Model大模型接口
LangChain是一个支持集成多种大语言模型的工具框架,主要包括LLM(文本生成)、ChatModel(对话模型)和Embeddings(文本向量)三类模型。它通过标准化的接口和参数(如temperature、max_tokens等)统一调用方式,支持OpenAI、DeepSeek、Ollama等第三方模型。使用前需配置API密钥环境变量,通过python-dotenv加载密钥。LangChai
文章目录
Model介绍
一个 AI 应用的核心就是它所依赖的大语言模型,LangChain作为一个“工具”,不提供任何 LLMs,而是依赖于第三方集成各种大模型。比如,将 OpenAI、Anthropic、Hugging Face 、LlaMA、阿里Qwen、ChatGLM等平台的模型无缝接入到你的应用。
LangChain 模型接口可参考官方文档:https://reference.langchain.com/python/langchain_core/language_models/
Model的分类
LangChain中将大语言模型分为以下几种,我们主要使用的是聊天模型:
| 模型类型 | 输入形式 | 输出形式 | 主要特点 | 典型适用场景 |
|---|---|---|---|---|
| LLM(Large Language Model) | 纯文本字符串 | 文本字符串 | 1. 最基础的文本生成模型 2. 无上下文记忆 3. 高速、轻量 |
1. 单轮问答 2. 摘要生成 3. 文本改写/扩写 4. 指令执行(Instruct 模型) |
| ChatModel(聊天模型) | 消息列表(List[BaseMessage])包括 HumanMessage, SystemMessage, AIMessage等 | 聊天消息对象(AIMessage) | 1. 面向对话场景 2. 支持多轮上下文 3. 更贴近人类对话逻辑 |
1. 智能助手 2. 客服机器人 3. 多轮推理任务 4. LangChain Agent 工具调用 |
| Embeddings(文本向量模型) | 文本字符串或列表(str 或 List[str]) | 向量(List[float] 或 ndarray) | 1. 将文本转化为语义向量 2. 可用于相似度搜索 3. 通常不生成文本 |
1. 文本检索增强(RAG) 2. 知识库问答 3. 聚类 / 分类 / 推荐系统 |
Model 继承关系
在 LangChain 的类结构中,顶层基类是 BaseLanguageModel,用于定义模型的通用接口。它分为两支:BaseChatModel 和 BaseLLM。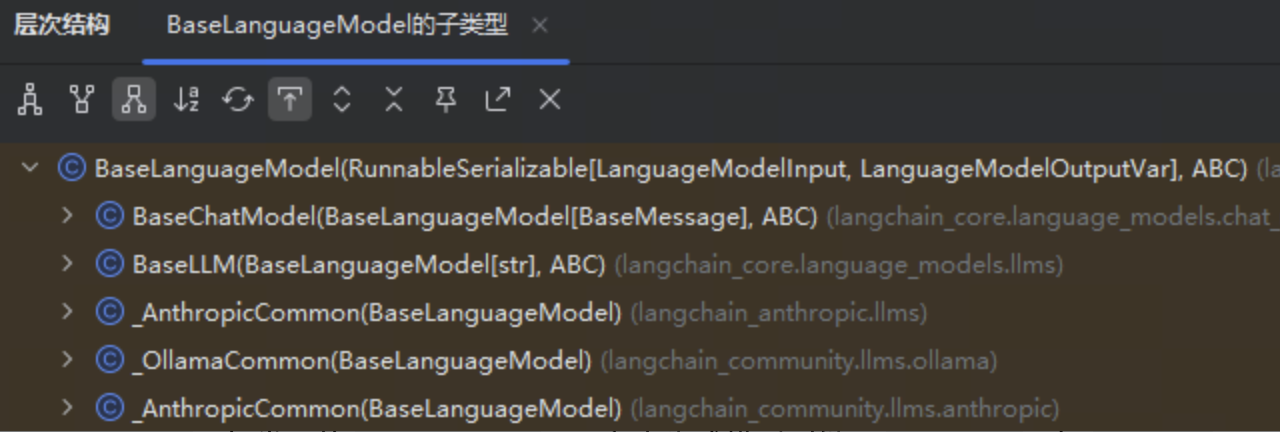
接入聊天模型时需继承 BaseChatModel,如常用的 ChatOpenAI;而文本生成模型则继承 BaseLLM,如 OpenAI。
Chat Model 主要参数
在构建聊天模型时,有一些标准化参数:
| 参数名 | 参数含义 |
|---|---|
| model | 指定使用的大语言模型名称(如 “gpt-4”、“gpt-3.5-turbo” 等) |
| temperature | 温度,温度越高,输出内容越随机;温度越低,输出内容越确定 |
| timeout | 请求超时时间 |
| max_tokens | 生成内容的最大token数 |
| stop | 模型在生成时遇到这些“停止词”将立刻停止生成,常用于控制输出的边界。 |
| max_retries | 最大重试请求次数 |
| api_key | 大模型供应商提供的API秘钥 |
| base_url | 大模型供应商API 请求地址 |
以上的标准参数,也只是适用于部分的大语言模型,有些参数在特定模型中可能是无效的,这些标准化参数仅对 LangChain 官方提供集成包的模型(如 langchain-openai、langchain-anthropic)生效,在langchain-community包中的第三方模型,则不需要遵守这些标准化参数的规则。
Message组件
调用模型后返回了一条AI消息,在LangChain中,消息有几种不同的类型。所有消息都有 type 、 content 、 response_metadata 等属性。
下面是这几个属性的作用:
| 属性名 | 属性作用 |
|---|---|
| type | 描述了是哪个类型的消息,包含类型有"user"、“ai”、“system” 和 “tool” |
| content | 通常是字符串,有些情况下可能是字典列表,这个字典列表用于大模型的多模态输出。 |
| name | 用来区分当消息类型相同,对消息进行区分,但不是所有模型都支持这一功能。 |
| response_metadata | AI消息才会包含的属性,大语言模型的响应中附加元数据,根据不同模型会有不同,如可能会包含本次 token 使用量等信息。 |
| tool_calls | AI消息才会包含的属性,当大语言模型决定调用工具时,在 AIMessage 中就会包含这个属性,可以通过 .tool_calls 属性进行获取该属性返回一个 ToolCall 列表,每个 ToolCall 是一个字典,包含以下字段: name:应调用的工具名 args: 调用工具的参数 id: 工具调用的唯一标识 ID |
创建密钥环境变量
# touch .env
.env 文件内容如下
DEEPSEEK_API_KEY=XXXX
QWEN_API_KEY=XXXX
OPENAI_API_KEY=XXX
通过 python-dotenv 库读取 env 文件中的环境变量,并加载到当前运行的环境中,代码如下:
import os
from dotenv import load_dotenv
load_dotenv(override=True)
deepseek_api_key = os.getenv("DEEPSEEK_API_KEY")
print(deepseek_api_key) # 可以通过打印查看
接入大模型
接入 Ollama
参考文档:https://python.langchain.com/docs/integrations/chat/ollama/
from langchain_ollama import ChatOllama
# 设置本地模型,不使用深度思考
model = ChatOllama(base_url="http://localhost:11434", model="qwen3:14b", reasoning=False)
# 打印结果
print(model.invoke("什么是LangChain?"))

接入 deepseek
参考文档:https://python.langchain.com/api_reference/deepseek/chat_models/langchain_deepseek.chat_models.ChatDeepSeek.html
申请地址:https://platform.deepseek.com/
支持模型列表
- deepseek-chat:通用对话模型
- deepseek-coder:偏向代码理解与生成
- deepseek-llm:较大通用模型(如 DeepSeek-VL)
- deepseek-moe:Mixture of Experts 多专家模型
import os
from dotenv import load_dotenv
from langchain_deepseek import ChatDeepSeek
load_dotenv(override=True)
deepseek_api_key = os.getenv("DEEPSEEK_API_KEY")
# 初始化 deepseek
model = ChatDeepSeek(
model="deepseek-chat",
temperature=0,
max_tokens=None,
timeout=None,
max_retries=2,
api_key=deepseek_api_key,
)
# 打印结果
print(model.invoke("什么是LangChain?"))
接入通义千问
参考文档:https://python.langchain.com/api_reference/community/chat_models/langchain_community.chat_models.tongyi.ChatTongyi.html
申请地址:https://dashscope.console.aliyun.com/overview
import os
from dotenv import load_dotenv
from langchain_community.chat_models import ChatTongyi
load_dotenv(override=True)
qwen_api_key = os.getenv("QWEN_API_KEY")
# 初始化 deepseek
model = ChatTongyi(
model="deepseek-chat",
temperature=0,
max_tokens=None,
timeout=None,
max_retries=2,
api_key=qwen_api_key,
)
# 打印结果
print(model.invoke("什么是LangChain?"))
接入 openAI
参考文档:https://python.langchain.com/docs/integrations/chat/
申请地址:https://platform.openai.com/account/api-keys
需要注意的是国内网络原因不能直接调用,可以通过第三方平台调用。例如https://closeapi.net/
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage
load_dotenv(override=True)
openai_api_key = os.getenv("OPEN_API_KEY")
model = ChatOpenAI(
api_key=openai_api_key,
model="gpt-4", # 或者 gpt-3.5-turbo
temperature=0.3, # 可调
)
# 打印结果
print(model.invoke("什么是LangChain?"))
模型调用方法
对话模型
聊天模型,除了将字符串作为输入外,还可以使用聊天消息作为输入,并返回聊天消息作为输出。LangChain有一些内置的消息类型:
- HumanMessage:人类消息,type为"user",表示来自用户输入。比如“实现 一个快速排序方法”。
- AIMessage: AI 消息,type为"ai",这可以是文本,也可以是调用工具的请求。
- SystemMessage:系统消息,type为"system",告诉大模型当前的背景是什么,应该如何做,并不是所有模型提供商都支持这个消息类型
- ToolMessage/FunctionMessage:工具消息,type为"tool",用于函数调用结果的消息类型
- ChatMessage:可以自定义角色的通用消息类型。
from langchain_core.messages import SystemMessage, HumanMessage
from langchain_ollama import ChatOllama
# 设置本地模型,不使用深度思考
model = ChatOllama(base_url="http://localhost:11434", model="qwen3:14b", reasoning=False)
# 构建消息列表
messages = [SystemMessage(content="你叫小liang,是一个乐于助人的人工助手"),
HumanMessage(content="你是谁")
]
# 调用大模型
response = model.invoke(messages)
# 打印结果
print(response.content)
print(type(response))
流式输出
在Langchain中,语言模型的输出分为了两种主要的模式:流式输出与非流式输出。
- 非流式输出:这是Langchain与LLM交互时的默认行为,是最简单、最稳定的语言模型调用方式。当用户发出请求后,系统在后台等待模型生成完整响应,然后一次性将全部结果返回。
举例:用户提问,请编写一首诗,系统在静默数秒后突然弹出了完整的诗歌。(体验较单调)
在大多数问答、摘要、信息抽取类任务中,非流式输出提供了结构清晰、逻辑完整的结果,适合快速集成和部署。
- 流式输出:一种更具交互感的模型输出方式,用户不再需要等待完整答案,而是能看到模型逐个token 地实时返回内容。
举例:用户提问,请编写一首诗,当问题刚刚发送,系统就开始一字一句(逐个token)进行回复,感觉是一边思考一边输出。更像是“实时对话”,更为贴近人类交互的习惯,更有吸引力。适合构建强调“实时反馈”的应用,如聊天机器人、写作助手等。
Langchain 中通过设置 stream=True 并配合 回调机制 来启用流式输出。
通过 model.stream 方法即可实现流式调用,代码如下:
from langchain_core.messages import SystemMessage, HumanMessage
from langchain_ollama import ChatOllama
# 设置本地模型,不使用深度思考
model = ChatOllama(base_url="http://localhost:11434", model="qwen3:14b", reasoning=False)
# 构建消息列表
messages = [SystemMessage(content="你叫小liang,是一个乐于助人的人工助手"),
HumanMessage(content="你是谁")
]
# 流式调用大模型
response = model.stream(messages)
# 流式打印结果
for chunk in response:
print(chunk.content, end="",flush=True) # 刷新缓冲区 (无换行符,缓冲区未刷新,内容可能不会立即显示)
print("\n")
print(type(response))
批量调用
LangChain 支持 批量调用(Batch Inference),也就是一次性向模型提交多个输入并并行处理,从而显著提升吞吐量。
当你需要让模型处理多条输入时,比如:文本摘要批量生成、多轮任务预处理逐条 .invoke() 会导致网络请求多次、速度慢、成本高等问题,而LangChain 提供的 .batch() 接口 能在内部自动并行执行。
代码如下:
from langchain_ollama import ChatOllama
# 设置本地模型,不使用深度思考
model = ChatOllama(base_url="http://localhost:11434", model="qwen3:14b", reasoning=False)
# 问题列表
questions = [
"什么是LangChain?",
"Python的生成器是做什么的?",
"解释一下Docker和Kubernetes的关系"
]
# 批量调用大模型
response = model.batch(questions)
for q, r in zip(questions, response):
print(f"问题:{q}\n回答:{r}\n")
异步调用
LangChain 提供 ainvoke() 异步调用接口,用于在 异步环境(async/await) 中高效并行地执行模型推理。
它的核心作用是:让你同时调用多个模型请求而不阻塞主线程 —— 特别适合大批量请求或 Web 服务场景(如 FastAPI)。
代码如下
import asyncio
from langchain_ollama import ChatOllama
# 设置本地模型,不使用深度思考
model = ChatOllama(base_url="http://localhost:11434", model="qwen3:14b", reasoning=False)
async def main():
# 异步调用一条请求
response = await model.ainvoke("解释一下LangChain是什么")
print(response)
# 运行异步程序的入口点
asyncio.run(main())

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 28
28 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)