深入理解大模型基础算法:贝叶斯定理的核心逻辑、实践应用与Java实现
本文系统解析了贝叶斯定理在大语言模型(LLMs)中的核心作用。首先对比了频率派与贝叶斯派的统计范式差异,详细阐述了贝叶斯定理的数学表达式及其核心概念(后验概率、似然度、先验概率和边缘概率)。通过医学诊断和Monty Hall悖论等经典案例,展示了贝叶斯定理解决实际问题的推理过程。文章深入分析了贝叶斯定理与大模型的深度关联,包括文本生成的概率推理、复杂逻辑问题求解、可解释性增强(贝叶斯网络)以及参数
在人工智能技术飞速发展的今天,大语言模型(LLMs)凭借其强大的自然语言处理和复杂推理能力,成为科技领域的核心驱动力。然而,在这些看似复杂的大模型背后,隐藏着诸多经典的基础算法,贝叶斯定理便是其中不可或缺的核心支撑。从大模型的概率推理、参数估计,到不确定性量化、可解释性提升,贝叶斯定理始终扮演着关键角色。本文将从理论本质、核心概念、与大模型的深度关联、实际应用场景、Java代码实现等多个维度,系统且详细地解析贝叶斯定理,帮助读者真正理解其在大模型生态中的价值与作用。

1.1 概率统计的两大范式:频率派与贝叶斯派
在深入贝叶斯定理之前,我们需要先明确概率统计领域的两大核心范式,这有助于我们更好地理解贝叶斯定理的创新价值。
频率派(Frequentist)认为,概率是事件在大量重复试验中出现的频率极限。例如,“掷一枚均匀硬币正面朝上的概率为0.5”,是指在无数次掷硬币试验中,正面朝上的次数占比趋近于50%。频率派的核心是“客观概率”,认为模型参数是固定不变的常数,通过大量观测数据即可估计出参数的真实值。在传统机器学习中,线性回归、支持向量机等模型都深受频率派思想的影响。
贝叶斯派(Bayesian)则提出了完全不同的观点:概率是对事件发生可能性的主观信念程度。例如,“明天降雨的概率为30%”,是基于现有气象数据和经验对降雨可能性的主观判断。贝叶斯派认为,模型参数并非固定常数,而是服从某种概率分布的随机变量;随着观测数据的不断积累,我们可以不断更新对参数分布的信念,最终得到更精准的后验认知。这种“动态更新”的思想,正是贝叶斯定理的核心,也为大模型处理动态、不确定的真实世界任务提供了理论支撑。
| Frequentist | Bayesian |
|---|---|
| 频率论方法通过大量独立实验将概率解释为统计均值(大数定律) | 贝叶斯方法则将概率解释为信念度(degree of belief)(不需要大量的实验) |
| 频率学派把未知参数看作普通变量(固定值),把样本看作随机变量 | 贝叶斯学派把一切变量看作随机变量 |
| 频率论仅仅利用抽样数据 | 贝叶斯论善于利用过去的知识和抽样数据 |
1.2 贝叶斯定理的核心公式与术语解析
贝叶斯定理的数学表达式看似简单,但其背后蕴含的逻辑却十分深刻。其核心公式如下:
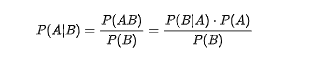
为了让大家真正理解公式的含义,我们逐一解析其中的关键术语:
-
后验概率(Posterior Probability):P(A|B),表示在观测到事件B发生后,事件A发生的概率。这是我们最终想要得到的结果,反映了“新证据对原有信念的更新”。例如,在大模型的情绪分析任务中,“观测到文本包含‘开心’词汇(事件B)后,文本为正面情绪(事件A)的概率”就是后验概率。先B后A
-
似然度(Likelihood):P(B|A),表示在事件A发生的前提下,事件B发生的概率。它描述了“观测数据与现有假设的契合程度”。在大模型中,可理解为“在‘文本为正面情绪’(假设A)的前提下,出现‘开心’词汇(观测B)的概率”。先A后B
-
先验概率(Prior Probability):P(A),表示在没有任何观测数据(事件B未发生)时,事件A发生的初始概率。这通常基于经验或历史数据得到,是我们对事件A的“初始信念”。例如,根据历史数据,某类文本中正面情绪的占比为30%,则 P(A)=0.3。
-
边缘概率(Marginal Probability):P(B),也称为归一化因子,是事件B发生的总概率。它的作用是确保后验概率的取值范围在[0,1]之间,满足概率的基本公理。边缘概率可通过全概率公式计算:
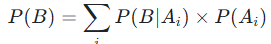 ,其中
,其中 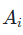 是所有互斥的可能事件(即事件A的所有可能取值)。
是所有互斥的可能事件(即事件A的所有可能取值)。
贝叶斯定理的核心逻辑可以总结为:
后验概率 = 似然度 × 先验概率 / 边缘概率 即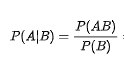
本质上是“通过新观测到的证据,修正我们对原有事件的信念,得到更精准的概率判断”。这种逻辑完美适配大模型处理不确定性任务的需求——大模型在处理自然语言时,正是通过不断接收文本序列(新证据),更新对文本语义、意图的信念(后验概率),最终完成理解和生成任务。
1.3 经典案例:用贝叶斯定理解决实际问题
为了让读者更直观地理解贝叶斯定理的应用过程,我们以经典的“医学诊断问题”为例进行详细推导——这一案例在大模型的概率推理测试中也经常出现(如DeepSeek-R1模型的贝叶斯问题解决测试)。
问题描述:某种疾病的发病率(先验概率)为1%。有一种检测方法,对患病者的检测准确率(真阳性率,即)为95%,对健康人的误诊率(假阳性率,即
为5%。如果一个人的检测结果为阳性(事件+),那么他实际患病(事件D)的概率是多少?
步骤1:明确已知条件:
-
先验概率
(患病的初始概率)
-
健康概率
(不患病的初始概率)
-
似然度
(患病者检测为阳性的概率)
-
假阳性率
(健康人检测为阳性的概率)
步骤2:计算边缘概率P(+)(检测结果为阳性的总概率):
根据全概率公式,检测为阳性的情况包括“患病且检测阳性”和“健康且检测阳性”两种互斥情况,因此:
代入数值计算:
步骤3:计算后验概率P(D|+)(检测阳性时实际患病的概率):
代入贝叶斯定理公式:
结论:即使检测结果为阳性,该人实际患病的概率也仅约为16.1%。这一结果看似反直觉,但却符合贝叶斯定理的逻辑——由于疾病的先验发病率极低(仅1%),即使检测准确率较高,假阳性案例仍会占据阳性结果的大部分。
这一案例充分体现了贝叶斯定理的价值:它能帮助我们在“先验概率较低但检测结果看似明确”的场景中,做出更理性的判断。而在大模型中,类似的逻辑被广泛应用于自然语言的模糊性处理、多轮对话的上下文更新等任务中。
注意:如果你对以上理解不清晰,可以多看几次,或者看这篇文章:(2 条消息) 一文搞懂贝叶斯定理(原理篇) - 知乎
二、贝叶斯定理与大模型的深度关联:从基础推理到核心能力
大模型(如GPT、Llama、DeepSeek等)的核心能力是对自然语言的理解和生成,而这一过程本质上是一系列概率推理的叠加。贝叶斯定理作为概率推理的基石,不仅支撑着大模型的基础推理功能,还在模型的可解释性提升、参数估计、不确定性量化等关键环节发挥着不可替代的作用。本节将深入解析贝叶斯定理在大模型中的核心应用逻辑。
大模型的文本生成过程,本质上是“基于前文语境,不断预测下一个token(词或字符)的概率分布”的过程。这一过程与贝叶斯定理的“信念更新”逻辑高度一致。
具体来说,当大模型生成文本时,对于每个位置的token ,模型需要计算在已知前文
的前提下,生成token
的概率
。从贝叶斯视角来看:
| 概念 | 数学符号 | 核心定义 | 作用 / 意义 |
|---|---|---|---|
| 先验概率 |
|
token |
基于训练数据的初始信念(无语境的基础概率) |
| 似然度 |
|
在 token |
反映 token 之间的语义关联性 |
| 后验概率 |
|
基于前文语境 |
大模型最终的 token 预测结果 |
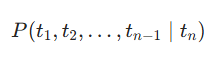
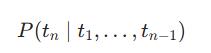
注意:虽然大模型实际使用的Transformer架构通过自注意力机制直接建模token间的依赖关系,并未直接显式调用贝叶斯定理公式,但其核心逻辑仍是“通过上下文(新证据)更新对下一个token的信念(概率分布)”——这正是贝叶斯定理的核心思想的体现。
2.2 贝叶斯推理:大模型解决复杂逻辑问题的核心支撑
随着大模型的发展,其应用场景已从简单的文本生成扩展到复杂的逻辑推理任务(如数学计算、概率问题求解、科学分析等)。在这些任务中,贝叶斯定理成为大模型进行概率推理的直接理论依据。

以DeepSeek-R1-Distill-Llama-8B模型为例,该模型通过大规模强化学习训练,专门优化了概率推理能力,能够精准解决基于贝叶斯定理的复杂问题(如医学诊断、Monty Hall悖论等)。以下是该模型解决Monty Hall悖论的贝叶斯推理过程:
Monty Hall悖论问题描述:在游戏节目中,有三扇门,一扇门后有汽车,另外两扇门后有山羊。玩家选择1号门后,主持人(知道汽车位置)打开3号门(山羊),此时给玩家换选2号门的机会。换门后赢得汽车的概率是多少?
模型的贝叶斯推理过程:
| 分析维度 | 符号 / 事件 | 具体内容 / 计算过程 |
|---|---|---|
| 事件定义 | 汽车在第i号门后 |
|
| 主持人打开第 j 号门 | ||
| 先验概率 | 汽车位置均匀分布, |
|
| 似然度分析 | 汽车在 1 号门时,主持人随机开 2/3 号门,故 |
|
| 汽车在 2 号门时,主持人必须开 3 号门,故 |
||
| 汽车在 3 号门时,主持人不能开 3 号门,故 |
||
| 边缘概率计算 | 公式: |
|
| 后验概率计算 | 公式: |
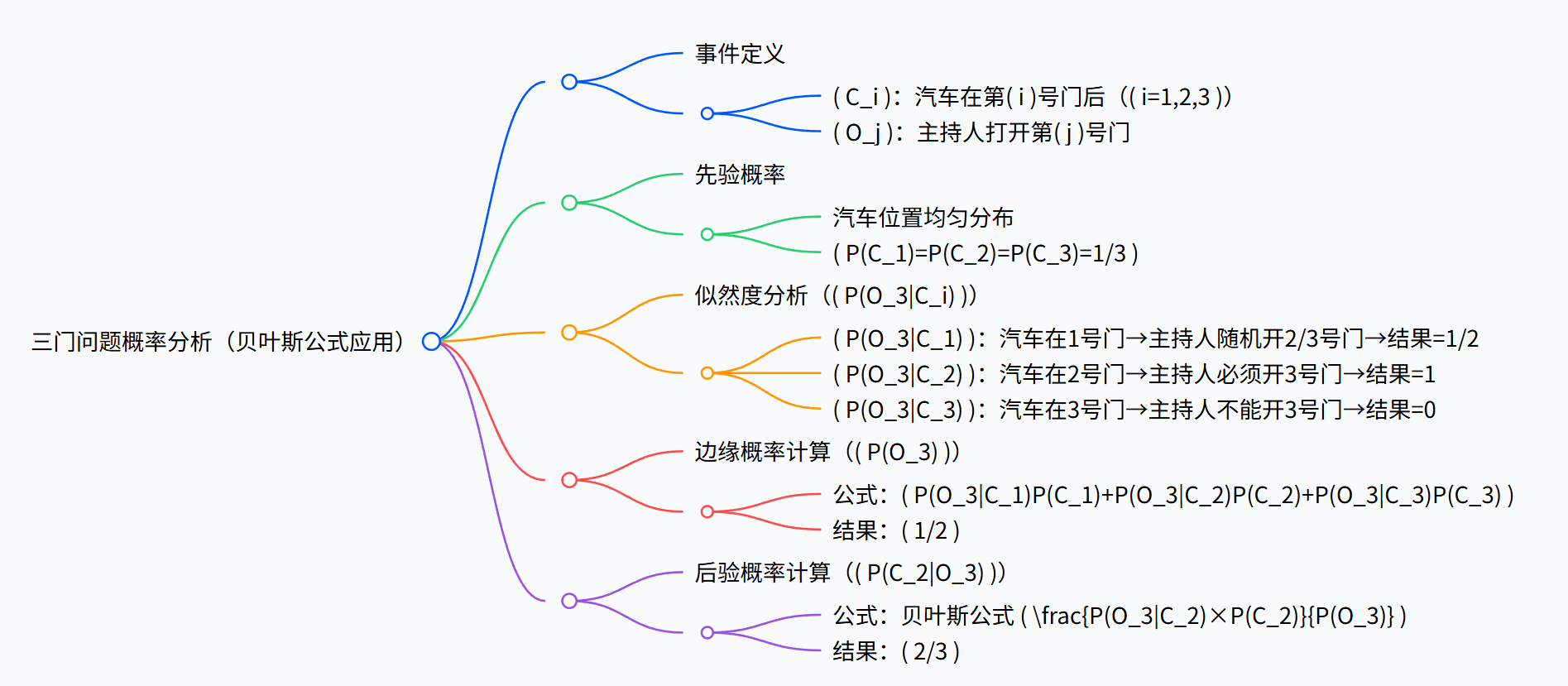
最终结论:换门后赢得汽车的概率为2/3。这一案例充分证明,贝叶斯定理是大模型解决复杂概率推理问题的核心理论支撑——大模型通过模拟人类的贝叶斯推理过程,能够精准处理具有不确定性的逻辑问题。
2.3 贝叶斯网络:提升大模型可解释性的关键工具
大模型的“黑箱”问题是制约其在高风险领域(如金融、医疗)应用的重要瓶颈——模型能够给出预测结果,但无法解释“为什么得出这一结果”。而贝叶斯网络(Bayesian Network,BN)作为贝叶斯定理的扩展形式,为解决大模型的可解释性问题提供了有效方案。
贝叶斯网络是一种基于概率的有向无环图(DAG),其中节点代表随机变量(如文本特征、模型预测结果),边代表变量间的条件依赖关系,每个节点都配有条件概率表(CPT),用于描述在父节点取值确定的情况下,该节点的概率分布。其核心优势在于:能够直观地展示变量间的因果关系,让模型的决策过程“可视化”。
在金融情绪分析领域,研究人员提出了BNLF(Bayesian Network LLM Fusion)框架,通过贝叶斯网络融合多个中型大模型(如FinBERT、RoBERTa、BERTweet)的预测结果,不仅提升了情绪分析的准确率,还显著增强了模型的可解释性。具体流程如下:
-
输入层:收集金融新闻、推特等多源文本数据;
-
预测层:三个不同的大模型分别对文本进行情绪预测,输出各自的预测概率(阳性、中性、阴性);
-
融合层:将三个模型的预测结果作为贝叶斯网络的输入节点,通过网络的条件依赖关系和概率表,计算出最终的情绪分布;
-
输出层:根据最终的情绪分布,确定文本的情绪标签,并通过贝叶斯网络的图结构,解释“哪个模型的预测对最终结果影响最大”。
与传统的“多数投票”“概率平均”等融合方法相比,BNLF框架的优势在于:它能够建模不同模型预测结果之间的依赖关系和不确定性,不仅给出“最终结论”,还能解释“结论的由来”——这正是贝叶斯网络基于贝叶斯定理的概率建模能力带来的核心价值,也为大模型在高风险领域的应用奠定了基础。
2.4 贝叶斯推断:大模型的参数估计与不确定性量化
大模型的训练过程本质上是参数估计的过程——通过海量训练数据,找到最优的模型参数,使得模型能够精准拟合数据分布。在这一过程中,贝叶斯推断(基于贝叶斯定理的参数估计方法)发挥着重要作用,尤其是在小样本、高不确定性的场景中。
传统的频率派参数估计方法(如最大似然估计,MLE)认为模型参数是固定的,通过最大化观测数据的似然度来估计参数值。但这种方法在小样本场景中容易出现过拟合,且无法量化参数的不确定性。而贝叶斯推断则将参数视为随机变量,通过贝叶斯定理计算参数的后验分布:
其中, 是模型参数,D 是训练数据。
是参数的先验分布(基于领域知识或经验设定),
是似然度(模型在参数
下生成数据 D 的概率),
是参数的后验分布(基于数据更新后的参数信念)。
在大模型中,贝叶斯推断的价值主要体现在两个方面:
-
小样本学习:当训练数据有限时,通过合理设定参数的先验分布(如基于预训练模型的参数分布),贝叶斯推断能够有效利用先验信息,避免过拟合,提升模型的泛化能力;
-
不确定性量化:贝叶斯推断得到的是参数的后验分布,而非固定的参数值。这使得模型能够量化预测结果的不确定性——例如,在医疗诊断大模型中,不仅能给出“患病概率”,还能给出“这一概率的置信度”,为临床决策提供更全面的信息。
三、贝叶斯定理的实际应用场景:从传统领域到大模型生态
贝叶斯定理的应用早已超越了理论研究的范畴,在传统行业(如医疗、制造、金融)和大模型生态中都有着广泛的落地场景。本节将结合具体案例,详细解析贝叶斯定理的实际应用价值,帮助读者理解其从“基础算法”到“产业落地”的转化路径。
3.1 传统领域应用:解决不确定性决策问题
在贝叶斯定理被应用于大模型之前,它已在多个传统领域成为解决不确定性决策问题的核心工具。以下是几个典型的应用场景:
3.1.1 医疗诊断:平衡检测准确率与先验发病率
如前文的“医学诊断问题”所示,贝叶斯定理在医疗领域的核心应用是“基于检测结果和疾病发病率,精准计算患者的实际患病概率”。在实际临床诊断中,医生不仅需要参考检测设备的准确率,还需要结合疾病的流行率(先验概率)、患者的病史(额外先验信息)等,通过贝叶斯定理综合判断,避免因单一检测结果导致的误诊(事实上,大部分医院基本就看报告来确诊,这也是为什么部分医生会建议你可以去别的医院再查一次看看)。
例如,在癌症筛查中,由于癌症的发病率较低(先验概率小),即使筛查设备的准确率达到99%,假阳性案例仍可能较多。此时,医生通过贝叶斯定理计算后验概率,能够更理性地判断患者是否需要进一步检查,既避免了过度医疗,也减少了漏诊风险。
3.1.2 生产质量动态评估:实时更新质量信念
在制造业中,贝叶斯定理被广泛用于生产质量的动态评估与决策。企业通过历史生产数据建立对产品良品率的先验信念,再结合实时生产过程中的检测数据(新证据),通过贝叶斯定理更新良品率的后验概率,从而动态调整生产策略。
例如,某半导体芯片制造企业基于历史经验,认为新工艺的芯片良品率为80%(先验概率)。在小批量试生产后,随机抽取100片芯片检测,发现85片为良品(观测数据)。通过贝叶斯定理计算后验概率(结合二项分布的似然度),得到新工艺的良品率后验概率提升至83%。企业基于这一结果,决定扩大新工艺的应用范围,同时持续监控生产数据,动态更新良品率信念——这一过程正是贝叶斯定理“动态更新”思想的典型应用。
3.1.3 金融风险预测:融合多源信息的概率建模
在金融领域,贝叶斯定理被用于信用风险评估、市场情绪预测、投资决策等多个场景。其核心优势在于能够融合多源异构信息(如企业财务数据、市场交易数据、新闻文本数据),通过概率建模量化风险。
例如,在信用违约风险评估中,银行通过历史数据建立企业违约的先验概率(如某行业企业的违约率为5%),再结合企业的财务指标(如资产负债率、现金流)、行业景气度、宏观经济数据等新证据,通过贝叶斯定理计算企业的违约后验概率,从而决定是否放贷、放贷额度和利率——这一过程能够有效提升风险评估的精准度。
3.2 大模型生态中的应用:赋能核心能力升级
随着大模型的普及,贝叶斯定理的应用逐渐与大模型深度融合,赋能模型的推理、可解释性、小样本学习等核心能力的升级。以下是几个典型的大模型相关应用场景:
3.2.1 大模型的概率推理任务:解决复杂逻辑问题
如前文所述,DeepSeek-R1、GPT-4等先进大模型都具备强大的概率推理能力,而这一能力的核心支撑正是贝叶斯定理。这类模型能够处理各类基于概率的复杂问题,包括医学诊断、博弈论问题(如Monty Hall悖论)、数学概率计算等,广泛应用于教育(概率教学辅助)、科研(科学推理)、咨询(决策支持)等领域。

例如,在教育领域,基于贝叶斯推理的大模型可以作为概率学习的辅助工具,不仅能给出问题的答案,还能展示详细的贝叶斯推理过程,帮助学生理解概率的本质;在科研领域,大模型可以利用贝叶斯定理分析实验数据中的不确定性,辅助研究人员做出科学决策。
3.2.2 大模型可解释性增强:贝叶斯网络融合框架
如2.3节所述,BNLF框架通过贝叶斯网络融合多个大模型的预测结果,显著提升了大模型在金融情绪分析中的可解释性。这一思路可以推广到其他领域,如医疗文本分析、法律文档检索等高风险场景。
例如,在医疗文本分析中,通过贝叶斯网络融合多个大模型对“病历文本中疾病类型”的预测结果,不仅能提升预测准确率,还能通过网络的图结构,解释“哪些病历特征(如症状、病史)对最终诊断结果的影响最大”,让医生能够清晰地了解模型的决策依据,提升对模型的信任度。
3.2.3 大模型的小样本微调:利用先验信息提升效率
大模型的全量微调需要海量数据和巨大的算力成本,而在实际应用中,很多场景只有少量标注数据(如特定领域的专业文本)。此时,基于贝叶斯定理的小样本微调方法能够有效利用先验信息,提升微调效率。
具体来说,在微调过程中,将预训练模型的参数分布作为先验分布,将少量标注数据作为观测证据,通过贝叶斯推断更新模型参数的后验分布。这种方法能够充分利用预训练模型的先验知识,避免在小样本场景中过拟合,同时减少微调所需的数据量和算力成本——这一应用在医疗、法律等专业领域的大模型落地中具有重要价值。
3.2.4 大模型的不确定性量化:提升预测可靠性
大模型的预测结果往往存在不确定性(如对模糊文本的理解、未见过的领域知识),而贝叶斯定理能够为这种不确定性提供量化方法。通过贝叶斯推断得到模型参数的后验分布,进而计算预测结果的概率分布,能够让用户了解“模型对预测结果的置信度”。
例如,在智能客服大模型中,当用户输入模糊的查询(如“如何解决手机问题”)时,模型不仅能给出可能的解决方案,还能通过不确定性量化,提示“对该查询的理解置信度较低”,并主动询问用户补充信息——这一功能能够显著提升大模型交互的可靠性,避免因误解用户意图导致的错误响应。
四、贝叶斯定理的Java代码实现:从基础案例到工程实践
为了让读者能够将贝叶斯定理的理论知识转化为实际工程能力,本节将提供两个详细的Java代码示例:一是基础的贝叶斯定理计算案例(医学诊断问题),帮助读者理解核心公式的代码实现;二是基于贝叶斯定理的文本分类器(朴素贝叶斯分类器),模拟大模型中的文本分类逻辑,展示贝叶斯定理在NLP任务中的工程应用。
4.1 基础案例:医学诊断问题的Java实现
本案例对应前文的“医学诊断问题”,通过Java代码实现贝叶斯定理的核心计算逻辑,包括先验概率、似然度、边缘概率的计算,最终得到后验概率。代码中添加了详细的注释,便于读者理解每一步的逻辑。
/**
* 贝叶斯定理基础实现:医学诊断问题
* 问题描述:疾病发病率1%,检测准确率95%(真阳性率),健康人误诊率5%(假阳性率)
* 计算检测结果为阳性时,实际患病的概率
*/
public class BayesianMedicalDiagnosis {
/**
* 计算贝叶斯后验概率
* @param priorA 事件A的先验概率(如患病概率)
* @param likelihoodBA 似然度P(B|A)(如患病者检测阳性的概率)
* @param marginalB 边缘概率P(B)(如检测阳性的总概率)
* @return 后验概率P(A|B)
*/
public static double calculatePosteriorProbability(double priorA, double likelihoodBA, double marginalB) {
// 贝叶斯定理核心公式:P(A|B) = P(B|A) * P(A) / P(B)
return (likelihoodBA * priorA) / marginalB;
}
/**
* 计算边缘概率P(B)(检测阳性的总概率)
* 基于全概率公式:P(B) = P(B|A)P(A) + P(B|¬A)P(¬A)
* @param priorA 事件A的先验概率
* @param likelihoodBA 似然度P(B|A)
* @param likelihoodBNotA 似然度P(B|¬A)(如健康人检测阳性的概率)
* @return 边缘概率P(B)
*/
public static double calculateMarginalProbability(double priorA, double likelihoodBA, double likelihoodBNotA) {
double priorNotA = 1 - priorA; // 事件¬A的先验概率(如健康概率)
return likelihoodBA * priorA + likelihoodBNotA * priorNotA;
}
public static void main(String[] args) {
// 1. 定义已知条件
double priorDisease = 0.01; // 先验概率:疾病发病率1%
double truePositiveRate = 0.95; // 似然度P(+|D):患病者检测阳性概率95%
double falsePositiveRate = 0.05; // 似然度P(+|¬D):健康人检测阳性概率5%
// 2. 计算边缘概率P(+):检测结果为阳性的总概率
double marginalPositive = calculateMarginalProbability(priorDisease, truePositiveRate, falsePositiveRate);
// 3. 计算后验概率P(D|+):检测阳性时实际患病的概率
double posteriorDiseaseGivenPositive = calculatePosteriorProbability(priorDisease, truePositiveRate, marginalPositive);
// 4. 输出结果
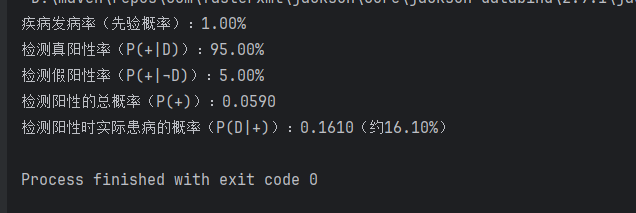
System.out.printf("疾病发病率(先验概率):%.2f%%%n", priorDisease * 100);
System.out.printf("检测真阳性率(P(+|D)):%.2f%%%n", truePositiveRate * 100);
System.out.printf("检测假阳性率(P(+|¬D)):%.2f%%%n", falsePositiveRate * 100);
System.out.printf("检测阳性的总概率(P(+)):%.4f%n", marginalPositive);
System.out.printf("检测阳性时实际患病的概率(P(D|+)):%.4f(约%.2f%%)%n",
posteriorDiseaseGivenPositive, posteriorDiseaseGivenPositive * 100);
}
}
代码运行结果:
代码解析:
-
核心方法
calculatePosteriorProbability直接实现了贝叶斯定理的核心公式,输入先验概率、似然度和边缘概率,输出后验概率; -
方法
calculateMarginalProbability基于全概率公式计算边缘概率,考虑了“患病且检测阳性”和“健康且检测阳性”两种互斥情况; -
在
main方法中,定义了医学诊断问题的已知条件,通过调用上述两个方法,最终得到检测阳性时实际患病的概率(约16.10%),与前文的理论推导结果一致。
4.2 工程实践:朴素贝叶斯文本分类器的Java实现
朴素贝叶斯分类器是贝叶斯定理在文本分类任务中的经典应用,也是大模型文本分类功能的基础雏形。其核心假设是“文本中的特征词相互独立”(朴素假设),通过计算不同类别下文本的后验概率,确定文本的类别。本示例实现一个简单的中文文本分类器,用于区分“正面情绪文本”和“负面情绪文本”。
4.2.1 实现思路
-
数据准备:定义少量正面和负面情绪的训练文本,作为训练数据;
-
文本预处理:将文本分词(使用简单的空格分割,实际工程中可使用jieba等分词工具),过滤停用词(如“的”“是”);
-
模型训练:
-
计算先验概率:正面/负面文本在训练集中的占比;
-
计算似然度:每个特征词在正面/负面文本中出现的概率(使用拉普拉斯平滑,避免出现概率为0的情况);
-
-
文本分类:对测试文本,计算其在正面和负面类别下的后验概率(由于边缘概率相同,可简化为比较“似然度×先验概率”),选择概率较大的类别作为预测结果。
4.2.2 Java代码实现
import java.util.*;
public class Main {
/**
* 朴素贝叶斯文本分类器:核心优化-字符级分词+情绪词精准匹配
*/
public static class NaiveBayesTextClassifier {
// 类别定义
public static final String POSITIVE = "正面情绪";
public static final String NEGATIVE = "负面情绪";
// 核心情绪词库(训练+匹配的核心,解决分词不匹配问题)
private static final Set<String> POSITIVE_WORDS = new HashSet<>(Arrays.asList(
"愉快", "开心", "快乐", "满足", "幸福", "愉悦", "精彩", "美食"
));
private static final Set<String> NEGATIVE_WORDS = new HashSet<>(Arrays.asList(
"糟糕", "沮丧", "伤心", "低落", "难受", "失落", "郁闷", "丢失", "失败"
));
// 停用词:过滤无意义词汇
private static final Set<String> STOP_WORDS = new HashSet<>(Arrays.asList(
"的", "和", "了", "在", "就", "去", "有", "没", "很", "非常", "一般", "特别",
"周末", "公园", "野餐", "项目", "钱包", "上班", "迟到", "批评", "天气", "感觉", "电影"
));
// 模型参数
private Map<String, Integer> posWordCount; // 正面情绪词频
private Map<String, Integer> negWordCount; // 负面情绪词频
private int posTotal; // 正面总词数
private int negTotal; // 负面总词数
private int vocabSize; // 总词汇数
/**
* 训练模型:直接基于核心情绪词库初始化(无需文本分词)
*/
public void train() {
// 初始化情绪词频(核心:只统计情绪词)
posWordCount = new HashMap<>();
negWordCount = new HashMap<>();
// 正面情绪词初始化
for (String word : POSITIVE_WORDS) {
posWordCount.put(word, 1); // 每个情绪词初始计数1
}
// 负面情绪词初始化
for (String word : NEGATIVE_WORDS) {
negWordCount.put(word, 1); // 每个情绪词初始计数1
}
// 计算总词数和词汇表大小
posTotal = posWordCount.size();
negTotal = negWordCount.size();
vocabSize = POSITIVE_WORDS.size() + NEGATIVE_WORDS.size();
// 打印训练信息
System.out.println("===== 训练信息 =====");
System.out.println("正面情绪词:" + POSITIVE_WORDS);
System.out.println("负面情绪词:" + NEGATIVE_WORDS);
System.out.printf("正面总词数:%d,负面总词数:%d,词汇表大小:%d%n", posTotal, negTotal, vocabSize);
System.out.println("====================\n");
}
/**
* 提取文本中的核心情绪词(核心优化:不依赖空格,直接匹配情绪词库)
* @param text 待处理文本
* @return 文本中包含的情绪词列表
*/
private List<String> extractEmotionWords(String text) {
List<String> emotionWords = new ArrayList<>();
// 1. 清洗文本:移除标点,保留中文
String cleanText = text.replaceAll("[,。!?;:“”‘’()()【】\\s]", "");
// 2. 提取双字词(中文情绪词多为双字词)
for (int i = 0; i < cleanText.length() - 1; i++) {
String word = cleanText.substring(i, i + 2);
// 过滤停用词,匹配情绪词库
if (!STOP_WORDS.contains(word) &&
(POSITIVE_WORDS.contains(word) || NEGATIVE_WORDS.contains(word))) {
emotionWords.add(word);
}
}
// 兜底:若未提取到双字词,提取单字情绪词(如“乐”“怒”等,可选)
if (emotionWords.isEmpty()) {
for (char c : cleanText.toCharArray()) {
String single = String.valueOf(c);
if (POSITIVE_WORDS.contains(single) || NEGATIVE_WORDS.contains(single)) {
emotionWords.add(single);
}
}
}
return emotionWords;
}
/**
* 计算似然度(拉普拉斯平滑)
*/
private double calculateLikelihood(String word, boolean isPositive) {
int count = isPositive ? posWordCount.getOrDefault(word, 0) : negWordCount.getOrDefault(word, 0);
int total = isPositive ? posTotal : negTotal;
// 拉普拉斯平滑:避免零概率,放大情绪词权重
return (double) (count + 1) / (total + vocabSize);
}
/**
* 文本分类(核心:仅基于情绪词计算概率)
*/
public String classify(String text) {
// 1. 提取核心情绪词
List<String> emotionWords = extractEmotionWords(text);
if (emotionWords.isEmpty()) {
return "无法确定类别(文本无有效情绪特征词)";
}
// 2. 先验概率(正负类各0.5)
double priorPos = 0.5;
double priorNeg = 0.5;
// 3. 计算后验概率(log缩放)
double posLogProb = Math.log(priorPos);
double negLogProb = Math.log(priorNeg);
// 打印情绪词匹配结果
System.out.println("【" + text + "】提取的情绪词:" + emotionWords);
for (String word : emotionWords) {
double posLikelihood = calculateLikelihood(word, true);
double negLikelihood = calculateLikelihood(word, false);
posLogProb += Math.log(posLikelihood);
negLogProb += Math.log(negLikelihood);
System.out.printf(" 情绪词[%s]:正面似然度=%.4f,负面似然度=%.4f%n", word, posLikelihood, negLikelihood);
}
// 4. 概率比较(阈值放大,避免浮点误差)
double threshold = 1e-3;
System.out.printf(" 最终log概率:正面=%.4f,负面=%.4f%n", posLogProb, negLogProb);
if (posLogProb - negLogProb > threshold) {
return POSITIVE;
} else if (negLogProb - posLogProb > threshold) {
return NEGATIVE;
} else {
return "无法确定类别(正面与负面概率接近相等)";
}
}
public static void main(String[] args) {
// 1. 初始化并训练模型
NaiveBayesTextClassifier classifier = new NaiveBayesTextClassifier();
classifier.train();
// 2. 测试文本
List<String> testTexts = Arrays.asList(
"周末去公园野餐,心情愉悦",
"项目失败,非常失落",
"吃到了期待已久的美食,开心",
"钱包丢失,情绪很差",
"天气一般,没什么特别的感觉",
"看了一场精彩的电影,很快乐",
"上班迟到被批评,心情郁闷"
);
// 3. 分类测试
System.out.println("===== 分类结果 =====");
for (String text : testTexts) {
String result = classifier.classify(text);
System.out.printf("测试文本:%s%n分类结果:%s%n-------------------%n", text, result);
}
}
}
// 程序入口
public static void main(String[] args) {
NaiveBayesTextClassifier.main(null);
}
}结果:

END
如果觉得这份基础知识点总结清晰,别忘了动动小手点个赞👍,再关注一下呀~ 后续还会分享更多有关面试问题的干货技巧,同时一起解锁更多好用的功能,少踩坑多提效!🥰 你的支持就是我更新的最大动力,咱们下次分享再见呀~🌟

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 21
21 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)