大模型应用开发-向量数据库
本文介绍了大模型应用开发中常用的向量数据库工具,重点阐述了其在高维数据管理方面的优势。文章首先解释了高维向量数据的特点和处理难点,对比了传统数据库与向量数据库的区别。然后详细介绍了向量嵌入空间评估方法(t-SNE和UMAP)以及主流向量索引结构(HNSW、IVF-PQ等)。最后以FAISS为例,展示了向量数据库的实际应用,包括索引构建和查询策略。向量数据库通过高效存储和检索高维向量,为大模型应用开
这篇文章介绍大模型应用开发过程中常用的持久化工具-向量数据库,可以将其类比为Web开发中的MySQL等数据库工具,需要提前了解一些概念:
聚类,可以看:机器学习基础-8 聚类分析
距离概念的详细介绍、KNN概念的详细介绍,可以看:机器学习基础-3 k近邻
一 高维数据存在的问题
深度学习的核心思想是“嵌入”,嵌入是指在保留原始输入信息语义的前提下,将信息表示为一个向量,如在自然语言处理中,将词语表示为词嵌入向量,在计算机视觉中,利用卷积神经网络从图像中提取出特征图张量等,这些得到的结果都是高维数据。高维向量表示是现代深度学习将文本、图像等数据转换为数值表示的一种核心方法,其目标是将原始数据的语义或特征映射到一个高维空间中,便于后续进行计算和分析。



总的来说,对于高维向量数据:
1)普通的欧氏距离等距离度量函数,无法准确衡量不同向量之间的相似性,需要人工显式的将相似性建模到信息嵌入的过程中,让语义相似的信息得到的嵌入向量在向量空间中距离也相近
2)难管理,向量数据维度多、数据量大,存储困难,需要设计合理的存储结构、索引结构进行管理
而在大模型应用开发中,我们要经常和向量数据打交道,如知识库最终要进行分块嵌入保存起来、用户输入的文章、图片等内容需要转换为向量才能进行下一步的分析等。向量数据库可以更好的管理高维数据,对高维数据进行高效的存储和查询,满足我们大模型应用开发中的持久化需求。
二 传统数据库和向量数据库对比

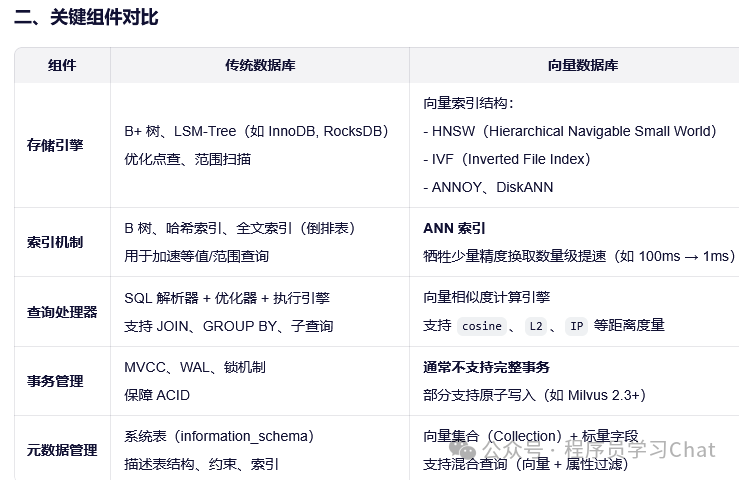


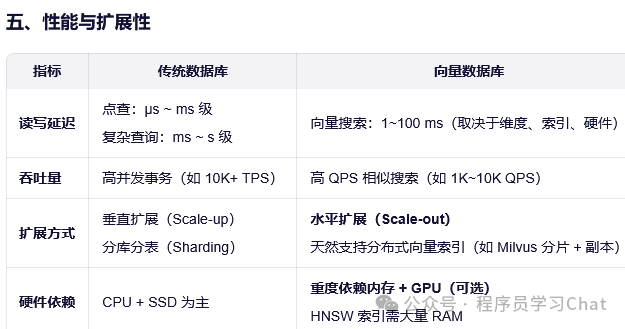
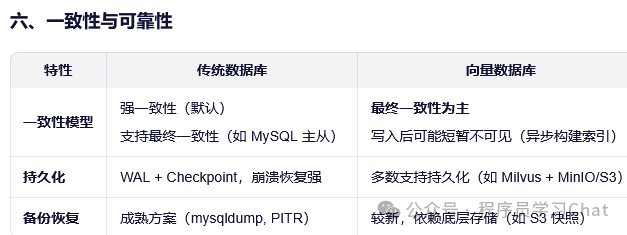
向量数据库(Vector Database)是专为高效存储和检索高维向量(如文本、图像、音频的嵌入表示)而设计的系统。其核心目标是支持近似最近邻搜索(Approximate Nearest Neighbor, ANN),在可接受的精度损失下,将原本 O(N) 的精准最近邻暴力搜索复杂度降低到 O(logN) 甚至更低。










举例来说,原始文本信息经过嵌入模型嵌入变为向量,向量数据库对其进行索引构建、存储,持久化到向量数据库中,用户新输入一段文本,想查询向量数据库中和这个新文本最相似的top k个文本。我们需要利用同一个嵌入模型将用户新输入的文本进行嵌入,得到新输入文本的嵌入向量,向量数据库根据新输入文本的嵌入向量和已经保存的嵌入向量进行向量层面的相似性搜索,因为有索引结构的加持,这个速度回很快,找到top k个最相似的文本嵌入向量后,返回给用户这些向量对应的原文本信息。

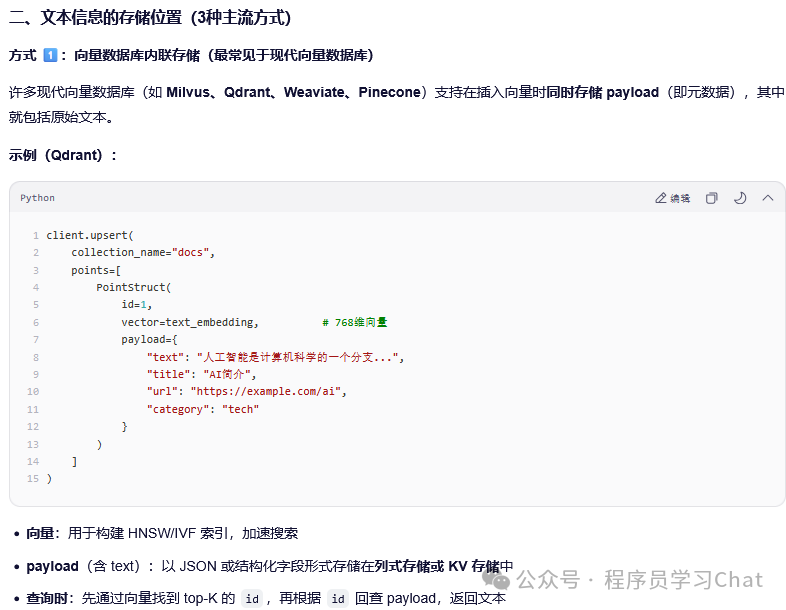



三 向量嵌入空间评估
评估一个向量嵌入空间(Embedding Space)的质量,是构建高质量语义搜索、推荐系统或 RAG 系统的关键前提。嵌入质量直接影响下游任务的性能。评估方法可分为内在评估(Intrinsic Evaluation)和外在评估(Extrinsic Evaluation)两大类。







3.1 t-SNE
t-SNE(t-Distributed Stochastic Neighbor Embedding)是一种非线性降维与可视化技术,由 Laurens van der Maaten 和 Geoffrey Hinton 于 2008 年提出。它的核心目标是:将高维数据(如向量嵌入、图像特征)映射到 2D 或 3D 空间,使得原始空间中“相似”的点在低维空间中依然靠近,从而揭示数据的内在结构。t-SNE 是探索性数据分析(EDA)中最常用的可视化工具之一,尤其在 NLP(词/句嵌入)、计算机视觉(图像特征)、单细胞 RNA 测序等领域广泛应用。



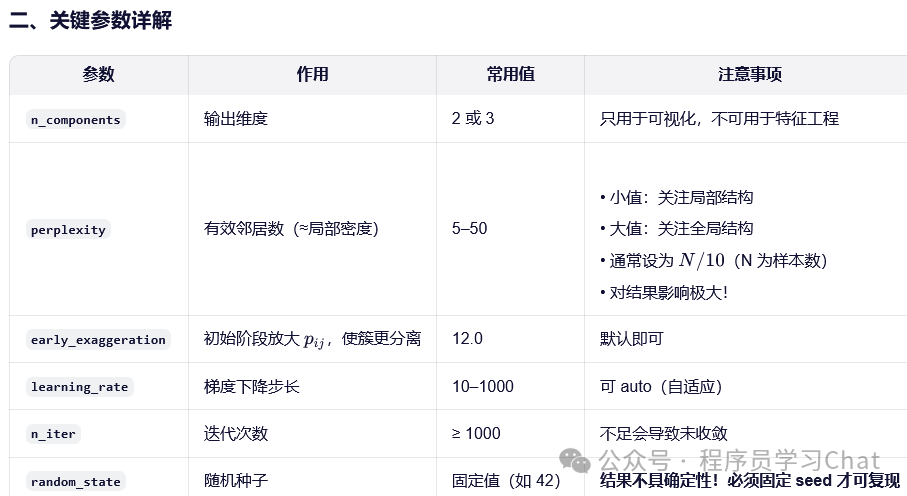
Python实现
import numpy as np
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
from sklearn.datasets import fetch_openml
# 1. 加载数据(以 MNIST 为例)
mnist = fetch_openml('mnist_784', version=1, as_frame=False)
X = mnist.data[:5000] # 取前 5000 张图片(784 维)
y = mnist.target[:5000].astype(int)
# 2. 应用 t-SNE
tsne = TSNE(
n_components=2,
perplexity=30,
n_iter=1000,
random_state=42,
verbose=1
)
X_tsne = tsne.fit_transform(X)
# 3. 可视化
plt.figure(figsize=(10, 8))
scatter = plt.scatter(X_tsne[:, 0], X_tsne[:, 1], c=y, cmap='tab10', s=5)
plt.colorbar(scatter)
plt.title('t-SNE visualization of MNIST')
plt.xlabel('t-SNE dim 1')
plt.ylabel('t-SNE dim 2')
plt.show()输出效果:
每个数字(0–9)形成清晰簇
相似数字(如 4/9、3/5)可能部分重叠
3.2 UMAP
UMAP(Uniform Manifold Approximation and Projection)是一种非线性降维与可视化技术,由 Leland McInnes、John Healy 和 James Melville 于 2018 年提出。它旨在将高维数据(如文本嵌入、图像特征、基因表达向量)映射到低维空间(通常是 2D 或 3D),同时保留数据的局部和全局拓扑结构。UMAP 已成为 t-SNE 的强大替代品,因其速度更快、可扩展性更好、支持新样本映射(out-of-sample extension),并能更好地保留全局结构,在机器学习、生物信息学、自然语言处理等领域广泛应用。



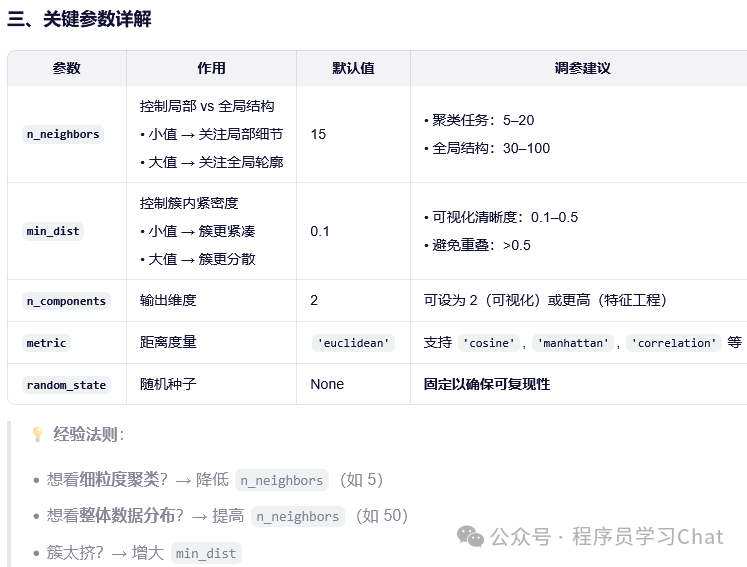

Python实现
import umap
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_openml
# 加载数据
mnist = fetch_openml('mnist_784', version=1, as_frame=False)
X = mnist.data[:10000] # 1 万张图片
y = mnist.target[:10000].astype(int)
# UMAP 降维
reducer = umap.UMAP(
n_neighbors=15,
min_dist=0.1,
n_components=2,
metric='euclidean',
random_state=42
)
embedding = reducer.fit_transform(X)
# 可视化
plt.figure(figsize=(12, 10))
plt.scatter(embedding[:, 0], embedding[:, 1], c=y, cmap='Spectral', s=0.5)
plt.colorbar(boundaries=range(11))
plt.title('UMAP projection of MNIST')
plt.show()UMAP也常用做衡量多模态对齐的工具



四 向量数据库索引
向量数据库的核心挑战是:如何在海量高维向量中快速找到与查询向量最相似的 Top-K 项?暴力搜索的时间复杂度为 O(Nd)(N 为向量数,d 为维度),当 N=108、d=1024 时就已经完全不可行。向量索引(Vector Index)就是为解决这一问题而设计的数据结构——它通过预处理原始向量,为它们构建一种近似但高效的检索结构,将搜索复杂度降至 O(logN) 或更低,同时保持较高的召回率(Recall)。
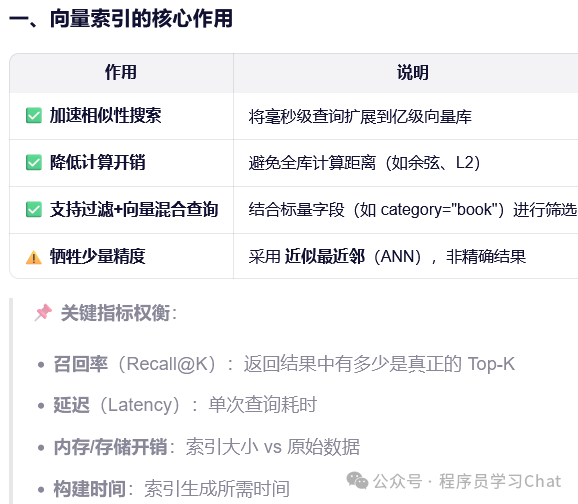






树索引的特性导致大模型应用开发中较少使用


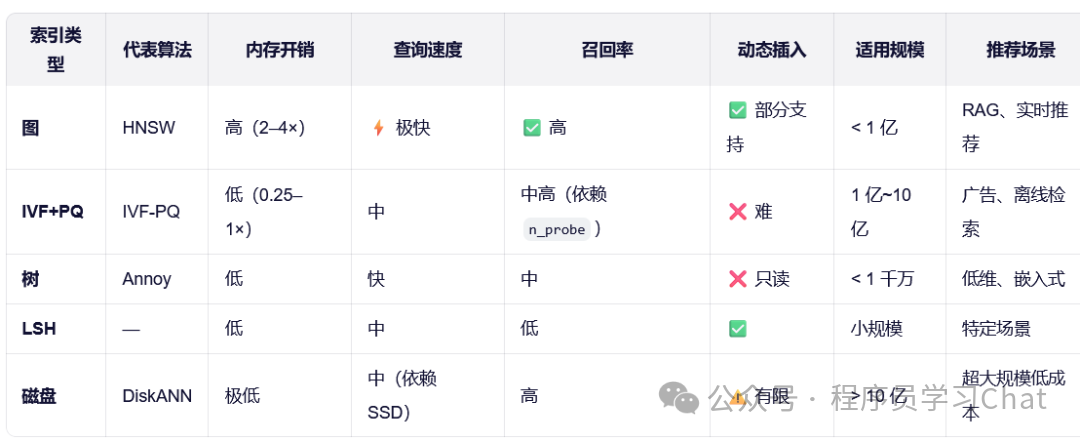
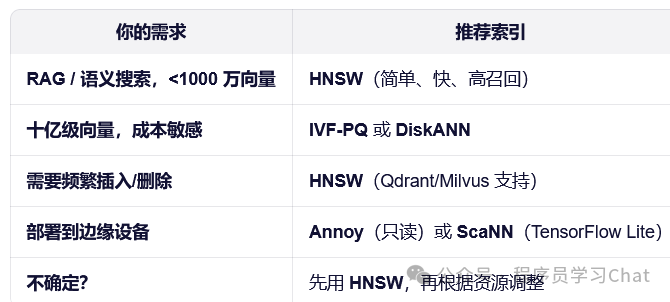
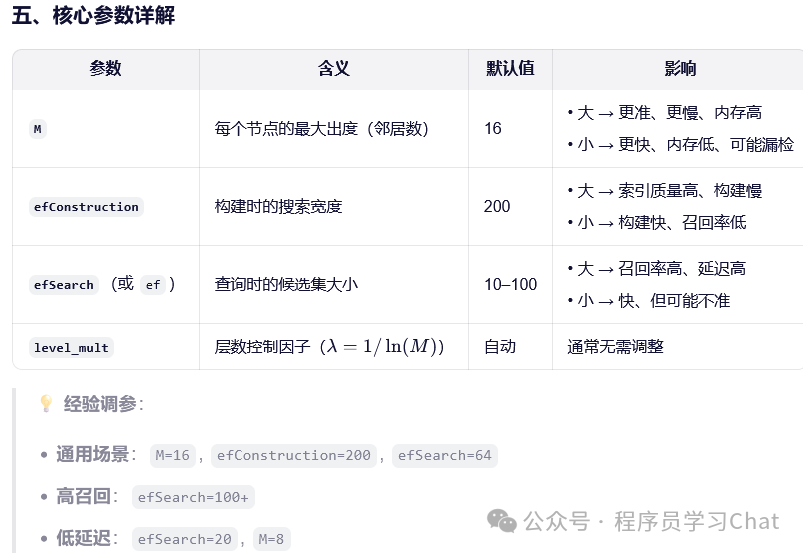
4.1 图结构索引-HNSW
HNSW(Hierarchical Navigable Small World)是目前最主流、性能最优异的近似最近邻(ANN)索引之一,由 Yu. A. Malkov 和 D. A. Yashunin 于 2016 年提出。它被广泛应用于 Milvus、Qdrant、Weaviate、FAISS、Elasticsearch 等向量数据库中,尤其适合高维、大规模、低延迟的语义搜索场景(如 RAG、推荐系统)。






FAISS向量数据库实现
import faiss
import numpy as np
# 1. 准备数据
d = 768 # 向量维度
nb = 100_000 # 向量数量
nq = 1000 # 查询数量
xb = np.random.random((nb, d)).astype('float32')
xq = np.random.random((nq, d)).astype('float32')
# 2. 创建 HNSW 索引
index = faiss.IndexHNSWFlat(d, 16) # dim=768, M=16
index.hnsw.efConstruction = 200 # 构建参数
index.verbose = True # 打印日志
# 3. 添加向量(自动构建索引)
index.add(xb)
# 4. 设置查询参数
index.hnsw.efSearch = 64
# 5. 执行搜索
k = 10
D, I = index.search(xq, k) # D: 距离, I: ID
print(f"Top-10 IDs for first query: {I[0]}")
print(f"Distances: {D[0]}")4.2 IVF-PQ索引









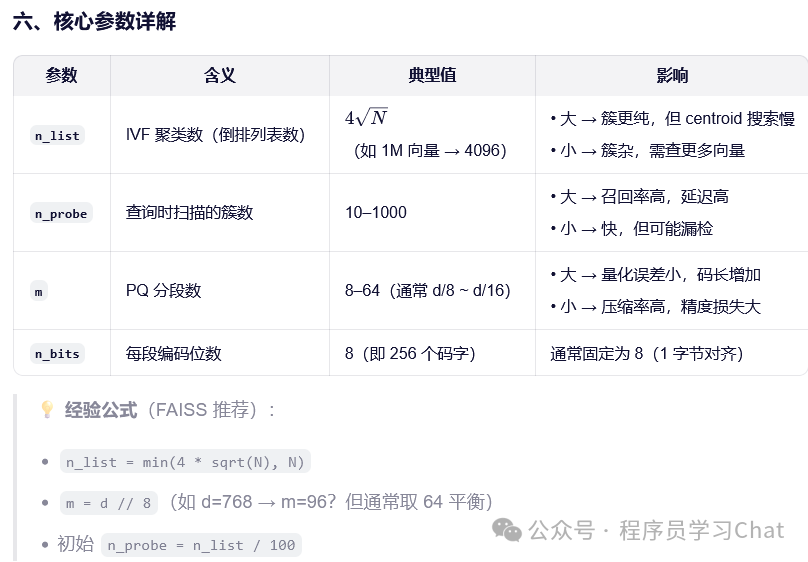

FAISS向量数据库实现
import faiss
import numpy as np
# 1. 数据准备
d = 768
nb = 1_000_000 # 100 万向量
nq = 1000
xb = np.random.random((nb, d)).astype('float32')
xq = np.random.random((nq, d)).astype('float32')
# 2. 创建 IVF-PQ 索引
n_list = 4096 # IVF 聚类数
m = 64 # PQ 分段数(768/64=12 维/段)
quantizer = faiss.IndexFlatIP(d) # 内部用于聚类的索引
index = faiss.IndexIVFPQ(quantizer, d, n_list, m, 8) # 8 bits per subvector
# 3. 必须先 train!
index.train(xb)
# 4. 添加向量
index.add(xb)
# 5. 设置查询参数
index.nprobe = 10 # 扫描 10 个簇
# 6. 搜索
k = 10
D, I = index.search(xq, k)
print(f"Top-10 IDs: {I[0]}")
print(f"Distances: {D[0]}")4.3 哈希索引-LSH







4.4 磁盘优化索引-DiskANN
DiskANN 是一种专为超大规模向量检索(十亿级甚至百亿级)设计的磁盘友好型近似最近邻(ANN),由微软研究院在 2020 年左右提出,并已成功应用于 Microsoft Bing 搜索引擎等生产系统。它巧妙地结合了内存索引引导 + SSD 高吞吐 I/O,在极低内存占用下实现高召回、低延迟的向量搜索。








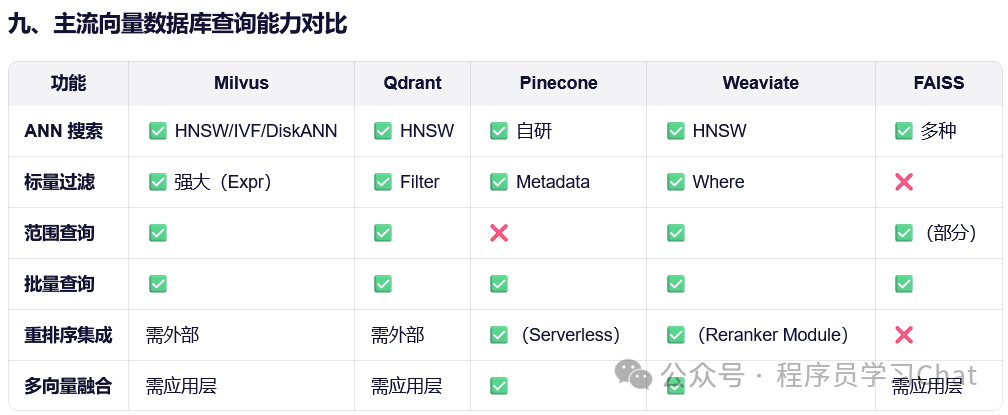
五 向量数据库查询









六 FAISS的使用
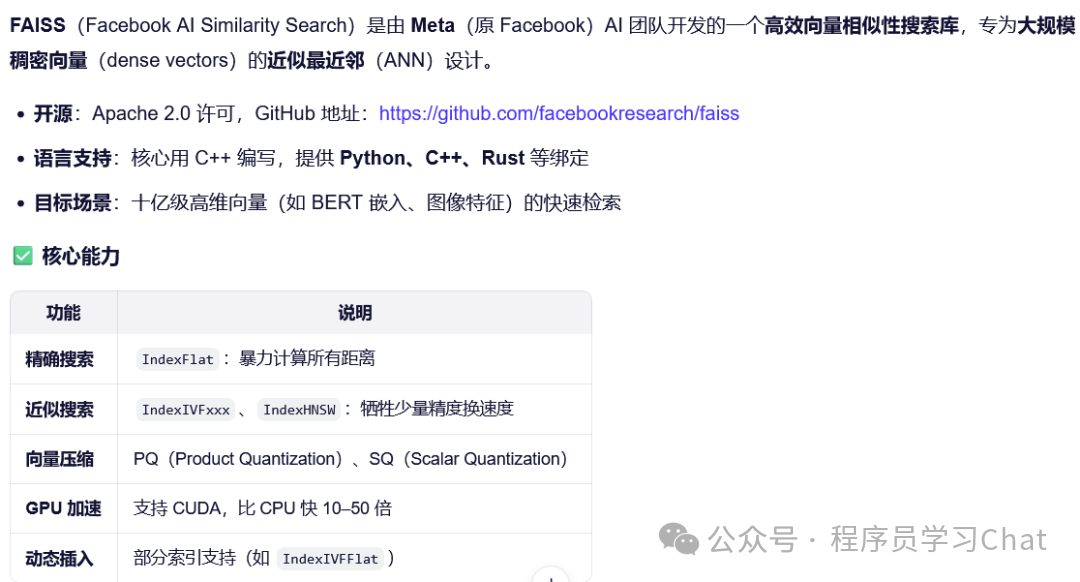

6.1 安装(Python)
# cpu版本
pip install faiss-cpu
#GPU加速版本
# 要求:已安装 CUDA Toolkit(如 11.8, 12.1)
pip install faiss-gpu注意!faiss-cpu 和 faiss-gpu 不能共存,需卸载一个再装另一个,GPU 版本在导入时自动使用 GPU,无需额外代码
6.2 不同索引构建

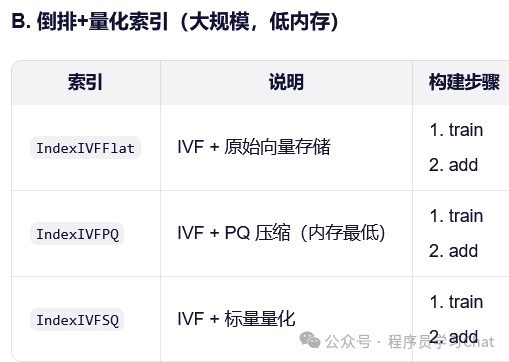
Python示例
d = 768
nlist = 4096 # IVF 聚类数
m = 64 # PQ 分段数(768/64=12 维/段)
quantizer = faiss.IndexFlatIP(d)
# 创建索引
index = faiss.IndexIVFPQ(quantizer, d, nlist, m, 8) # 8 bits per subvector
# 必须先 train!
index.train(train_vectors) # 用部分或全部数据训练
# 添加向量
index.add(vectors)
# 设置查询参数
index.nprobe = 10 # 搜索时扫描 10 个簇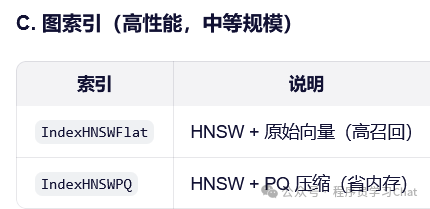
Python示例
d = 768
M = 16 # 每个节点的邻居数
index = faiss.IndexHNSWFlat(d, M, faiss.METRIC_INNER_PRODUCT)
# 可选:设置构建/查询参数
index.hnsw.efConstruction = 200 # 构建时候选集大小
index.hnsw.efSearch = 64 # 查询时候选集大小
index.add(vectors)6.3 不同查询策略
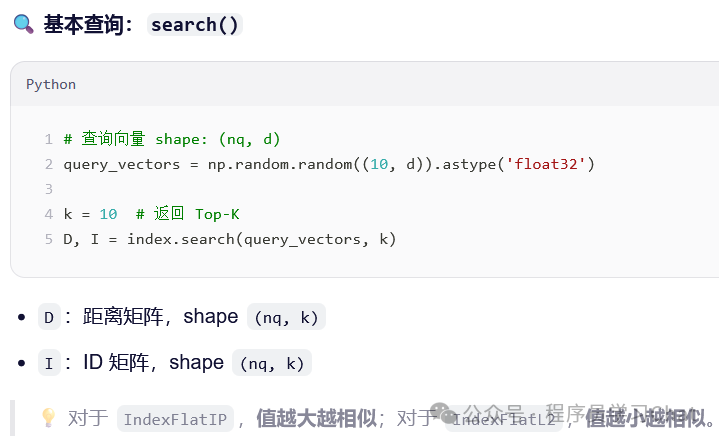
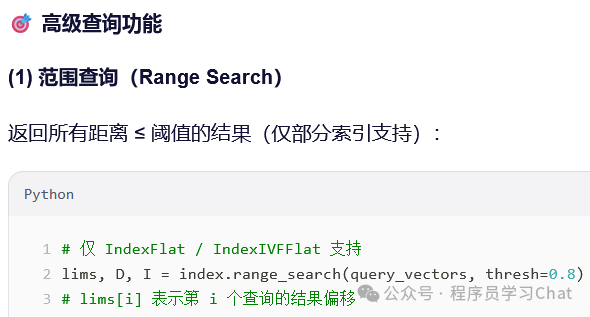

Python示例
import faiss
import numpy as np
# 1. 准备数据
d = 768
nb = 100_000
nq = 1
docs = ["文本1", "文本2", ..., "文本100000"]
vectors = np.random.random((nb, d)).astype('float32') # 实际用 embedding model 生成
query_vec = np.random.random((nq, d)).astype('float32')
# 2. 构建带 ID 的 HNSW 索引
index_flat = faiss.IndexHNSWFlat(d, 16, faiss.METRIC_INNER_PRODUCT)
index = faiss.IndexIDMap(index_flat)
# 自定义 ID(对应文档索引)
ids = np.arange(nb, dtype=np.int64)
index.add_with_ids(vectors, ids)
# 3. 查询
k = 5
D, I = index.search(query_vec, k)
# 4. 返回原文
top_docs = [docs[i] for i in I[0]]
print("Top similar docs:", top_docs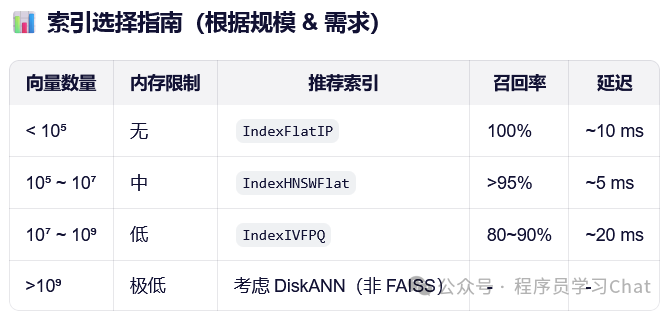

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 4
4 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)