agentic设计模式 第1章:提示链(Prompt Chaining)
所谓“工程”,即是在运行时搭建稳定的数据获取与转换管道,并配套持续迭代的反馈回路,动态优化上下文质量,让模型始终“看得全、看得准、用得巧”。为强化输出质量,可在各阶段赋予模型明确角色:首步设定为“市场分析师”,次步切换为“行业趋势分析师”,终步交由“专业文档撰写员”执行,以此类推,实现角色-任务精准匹配。提示链的价值远不止于“把大问题拆小”。与其把难题一次性甩给模型,不如“分而治之”:把庞然大物拆
第一章:提示链(Prompt Chaining)技术解析
1.1 提示链模式简介
提示链(Pipeline模式)是大语言模型处理复杂任务的高效策略。其核心理念在于将复杂问题分解为一系列小而精的子任务,通过定制化提示逐步解决,形成环环相扣的处理流程。
这种模块化设计为LLM交互带来了显著优势:
- 每个步骤专注于特定子任务,使调试和优化更加精准
- 前序步骤的输出自然引导后续处理方向,形成清晰的依赖关系
- 支持与外部系统的无缝集成,可随时调用API或数据库扩展能力
提示链技术的核心价值体现在:
- 突破模型自身知识限制,构建更智能的系统
- 支持多步推理和动态决策,实现类人思维的工作流
- 为构建自适应智能体提供关键技术支撑
这种渐进式处理方法不仅提升了任务完成的可靠性,更使整个推理过程具有更好的可解释性。
单提示的局限性分析: 在处理复杂多维度任务时,若采用单一冗长提示要求语言模型一次性完成所有步骤,往往会导致效率低下和效果不佳。这种操作方式容易使模型在多重约束与指令间顾此失彼,主要表现为以下问题:
- 指令遗漏:部分关键要求被忽略
- 目标偏移:执行过程中逐渐偏离初始任务目标
- 误差累积:早期细微错误在后续环节中被逐步放大
- 信息不足:需要更多上下文时反而无法获取足够支持信息
- 幻觉加剧:认知负担加重导致虚构内容生成概率显著上升
比如,当用户要求"分析市场调研报告、总结核心发现、提取关键数据趋势并撰写邮件"时,模型可能能较好地完成总结部分,却无法准确抓取重要数据点,或者生成的邮件内容偏离主题,导致整个任务执行失败。
分步拆解提升任务可靠性: 采用提示链技术将复杂任务分解为专注有序的流程,每个步骤仅处理单一任务。这种方法既能减轻模型认知负担,又便于单独优化。以"调研报告→趋势提炼→邮件撰写"为例,该流程可分解为以下三步:
-
初步总结:"请阅读以下市场调研报告,提取3-5个核心发现,每条不超过50字:[text]"
-
趋势分析:"根据上述发现,识别三大新兴趋势,并为每条趋势提供1组量化数据或权威来源,以JSON格式输出:{'trends':[{'name':'趋势名称','evidence':'支撑数据'}]}"
-
邮件撰写:"以市场分析师身份,用中文撰写一封约150字的邮件,向营销团队概述这三大趋势及相关数据,并附上1条具体可行的营销建议"
这种拆解将流程颗粒度细化,使每一步都更聚焦、可控。通过“单步单任务”降低模型认知负荷,减少歧义,从而提升整体准确率与稳定性,类似计算流水线:函数依次完成特定操作后,将结果精准传递至下一环节。为强化输出质量,可在各阶段赋予模型明确角色:首步设定为“市场分析师”,次步切换为“行业趋势分析师”,终步交由“专业文档撰写员”执行,以此类推,实现角色-任务精准匹配。
结构化输出的核心价值: 提示链的顺畅运行依赖于每个环节输出的完整性、精确性和可解析性。当中间产物存在模糊或格式不规范时,后续处理极易因输入偏差而失败。必须要求模型返回结构化数据(如JSON、XML等),将模糊语义转化为机器可读的标准化字段,从而最大限度地降低链式流程的错误风险。
例如,趋势识别步骤格式化输出的 JSON 对象:
{
"trends": [
{
"trend_name": "AI-Powered Personalization",
"supporting_data": "73% of consumers favor brands that leverage personal data to enhance shopping relevance."
},
{
"trend_name": "Sustainable and Ethical Brands",
"supporting_data": "Products with ESG claims saw 28% sales growth over five years, outpacing the 20% growth of conventional products."
}
]
}
这种结构化格式不仅保证机器可读,还能被后续环节精准、零歧义地解析与复用,显著削弱自然语言理解带来的误差,是打造高可靠多步 LLM 系统的核心保障。
实际应用与案例
提示链作为构建智能体系统的核心模式,具有出色的通用性和适应性。其核心优势在于通过任务分解,将复杂问题转化为可执行、可验证的子步骤,从而大幅提升系统可靠性和可控性。以下是提示链的典型应用场景:
1. 信息处理工作流
适用于需要对原始信息进行多轮加工的场景,典型流程包括:文档摘要→关键实体提取→数据库查询→报告生成。对应的提示链设计如下:
- 提示1:从指定URL或文档中提取正文内容
- 提示2:对处理后的文本生成摘要
- 提示3:从摘要/原文中提取特定实体(如人名、日期、地点)
- 提示4:使用提取的实体查询内部知识库
- 提示5:整合摘要、实体和查询结果生成最终报告
该模式已成功应用于自动化内容分析、AI研究助手开发及复杂报告生成等多个领域。
2. 复杂查询处理方案:
针对需要多步推理或多源信息整合的复杂问题,提示链技术展现出显著优势。以"1929年股市崩盘原因及政府应对措施"为例,可分解为四个步骤:
- 问题解析:将原始问题拆解为"崩盘原因分析"和"政府应对措施"两个子问题模块
- 原因溯源:针对崩盘原因子问题,检索1929年经济危机的历史背景与相关经济学理论
- 政策溯源:针对政府应对子问题,检索当时及后续实施的经济政策与立法措施
- 信息整合:将两项检索结果进行时间线对齐,生成因果关系明确、数据支撑充分的完整回答
这种流水线处理方法将"多维复杂问题"转化为"可验证的模块化任务",有效提升AI系统的可解释性与回答可靠性,是多跳问答系统、智能研究助手等高级应用的标准配置模式。
以自动化研究智能体为例,其生成专题报告的工作流程如下:
- 首先进行大规模相关文献检索
- 随后对每篇文献进行并发式关键信息提取(此阶段适合并行处理)
- 信息提取完成后转为顺序处理流程:
- 数据整理
- 内容综合
- 文稿润色
提示链在此过程中发挥关键作用:整理后的数据作为"综合"提示的输入,综合文稿又成为"润色"提示的基础。由此可见,复杂操作通常采用并行处理完成独立数据收集,而通过提示链实现依赖性强的信息整合与精炼步骤。
3. 数据提取与转换:
将非结构化文本转化为结构化数据通常需要多轮迭代处理,每轮专注于解决特定类型的错误,逐步实现100%的准确性与完整性。
-
首轮提取(初步筛选):
从发票等文档中一次性提取关键字段(如姓名、地址、金额等),要求模型以JSON格式返回结果。 -
首轮处理:
使用规则或脚本校验字段的完整性和格式合法性,记录缺失或格式异常的条目。 -
次轮修复(定向修正):
仅将异常条目连同首轮JSON结果输入模型,要求其进行补充和修正,同时保留其他正确字段不变。 -
次轮处理:
再次校验修正结果。若仍有问题,可进行第三轮微调,直至所有字段符合要求。 -
最终输出:
返回经过多轮验证的结构化数据。
这种"提取→校验→定向修复"的循环处理方式特别适用于表单、发票、邮件等复杂版式文档。例如,OCR扫描的PDF表单常存在歪斜、水印或手写批注等问题,单次LLM处理容易出现遗漏或错位。采用"先粗提、再精修"的链式策略,可将总错误率从15%降至2%以下,且每轮只需处理增量问题,效率更高、成本更低。
具体实施流程:
- 首先利用大语言模型对文档图像进行OCR级文本提取
- 然后由模型对原始结果进行数据规范化处理(如将"一千零五十"转换为1050)
- 鉴于LLM在精确数学运算上的局限性,系统会调用外部计算工具:
- 模型判断需要执行的算式
- 将规范化数值输入计算工具
- 将工具返回的精确结果嵌入最终答案
这种"提取→清洗→外挂计算"的链式流程,能稳定输出单次LLM处理难以保证的精确数值结果。
4. 内容生成流水线:
长文、长图、长视频等"重内容"的生产本质上是一条可编排的流水线。通过将创意、结构、撰写和打磨拆分为独立节点,让模型逐段聚焦,不仅能显著降低"跑题"和"前后矛盾"的风险,还便于人工在任意环节介入调整。典型流程如下:
- 节点1 创意发散:基于受众画像与热点,生成5-10个差异化选题,并明确各选题的核心卖点。
- 节点2 智能筛选:通过轻量级评分模型或规则自动排序,也可由运营人员一键确认最终选题。
- 节点3 骨架成型:围绕选定主题,输出包含"标题+导语+二级标题+金句"的JSON结构框架,确保逻辑清晰。
- 节点4 分段扩写:根据框架逐点生成正文内容,每完成一段自动更新上下文窗口,保持行文连贯性。
- 节点5 一致性检查:调用独立审校模型,核查事实准确性、数据可靠性、品牌一致性及合规风险,并标注修改建议。
- 节点6 终稿优化:整合审校意见输出最终版本,同时生成140字以内的内容摘要和3组配图关键词,直接对接发布系统。
整个流程支持串行或局部并行执行,各节点间通过结构化JSON传递数据。人工只需在"选题筛选"和"最终审核"两个关键环节把关,即可将日产量从百篇提升至千篇级别,同时确保内容风格统一且风险可控。该模式已成功应用于营销文案、技术白皮书、电商详情页及短视频脚本的规模化生产。
5. 带状态的对话智能体:
采用提示链架构为对话连续性构建轻量高效的"记忆骨架"。每轮对话都被封装为独立提示,同时自动注入前轮提取的意图、实体及历史摘要,实现无缝的上下文传递。
- 首轮处理(提示1):解析用户初始输入,输出结构化结果
{intent, entities, core_utterance} - 状态维护:基于解析结果更新全局状态(数据库/缓存/JSON文件),并制定后续交互策略
- 后续轮次(提示2):将最新状态与当前输入智能融合,生成精准回复或信息补充请求;输出保持结构化格式,确保下游处理流畅
该架构天然支持长期、多轮的人机对话,各环节均可动态替换为外部API、知识检索或人工审核模块,在保持系统弹性的同时确保稳健性,是构建可扩展对话系统的核心方案。
6. 代码生成与优化:
代码生成通常采用分阶段执行策略,通过将复杂问题拆解为多个逻辑步骤来实现。
- 阶段 1(需求分析):理解功能需求,输出伪代码或设计框架
- 阶段 2(初步实现):基于框架编写初始代码版本
- 阶段 3(问题诊断):检测代码缺陷与优化空间(可结合静态分析工具或LLM二次验证)
- 阶段 4(迭代优化):根据诊断结果重构改进代码
- 阶段 5(最终验证):确认代码质量,补充文档及测试用例
在AI辅助开发场景中,提示链的核心优势在于:
- 将复杂编码任务模块化为可管理的子任务
- 降低单步操作的模型处理难度
- 支持在模型调用间插入确定性逻辑,实现:
- 中间数据流转
- 输出验证
- 条件分支控制
该方案通过结构化执行框架,将原本可能产生不可靠输出的复合请求,转化为可控的标准化流程。
7. 多模态数据解析与跨模态推理: 在处理包含图像、文本、表格等多种模态的复合数据时,建议采用分步式处理策略。以解析一张同时包含嵌入文字、视觉标注及关联表格的复杂图像为例,可按照以下流程操作:
- 步骤1(多模态输入处理):通过OCR技术提取图像中的全部文字信息,并进行基础语义分析
- 步骤2(跨模态关联):建立提取文字与图像视觉标注之间的精确对应关系
- 步骤3(多模态融合推理):综合前两步结果,深度解析表格内容并输出结构化数据
动手实践:代码示例
提示链的实现方式灵活多样,既可通过脚本中的顺序函数调用来完成,也能借助专门管理控制流、状态和组件集成的框架实现。诸如 LangChain、LangGraph、Crew AI 以及 Google Agent Development Kit(ADK)等框架,为构建和执行多步骤流程提供了结构化解决方案,尤其适用于复杂架构场景。
为便于演示,我们选用 LangChain 和 LangGraph 进行展示:这两个框架的核心 API 专为"链"与"图"的编排而设计。LangChain 提供了线性序列的基础抽象,而 LangGraph 进一步支持有状态计算和循环逻辑,能够实现更高级的智能体行为。
本示例将重点演示最基本的线性序列场景。下方代码实现了一个两步提示链的数据处理管道:
- 第一阶段解析非结构化文本并提取关键信息
- 第二阶段将提取结果转换为结构化数据格式
要复现此流程,请先运行以下安装命令获取所需库:
pip install langchain langchain-community langchain-openai langgraph
提示:langchain-openai 可替换为其他厂商的等效包;使用时请确保在运行环境中配置对应 LLM 厂商(如 OpenAI、Google Gemini 或 Anthropic)的 API 密钥等认证信息。
import os
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
# Security recommendation: Load environment variables from .env file
# from dotenv import load_dotenv
# load_dotenv()
# Ensure OPENAI_API_KEY is set in .env file
# Initialize Language Model (ChatOpenAI recommended)
llm = ChatOpenAI(temperature=0)
# Information Extraction Prompt
prompt_extract = ChatPromptTemplate.from_template(
"Extract the technical specifications from the following text:\n\n{text_input}"
)
# JSON Transformation Prompt
prompt_transform = ChatPromptTemplate.from_template(
"Transform these specifications into JSON format with 'cpu', 'memory', and 'storage' keys:\n\n{specifications}"
)
# Build Processing Chain using LCEL
extraction_chain = prompt_extract | llm | StrOutputParser() # Converts LLM output to string
# Full processing pipeline
full_chain = (
{"specifications": extraction_chain}
| prompt_transform
| llm
| StrOutputParser()
)
# Execute the chain
input_text = "The new laptop model features a 3.5 GHz octa-core processor, 16GB of RAM, and a 1TB NVMe SSD."
final_result = full_chain.invoke({"text_input": input_text})
print("\n--- Final JSON Output ---")
print(final_result)
这段示例代码展示了 LangChain 的典型应用场景:首先通过提示模板提取输入文本中的技术参数,然后使用第二个提示将其转换为结构化 JSON 格式。ChatOpenAI 处理模型调用,StrOutputParser 确保输出为整洁字符串;利用 LCEL 的管道操作符,仅需两行代码就能将"提取→转换"流程串联成完整链路。运行程序时,输入笔记本描述文本,即可在终端输出字段明确的 JSON 规格数据。
1.2 上下文工程与提示工程
上下文工程(见图1)是一种系统化方法论,专注于在模型生成首个token前,为其构建并传递完整、动态演进的信息环境。该理论认为,模型输出质量的核心决定因素不是规模或架构,而是上下文信息的广度、深度和动态适配能力。只有当"场景、记忆、工具、意图"四维数据有机融合时,才能充分释放大模型的推理与决策潜力。
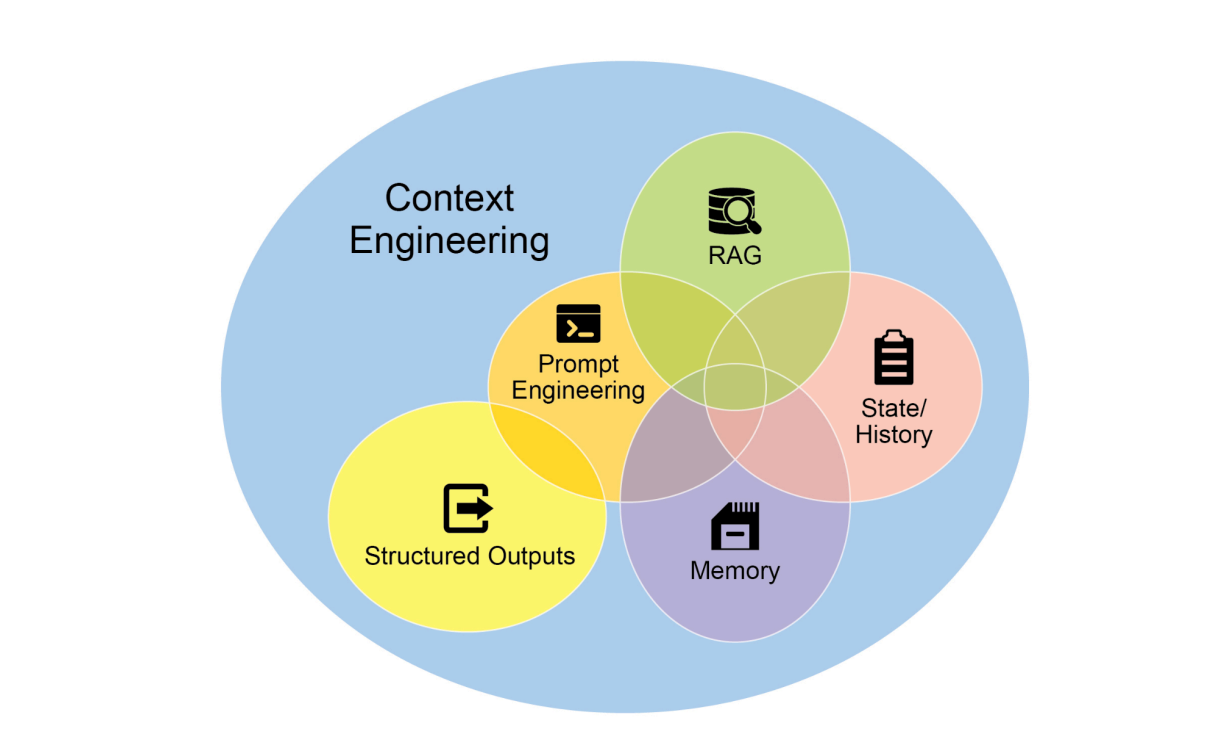
图1:上下文工程通过为AI构建丰富全面的信息环境,成为决定高级智能体性能表现的核心因素。
相较于传统提示工程仅关注优化用户即时查询的措辞,上下文工程实现了显著进化,其范围扩展至多层次信息体系:
- 系统提示:定义AI基础运行参数的核心指令(如"你是一名技术写作者,语气需正式且精确")
- 外部数据:
- 检索文档(AI主动从知识库获取辅助信息,如项目技术规格)
- 工具输出(通过API获取实时数据,如查询用户空闲时间) 这些显性数据与关键隐性数据(用户身份、交互历史、环境状态)深度融合,共同构成智能体的认知基础。其核心原则明确:再先进的模型,若仅获得有限或构建不当的运行环境视图,表现必然受限。
这种方法将任务重心从"简单应答"升级为"为智能体构建全景式运行图景"。经过上下文工程优化的智能体在响应前,会整合用户空闲时间(工具输出)、与收件人关系(隐性数据)及会议纪要(检索文档)等多维信息,最终生成高度个性化、可立即执行的输出。所谓"工程化",就是建立稳定的运行时数据获取与转换管道,配合持续迭代的反馈机制,动态优化上下文质量,确保模型始终"信息全面、判断精准、运用巧妙"。
为实现这一闭环,可采用自动化调优系统持续优化上下文。以Google Vertex AI提示优化器为例:上传样本输入、预期输出和评估指标后,系统会自动比对模型响应,迭代生成更精准的系统提示和模板,无需人工反复调试。该方案支持跨模型迁移,一键复用即可让不同LLM获得同等高质量的上下文,大幅降低复杂上下文工程的实施和维护门槛。
这种结构化方法是区分初级AI工具与成熟、上下文感知系统的关键。它将"上下文"置于核心地位,系统关注智能体"知道什么、何时知道、如何利用"。通过持续整合用户意图、历史交互和实时环境,模型得以建立全景认知。最终,上下文工程成为将基础聊天机器人升级为高度智能、情境敏感系统的核心方法论。
速览
What: 将复杂任务强行压缩为单一提示,如同让大模型"一口吞象"——认知负荷急剧增加,导致输出质量骤降:指令遗漏、上下文偏离、幻觉增多、错误不断累积,最终生成看似完整实则零散的不可靠结果。
Why: 提示链采用"分而治之"的模块化思维,将庞大任务拆解为多个高内聚、低耦合的子任务。每个步骤专注单一目标,输出作为下一环节输入,形成可验证、可回滚、可插拔的链式流程。这种设计带来三大优势:① 单点调试更便捷;② 可在任意节点接入外部工具或结构化数据;③ 天然支持多步推理与状态维护,是构建具备自主规划和执行能力的高级智能体的基础。
经验法则: 当任务符合以下任一条件时,应立即采用提示链:① 单一提示包含超过3重约束或需要顺序推理;② 流程中存在独立可复用的处理阶段;③ 必须调用外部API或工具;④ 需要跨轮次的记忆与状态追踪。
可视化说明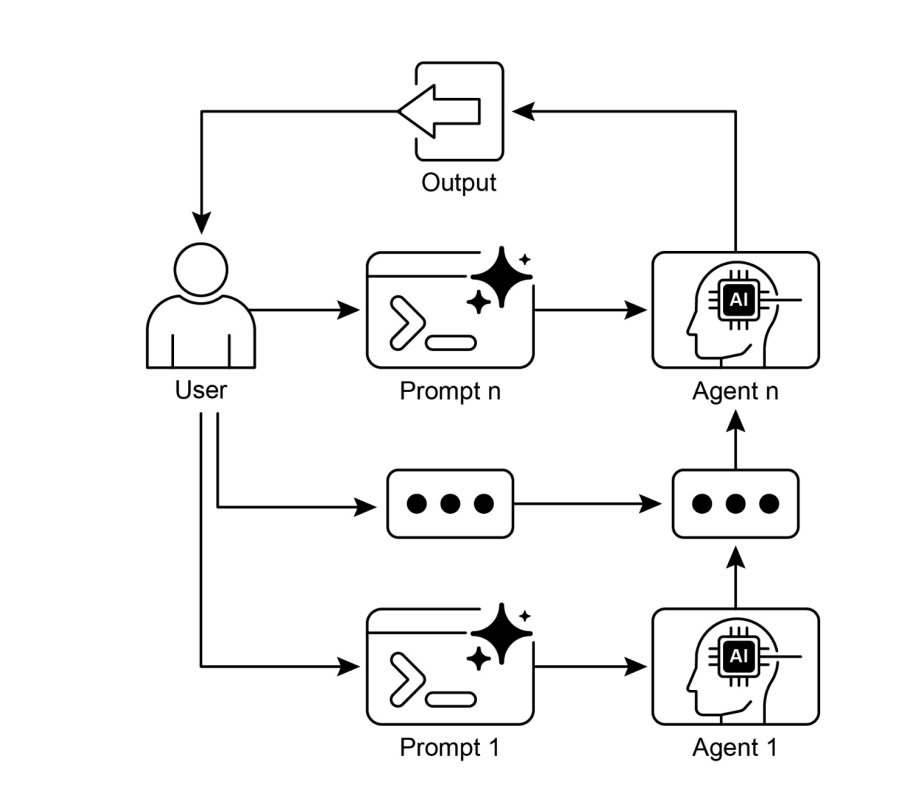
图2:提示链工作流程——用户输入通过多级提示逐步传递,每步LLM的输出自动成为下一步的输入,构建链式推理与处理机制。
核心优势
技术亮点精要
- 任务解耦:将复杂问题分解为高度聚焦的模块化子任务,构建清晰的任务执行链路
- 流程闭环:采用端到端流水线设计,确保各环节输出无缝衔接下一环节输入
- 质量保障:分层处理有效降低模型负载,大幅减少错误传播,提升结果可靠性
- 生态支持:兼容主流开发框架(LangChain/LangGraph/Google ADK),提供可视化流程编排和组件化管理能力
结论
提示链(Prompt Chaining)通过将复杂任务系统分解为聚焦且可管理的子任务序列,为大型语言模型(LLM)处理复杂问题提供了高效框架。这种模块化方法使模型在每步只需专注单一操作,有效降低认知负荷,同时大幅提升输出质量的可控性和可解释性。
作为智能体设计的核心范式,提示链支持开发具有多步推理、工具调用和动态状态管理能力的AI系统。它突破了单次提示的局限,使系统能够基于中间结果持续迭代优化,逐步逼近复杂问题的最优解。
掌握提示链技术对构建超越单次提示能力的AI工作流至关重要。这一方法不仅是技术工具,更是连接基础LLM能力与复杂应用场景的战略桥梁。
参考文献
- LangChain LCEL文档:https://python.langchain.com/v0.2/docs/core_modules/expression_language/
- LangGraph官方文档:https://langchain-ai.github.io/langgraph/
- 提示工程指南 - 链式提示:https://www.promptingguide.ai/techniques/chaining
- OpenAI API提示指南:https://platform.openai.com/docs/guides/gpt/prompting
- Crew AI任务流程文档:https://docs.crewai.com/
- Google AI提示工程指南:https://cloud.google.com/discover/what-is-prompt-engineering?hl=en
- Vertex AI提示优化器:https://cloud.google.com/vertex-ai/generative-ai/docs/learn/prompts/prompt-optimizer

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)