一文读懂通过定价多智能体强化学习的需求响应
深度强化学习电气工程复现文章,适合小白学习关键词:深度强化学习,神经网络,多智能体系统,需求响应编程语言:python平台主题:通过定价多智能体强化学习的需求响应内容简介:基于价格的需求响应是一种在间歇性可再生能源渗透率高的电力系统中获得所需灵活性的经济有效的方式。提出了无模型深度强化学习作为一种训练自主代理的方法,以使建筑物能够参与需求响应计划,并通过多代理设置中的价格设置来协调此类计划。首先,
深度强化学习电气工程复现文章,适合小白学习 关键词:深度强化学习,神经网络,多智能体系统,需求响应 编程语言:python平台 主题:通过定价多智能体强化学习的需求响应 内容简介: 基于价格的需求响应是一种在间歇性可再生能源渗透率高的电力系统中获得所需灵活性的经济有效的方式。 提出了无模型深度强化学习作为一种训练自主代理的方法,以使建筑物能够参与需求响应计划,并通过多代理设置中的价格设置来协调此类计划。 首先,我们展示了使用深度确定性政策梯度对带有电热泵的建筑物的价格响应控制。 然后训练协调代理通过调整价格来管理建筑群,以防止总负载超过可用容量,同时考虑非灵活的基本负载。 。 复现论文截图:
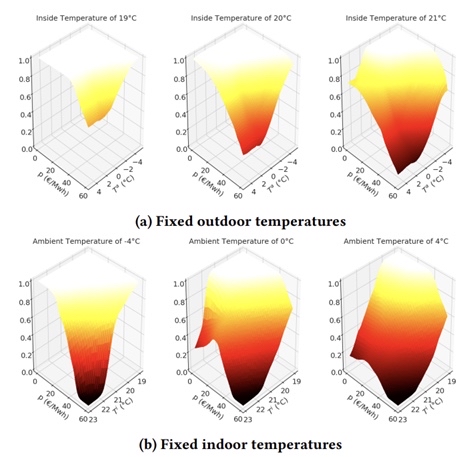
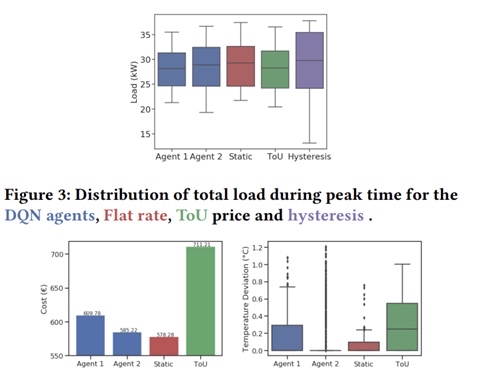
在如今间歇性可再生能源渗透率越来越高的电力系统中,如何获得所需的灵活性成为了关键问题。基于价格的需求响应(Price - based Demand Response)提供了一种经济有效的方式。今天咱们就来聊聊如何通过定价多智能体强化学习实现需求响应,这篇很适合小白上手哦。
深度强化学习在其中的角色
深度强化学习为训练自主代理提供了强大的工具,让建筑物能够积极参与需求响应计划。在多代理设置中,还能通过价格设置来协调这些计划。咱们这里使用Python平台来实现相关功能。
使用深度确定性政策梯度(DDPG)实现价格响应控制
先看看怎么用深度确定性政策梯度对带有电热泵的建筑物进行价格响应控制。DDPG是一种适用于连续动作空间的深度强化学习算法。
简单的DDPG代码框架示例
import numpy as np
import tensorflow as tf
# 定义策略网络(Actor)
class Actor(tf.keras.Model):
def __init__(self, state_dim, action_dim, action_bound):
super(Actor, self).__init__()
self.fc1 = tf.keras.layers.Dense(32, activation='relu')
self.fc2 = tf.keras.layers.Dense(32, activation='relu')
self.mu = tf.keras.layers.Dense(action_dim, activation='tanh')
self.action_bound = action_bound
def call(self, state):
x = self.fc1(state)
x = self.fc2(x)
action = self.mu(x) * self.action_bound
return action
# 定义价值网络(Critic)
class Critic(tf.keras.Model):
def __init__(self, state_dim, action_dim):
super(Critic, self).__init__()
self.fc1 = tf.keras.layers.Dense(32, activation='relu')
self.fc2 = tf.keras.layers.Dense(32, activation='relu')
self.q = tf.keras.layers.Dense(1)
def call(self, state, action):
x = self.fc1(state)
x = tf.concat([x, action], axis=-1)
x = self.fc2(x)
q_value = self.q(x)
return q_value
# 简单的训练循环示例
# 假设我们有环境env,状态state_dim,动作action_dim,动作边界action_bound
actor = Actor(state_dim, action_dim, action_bound)
critic = Critic(state_dim, action_dim)
actor_optimizer = tf.keras.optimizers.Adam(learning_rate=1e - 4)
critic_optimizer = tf.keras.optimizers.Adam(learning_rate=1e - 3)
for episode in range(1000):
state = env.reset()
done = False
while not done:
action = actor(tf.convert_to_tensor(state[np.newaxis, :], dtype=tf.float32)).numpy()[0]
next_state, reward, done, _ = env.step(action)
# 这里省略了经验回放等细节,实际应用中需要完善
with tf.GradientTape() as tape:
target_q = reward + (1 - done) * critic(tf.convert_to_tensor(next_state[np.newaxis, :], dtype=tf.float32),
actor(tf.convert_to_tensor(next_state[np.newaxis, :], dtype=tf.float32)))
current_q = critic(tf.convert_to_tensor(state[np.newaxis, :], dtype=tf.float32),
tf.convert_to_tensor(action[np.newaxis, :], dtype=tf.float32))
critic_loss = tf.reduce_mean(tf.square(target_q - current_q))
critic_grad = tape.gradient(critic_loss, critic.trainable_variables)
critic_optimizer.apply_gradients(zip(critic_grad, critic.trainable_variables))
with tf.GradientTape() as tape:
actor_loss = -tf.reduce_mean(critic(tf.convert_to_tensor(state[np.newaxis, :], dtype=tf.float32),
actor(tf.convert_to_tensor(state[np.newaxis, :], dtype=tf.float32))))
actor_grad = tape.gradient(actor_loss, actor.trainable_variables)
actor_optimizer.apply_gradients(zip(actor_grad, actor.trainable_variables))
state = next_state代码分析
- 策略网络(Actor):它接收状态作为输入,通过两层全连接层(
fc1和fc2)进行特征提取,最后通过mu层输出动作。由于动作通常有一定范围,这里使用tanh激活函数将输出值限制在 [-1, 1] 之间,再乘以动作边界action_bound得到实际的动作值。 - 价值网络(Critic):接收状态和动作作为输入,先对状态进行特征提取,然后将状态特征与动作拼接起来,再经过一层全连接层,最后通过
q层输出 Q 值,用于评估当前状态 - 动作对的价值。 - 训练循环:在每个episode中,智能体从环境中获取初始状态,根据当前策略网络选择动作并执行,得到新的状态、奖励和是否结束的信息。通过计算目标 Q 值和当前 Q 值的差异来更新价值网络,同时通过最大化当前状态下的 Q 值来更新策略网络。
训练协调代理管理建筑群
在管理建筑群时,协调代理需要通过调整价格来防止总负载超过可用容量,同时考虑非灵活的基本负载。这就涉及到多智能体系统的知识啦。
多智能体相关代码思路示例
class BuildingAgent:
def __init__(self):
# 初始化每个建筑物代理的相关参数,例如其电热泵的参数等
self.params = {...}
def take_action(self, price):
# 根据当前价格采取动作,例如调整电热泵的功率
action = self._calculate_action(price)
return action
class CoordinatorAgent:
def __init__(self, building_agents, capacity):
self.building_agents = building_agents
self.capacity = capacity
def adjust_price(self, total_load):
# 根据总负载调整价格
if total_load > self.capacity:
new_price = self._increase_price()
else:
new_price = self._decrease_price()
return new_price
# 模拟多智能体交互
building_agents = [BuildingAgent() for _ in range(10)]
coordinator = CoordinatorAgent(building_agents, capacity=100)
for time_step in range(100):
price = coordinator.adjust_price(total_load)
total_load = 0
for agent in building_agents:
action = agent.take_action(price)
# 根据动作计算该建筑物的负载并累加到总负载中
load = agent.calculate_load(action)
total_load += load代码分析
BuildingAgent类:代表每个建筑物代理,它有自己的参数params,并根据接收到的价格takeaction,通过calculate_action方法计算具体动作。CoordinatorAgent类:管理所有建筑物代理,它需要知道总的可用容量capacity。adjust_price方法根据总负载与容量的比较来调整价格。- 多智能体交互模拟:创建多个
BuildingAgent实例,并将它们传递给CoordinatorAgent。在每个时间步,协调代理先调整价格,然后每个建筑物代理根据价格采取动作,并计算其负载,最后累加所有建筑物的负载得到总负载。
通过以上步骤,咱们就初步实现了通过定价多智能体强化学习的需求响应啦。小白们可以根据这个思路进一步深入研究和完善代码哦。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)