原力灵机提出ManiAgent!会 “动手”,会 “思考”,还会“采数据”!
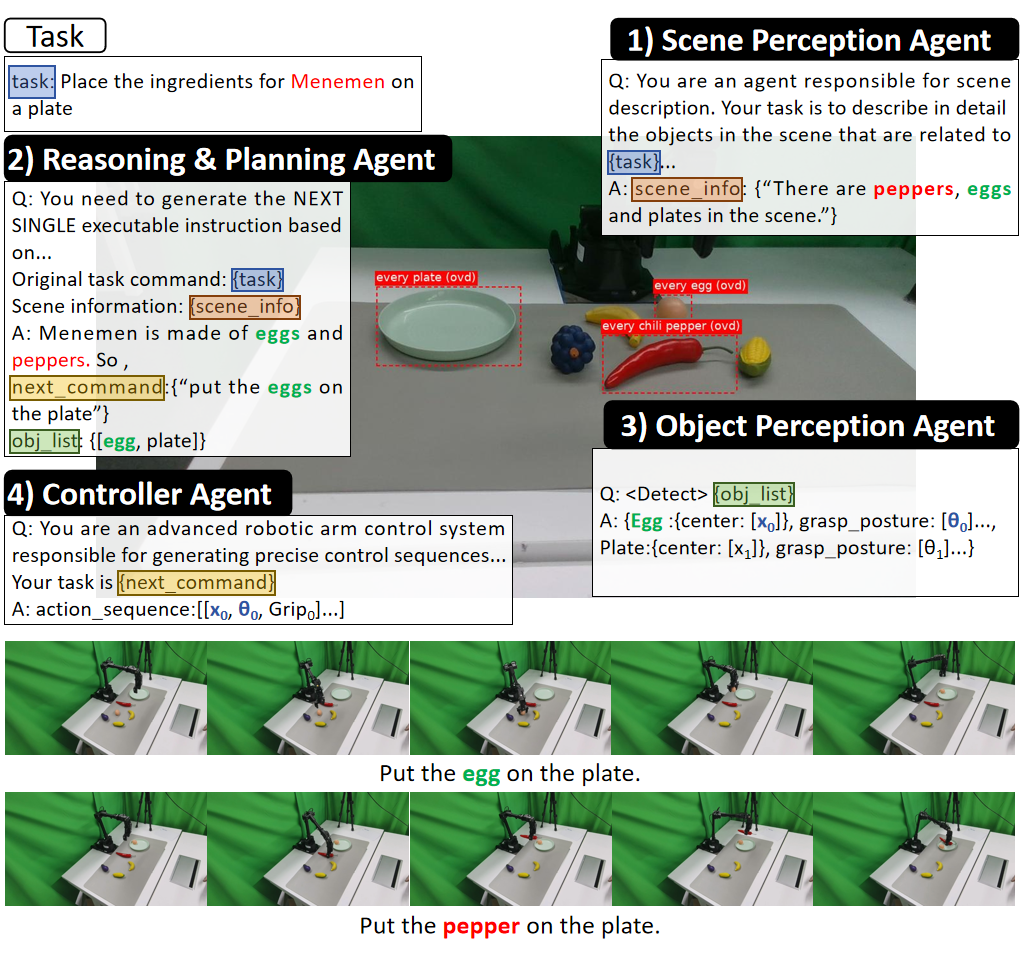
ManiAgent场景感知智能体:以场景图像和用户提供的指令作为输入,调用视觉语言模型(VLM)生成与任务相关的场景描述,为后续任务处理提供环境信息基础。推理智能体:接收感知智能体输出的场景描述与初始任务指令,通过查询**大型语言模型(LLM)**对当前任务状态进行评估,提出明确可以完成的子任务。物品级别感知智能体:在子任务执行过程中,感知智能体采用目标检测方法,精准识别场景中的目标物体,并提取其
在机器人操作领域,Vision-Language-Action(VLA)模型虽已展现出一定技术潜力,但其在复杂推理与长程任务规划场景下的性能,仍受限于数据稀缺与模型容量两大核心问题。为此,我们提出了 ManiAgent —— 一种面向通用机器人操作任务的智能体架构,该架构可实现从任务描述、环境输入到机器人操作动作的端到端输出。
在 ManiAgent 框架中,多个智能体通过协同交互分别承担环境感知、子任务分解与动作生成功能,能够高效应对复杂操作场景。我们通过实验评估发现,ManiAgent 在 SimplerEnv 基准测试中的任务成功率达86.8%,在真实世界拾取 - 放置任务中的成功率更高达95.8%。值得注意的是,依托其高任务成功率,ManiAgent 还可作为高效数据采集工具,基于该工具获取的训练数据所构建的 VLA 模型,性能能够与基于人工标注数据集训练的 VLA 模型相媲美,这为机器人操作领域的技术优化与落地提供了重要支撑。
- 论文题目:ManiAgent: An Agentic Framework for General Robotic Manipulation
- 论文链接:https://arxiv.org/abs/2510.11660
- 项目主页:https://yi-yang929.github.io/ManiAgent/
- 论文时间:Oct, 13, 2025
- 作者单位:北京工业大学,南京大学,中国科学技术大学,原力灵机
🌟 研究亮点概览
- 提出全新的端到端机器人操作解决方案:ManiAgent 可直接接收任务描述与环境输入,输出机器人可执行的操作动作,实现从任务指令到机械臂动作的端到端闭环,大幅简化算法部署流程。
- 构建通用操作任务分解机制:ManiAgent 将通用操作任务拆解为环境感知、推理规划、动作生成三大核心环节,分别由对应的智能体各司其职,通过智能体间的协作高效应对复杂操作场景。
- 高成功率验证与数据采集赋能:大量实验表明,ManiAgent 在 SimplerEnv 仿真基准测试中成功率达86.8%,在真实世界拾取 - 放置任务中成功率高达95.8%;依托其高可靠性,ManiAgent 还可作为高效的自动化数据采集工具,生成的训练数据能支撑 VLA 模型训练,且训练出的 VLA 模型性能可与人工标注数据集训练的模型媲美,显著降低数据采集成本并为 VLA 技术落地提供数据支撑。
🤖 方法概述
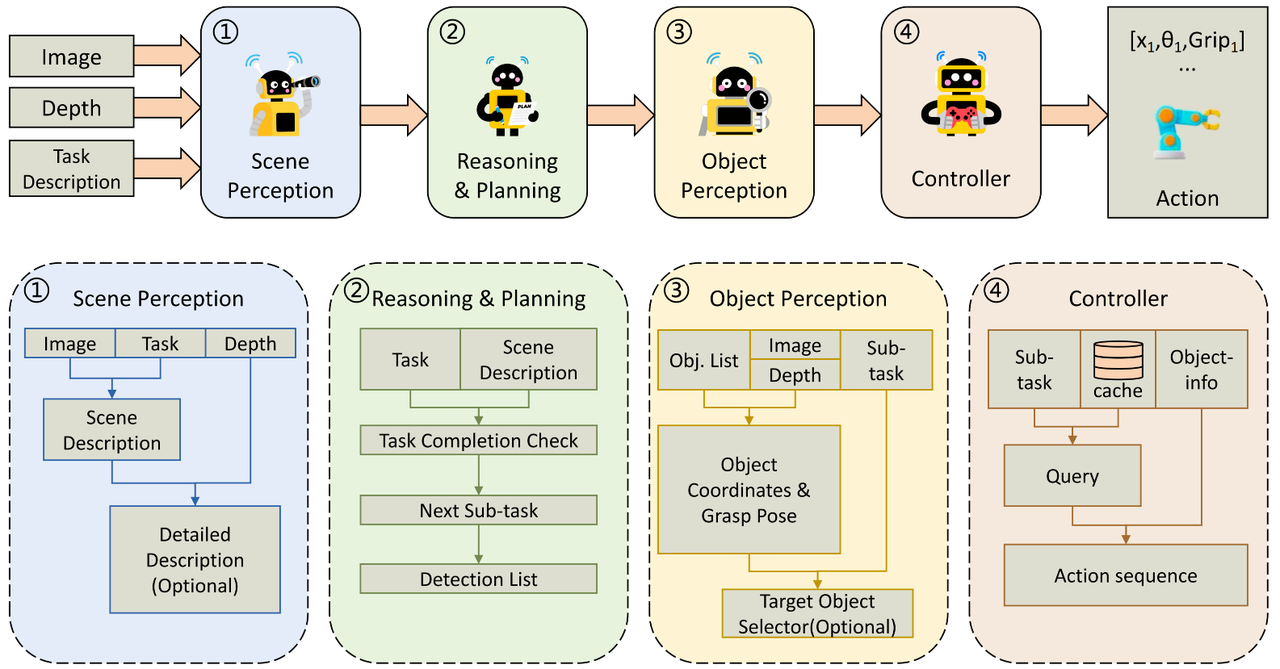
ManiAgent 由4个智能体组成:
- 场景感知智能体:以场景图像和用户提供的指令作为输入,调用视觉语言模型(VLM)生成与任务相关的场景描述,为后续任务处理提供环境信息基础。
- 推理智能体:接收感知智能体输出的场景描述与初始任务指令,通过查询**大型语言模型(LLM)**对当前任务状态进行评估,提出明确可以完成的子任务。
- 物品级别感知智能体:在子任务执行过程中,感知智能体采用目标检测方法,精准识别场景中的目标物体,并提取其详细信息(如3D位置、抓取姿态等),为动作生成提供关键数据。
- 控制器智能体:控制器智能体先依据当前子任务查询缓存,若存在匹配的已缓存动作序列,则直接调用该序列;若未找到匹配项,便结合子任务描述与感知到的物体细节查询 LLM,生成可直接执行的完整动作序列。
🔍 实现细节
ManiAgent 框架通过工具调用、上下文工程、实时性优化与自动数据采集四大关键技术突破,构建了从环境感知到动作执行的完整技术链路,以下为各模块具体实现逻辑:
🔧 工具调用
ManiAgent 通过多工具协同支撑全流程操作:
- 视觉语言模型(VLM):用于场景感知与物体筛选,如调用 Qwen-VL 生成任务相关场景描述,借助 Florence-v2 实现开放词汇目标检测,精准定位物体像素坐标并转换为3D 空间坐标;
- 大型语言模型(LLM):负责推理规划与动作生成,例如通过 GPT-5 完成子任务分解、历史任务记忆存储,以及结合物体位置 / 抓取姿态信息生成可执行动作序列;
- 专用感知工具:采用 AnyGrasp 生成全场景抓取姿态,结合深度图与相机参数计算物体 3D坐标,解决机械臂抓取精度问题。
🖋 上下文工程
围绕 “提升任务相关性与信息有效性” 设计上下文处理机制:
- 场景描述优化:在提示词(Prompt) 的设计过程中,优先确保覆盖场景中所有任务相关真实信息,再剔除冗余内容,避免干扰后续推理;
- 子任务上下文管理:推理智能体采用增量式子任务分解,不一次性拆解全流程,而是结合实时场景动态调整,同时存储历史子任务作为记忆,防止局部循环;
- 物体信息格式化:将感知到的物体中心坐标、抓取姿态等关键数据转换为统一文本格式,作为 LLM 生成动作序列的输入上下文,确保信息传递一致性,避免格式偏差导致的动作失效。
⚡️ 实时性优化
通过缓存机制降低动作生成延迟,提升任务执行效率:
- 参数化动作缓存:控制器智能体将已执行子任务的动作序列参数化存储(如抓取姿态、移动轨迹模板),当新任务与缓存任务提示完全匹配时,直接调用缓存序列并结合当前物体坐标生成具体动作,无需重复查询LLM;
- 缓存一致性保障:依托物体感知阶段固定的物体索引,确保缓存动作序列与当前场景中物体信息的匹配性,避免因物体位置变化导致的动作错位;
- 轻量验证逻辑:在采集数据等相对可控的场景下,采用规则化任务成功判定(如物体最终位置与目标位置距离 < 15cm),替代耗时的 VLM 二次验证,减少流程冗余。
🎮 自动数据采集
基于高任务成功率构建端到端自动化数据采集体系:
- 场景重置机制:支持随机或规则化场景重置,例如通过规则生成物体坐标,使物体沿固定轨迹排列,确保数据采集的位置多样性;
- 数据记录与筛选:在控制器中集成数据集记录功能,自动采集机械臂动作轨迹、场景图像、物体位置等数据,在采集阶段,系统借助规则化的任务验证逻辑即可完成对数据的筛选;
- 低干预运维:整个采集过程仅需少量人工介入(如处理逆运动学规划失败导致的物体移位,平均每 46 分钟 1 次干预),大幅降低人力成本;采集数据可直接用于 VLA 模型训练,如用其训练的 CogACT 模型,性能可媲美人工标注数据集训练模型。

✍️ 实验设计
我们分别在 SimplerEnv 仿真环境、真实场景中对 ManiAgent 的表现进行了评估。值得注意的是,在整个实验中(包含仿真和实物实验),我们使用的 prompt 完全保持一致,没有针对任何特殊任务做调整。与此同时,针对自动化数据采集,我们也设计了对应的实验。
1. SimplerEnv(高拟真仿真平台)
任务:4项典型的抓取-放置任务(将绿色方块堆叠到黄色方块上、把胡萝卜放在盘子里、将勺子置于毛巾上、把茄子从水槽移至篮子中)。
实验流程:每组任务重复 3 次(含不同随机种子),每次实验以 24 次操作尝试为单位,最终取平均值作为结果,确保数据稳定性。
评价指标:各任务的平均成功率及整体平均成功率。
2. 真实场景(使用 WidowX 250S 机械臂)
任务:设计 8 项覆盖多能力维度的代表性任务,包括基础抓取 - 放置(如将特定物品放入对应容器)、较复杂的抓取 - 放置(如堆叠方块)、意图推理(如从模糊指令 “我饿了” 中识别拿取的物品)、常识知识应用(如按餐桌礼仪将刀叉分别放在左右手边)、长序列任务(如按食谱摆放多种食材)。
实验设定:两个Realsense D435相机,分别提供正向视角和侧向视角的RGBD信息,其中正向视角作为各智能体推理输入,侧向视角用于进行更细致的点云生成补充。
评价指标:成功率。
3. 自动化数据采集(使用 WidowX 250S 机械臂)
在简单的抓取放置任务上对 ManiAgent 的数据采集功能进行验证,
流程:自动布置环境(随机或规则化方法)➡️ 自动采集 ➡️ 标记采集数据
评价指标:人工干预频率、采集成功率、采集速度
📊 实验结果
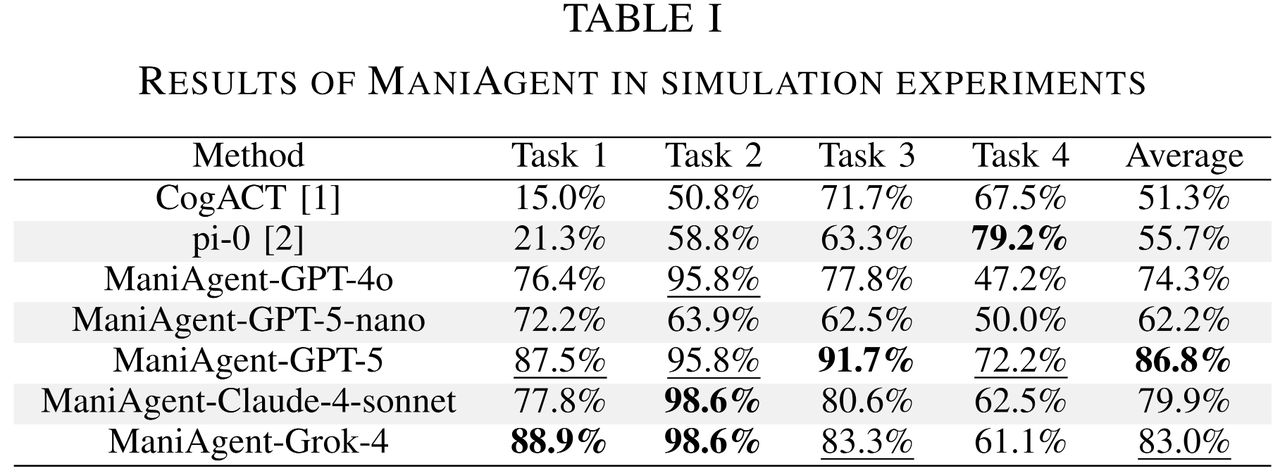
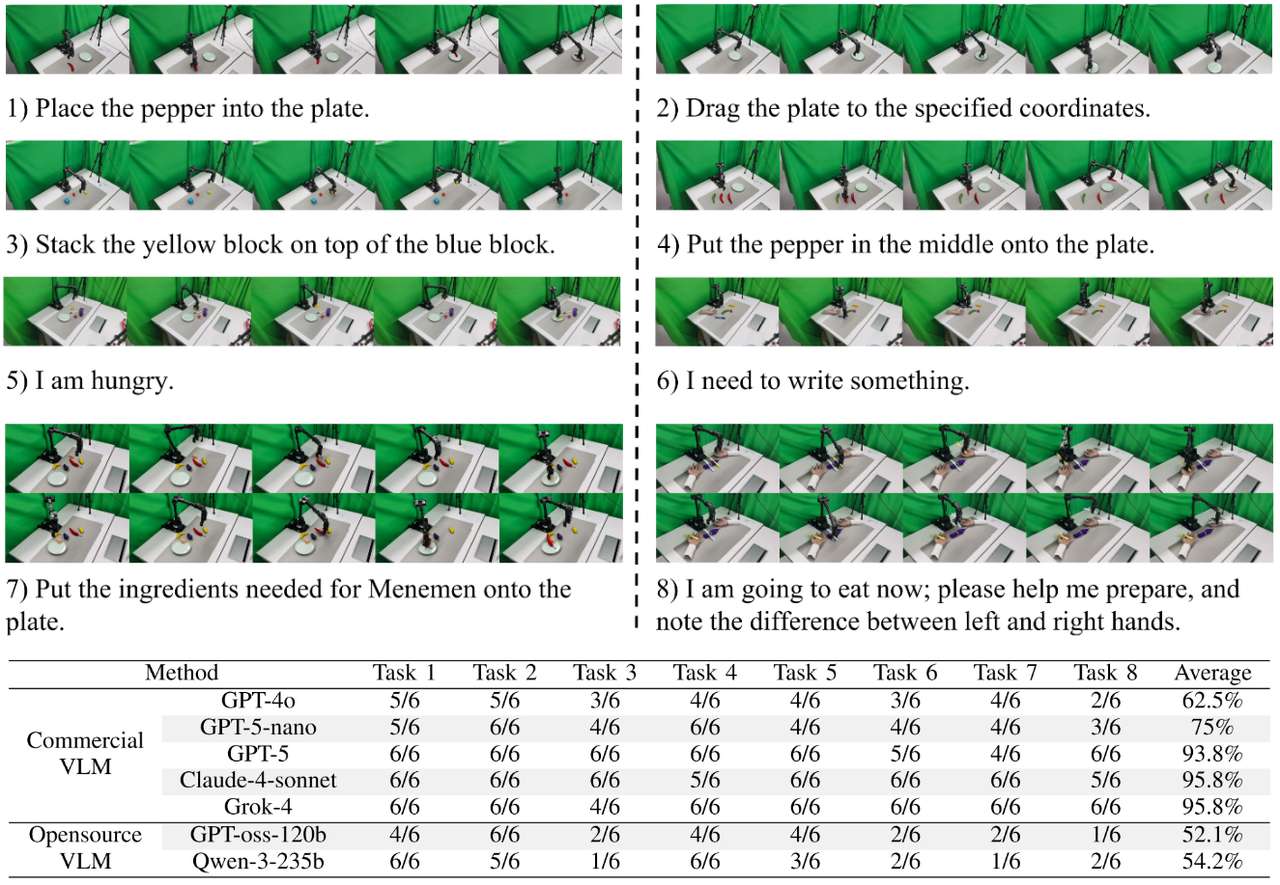
主要结论:
- SimplerEnv 中最高取得86.8%的平均成功率。
- 在包含各类复杂推理任务的实物实验中最高取得95.8%的平均成功率。
- 通过ManiAgent自动采集的数据可以达到与人工采集数据相同的训练效果。
📍 研究意义与展望
ManiAgent 的价值在于突破传统VLA模型在意图推理以及长程任务上的瓶颈,通过多个智能体的相互配合实现在仿真与真实任务场景下,以较高的成功率完成通用操作任务,无需额外训练数据;同时,ManiAgent 也可以自动采集高质量数据,大幅降低 VLA 技术落地成本,并打通 “感知 - 推理 - 控制” 技术链路,为机器人操作框架提供参考。在未来的工作中,我们将重点聚焦于强化实时反馈以适配动态场景,将算法拓展至移动机器人等多平台,优化算法的人机交互体验,提升算法中指令理解部分的灵活性,进一步拓展应用边界。
具身求职内推来啦
国内最大的具身智能全栈学习社区来啦!
推荐阅读
从零部署π0,π0.5!好用,高性价比!面向具身科研领域打造的轻量级机械臂
工业级真机教程+VLA算法实战(pi0/pi0.5/GR00T/世界模型等)
具身智能算法与落地平台来啦!国内首个面向科研及工业的全栈具身智能机械臂
VLA/VLA+触觉/VLA+RL/具身世界模型等!具身大脑+小脑算法与实战全栈路线来啦~
MuJoCo具身智能实战:从零基础到强化学习与Sim2Real
Diffusion Policy在具身智能领域是怎么应用的?为什么如此重要?
1v1 科研论文辅导来啦!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 3
3 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)