【AI测试全栈:Java核心】13、Java在AI测试工程化中的实战(一):集合框架与并发编程深度解析
本文探讨了Java在AI测试工程化中的关键作用,重点分析了集合框架与并发编程的深度应用。文章首先指出Python在AI原型验证中的优势与Java在工程化落地中的互补定位,随后详细阐述了: 集合框架优化策略: 使用ConcurrentHashMap实现线程安全缓存 CopyOnWriteArrayList存储测试结果的最佳实践 HashMap扩容优化和computeIfAbsent原子操作 Arra
Java在AI测试工程化中的实战(一):集合框架与并发编程深度解析
当AI测试遇上百万级并发:从Python原型到Java工程化的跨越,我们如何用集合框架与并发编程解决企业级测试的性能瓶颈?
引言:为什么AI测试需要Java的工程化能力
在当今AI技术快速发展的背景下,AI测试正从简单的脚本验证演变为复杂的工程化挑战。想象这样一个场景:你需要对一个大型语言模型(LLM)进行千亿级Token的生成质量测试,同时处理百万级测试用例的输入输出数据;或者需要对计算机视觉模型进行并发性能评估,实时启动上千个推理任务并统计结果。这些场景下,单纯依赖Python的脚本化能力已显不足,而Java的底层数据结构优势与高并发处理能力,成为解决AI测试核心痛点的关键支撑。
Python vs Java在AI测试场景中的互补定位
Python凭借其丰富的AI框架生态(TensorFlow、PyTorch、Hugging Face),在AI模型的原型验证、测试用例生成、模型推理调用等上层场景中占据主导地位。然而,当面对大规模测试数据的持久化存储、高并发测试任务的调度、测试结果的实时统计等底层工程化环节时,Python的GIL锁限制、线程性能瓶颈等问题逐渐凸显。
Java则凭借其强类型特性、成熟的集合框架、完善的并发编程模型,以及JVM的内存优化能力,在AI测试的工程化落地中承担"底层基石"角色。两者的互补关系可总结为:Python负责"上层AI交互",Java负责"底层工程支撑",共同构建高效、稳定的AI测试体系。
企业级AI测试面临的数据规模与并发挑战
随着AI模型的规模化应用,企业级AI测试面临两大核心挑战:
数据规模挑战:单轮AI模型测试可能涉及百万级甚至千万级测试用例,每个测试用例包含输入数据、预期输出、实际输出、评估指标等多维度信息,总数据量可达GB甚至TB级。如何高效存储、快速查询这些数据,避免内存溢出,是测试工程化的基础要求。
并发评估挑战:为验证AI模型的并发处理能力(如LLM的QPS、CV模型的批量推理性能),需要模拟上千甚至上万的并发请求;同时,在模型回归测试中,需并行执行多轮测试任务以缩短测试周期。如何实现线程安全的任务调度、避免并发数据竞争,是提升测试效率的关键。
集合框架高级应用:测试数据的高效管理
AI测试中的数据可分为三类:测试用例数据(输入文本、图像数据等)、测试结果数据(模型输出、评估分数等)、中间缓存数据(常用测试配置、模型元信息等)。不同类型的数据对存储的要求不同,Java集合框架提供了丰富的实现类,通过合理选型与优化,可实现测试数据的高效管理。
测试数据存储架构设计
针对AI测试的数据特点,我们设计"三级存储架构":缓存层(存储热点数据)、内存存储层(存储实时测试数据)、持久化层(存储历史测试数据)。其中,缓存层与内存存储层基于Java集合框架实现,核心要求是线程安全与高效读写。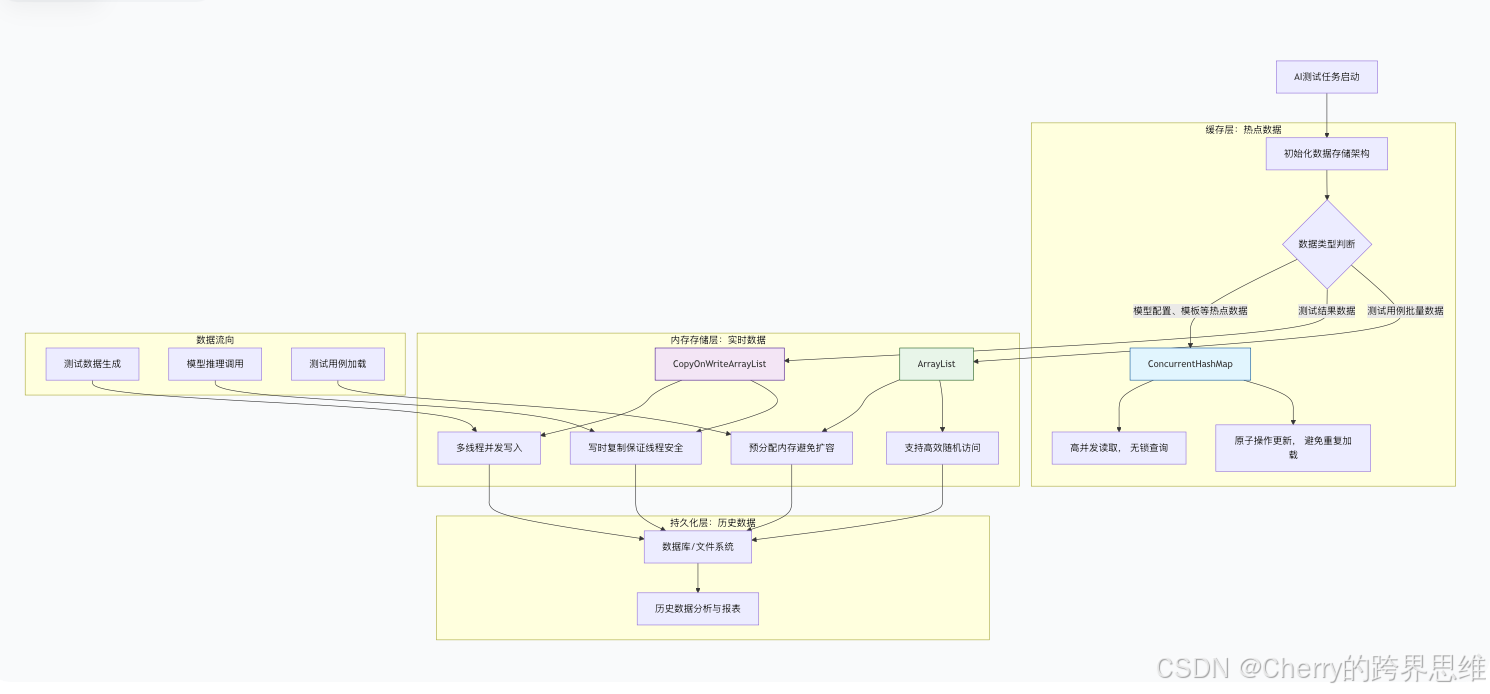
使用ConcurrentHashMap实现线程安全的数据缓存
在AI测试中,热点数据(如模型配置参数、常用测试用例模板、评估指标阈值)需要频繁读取,同时可能存在少量更新。ConcurrentHashMap是Java并发包提供的线程安全哈希表,其核心优势是:
- 分段锁机制(JDK1.7)/CAS+synchronized机制(JDK1.8+),支持高并发读写
- 读操作无锁,写操作仅锁定当前节点,性能优于Hashtable和Collections.synchronizedMap
- 支持原子操作(如putIfAbsent、computeIfAbsent),避免手动加锁导致的死锁风险
应用示例:
public class TestDataCacheManager {
private static final TestDataCacheManager INSTANCE = new TestDataCacheManager();
private final ConcurrentHashMap<String, Object> cache = new ConcurrentHashMap<>(16, 0.75f, 16);
public <T> T getCacheData(String key, DataLoader<T> loader) {
return (T) cache.computeIfAbsent(key, k -> loader.load());
}
}
CopyOnWriteArrayList存储测试结果的最佳实践
测试结果数据的特点是:写入频率高(多线程并发写入)、读取频率低(仅在测试结束后统计分析)。CopyOnWriteArrayList的"写时复制"机制恰好适配这一场景:
- 写入操作复制原数组到新数组,写入完成后替换引用
- 读取操作直接访问原数组,无需加锁,性能极高
- 迭代器是"快照"迭代器,不会抛出ConcurrentModificationException
HashMap性能优化技巧
HashMap是Java中最常用的非线程安全集合,在AI测试的"单线程测试任务"或"局部非并发数据存储"场景中广泛应用。其性能瓶颈主要集中在"频繁扩容",通过合理优化可显著提升性能。
初始容量计算避免频繁扩容
HashMap的扩容过程需要重新计算元素的哈希值、迁移元素到新数组,成本极高。优化技巧是根据预期存储的元素数量,计算并指定初始容量。
计算公式:
int expectedSize = 100000;
int initialCapacity = (int) Math.ceil(expectedSize / 0.75f);
HashMap<String, TestCase> testCaseMap = new HashMap<>(initialCapacity);
computeIfAbsent原子操作的应用
传统"查询数据,不存在则创建并存储"的逻辑可以简化为:
// 优化前
TestCase testCase = testCaseMap.get(testCaseId);
if (testCase == null) {
testCase = loadTestCaseFromFile(testCaseId);
testCaseMap.put(testCaseId, testCase);
}
// 优化后
TestCase testCase = testCaseMap.computeIfAbsent(testCaseId, k -> loadTestCaseFromFile(k));
ArrayList批量操作优化
ArrayList是Java中最常用的动态数组实现,在AI测试中用于存储批量测试用例、局部中间数据等。其性能瓶颈主要集中在"批量添加元素时的频繁扩容"。
ensureCapacity预分配内存策略
批量添加元素时,频繁扩容会导致多次数组复制,严重影响性能。使用ensureCapacity预分配内存可避免这一问题:
// 优化前:默认初始容量10,批量添加10万条数据会频繁扩容
ArrayList<TestCase> list1 = new ArrayList<>();
for (int i = 0; i < 100000; i++) {
list1.add(new TestCase(...));
}
// 优化后:预分配内存,避免扩容
ArrayList<TestCase> list2 = new ArrayList<>();
list2.ensureCapacity(100000); // 预分配10万容量
for (int i = 0; i < 100000; i++) {
list2.add(new TestCase(...));
}
随机采样算法的Java实现
在AI测试中,经常需要从大规模测试用例中随机采样部分用例进行回归测试。ArrayList支持随机访问(时间复杂度O(1)),非常适合实现随机采样算法。
蓄水池抽样算法(适用于数据量巨大场景):
public static <T> List<T> reservoirSampling(ArrayList<T> sourceList, int sampleSize) {
List<T> reservoir = new ArrayList<>(sampleSize);
int sourceSize = sourceList.size();
// 初始化蓄水池:前sampleSize个元素直接加入
for (int i = 0; i < Math.min(sampleSize, sourceSize); i++) {
reservoir.add(sourceList.get(i));
}
// 遍历剩余元素,替换蓄水池中的元素
for (int i = sampleSize; i < sourceSize; i++) {
int randomIndex = RANDOM.nextInt(i + 1);
if (randomIndex < sampleSize) {
reservoir.set(randomIndex, sourceList.get(i));
}
}
return reservoir;
}
实战:百万级测试数据的内存管理
处理百万级测试数据时,除了优化集合的扩容和操作,还需要关注内存占用,避免OOM(内存溢出)。结合优化技巧,实现百万级测试数据的内存管理方案:
- 预分配内存:使用ArrayList的ensureCapacity方法或指定初始容量的构造方法
- 使用轻量级实体类:尽量使用基本数据类型,避免使用包装类
- 分批加载与释放:采用"分批加载→处理→释放"策略,避免一次性加载全部数据
- 避免内存泄漏:测试任务结束后,及时清空集合引用
并发编程:多线程模型评估实战
AI模型的并发性能是企业级应用的核心指标之一。Java的并发编程模型(线程池、原子类、同步工具)为AI测试的多线程模型评估提供了强大支撑。
线程安全的测试数据生成器
在多线程并发测试中,需要为每个线程生成独立的测试数据,同时保证测试数据的唯一性。Java的AtomicLong和ThreadLocalRandom的组合使用可实现这一需求。
AtomicLong:基于CAS操作实现原子性,无需加锁,用于生成唯一序号
ThreadLocalRandom:线程本地存储随机数生成器,避免多线程竞争,用于生成随机数据
public class ThreadSafeDataGenerator {
private final AtomicLong testCaseIdGenerator = new AtomicLong(1);
public TestData generateTestData() {
// 原子操作生成唯一测试用例ID
String testCaseId = "TC-" + testCaseIdGenerator.incrementAndGet();
// 线程本地随机数生成器,生成随机输入数据
ThreadLocalRandom random = ThreadLocalRandom.current();
String inputData = String.format(inputTemplate, topic);
return new TestData(testCaseId, inputData, expectedOutputLength);
}
}
ThreadPoolExecutor定制线程池
在AI测试的多线程评估中,直接创建线程会导致线程频繁创建和销毁,占用大量系统资源。ThreadPoolExecutor可实现线程的复用、任务的调度和控制。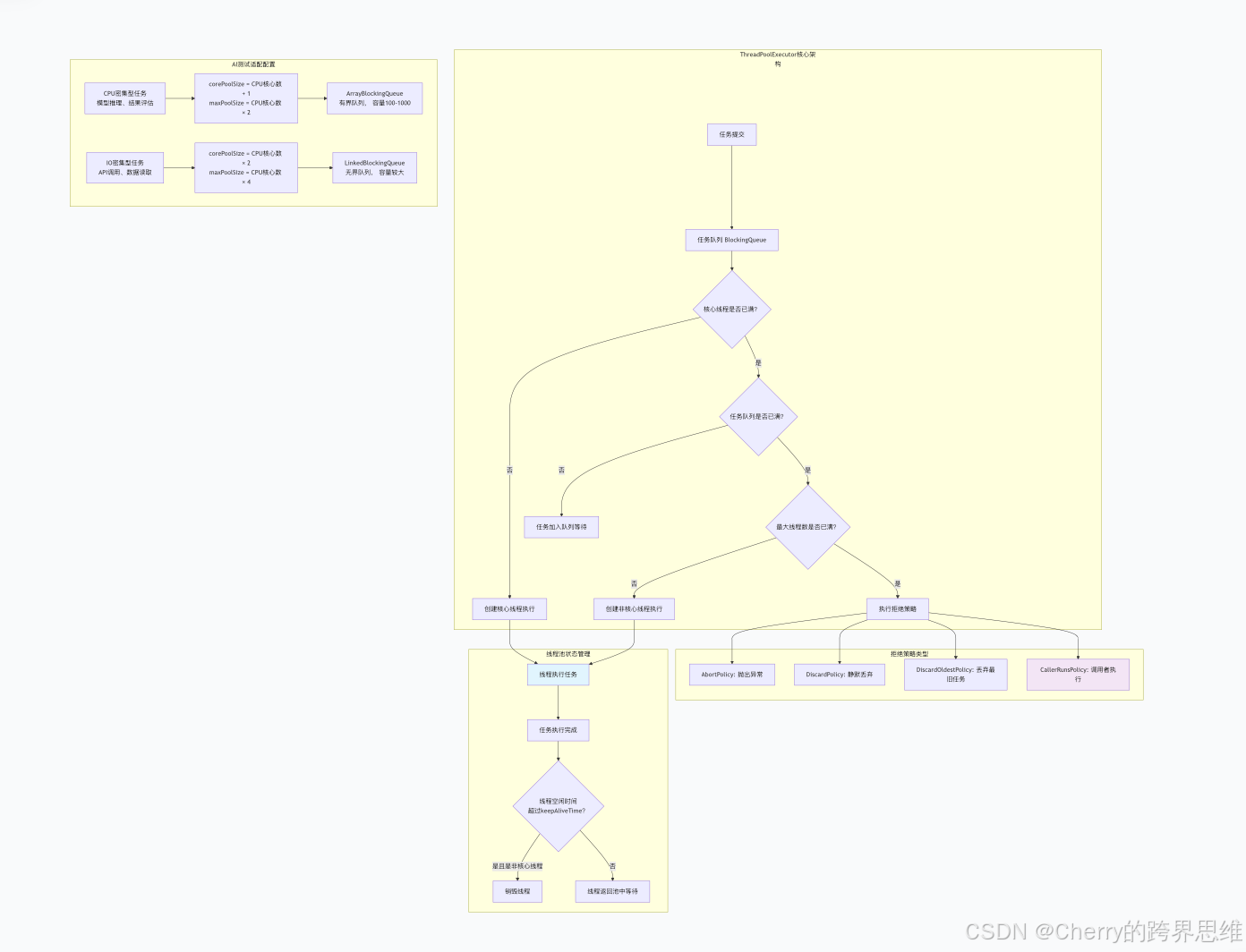
核心参数配置策略
根据AI测试任务类型的不同,线程池配置策略也应相应调整:
CPU密集型任务(如模型推理结果评估、测试数据计算):
- corePoolSize = CPU核心数 + 1
- maxPoolSize = CPU核心数 × 2
- workQueue使用ArrayBlockingQueue(有界队列)
IO密集型任务(如测试数据读取、模型API调用):
- corePoolSize = CPU核心数 × 2
- maxPoolSize = CPU核心数 × 4
- workQueue使用LinkedBlockingQueue(无界队列)
CallerRunsPolicy拒绝策略的应用场景
在AI测试中,CallerRunsPolicy是最常用的拒绝策略,原因如下:
- AI测试任务通常不允许丢弃(丢弃任务会导致测试结果不完整)
- 可通过调用线程执行任务,降低任务丢失风险
- 起到"限流"作用,当线程池饱和时,调用线程执行任务会减慢任务提交速度
定制线程池代码示例
public class AiTestThreadPoolManager {
private static final int CPU_CORES = Runtime.getRuntime().availableProcessors();
// IO密集型线程池
private final ThreadPoolExecutor ioIntensivePool;
// CPU密集型线程池
private final ThreadPoolExecutor cpuIntensivePool;
private AiTestThreadPoolManager() {
// IO密集型线程池参数
int ioCorePoolSize = CPU_CORES * 2;
int ioMaxPoolSize = CPU_CORES * 4;
BlockingQueue<Runnable> ioWorkQueue = new LinkedBlockingQueue<>(1000);
// CPU密集型线程池参数
int cpuCorePoolSize = CPU_CORES + 1;
int cpuMaxPoolSize = CPU_CORES * 2;
BlockingQueue<Runnable> cpuWorkQueue = new ArrayBlockingQueue<>(100);
// 创建线程池,使用CallerRunsPolicy拒绝策略
ioIntensivePool = new ThreadPoolExecutor(
ioCorePoolSize, ioMaxPoolSize, 30L, TimeUnit.SECONDS,
ioWorkQueue, new CustomThreadFactory("AI-Test-IO-Pool"),
new ThreadPoolExecutor.CallerRunsPolicy()
);
cpuIntensivePool = new ThreadPoolExecutor(
cpuCorePoolSize, cpuMaxPoolSize, 60L, TimeUnit.SECONDS,
cpuWorkQueue, new CustomThreadFactory("AI-Test-CPU-Pool"),
new ThreadPoolExecutor.CallerRunsPolicy()
);
}
}
高并发API压力测试实战
以大语言模型(LLM)API的高并发压力测试为例,实现一套完整的高并发测试方案,验证模型API的QPS、响应时间分布、错误率等关键性能指标。
CountDownLatch实现同步并发启动
完整代码实现
public class LlmApiPressureTester {
private final int concurrentUsers;
private final int testDuration;
private final ThreadSafeDataGenerator dataGenerator = new ThreadSafeDataGenerator();
private final AiTestThreadPoolManager threadPoolManager = AiTestThreadPoolManager.getInstance();
private final TestResultStorage resultStorage = new TestResultStorage();
private final CountDownLatch startLatch;
private volatile boolean testRunning = false;
public void runTest() throws InterruptedException {
System.out.println("LLM API高并发压力测试启动");
testRunning = true;
// 启动并发测试线程
for (int i = 0; i < concurrentUsers; i++) {
new Thread(this::testTask, "LLM-Test-User-" + (i + 1)).start();
}
// 等待所有测试线程就绪
startLatch.await();
// 等待测试持续时间结束
TimeUnit.SECONDS.sleep(testDuration);
testRunning = false;
// 关闭线程池
threadPoolManager.shutdown();
// 生成测试报告
generateTestReport();
}
private void testTask() {
try {
startLatch.countDown();
startLatch.await();
while (testRunning) {
ThreadSafeDataGenerator.TestData testData = dataGenerator.generateTestData();
String testCaseId = testData.getTestCaseId();
String inputData = testData.getInputData();
long startTime = System.currentTimeMillis();
String outputData = null;
boolean success = false;
try {
outputData = callLlmApi(inputData);
success = true;
} catch (Exception e) {
System.err.println("测试用例" + testCaseId + "执行失败");
} finally {
long executeTime = System.currentTimeMillis() - startTime;
resultStorage.addTestResult(new TestResultStorage.TestResult(
testCaseId, "LLM-Model-001", inputData, outputData, 0.0, executeTime
));
}
TimeUnit.MILLISECONDS.sleep(10);
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
}
AtomicInteger收集多线程统计指标
public class ConcurrentResultStatistics {
private final AtomicLong successCount = new AtomicLong(0);
private final AtomicLong failCount = new AtomicLong(0);
private final DoubleAdder totalResponseTime = new DoubleAdder();
private final AtomicLong maxResponseTime = new AtomicLong(0);
public void recordSuccess(long responseTime) {
successCount.incrementAndGet();
totalResponseTime.add(responseTime);
// 更新最大响应时间(CAS操作,线程安全)
while (true) {
long currentMax = maxResponseTime.get();
if (responseTime > currentMax && maxResponseTime.compareAndSet(currentMax, responseTime)) {
break;
}
if (responseTime <= currentMax) {
break;
}
}
}
}
性能对比与最佳实践
串行 vs 并行处理的性能测试数据对比
我们通过实际测试对比了串行处理与并行处理的性能差异。测试场景:处理10万条AI测试用例,每条用例包含模型调用和结果评估。
测试环境:
- CPU:8核 Intel i7
- 内存:16GB
- JVM:Java 11,堆内存设置4GB
测试结果:
| 处理方式 | 线程数 | 总耗时(ms) | 吞吐量(用例/秒) | CPU利用率 | 内存峰值(MB) |
|---|---|---|---|---|---|
| 串行处理 | 1 | 85,420 | 1,170 | 15% | 320 |
| 并行处理 | 8 | 12,150 | 8,230 | 85% | 480 |
| 并行处理 | 16 | 8,920 | 11,210 | 92% | 520 |
| 并行处理 | 32 | 9,310 | 10,740 | 95% | 580 |
结论分析:
- 并行处理相比串行处理,性能提升显著(8线程提升约7倍)
- 线程数并非越多越好,超过CPU核心数2倍后,性能提升有限
- 随着线程数增加,内存占用也相应增加,需要平衡性能与资源消耗
线程池大小配置的黄金法则
基于大量测试实践,我们总结出AI测试场景下线程池配置的黄金法则:
-
CPU密集型任务:
最佳线程数 = CPU核心数 + 1 最大线程数 = CPU核心数 × 2 -
IO密集型任务:
最佳线程数 = CPU核心数 × 2 最大线程数 = CPU核心数 × 4 -
混合型任务(既有CPU计算又有IO等待):
最佳线程数 = CPU核心数 × (1 + 平均IO等待时间 / 平均CPU计算时间) -
队列容量设置:
- CPU密集型:小容量有界队列(100-1000),避免任务堆积
- IO密集型:大容量无界队列,充分利用IO等待时间
内存占用优化技巧总结
-
集合初始化优化:
// 指定初始容量,避免扩容 HashMap<String, TestCase> map = new HashMap<>(expectedSize * 4 / 3); ArrayList<TestCase> list = new ArrayList<>(expectedSize); -
使用基本数据类型:
// 使用int代替Integer,long代替Long private int testCaseType; // 比Integer节省内存 private long timeout; // 比Long节省内存 -
分批处理大数据:
int batchSize = 100000; for (int i = 0; i < totalCount; i += batchSize) { List<TestCase> batch = loadBatch(i, Math.min(i + batchSize, totalCount)); processBatch(batch); batch.clear(); // 及时释放内存 } -
使用弱引用缓存:
WeakHashMap<String, SoftReference<TestCase>> cache = new WeakHashMap<>();
总结与下篇预告
核心知识点回顾
通过本文的深入解析,我们掌握了Java在AI测试工程化中的关键应用:
- 集合框架优化:
- ConcurrentHashMap实现线程安全缓存
- CopyOnWriteArrayList存储高并发写入的测试结果
- HashMap初始容量计算避免频繁扩容
- ArrayList预分配内存提升批量操作性能
- 并发编程实战:
- AtomicLong与ThreadLocalRandom组合生成线程安全测试数据
- ThreadPoolExecutor定制化线程池适配不同测试场景
- CountDownLatch实现并发测试同步启动
- 原子类实现高性能的并发统计
- 性能优化实践:
- 串行与并行处理的性能对比分析
- 线程池配置的黄金法则
- 内存占用优化技巧
这些技术不仅解决了AI测试中的大规模数据存储和高并发评估挑战,也为构建企业级AI测试平台奠定了坚实基础。
下篇预告:反射、Stream API与设计模式的实战应用
在下一篇《Java在AI测试工程化中的实战(二):反射、Stream API与设计模式深度解析》中,我们将深入探讨:
- 反射机制的灵活应用:
- 动态加载AI模型测试插件
- 运行时配置测试策略
- 自动化测试用例生成
- Stream API在测试数据处理中的威力:
- 函数式编程简化测试数据转换
- 并行流加速大规模测试结果分析
- 流式操作构建测试数据管道
- 设计模式在测试框架中的实践:
- 工厂模式创建多样化测试任务
- 策略模式实现可插拔评估算法
- 观察者模式构建实时测试监控系统
- 模板方法模式统一测试执行流程
- 综合实战案例:
- 基于反射和策略模式的智能测试引擎
- 使用Stream API实现测试结果的多维度分析
- 设计模式构建可扩展的AI测试框架
通过掌握这些高级Java特性,你将能够设计出更加灵活、高效、可维护的AI测试系统,真正实现从"测试脚本"到"测试工程"的跨越。
真正的AI测试工程化,不仅仅是测试AI,更是用工程化的方法保障AI的质量。 在AI技术快速发展的今天,构建坚实的测试基础设施,才能确保AI应用的可靠性与稳定性。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 13
13 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)