让 AI 更普惠:向量存储桶为海量 AI 记忆提供高性价比的 “数字基石”
传统 AI 应用,比如基于检索增强生成(RAG)的私域知识库,经常会面临一个两难选择:使用高性能的向量数据库,意味着需要为常驻内存的数据资源支付高昂费用,海量的历史数据成为 “成本黑洞”;若为了成本将数据存于廉价的对象存储,则无法实现高效的语义检索,AI 应用的价值大打折扣。
引言
在人工智能技术以前所未有的速度重塑各行各业的今天,一个核心矛盾日益凸显:一方面,大模型与 AI 应用展现出惊人的潜力,正从 “炫技” 走向 “赋能千行百业”;另一方面,其高昂的部署与运营成本,尤其是处理海量私有数据时产生的巨额存储与检索开销,成为了许多企业,特别是中小企业和开发者拥抱 AI 的现实门槛。让 AI 技术从少数科技巨头的 “奢侈品”,变为惠及更广泛开发者和企业的 “日用品”,是推动产业智能化的关键。
要理解这一挑战的根源,我们首先要从 AI 理解世界的 “语言”—— 向量说起。 在 AI 的世界里,无论是文本、图片、音频还是视频,最终都会被转化为一组高维度的数字,这就是向量。例如,一张人脸照片可以被编码成一个由数百个数字组成的向量,一段文字的含义也可以通过大模型被 “翻译” 成一个语义向量,这些向量被放置在同一个 “向量空间” 中,在这个空间里,向量之间的距离就代表了其背后数据含义的远近。
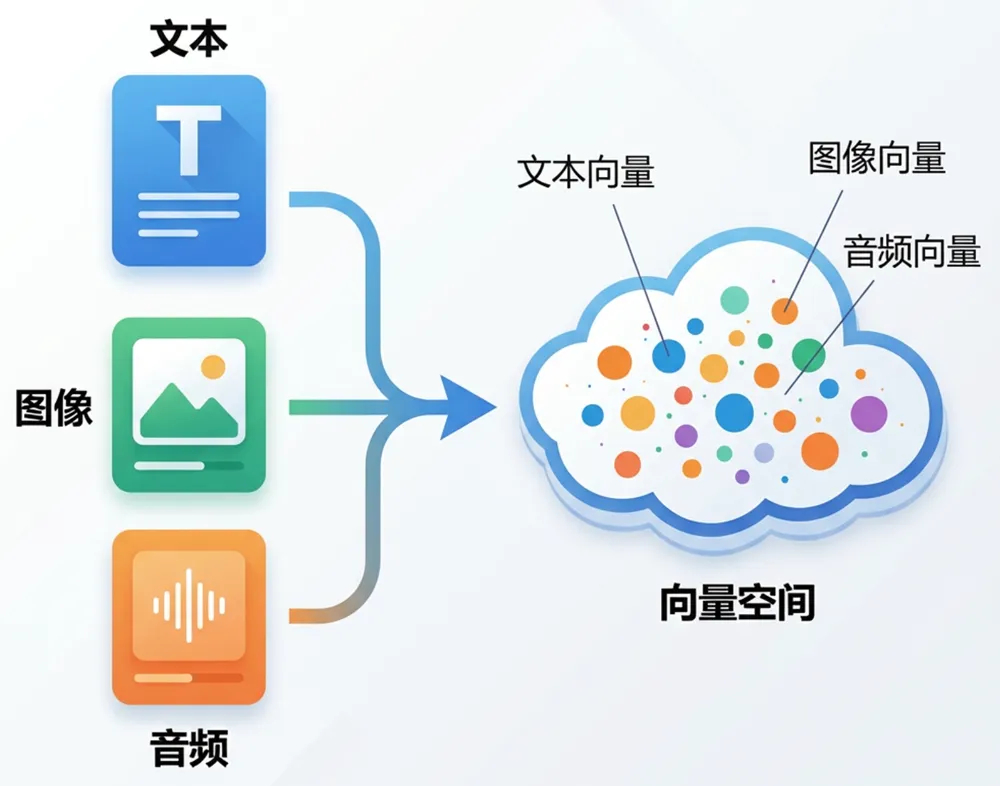
例如,“新能源车” 和 “电动车” 在字面上完全不同,但它们的向量会非常接近,这使得机器第一次具备了理解 “意思” 的能力,而不仅仅是进行字面上的匹配。基于这种能力,向量检索技术应运而生,它的核心任务就是:当给定一个查询向量(例如用户的问题),系统能快速从海量的向量数据集中,找到与之最相似的那些向量(即最近邻搜索)。这背后依赖高效的相似度计算(如余弦相似度、欧氏距离)和索引算法。为了应对亿级甚至更大规模数据的实时检索需求,近似最近邻(ANN)算法成为主流,它通过构建树(如 Annoy)、图(如 HNSW)或量化(如 PQ)等索引结构,在精度和速度之间取得平衡,实现超大规模向量检索的毫秒级响应。正是这些向量相关的技术,支撑起了我们熟悉的智能推荐、语义搜索、以图搜图等核心 AI 应用场景。
然而,当企业试图构建自己的私域知识库或 AI 应用时,一个严峻的现实问题摆在面前:海量向量数据的存储与长期管理成本高昂。传统的向量数据库或存算一体方案,通常需要将庞大的向量索引常驻于昂贵的内存或固态硬盘(SSD)中。这意味着,存储成本与计算资源强绑定,数据量越大,所需的内存和 SSD 成本就呈线性甚至指数级增长。对于访问频率较低的温、冷历史数据(如过去的客服记录、归档的文档、非实时的用户画像),这种 “高性能存储一切” 的模式造成了巨大的资源浪费和成本黑洞,使得许多企业望而却步。
腾讯云正式推出向量存储桶(COS Vector Bucket),正是为了解决这一难题。它并非又一个昂贵的、需要复杂运维的计算型向量数据库,而是一种革命性的、以存储为核心的 AI 原生基础设施。我们旨在通过极致简化的体验与颠覆性的成本结构,让每一家企业都能以极低的门槛,为 AI 应用构建起海量的 “长期记忆”,真正实现 AI 能力的普惠化落地。
从 “算力奢侈品” 到 “存储日用品”:重新定义 AI 数据基石的性价比
传统 AI 应用,比如基于检索增强生成(RAG)的私域知识库,经常会面临一个两难选择:使用高性能的向量数据库,意味着需要为常驻内存的数据资源支付高昂费用,海量的历史数据成为 “成本黑洞”;若为了成本将数据存于廉价的对象存储,则无法实现高效的语义检索,AI 应用的价值大打折扣。
腾讯云在向量存储与检索领域耕耘多年,如广受欢迎的智能检索 MetaInsight 产品,利用丰富的图片、视频、语音、文档等数据处理能力,提取原始文件的向量特征或元数据并索引到数据集中,从而提供文件的聚合统计查询、人脸图像检索、图片内容检索等能力。因此,我们深刻认识到向量存储与检索的痛点,开创性地提出了第三种路径:将向量数据的 “存储” 与 “计算” 解耦,推出 COS 向量存储桶产品。它深度集成于腾讯云对象存储(COS)这一久经考验、高可靠、低成本的存储服务中,并专门为向量数据的存储和检索进行了原生优化。
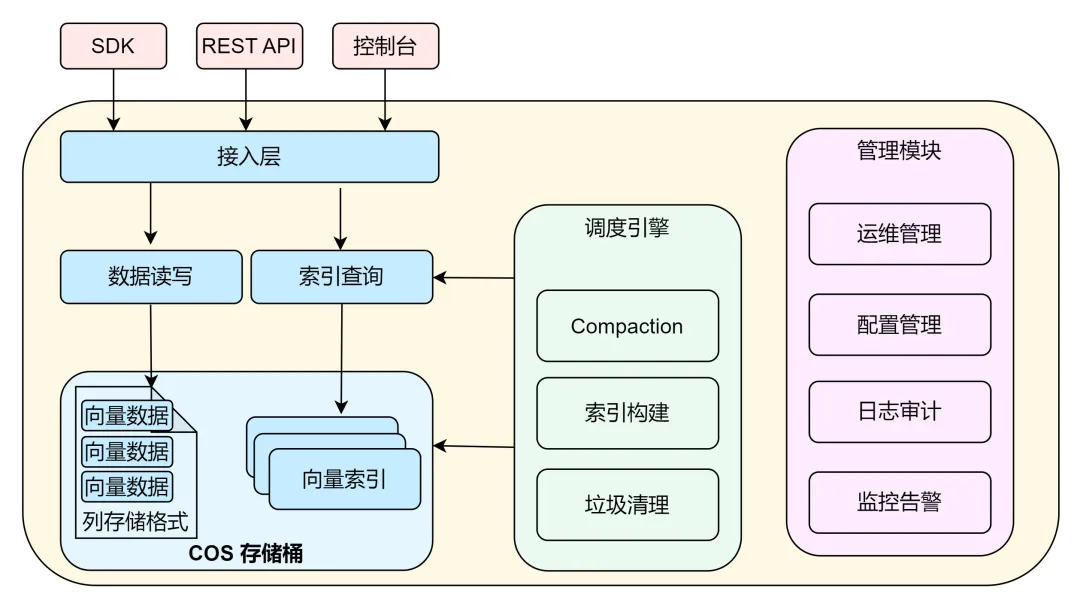
1、成本降低可达 90%:向量存储桶的核心计费锚定在海量向量数据长期存储和低频率检索上。对于访问频率较低的温、冷向量数据,其综合使用成本相比传统的向量数据库方案,可降低高达 90%。这意味着,企业可以毫无负担地将 TB 乃至 PB 级的非结构化数据转化为向量,构建起真正完整的、覆盖全生命周期的 AI 知识体系,而无需担忧成本失控。
2、开箱即用,零运维负担:作为一项全托管服务,用户无需关心底层基础设施的容量规划、副本配置、扩缩容与故障恢复。通过控制台、COS SDK 或简单的 API,几分钟内即可创建一个专属于 AI 的向量知识库,真正实现了 “所见即所得”。这极大地降低了企业,尤其是技术团队规模有限的企业的启动与运维门槛。
不止于存储:为 AI 应用量身打造的 “智能记忆体”
腾讯云向量存储桶不仅仅是一个廉价的仓库,它更是一个为 AI 时代数据特性而设计的 “智能记忆体”。
1、高效的原生向量处理能力:它内置了高效的向量索引与检索能力,支持百毫秒级响应时间的相似性查询。您可以将它直接作为大模型的外部知识库,或 AI Agent 的长期记忆存储。
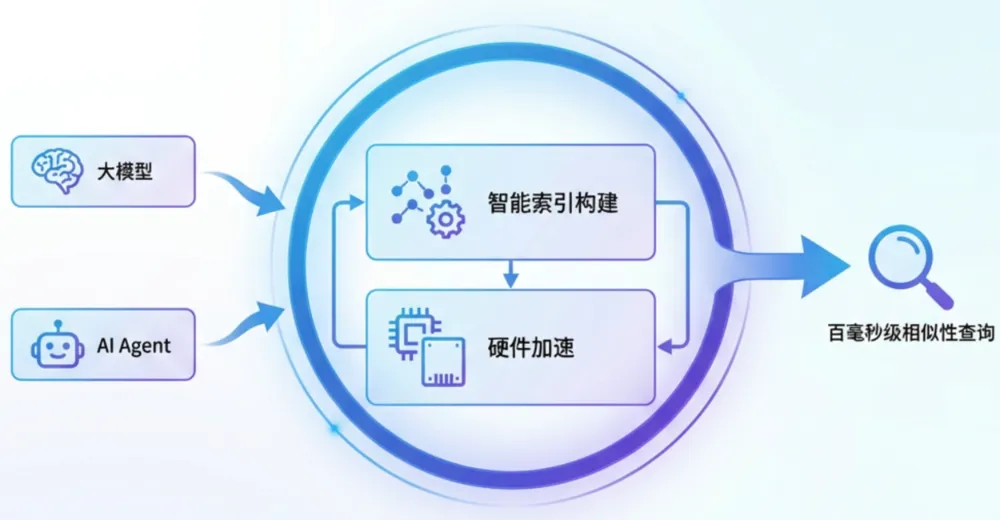
a. 智能向量索引构建:智能化的分析客户向量数据的特征,如向量维度,向量密度等特征,选择合适的向量索引类型,如 IVF/HNSW;选择最具性价比的量化算法,如 PQ/SQ/RQ 等,在为客户提供百毫秒级向量相似度检索性能的同时,不损失查询的精度,保障高召回率。
b. 硬件级性能加速:利用 CPU 硬件级 SIMD 指令加速向量索引构建与距离计算;结合内存 + SSD 多级缓存,对热点索引与数据进行就近加速,显著提升向量检索的吞吐与响应速度。
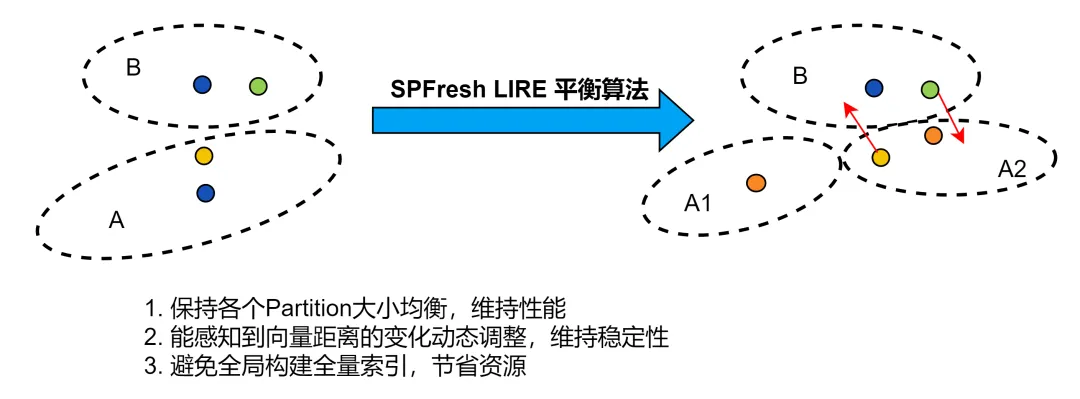
2、海量向量存储能力:向量存储桶按照索引来管理不同类型的向量数据,单个存储桶支持 100 个索引,单个索引支持最大 5000 万个向量。因此,单桶最大支持数十亿级别的向量存储与检索,完全满足各种 AI 应用的海量向量存储需求。腾讯云向量存储桶采用 SPFresh 增量向量索引更新的算法,保障向量存储大规模增长的同时,向量索引更新和查询性能及查询结果的准确度。
3、企业级可靠与安全:它继承了腾讯云对象存储高达 99.9999999999%(12 个 9)的数据持久性和 99.99% 的服务可用性。所有数据在存储和传输过程中均默认开启加密,并支持客户自管理密钥(CMK),满足金融、政务等对数据安全与合规有严苛要求的场景需求。
让普惠照进现实:赋能更广泛的 AI 创新场景
腾讯云向量存储桶的诞生,旨在让更多曾经被成本和技术复杂度阻挡在门外的创新想法得以实现。它提供直接访问向量数据的接口,不绑定任何平台,开发者可以轻松地将它与各类自建 Embedding 模型、第三方云平台 AI 服务、以及 DeepSeek 等生成式大语言模型结合,快速搭建从数据预处理、向量化、存储到智能问答的完整流水线,显著提升开发效率。
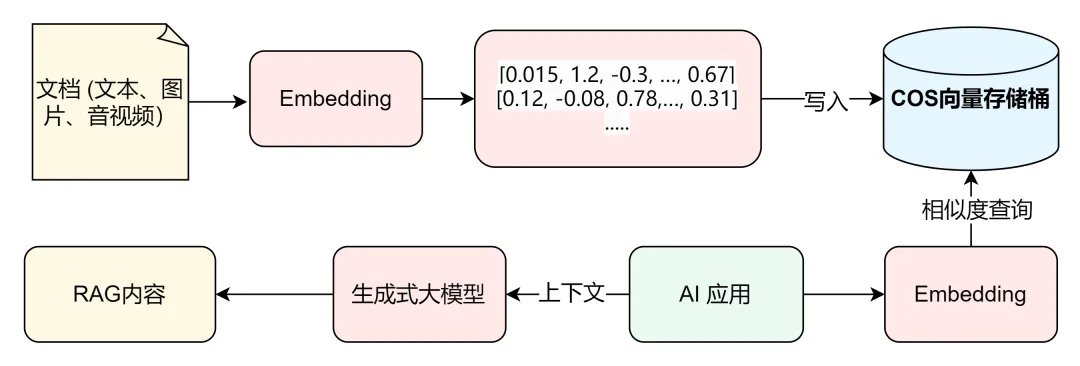
1、助力中小企业构建专属知识库:一个创业公司可以将其所有的产品手册、客服记录、市场报告转换为向量,存入向量存储桶,以极低的成本构建一个随时可供大模型调用的 “企业大脑”,提升客户服务与决策效率。
2、承载 AI Agent 的海量记忆:无论是个人数字助理,还是企业流程自动化机器人,向量存储桶能为它们提供几乎无限扩展的、低成本的记忆空间,让 AI 智能体真正具备持续学习和上下文理解的能力,成为更贴心的伙伴。
3、保存多媒体资产的 “语义指纹”:文化传媒、创意设计公司可以为图片、视频、音频库建立向量索引。即使多年后,也能通过自然语言描述,瞬间从海量归档资料中精准定位所需素材,释放数字资产的价值。
4、支持科研与长期数据分析:研究机构可以将长期的实验数据、文献资料向量化存储,为未来的数据关联分析与发现奠定基础,而无需在项目初期就投入巨额 IT 预算。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 17
17 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)