悬壶GPT:中医药领域大语言模型的参数高效微调
本研究构建了包含10万条高质量数据的XhTCM数据集,并基于此开发了中医药专用大语言模型XuanHuGPT。通过参数高效微调技术(PEFT),该模型在准确性、覆盖度、流畅性等多维度评估中显著优于通用大模型和现有中医专用模型,为中医药知识的数字化转型和智能传播提供了可复制的范式。

摘要
本研究构建了包含10万条高质量数据的XhTCM数据集,并基于此开发了中医药专用大语言模型XuanHuGPT。通过参数高效微调技术(PEFT),该模型在准确性、覆盖度、流畅性等多维度评估中显著优于通用大模型和现有中医专用模型,为中医药知识的数字化转型和智能传播提供了可复制的范式。
阅读原文或https://t.zsxq.com/z4rgX获取原文pdf
一、研究背景:大语言模型遇上传统中医药
1.1 大语言模型的领域化趋势
近年来,大语言模型(LLMs)在各专业领域展现出卓越的泛化能力。从金融领域的专业训练模型,到法律应用的Lawyer LLaMA,领域特定的大模型正在重塑各行各业的智能化进程。值得关注的是,大语言模型也为传统中医药文化的保护和传承开辟了全新机遇,为这一历史悠久的领域带来创新应用路径。
1.2 中医药面临的现代化挑战
中医药作为中华文化的重要组成部分,跨越5000多年历史,涵盖了大量经典文献、医案和方剂,凝聚了中华民族数千年的健康智慧。联合国教科文组织已将针灸和藏医药浴列入人类非物质文化遗产名录,《黄帝内经》和《本草纲目》等典籍也被收录进世界记忆名录。特别是在新冠疫情防控中,中医药展现出独特疗效。
然而,传统中医药在现代社会面临诸多挑战:
- 知识传播方式落后
:主要依赖纸质文献和口耳相传,导致信息碎片化
- 数字化平台缺失
:缺乏全面的数字平台限制了中医药知识的可及性和共享
- 公众认知不足
:权威资源获取渠道有限,阻碍了公众对中医药丰富遗产的深入了解
大语言模型的发展为解决这些问题提供了契机。LLMs能够高效处理、翻译和总结中医药文献,实现快速访问关键信息和专业咨询。开发中医药专用大模型,对于推动中医药数字化、知识保护和应用创新至关重要。
二、技术创新:参数高效微调破解训练难题
2.1 传统全量微调的困境
传统的大模型全量微调需要在监督学习过程中更新所有模型权重,这要求:
-
海量的标注数据集
-
庞大的计算资源投入
-
高昂的训练成本
这些要求对于专业领域应用构成了巨大障碍。
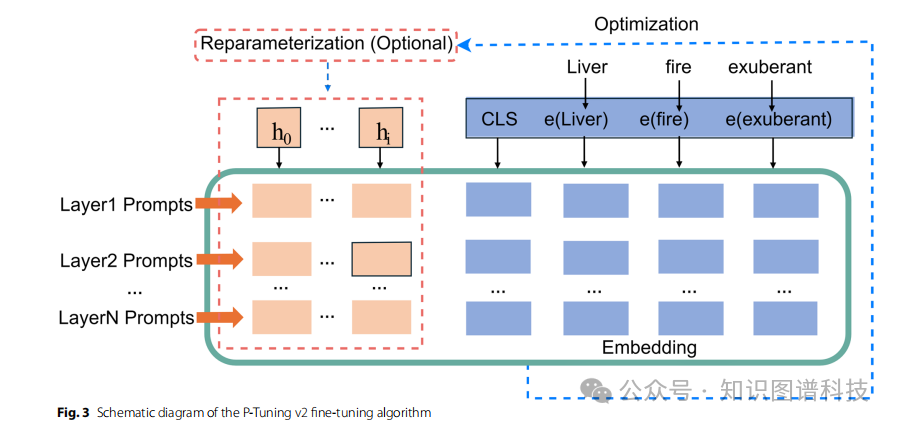
2.2 PEFT技术的突破
参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)技术应运而生。PEFT方法通过以下方式实现突破:
- 减少可调参数
:大幅降低需要训练的参数量
- 降低计算复杂度
:显著减少计算资源需求
- 保持模型性能
:在新任务上提升预训练模型性能的同时最小化训练负担
这种方法不仅提高了效率、缩短了训练时间,还大幅降低了成本,已成为模型优化研究的焦点。例如,GatorTronGPT利用p-tuning技术优化抽象摘要生成,使LLMs能够优先处理关键患者信息并生成高质量摘要。
2.3 XuanHuGPT的技术架构
XuanHuGPT基于开源双语模型ChatGLM2-6B构建,融合了两种参数高效微调方法:
- LoRA(Low-Rank Adaptation)
:通过低秩矩阵分解减少可训练参数
- P-Tuning v2
:优化提示学习机制
这些技术显著降低了训练资源需求,同时保持了强大的模型性能。
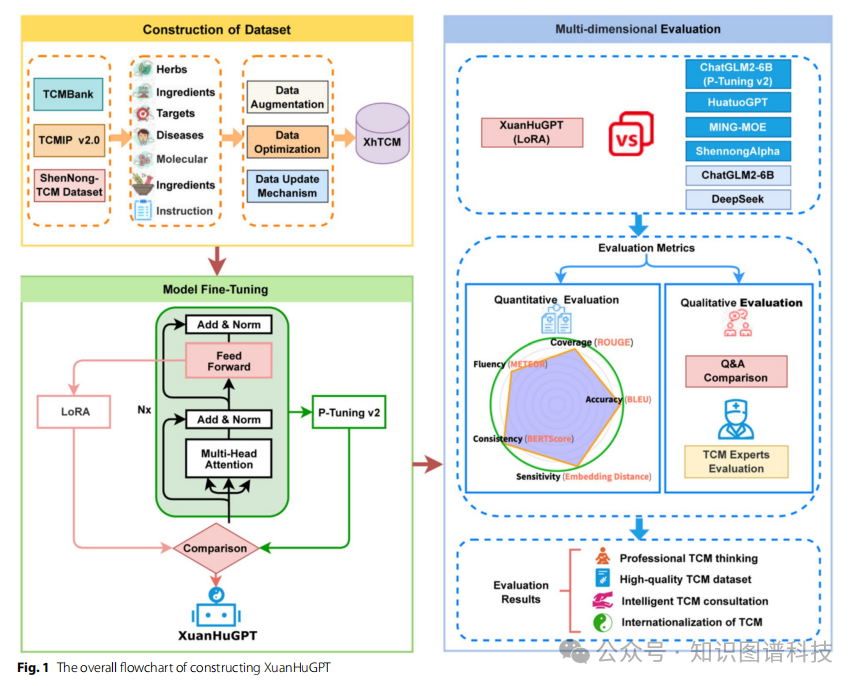
三、数据基石:XhTCM数据集的构建
3.1 数据来源与整合
XhTCM数据集通过系统整合三个权威数据源构建而成:
- ShenNong_TCM_Dataset
:经典中医理论数据
- TCMBank
:中药药理数据
- TCMIP v2.0
:现代临床实践数据
数据集包含10万条结构化条目,涵盖:
-
经典理论
-
方剂配伍
-
中药药理
-
现代临床实践
确保了中医药知识的广度和深度。
3.2 数据优化技术
3.2.1 RAG技术增强
检索增强生成(Retrieval-Augmented Generation, RAG)技术用于解决模型知识局限、幻觉问题和数据安全等挑战。通过从专有领域数据库检索相关信息并整合到提示模板中,RAG将私有数据作为数据提示提供给大语言模型,从而减少生成式AI的幻觉现象并增强生成能力。
研究团队利用LangChain-Chatbot框架,将ChatGLM与预处理数据集结合,构建了中医药问答生成模型。从该模型生成的高质量中医药问答对被筛选出来,进一步丰富了数据集。
3.2.2 ChatGLM自对话增强
ChatGLM被用于自对话,自动生成高质量的多轮对话数据集,增强了数据集的覆盖范围和质量。这种方法解决了中英文混杂、语义表达不清等问题,提高了数据的整体可读性和一致性。
经过大量清洗、整合和精炼处理后,最终构建的XhTCM数据集包含10万条高质量条目,为中医药专用模型的训练和评估奠定了坚实基础。

四、全面评估:多维度验证模型性能
4.1 评估框架设计
为全面评估模型性能,研究团队设计了多维度评估框架,结合自动化指标和专家人工评估:
4.1.1 自动化量化指标
- BLEU
:评估翻译质量和文本相似度
- ROUGE
:衡量摘要质量
- METEOR
:综合考虑精确率、召回率和语义相似度
- BERTScore
:基于BERT的语义相似度评分
- Embedding Distance
:嵌入空间距离度量
4.1.2 专家定性评估维度
- 准确性
(Accuracy):答案的正确性
- 覆盖度
(Coverage):知识点的全面性
- 流畅性
(Fluency):语言表达的流畅程度
- 一致性
(Consistency):前后逻辑的连贯性
- 敏感性
(Sensitivity):对专业术语的精准把握
- 安全性
(Safety):医疗建议的安全性和合理性
评估任务涵盖症状分析、中药功效解释、辨证论治方案制定等。
4.2 实验结果
实验结果表明,XuanHuGPT在多个维度上显著优于通用大语言模型和部分现有中医专用模型:
- 准确性提升
:对中医专业术语和理论的理解更加精准
- 覆盖度增强
:能够整合经典理论与现代临床知识
- 推理能力强化
:在辨证论治等复杂推理任务中表现突出
- 答案质量优化
:生成的回答更加流畅、连贯且安全
这些结果验证了参数高效微调技术在中医药领域应用的有效性。
五、核心贡献:推动中医药智能化发展
5.1 高质量领域数据集
研究构建了XhTCM数据集,系统整合了经典中医文献、现代临床案例、中药药理和方剂知识,为后续中医药大模型研发提供了宝贵资源。
5.2 高效训练范式
通过应用参数高效微调技术,模型在保持强大性能的同时有效平衡了训练成本。这为资源受限环境下的专业领域模型开发提供了可行方案。
5.3 全面评估体系
建立了中医药大语言模型的综合评估框架,采用定量指标与定性专家评审相结合的双轨评估策略。XuanHuGPT在准确性、覆盖度、流畅性、一致性、敏感性和安全性等核心维度表现优异。
5.4 智能化应用范式
本研究为构建智能中医药问答系统提供了可复制的范式,有助于:
- 数字化转型
:推动中医药知识的数字化进程
- 智能化发展
:促进中医药诊疗的智能化升级
- 全球传播
:增强中医药文化的现代诠释和国际认可度
从而为中医药知识的传承创新和国际传播做出贡献。
六、未来展望:中医药AI的发展方向
6.1 技术演进路径
随着大语言模型技术的不断发展,中医药AI系统将朝着以下方向演进:
- 多模态融合
:整合文本、图像(如舌诊、脉象图)和结构化数据
- 知识图谱增强
:构建中医药知识图谱,提升推理能力
- 个性化诊疗
:基于患者体质和症状提供定制化方案
6.2 应用场景拓展
XuanHuGPT等中医药AI系统的应用场景将不断拓展:
- 医学教育
:辅助中医药院校教学和实训
- 临床辅助决策
:为临床医生提供诊疗建议参考
- 公众健康咨询
:普及中医养生保健知识
- 科研数据挖掘
:从海量文献中发现新规律和新药方
6.3 挑战与机遇
尽管前景广阔,中医药AI发展仍面临挑战:
- 数据质量
:需要更多高质量标注数据
- 可解释性
:增强模型决策过程的透明度
- 临床验证
:需要大规模临床试验验证
- 监管合规
:确保符合医疗AI相关法规
同时,这些挑战也孕育着巨大机遇,为跨学科合作和技术创新提供了空间。
七、结语
XuanHuGPT的成功开发标志着中医药智能化发展的重要里程碑。通过构建高质量领域数据集、应用参数高效微调技术、建立全面评估体系,本研究为中医药大模型的研发提供了完整的方法论和技术路线。
这不仅是技术创新的成果,更是传统医学与现代AI技术深度融合的典范。随着技术的不断成熟和应用的持续深化,中医药AI系统必将在传承中华医学智慧、服务人类健康事业中发挥越来越重要的作用。
对于专家、投资人和科研机构而言,中医药AI代表着一个充满潜力的新兴领域。它既承载着五千年中医智慧的传承使命,又肩负着推动医疗健康产业数字化转型的时代责任。XuanHuGPT的成功实践证明,这条道路是可行的、有价值的,也是值得持续投入和深入探索的。
标签
#中医药 #大语言模型 #LLM #参数高效微调 #PEFT #XuanHuGPT
欢迎加入「知识图谱增强大模型产学研」知识星球,获取最新产学研相关"知识图谱+大模型"相关论文、政府企业落地案例、避坑指南、电子书、文章等,行业重点是医疗护理、医药大健康、工业能源制造领域,也会跟踪AI4S科学研究相关内容,以及Palantir、OpenAI、微软、Writer、Glean、OpenEvidence等相关公司进展。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献58条内容
已为社区贡献58条内容

所有评论(0)