衔,现有固定教师6人(包括教授4人,副教授2人),博士后2人,研究生50余人。团队承担了一批与智能流体力学、气动弹性力学、飞行器设计等方向紧密相关的科研任务,成果应用于航空航天、人工智能、能源等领域20多个头部单位的重大工程研制,为AI4Eng形成了良好示范。杨孟超(第一作者),西北工业大学航空学院获硕士学位,现为中国航空工业618所
以下文章来源于航空学报CJA,作者杨孟超,张伟伟等
原文链接:https://mp.weixin.qq.com/s/NxeHKxBDP08stMrUEwSCRQ

2025《CJA》亮点文章
近年来,国际战略竞争态势持续升级,各国空军现代化转型进程加快。智能化空战作为夺取制空权的关键,其战略价值正得到全新诠释。本文针对当前空战智能化发展的迫切需求,通过高精度飞行器动力学建模、武器系统仿真及战场环境构建,建立了高保真的近距对抗仿真平台,提出了优化的自博弈强化学习架构。通过飞行模拟设备验证,该智能决策系统在与成熟飞行员的近距格斗对抗中取得超过75%的胜率,为智能空战系统的发展提供了重要技术支撑。
论文标题:Decision-making and confrontation in close-range air combat based on reinforcement learning
论文作者:Mengchao Yang(杨孟超),Shengzhe Shan(单圣哲),Weiwei Zhang*(张伟伟*)
作者单位:西北工业大学,中国人民解放军93995部队等
出版信息:Chinese Journal of Aeronautics, 2025, https://doi.org/10.1016/j.cja.2025.103526
识别以下二维码下载论文全文

01 研究背景
人工智能技术的突破正深刻改变现代空战规则,随着战机与机载装备的升级,战场环境日趋复杂,这对智能战场感知与机动决策提出了全新挑战。美国空军早在20世纪便开始军事智能化布局,2019年启动的"空战演化"(ACE)项目更推动下一代战机向自主决策迈进;我国也明确提出加快军事智能化与无人作战能力建设,智能化战争时代已全面来临。然而,战场态势瞬息万变,加之战机机动动作灵活多变,由此产生的强非线性和强时变特性使得传统基于规则的方法难以有效应对。当前研究仍存在以下主要局限:多数工作仅基于简化的三自由度飞机模型开展控制研究,未能整合实际战机的气动特性、武器包线等关键参数,导致仿真环境与真实空战存在显著差异;其次,现有智能决策模型普遍存在决策能力不足、泛化性能有限的问题,难以应对多变的战场态势,决策也缺乏实际的指导意义;相关研究多停留在理论验证层面,仅通过特定预设场景的轨迹仿真验证算法可行性。因此,为满足辅助作战及训练指导的实际需求,需要进一步提升智能模型的决策能力,保证复杂环境下的适应性、决策的合理性及一定的可解释性,并从应用层面给出完整的解决方案。
02 研究亮点
1)针对智能体与实际战场环境的适配性问题,基于JSBSim飞行动力学模型和Unity3D引擎,构建了融合六自由度飞行动力学、武器火控系统及复杂战场环境的高保真仿真平台,平台结构如图1所示。
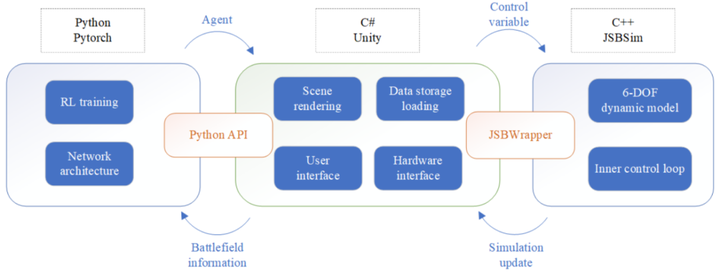
平台包含智能体决策模型、视景环境与动力学仿真模型三大部分,集成于Unity3D中。除本体动力学模型外,还建立了机载雷达、航空机炮与红外导弹模型,飞机本体通过油门与操纵杆指令进行控制,如图2所示。
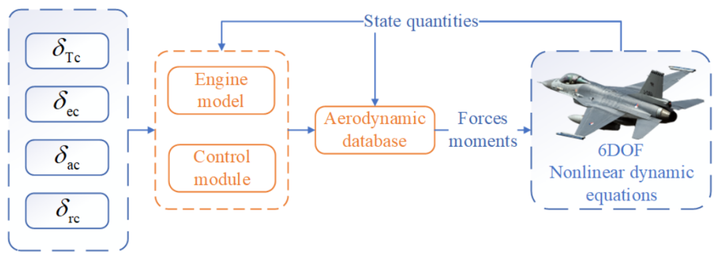
视景对战场环境、飞机模型及武器攻击包线等关键要素进行三维可视化渲染建模,支持第一人称驾驶舱视角、第三人称追踪视角以及自由漫游视角的多模式切换,实时动态呈现战场态势,如图3所示。

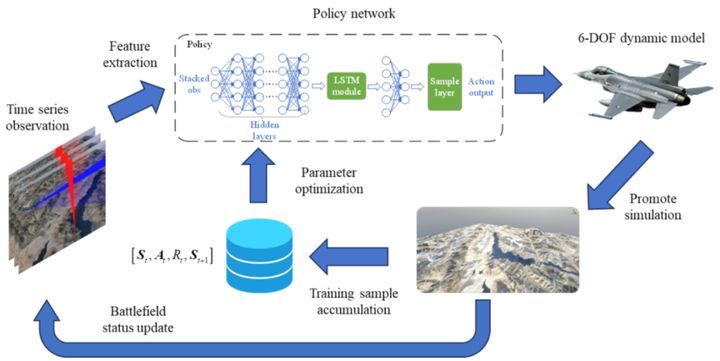
智能决策平台的工作流程如图4所示:系统采集时序战场态势观测数据作为输入,通过深度神经网络模型实时生成最优动作决策,驱动战机飞控系统及武器设备执行相应操作,更新战场态势。在训练阶段,系统会根据下一时刻的敌我态势评估指标(如能量优势、攻击角度等)计算即时奖励,并采用强化学习算法持续优化策略网络参数,最终使智能体收敛至最优战术决策策略。
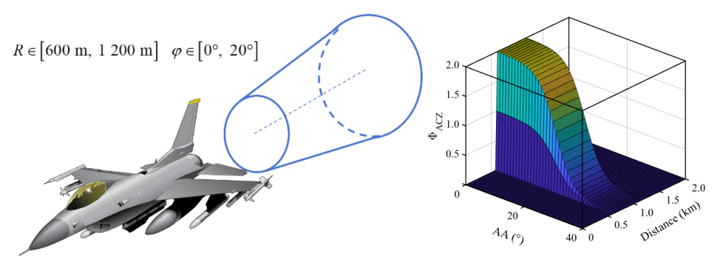
基于真实空战战术逻辑,创新性地设计了由事件(雷达探测、导弹锁定等)、引导(基于能量-角度的态势奖励,如图5)与结果(毁伤、击杀)构成的复合奖励函数,在保证决策合理性的同时提升训练的收敛性。
{Rsituation =Φ r−Φ bRevent =ν r−νbRtotal =Rsituation +Revent +Rresult
2)针对智能决策模型的决策能力、泛化性能及可解释性,从以下3个角度进行系统性优化:在强化学习环境设计方面,基于实际空战场景的战术需求,构建了多维复合奖励函数体系;在网络架构层面,融入长短时记忆与好奇心网络机制;在训练过程中,引入了基于课程学习的渐进式训练,并在自博弈架构中融入了专家策略。算法架构如图6所示。
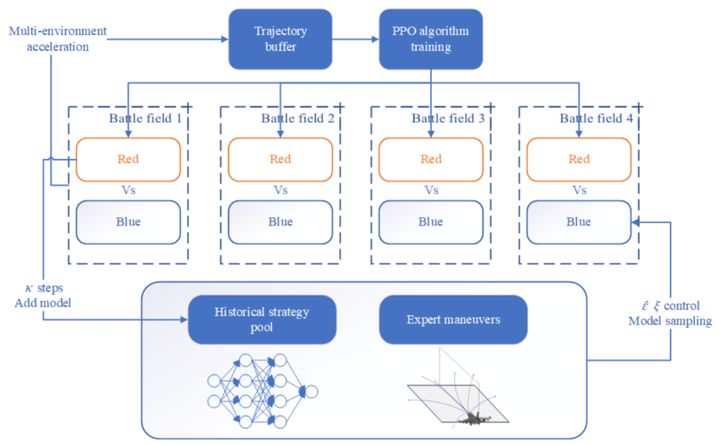
内核采用PPO算法与Actor-Critic架构,添加LSTM网络层,以适配决策的时序特性(图7)。
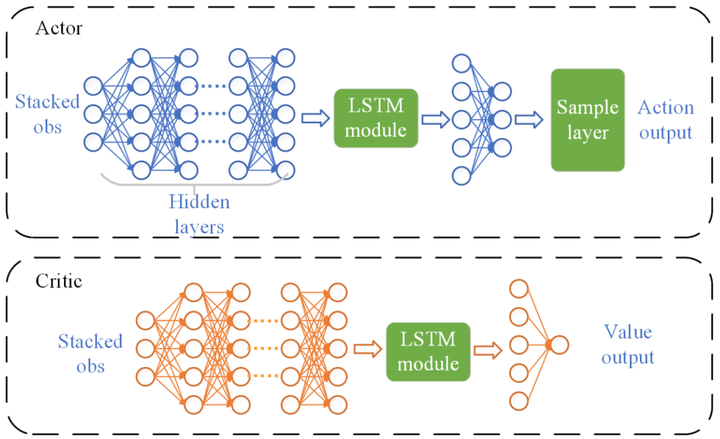
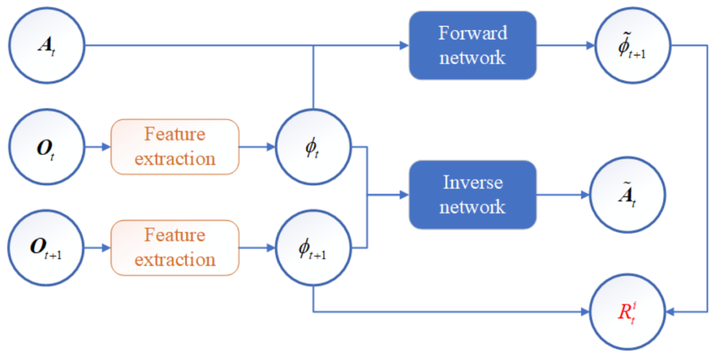
附加好奇心奖励模块,以预测状态与实际状态的差别作为附加奖励,鼓励智能体探索,实现模型决策能力与探索能力的提升(图8)。
基于课程学习架构,在训练过程中阶段性地引入战场态势、初始位置及环境参数的随机初始化,在保证训练稳定性的同时增强模型泛化能力。进一步地,在自博弈训练过程中,注入了平飞、转弯、爬升等典型程控机动策略作为基准对手,构建多模态对抗环境,既增加了训练对手多样性又一定程度上提升了网络决策的可解释性。
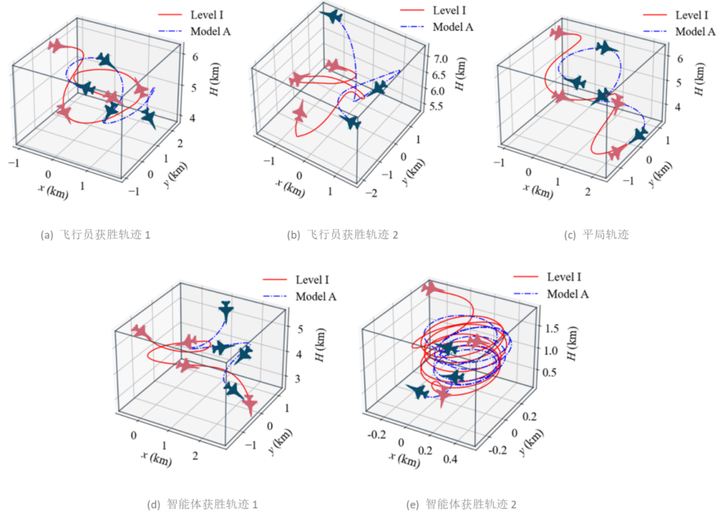
3)通过多维度实验验证了智能决策模型的有效性:首先,基于典型空战场景的仿真轨迹分析,验证了模型在机动决策、态势评估等关键环节的合理性,如图9所示;
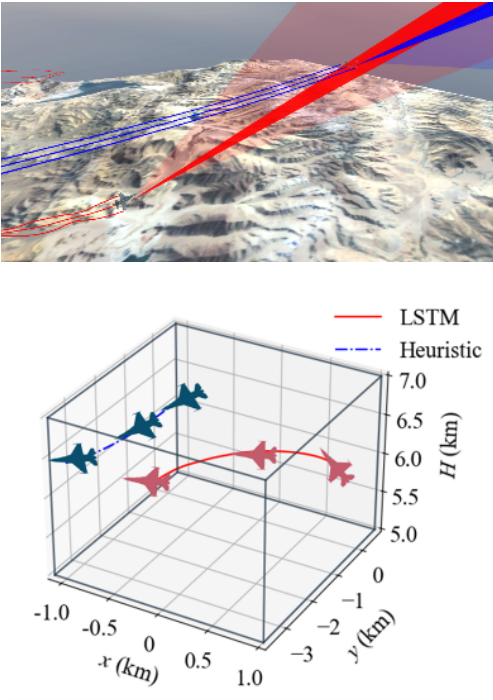
其次,通过设置不同难度等级的AI对手进行对抗测试,系统评估了模型的战术适应性和鲁棒性。
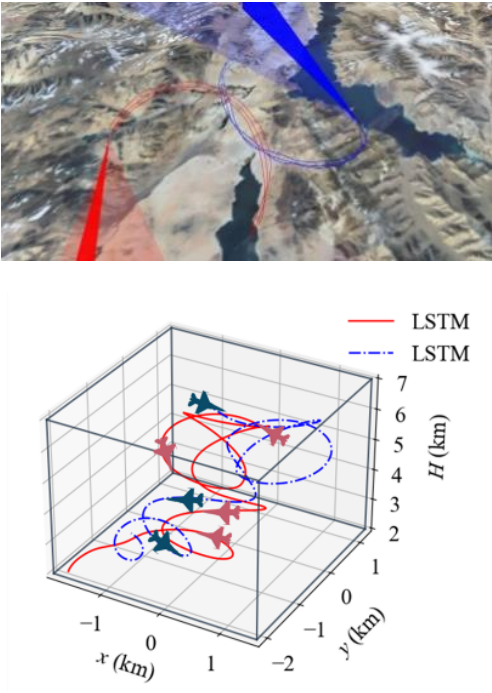
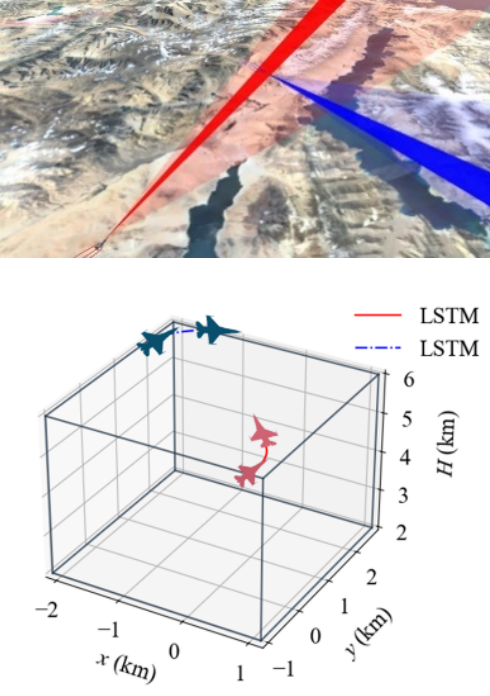
更重要的是,依托仿真平台与飞行模拟硬件设备,与某部队合作开展了实战化的人机对抗验证,由掌握熟练技能的飞行员与智能体进行多回合近距格斗对抗,结果表明所提方法能够展现出显著优势,对抗过程轨迹如图10所示(3D渲染视景动图见文末链接)。
03 研究结论
1)本文搭建了与真实战场高度适配的仿真环境,提供从算法开发、模型训练、视景渲染、仿真模拟及对抗应用验证的系统性解决方案;
2)通过引入LSTM网络与ICM模块、设计复合奖励函数、融入专家策略,分阶段开展自博弈对抗训练,有效提升了策略模型的决策与泛化能力,能够应对多场景下的复杂机动,与基本模型对抗中能够取得压倒性优势,如图11所示;
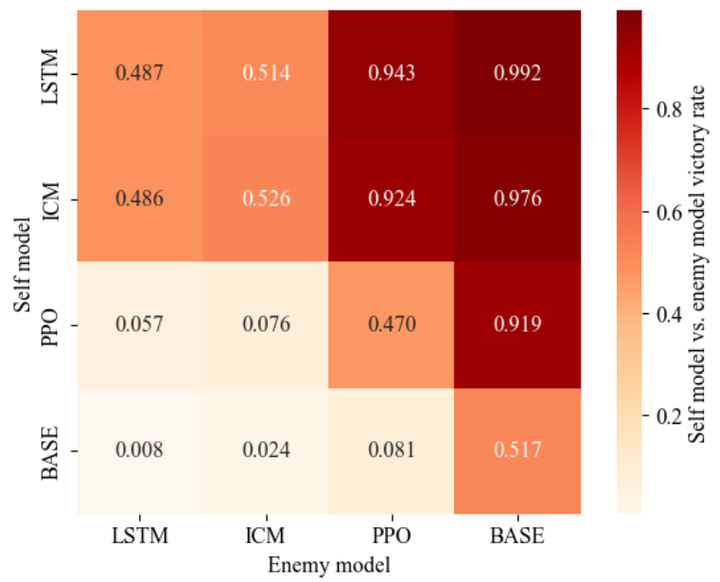
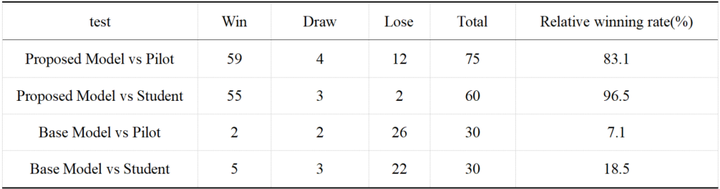
3)通过成熟飞行员参与的人机对抗验证,该智能模型展现出强大的决策能力,平均对抗胜率达75%以上,决策合理性受到认可,能够初步应用于飞行模拟训练,提升训练效率,缩短周期,降低耗费成本(表1)。
团队及作者介绍
>>团队介绍
西北工业大学航空学院“大树之家”团队由国家级领军人才张伟伟教授领衔,现有固定教师6人(包括教授4人,副教授2人),博士后2人,研究生50余人。团队承担了一批与智能流体力学、气动弹性力学、飞行器设计等方向紧密相关的科研任务,成果应用于航空航天、人工智能、能源等领域20多个头部单位的重大工程研制,为AI4Eng形成了良好示范。
>>作者介绍

杨孟超(第一作者),西北工业大学航空学院获硕士学位,现为中国航空工业618所工程师,主要从事智能空战与深度强化学习方向研究。

单圣哲,中国人民解放军93995部队。主要就智能空中作战方向展开研究,将飞行经验融入强化学习过程,使智能体“涌现”通用空战技能,为后续研究提供了范式。

张伟伟(通信作者),西北工业大学航空学院教授,国家级领军人才,中国空气动力学会副理事长。主要从事智能流体力学、气动弹性力学和飞行器智能化设计研究。主持国家级项目20余项,有力支撑了我国航空、航天、兵器等20多个单位的重大任务,为C919等重大型号研制做出贡献,获得省部级科研成果奖5项。在PAS、JFM等国内外知名刊物发表论文200余篇,撰写著作3部。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 0
0 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)