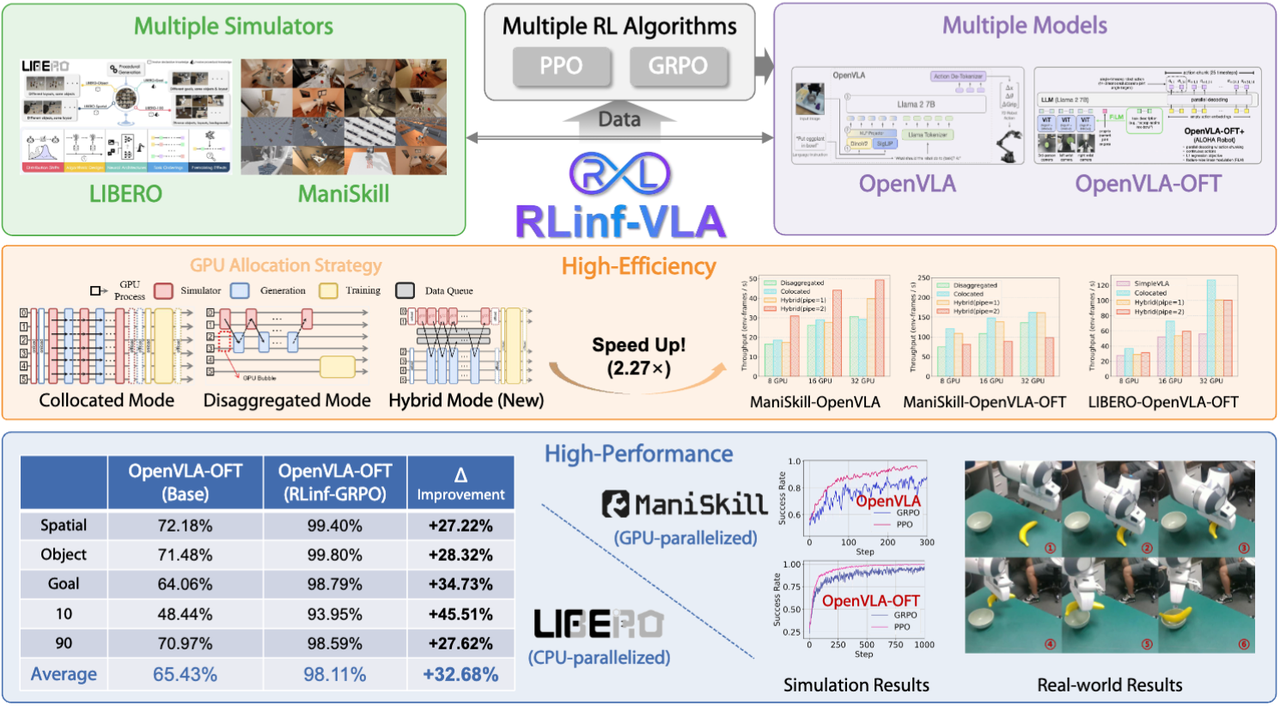
统一高效VLA+RL训练平台RLinf-VLA!
如图2所示,VLA+RL训练流程可以分为2个部分(Rollout 和 Training),其中涉及3个三个组件:分别是红色的 Simulator(仿真器)、蓝色的 Generation(模型生成)、黄色的 Training(模型训练)。其中在 Rollout 阶段,Simulator 和 Generation 多步交互,对资源调度提出新挑战。具体而言,不同的仿真器所占用的资源是不同的。
😃 引言
前段时间清华大学推出了首个面向具身智能的大规模强化学习框架 RLinf(中文介绍:https://mp.weixin.qq.com/s/Xtv4gDu3lhDDGadLrzt6Aw,论文链接:https://arxiv.org/abs/2509.15965),之前主要是从系统设计的角度出发,介绍RLinf极度灵活的系统设计思想。最近,团队加班加点,终于出炉了RLinf系统中关于VLA+RL部分的算法技术报告(简写为 RLinf-VLA,论文链接:https://arxiv.org/pdf/2510.06710 )。简单来说,RLinf-VLA提供了一个统一、高效的平台用于VLA+RL的研究。(1)“快”:系统级优化方案使得吞吐量比基线平台提升2.27倍;(2)“多”:支持大规模多任务强化学习训练,所得到的单个模型可以在 LIBERO 所有130个任务中取得平均98.11%的成功率;(3)“好”:系统阐述了具身大模型时代应用PPO和GRPO算法的设计思路和最佳实践。
🌏 性能快览版
当前已经有一些研究工作开展VLA+RL的相关研究,从不同维度展示了这种技术路线的潜力。然而,这些研究大多仅采用某一个模型、某一种算法或者只在小规模任务下进行实验,缺少对不同算法设计、不同模型的全面系统分析。同时大模型时代的RL Infra上手难度高,算力昂贵,成为算法研究人员的主要瓶颈。RLinf-VLA正是为解决这样的开发困境而出现的,RLinf-VLA的主要特点是“统一”和“高效”。
- “统一”:(1)多仿真器支持:支持 LIBERO 和 ManiSkill。RLinf-VLA 选择首先支持这两个仿真器的原因是他们代表了两类典型的具身仿真器设计思路:CPU 并行(LIBERO)和GPU并行(ManiSkill)。针对这两类典型的仿真器,RLinf 提出了一系列系统级优化手段,高效解决仿真中开展VLA+RL训练的“仿训推一体化”难题。其他类别仿真器都可以采取类似的思路进行系统化集成和优化。(2)多 VLA 模型支持:采用统一接口支持两种主流的模型 OpenVLA 和 OpenVLA-OFT,能够一键切换 LoRA 微调/全量微调,减少模型适配工作量。(3)多 RL 算法支持:支持具身版本 PPO 和 GRPO 两种主流强化学习算法。
- “高效”:RLinf-VLA 在系统与算法两个层面针对效率进行了优化。系统层面,仅通过YAML文件就可以灵活切换3种分配模式,与基线框架相比,系统吞吐量提升高达 2.27倍。特别地,在采用GPU并行仿真器的情况下,创新的混合细粒度流水机制可加速1.61×–1.88× 的吞吐量。算法层面,RLinf-VLA引入了多项设计优化,包括轻量化critic、轨迹长度归一化、动作掩码以及过滤机制等,显著提升了训练效率。
我们通过大量的实验验证了RLinf-VLA的效果。在仿真环境中,单个统一模型在 130 个 LIBERO 任务 上首次达到了 98.11% 的成功率,并在 25 个 ManiSkill pick&place任务 上取得了 97.66% 的成功率。在真实的 Franka 机械臂 上展示了初步部署结果:与基于 SFT 训练的策略相比,RL 训练的策略在零样本(zero-shot)泛化能力上表现更强。更重要的是,技术报告提炼了一系列 VLA+RL 训练的最佳实践,例如:
- PPO:在使用动作块(action chunks)时,基于动作级(action-level)的价值估计优于基于块级(chunk-level)的估计;此外,部分重置(partial resets)可显著提升采样效率。
- GRPO:轨迹长度归一化(trajectory-length normalization)与动作掩码(action masking)是稳定训练的关键。
- 通用实践:更大的 rollout 批量规模通常有助于性能提升;LoRA 虽可能不直接影响性能,但往往需要重新调整超参数。
⚙️ 详细介绍版
1. 系统设计
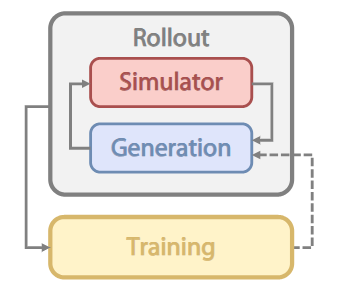
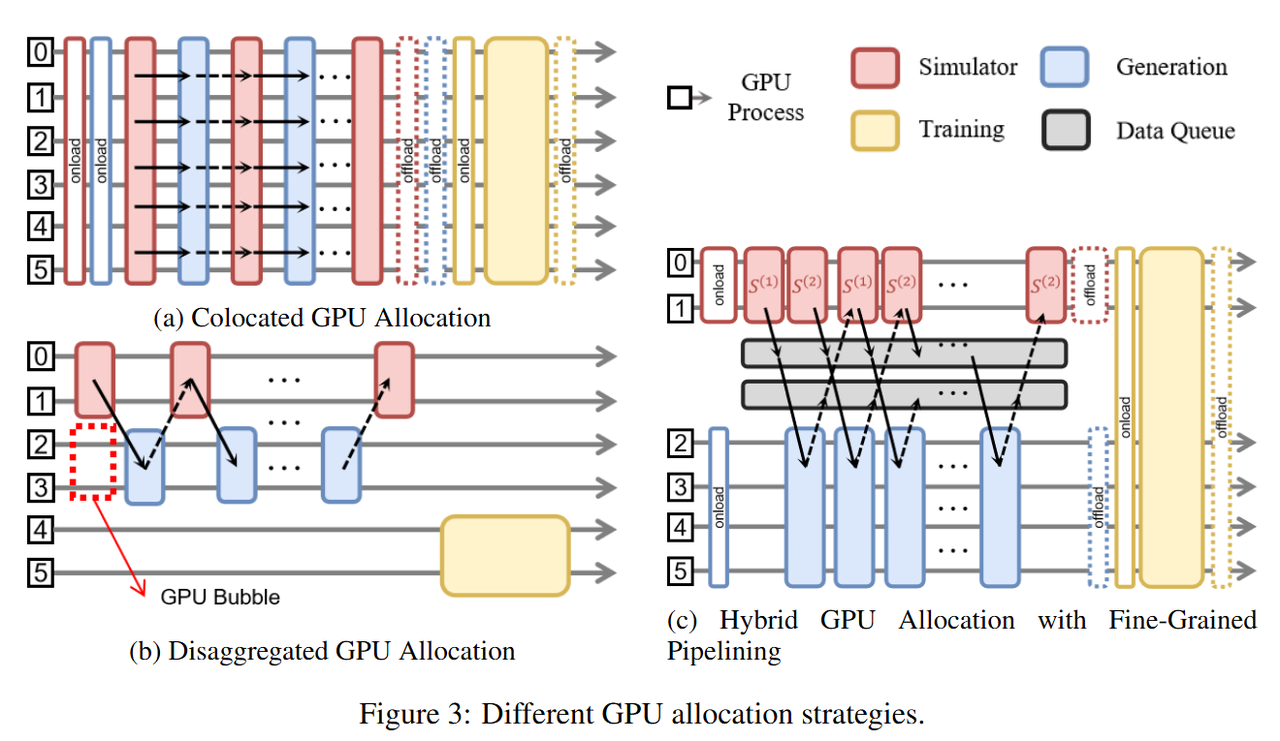
如图2所示,VLA+RL训练流程可以分为2个部分(Rollout 和 Training),其中涉及3个三个组件:分别是红色的 Simulator(仿真器)、蓝色的 Generation(模型生成)、黄色的 Training(模型训练)。其中在 Rollout 阶段,Simulator 和 Generation 多步交互,对资源调度提出新挑战。具体而言,不同的仿真器所占用的资源是不同的。对于 LIBERO 这类 CPU 并行的任务,其并行环境数量被节点 CPU 总数限制,因此 GPU 显存相对富余,可以更多调度给模型 Generation 。对于 ManiSkill 这类 GPU 并行的任务,其并行环境数量则主要由显存限制。因此需要精细调整分配给仿真器和模型的 GPU 资源。为了能够灵活地调度资源,RLinf-VLA提供了共享式、分离式、混合式三类 GPU 调度模式,并在混合式支持细粒度流水设计,如图3所示。
在 RLinf-VLA 中,只需要简单修改行 YAML 的几个配置即可在多种调度模式之间任意切换: 对于 Simulator, Generation 和 Training 三个组件的 GPU 的分配,只需在 cluster.component_placement 下分别设置想要使用的 GPU ID;对于混合式中流水线的配置,将 Simulator 分成 k 个实例,可将该超参配置为 rollout.pipeline_stage_num=k;
- 以 OpenVLA 在 ManiSkill 中进行强化学习训练为例,我们发现混合式细粒度流水的调度模式展现了最佳的吞吐。为了减少 GPU 空闲等待的时间,我们以流水线数量 k = 2 来配置 Rollout 的组合,即 Simulator 部分使用 GPU 0~1 两张卡创建四个 ManiSkill 实例,而 Generation 部分使用 GPU 2~3 两张卡运行两个 OpenVLA 实例的推理过程。在 Rollout 结束之后,Training 的实例可独立运行,并不依赖其他组件,所以,我们空出所有的 GPU 资源给 Training。
2. 算法设计
2.1 关于优势函数和logprob的设计
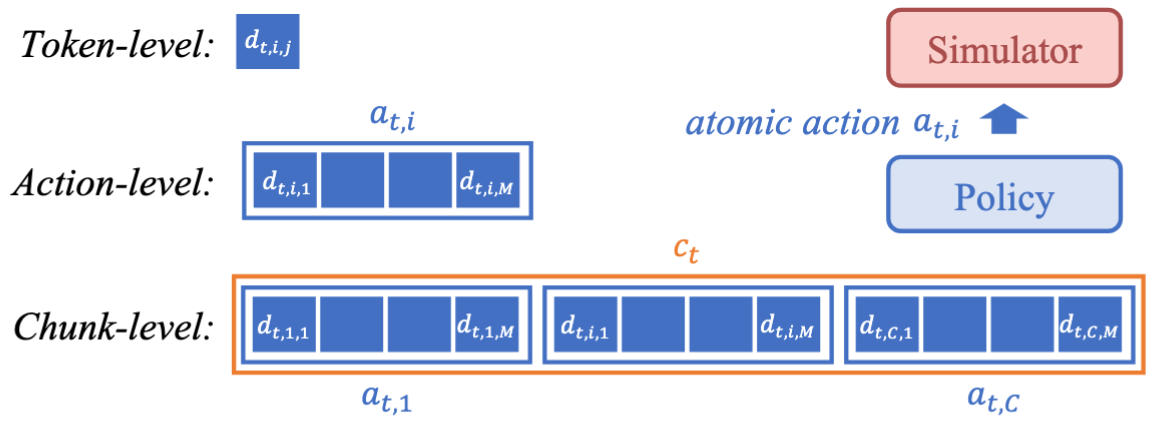
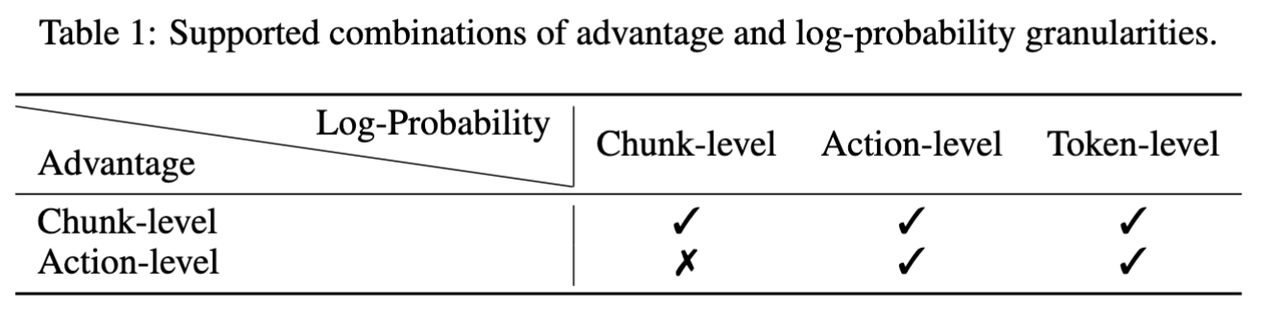
在讲算法设计之前,需要首先定义VLA 模型输出的三个粒度,如图4所示。(1)Token-level:这是最小的输出单元,例如表示夹爪开合的一个token;(2)Action-level:机器人领域常用的atomic action,通常表示模型的动作轨迹中某个时刻的一次动作;(3)Chunk-level:模型在一次前向中就能输出多个动作,这些动作可以在仿真环境中依次执行得到多个过程奖励,这是最大粒度,在模仿学习中常被称为动作块( action chunk )。下面将分别介绍RL算法中关键的对数似然(log-probability)计算和优势(advantage)计算。
- 两种粒度的 advantage 的计算粒度:在 LLM +RL 算法中,通常有token-level的奖励,但是在具身领域我们通常关注action-level或chunk-level的奖励,因为某个词元不足以表示某次动作,因此也就无法从环境中获取奖励。但是计算动作优势需要奖励信息,所以优势函数(advantage function)的计算粒度只有 chunk-level 和 action-level 两种级别。前者是说将动作块中的所有动作的反馈的奖励加和到一起,将整个块视为一个动作。在 RLinf-VLA中,只需要更改
reward_type参数即可,可选参数为chunk_level和action_level。 - 三种粒度的 log-probability 的计算粒度:在 GRPO和PPO算法中更新策略,计算 log-probability是计算重要性采样比例的必不可少的一步,在 RLinf-VLA中,我们支持了三种粒度的 log-probability 的计算方式。只需要更改 logprob_type 参数即可,可选参数为 token_level,chunk_level 和 action_level。
2.2 支持三种环境采样的重置方式
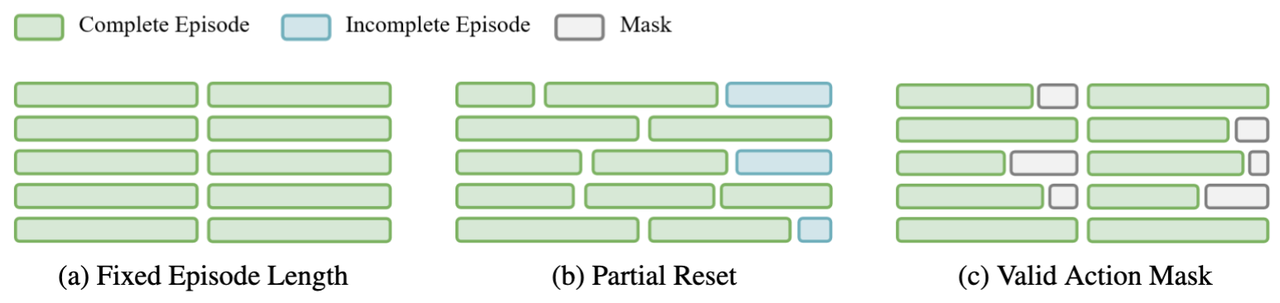
RL 算法中,策略在环境中采样会遇到两种结束的情况,第一种是环境执行成功返回终止( termination ),第二种是策略在环境中交互达到最大的交互次数,循环中止,返回截断( truncation )。为了应对这两种结束情况,提高我们采样的效率,我们在 PPO 算法中提供了两种环境采样的重置方式:
- 方法一:强制策略执行到固定步数才结束( Fixed Episode Length):只需要打开
ignore_terminations =True即可实现。这种重置方式对应的优化目标是希望策略能够在执行成功后继续保持成功的状态,所以需要关注success_at_end这个目标。这个重置方式如图5(a)所示。 - 方法二:只要模型执行到有成功返回就立刻重置环境( Partial Reset ):需要同时打开
auto_reset=True和ignore_terminations=False。由于这种模式只需要策略执行成功至少一次,所以需要关注success_once这个目标。这个重置方式如图5(b)所示。
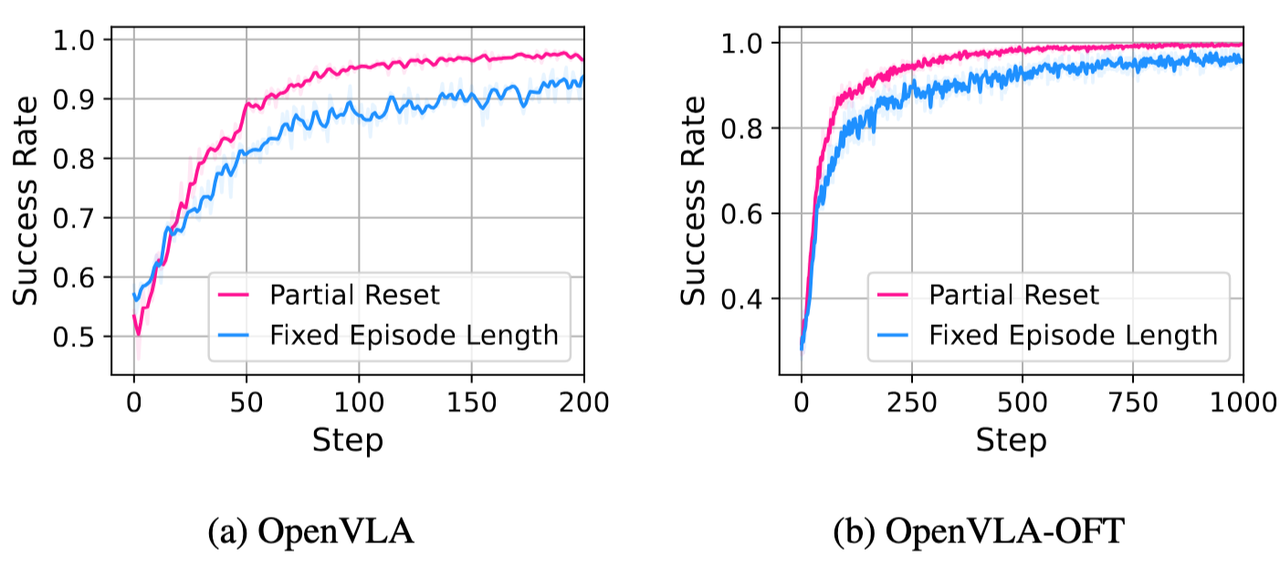
我们对两种方案进行了消融实验,如图6所示。我们发现在PPO算法中应用Partial Reset在两种模型下的效果都更优。
对于 GRPO 算法来说,也可以采用第一种重置方法,然而这种重置方法在同步执行多个任务时,有的任务较为简单,可能早早地就完成了。这就引出了第三种情况,即不重置环境,但成功之后的动作不会参与训练。在 RLinf-VLA 中,我们通过增加掩码来实现这种情况,这就是第三种重置方式:
- 方法三:模型执行到固定步数结束并将成功后的动作做掩码( Valid Action Mask ):只需要打开
auto_reset=False和ignore_terminations=False。这种模式只需要策略执行成功至少一次,所以需要关注success_once这个目标。这个重置方式如图5©所示。该部分曲线结果在后文展示。
2.3 关于 PPO 算法的设计
- 轻量化的 Critic 模型
由于使用整个独立的神经网络模型来估计期望回报占用的 GPU 资源较多,RLinf-VLA将 Actor 策略和 Critic 模型共享大部分参数,为 Actor 神经网络后接一个三层的线性层网络作为 Critic 模型。Critic 模型以 Actor 最后一层神经网络输出的第一个词元 token 前的隐藏状态 (hidden state) 作为输入,输出当前动作的期望回报。
- 估计价值函数的两种粒度
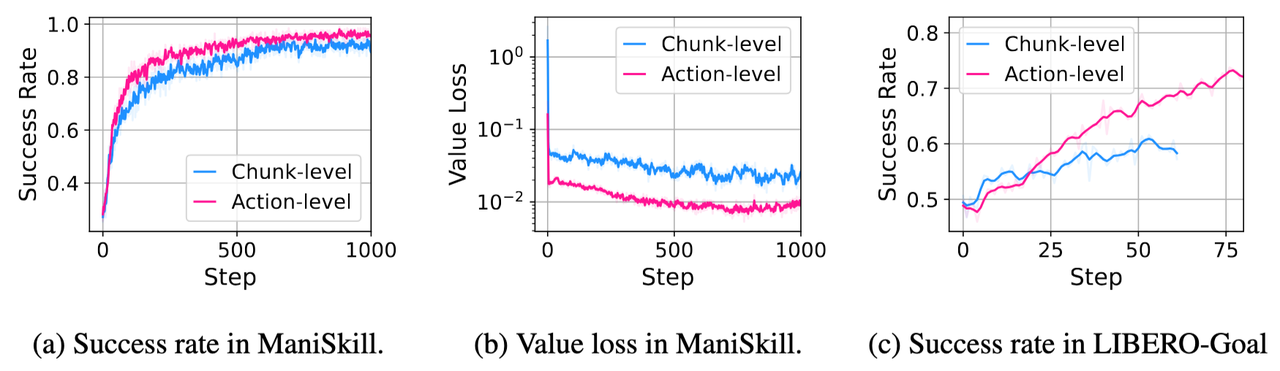
价值函数 (value function) 的估计跟优势函数的估计粒度一样,计算粒度只有chunk-level和action-level两种级别。前者是将整个块视为一个动作。在 RLinf-VLA 中,只需要更改 value_type 参数即可。默认情况下,这个参数与优势函数估计方式相同,即 value_type = reward_type。在 PPO 算法实验中发现, 价值函数的粒度取 action-level 能够让模型收敛更快,成功率更高,如图7所示。
2.4 关于GRPO算法的设计
- GRPO 动作轨迹的长度归一化
不同于 LLM 中较长的回答有更大的可能是符合期望的回答,具身操作场景下,较长的交互轨迹很可能是失败的轨迹。因此失败的轨迹往往会执行到最大的交互步数而被截断,相反,由于环境返回的终止信号,成功轨迹的长度较短。因此,为了让策略更公平地学习成功与失败的轨迹,RLinf-VLA在更新策略时,对损失的计算加上了对每一个时间步的损失做在有效轨迹长度上的归一化。具体而言,当一条轨迹有 T 个成功的时间步,那么这一条轨迹上的所有成功时间步(失败的时间步已经被掩码盖住)对应的损失都应该除以 T 。公式如下:
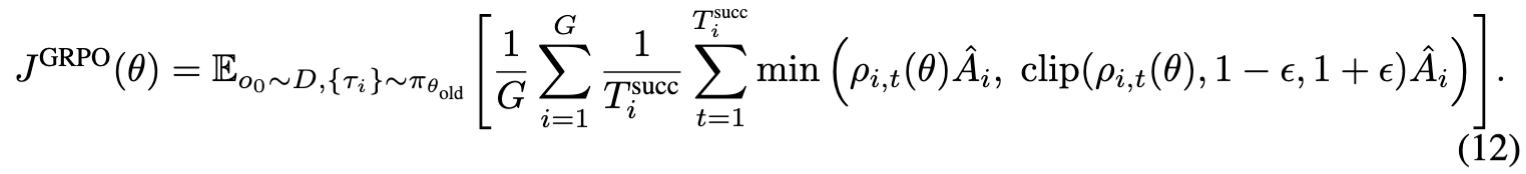
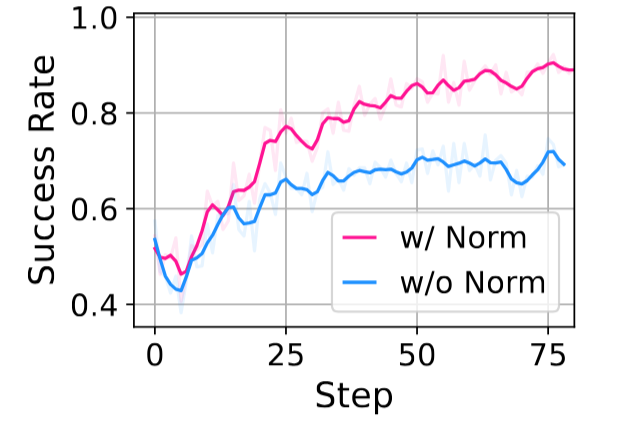
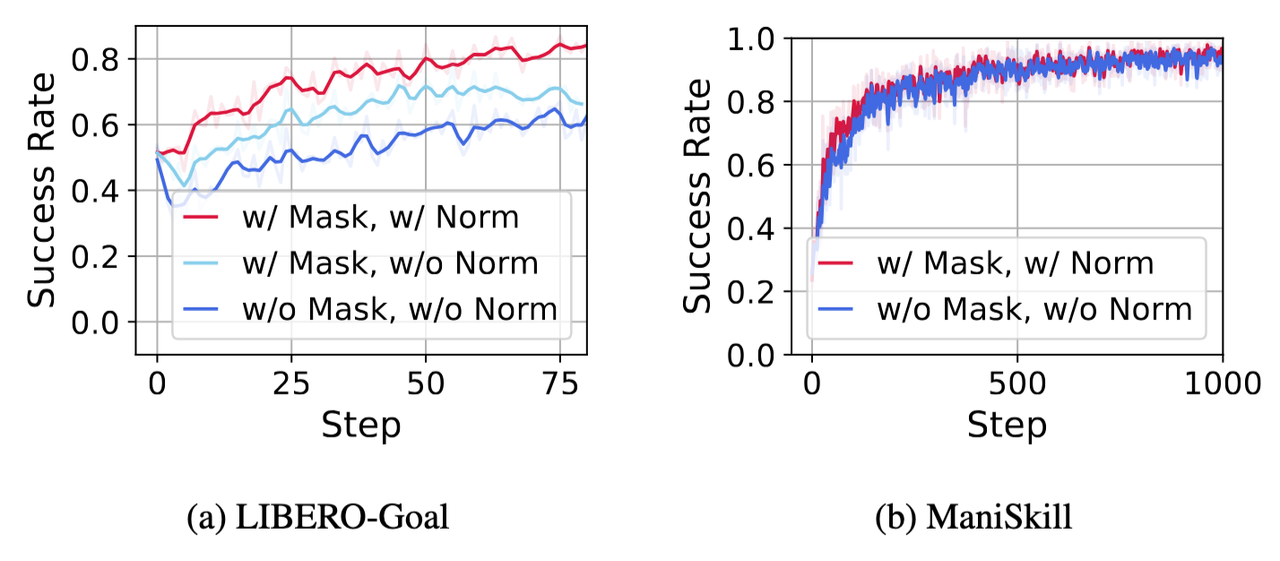
图8展示了有无动作轨迹的长度归一化的对比结果,可以长度归一化对于最终性能影响相对较大。图9进一步展示了结合前面的动作掩码的长度归一化的对比结果,可以看出在 LIBERO 任务中,二者均有正向效果,在 ManiSkill 的任务中效果相当。
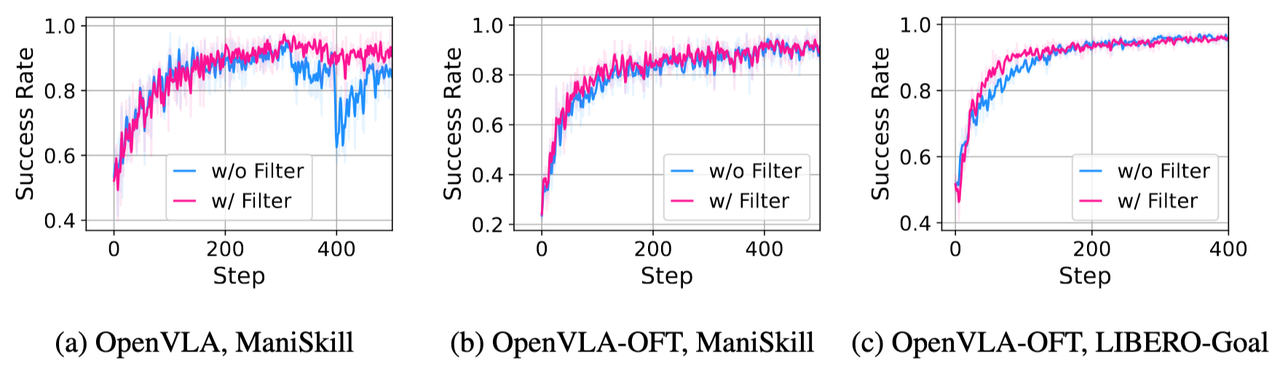
- 过滤 GRPO 组内的轨迹
与 DAPO 类似,RLinf-VLA 设计了过滤机制,如果某个组内的所有的轨迹都是成功的或者失败的,那么这个组的所有的轨迹都不会参与策略的更新。因为在 GRPO 的优势函数计算方法下,组内的所有轨迹的优势值都是0,并不会对策略的更新提供贡献。过滤这个操作能够加速策略的性能收敛并且最终能够提升模型的性能,如图10所示。
3. 性能一览
3.1 高性能
(1)多任务实验-ManiSkill
在 ManiSkill 的25个pick&place任务中, OpenVLA 模型和 OpenVLA-OFT 模型在 PPO 和 GRPO 算法中都有明显的效果提升,相较于 Base 模型,提升幅度在45%~70%。如图11所示,PPO 算法相较GRPO算法更加稳定,模型最终的成功率更高。
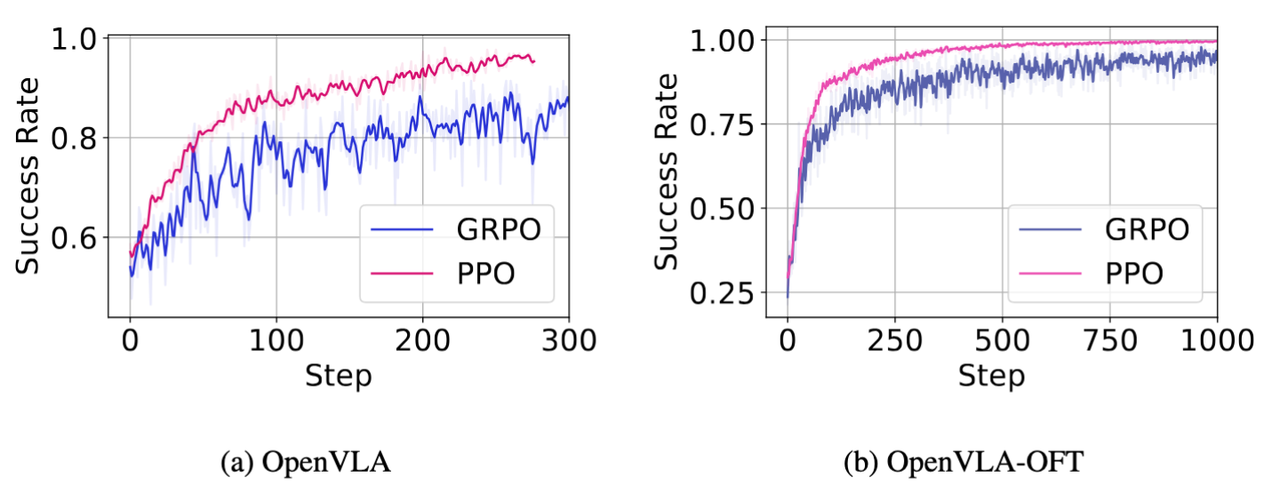
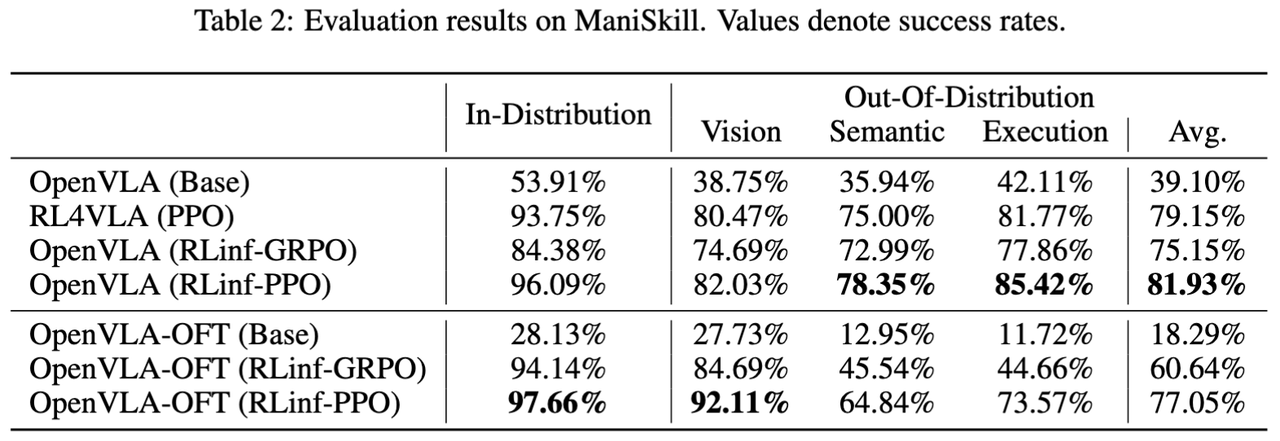
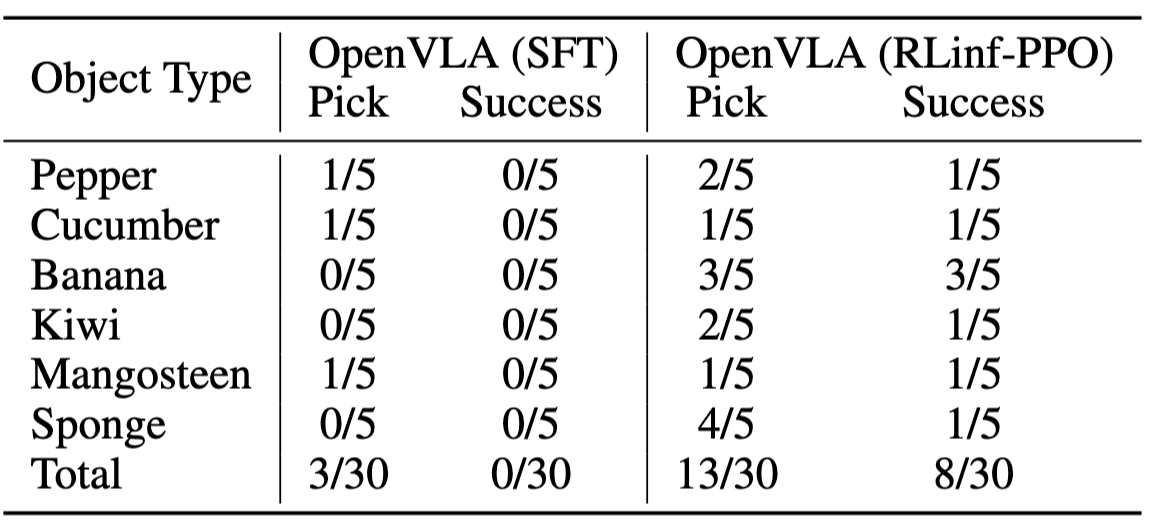
为了进一步验证模型的泛化能力,我们进一步测试了模型在训练数据分布外的性能实验。如表2所示,我们发现,OpenVLA(RLinf-PPO) 的算法和实验设置虽然与 RL4VLA 相同,但是 OpenVLA(RLinf-PPO) 有更优的效果,这说明了在相同的绝对时间中,RLinf-VLA 能够以更高效的方式采集更多的数据和进行更多轮次的训练。
(2)多任务实验-LIBERO
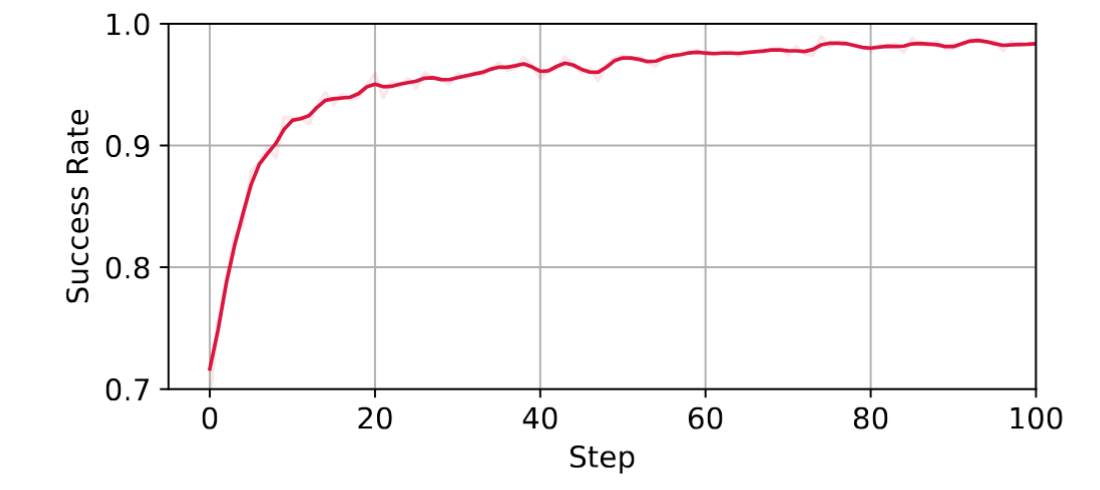
本文在LIBERO 所有的130个任务中采用GRPO算法训练OpenVLA-OFT。结果表明,训练后的单个模型在 LIBERO-Spatial 和 LIBERO-Object 的任务成功率达到 99% 以上,在 LIBERO-Goal 和 LIBERO-90的任务成功率提升到 98% 以上(注意:相关工作采用的是针对每一个任务组训练单独模型进行评估,而本文是一个模型在所有任务组进行评估)。这个实验表明RLinf-VLA能够支持大规模的具身智能的强化学习训练。

3.2 高效率
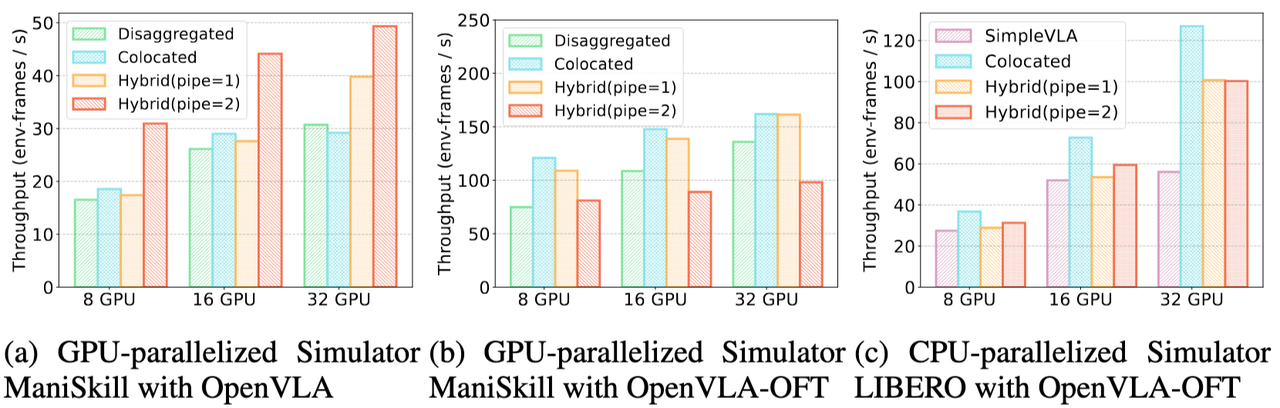
为了测试 RLinf-VLA 的吞吐,我们在多种实验设置下,对三种调度模式进行了广泛的测试,如图13所示,结论总结如下:
-
OpenVLA 与 ManiSkill 的实验设置(图13a):
a. 我们发现使用 pipe=2 的混合式调度的训练比使用分离式的基线快了1.88倍(8块 NVIDIA H100),并且在持续增加卡数后也能观察到吞吐量持续上涨。如图13a所示,其他模式则由于频繁地卸载加载组件和状态切换,出现多机的吞吐量下降的情况;
b. 在进一步比较pipe=1和pipe=2的调度模式之后,我们发现更细粒度地切分 Simulator 能够提升整体的吞吐量性能,意味着 RLinf-VLA 设计的混合式细粒度流水的设计能够有效地减少 GPU 空闲等待的时间,减少“气泡”; -
OpenVLA-OFT 与 ManiSkill 的实验设置(图13b):
a. 这个组合的最优调度模式则不同于前一组,这是由于 OpenVLA-OFT 模型输出的动作块,模型只需要前向传播一次就能生成8个动作,这8个动作依次在模拟器中执行,因此 Simulator 需要更多的 GPU 资源。那么 pipe=2 的混合式的优势因此消失,如图13b所示,pipe=1 的吞吐量更大;
b. 由于 ManiSkill 是 GPU 并行的模拟器,从图13b中也能观察到吞吐量随着 GPU 的数量增加而线性增长,因此,为 ManiSkill 分配更多 GPU 资源的共享式和 pipe=1 的混合式有明显更大的吞吐量; -
OpenVLA-OFT 与 LIBERO 的实验设置(图13c):
a. OpenVLA-OFT 在 LIBERO 中的最佳调度模式则是共享式。如图13c和图14所示,这是由于 LIBERO 是 CPU 并行程度高的模拟器,其并不会与 Generation 抢占 GPU 资源,所以使用共享式让 Generation 调度所有的 GPU 资源加速推理。
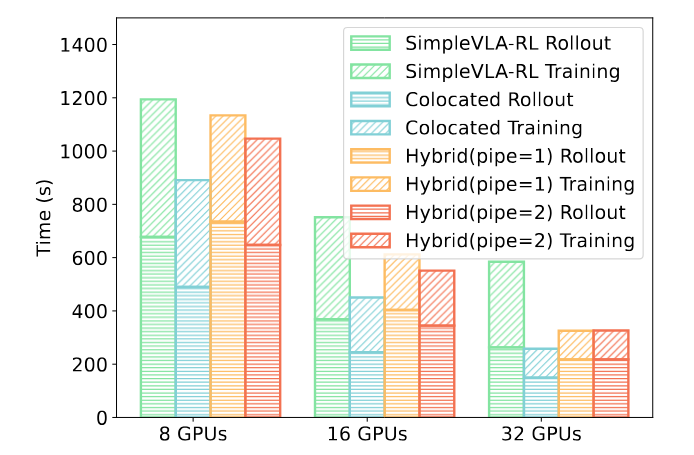
b. OpenVLA-OFT 在 LIBERO 的共享式比同样使用共享式的 SimpleVLA-RL(基于VeRL)要快1.34~2.27倍。如图14所示,RLinf 训练在 Rollout 和 在 Training 阶段都比基线需要更少的时间。在 Rollout 阶段,由于我们封装了 LIBERO 模拟器原生的多线程类,并且无需每条轨迹结束之后无需频繁重新创建模拟器实例,这减少了不少的时间开销,同时没有牺牲采样的效果和正确性;在 Training 阶段,得益于 RLinf 框架在系统上的多种优化手段,相比于基线,在拓展到多机后的耗时减少更多。
3.3 真机实验
为了验证使用 RLinf-VLA 训练策略的虚拟到真实的迁移性能,我们把在模拟器训练的 OpenVLA (RLinf-PPO) 直接部署到 Frank Panda 机械臂中进行多个任务的实验。真机实验不仅展现出OpenVLA (RLinf-PPO) 的零样本泛化到真实场景的能力,并且,在与使用 SFT 训练的策略相比,前者有更优的任务成功率,并且观察到后者有更严重的运动不稳定、抖动或震荡过大的现象。
结语
RLinf-VLA的目标是通过强化学习不断提升VLA的能力,让智能体在真实世界中具备更强的理解、推理与行动能力。要实现这一目标,需要一个可靠且可扩展的基础设施。我们将持续维护与升级 RLinf-VLA 框架,未来将持续扩展仿真平台、模型生态、算法和真机支持,欢迎大家关注!
具身求职内推来啦
国内最大的具身智能全栈学习社区来啦!
推荐阅读
从零部署π0,π0.5!好用,高性价比!面向具身科研领域打造的轻量级机械臂
工业级真机教程+VLA算法实战(pi0/pi0.5/GR00T/世界模型等)
具身智能算法与落地平台来啦!国内首个面向科研及工业的全栈具身智能机械臂
VLA/VLA+触觉/VLA+RL/具身世界模型等!具身大脑+小脑算法与实战全栈路线来啦~
MuJoCo具身智能实战:从零基础到强化学习与Sim2Real
Diffusion Policy在具身智能领域是怎么应用的?为什么如此重要?
1v1 科研论文辅导来啦!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 6
6 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)