如何使用 LangChain 和 Elasticsearch 构建 agent 知识库
本文介绍了如何利用Elasticsearch构建一个智能代理知识库系统。该系统通过结合大型语言模型(LLM)的决策能力和检索增强生成(RAG)技术,实现了更精准的信息检索。作者以潜水知识库为例,整合了美国海军潜水手册、潜水安全手册和Google搜索API三个数据源,使用LangChain框架创建代理工具集。测试表明,该系统能根据查询意图智能选择数据源,避免无关信息干扰,并能处理超出知识库范围的问题
作者:来自 Elastic Han Xiang Choong
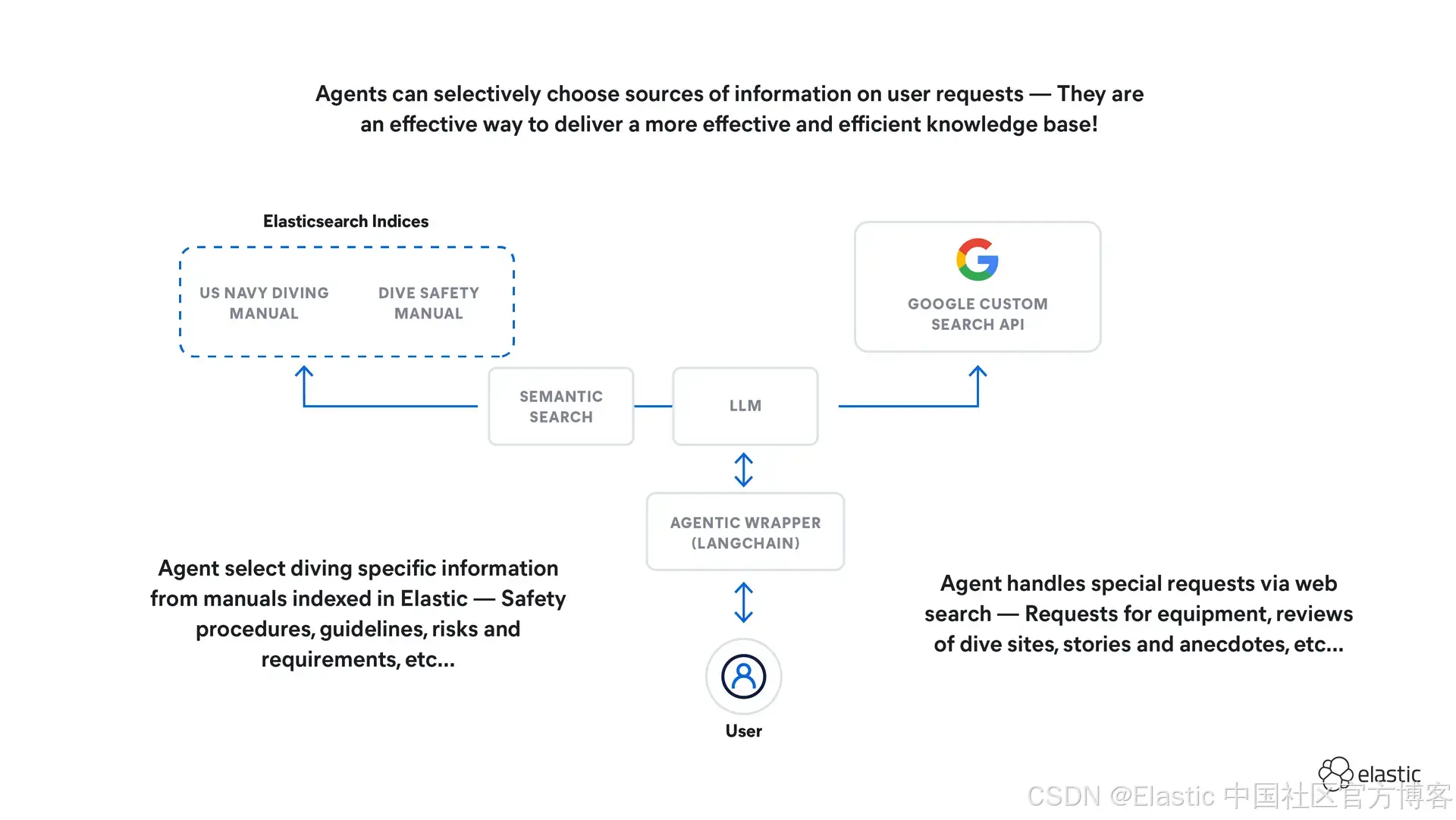
学习如何构建一个 agent 知识库,并测试它基于上下文查询信息源的能力,对超出范围的查询使用 WebSearch,并根据用户意图优化推荐。
Agent Builder 现在以 tech preview 形式提供。使用 Elastic Cloud Trial 开始,并在这里查看 Agent Builder 的文档。

在行业使用场景中,与大型语言模型( LLMs )交互主要有两种模式。直接查询,即以临时方式与 LLM 对话,适用于获取诸如摘要、校对、信息抽取以及非特定领域查询等任务的帮助。
对于特定的业务应用,例如客户关系管理、 IT 系统维护以及调查工作等,仅使用 LLM 是不够的。私有的、企业特有的信息,或关于小众兴趣和主题的信息,甚至来自特定文档和书面来源的信息,通常在 LLM 的训练数据集中是缺失的。此外,现实世界的数据在不断变化,企业环境也在持续演进。 LLM 也往往需要对事实准确性进行强化。所有这些因素都限制了直接使用 LLM 在企业使用场景中的实用价值,尤其是那些需要关于特定技术或业务主题的最新事实信息的场景。
检索增强生成( Retrieval Augmented Generation,RAG )通过使用可搜索的数据存储来检索与用户查询的上下文和意图相关的信息源,被推广为解决这一不足的方法。围绕 RAG 应用的实现、评估以及质量改进已经开展了大量工作, RAG 也在企业使用场景中被广泛采用,用于提升生产力和实现工作流自动化。然而, RAG 并未利用大型语言模型的决策能力。
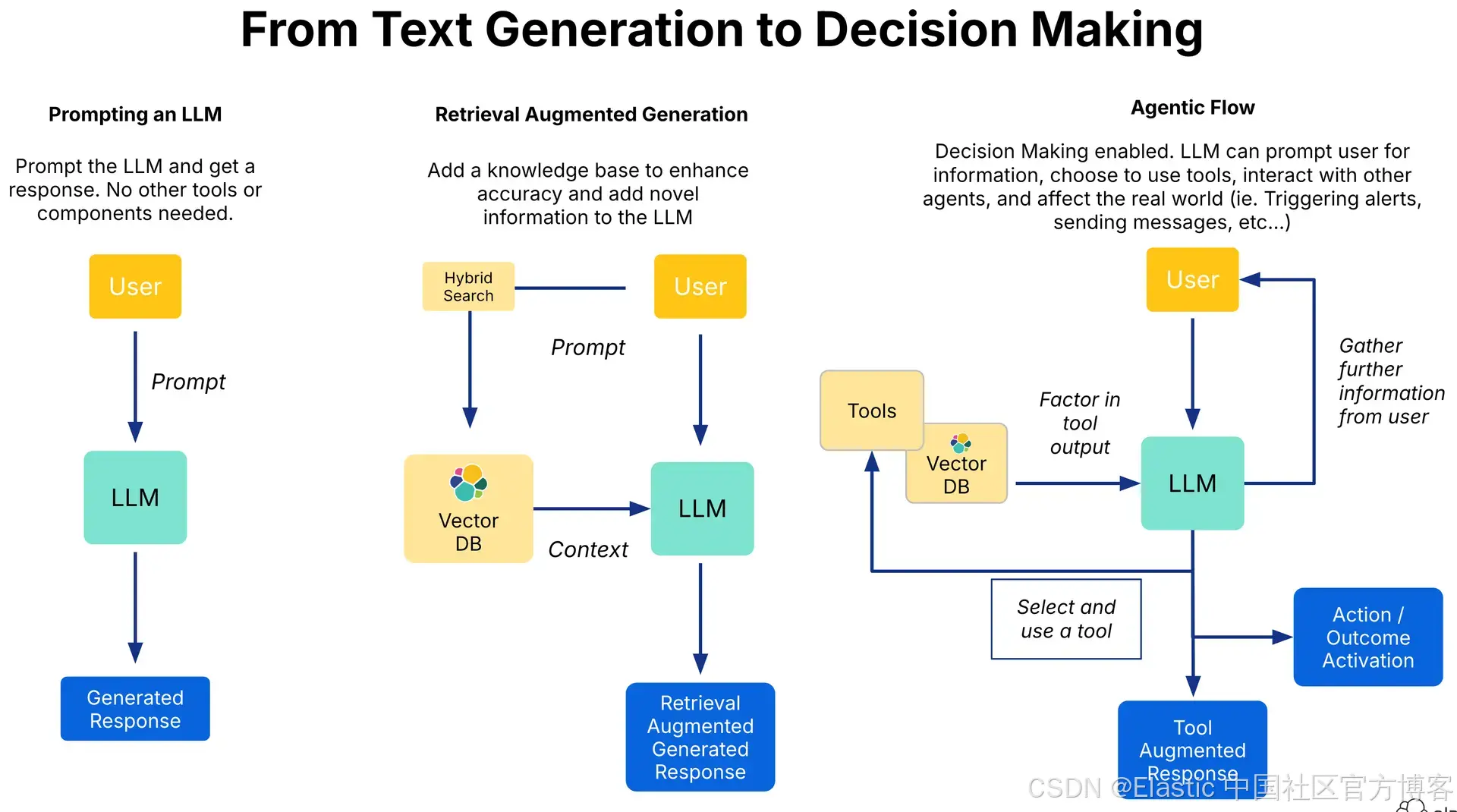
大型语言模型的不同应用模式。
Agentic 模型的核心在于 LLM 能够根据用户输入采取特定的行动。这些行动可能涉及使用工具来增强 LLM 现有的能力。从这个意义上说, RAG 充当一个长期记忆存储, LLM agent 可以选择使用它来增强和强化对用户查询的回答。传统的 RAG 模型是由 LLM 查询一个或多个知识库,而 agentic 实现则允许 LLM 从一组知识库中进行选择。这使问答行为更加灵活,并且可以提高准确性,因为无关知识库中的信息会被省略,从而减少潜在的噪声来源。我们可以将这样的系统称为 “ agent 知识库 ”。下面我们来看看如何使用 Elasticsearch 实现这样一个系统。
设计一个 agent 知识库
所有代码都可以在 GitHub 仓库中找到。
我最近在尝试潜水后对它产生了兴趣,并意识到它可以治愈我长期的海洋恐惧症( thalassophobia ),于是我决定为潜水专门建立一个 agent 知识库。
- 美国海军潜水手册 - 包含大量关于潜水操作和设备的技术细节。
- 潜水安全手册 - 包含面向休闲潜水员的一般指导方针和操作程序。
- Google Custom Search API - 能够搜索网页中不包含在上述两本手册中的任何信息。
目标是让这个 Diving Assistant 成为潜水相关知识的一站式工具,能够回答任何查询,即使是超出已导入知识库范围的问题。 LLM 会识别用户查询背后的动机,并选择最可能相关的信息源。我决定使用 LangChain 作为 agentic 包装器,并在其上构建了一个 streamlit UI。
设置端点
我首先创建一个 .env 文件,并填入以下变量:
ELASTIC_ENDPOINT=<ELASTIC CLOUD ENDPOINT>
ELASTIC_API_KEY=<ELASTIC CLOUD API KEY>
# Enable custom search API
# https://developers.google.com/custom-search/v1/introduction/?apix=true
GCP_API_KEY=<GCP API KEY>
GCP_PSE_ID=<GCP PSE ID>
AZURE_OPENAI_SYSTEM_PROMPT="You are a helpful assistant. Be as concise and efficient as possible. Convey maximum meaning in fewest words possible."
AZURE_OPENAI_ENDPOINT=<AZURE ENDPOINT>
AZURE_OPENAI_API_VERSION=<AZURE API VERDSION>
AZURE_OPENAI_API_KEY=<AZURE API KEY>
AZURE_OPENAI_MODEL="gpt-4o-mini"该项目使用了部署在 Azure OpenAI 上的 GPT-4o-Mini,以及 Google Custom Search API 和用于存储数据的 Elastic Cloud 部署。我还添加了一个自定义系统提示,鼓励 LLM 尽量避免啰嗦。
导入和处理
美国海军潜水手册和潜水安全手册都是 PDF 格式,因此下一步是将它们导入到 Elastic Cloud 部署中。我使用 Elastic 的 bulk API 设置了这个 python 脚本,将文档上传到 Elastic Cloud:
import os
from collections import defaultdict
from concurrent.futures import ThreadPoolExecutor, as_completed
from elasticsearch import Elasticsearch, helpers # elasticsearch==8.14.0
from tqdm import tqdm # tqdm==4.66.4
from llama_index.core import SimpleDirectoryReader
def bulk_upload_to_elasticsearch(data, index_name, es, batch_size=500, max_workers=10):
'''
data: [ {document} ]
document: {
"_id": str
...
}
index_name: str
es: Elasticsearch
batch_size: int
max_workers: int
'''
total_documents = len(data)
success_bar = tqdm(total=total_documents, desc="Successful uploads", colour="green")
failed_bar = tqdm(total=total_documents, desc="Failed uploads", colour="red")
def create_action(doc):
'''
Define upload action from source documents
'''
return {
"_index": index_name,
"_id": doc["id_"],
"body": doc["text"]
}
def read_and_create_batches(data):
'''
Yield document batches
'''
batch = []
for doc in data:
batch.append(create_action(doc))
if len(batch) == batch_size:
yield batch
batch = []
if batch:
yield batch
def upload_batch(batch):
'''
Make bulk call for batch
'''
try:
success, failed = helpers.bulk(es, batch, raise_on_error=False, request_timeout=45)
if isinstance(failed, list):
failed = len(failed)
return success, failed
except Exception as e:
print(f"Error during bulk upload: {str(e)}")
return 0, len(batch)
'''
Parallel execution of batch upload
'''
with ThreadPoolExecutor(max_workers=max_workers) as executor:
future_to_batch = {executor.submit(upload_batch, batch): batch for batch in read_and_create_batches(data)}
for future in as_completed(future_to_batch):
success, failed = future.result()
success_bar.update(success)
failed_bar.update(failed)
'''
Update progress bars
'''
total_uploaded = success_bar.n
total_failed = failed_bar.n
success_bar.close()
failed_bar.close()
return total_uploaded, total_failed
# This is connecting to ES Cloud via credentials stored in .env
# May have to change this to suit your env.
try:
es_endpoint = os.environ.get("ELASTIC_ENDPOINT")
es_client = Elasticsearch(
es_endpoint,
api_key=os.environ.get("ELASTIC_API_KEY")
)
except Exception as e:
es_client = None
print(es_client.ping())在下载美国海军潜水手册 PDF 并将其存放在单独文件夹后,我使用 LlamaIndex 的 SimpleDirectoryReader 加载 PDF 数据,然后触发批量上传:
reader = SimpleDirectoryReader(input_dir="./data")
documents = reader.load_data()
bulk_upload_to_elasticsearch([i.to_dict() for i in list(documents)],
"us_navy_dive_manual_raw",
es_client, batch_size=16, max_workers=10)这会将所有文本内容发送到 Elastic Cloud,每页 PDF 作为一个单独的文档,存入名为 us_navy_dive_manual_raw 的索引中。没有进行进一步处理,因此上传全部 991 页的过程不到一秒。下一步是在 Elastic Cloud 中进行语义嵌入。
语义数据嵌入与分块
在我的 Elastic Cloud DevTools 控制台中,我首先使用 Elastic 推理 API 部署 ELSER v2 模型。
PUT _inference/sparse_embedding/elser_v2
{
"service": "elasticsearch",
"service_settings": {
"num_allocations": 1,
"num_threads": 8,
"model_id": ".elser_model_2_linux-x86_64"
},
"chunking_settings": {
"strategy": "sentence",
"max_chunk_size": 250,
"sentence_overlap": 1
}
}然后我定义了一个简单的 pipeline。每个文档在 body 字段中存储潜水手册一页的文本,因此我将 body 的内容复制到一个名为 semantic_content 的字段中。
PUT _ingest/pipeline/diving_pipeline
{
"processors": [
{
"set": {
"field": "semantic_content",
"copy_from": "body",
"if": "ctx.body != null"
}
}
]
}然后我创建了一个名为 us_navy_dive_manual 的新索引,并将 semantic_content 设置为 semantic_text 字段:
PUT us_navy_dive_manual
{
"mappings": {
"properties": {
"semantic_content": {
"type": "semantic_text",
"inference_id": "elser_v2"
}
}
}
}然后我触发了一个 reindex 任务。现在数据将从 us_navy_dive_manual_raw 流向 ELSER 进行分块和嵌入,并重新索引到 us_navy_dive_manual 中以供使用。
POST _reindex?slices=auto&wait_for_completion=false
{
"source": {
"index": "us_navy_dive_manual_raw",
"size": 4
},
"dest": {
"index": "us_navy_dive_manual",
"pipeline": "diving_pipeline"
},
"conflicts": "proceed"
}我对潜水安全手册重复了这个过程,通过这个简单的流程,数据导入就完成了。
Agentic 搜索的工具
这个 agent 相对简单,所以我使用 LangChain 的 AgentExecutor,它可以创建一个 agent 并将其与一组工具捆绑在一起。复杂的决策流程可以使用 LangGraph 实现,我们将在未来的博客中介绍。这里我们将重点关注与 agent 相关的部分,关于实际的 streamlit UI 详情,请查看 github 仓库。
我为我的 agent 创建了两个工具。第一个是 ElasticSearcher 类,它对 Elastic 索引进行语义搜索,然后返回前 10 篇文章的文本。
class ElasticSearcher:
def __init__(self):
self.client = Elasticsearch(
os.environ.get("ELASTIC_ENDPOINT"),
api_key=os.environ.get("ELASTIC_API_KEY")
)
def search(self, query, index="us_navy_dive_manual", size=10):
response = self.client.search(
index=index,
body={
"query": {
"semantic": {
"field": "semantic_content",
"query": query
}
}
},
size=size
)
return "\n".join([hit["_source"].get("body", "No Body")
for hit in response["hits"]["hits"]])第二个工具是 Googler 类,它调用 Google Custom Search API 执行一般的网页搜索。
class Googler:
def __init__(self):
self.service = build('customsearch', 'v1', developerKey=os.getenv("GCP_API_KEY"))
def scrape(self, url):
try:
response = requests.get(url, timeout=10)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
for script in soup(["script", "style"]):
script.decompose()
text = soup.get_text()
lines = (line.strip() for line in text.splitlines())
chunks = (phrase.strip() for line in lines for phrase in line.split(" "))
return '\n'.join(chunk for chunk in chunks if chunk)[:5000]
return None
except:
return None
def search(self, query, n=5):
results = self.service.cse().list(q=query, cx=os.getenv("GCP_PSE_ID"), num=n).execute()
scraped_data = []
for item in results.get('items', []):
url = item['link']
title = item['title']
content = self.scrape(url) or item['snippet']
scraped_data.append(f"Page: {title}\nURL: {url}\n\n{content}\n")
return "\n".join(scraped_data)然后我为 agent 创建了一组工具。每个工具的描述是 prompt engineering 的重要部分,因为 agent 在选择用于响应用户查询的工具时主要会参考这些描述。
tools = [
Tool(
name="WebSearch",
func=lambda q: googler.search(q, n=3),
description="Search the web for information. Use for current events or general knowledge or to complement with additional information."
),
Tool(
name="NavyDiveManual",
func=lambda q: elastic.search(q, index="us_navy_dive_manual"),
description="Search the Operations Dive Manual. Use for diving procedures, advanced or technical operational planning, resourcing, and technical information."
),
Tool(
name="DivingSafetyManual",
func=lambda q: elastic.search(q, index="diving_safety_manual"),
description="Search the Diving Safety Manual. Use for generic diving safety protocols and best practices."
)
]接下来,我使用 AzureChatOpenAI 抽象定义一个 LLM:
llm = AzureChatOpenAI(
azure_endpoint=os.getenv("AZURE_OPENAI_ENDPOINT"),
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
api_version=os.getenv("AZURE_OPENAI_API_VERSION"),
deployment_name=os.getenv("AZURE_OPENAI_MODEL"),
streaming=False
)并且为 LLM 创建一个自定义 prompt,告诉它如何使用这些工具及其输出。
prompt = PromptTemplate.from_template("""Answer the following questions as best you can. You have access to the following tools:
{tools}
You should use multiple tools in conjunction to promote completeness of information.
Be comprehensive in your answer.
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Question: {input}
{agent_scratchpad}""")最后,我定义了 agent,将 LLM、prompt 和工具集传入,并将其集成到其余的 UI 中。
agent = create_react_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=False)到此,我们就可以测试我们的 agent 知识库了。
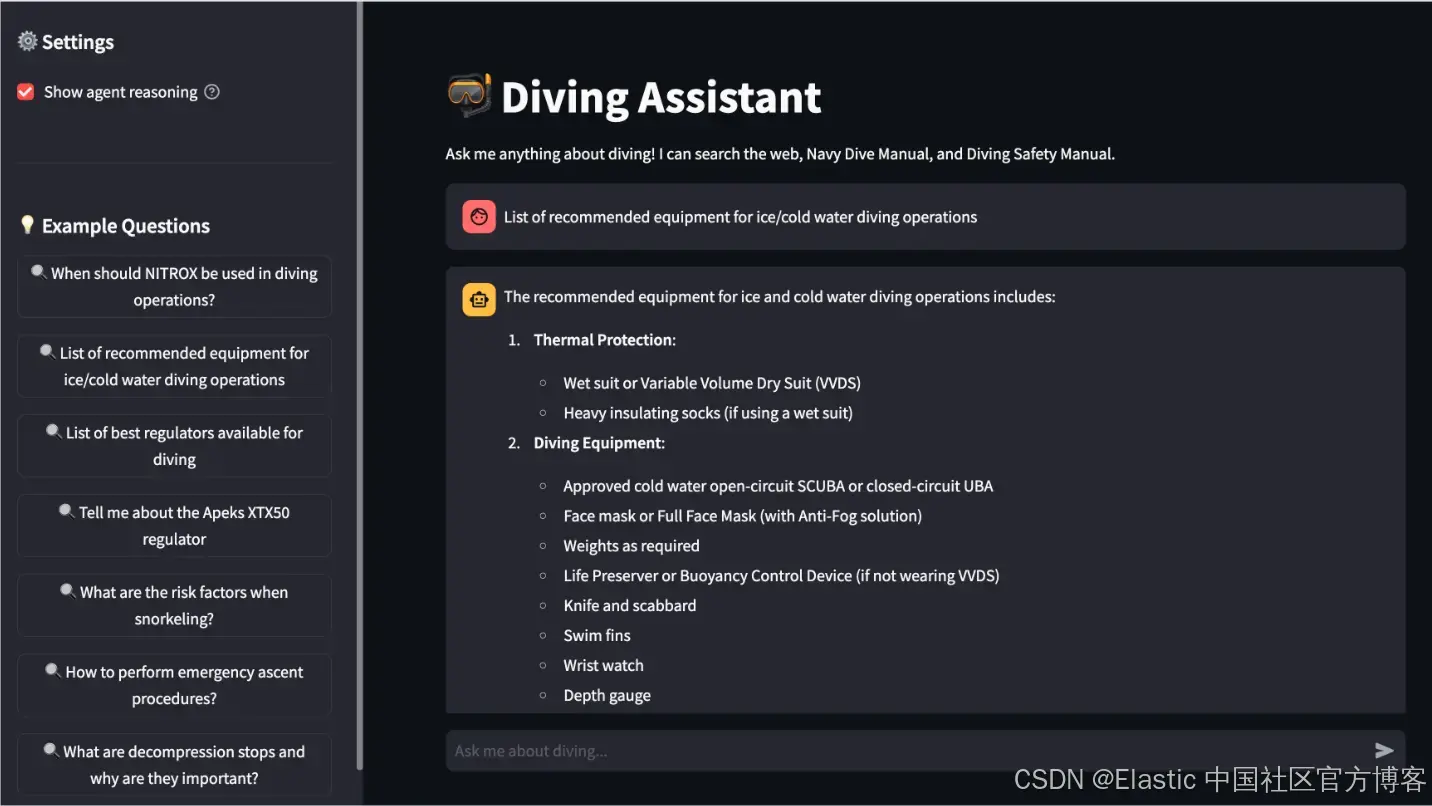
为 agentic 知识库实现的 UI。
测试 1:从特定知识库检索知识
首先,我们应测试知识库组件是否按预期工作。让我们从提出一个详细的技术问题开始。agent 应该选择正确的知识库,检索一些信息,并用它来生成回答。
List of recommended equipment for ice/cold water diving operationsUI 显示了 Agent 的思考过程,它的第一个想法是查阅潜水安全手册:
Thought: To provide a comprehensive list of recommended equipment for ice
or cold water diving operations, I should consult specialized diving
manuals that cover operational procedures and safety protocols.
This will ensure that I include all necessary items for safety and
efficiency in such challenging environments.
Action: NavyDiveManual
Action Input: "recommended equipment for ice cold water
diving operations"Agent 使用 NavyDiveManual 工具对 us_navy_dive_manual 索引进行语义搜索。结果是如下信息:
CHAPTER 11 — Ice and Cold Water Diving Operations 11-9
A detailed reconnaissance of the dive site will provide the
planner with information that is helpful in deciding what ancillary equipment is
required. Diving under ice will require special accessory equipment such as a line
with lights/strobes for under water navigation, ice-cutting tools, platforms, engine
protection kits, and stainless steel ice screws, quick draw, and carabineers.
The method of cutting the hole through the ice depends on ice thickness and availability
of equipment. Normally, two or more of the following tools are used: hand
ice chipper, ice handsaw, ice auger, chain saw, thermal ice cutter or blasting equipment.
In addition, equipment to lift the ice block, remove the slush, and mark ...LLM 然后使用这些信息生成回答:
The recommended equipment for ice and cold water diving operations includes:
Thermal Protection:
* Wet suit or Variable Volume Dry Suit (VVDS)
* Heavy insulating socks (if using a wet suit)
* Diving Equipment:
* Approved cold water open-circuit SCUBA or closed-circuit UBA回答正是我们想要的,太好了!
测试 2:迭代优化知识收集
下一个测试是看看 agent 是否能选择多个知识来源来优化其回答。让我们提出一个更开放性的问题:
What are the risk factors when snorkeling?Agent 的第一个想法是搜索 Google,以获取关于风险因素和危险的具体信息:
Thought: To provide a comprehensive answer to the risk factors associated with snorkeling,
I should gather information on general safety protocols and specific risks from both diving
and snorkeling perspectives. I will start by searching for general snorkeling risks and
then look into specific safety guidelines related to diving and snorkeling.
Action: WebSearch
Action Input: "risk factors when snorkeling"这会返回如下网页结果:
Factors Contributing to Snorkel Drowning in Hawai'i - PMC
URL: https://pmc.ncbi.nlm.nih.gov/articles/PMC8899085/
Causes of the extraordinarily high and increasing incidence of snorkeler drownings in Hawai'i
have remained unexplained for years. Defining the mechanisms and factors predisposing to
drowning while snorkeling is needed to provide recommendations to substantially mitigate
the incidence of this form of preventable death. The mechanisms of drowning are described
and insight into the predisposing factors are explored in this study...然后 agent 选择查阅 diving_safety_manual,并采取相应操作来获取安全规程和指导方针。
Action: DivingSafetyManual
Action Input: "snorkeling safety protocols"这会从 DivingSafetyManual 工具返回相关信息:
Pre-Snorkel briefing
Immediately before snorkelling commences, and using site diagrams or
photos as appropriate, the snorkeller supervisor should emphasise
the following points:
• On-site environmental conditions
• Boundaries of the snorkelling area
• Times when snorkelli ng is being conducted
• Specific site hazards
• Location of lookout
• Emergency and recall signals
• Buddy and guided group procedures最后,LLM 提供了一个全面的回答,包含风险因素和安全指导方针:
The risk factors when snorkeling include:
Environmental Conditions: Strong currents, waves, and marine life can pose
immediate threats. Snorkelers should be aware of local weather and water
conditions before entering.
Physical Fitness: Snorkeling is a strenuous activity that can be
challenging for individuals with pre-existing medical conditions
such as heart disease, respiratory issues (e.g., asthma), or those
who are not strong swimmers.
...
To mitigate these risks, snorkelers should engage in pre-snorkel briefings,
wear personal flotation devices, ensure proper equipment checks, and
maintain awareness of their environment and physical limits.测试 3:搜索超出范围的问题
最后一个测试是看看当用户提出的问题明显超出已准备知识库的范围时会发生什么。让我们询问一个特定的潜水产品:
Tell me about the Apeks XTX50 regulatorAgent 的第一个想法是查找外部网页以获取相关信息:
Thought: I need to gather information about the Apeks XTX50 regulator,
including its features, specifications, and performance in diving conditions.
I will begin with a web search for comprehensive details.
Action: WebSearch
Action Input: "Apeks XTX50 regulator review features specifications"它从商业网站和潜水爱好者网站中发现了大量信息,并返回了技术规格和用户反馈:
The Apeks XTX50 is a high-performance scuba diving regulator designed for
divers who seek reliability and advanced features at a moderate price point.
Here are the key features and specifications:
Features:
First Stage:
Utilizes the DST (Diver Adjustable) first stage with an environmentally
sealed design to prevent water ingress. Over-balanced diaphragm technology
provides superior performance as divers descend, with medium pressure gas
increasing faster than ambient pressure.
...
Divers appreciate the XTX50's reliability and comfort, making it a popular
choice for both recreational and technical diving.
The regulator is lauded for its performance in colder conditions, with
many users noting its effectiveness during deep dives.
Some divers have raised concerns about the availability of parts for maintenance,
as Apeks does not sell parts directly to consumers.
... Agent 没有选择搜索关注操作规划的 US Navy Dive Manual,也没有使用 DivingSafetyManual。
结论
在传统的 RAG 实现中,我们可能会选择强制 LLM 同时搜索并使用所有三个数据源的信息,但这会因为引入无关信息的噪声而降低准确性。使用 agentic 知识库,我们可以看到 LLM 根据用户意图和上下文针对性地搜索特定的知识源。agent 能够通过在初始搜索的基础上整合从其他来源收集的信息来优化知识收集。
Agent 还能够处理超出其准备数据范围的问题,同时能够排除与查询无关的知识库 —— 这是对传统 RAG 模型的显著增强。
这个 agent 知识库的概念提供了一种优雅的方式,将多种不同来源整合成一个连贯且全面的系统。下一步可以扩展可执行操作的范围以及可参考信息的多样性。引入事实核查和交叉引用的工作流将有助于整体可靠性,而像计算这样的专业能力工具将是一个非常有趣的探索方向。
原文:https://www.elastic.co/search-labs/blog/agent-knowledge-base-langchain-elasticsearch

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 21
21 0
0- 0



 已为社区贡献176条内容
已为社区贡献176条内容

所有评论(0)