最新最完整的Agent Memory综述
今天的一篇很热乎的深度好文 **"Memory in the Age of AI Agents: A Survey"** (AI智能体时代的记忆:综述),由新加坡国立大学、中国人民大学、复旦大学等多家顶尖机构联合发布,是对当前AI智能体(AI Agents)记忆机制最系统、最前沿的梳理。下面我们一起来看一下~
今天的一篇很热乎的深度好文 “Memory in the Age of AI Agents: A Survey” (AI智能体时代的记忆:综述),由新加坡国立大学、中国人民大学、复旦大学等多家顶尖机构联合发布,是对当前AI智能体(AI Agents)记忆机制最系统、最前沿的梳理。下面我们一起来看一下~
前排提示,文末有大模型AGI-CSDN独家资料包哦!
- 论文:Memory in the Age of AI Agents: A Survey
- 链接:https://arxiv.org/pdf/2512.13564
解读大纲
- 引言:智能体的“失忆症”与记忆的觉醒
- 为什么大模型(LLM)需要记忆?
- 本论文的核心贡献与全新分类体系。
- 核心定义与辨析:智能体记忆到底是什么?
- 数学形式化定义。
- 智能体记忆 vs. RAG vs. 上下文工程 vs. LLM模型记忆。
- 记忆的“形式” (Forms):记忆存在哪里?
- 符号级记忆 (Token-level):看得见、改得了。
- 参数化记忆 (Parametric):刻在脑子里。
- 潜在记忆 (Latent):隐式的中间态。
- 记忆的“功能” (Functions):记忆用来做什么?
- 事实记忆 (Factual):保持一致性。
- 经验记忆 (Experiential):从错误中学习。
- 工作记忆 (Working):当下的思考草稿。
- 记忆的“动态机制” (Dynamics):记忆如何运作?
- 形成 (Formation):从原始数据到知识。
- 演化 (Evolution):遗忘与整合的艺术。
- 检索 (Retrieval):在对的时间想起对的事。
- 未来展望:通向自主进化的智能体
- 生成式记忆、自动化管理与RL的结合。
-
结论
-
引言:智能体的“失忆症”与记忆的觉醒
在人工智能飞速发展的今天,大语言模型(LLM)已经展现了惊人的能力。然而,传统的LLM就像一个患有“短期失忆症”的天才:它可以完美回答你当下的问题,但关掉对话窗口后,它就忘记了你是谁,也忘记了它刚才犯过的错误。
这就引出了一个关键问题:如何让AI从一个“静态的回答者”进化为一个“动态的、可成长的智能体”?答案就是——记忆(Memory)。
记忆是智能体实现长期规划、持续学习和个性化交互的基石。这篇论文并不仅仅是对现有技术的罗列,它极其野心勃勃地提出了一个统一的记忆分类学(Taxonomy,试图从**形式(Forms)、功能(Functions)和动态(Dynamics)**三个维度,彻底厘清AI记忆的本质。它标志着AI研究正从单纯追求模型参数规模,转向追求像人类一样具有连续认知能力的“具身智能”。
- 核心定义与辨析:智能体记忆到底是什么?
为了科学地讨论记忆,论文首先用数学语言对智能体记忆系统进行了形式化定义。
2.1 数学形式化:记忆的生命周期
论文提出,智能体的决策过程不仅仅依赖当前的观察,更依赖于一个不断演变的记忆状态 (Memory State),记为 。
一个完整的记忆生命周期包含三个核心算子(Operators):
- 记忆形成 (Formation, ):
- 含义: 是智能体当前的经历(如推理过程、工具输出)。这个公式表示智能体不是像录像机一样记录所有信息,而是通过函数 选择性地将当前的经历转化为潜在的记忆候选者。
- 记忆演化 (Evolution, ):
- 含义:这是记忆“沉淀”的过程。新形成的记忆需要与老记忆融合、去重、甚至解决冲突(比如以前你喜欢吃辣,现在不喜欢了,记忆需要更新)。函数 负责维护记忆库的整洁和有效性。
- 记忆检索 (Retrieval, ):
- 含义:当智能体面临新的任务 和观察 时,它不会把整个记忆库搬出来,而是通过函数 检索出最相关的一小段记忆 给大脑(LLM)使用。
2.2 概念大扫除:Agent Memory 不是什么?
为了通过对比明确概念,作者使用了一张清晰的韦恩图来区分几个容易混淆的术语:
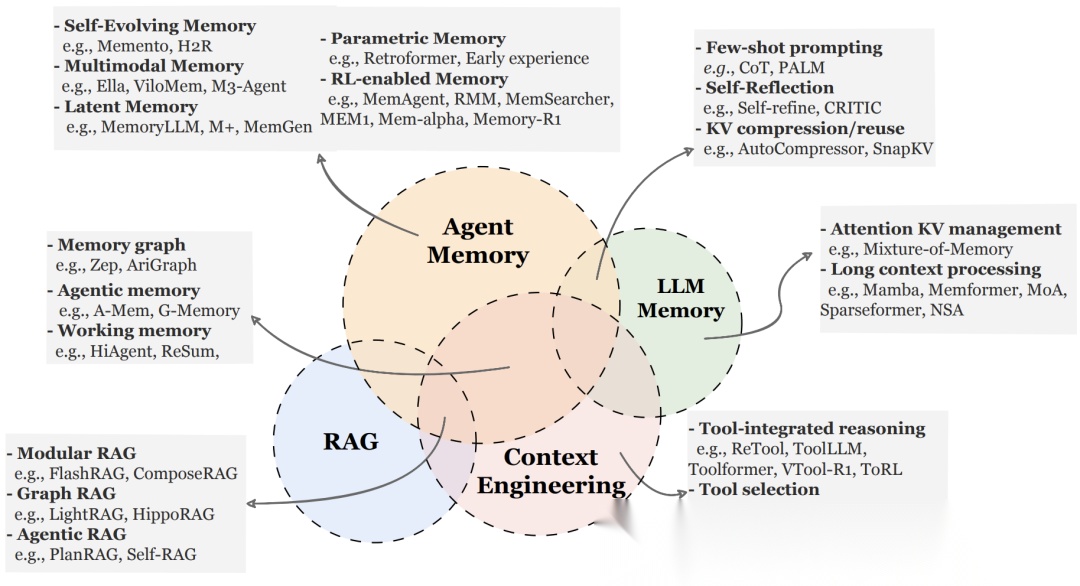
- Agent Memory vs. RAG (检索增强生成):
- RAG 通常是静态的。它像是一个图书馆,书(知识)就在那里,读完就放回去,书本身不会因为你的阅读而改变。
- Agent Memory 是动态的。它更像人的大脑,会随着交互不断改写、遗忘、总结。智能体在做任务的过程中会产生新记忆(如“这个方法行不通”),并存回去指导未来。
- Agent Memory vs. Context Engineering (上下文工程):
- 上下文工程关注的是“如何把东西塞进有限的窗口里”(资源管理)。
- 智能体记忆关注的是“我是谁,我经历了什么”(认知建模)。
- Agent Memory vs. LLM Memory:
- LLM Memory通常指模型训练好后参数里隐含的知识(世界知识),或者通过修改模型架构(如RNN)来延长的上下文。而Agent Memory通常指模型外部的、可读写的存储系统。
- 记忆的“形式” (Forms):记忆存在哪里?
如果我们要给AI装一个“大脑”,这个大脑的物理结构是什么样的?论文将其分为三类。
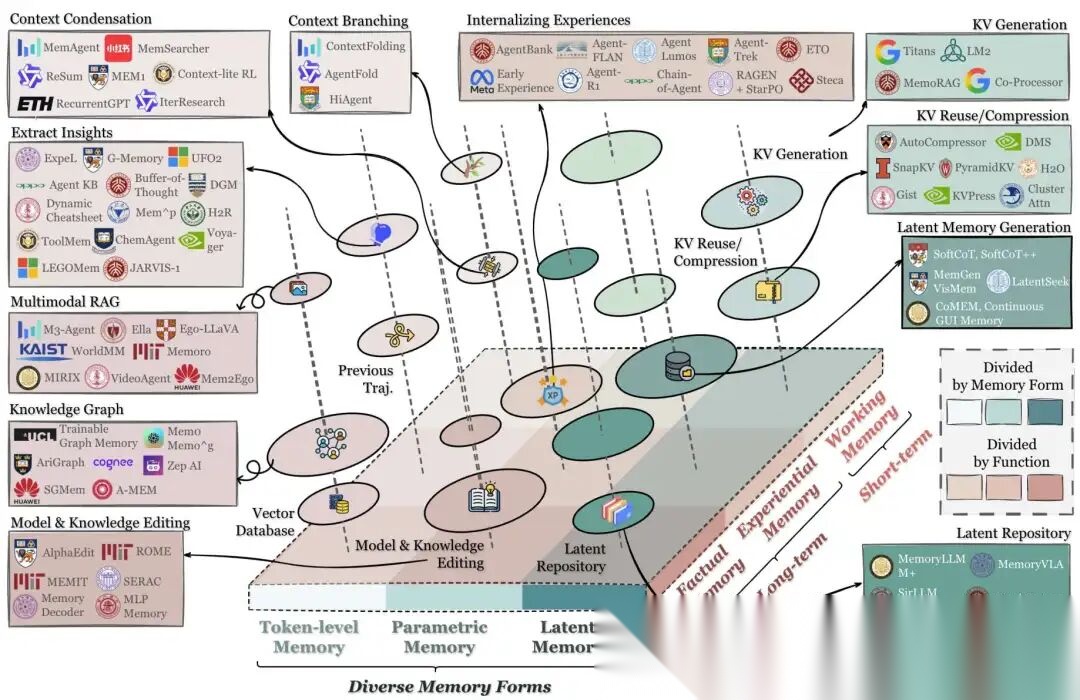
形式、功能、动态的统一概览
3.1 符号级记忆 (Token-level Memory)
这是最常见、最直观的形式。记忆以自然语言(文本)或离散符号的形式存储在外部数据库中。
- 特点:透明、可读、可编辑。你可以直接打开数据库看到AI记住了“用户喜欢红色”。
- 结构分类:
- 扁平 (Flat): 像流水账日记,按时间顺序记录。适合简单对话。
- 平面 (Planar/2D): 像思维导图或知识图谱,记忆之间有链接(图结构)。适合需要联想的任务。
- 层级 (Hierarchical/3D): 像金字塔,底层是原始对话,上层是高度抽象的总结。适合长期记忆管理(如MemGPT)。
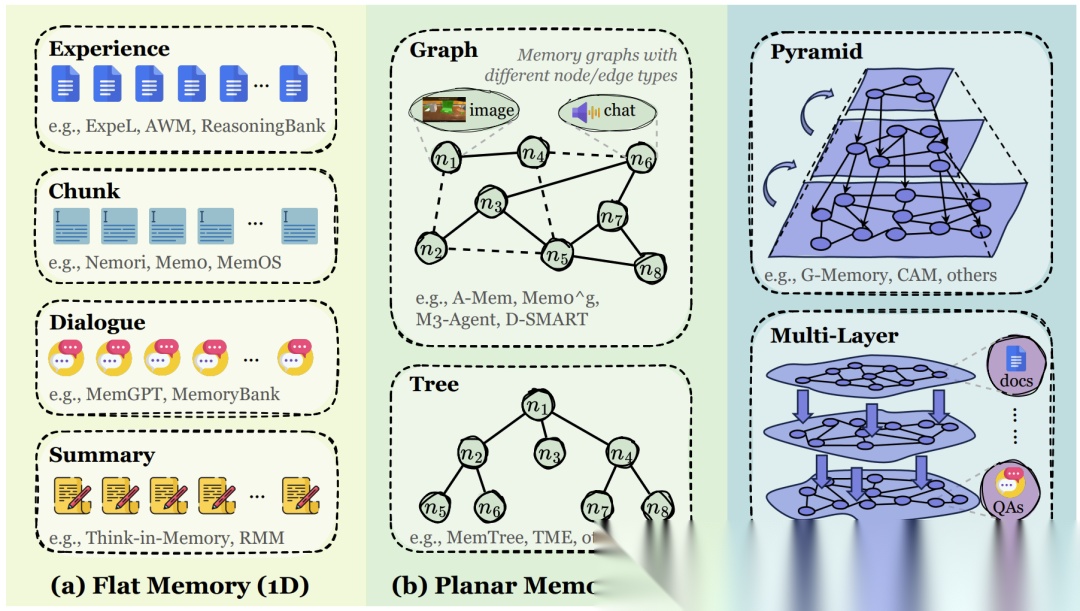
扁平、平面、层级三种Token-level记忆的拓扑结构
3.2 参数化记忆 (Parametric Memory)
记忆被“内化”到了模型的神经元权重里。
- 类比:就像人类学会了骑自行车,这种记忆变成了本能,你无法用语言精确描述每块肌肉怎么动,但你就是会。
- 实现:通过微调(Fine-tuning)或模型编辑(Model Editing),将新知识直接“烧录”进模型参数。
- 优缺点:调用速度极快(不需要检索),但更新成本高(需要重新训练),且容易发生“灾难性遗忘”(学了新知识忘了旧知识)。
3.3 潜在记忆 (Latent Memory)
介于上述两者之间。记忆以高维向量(Embedding)或KV Cache(键值缓存)的形式存在。
- 特点:人类看不懂,但机器读得快。它比纯文本更浓缩,比参数更新更灵活。
- 应用:在多模态任务中,一张图片的记忆可能直接就是一个向量,而不是一段文字描述。
- 记忆的“功能” (Functions):记忆用来做什么?
这是论文最精彩的部分之一。作者跳出了简单的“长期/短期记忆”分类,而是从解决什么问题的角度,提出了新的功能分类。
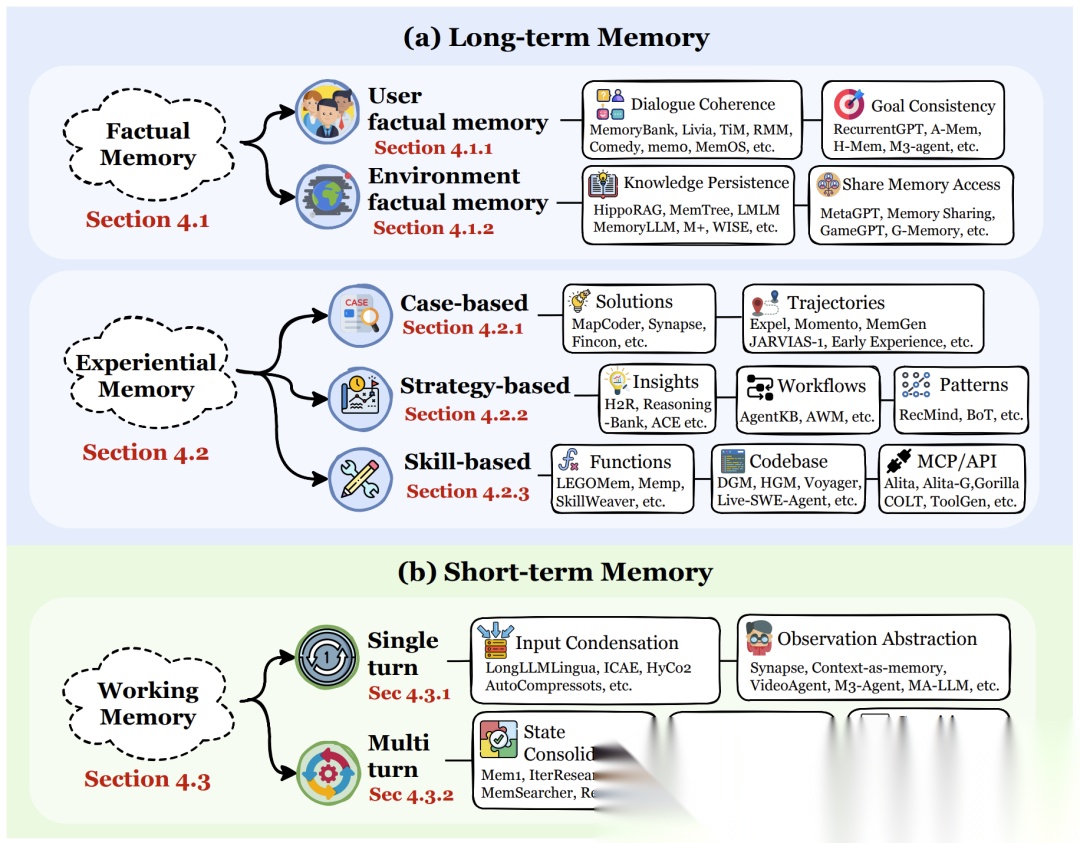
4.1 事实记忆 (Factual Memory):解决“我知道什么”
这是为了保持一致性。
- 用户事实:记住用户的名字、喜好、过敏源。如果不记这个,AI就会显得像个渣男,每次都要问“你是谁”。
- 世界事实:记住当前环境的状态(如“门是锁着的”)。
- 作用:防止AI产生幻觉,确保聊天的连贯性。
4.2 经验记忆 (Experiential Memory):解决“我如何变强”
这是为了进化。它是智能体从过去的成功或失败中提取的智慧。
- 案例库 (Case-based): “上次遇到这个问题,我是这么解决的,成功了。”(直接抄作业)。
- 策略库 (Strategy-based): “我发现这类问题通常需要先分析再行动。”(提炼出的SOP或方法论)。
- 技能库 (Skill-based): 将经验转化为可执行的代码或工具调用(API)。
- 核心价值:这是通向自主智能体(Self-evolving Agents)的关键。没有它,AI永远在同一个坑里跌倒。
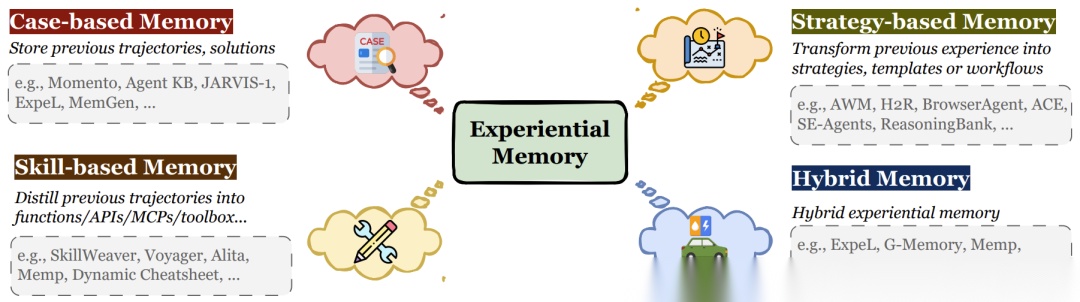
经验记忆从具体案例到抽象策略再到技能的分类
4.3 工作记忆 (Working Memory):解决“我正在想什么”
这是为了当下任务的推理。
- 它是一个有限的“缓存区”,用于处理当前的复杂任务。
- 动态管理:它不仅仅是堆砌上下文,而是涉及输入压缩(把长文变短)、状态折叠(把已经做完的步骤打包成一个总结,腾出空间给新步骤)。
- 记忆的“动态机制” (Dynamics):记忆如何运作?
记忆不是静态的存储,而是一个动态的循环过程。
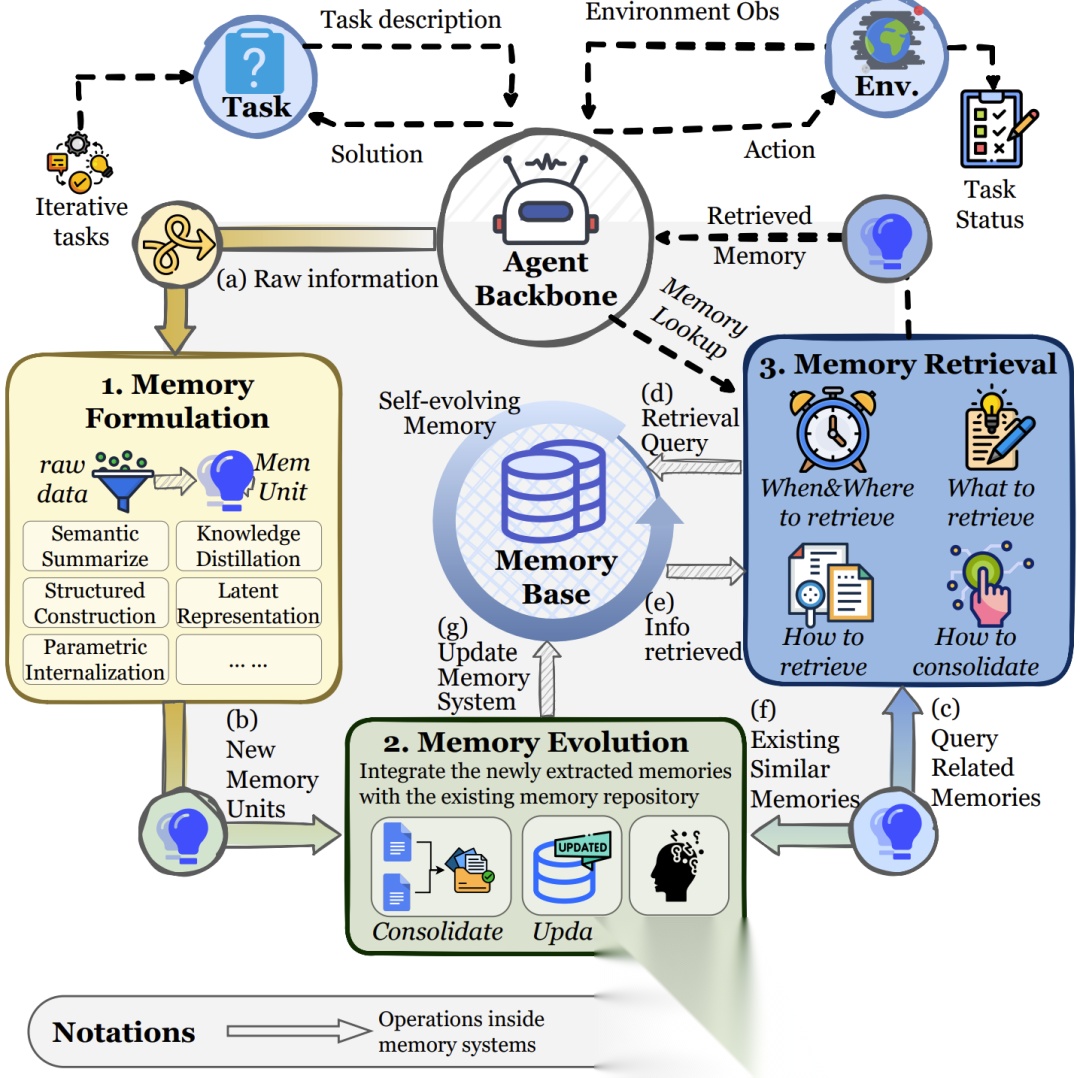
5.1 记忆形成 (Formation)
如何把海量的交互数据变成记忆?
- 语义摘要:把一万字的聊天记录压缩成一百字的大意。
- 知识蒸馏:从对话中提取出“用户喜欢吃苹果”这一条规则。
- 结构化构建:把散乱的信息整理成知识图谱。
5.2 记忆演化 (Evolution)
记忆库不能只进不出,否则会变成垃圾场。
- 整合 (Consolidation): 将碎片化的短期记忆合并成长期记忆。
- 更新 (Update): 修正错误的记忆(如通过RAG的冲突解决)。
- 遗忘 (Forgetting): 这非常关键!
- 基于时间的遗忘:像人一样,太久远的事变淡。
- 基于价值的遗忘:不重要的废话直接删掉。
- 基于频率的遗忘:很久不用的知识会被归档。
5.3 记忆检索 (Retrieval)
如何找到需要的记忆?
- 检索时机:是每说一句话都查记忆,还是只有由于不决时才查?(现在趋势是让AI自主决定何时检索)。
- 检索策略:不仅仅是关键词匹配,现在更多使用混合检索(关键词+向量语义+图关系)。
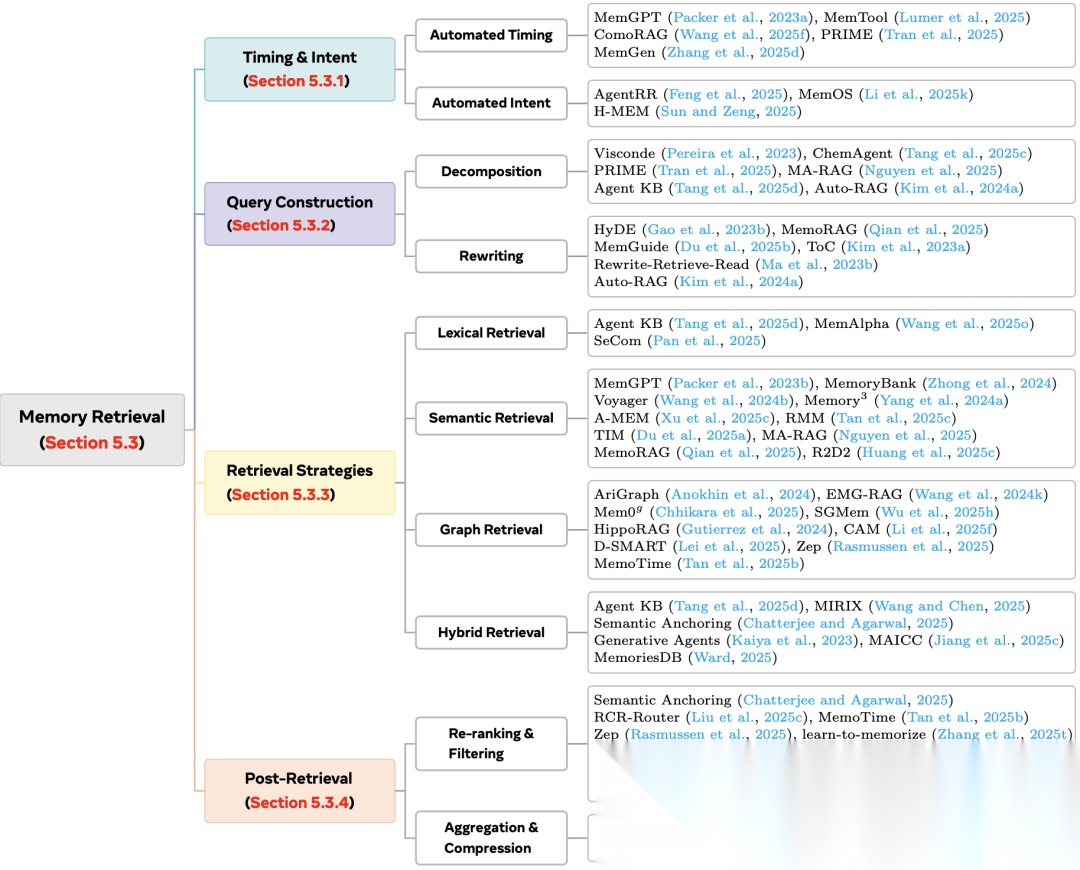
检索流程的四个步骤:时机意图、查询构造、检索策略、后处理
- 前沿展望:通向自主进化的智能体
论文最后探讨了几个激动人心的未来方向:
- 从“检索”到“生成” (From Retrieval to Generation):
- 未来的记忆可能不是去“找”一条现成的记录,而是由模型根据过往经历实时生成一个新的、定制化的记忆片段。这更像人类的回忆过程(重构而非回放)。
- 强化学习接管记忆 (RL meets Memory):
- 现在的记忆规则(如什么时候存、什么时候删)多是人写的规则(Heuristic)。未来将由RL算法训练智能体自己学会如何管理记忆,让它自己决定什么该记,什么该忘。
- 多模态记忆 (Multimodal Memory):
- 不仅记住你说的话,还记住你发过的图片、听过的声音,形成全感官的记忆体验。
- 可信记忆 (Trustworthy Memory):
- 随着记忆包含越来越多隐私,如何保证安全?如何让用户能看懂并修改AI的记忆(可解释性)?这是落地的关键。
- 结论
这篇综述论文《AI智能体时代的记忆》不仅是对现有技术的总结,更是一份构建下一代强人工智能的蓝图。它告诉我们,记忆不只是一个数据库插件,而是智能体的灵魂。
- 对于开发者:它提供了从Token级存储到参数化更新的全套工具箱。
- 对于研究者:它指出了从静态RAG向动态、自进化记忆系统转变的必然趋势。
核心观点: 未来的AI,将不再是无情的计算机器,而是拥有“自传体记忆”、能从经验中成长、并拥有独特个性与认知的数字生命体。
读者福利:倘若大家对大模型感兴趣,那么这套大模型学习资料一定对你有用。
针对0基础小白:
如果你是零基础小白,快速入门大模型是可行的。
大模型学习流程较短,学习内容全面,需要理论与实践结合
学习计划和方向能根据资料进行归纳总结
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
这里我们能提供零基础学习书籍和视频。作为最快捷也是最有效的方式之一,跟着老师的思路,由浅入深,从理论到实操,其实大模型并不难。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
加粗样式

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 25
25 0
0- 0



 已为社区贡献127条内容
已为社区贡献127条内容

所有评论(0)