从 MRD 到代码骨架:大模型如何重构需求与系统设计效率
AI正在从代码生成前移至需求分析与系统设计阶段,通过多智能体协作构建"需求→研发"的智能化中间层。该方案采用三层架构:RAG增强业务语境、多Agent生成结构化PRD、系统分析与研发衔接,将模糊需求转化为可执行工程输入。核心价值在于把个人经验转化为可复用的工程流程,减少需求理解偏差和返工成本。当前挑战在于RAG的意图对齐和领域数据积累,未来方向是持续优化检索机制和增量学习。AI
一次偏工程实践的拆解: AI 不只是写代码,而是如何提前介入需求拆解、系统分析与研发准备阶段,真正减少返工与沟通成本。
一、为什么真正的研发效率问题,出现在“写代码之前”
在多数团队中,研发效率的瓶颈并不发生在编码阶段,而是集中在以下环节:
-
需求理解不一致,反复对齐
-
PRD 质量依赖个人经验,难以复用
-
系统分析文档产出慢、结构不稳定
-
产品、研发、测试之间存在信息损耗
随着大模型能力逐步成熟,AI 开始前移到需求分析与系统设计阶段,其核心价值不在“生成文字”,而在于:
把模糊的业务诉求,提前转化为结构化、可执行的工程输入。
二、整体目标:构建“需求 → 研发”的智能化中间层
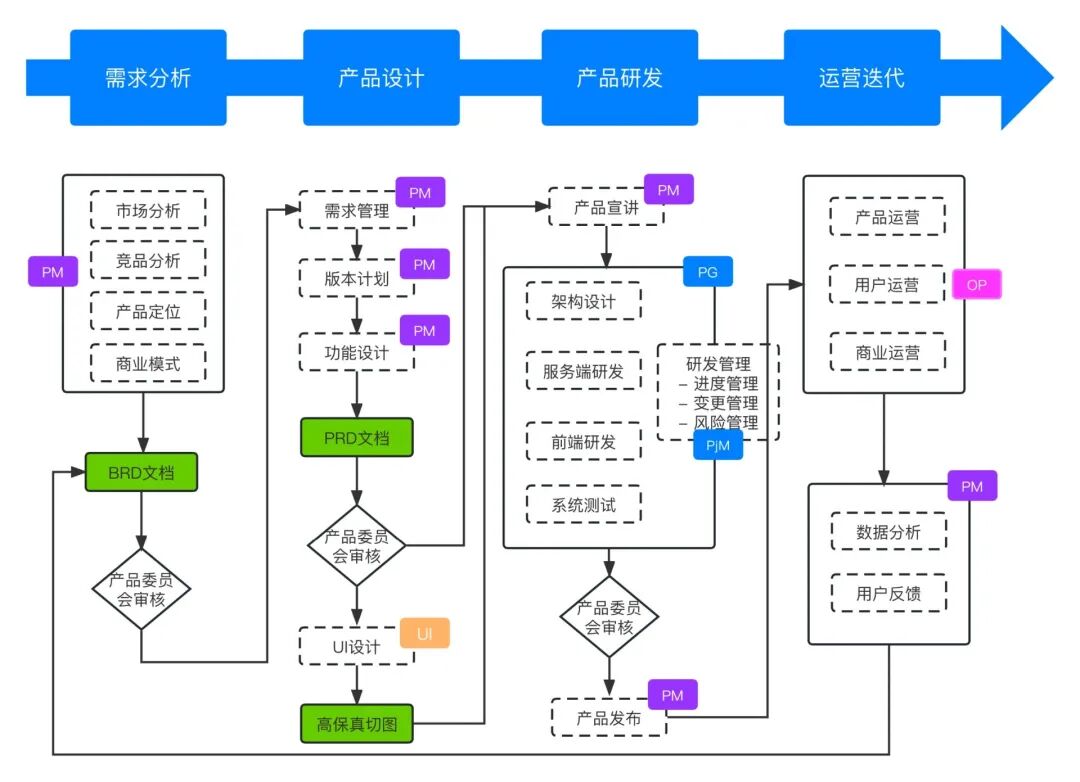
目标并不是让 AI 取代产品经理或架构师,而是让 AI 覆盖信息密度最高、最容易出错的中间环节:
业务诉求 → 需求结构化 → 系统分析 → 研发落地
通过多智能体协作,把原本高度依赖经验的工作,变成可重复、可校验的工程流程。
三、技术方案总览:多 Agent 驱动的需求工程流水线
3.1 总体流程框架
整体方案可以拆分为三层:
-
RAG 上下文增强层:补全业务语境
-
PRD 智能生成层:多 Agent 协作生成需求
-
系统分析与研发衔接层:输出结构化工程结果
这三层共同解决一个问题:如何在进入研发前,把“不确定性”压到最低。
四、从 MRD 到 PRD:需求不是“写出来的”,而是“拆出来的”
PRD 的智能生成并非简单文本输出,而是一套受控流程。
1. 输入阶段
-
自然语言描述业务诉求
-
上传 MRD、业务说明、流程图、截图等资料
2. 需求拆解阶段(多 Agent 协作)
-
模板约束 Agent:确保 PRD 结构一致
-
目标价值 Agent:明确需求目标与边界
-
需求价值 Agent:判断优先级与投入价值
-
流程建模 Agent:生成业务与功能流程图
3. 生成与优化阶段
-
自动补全功能点与约束条件
-
生成初步技术方案建议
-
支持多轮人工反馈与修订
4. 输出结果
-
可直接进入研发评审的标准化 PRD
-
结构清晰、信息完整、歧义显著减少
这一阶段最大的价值在于:把“脑内理解”提前外化成工程语言。
五、从 PRD 到系统分析,再到代码骨架生成
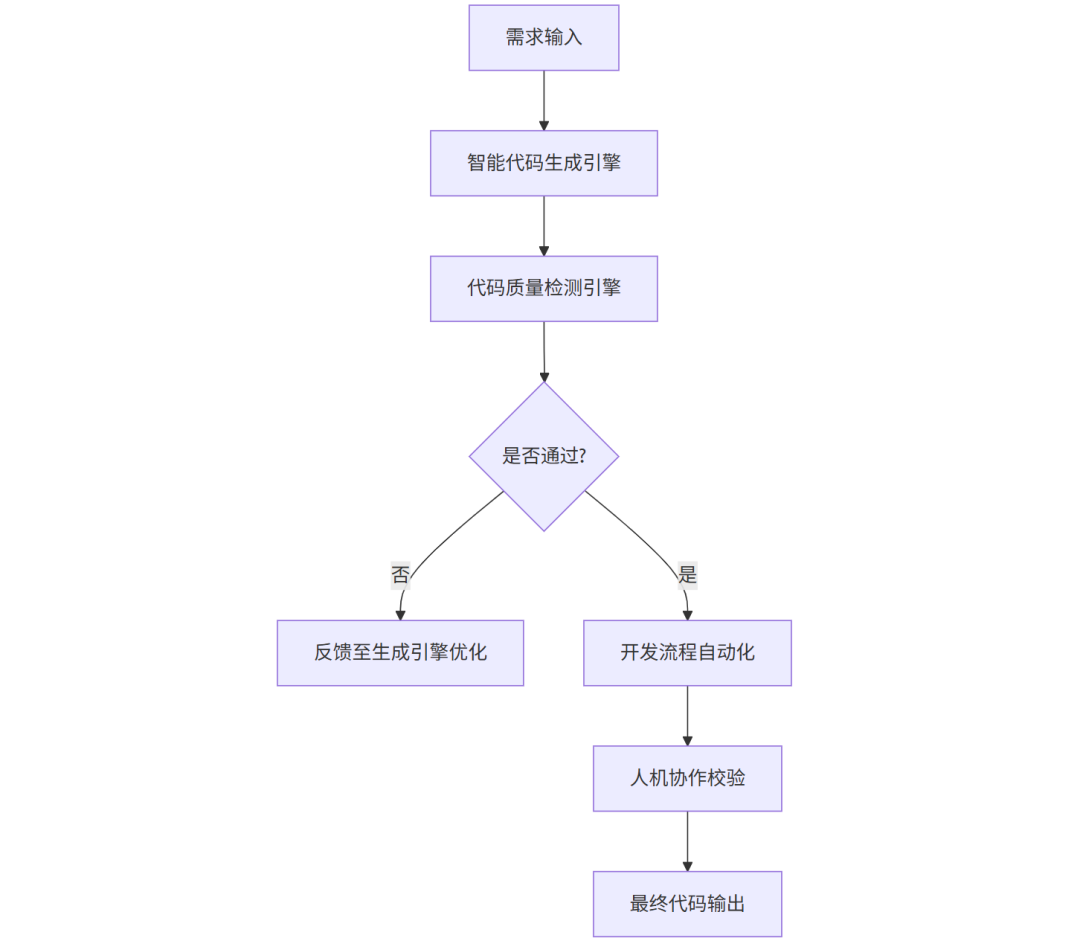
当 PRD 结构稳定后,AI 继续向下游推进。
1. PRD 输入与解析
-
解析自然语言需求
-
识别核心功能模块、数据对象、接口关系
2. 系统分析生成
-
拆解业务背景与技术约束
-
输出模块划分、数据流、接口设计思路
-
标注重点与潜在风险点
3. 文档与结构优化
-
自动生成系统架构图、数据流图
-
补全表结构、接口说明、交互逻辑
4. 研发准备输出
-
在 IDE 中生成基础代码骨架
-
覆盖常见的控制层、业务层、数据层结构
这里的关键不是“替代开发”,而是减少启动成本。
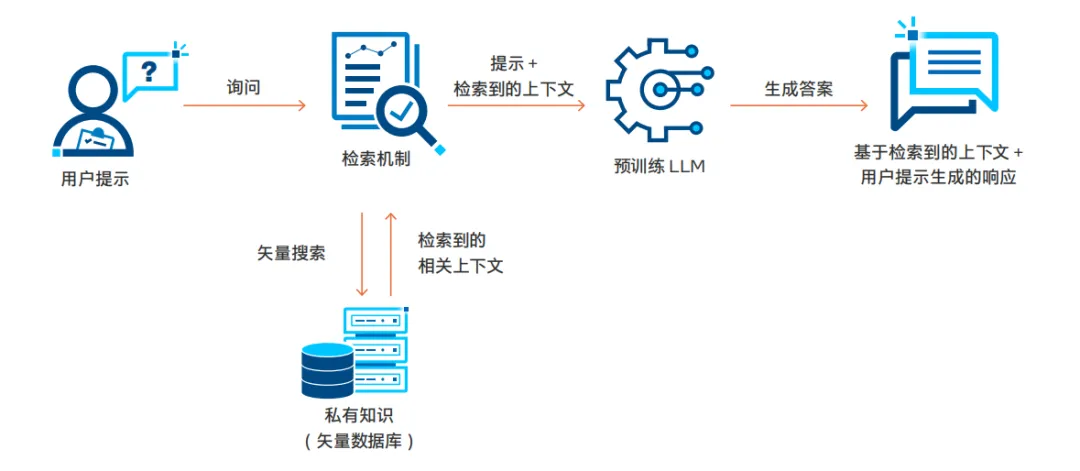
六、RAG:决定 AI 是否“真的懂业务”的关键能力

如果说 Agent 决定流程是否可控,那么 RAG 决定生成结果是否可信。
1. RAG 的核心目标
不是“查资料”,而是:
在生成之前,把模型放进你的业务语境中。
2. 检索与排序机制
-
稠密向量(如 BGE):语义相似度
-
稀疏向量(如 SPLADE):关键词召回
-
自研策略进行综合排序
最终输出与当前需求最相关的文档片段,作为上下文输入。
七、现实挑战与下一步演进方向
1. RAG 链路仍需更强的“意图对齐能力”
当前问题集中在:
-
召回正确,但不一定“正好有用”
改进方向包括:
-
先拆用户意图,再执行检索
-
对召回内容进行二次总结与提炼
-
结合历史对话上下文进行重组
2. 模型能力仍高度依赖真实业务数据
短期难点:
-
高质量领域数据不足
-
复杂业务难以一次覆盖
长期方向:
-
增量学习
-
格式约束数据采集
-
在真实业务中持续标注与迭代
AI 提效的真正意义,在“工程化经验”
当大模型被正确放进需求与系统设计流程中,它并不会制造混乱,而是帮助团队完成一件事:
把个人经验,转化为团队可复用的工程能力。
这,才是 AI 在研发体系中真正值得投入的地方。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 9
9 0
0- 0



 已为社区贡献156条内容
已为社区贡献156条内容

所有评论(0)