AI大模型基础
人工智能发展经历了从早期符号系统到当前大模型的演进过程。早期AI依赖人工规则(1950s-1980s),统计机器学习(1980s-2010s)实现了数据驱动学习,而深度学习(2012年起)通过神经网络自动提取特征。当前大模型时代(2020年起)以GPT、BERT等为代表,具有通用性强、多模态处理等特点,参数规模达千亿级。大模型通过预训练+微调方式,展现出零样本学习等能力,成为通向AGI(人工通用智
AI与大模型介绍
AI 的总体发展历程
| 阶段 | 时间 | 核心技术 | 特点 |
|---|---|---|---|
| 早期 AI(符号主义) | 1950s–1980s | 规则系统、专家系统 | 人工编规则,推理逻辑强,通用性差 |
| 统计机器学习 | 1980s–2010s | SVM、KNN、决策树、Naive Bayes | 模型从数据中学习,泛化更强 |
| 深度学习崛起 | 2012–至今 | CNN、RNN、Transformer | 端到端、自动提特征,突破图像/语音/NLP |
| 大模型时代 | 2020–至今 | GPT、BERT、Diffusion、多模态 | 预训练+微调,通用智能趋势 |
从机器学习到深度学习
机器学习(Machine Learning)
机器学习是从数据中学习模型的技术。典型流程:
- 人工提取特征(Feature Engineering)
- 输入特征给模型(如 SVM、逻辑回归、随机森林)
- 模型学习输入与输出的映射关系
示例模型:
- 监督学习:KNN、SVM、决策树、随机森林
- 无监督学习:K-Means、PCA
- 强化学习:Q-Learning
局限:
- 需要手工设计特征(如图像的边缘、颜色直方图)
- 对复杂结构数据(图像、语音、语言)学习能力差
深度学习(Deep Learning)
深度学习是以神经网络为核心的学习方式,它能够自动从原始数据中提取特征。
技术转折点:
- 2012 年 AlexNet 赢得 ImageNet 图像识别比赛,误差骤降,深度学习进入主流
- 利用 GPU、大数据训练多层神经网络
- 后续演变出 CNN、RNN、LSTM、Transformer 等模型
核心优势:
- 不再依赖人工特征设计
- 能直接处理图像、语音、文本等原始数据
- 越大越强,规模化带来性能跃迁
- 机器学习与深度学习对比
机器学习与深度学习对比
| 项目 | 机器学习(ML) | 深度学习(DL) |
|---|---|---|
| 特征提取 | 人工提取 | 自动学习 |
| 模型复杂度 | 中等 | 极高(百万~十亿参数) |
| 数据需求 | 相对较少 | 需要大规模数据 |
| 硬件依赖 | 低 | 高(依赖 GPU/TPU) |
| 应用范围 | 结构化数据 | 图像、语音、NLP 等非结构化数据 |
从深度学习到大模型
深度学习瓶颈
| 问题 | 描述 |
|---|---|
| 任务特定 | 模型只能解决一个任务,迁移性弱 |
| 监督学习依赖强 | 训练需要大量标注数据 |
| 推理能力差 | 缺乏常识和复杂推理 |
| 模型小、单一 | 模型参数百万级,能力受限 |
大模型时代的三大转变
| 项目 | 深度学习时代 | 大模型时代 |
|---|---|---|
| 模型规模 | 百万到千万参数 | 数十亿到数千亿(甚至万亿) |
| 训练方式 | 监督学习 | 自监督 + 大数据预训练 |
| 模型能力 | 专用 | 通用(多任务、多模态) |
大模型的核心特点
| 特点 | 描述 |
|---|---|
| 通用性强 | 一个模型可以应对 NLP 多个任务,甚至图像、语音等模态 |
| Few-shot / Zero-shot 能力 | 无需训练或仅需少量样本就能解决新任务 |
| 可拓展性 | 模型越大越强,性能近似线性增长(Scaling Laws) |
| 多模态能力 | 支持文本、图像、音频、视频等输入输出(GPT-4o、Gemini) |
| 工具化能力 | 能调用外部工具(如搜索、计算器、API) |
大模型引发的变革
| AI 2.0(深度学习) | AI 3.0(大模型) |
|---|---|
| 训练任务特定模型 | 训练通用基础模型 |
| 依赖标签 | 使用自监督数据 |
| 小模型拼接多系统 | 单一大模型解决多任务 |
| 专家调参 | 自动对齐、人类反馈训练 |
AGI
AGI(Artificial General Intelligence,人工通用智能) 指的是一种:能像人类一样完成任意智能任务,能进行跨任务迁移、推理与学习,具有持续学习、自我反思、动机与规划能力 的智能系统。
简单说:AGI ≠ 只能对话/写代码/生成图像,而是能像人一样通用地理解世界和解决问题。
大模型与 AGI 的关系图谱
| 方面 | 大模型(LLMs) | AGI |
|---|---|---|
| 通用性 | 高,跨任务能力强 | 极高,任意任务都能适应 |
| 推理能力 | 有限(依赖上下文) | 强,能自主构建知识链 |
| 学习能力 | 静态模型,需微调 | 持续学习,自适应变化 |
| 记忆能力 | 上下文窗口临时记忆 | 长期记忆 + 知识持久化 |
| 意图/动机 | 无真正意图 | 有目标、有自我决策能力 |
| 工具能力 | 通过函数调用拓展 | 工具内化、灵活使用 |
| 自我反思 | 无 | 有元认知(知道自己知道什么) |
大模型是AGI的阶段
人工智能 → 机器学习 → 深度学习 → 大模型 → 智能体(Agent)→ AGI
- 大模型是逼近 AGI过程中的基础能力载体
- 如果说 AGI 是目标,那么 大模型 + Agent 架构 + 工具能力 + 记忆系统 是通往它的路径
AIGC
AIGC(AI-Generated Content),即 “人工智能生成内容”,指的是通过 AI(尤其是生成式模型)自动生产文本、图像、音频、视频、代码等数字内容 的过程。
- AIGC = AI Generated Content
- 属于 内容创作方式的一种范式变革
- 相对传统内容(人创作)与 PGC(专业内容)/UGC(用户内容)
AIGC 的典型内容类型
| 类型 | 示例 | 常用模型 |
|---|---|---|
| 文本生成 | 写文章、写诗、摘要、对话 | Gemini, GPT-4, Claude, GLM |
| 图像生成 | 插画、头像、壁纸、设计图 | Gemini, DALL·E, Midjourney, SD |
| 音频生成 | 背景音乐、配音、拟人声音 | Gemini, MusicLM, TTS 模型 |
| 视频生成 | 动态广告、数字人、短片 | Gemini, Sora (OpenAI), Runway |
| 代码生成 | 自动补全、脚本生成 | Gemini, Copilot, CodeWhisperer |
| 3D生成 | 模型、数字资产 | Gemini, DreamFusion, GET3D |
AIGC 背后的技术基础
| 技术层 | 代表 |
|---|---|
| 模型架构 | Transformer, Diffusion Model |
| 训练范式 | 自监督预训练、RLHF、人类对齐 |
| 多模态融合 | 文本 + 图像、语音 + 视频 |
| 工具链 | Prompt 编写、API调用、模型微调 |
| 基础设施 | GPU、TPU、vLLM、LoRA、推理加速器 |
AIGC 与大模型、AGI 的区别和联系
| 概念 | 定义 | 关系 |
|---|---|---|
| AIGC | AI 生成的内容 | 是大模型的 直接应用产物 |
| 大模型 | 基础语言/图像模型 | 为 AIGC 提供核心能力(如 GPT) |
| AGI | 通用人工智能 | AIGC 是它可掌握的“技能”之一,但远非全部 |
可以理解为大模型是“发动机”,AIGC是“发动机驱动下的应用(车),AGI是“驾驶员”——能开车、会换挡、能理解上下文目的地。
AI应用场景
自然语言处理(NLP)
自然语言处理是目前最广泛的 AI 应用领域之一,依托大语言模型的能力,实现文本理解、生成、对话、信息提取等多种功能。
核心应用
| 应用方向 | 场景 | 说明 |
|---|---|---|
| 文本生成 | 内容创作、摘要撰写、对联、写稿 | ChatGPT、AI写作 |
| 对话系统 | 智能客服、企业机器人、语音助手 | 客服对话、知识问答 |
| 情感分析 | 舆情监控、评论分析 | 识别正负面态度 |
| 文本分类 | 垃圾邮件识别、意图识别 | 精准投放、问答意图识别 |
| 命名实体识别 | 人名、地名、组织提取 | 搜索、风控、金融 |
| 机器翻译 | 多语种翻译、实时字幕 | 百度翻译、Google Translate |
| 文档理解 | 法律、合同、财报理解 | 智能标注、知识抽取 |
| 代码生成 | 自动补全、Bug 解释、文档生成 | Copilot、ChatGPT Code Interpreter |
计算机视觉(Computer Vision)
计算机视觉使 AI 能“看懂世界”,目前已广泛应用于工业、安防、医疗、电商、交通等多个行业。
| 应用方向 | 场景 | 说明 |
|---|---|---|
| 图像分类 | 商品识别、动物识别、垃圾分类 | 图像内容打标签 |
| 目标检测 | 安防监控、人脸识别、车辆检测 | YOLO、Faster-RCNN |
| 图像分割 | 医疗图像(器官、肿瘤)、道路检测 | Pixel级识别,CV高精应用 |
| OCR | 发票识别、证件扫描、文本识别 | 实现图文转化 |
| 行为识别 | 店内轨迹分析、工地安全监测 | CV + 视频分析 |
| 图像生成 | AI画画、设计草图、插画创作 | Midjourney、DALL·E、SD |
| 图像搜索 | 以图搜图、电商找相似款 | 百度识图、淘宝识图 |
| 视频分析 | 安全监控、交通流量分析 |
语音识别与合成(ASR & TTS)
语音识别(ASR)
| 应用方向 | 场景 | 说明 |
|---|---|---|
| 语音转文字 | 会议记录、采访整理、语音备忘 | 腾讯听听、小爱同学录音整理 |
| 语音搜索 | 智能遥控器、车载语音 | 语音搜索比键入更快捷 |
| 多语种识别 | 中英混说、会议翻译 | 支持全球多语言实时转写 |
| 通话分析 | 客服质检、情绪识别、关键字提取 | 呼叫中心语音挖掘 |
| 医疗记录 | 医生口述病历自动录入 | 提高诊室效率与准确性 |
语音合成(TTS)
| 应用方向 | 场景 | 说明 |
|---|---|---|
| 虚拟人配音 | 数字员工、短视频 AI 主播 | 阿里“云小蜜”、科大讯飞 TTS |
| 导航播报 | 车载语音、地图导航 | 高德地图语音合成 |
| 情感合成 | 不同语调、情绪的语音输出 | 模仿主播、明星语音 |
| 个性语音定制 | 模拟用户声音、训练私有音色 | 数字遗嘱、数字人声音克隆 |
| 阅读辅助 | 新闻朗读、有声书 | 喜马拉雅、讯飞有声合成平台 |
三者融合场景(NLP + CV + 语音)
| 应用场景 | 涉及技术 | 说明 |
|---|---|---|
| 多模态问答 | CV + NLP | 看图问答(如文心一言、GPT-4o) |
| 视频字幕生成 | CV + ASR + NLP | 自动转字幕、翻译、多语合成 |
| 数字人 | TTS + NLP + CV | 虚拟形象对话、AI 主播、讲解员 |
| 智能会议助手 | ASR + NLP + Summarization | 自动会议纪要,关键词提取 |
| 智能驾驶舱 | CV + ASR + TTS | 人脸识别 + 语音交互 + 驾驶辅助 |
应用领域案例汇总(按行业)
| 行业 | 典型 AI 应用 |
|---|---|
| 教育 | 语音评测、作文批改、智能讲题 |
| 医疗 | 影像识别、病例录入、医学 NLP |
| 金融 | 智能风控、客服机器人、报表生成 |
| 零售 | 图像识别收银、语音客服、广告创意生成 |
| 政务 | 智能问答、证件识别、舆情监测 |
| 安防 | 人脸布控、异常行为检测 |
| 交通 | 车流量分析、语音导航 |
| 内容创作 | 文案生成、AI 画图、视频剪辑 |
大模型架构
Transformer 架构
参考文档:https://www.runoob.com/nlp/transformer-architecture.html
公众号文章:https://mp.weixin.qq.com/s/bQE58LII4nXvO2hkjlYvsw
BERT 模型
参考文档:https://www.runoob.com/nlp/bert-encoder.html
公众号文章:https://mp.weixin.qq.com/s/0wA8BMGrJxWYDu0HAl7Bhg
GPT 架构
参考文档:https://www.runoob.com/nlp/generative-pre-trained-transformer.html
公众号文章:https://mp.weixin.qq.com/s/S-gdaAn3izW2NC70-MZjuw
MoE 模型
公众号文章:https://mp.weixin.qq.com/s/I9L3Ldw6s5Ui3vbPX5g8mw
大模型术语
大模型工作流程
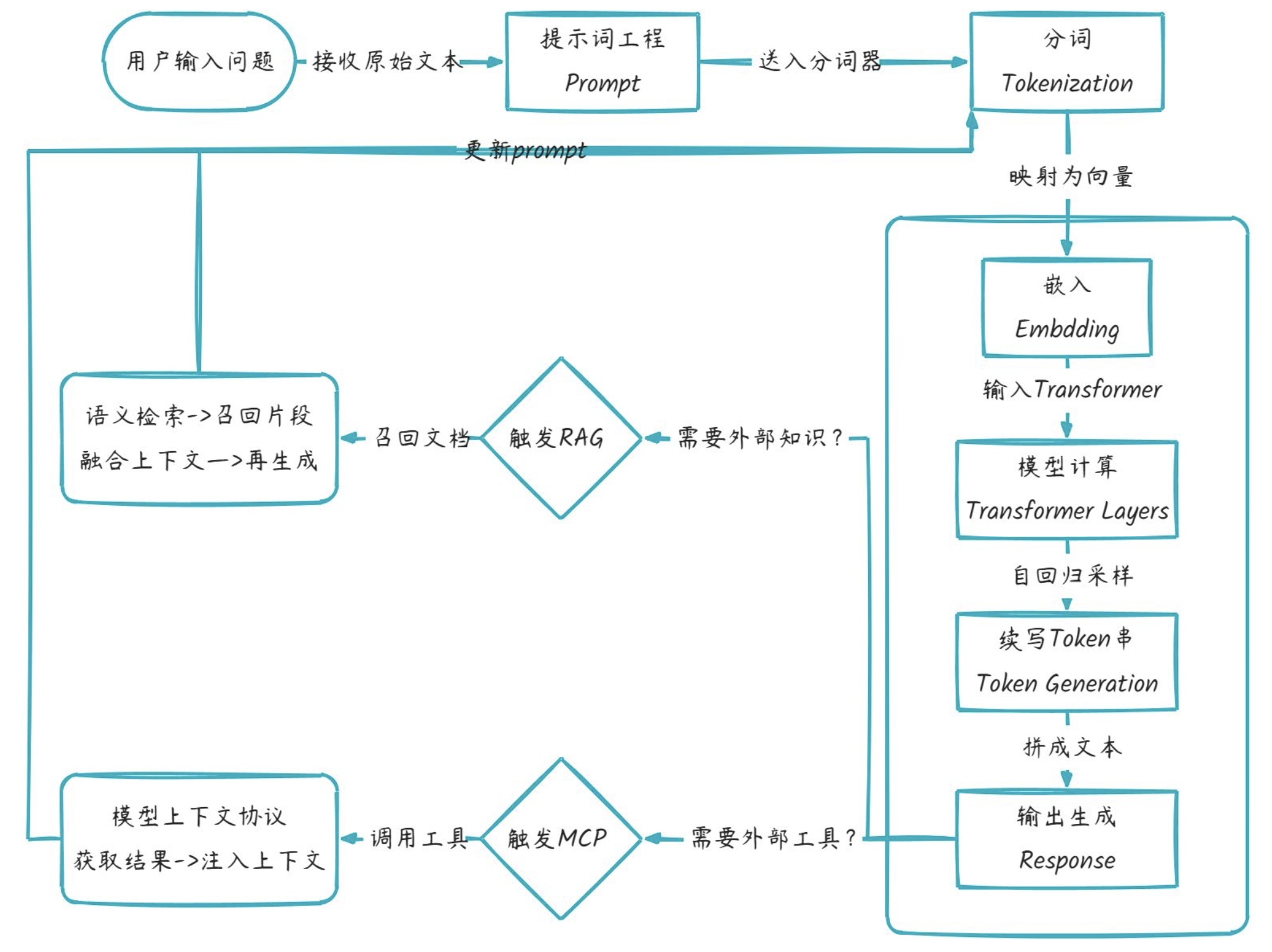
| 环节 | 解释 |
|---|---|
| 提示词 Prompt | 用户给模型的“任务指令”,决定后续所有 token 的生成方向。 |
| 分词 Tokenization | 把文本切成模型字典里有编号的最小片段(token),供向量层查表。 |
| 嵌入 Embedding | 将每个 token 编号映射成高维向量,使语义相近的词在向量空间靠得更近。 |
| 模型计算 Transformer Layers | 多层自注意力 + 前馈网络对整句向量做并行计算,输出每个位置的上下文语义向量。 |
| 续写 token 串 Token Generation | 以上一步的向量为基础,逐个采样下一个 token,自回归拼成完整回答。 |
| RAG | 检索增强生成,结合外部知识库进行语义检索并增强生成质量。 |
| MCP | 模型上下文协议,允许模型调用外部工具或服务(如 API、数据库)扩展能力。 |
模型参数类型
稠密模型(Dense Model)
定义:在推理或训练时,所有参数都会被参与计算。
特点:
- 每一层的参数都“稠密连接”在一起
- 每个输入都会激活所有权重(没有参数被“跳过”)
优点:
- 结构简单,训练和推理逻辑清晰
- 对小规模模型和常规任务效果稳定
缺点:
- 参数量大 → 推理计算和显存占用高
- 无法做到“部分参数参与计算”以节省资源
稀疏模型(Sparse Model)
定义:在推理或训练时,只有部分参数被激活,其余参数不参与计算。
常见形式:
- 权重稀疏化:把部分权重设为零(例如通过剪枝 pruning),减少计算量
- 激活稀疏化:某些神经元只有在特定输入下才被激活
优点:
- 提升计算效率,降低显存和算力需求
- 仍能保持较高精度
缺点:
- 稀疏化的效果和方法依赖任务,可能影响模型表现
- 工程上需要专门的稀疏计算库支持
MoE 模型(Mixture of Experts)
定义:又称混合专家模型,一种 稀疏化的特殊形式。模型内部包含多个“专家子网络”(Experts),每个输入 token 只会激活其中一部分专家(而非全部)。
核心机制:
- 门控网络(Gating Network):根据输入内容,选择最合适的专家来处理
- 稀疏激活:例如有 100 个专家,只激活其中 2 个 → 节省计算成本
优点:
- 参数量可以非常大(比如上万亿),但实际计算开销比稠密模型低
- 不同专家可以专注于不同知识领域(比如数学专家、代码专家)
缺点:
- 训练难度大(负载均衡问题,容易出现部分专家过载)
- 工程复杂度高(需要专门的分布式训练策略)
| 维度 | 稠密模型 | 稀疏模型(广义) | MoE(稀疏的一种) |
|---|---|---|---|
| 激活比例 | 100% | <10% | 通常 Top-1 或 Top-2 专家 |
| 参数总量 | = 激活量 | >>激活量 | 同左,易破百亿/千亿 |
| 计算量 FLOPs | 高 | 低 | 低(与稀疏一致) |
| 显存占用 | 中 | 高(存全套参数) | 高(存全套专家) |
| 通信开销 | 无 | 低 | 高(需跨设备传专家) |
| 训练难度 | 低 | 中 | 高(负载均衡、门控学习) |
| 代表模型 | GPT-3/LLaMA | 无普遍开源 | Switch-Transformer、GLaM、PaLM-E、DeepSeek-MoE |
模型压缩加速
蒸馏模型(Model Distillation)
定义:模型蒸馏(Knowledge Distillation)是一种 模型压缩技术,就好比“老师教学生”——用大模型(Teacher)的输出当“软标签”,训练一个小模型(Student)模仿行为,参数变少,精度尽量保留。
- 用一个大而强的模型(教师模型 Teacher)指导一个小模型(学生模型 Student)的训练。
- 学生模型学习的不仅是训练数据的标签,还要模仿教师模型的 输出分布(soft targets)。
原理
- 教师模型输出一个“软概率分布” (softmax + 温度参数)
- 学生模型通过最小化与教师分布的差异来学习知识
- 最终得到一个更小、更快,但性能接近的学生模型
优点
- 大幅降低模型大小和推理延迟
- 在移动端、边缘设备部署更容易
- 保留大部分性能
缺点
- 蒸馏效果依赖教师模型的质量
- 蒸馏过程需要额外训练,成本不低
典型应用
- BERT → DistilBERT(小一半参数,保留 ~95% 性能)
- GPT 系列在移动端的轻量化版本
量化模型(Model Quantization)
定义:模型量化是一种 模型推理加速和压缩技术,就好比“削精度减位数”——把权重/激活的浮点 32 位→16/8/4 位整数,存储↓、计算↓、显存↓,直接跑在端侧芯片。
- 将模型参数(权重、激活值)从高精度浮点数(如 FP32)压缩到低比特表示(FP16、INT8、INT4 甚至二值)。
常见方法
- Post-Training Quantization (PTQ):训练后直接量化,不需要重新训练
- Quantization-Aware Training (QAT):训练过程中就引入量化,效果更好
- List item
- 混合精度(Mixed Precision):部分关键层保持高精度,其他层用低精度
优点
- 显著减少显存占用(FP32 → INT8 可减 4 倍)
- 提升推理速度(尤其在支持低精度算子的硬件上,如 GPU Tensor Cores / TPU / NPU)
- 能与剪枝、蒸馏结合使用
缺点
- 精度可能下降(尤其在极端低比特时,如 INT4)
- 对硬件依赖较强(要支持低比特计算)
典型应用
- INT8 BERT、GPTQ(量化 LLM)
- LLaMA、Qwen 等开源大模型常见的 4bit/8bit 量化版本,用于个人显卡部署
| 维度 | 知识蒸馏 | 量化 |
|---|---|---|
| 目标 | 模型结构变小 | 权重位数变少 |
| 参数量 | 减少(Student 网络更瘦) | 不变(只是精度压缩) |
| 存储体积 | ↓↓(结构剪完再量化可叠加) | ↓↓(通常 4× 或 8×) |
| 计算加速 | 依赖小模型结构 | 依赖整数单元/专用指令 |
| 精度损失 | 可控(跟 Teacher 差距) | 可控(INT8 几乎无损,INT4 需精细调) |
| 是否需要原模型 | 需要 Teacher 在线/离线推理 | 不需要,可后训练直接压 |
| 代表方案 | MiniLLaMA、DistilBERT、TinyGPT | LLM.int8()、GPTQ、AWQ、KV-cache 量化 |
大模型训练
想象一下你是一位图书管理员,要为AI建造一座包含全人类知识的图书馆,训练好的模型就像整整齐齐装满知识的图书馆。
训练过程就是
- 收集材料:把海量本书(如维基百科、小说、论文)堆进仓库
- 制定规则:教会AI识别词语关系(比如"猫追老鼠"中"追"代表动作关系)
- 反复练习:让AI猜下一句话是什么,猜错就调整记忆库(参数),直到能基本猜对(这个不同大模型准确率不一样,一般都会有评测)。
训练的本质:通过海量训练数据(tokens)调整模型参数(权重、偏置等),让模型学会语言规律和常识。
就像教婴儿认字——先看百万张图片,逐渐理解"猫"对应毛茸茸的动物。
大模型训练再细分的话分为预训练和后训练。
大模型预训练
大模型预训练(Pre-training):模型在大规模通用数据上首先进行无监督或自监督训练,学习通用知识、语义和基本能力。
例如DeepSeek-V3-Base、DeepSeek-V2、DeepSeek-Coder V1未经过任何微调,是预训练大模型。
大模型后训练
大模型后训练 (Post-training):是在预训练模型基础上,通过人类反馈(SFT/RL)优化行为,使其符合特定需求如人类偏好。
例如DeepSeek-V3、DeepSeek-R1系列、DeepSeek-Coder V2、DeepSeek-VL2都是后训练大模型。
| 维度 | 预训练模型 | 后训练模型 |
|---|---|---|
| 目标 | 学习语言通用规律 | 对齐人类偏好,专精任务 |
| 数据 | 无标注文本(万亿级) | 带标注指令/偏好数据(百万级) |
| 典型技术 | MoE架构、FP8混合精度 | GRPO强化学习、思维链蒸馏 |
| 输出特点 | 通用文本生成 | 结构化答案、分步推理 |
大模型微调
微调其实也是模型后训练的一种方法。 只是后训练通常由模型提供商负责,会在出厂前进行预训练和后训练,以便把模型打造成可交付的状态,而微调这种后训练,一般由模型使用者(甲方自己的技术团队或技术厂商)进行,以便实现领域垂直大模型。
例如通用模型已掌握医学基础知识(如解剖学名词),但要做心脏手术还需专项训练
定向输入:给模型海量心脏病例和手术记录(特定领域数据)
专家经验(示范):展示优秀医生的诊断思路(带答案的例题,即问答对)
模拟考核:让模型诊断病例并评分,重点纠正误诊(模型评价)
微调本质:在预训练模型上,用少量专业数据(如1%原数据量)调整部分参数。就像让全科医生专攻心血管科——保留基础能力(如问诊技巧),强化专科知识(如心电图解读)。
微调后的模型能像资深医生一样,根据症状精准判断病因 。
微调的方法有很多种,常用方法有:
全量微调
全量微调是在预训练模型的基础上,对所有参数进行微调。在参数修改方面,所有参数都会被更新。其优点显著,能够充分利用预训练模型的通用知识,同时针对特定任务进行优化,通常可以获得较好的性能。
然而,该方法也存在明显不足,计算资源需求较高,尤其是对于参数量非常大的模型来说,这一问题更为突出;训练时间较长,而且在数据量较少的情况下,可能会导致模型过拟合。
参数高效微调
参数高效微调的核心是只对模型的一部分参数进行微调,保持大部分参数不变,这使得它在资源利用上更加高效。
以下是几种常见的参数高效微调方法:
LoRA(Low-Rank Adaptation)
LoRA 通过低秩分解来调整模型的权重矩阵,只训练少量的新增参数。这种方法的优点是计算资源需求低,训练时间短,并且保留了预训练模型的大部分知识。不过,其缺点是可能达不到全量微调的性能。
Prefix-Tuning
Prefix-Tuning 在模型的输入端添加可训练的前缀,这些前缀参数在微调过程中被更新。它适用于自然语言生成任务,具有计算资源需求低、训练时间短的优点,但可能需要更多的调参经验。
Adapter
Adapter 在模型的每一层或某些层之间插入可训练的适配器模块,这些适配器参数在微调过程中被更新。该方法计算资源需求低、训练时间短,还可以针对多个任务进行微调,不过同样可能需要更多的调参经验。
BitFit
BitFit 只微调模型的偏置项(bias terms),而不改变权重。其最大优势是计算资源需求极低,训练时间非常短,但性能提升可能有限。
强化学习微调
强化学习微调使用强化学习方法,通过人类反馈或其他奖励信号来优化模型,模型参数会根据奖励信号进行更新。它的优点在于可以优化模型的交互行为,特别是在对话系统等交互式任务中,还能更灵活地调整模型的行为以满足特定的业务需求。但该方法实现复杂,需要设计合适的奖励机制,且训练过程可能不稳定,需要更多的调试和监控。
提示调优
提示调优通过冻结整个预训练模型,只允许每个下游任务在输入文本前面添加可调的标记(Token)来优化模型参数,仅更新提示部分的参数。它具有计算资源需求低、训练时间短的优点,适用于少样本学习任务。不过,其可能达到的性能可能略低于全量微调,且需要精心设计提示。
深度提示调优
深度提示调优在预训练模型的每一层应用连续提示,而不仅仅是输入层,同样只更新提示部分的参数。这种方法可以在更深层次上优化模型,提高性能,适用于复杂任务,但实现复杂,需要更多的调参经验。
动态低秩适应
DyLoRA 在 LoRA 的基础上,动态调整低秩矩阵的大小,动态调整低秩矩阵的大小,只更新部分参数。它计算资源需求低,训练时间短,可以在更广泛的秩范围内优化模型性能,但实现复杂,需要更多的调参经验。
自适应低秩适应
AdaLoRA 根据权重矩阵的重要性得分,自适应地分配参数规模,根据重要性动态调整参数规模,只更新部分参数。该方法计算资源需求低,训练时间短,可以更高效地利用参数,提高模型性能,但同样存在实现复杂、需要更多调参经验的问题。
量化低秩适应
QLoRA 结合 LoRA 方法与深度量化技术,减少模型存储需求,同时保持模型精度,只更新部分参数,同时进行量化。它计算资源需求低,训练时间短,适用于资源有限的环境,但实现复杂,需要更多的调参经验。
大模型推理
大模型推理好比"教AI玩解谜游戏"——就像你给一个拥有全人类知识库的AI玩家,让它通过拆解线索、组合逻辑碎片,最终拼出完整答案的过程。
当用户问"如何用大象称体重?",推理过程如同:
(1) 线索搜集:激活“大象-体重-称量”相关记忆(如阿基米德浮力原理)
(2) 逻辑推演:
- 第一步:回忆"曹冲称象"故事(类比迁移)
- 第二步:计算船排水量与浮力关系(数学推理)
- 第三步:设计具体操作步骤(工程思维)
(3) 验证优化:检查方案可行性(如大象是否配合),生成分步指导
推理本质:将输入问题拆解为知识图谱中的关联节点,通过Transformer架构的多层计算,最终输出逻辑连贯的答案。就像用千万块拼图(参数)组合出完整图案,过程中不断排除错误组合(如"用蚂蚁称大象"的荒谬方案)。
训练、微调、推理对比总结
| 阶段 | 目标 | 数据量 | 学习方式 | 成果表现 |
|---|---|---|---|---|
| 训练 | 建立基础知识体系 | 百万亿级 | 无监督学习 | 通晓语言和常识 |
| 微调 | 培养专业能力 | 千万级 | 有监督+强化学习 | 专科医生水平 |
| 推理 | 解决具体问题 | 实时输入 | 概率计算 | 生成定制化解决方案 |
大模型部署
单机 TP 模式
定义:Tensor Parallel, 张量并行。在单台机器上,利用多张 GPU 对一个层内部的矩阵乘法等计算进行 张量级拆分。
特点:
- 单层参数被切分到不同 GPU 上执行,比如把权重矩阵横向或纵向分块。
- 各 GPU 并行完成部分计算,再通过通信聚合结果。
适用场景:单机多卡,模型权重大,单卡显存放不下时。
代价:通信量较大(AllReduce/AllGather)。
单机 EP 模式
定义:Expert Parallel, 专家并行。在单机多卡下,部署 Mixture-of-Experts (MoE) 模型时,每张 GPU 只存储部分专家网络(Experts)。
特点:
- 输入 token 会根据路由器 (Router) 分配到相应的专家所在的 GPU。
- 可以显著减少单卡显存占用,提升模型容量。
- 适用场景:MoE 模型(比如 DeepSeekMoE),需要单机就能容纳上百亿以上参数。
代价:需要高效的路由与负载均衡,否则会造成卡间负载不均。
多机 TP 模式
定义:将 张量并行 扩展到多机多卡,跨机器切分权重矩阵。
特点:
- 每层的参数和计算进一步拆分,涉及跨节点通信(一般走高速网络如 InfiniBand)。
- 常和 流水线并行 (PP)、数据并行 (DP) 结合使用。
适用场景:模型超大(百亿 ~ 千亿参数),单机算力不够。
代价:网络通信成为瓶颈,带宽和延迟要求高。
多机 EP 模式
定义:将 专家并行 扩展到多机,每台机器的 GPU 保存不同子集的专家。
特点:
- Router 需要跨机调度 token → 对应专家 → 返回结果。
- 单机放不下所有专家时的必选方案。
适用场景:千亿级 MoE 模型,比如 DeepSeek-R1、GPT-MoE 系列。
代价:跨机通信开销更大,对路由调度系统要求更高。
PD 分离模式
定义:Prefill-Decoding Separation,将推理过程中的 预填充 (Prefill) 和 解码 (Decoding) 阶段拆分到不同的计算节点。
特点:
- 预填充:对输入 prompt 进行一次性计算,耗时长但并行度高。
- 解码:生成阶段,每步依赖上一步结果,序列化强,吞吐低。
- 分离后可按需分配资源,提升整体吞吐。
适用场景:在线服务,既要处理长 prompt,又要保证生成的低延迟。
多 PD Master 模式
定义:多个 Prefill-Decoding Master 节点 共同调度推理请求,避免单点瓶颈。
特点:
- 支持多 Master 协同负载均衡。
- 每个 Master 可独立分配请求到 Prefill / Decode 工作节点。
- 提高可扩展性和容错性。
适用场景:大规模推理服务,海量并发请求,要求高可用。
总结对比
| 模式 | 粒度 | 主要目标 | 典型场景 |
|---|---|---|---|
| 单机 TP | 层内张量切分 | 显存放不下单层 | 单机多卡部署大模型 |
| 单机 EP | 专家分布在单机 | MoE 显存节省 | 小规模 MoE |
| 多机 TP | 跨机张量并行 | 超大模型训练/推理 | 千亿模型 |
| 多机 EP | 专家跨机分布 | MoE 扩展 | 千亿 MoE 模型 |
| PD 分离 | 阶段拆分 | 吞吐优化 | 在线推理 |
| 多 PD Master | 调度层冗余 | 高可用 + 扩展 | 大规模服务 |
GPU
GPU的英文全称Graphics Processing Unit,图形处理单元。
说直白一点:GPU是一款专门的图形处理芯片,做图形渲染、数值分析、金融分析、密码破解,以及其他数学计算与几何运算的。GPU可以在PC、工作站、游戏主机、手机、平板等多种智能终端设备上运行。
GPU和显卡的关系,就像是CPU和主板的关系。前者是显卡的心脏,后者是主板的心脏,显卡不仅包括GPU,还有一些显存、VRM稳压模块、MRAM芯片、总线、风扇、外围设备接口等等。
CPU 与 GPU 区别
CPU和GPU都是运算的处理器,在架构组成上都包括3个部分:运算单元ALU、控制单元Control和缓存单元Cache。
但是,三者的组成比例却相差很大。
在CPU中缓存单元大概占50%,控制单元25%,运算单元25%;
在GPU中缓存单元大概占5%,控制单元5%,运算单元90%。
结构组成上的巨大差异说明:CPU的运算能力更加均衡,但是不适合做大量的运算;GPU更适合做大量运算。
这倒不是说GPU更牛X,实际上GPU更像是一大群工厂流水线上的工人,适合做大量的简单运算,很复杂的搞不了。但是简单的事情做得非常快,比CPU要快得多。
相比GPU,CPU更像是技术专家,可以做复杂的运算,比如逻辑运算、响应用户请求、网络通信等。但是因为ALU占比较少、内核少,所以适合做相对少量的复杂运算。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 14
14 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)