L2 书生大模型 Browse Use 实践
本文介绍了书生Intern-S1 API的使用方法,包括环境搭建、API调用和多模态交互实现。详细讲解了如何获取API Token,并通过Python SDK和原生调用两种方式进行天气查询、小红书搜索等操作。同时介绍了Browser-Use工具的开发环境配置和Web-UI运行方法,展示了模型与浏览器的交互过程。文中还提供了三轮对话示例代码和API计费规则说明,并针对常见报错给出了解决方案。该技术目
本文将介绍如何利用书生 Intern-S1 API,实现控制浏览器完成查询天气、搜索小红书信息等。当然结合 Intern-S1还有更多的有趣的案例,等待同学们自行探索~
书生 API 介绍及实践
书生 API 是上海人工智能实验室推出的核心产品之一,旨在为开发者提供便捷、高效的大模型调用能力。作为书生大模型全链路开源体系的重要组成部分,其依托 Intern 系列模型(如Intern-s1、InternLM3、InternVL3.5 等)及工具链生态(XTuner、LMDeploy 等),支持文本交互、多模态处理及智能体开发。
本课程仅对API调用作基础讲解~,更多详细内容请参考https://internlm.intern-ai.org.cn/api/document
2.1.1 环境搭建
API 部分可以在本地or开发机上操作都可
步骤 1.安装依赖库
conda activate base
pip install requests openai dotenv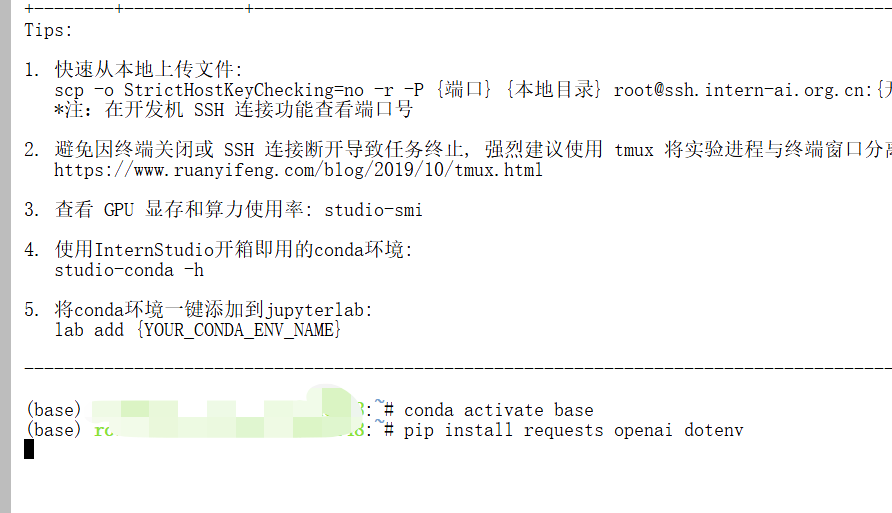
步骤 2.获取API Token
-
访问 书生 AI 官网 注册并申请 API 权限。
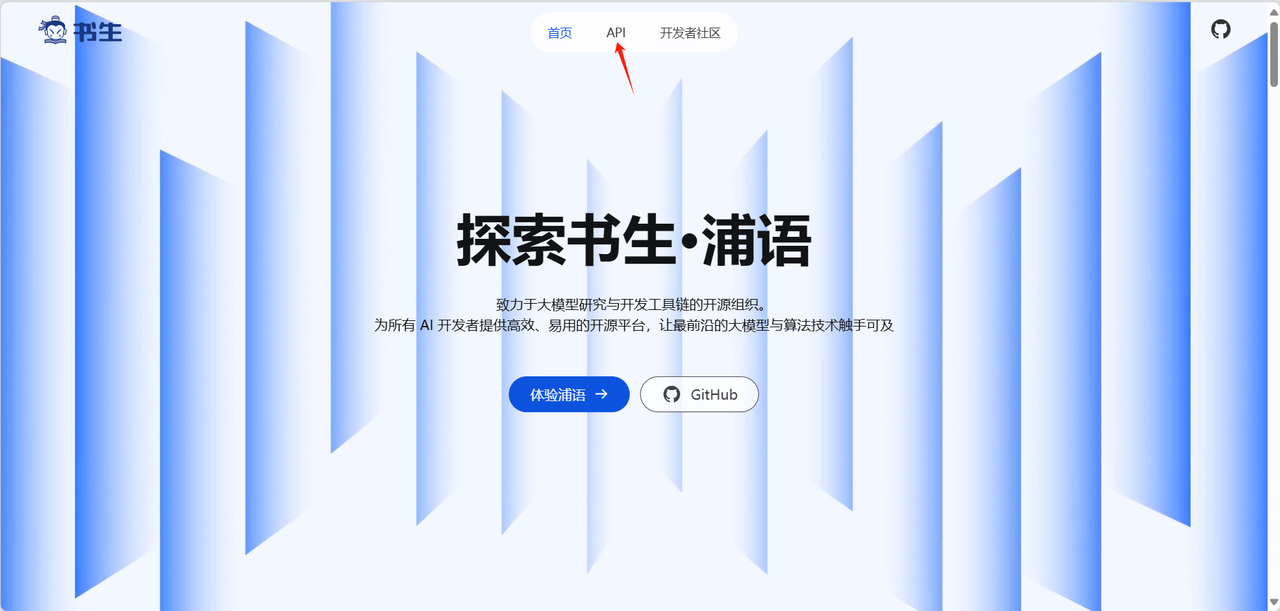
-
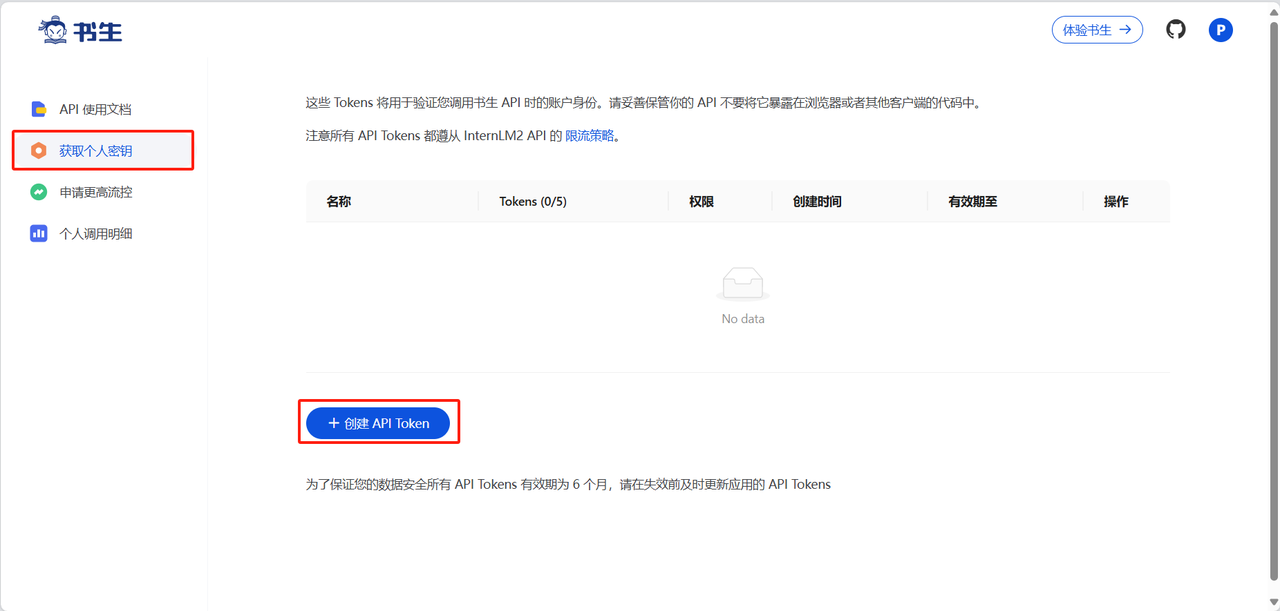
进入到API页面(https://internlm.intern-ai.org.cn/api/tokens)之后,点击获取个人密钥,接着创建API Token。
-
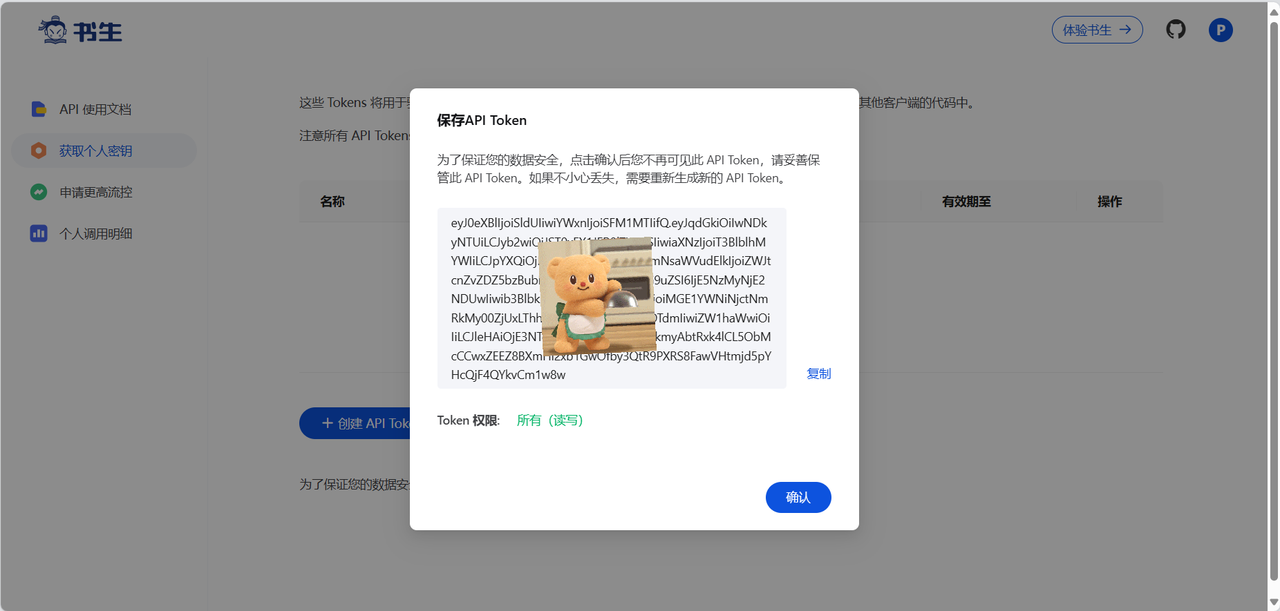
给你的API Token取个名字,接着就能得到一串字符,注意,API Tokne 只能复制一次,点击确认之后,便不可见,妥善保管自己的API Token。且在使用过程中,不要显式地暴露在代码中。
步骤 3.python代码调用
在 /root/Internlm 目录下
-
使用 openai python sdk
from openai import OpenAI
from dotenv import load_dotenv
import os
InternLM_api_key = os.getenv("InternLM", load_dotenv())
client = OpenAI(
api_key=InternLM_api_key,
base_url="https://chat.intern-ai.org.cn/api/v1/",
)
chat_rsp = client.chat.completions.create(
model="intern-s1",
messages=[{
"role": "user", #role 支持 user/assistant/system/tool
"content": "你知道刘慈欣吗?"
}, {
"role": "assistant",
"content": "为一个人工智能助手,我知道刘慈欣。他是一位著名的中国科幻小说家和工程师,曾经获得过多项奖项,包括雨果奖、星云奖等。"
},{
"role": "user",
"content": "他什么作品得过雨果奖?"
}],
stream=False
)
for choice in chat_rsp.choices:
print(choice.message.content)
#若使用流式调用:stream=True,则使用下面这段代码
#for chunk in chat_rsp:
# print(chunk.choices[0].delta.content)
原生调用
import requests
import json
from dotenv import load_dotenv
import os
InternLM_api_key = os.getenv("InternLM", load_dotenv())
url = 'https://chat.intern-ai.org.cn/api/v1/chat/completions'
header = {
'Content-Type':'application/json',
"Authorization":"Bearer "+InternLM_api_key,
}
data = {
"model": "intern-s1",
"messages": [{
"role": "user",
"content": "你好~"
}],
"n": 1,
"temperature": 0.8,
"top_p": 0.9
}
res = requests.post(url, headers=header, data=json.dumps(data))
print(res.status_code)
print(res.json())
print(res.json()["choices"][0]['message']["content"])
2.1.2 多模态交互
-
使用 openai python sdk
from openai import OpenAI
from dotenv import load_dotenv
import os
InternLM_api_key = os.getenv("InternLM", load_dotenv())
client = OpenAI(
api_key=InternLM_api_key,
base_url="https://chat.intern-ai.org.cn/api/v1/",
)
chat_rsp = client.chat.completions.create(
model="intern-s1",
messages=[
{
"role": "user",
"content": "你好"
},
{
"role": "assistant",
"content": "你好,我是 internvl"
},
{
"role": "user",
"content": [ #用户的图文提问内容,数组形式
{
"type": "text", # 支持 text/image_url
"text": "Describe these two images please"
},
{
"type": "image_url",
"image_url": {
"url": "https://static.openxlab.org.cn/internvl/demo/visionpro.png" #支持互联网公开可访问的图片 url 或图片的 base64 编码
}
},
{
"type": "image_url", # 单轮对话支持上传多张图片
"image_url": {
"url": "https://static.openxlab.org.cn/puyu/demo/000-2x.jpg"
}
}
]
}
],
n=1,
stream=False
)
for choice in chat_rsp.choices:
print(choice.message.content)
2.1.3 三轮对话示例代码
from openai import OpenAI
from dotenv import load_dotenv
import os
# 加载环境变量
load_dotenv()
InternLM_api_key = os.getenv("InternLM")
# 初始化客户端
client = OpenAI(
api_key=InternLM_api_key,
base_url="https://chat.intern-ai.org.cn/api/v1/",
)
# 构建包含3轮对话的上下文
messages = [
# 第一轮对话
{
"role": "user",
"content": "你好,请介绍一下你自己"
},
{
"role": "assistant",
"content": "你好!我是 InternVL,一个多模态AI助手。我可以理解和分析文本与图像,帮助您处理各种任务,包括图像描述、视觉问答、文档理解等。有什么我可以帮助您的吗?"
},
# 第二轮对话
{
"role": "user",
"content": "你能处理哪些类型的图像任务?"
},
{
"role": "assistant",
"content": "我可以处理多种图像任务:\\n1. 图像描述:详细描述图片内容\\n2. 视觉问答:回答关于图片的问题\\n3. 图像对比:分析多张图片的异同\\n4. OCR识别:提取图片中的文字\\n5. 图表分析:理解图表、图形数据\\n6. 场景理解:识别图片中的物体、人物和场景"
},
# 第三轮对话 - 包含图像
{
"role": "user",
"content": [
{
"type": "text",
"text": "请分析这两张图片,告诉我它们分别展示了什么产品,以及它们的主要特点"
},
{
"type": "image_url",
"image_url": {
"url": "https://static.openxlab.org.cn/internvl/demo/visionpro.png"
}
},
{
"type": "image_url",
"image_url": {
"url": "https://static.openxlab.org.cn/puyu/demo/000-2x.jpg"
}
}
]
}
]
# 调用API获取最终回复
try:
chat_rsp = client.chat.completions.create(
model="intern-s1",
messages=messages,
n=1,
stream=False,
temperature=0.8, # 控制回复的创造性
max_tokens=500 # 限制回复长度
)
# 打印最终回复
print("=== API 最终回复 ===")
for choice in chat_rsp.choices:
print(choice.message.content)
# 可选:打印整个对话历史
print("\\n=== 完整对话历史 ===")
for i, msg in enumerate(messages):
print(f"\\n轮次 {i//2 + 1}:")
if msg["role"] == "user":
if isinstance(msg["content"], str):
print(f"用户: {msg['content']}")
else:
print(f"用户: {msg['content'][0]['text']}")
print(f" (包含 {len(msg['content'])-1} 张图片)")
else:
print(f"助手: {msg['content']}")
except Exception as e:
print(f"API调用出错: {str(e)}")
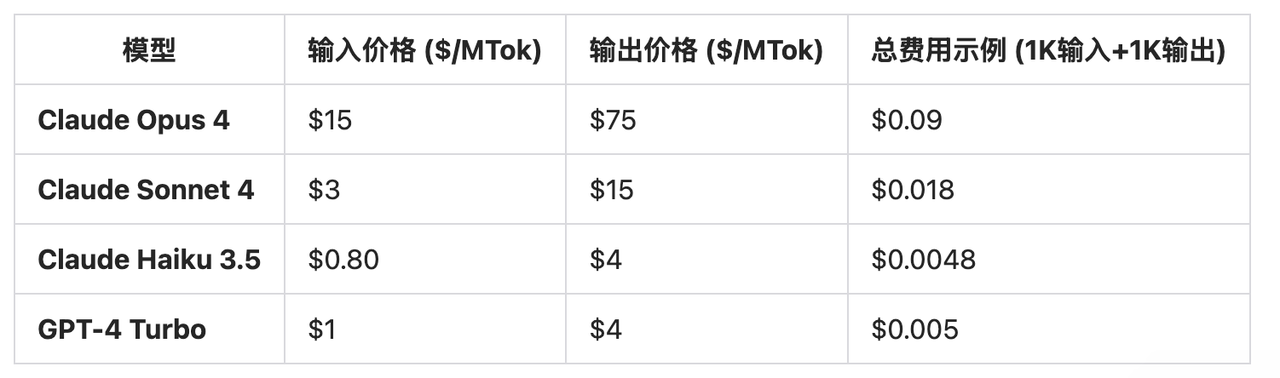
Model api计费规则示例:
# GPT-4 Turbo 价格(2024年)
输入价格:$0.01 / 1K tokens
输出价格:$0.03 / 1K tokens(输出更贵!)
# 一轮对话
你:"帮我写个Python排序函数"(10 tokens)
AI:"def sort_list(lst):..."(100 tokens)
费用 = 10×0.00001 + 100×0.00003 = $0.0031当然现在的顶级模型api价格感人 ——然而书生api免费给大家玩!
2.2 Browser-Use 简介
Browser-Use 是一款专为 Agent 与浏览器交互而设计的工具,通过简洁而高效的自动化接口,使 Agent 能够轻松访问并操作网页。它为大模型与浏览器之间搭建了便捷的桥梁,帮助开发者快速实现网页自动化任务,而无需编写复杂代码。
其运行机制基于模型的多模态能力,并通过固定的 JSON 输出格式与浏览器交互。因此,模型的输出稳定性与能力水平直接决定了工具的整体效果。
2.3 开发环境配置
Browser-user 部分需在本地电脑(os:Windows,macOS)实现,方便观察 Agent 操控操作网页过程~
步骤 1.安装 git
Windows:
-
下载并安装适合您 Windows 版本的安装程序:下载地址
-
按照安装向导完成安装。(默认设置安装即可)
-
打开终端,输入指令
git --version检查是否安装成功
MacOS:
-
下载并安装适合您 MacOS 版本的安装程序:下载地址
-
按照安装向导完成安装。(默认设置安装即可)
-
打开终端,输入指令
git --version检查是否安装成功
安装成功后,使用git将browser-use项目克隆到本地
git clone https://github.com/fak111/Web-ui.git
cd Web-ui步骤 2.安装 uv 并创建项目环境
这里我们使用uv进行项目环境管理,直接使用Python自带的pip安装,兼容性最佳,这里需要python版本为3.8及以上:
pip install uv
# 检测是否安装成功,出现版本号则成功
uv --version 
如果没安装python需要去 Python 官网 下载安装包,安装时勾选 “Add Python to PATH”(安装向导底部),并选择 自定义安装 → 确保勾选 “Install pip”。
另外,如果网速不行pip下载包的时候可以加 -i https://pypi.tuna.tsinghua.edu.cn/simple/ 起到一个换下载源加速的作用。
接着输入以下命令来创建项目环境并进入
# 第一步:创建环境(只需执行一次)
uv venv Internlm --python 3.11
# 第二步:根据你的操作系统激活环境(每次使用项目时都需要)
# 如果是Windows:
Set-ExecutionPolicy -Scope Process -ExecutionPolicy Bypass
.\Internlm\Scripts\Activate.ps1
# 如果是macOS:
source Internlm/bin/activate步骤 3.在项目环境下安装依赖
安装项目依赖
uv pip install -r requirements.txt
uv pip install --upgrade gradio -i https://pypi.tuna.tsinghua.edu.cn/simple/
uv pip install "httpx[socks]" -i https://pypi.tuna.tsinghua.edu.cn/simple/
playwright install --with-deps chromium
playwright install
web-ui下有个.env.example文件,这是我们项目的启动配置,复制一份并重命名为 .env,然后填写我们的 key
# macOS/Linux/Windows (PowerShell):
cp .env.example .env启动 Browser-use Web-UI
2.3.1 运行 Web-UI
运行 WebUI,完成上面的安装步骤后,启动应用程序:
python webui.py --ip 127.0.0.1 --port 7788启动后,打开 http://127.0.0.1:7788 即可看到以下界面
上面启动的服务可以通过端口映射查看
ssh -CNg -L 本地映射端口号:127.0.0.1:部署的web-ui端口号 root@ssh.intern-ai.org.cn -p 开发机SSH端口号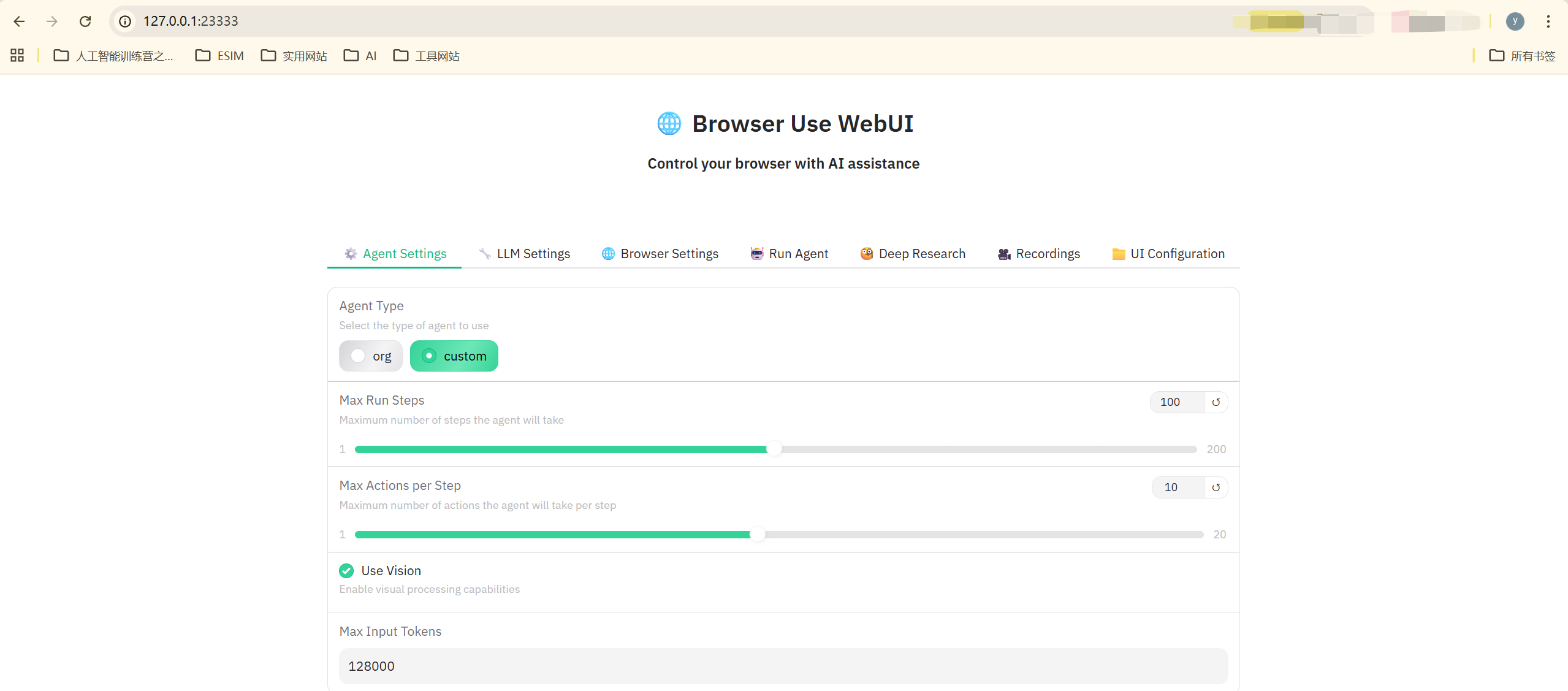
2.3.2 Web-UI 选项配置
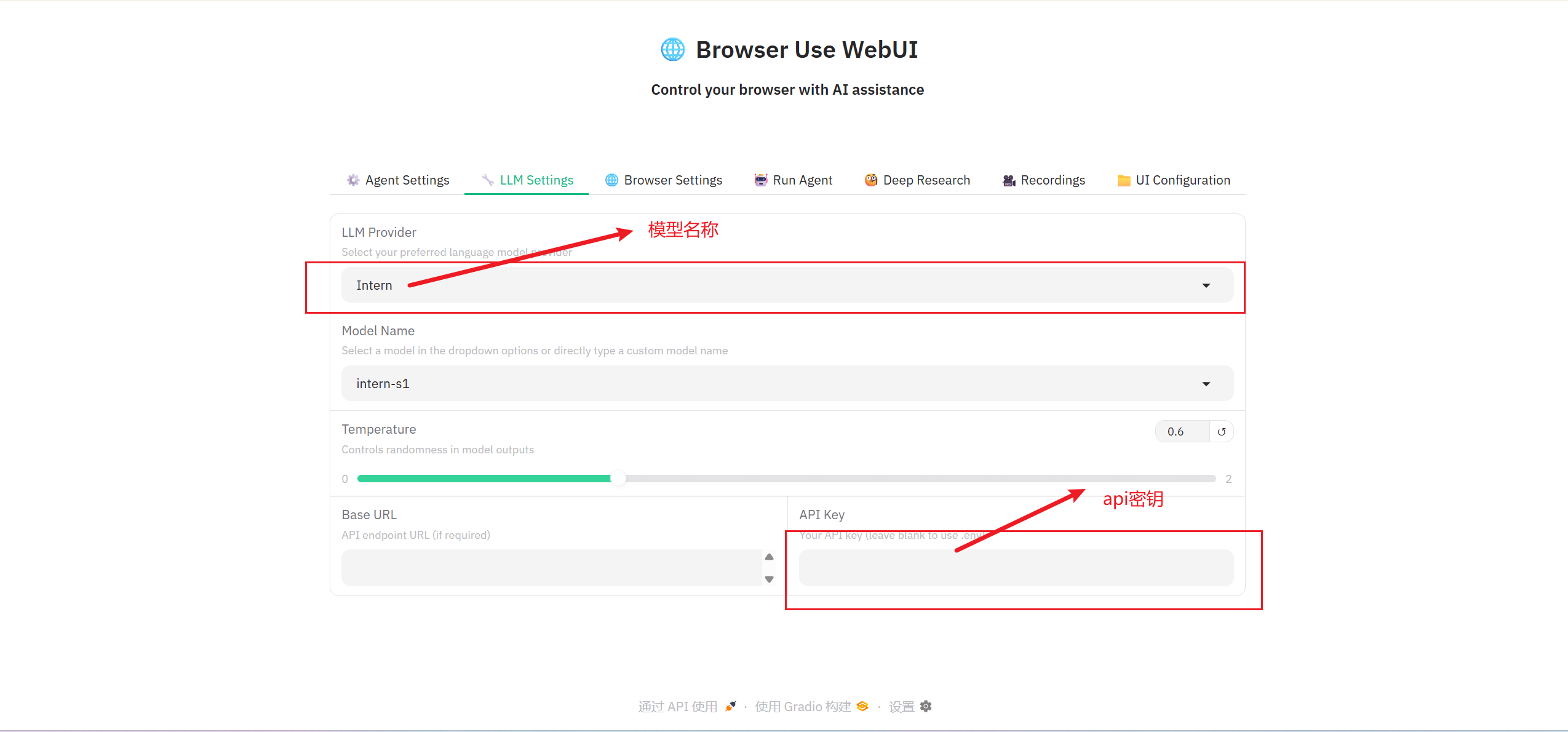
在 LLM Settings 下选择 Intern
模型选择 intern-s1
API KEY 位置填入你的 API Token
API KEY 也可以直接写入 .env 文件中
去百度查一下今天西安的天气,给我结果
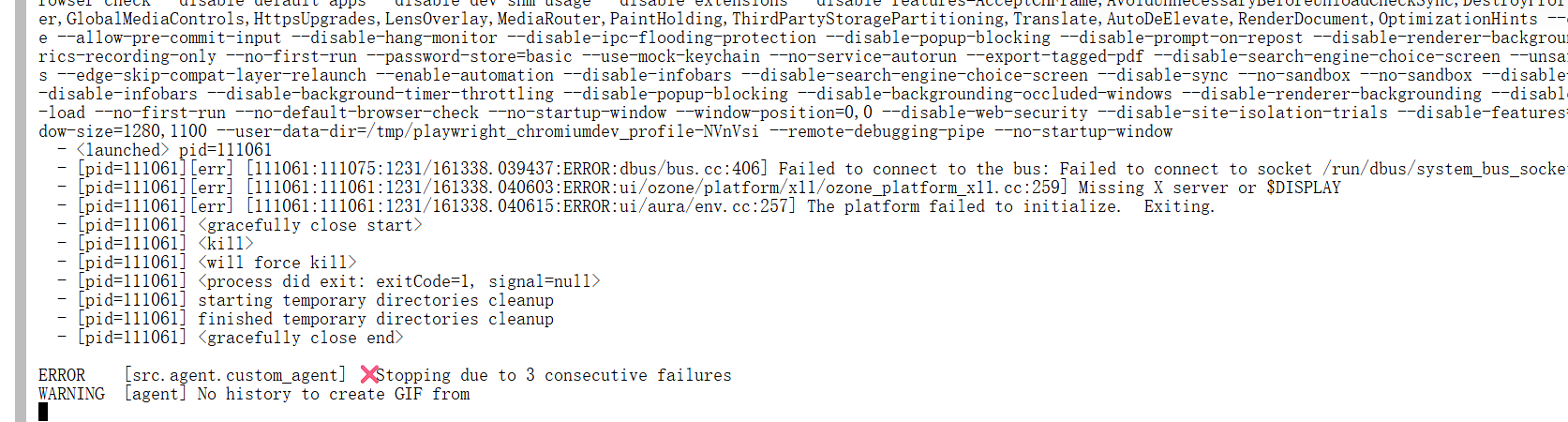
报错误,需要解决。
报错核心
Playwright 默认启动「有头(headed)」浏览器,而容器 / 远程服务器里没有 X11 服务,所以 Chromium 报错
Missing X server or $DISPLAY → 直接退出。
解决思路
要么让浏览器无头运行(最简单),要么装虚拟 X 帧缓冲(xvfb)。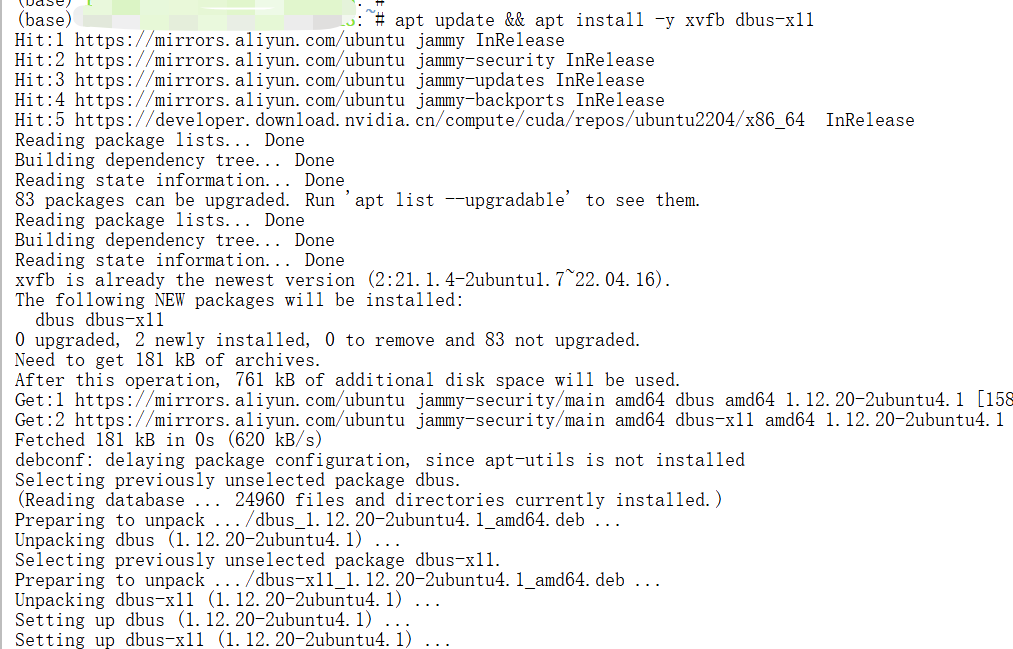
每次运行前套一层虚拟帧缓冲
apt update && apt install -y net-tools
xvfb-run -a --server-args="-screen 0 1280x720x24" python webui.py --ip 127.0.0.1 --port 7788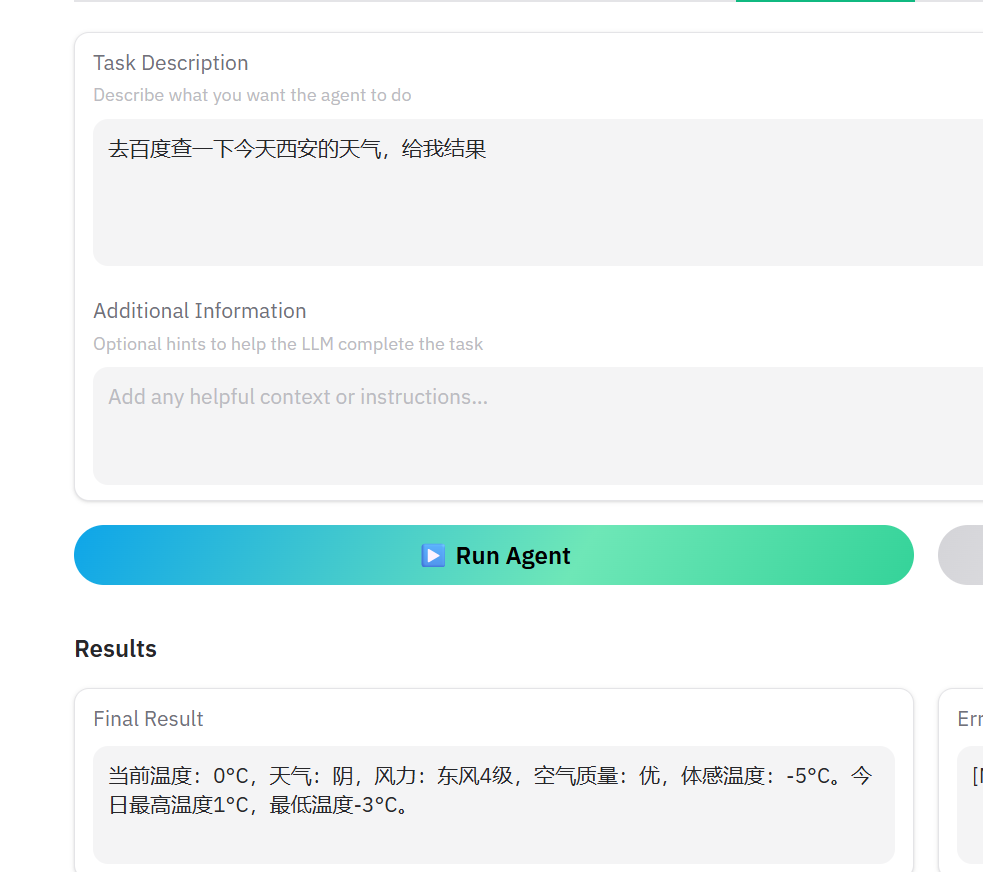
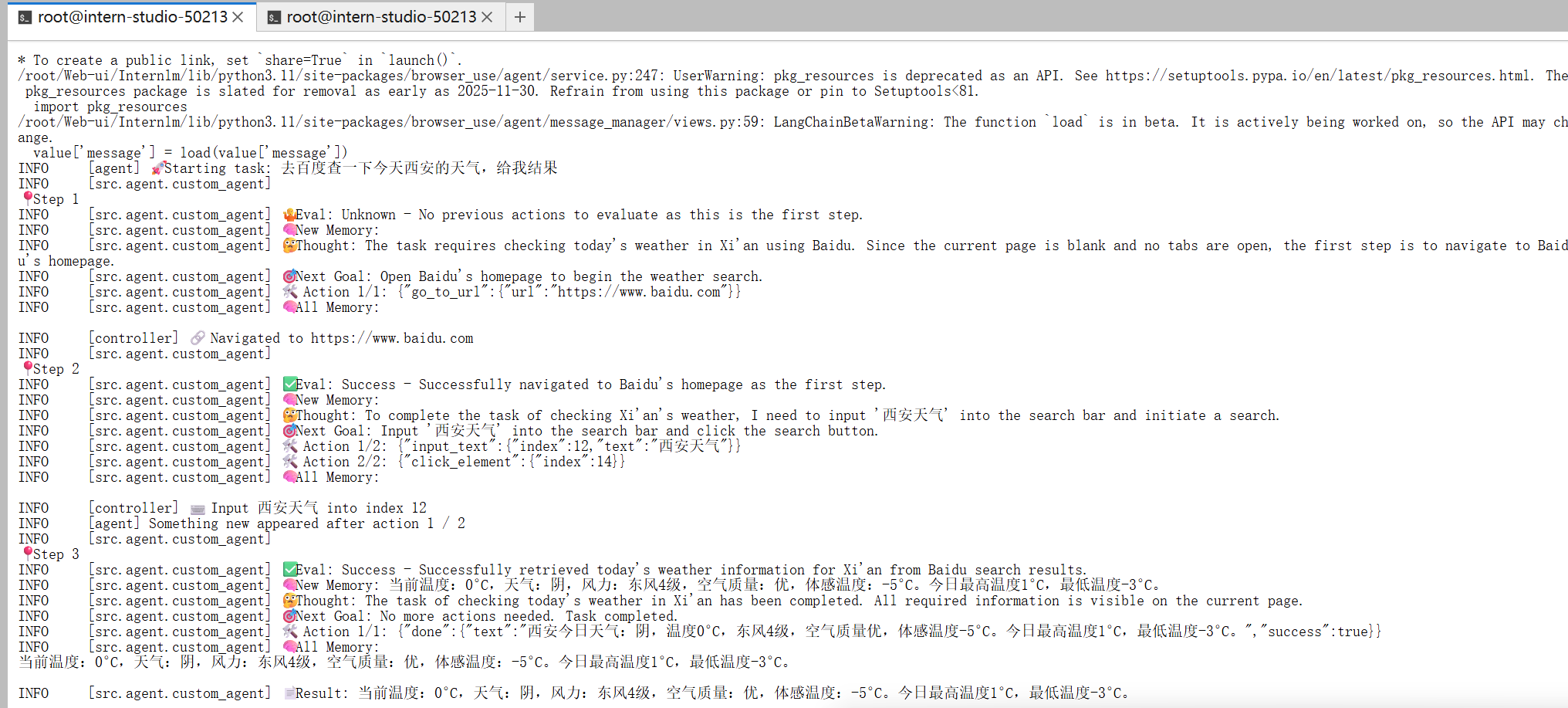
最后一张是这个后台进程的界面。
去小红书搜索东方明珠
在执行该任务时,GUI Agent 在登录界面卡住。我手动完成了扫码登录操作,但它在输入框中输入“东方明珠”后并未点击搜索按钮,因此我代为完成了点击操作。这也反映出此类技术仍存在诸多挑战,未来各位开发者可以在这一方向上还有广阔的探索与突破空间。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)