【AI测试全栈:Python核心】11、电商推荐系统数据集质量校验实战:7000字全流程工程化脚本落地指南
文章摘要 《电商推荐系统数据集质量校验实战》针对推荐系统中数据质量问题,提出一套完整的工程化解决方案。文章设计了一个基于Python的EcommerceRecommendationDataValidator核心类,包含5大验证模块:数据结构、数据质量、业务规则、特征工程和可视化报告。通过JSON配置文件实现灵活适配不同电商场景,支持交互、用户、物品三类数据的自动化校验。系统可生成包含9张子图的可视
数据质量噩梦终结者:自动化、工程化电商推荐系统数据集校验脚本全解
核心关键词:推荐系统数据校验、数据质量工程、自动化验证、Python数据验证、CI/CD集成
摘要:本文深入探讨如何构建一套生产级别的电商推荐系统数据集质量校验脚本。通过五层验证体系、灵活的配置设计和直观的可视化报告,解决高稀疏度、冷启动用户、业务规则违规等特有数据痛点,并提供完整的工程化落地方案。
开篇导语:为何通用数据质量工具在推荐系统面前“失灵”?
在电商推荐系统的迭代过程中,许多团队都经历过这样的挫败:离线评估指标(如AUC、Precision@K)表现优异的模型,上线后点击率(CTR)却惨不忍睹,甚至出现“给婴儿推荐剃须刀”的荒谬场景。究其根源,数据质量问题往往是罪魁祸首。
推荐系统的数据具有鲜明的场景特殊性:
- 高交互稀疏性:在用户-物品的庞大笛卡尔积中,真实交互通常不足1%,这并非异常,而是常态。
- 强业务规则约束:评分需在1-5分,年龄需在合理范围,时间戳不能来自未来。
- 特有的数据实体:“冷启动用户”、“长尾物品”等概念,在通用数据质量工具的字典里并不存在。
因此,依赖Apache Griffin、Great Expectations等通用工具,往往会出现误报(将高稀疏度判为异常) 或漏报(无法识别业务违规)。构建一套量身定制、工程化、自动化的数据质量校验体系,已成为推荐系统成功落地的前置必备环节。
本文将带领您从零打造一个具备以下亮点的校验脚本:
- 五层纵深验证:从数据结构到业务特征,层层深入。
- 全自动报告:一键生成含9张专业图表和可执行建议的JSON报告。
- 工程化友好:配置驱动、结果标准化,轻松嵌入CI/CD流水线。
- 开箱即用:提供完整代码、模拟数据与实战演练。
第一章:项目架构设计 —— 工程化的基石
一个健壮的工程化脚本,始于清晰的架构。我们采用 “核心验证器类 + 配置文件 + 标准化输出” 的三元设计,确保高内聚、低耦合与易扩展。
1.1 核心验证器类设计:EcommerceRecommendationDataValidator
该类是整个脚本的大脑,采用 “验证流水线” 设计模式,按固定顺序执行各层验证,确保依赖关系正确。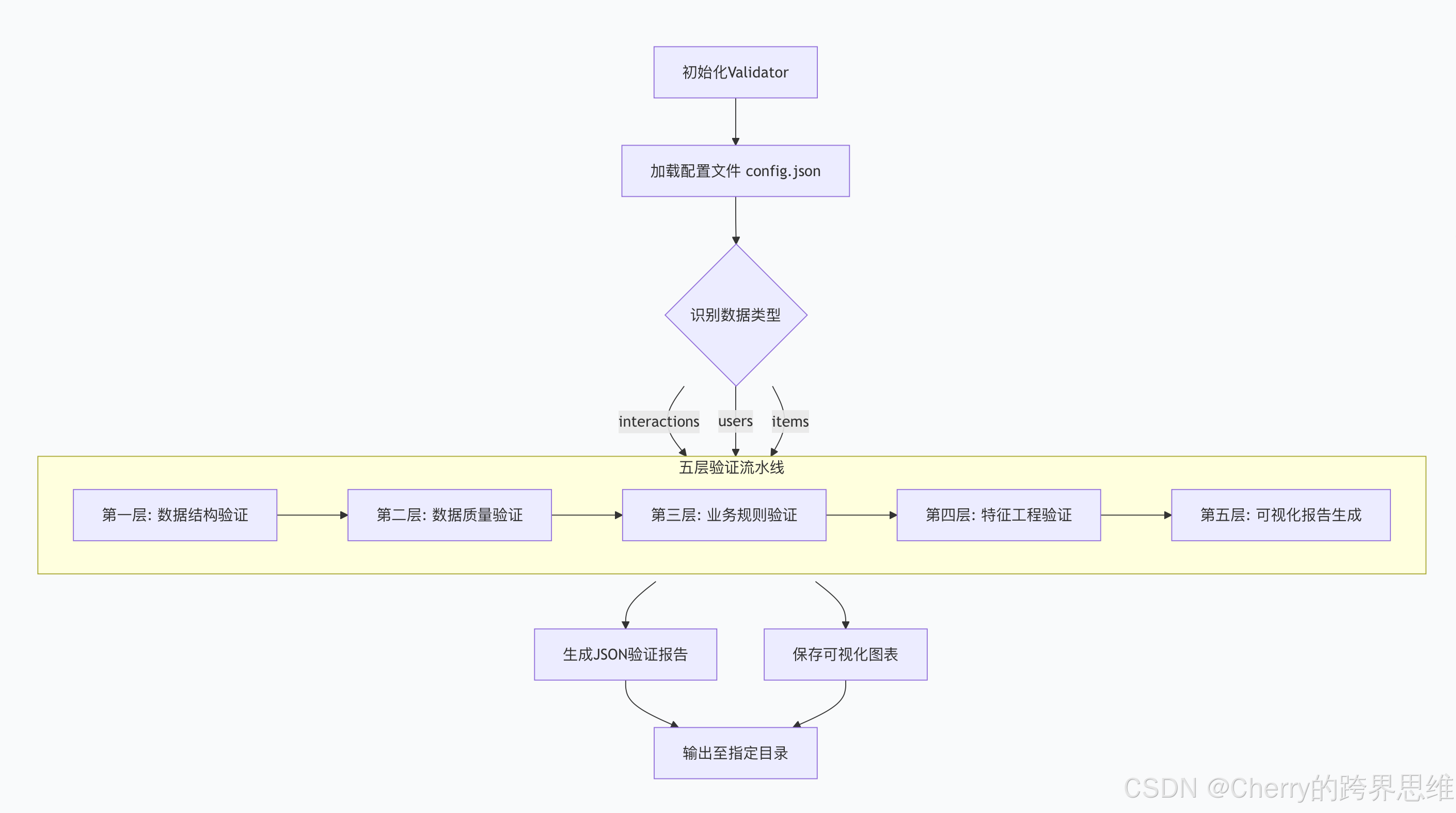
类核心职责:
- 初始化:加载配置,创建结果存储结构。
- 调度:按序调用各验证模块。
- 汇总:收集各模块结果,生成最终报告与图表。
- 输出:持久化所有结果,支持后续集成。
1.2 灵活的配置设计:JSON配置文件
所有验证规则、阈值和输出格式均通过JSON文件配置,实现逻辑与配置的分离,无需修改代码即可适配不同业务场景(如生鲜电商与奢侈品电商的规则不同)。
{
"basic_config": {
"supported_data_types": ["interactions", "users", "items"],
"output_dir": "validation_results/"
},
"validation_thresholds": {
"missing_rate_threshold": 0.05,
"sparsity_warning_threshold": 0.95,
"cold_start_user_threshold": 0.3
},
"business_rules": {
"interactions": {
"rating_range": [1.0, 5.0],
"quantity_min": 1
},
"users": {
"age_range": [18, 80]
}
}
}
配置文件核心模块示意图
1.3 标准化的结果存储:为CI/CD而生
验证结果采用机器可读的JSON报告和人眼可观的可视化图表组合输出。JSON结构经精心设计,便于CI/CD流水线(如Jenkins, GitLab CI)自动解析,实现“验证不通过则阻塞部署”的卡点效果。
{
"summary": {
"validation_pass": false,
"total_violations": 5,
"error_count": 2,
"warning_count": 3
},
"details": {
"structure_validation": {...},
"business_validation": {
"rating_range_check": {
"status": "error",
"violation_count": 300,
"violation_details": "rating值超过[1.0,5.0]范围"
}
}
},
"recommendations": {
"high_priority": ["处理评分异常值..."]
}
}
标准化JSON报告结构示例
第二章:五层验证体系详解 —— 从“可用”到“好用”
我们的验证体系像一座五层金字塔,从基础稳固性到高级适应性,逐层构筑数据质量的防线。
2.1 第一层:数据结构验证 —— 确保“能读”
目标:检查数据的“形”是否正确,是后续所有分析的基础。
- 必需列检查:例如,
interactions数据必须包含user_id,item_id,timestamp。 - 数据类型验证:确保
user_id是整数,timestamp是时间戳格式,防止后续计算崩溃。
2.2 第二层:数据质量验证 —— 确保“干净”
目标:识别并量化通用数据脏污问题。
- 缺失值检测:计算各字段缺失率,超过阈值(如5%)则告警。
- 重复值检测:识别完全重复的行。
- 异常值检测(IQR方法):相较于对极值敏感的Z-score法,IQR(四分位距)法更适合实际业务数据分布,能稳健地找出“离谱”的值。
IQR异常值检测算法流程图
2.3 第三层:业务规则验证 —— 确保“合理”
目标: enforcing 领域知识,这是通用工具无法做到的核心价值。
- 值域校验:评分必须在1-5分,年龄必须在18-80岁。
- 逻辑一致性校验:购买总价是否等于单价乘以数量?交互时间戳是否早于当前时间(防止未来数据)?
- 枚举值校验:性别字段是否只包含
M/F/O?
2.4 第四层:特征工程验证 —— 确保“可建模”
目标:诊断影响推荐模型效果的特有数据问题。
- 交互稀疏度计算:
Sparsity = 1 - (观测交互数) / (用户数 * 物品数)。超过95%警告,超过99%报错。 - 冷启动用户识别:交互次数≤1的用户比例。比例过高(如>30%)意味着模型缺乏学习信号。
- 特征分布偏斜度:计算数值特征的Skewness。绝对值大于2表示分布严重偏斜,可能需进行对数变换。
- 特征相关性:检测高度相关(如|r|>0.8)的特征对,避免多重共线性。
2.5 第五层:可视化验证报告 —— 确保“易懂”
目标:一图胜千言,为团队提供直观的数据健康全景图。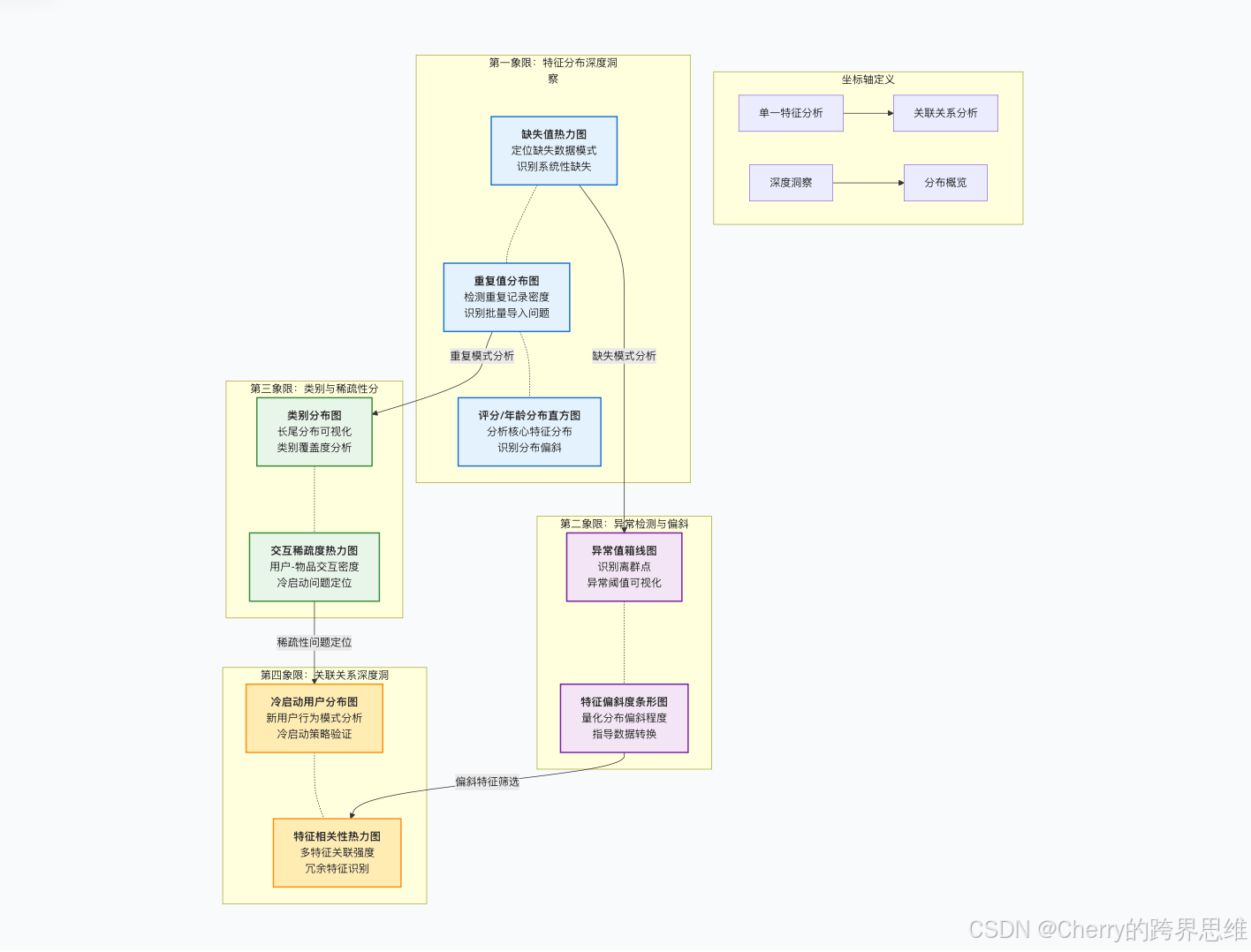
第三章:实战演练 —— 用“问题数据”检验脚本
让我们创建一份充满“陷阱”的模拟数据,看脚本如何精准揪出问题。
3.1 创建有问题的Interactions数据集 (10万条)
我们故意注入常见问题:
- 缺失值:
rating字段缺失3%。 - 业务违规:混入300条
rating=10的异常评分。 - 重复行:制造2%的完全重复记录。
- 未来时间戳:插入50条时间戳为明天的时间记录。
3.2 创建有问题的Users数据集 (1千用户)
- 无效年龄:加入20个年龄为150岁的用户。
- 非法枚举值:在
gender字段中加入X。
3.3 执行验证脚本
python ecommerce_data_validator.py \
--data ./data/interactions.csv \
--type interactions \
--config ./config/validator_config.json
脚本输出:
- 终端摘要:立即显示关键错误和警告数量。
- 结果目录:在
validation_results/下生成validation_report_20231027.json和包含9张图表的figures/文件夹。
第四章:报告解读与问题修复指南
4.1 解码JSON报告:从摘要到建议
- 看
summary:“validation_pass”: false,有2个错误、3个警告。决策:必须修复错误,评估警告。 - 挖
details:business_validation.rating_range_check:300条评分超出1-5范围。高优先级。quality_validation.duplicate_value_check:重复率2%。高优先级。feature_validation.sparsity_check:稀疏度96%(警告)。中优先级。
- 用
recommendations:报告已给出具体建议,如“过滤rating=10的记录”、“使用drop_duplicates()去重”。
4.2 典型问题修复策略
- 高缺失率列:若为关键特征(如
user_id),必须回溯数据源修复;若为辅助特征且缺失率高,可考虑删除该列。 - 冷启动用户:不能简单删除,他们是业务的增长点。应采用热门物品推荐、基于内容的推荐或探索性策略进行冷启动处理。
- 交互稀疏度过高:这是系统性问题。建议优化数据采集(如记录更多隐式反馈),或采用矩阵补全、图神经网络等对稀疏数据更友好的算法。
4.3 可视化图表解读
- 缺失值热力图:
rating列有连续浅色块,直观显示缺失。 - 箱线图:
rating的箱体上方出现大量孤立点,指向“10分”异常。 - 交互稀疏度热力图:大部分区域呈深色(表示无交互),直观展示了96%稀疏度的严峻现实。
第五章:生产环境部署与进阶优化
5.1 集成至CI/CD流水线
将校验脚本设置为数据管道或模型训练前的强制关卡。
- GitHub Actions示例:
- name: Validate Training Data run: | python scripts/validate_data.py --data ${{ secrets.DATA_PATH }} continue-on-error: false # 验证失败则终止工作流 - 告警:将JSON报告的
summary部分发送至钉钉/企业微信/Slack,或与监控系统(如Prometheus)集成。
5.2 大数据量性能优化
- 分块处理:使用
pandas.read_csv(chunksize=50000)迭代处理百万级数据。 - 并行验证:对
interactions、users、items三个独立数据集,使用concurrent.futures进行并行验证。 - 采样验证:对于超大规模数据,可先对数据进行分层采样,进行快速验证。
5.3 扩展方向
- 支持更多数据源:扩展以支持直接从Hive、Snowflake或数据库读取数据。
- 插件化验证规则:允许用户通过配置文件自定义Python函数,实现更复杂的业务规则校验。
- 与数据沿袭集成:将质量问题追溯至具体的数据作业或任务,实现根因分析。
总结与资源
数据质量是推荐系统,乃至所有数据驱动系统的生命线。本文提供的不仅是一个脚本,更是一套可落地的工程化方法论。通过五层验证、配置驱动和自动化报告,您可以将数据质量从被动的“救火”变为主动的“防控”。
立即行动:
- 获取完整代码:GitHub项目链接(包含完整类实现、配置模版与模拟数据生成脚本)。
- 您的第一个任务:根据
items的配置规则,扩展脚本以完成对商品数据集的完整验证。 - 进阶挑战:尝试将脚本集成到您团队现有的数据管道中,并设置第一个验证告警。
下篇预告:《性能提升10倍!大数据环境下推荐系统测试脚本优化全策略》—— 我们将深入探讨如何利用并行计算、智能采样与缓存技术,让您的数据校验与模型测试飞起来。
版权声明:本文涉及的技术方案与代码均为实战总结,欢迎用于学习与交流。转载请联系作者并注明出处。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 14
14 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)