2025 AI 大模型年终盘点:谷歌反超,国产爆发,三大榜单一文看懂!
2025 AI 大模型年终盘点:谷歌反超,国产爆发,三大榜单一文看懂!
2026 年第一天,盘点过去一年的 AI 大模型格局。
这篇文章汇总了 LMArena、LiveBench、Artificial Analysis 三大权威平台截至 2025 年 12 月底的最新排名。
数据量很大,先说结论。
谷歌
Gemini 3成功逆袭,拿下文本对话和多模态的双料冠军;OpenAIGPT-5系列不及预期,勉强守住推理和搜索的阵地;偏科生 AnthropicClaude Opus 4.5在代码和智能体任务上继续称王。
而国产大模型的表现,是今年最大的惊喜。
01|三大榜单,各测什么?
简单介绍我最常看的三个榜单。
LMArena(原 Chatbot Arena)由加州大学伯克利分校 LMSYS 团队开发,采用类似国际象棋的 Elo 评分系统。
用户在平台上和两个匿名模型对话,投票选出更好的那个。
累计超过 500 万次真人投票,几乎是 AI 领域的「黄金标准」。
它现在细分出多个榜单:Text Arena(文本对话)、WebDev(网页开发)、Vision(视觉理解)、Text-to-Image(文生图)、Image Edit(图像编辑)、Search(搜索能力)。
LiveBench 是一个「防污染」的学术基准测试,已被 ICLR 2025 收录为 Spotlight Paper。
核心特点是每月更新测试题目,来源包括最新数学竞赛(AMC、AIME、IMO)、arXiv 论文、新闻文章等。
所有问题都有客观标准答案,不依赖 LLM 当评委,避免了「AI 评 AI」的偏差。
Artificial Analysis 是独立 AI 模型评测机构。
最新的 Intelligence Index v3.0 综合了 10 项评估,覆盖知识、推理、数学、编程、指令遵循、长文本理解、智能体任务等维度。
三个平台评测方法不同,但互为补充。
一句话总结:「LMArena 测真人偏好,LiveBench 测客观能力,Artificial Analysis 测综合智商。」
02|文本对话:谷歌 Gemini 3 登顶
Text Arena 是 LMArena 最核心的榜单,截至 12 月 30 日累计投票数近 500 万。
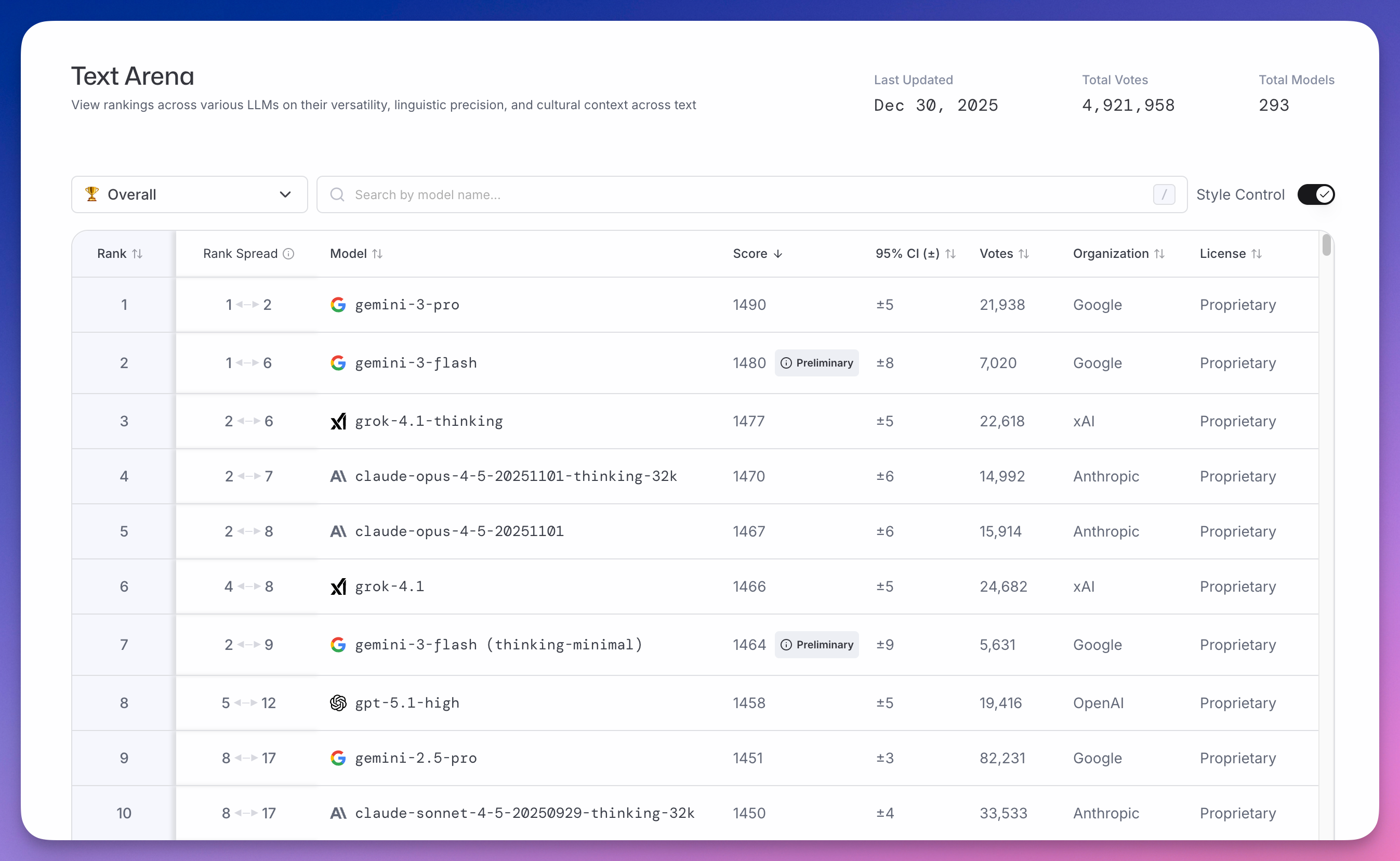
榜首是谷歌 gemini-3-pro,得分 1490。
更魔幻的是,第二名还是谷歌,gemini-3-flash 得分 1480。
马斯克 xAI 的 grok-4.1-thinking 以 1477 分排第三。
Anthropic 的 claude-opus-4-5 系列分列四、五位,得分 1470 和 1467。
OpenAI 的 gpt-5.1-high 排到了第八,得分 1458。
2024 年,谷歌 Gemini 还在被 GPT 和 Claude 压着打。
现在,直接翻盘。
03|前端代码:Claude 继续称王
WebDev Leaderboard 测试模型写前端代码的能力,截至 12 月 29 日累计 8 万票。
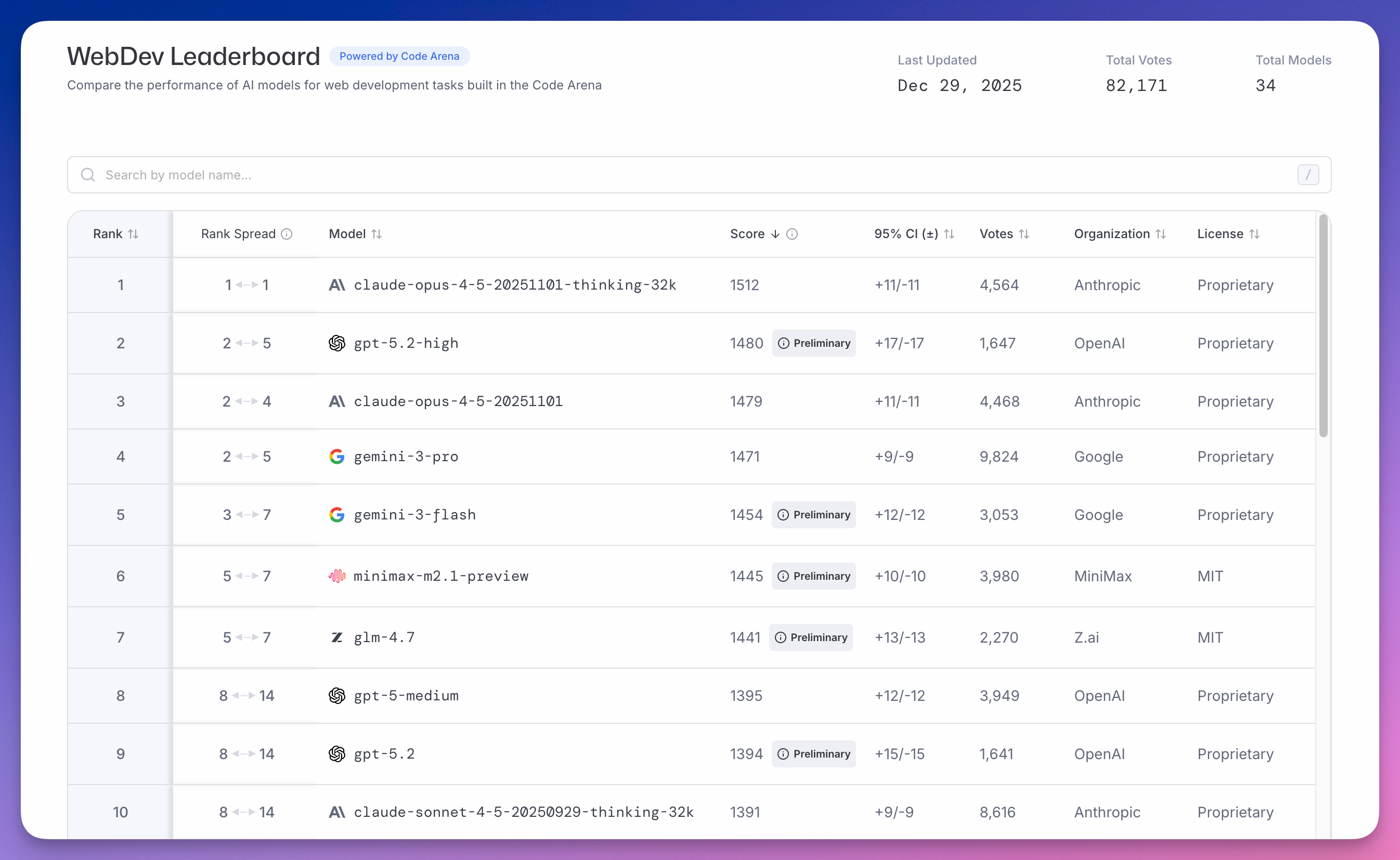
Anthropic claude-opus-4-5-20251101-thinking-32k 以 1512 分遥遥领先,比第二名 OpenAI 的 gpt-5.2-high(1480 分)高 32 分。
第三还是 Claude claude-opus-4-5-20251101(1479 分)。
谷歌 gemini-3-pro 以 1471 分排第四。
值得一提的是,国产模型真的站起来了。
MiniMax minimax-m2.1-preview 以 1445 分排第六。
智谱 glm-4.7 以 1441 分排第七。
全球前十。
04|视觉理解:谷歌继续碾压
Vision Arena 测试模型理解和处理图像(多模态)的能力,截至 12 月 16 日累计 57 万票。
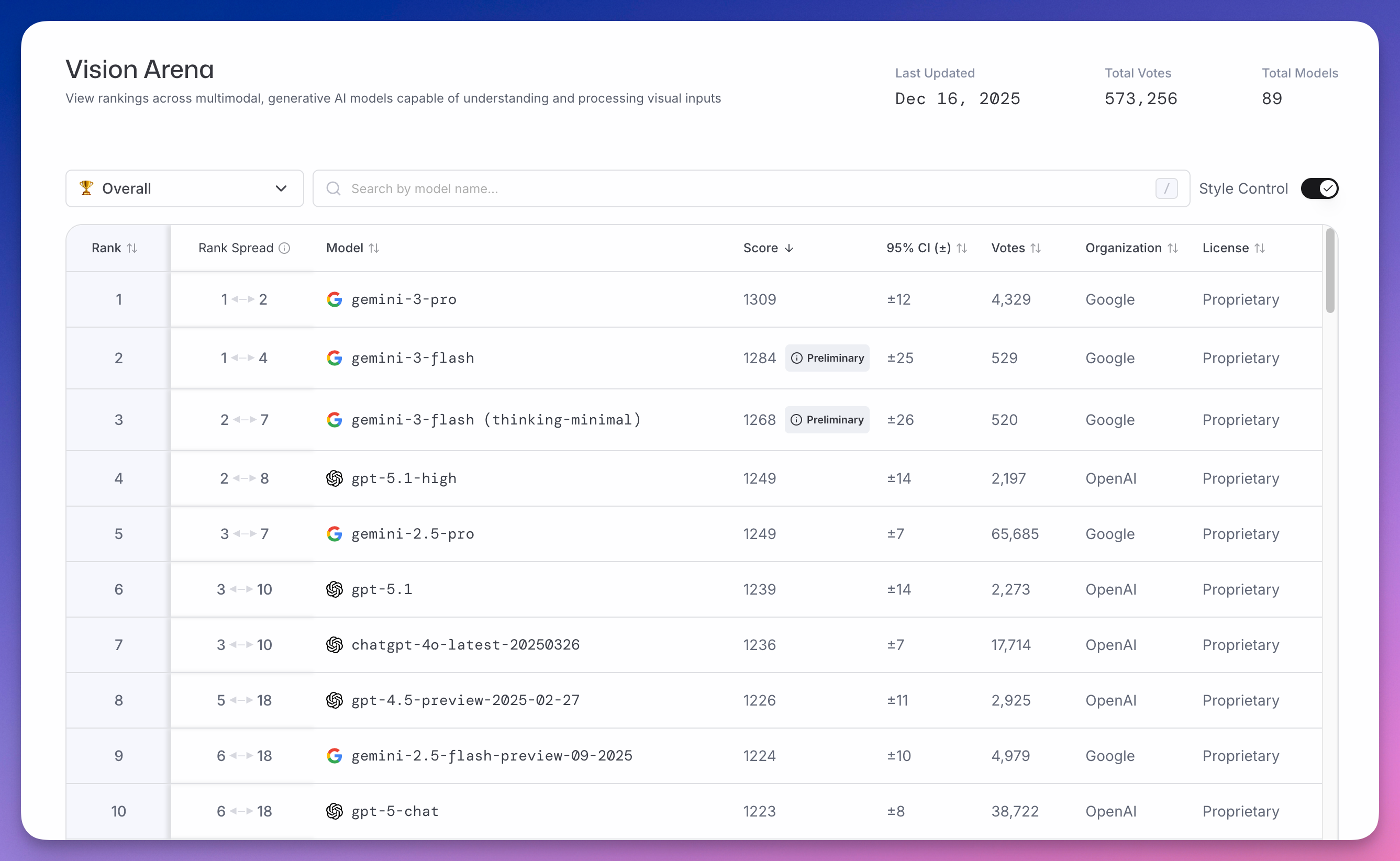
前三全是谷歌:gemini-3-pro(1309 分)、gemini-3-flash(1284 分)、gemini-3-flash (thinking-minimal)(1268 分)。
OpenAI 的 gpt-5.1-high 以 1249 分排第四。
多模态这个赛道,谷歌 Gemini 领先优势太明显了。
05|图像生成与编辑:字节杀进全球前五
Text-to-Image Arena(文生图)榜单上,OpenAI gpt-image-1.5 以 1264 分排第一。
谷歌大香蕉 Nano Banana Pro 图像模型以 1235 分第二。
Black Forest Labs 的 Flux 2 系列占据四到七位。
国产模型,腾讯 hunyuan-image-3.0 以 1152 分排第八。
字节 seedream-4.5 以 1147 分第十。
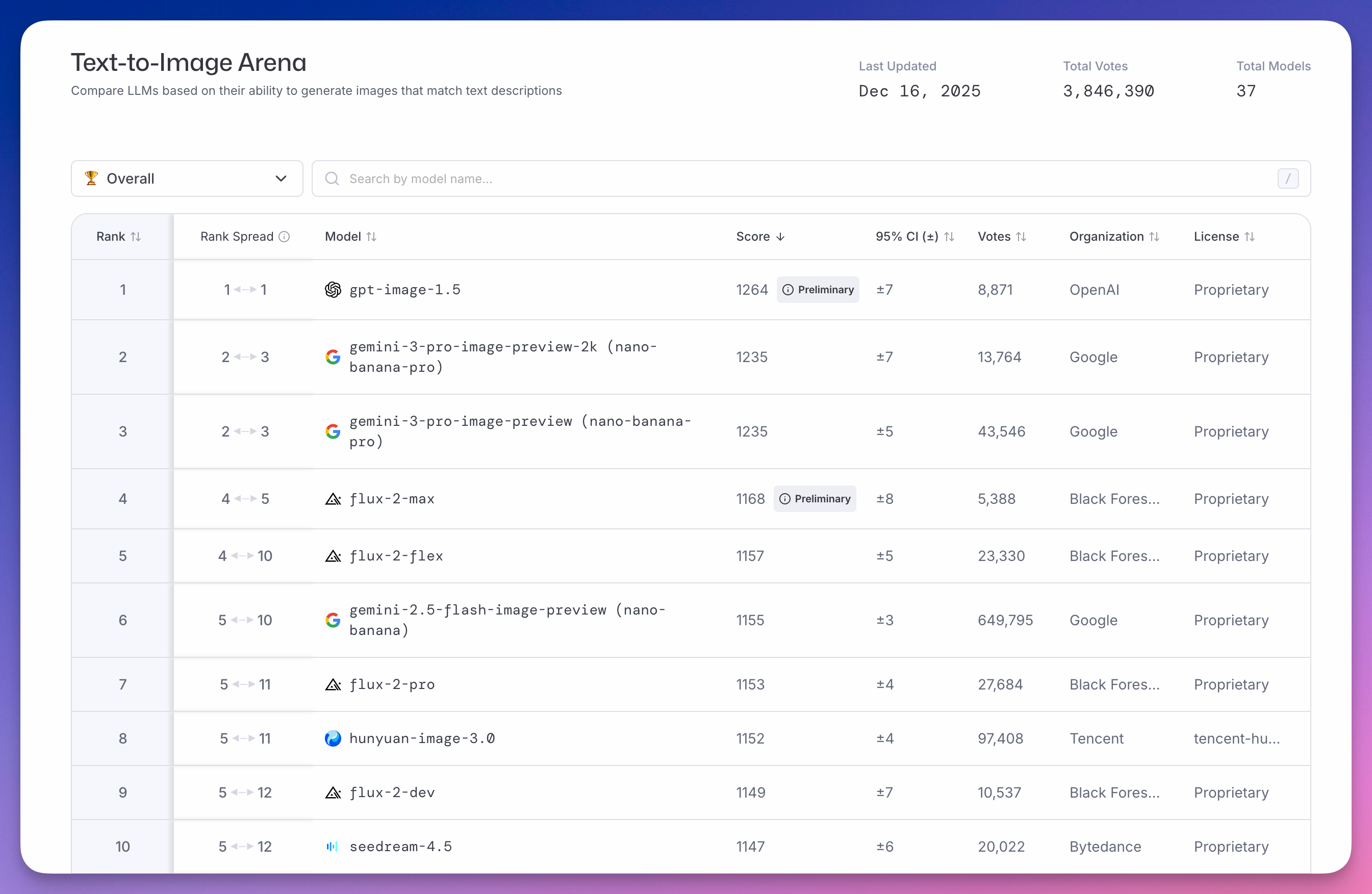
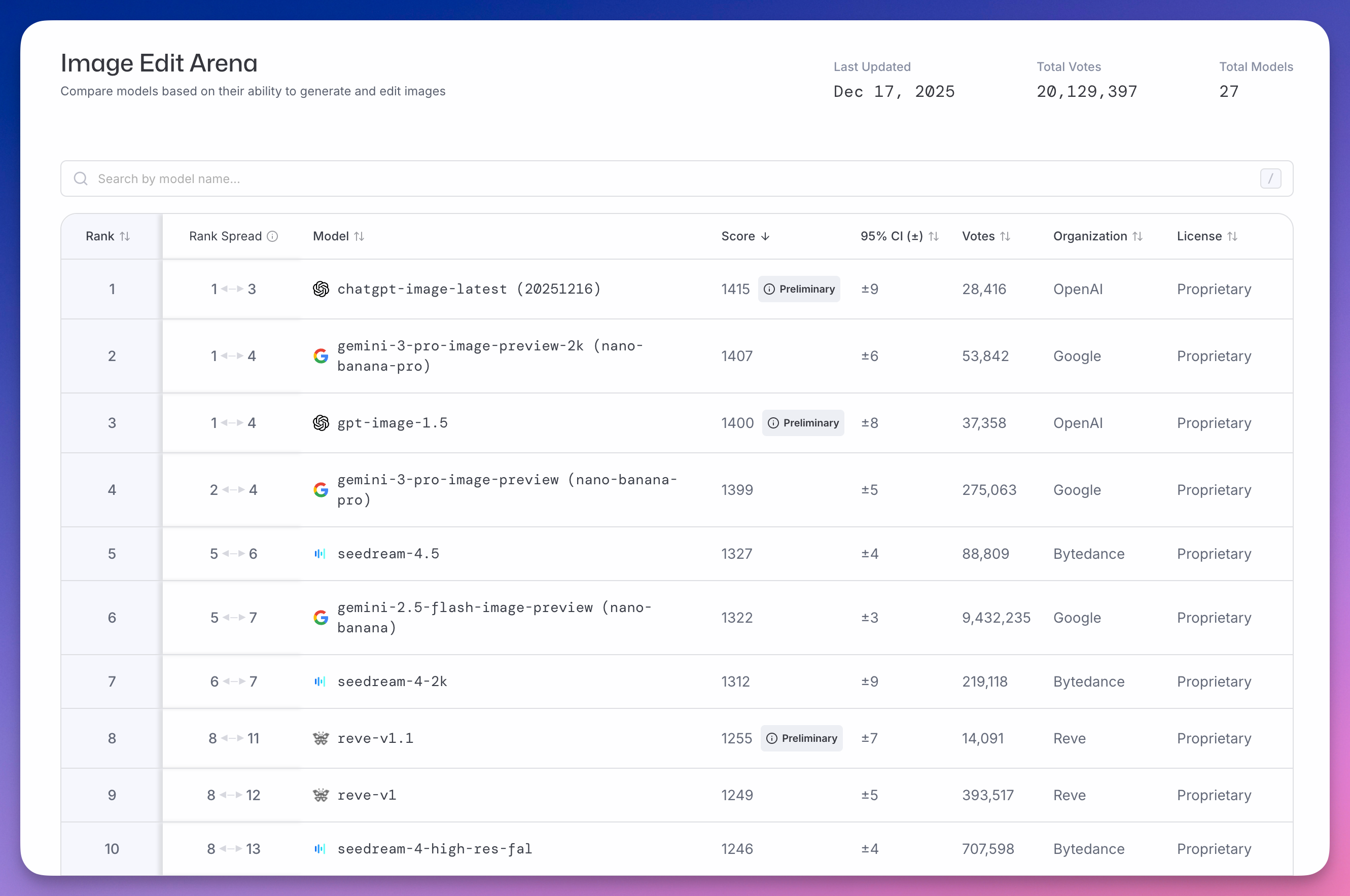
Image Edit Arena(图像编辑)榜单上,字节表现更亮眼。
seedream-4.5 以 1327 分排第五,seedream-4-2k 以 1312 分排第七,seedream-4-high-res-fal 以 1246 分排第十。
前十,字节占了三个。
图像生成和编辑,国产模型已经杀进全球第一梯队了。
06|搜索能力:谷歌 vs OpenAI
Search Arena 测试模型联网搜索的能力,截至 12 月 17 日累计 12 万票。
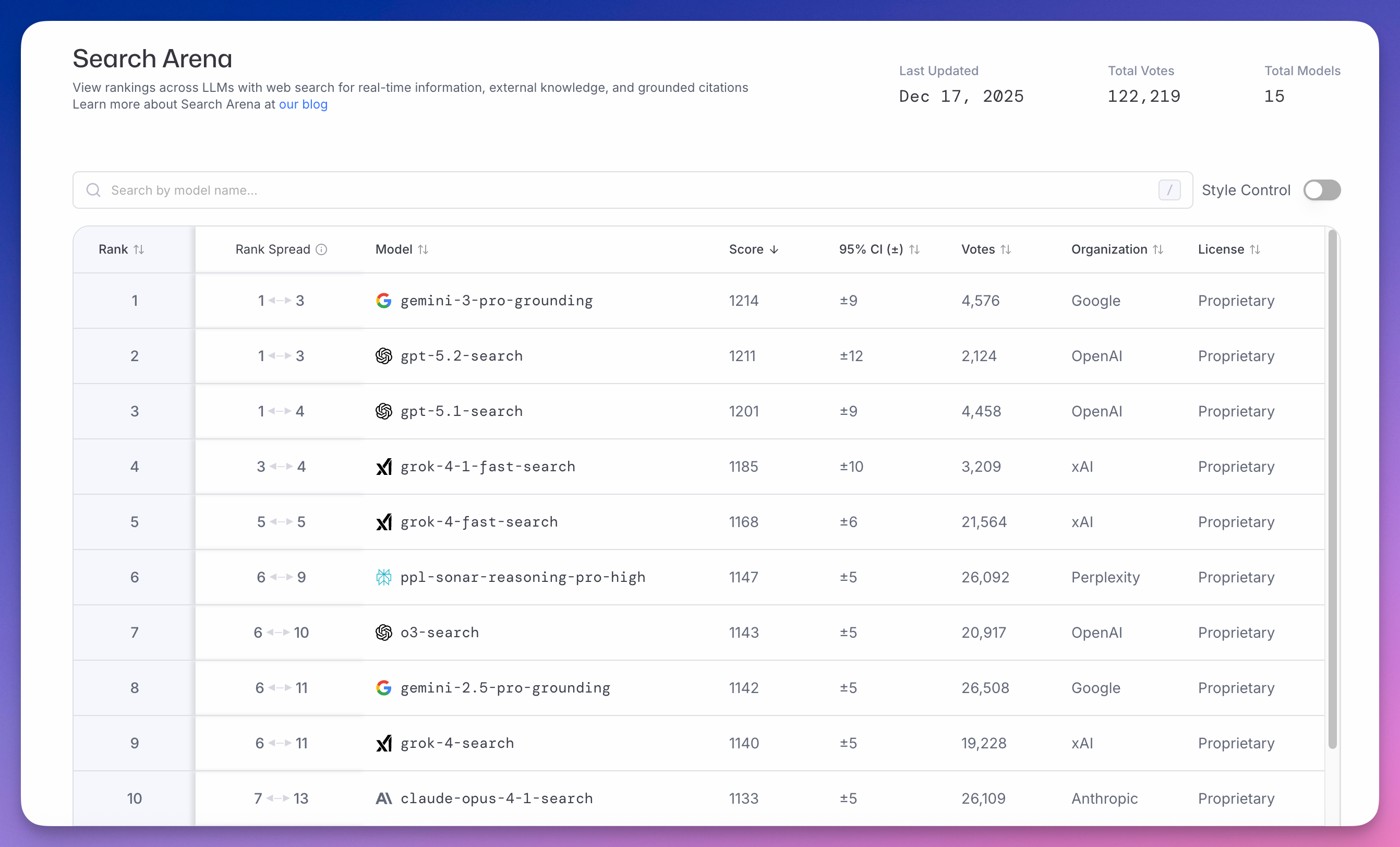
谷歌 gemini-3-pro-grounding(Gemini 3 Pro 的搜索模式)以 1214 分居首。
OpenAI gpt-5.2-search 紧随其后得分 1211,差距只有 3 分。gpt-5.1-search 以 1201 分排第三。
xAI Grok 系列占据四到六位。
Perplexity 的 ppl-sonar-reasoning-pro-high 排第六,得分 1147。
谷歌做了二十多年搜索引擎,只领先 3 分,OpenAI 已经很能打了。
07|LiveBench:硬核推理
LiveBench 是百分制。
测试内容包括推理、数学、编程、数据分析、语言理解、指令遵循几大类。
这个榜单的题目非常难,每月更新(这是名字里 Live 这个词的精髓),专治各种「刷榜」。
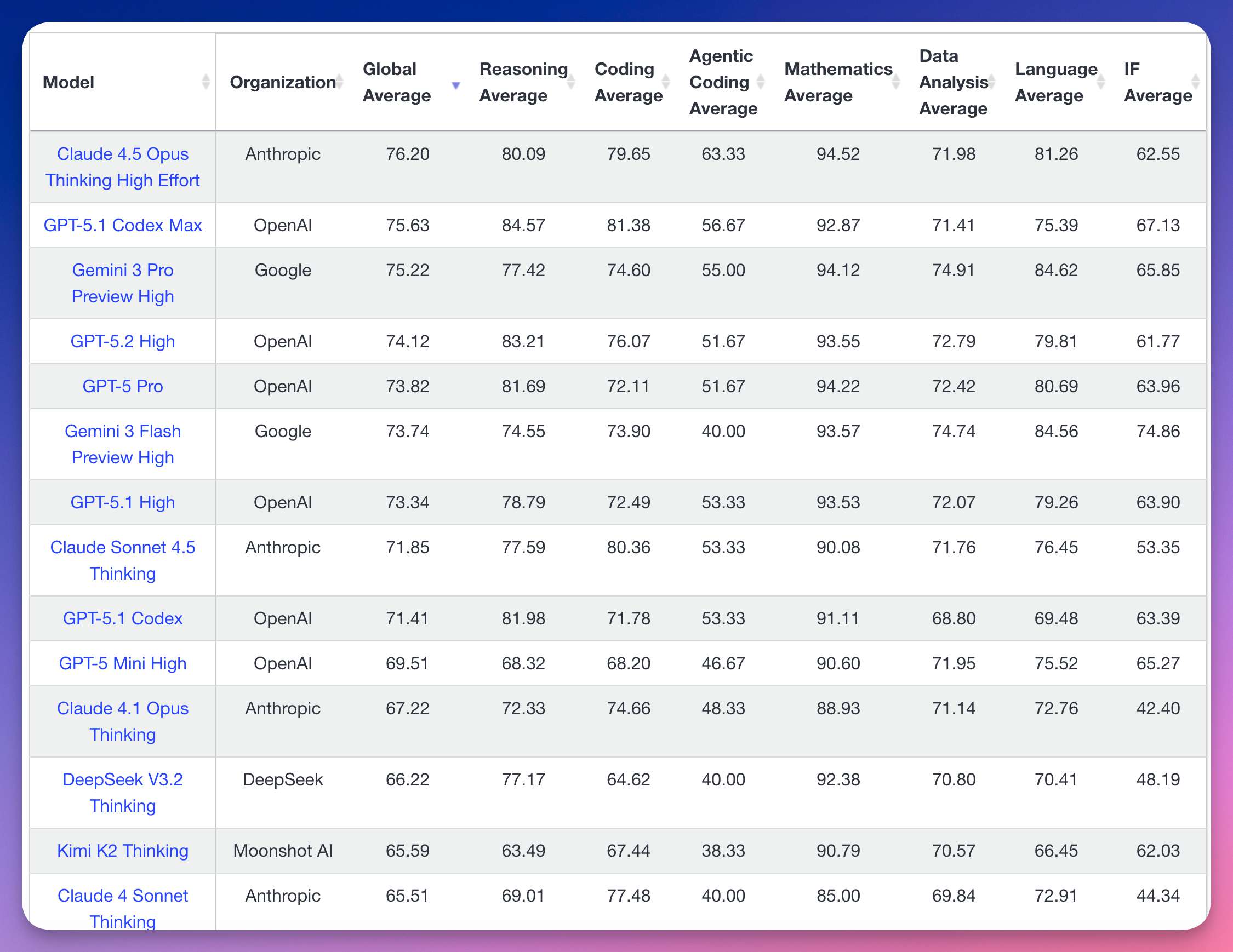
Anthropic Claude 4.5 Opus Thinking High Effort 以 76.20 分排第一。
OpenAI GPT-5.1 Codex Max 以 75.63 分紧随其后。
谷歌 Gemini 3 Pro Preview High 以 75.22 分排第三。
国产模型,DeepSeek V3.2 Thinking 以 66.22 分排第十二。
月之暗面 Kimi K2 Thinking 以 65.59 分排第十三。
顶尖模型也就 70% 多的正确率,可见难度。
需要说明的是,LiveBench 更新比较慢,很多国产新模型还没来得及上榜。
08|Artificial Analysis:智能体成新战场
Artificial Analysis Intelligence Index 是综合指数,把 10 项评估加权平均。
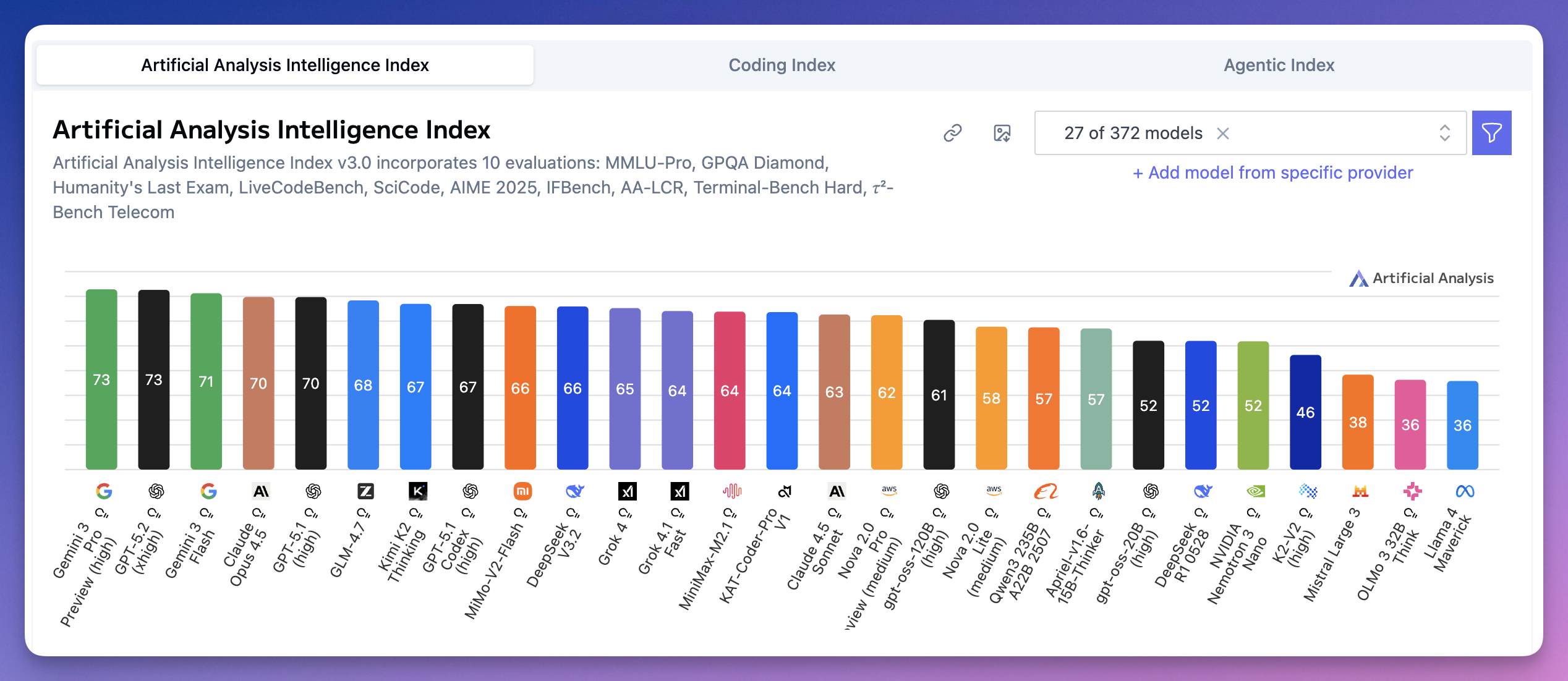
总榜上,谷歌 Gemini 3 Pro Preview 和 OpenAI GPT-5.2 并列第一,都是 73 分。
Gemini 3 Flash 71 分排第三。
Claude Opus 4.5 和 GPT-5.1 并列第四,都是 70 分。
国产模型排名亮眼。
智谱 GLM-4.7 68 分(第六);Kimi K2 Thinking 67 分(第七);小米 MiMo-V2-Flash 66 分(第九);DeepSeek V3.2 66 分(第十)。
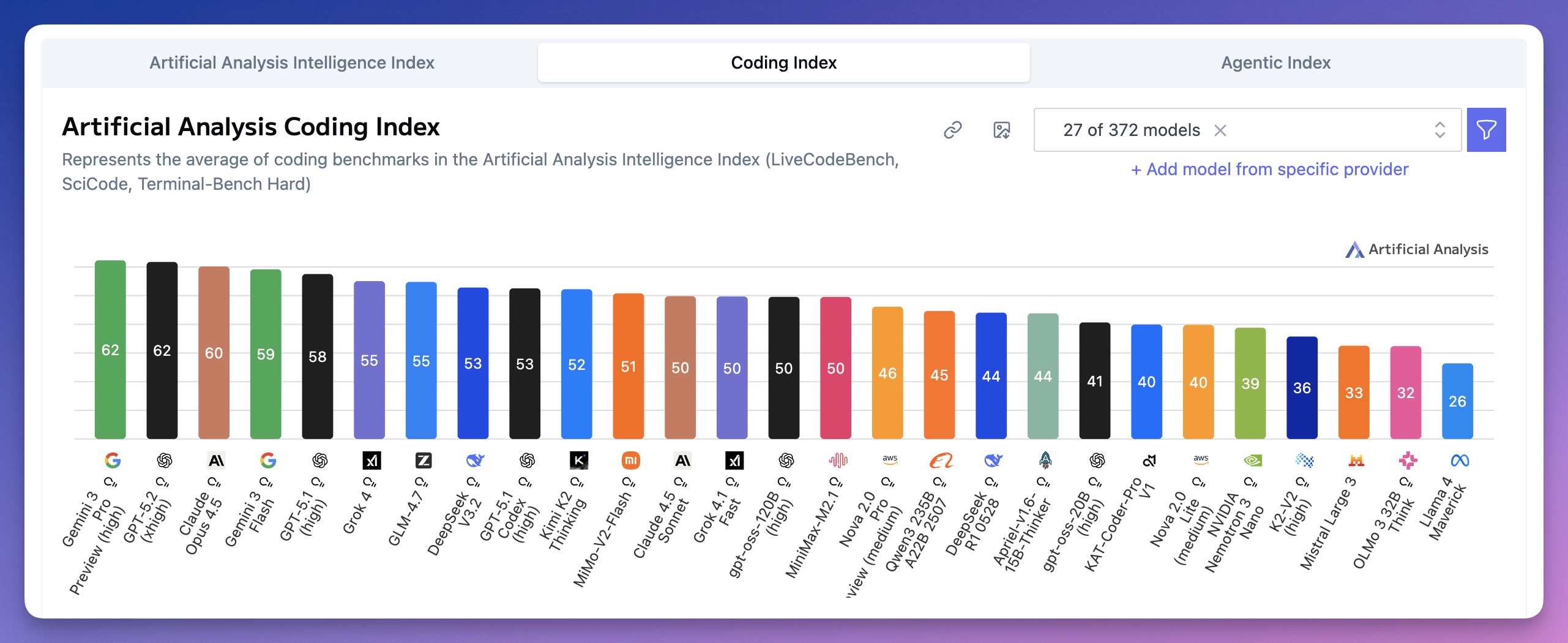
Coding Index(编程能力)榜,谷歌 Gemini 3 Pro 和 OpenAI GPT-5.2 并列第一,都是 62 分。
Claude Opus 4.5 60 分排第三。
国产方面,GLM-4.7 55 分;DeepSeek V3.2 53 分;Kimi K2 Thinking 52 分,MiMo-V2-Flash 51 分。
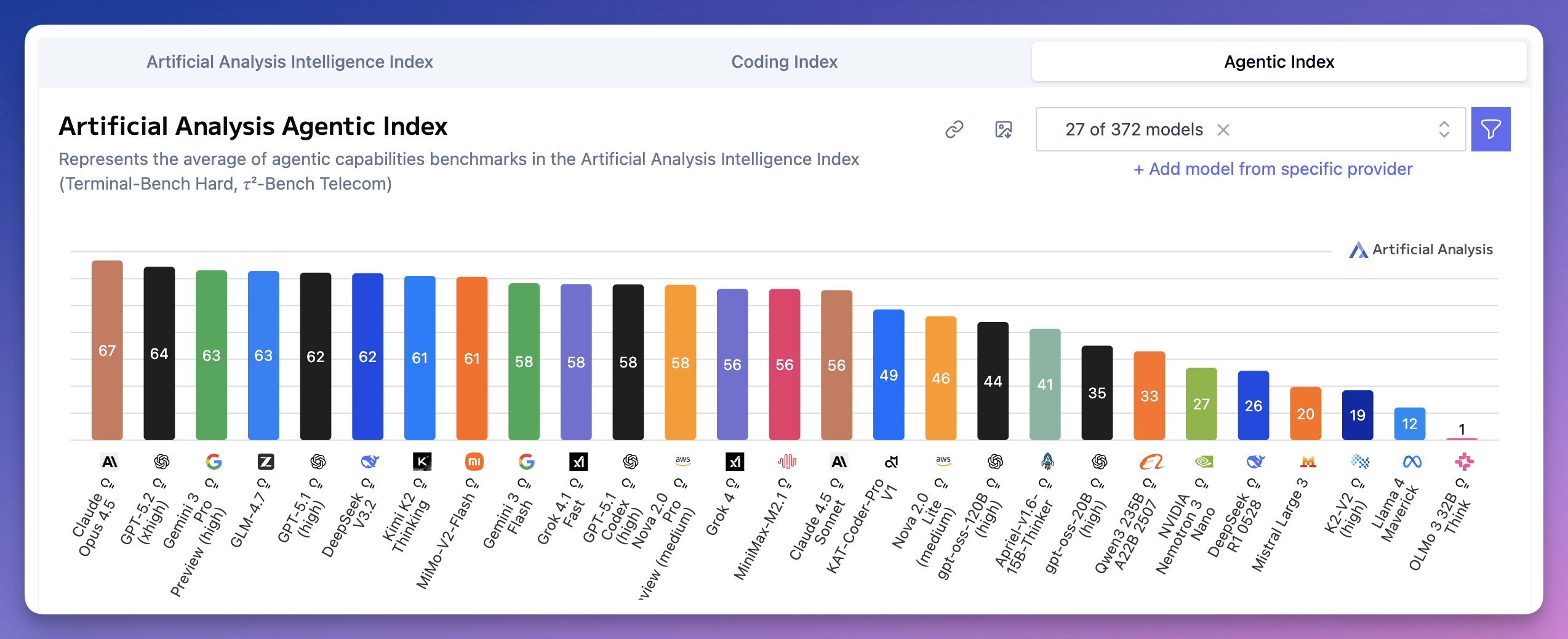
Agentic Index(智能体能力)是 2025 年的新赛道,测试模型执行复杂多步骤任务的能力。
Claude Opus 4.5 以 67 分排第一。
GPT-5.2 64 分排第二。
Gemini 3 Pro 和智谱 GLM-4.7 并列第三,都是 63 分。
DeepSeek V3.2 62 分,第六;Kimi K2 和小米 MiMo-V2-Flash 都是 61 分,排第七。
智谱和榜首差距只有 4 分。
智能体这个赛道,国产模型起点很高了。
09|2026 怎么选?
日常对话、搜索、信息整合和多模态理解,选今年进步最大的 Gemini,或者 8 亿周活的 ChatGPT;用不了的,直接豆包或者千问。
写代码,后端选 Claude(或复杂任务 GPT,前端也可以 Gemini),这块它还是王者;嫌麻烦直接 GLM-4.7、MiniMax M2.1、或 Kimi K2。
复杂自动化任务,Claude 目前最强,但国产模型的 Agentic 能力也值得一试。
图像生成,OpenAI(仅限英文)和谷歌领先,但字节 Seedream 已经很能打了。
2026 年,智能体(AI Agent)还是主战场之一。
新年快乐。
关注我,2026 继续和 AI 一起进化。
我是木易,Top2 + 美国 Top10 CS 硕,现在是 AI 产品经理。
关注「AI信息Gap」,让 AI 成为你的外挂。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 23
23 0
0- 0



 已为社区贡献96条内容
已为社区贡献96条内容

所有评论(0)