L2 LMDeploy 量化部署书生大模型实践
本文介绍了使用LMDeploy工具链部署和优化大语言模型的完整流程。首先通过Conda环境安装所需依赖,然后演示了如何配置PytorchEngineConfig参数(如max_batch_size、enable_prefix_caching等)来优化推理性能。文章详细展示了多模态推理服务的构建方法,包括批量请求处理对比实验。针对显存不足的情况,重点讲解了INT4模型量化和KV Cache量化技术,
1.环境安装
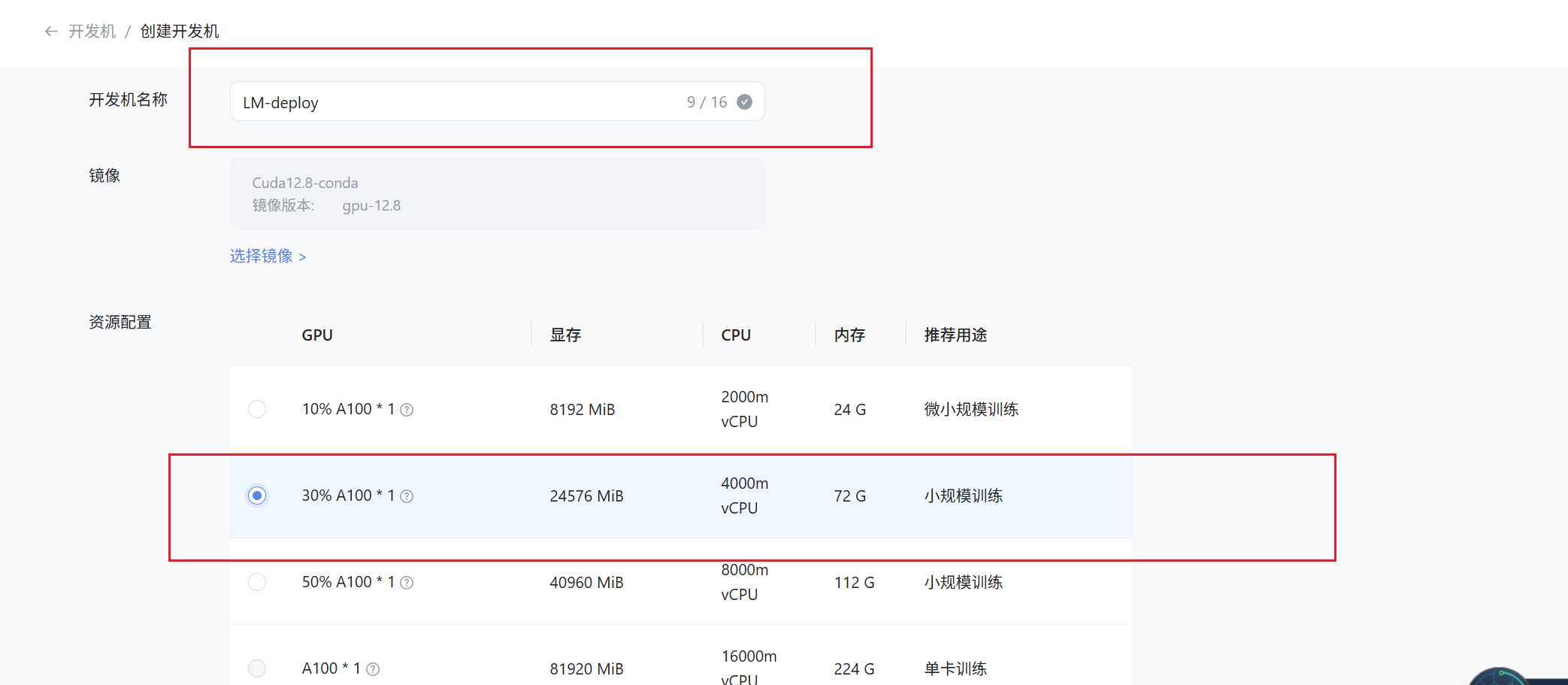
在创建开发机界面选择镜像为 Cuda12.8-conda,并选择 GPU 为 30% A100
首先创建并激活 Conda 环境,安装 lmdeploy 库:
conda create -n lmdeploy2 python=3.10 -y
conda activate lmdeploy2
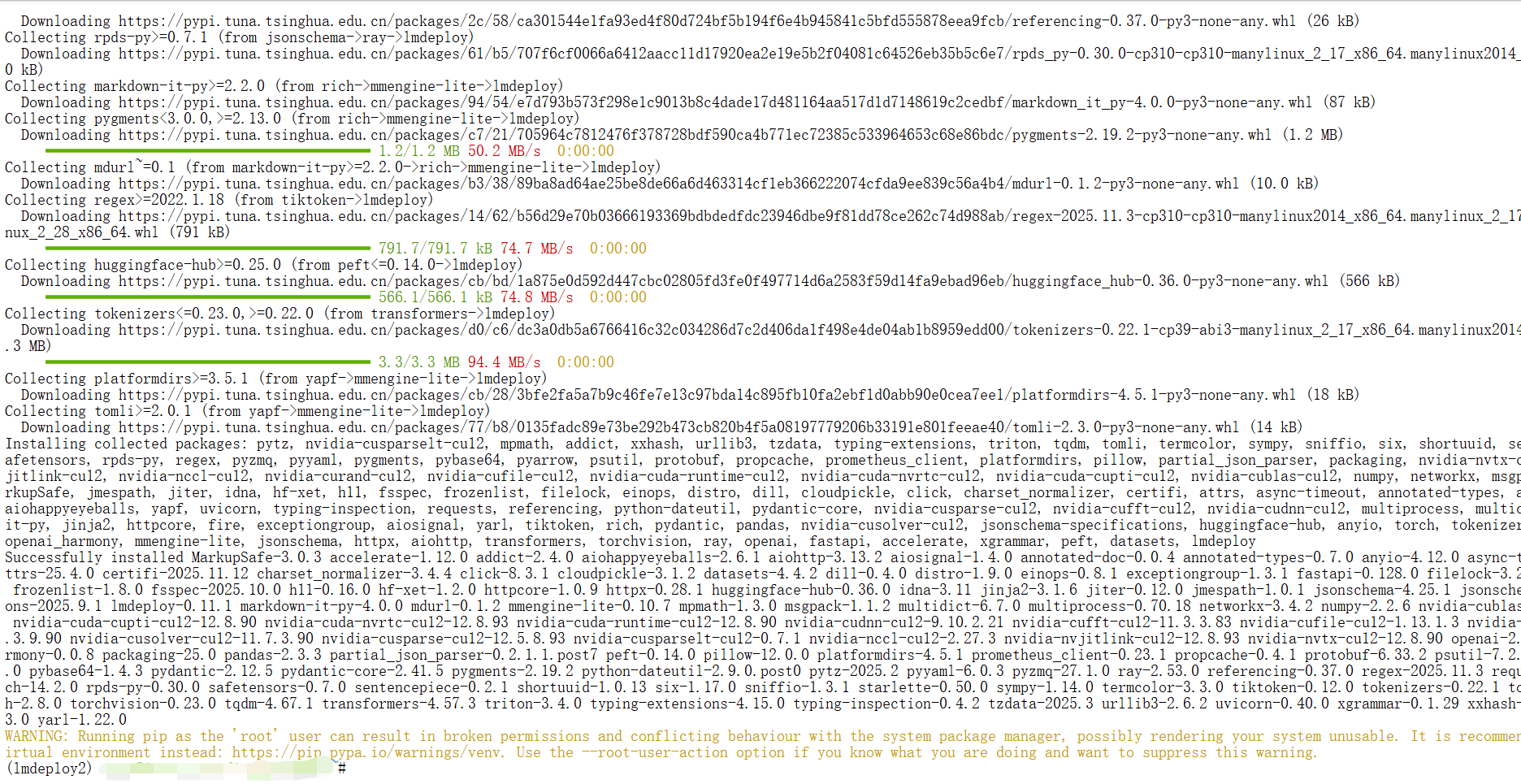
pip install lmdeploy openai datasets jmespath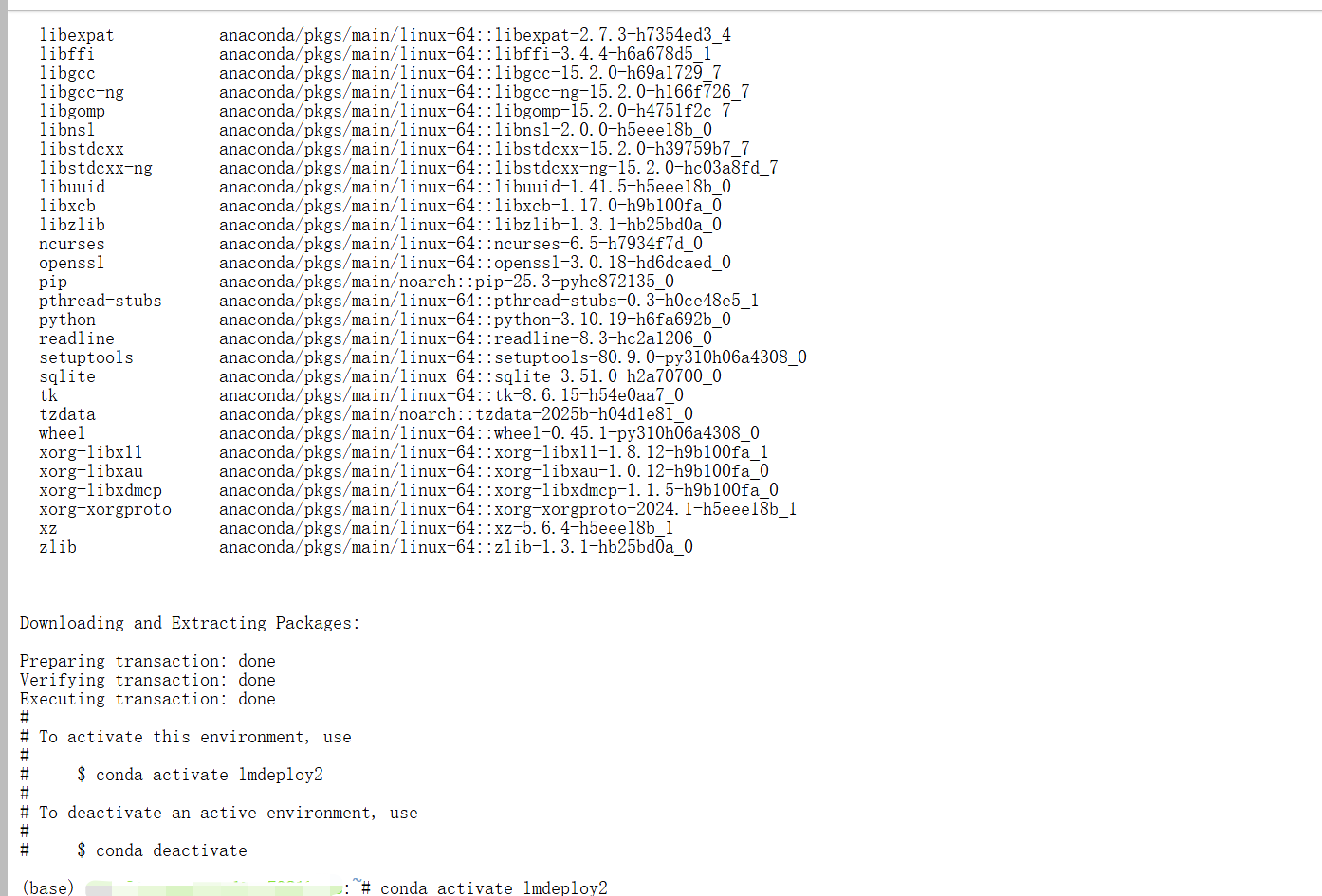
2.快速开始
以下示例演示了如何使用 LMDeploy 构建一个支持多模态任务的推理服务。通过配置 PytorchEngineConfig 中的关键参数,可以优化模型在并发、缓存和会话管理方面的表现:
from lmdeploy import pipeline, PytorchEngineConfig
from lmdeploy.vl import load_image
def main():
# 初始化pipeline
pipe = pipeline("/root/share/new_models/Intern-S1-mini",
backend_config=PytorchEngineConfig(
max_batch_size=32,
enable_prefix_caching=True,
cache_max_entry_count=0.1,
session_len=4096,
))
print("✅ Pipeline初始化成功!")
# 测试推理
image_path = "https://pic1.imgdb.cn/item/68d20846c5157e1a8828f9bf.jpg" # 替换为实际图片路径
prompt = "请描述这张图片的内容"
response = pipe([(prompt, load_image(image_path))])
print("回复:", response[0].text)
return pipe
if __name__ == '__main__':
pipe = main()配置详解
backend_config=PytorchEngineConfig(
max_batch_size=32,
enable_prefix_caching=True,
cache_max_entry_count=0.1,
session_len=4096,
)配置参数说明 我们可以将
PytorchEngineConfig的配置类比为经营一家智能快餐店,每个参数对应一个运营环节:
max_batch_size=32:如同厨房一次可接受32个订单,显著提升请求并发处理能力;
enable_prefix_caching=True:类似预制常用食材,对相似请求可复用中间结果,加快推理速度;
cache_max_entry_count=0.1:控制缓存区大小,合理分配内存资源,避免浪费或不足;
session_len=4096:设定对话记忆长度,保持上下文连贯性,同时防止内存过载。这些参数协同作用,构建出一个高吞吐、低延迟、资源可控的推理服务。
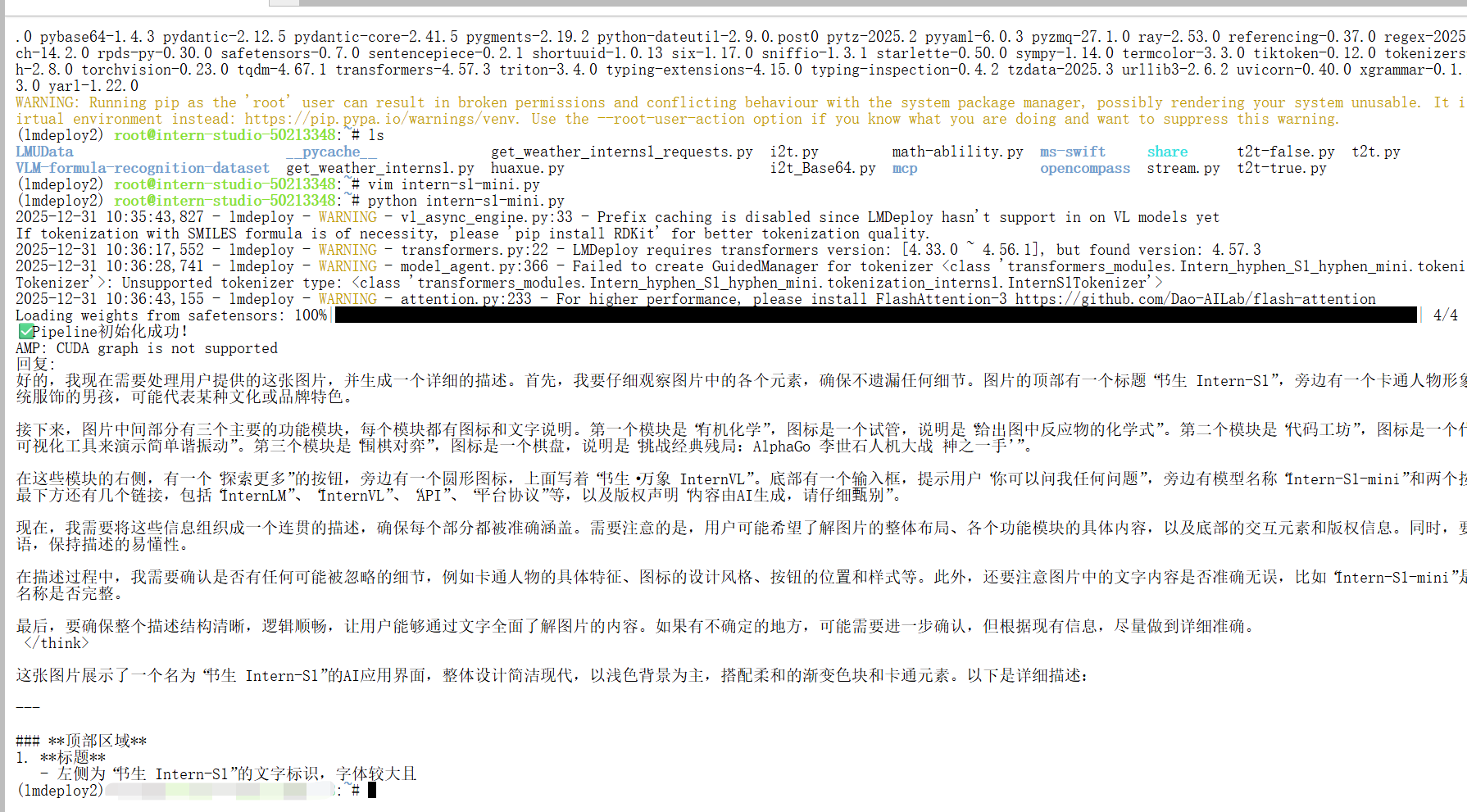
2.1 高并发请求实战示例
在实际应用中,若需处理大量并发请求,可参考以下示例,体验 max_batch_size 带来的性能优势:
from lmdeploy import pipeline, PytorchEngineConfig
from lmdeploy.vl import load_image
import time
def main():
# 初始化pipeline - 设置批量处理能力
pipe = pipeline("/root/share/new_models/Intern-S1-mini",
backend_config=PytorchEngineConfig(
max_batch_size=32, # 一次能处理32个请求
enable_prefix_caching=True,
cache_max_entry_count=0.1,
session_len=4096,
))
print("✅ Pipeline初始化成功!")
print("🚀 模拟多个用户同时请求...")
# 准备多个不同的图片和问题(模拟多个用户)
requests = [
("描述这张图片的主要内容", "https://pic1.imgdb.cn/item/68d20846c5157e1a8828f9bf.jpg"),
("图片里有什么颜色?", "https://pic1.imgdb.cn/item/68d20846c5157e1a8828f9bf.jpg"),
("这张图片让你想到什么?", "https://pic1.imgdb.cn/item/68d20846c5157e1a8828f9bf.jpg"),
("分析图片的构图", "https://pic1.imgdb.cn/item/68d20846c5157e1a8828f9bf.jpg"),
("图片中有文字吗?", "https://pic1.imgdb.cn/item/68d20846c5157e1a8828f9bf.jpg")
]
# 方法1:一次性批量发送所有请求(就像快餐店一次接多个订单)
print("\n📦 方法1:批量处理(一次发送所有请求)")
batch_inputs = []
for prompt, img_path in requests:
batch_inputs.append((prompt, load_image(img_path)))
start_time = time.time()
batch_responses = pipe(batch_inputs) # 一次处理所有请求
end_time = time.time()
for i, response in enumerate(batch_responses):
print(f"用户{i+1} 问: {requests[i][0]}")
print(f"AI回复: {response.text[:50]}...") # 只显示前50个字
print("---")
print(f"✅ 批量处理耗时: {end_time - start_time:.2f}秒")
# 方法2:逐个发送请求(对比效果)
print("\n🐌 方法2:逐个处理(一个一个来)")
start_time = time.time()
for prompt, img_path in requests:
single_response = pipe([(prompt, load_image(img_path))])
print(f"单个回复: {single_response[0].text[:30]}...")
end_time = time.time()
print(f"⏱️ 逐个处理耗时: {end_time - start_time:.2f}秒")
return pipe
if __name__ == '__main__':
pipe = main()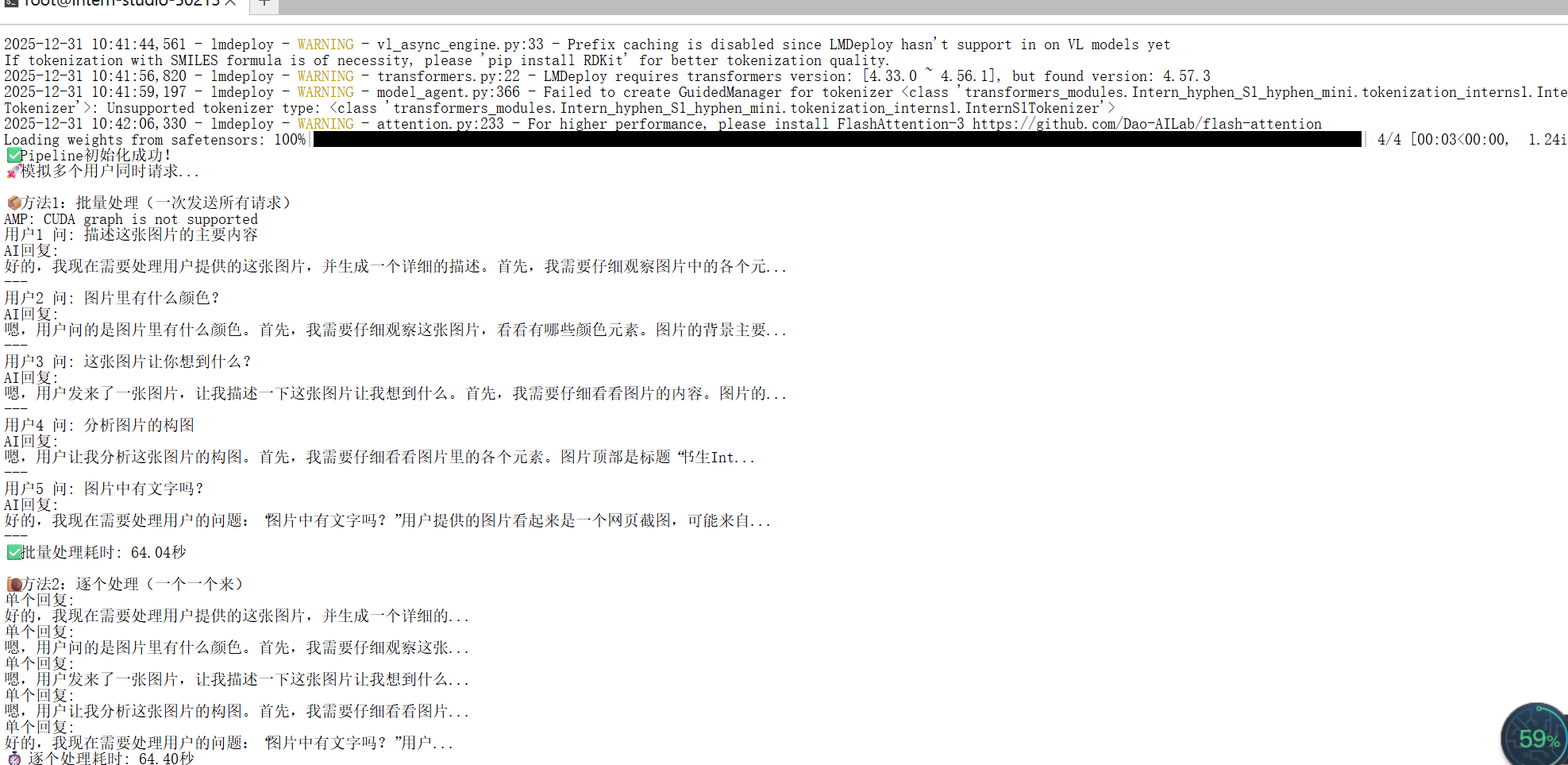
3.模型服务
使用以下命令即可将模型部署为 OpenAI 格式的 API 服务,然后 API 服务请求示例可以参考L1 玩转书生大模型 API 与 MCP
lmdeploy serve api_server /root/share/new_models/Intern-S1-mini \
--model-format hf \
--quant-policy 0 \
--cache-max-entry-count 0.1 \
--server-name 0.0.0.0 \
--server-port 23333 \
--tp 1inter-openai.py
from openai import OpenAI
client = OpenAI(api_key='YOUR_API_KEY', # A dummy api_key is required
base_url='http://0.0.0.0:23333/v1')
model_name = client.models.list().data[0].id
response = client.chat.completions.create(
model=model_name,
messages=[{
'role':
'user',
'content': [{
'type': 'text',
'text': 'Describe the image please',
}, {
'type': 'image_url',
'image_url': {
'url':
'https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg',
},
}],
}],
temperature=0.8,
top_p=0.8)
print(response)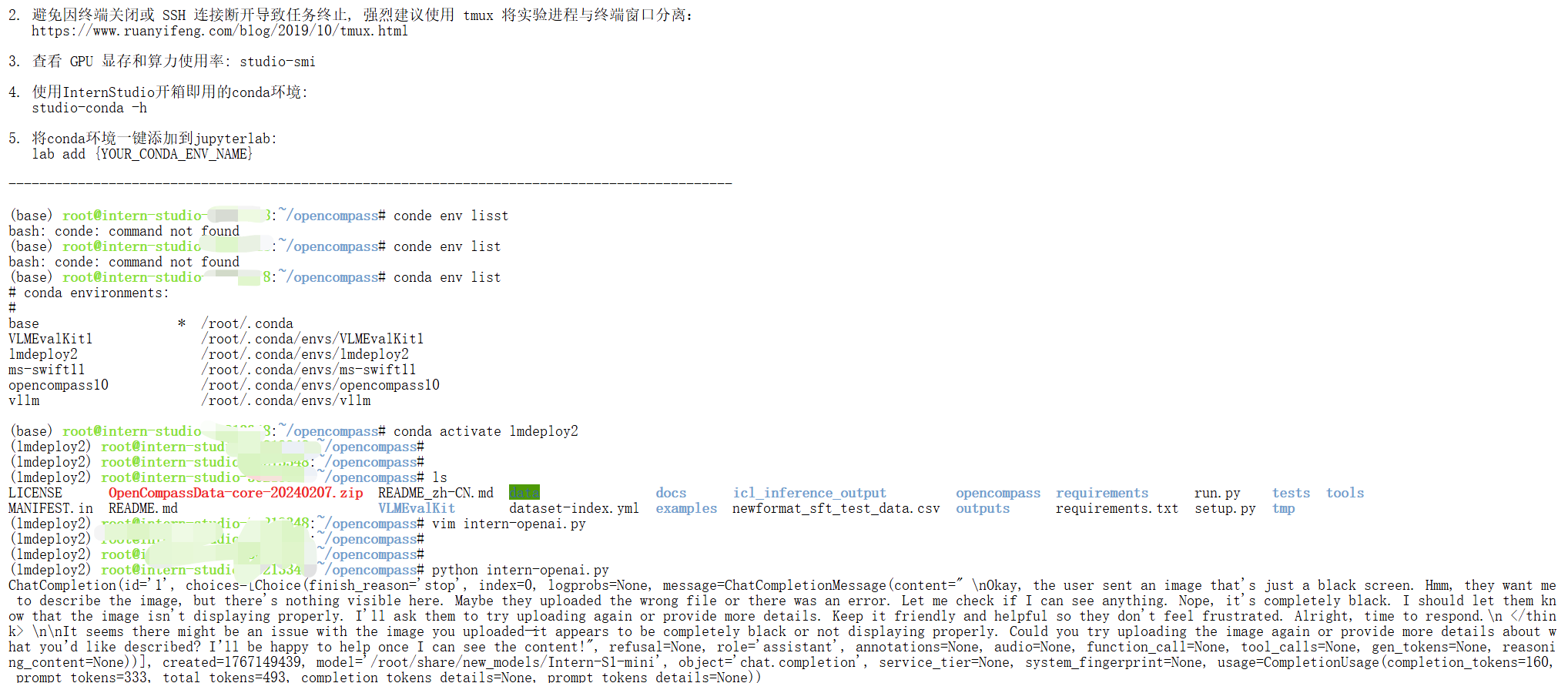
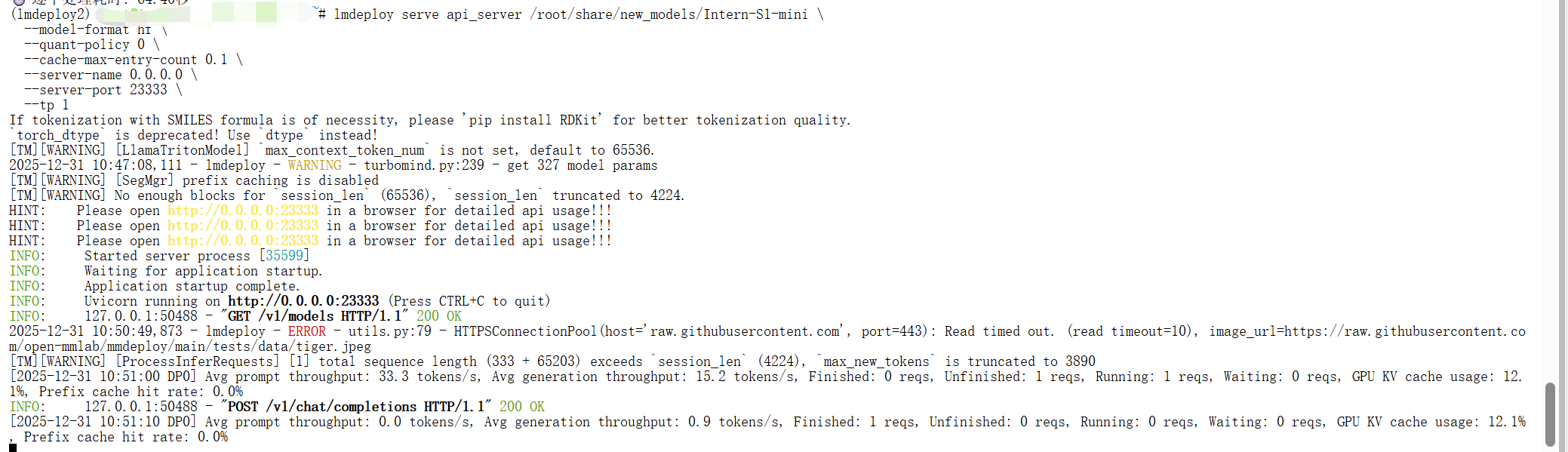
4.模型量化
当显存资源充足时,可直接启动模型服务::
lmdeploy serve api_server /root/share/model_repos/internlm2-7b
然而,在显存不足的情况下,直接运行会导致启动失败,如下图。此时需要通过模型量化技术,在可接受的性能损失范围内降低显存需求,确保服务能够正常运行。
4.1 INT4 模型量化和部署
4.1.1执行模型量化
使用以下命令将原始模型转换为4-bit量化版本:
lmdeploy lite auto_awq /root/share/model_repos/internlm2-7b --work-dir /root/internlm2-7b-4bit如遇到RuntimeError: Dataset scripts are no longer supported, but found ptb_text_only.py,可以加上--calib-dataset wikitext 启动:
lmdeploy lite auto_awq /root/share/model_repos/internlm2-7b --work-dir /root/internlm2-7b-4bit --calib-dataset wikitext可能还会报如下的错误
(lmdeploy2) root@intern-studio:~/opencompass# lmdeploy lite auto_awq /root/share/model_repos/internlm2-7b --work-dir /root/internlm2-7b-4bit --calib-dataset wikitext
Traceback (most recent call last):
File "/root/.conda/envs/lmdeploy2/bin/lmdeploy", line 7, in <module>
sys.exit(run())
File "/root/.conda/envs/lmdeploy2/lib/python3.10/site-packages/lmdeploy/cli/entrypoint.py", line 39, in run
args.run(args)
File "/root/.conda/envs/lmdeploy2/lib/python3.10/site-packages/lmdeploy/cli/lite.py", line 111, in auto_awq
auto_awq(**kwargs)
File "/root/.conda/envs/lmdeploy2/lib/python3.10/site-packages/lmdeploy/lite/apis/auto_awq.py", line 86, in auto_awq
vl_model, model, tokenizer, work_dir = calibrate(model,
File "/root/.conda/envs/lmdeploy2/lib/python3.10/site-packages/lmdeploy/lite/apis/calibrate.py", line 240, in calibrate
assert calib_dataset in ['c4', 'ptb', 'wikitext2', 'pileval'], \
AssertionError: Support only `c4`, `ptb`, `wikitext2` or `pileval`.问题根源
lmdeploy lite auto_awq 的 --calib-dataset 只接受
c4 、 ptb 、 wikitext2 、 pileval 四种名字,而你的命令里写的是 wikitext ,因此触发断言失败。
修正办法
把参数改成官方支持的 wikitext2 (注意末尾的 2 )即可:
lmdeploy lite auto_awq \
/root/share/model_repos/internlm2-7b \
--work-dir /root/internlm2-7b-4bit \
--calib-dataset wikitext2
运行可能还会有错误
Warning: we cast model to float16 to prevent OOM. You may enforce it bfloat16 by `--dtype bfloat16`
`torch_dtype` is deprecated! Use `dtype` instead!
Loading checkpoint shards: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:24<00:00, 12.27s/it]
Move model.tok_embeddings to GPU.
Move model.layers.0 to CPU.
Move model.layers.1 to CPU.
Move model.layers.2 to CPU.
Move model.layers.3 to CPU.
Move model.layers.4 to CPU.
Move model.layers.5 to CPU.
Move model.layers.6 to CPU.
Move model.layers.7 to CPU.
Move model.layers.8 to CPU.
Move model.layers.9 to CPU.
Move model.layers.10 to CPU.
Move model.layers.11 to CPU.
Move model.layers.12 to CPU.
Move model.layers.13 to CPU.
Move model.layers.14 to CPU.
Move model.layers.15 to CPU.
Move model.layers.16 to CPU.
Move model.layers.17 to CPU.
Move model.layers.18 to CPU.
Move model.layers.19 to CPU.
Move model.layers.20 to CPU.
Move model.layers.21 to CPU.
Move model.layers.22 to CPU.
Move model.layers.23 to CPU.
Move model.layers.24 to CPU.
Move model.layers.25 to CPU.
Move model.layers.26 to CPU.
Move model.layers.27 to CPU.
Move model.layers.28 to CPU.
Move model.layers.29 to CPU.
Move model.layers.30 to CPU.
Move model.layers.31 to CPU.
Move model.norm to GPU.
Move output to CPU.
Loading calibrate dataset ...
`trust_remote_code` is not supported anymore.
Please check that the Hugging Face dataset 'wikitext' isn't based on a loading script and remove `trust_remote_code`.
If the dataset is based on a loading script, please ask the dataset author to remove it and convert it to a standard format like Parquet.
README.md: 10.5kB [00:00, 39.3MB/s]
Traceback (most recent call last):
File "/root/.conda/envs/lmdeploy2/bin/lmdeploy", line 7, in <module>
sys.exit(run())
File "/root/.conda/envs/lmdeploy2/lib/python3.10/site-packages/lmdeploy/cli/entrypoint.py", line 39, in run
args.run(args)
File "/root/.conda/envs/lmdeploy2/lib/python3.10/site-packages/lmdeploy/cli/lite.py", line 111, in auto_awq
auto_awq(**kwargs)
File "/root/.conda/envs/lmdeploy2/lib/python3.10/site-packages/lmdeploy/lite/apis/auto_awq.py", line 86, in auto_awq
vl_model, model, tokenizer, work_dir = calibrate(model,
File "/root/.conda/envs/lmdeploy2/lib/python3.10/site-packages/lmdeploy/lite/apis/calibrate.py", line 295, in calibrate
calib_loader, _ = get_calib_loaders(calib_dataset, tokenizer, nsamples=calib_samples, seqlen=calib_seqlen)
File "/root/.conda/envs/lmdeploy2/lib/python3.10/site-packages/lmdeploy/lite/utils/calib_dataloader.py", line 292, in get_calib_loaders
return get_wikitext2(tokenizer, nsamples, seed, seqlen)
File "/root/.conda/envs/lmdeploy2/lib/python3.10/site-packages/lmdeploy/lite/utils/calib_dataloader.py", line 25, in get_wikitext2
traindata = load_dataset('wikitext', 'wikitext-2-raw-v1', split='train', trust_remote_code=True)
File "/root/.conda/envs/lmdeploy2/lib/python3.10/site-packages/datasets/load.py", line 1492, in load_dataset
builder_instance = load_dataset_builder(
File "/root/.conda/envs/lmdeploy2/lib/python3.10/site-packages/datasets/load.py", line 1137, in load_dataset_builder
dataset_module = dataset_module_factory(
File "/root/.conda/envs/lmdeploy2/lib/python3.10/site-packages/datasets/load.py", line 1036, in dataset_module_factory
raise e1 from None
File "/root/.conda/envs/lmdeploy2/lib/python3.10/site-packages/datasets/load.py", line 1009, in dataset_module_factory
).get_module()
File "/root/.conda/envs/lmdeploy2/lib/python3.10/site-packages/datasets/load.py", line 592, in get_module
standalone_yaml_path = cached_path(
File "/root/.conda/envs/lmdeploy2/lib/python3.10/site-packages/datasets/utils/file_utils.py", line 180, in cached_path
).resolve_path(url_or_filename)
File "/root/.conda/envs/lmdeploy2/lib/python3.10/site-packages/huggingface_hub/hf_file_system.py", line 199, in resolve_path
repo_and_revision_exist, err = self._repo_and_revision_exist(repo_type, repo_id, revision)
File "/root/.conda/envs/lmdeploy2/lib/python3.10/site-packages/huggingface_hub/hf_file_system.py", line 126, in _repo_and_revision_exist
self._api.repo_info(
File "/root/.conda/envs/lmdeploy2/lib/python3.10/site-packages/huggingface_hub/utils/_validators.py", line 114, in _inner_fn
return fn(*args, **kwargs)
File "/root/.conda/envs/lmdeploy2/lib/python3.10/site-packages/huggingface_hub/hf_api.py", line 2867, in repo_info
return method(
File "/root/.conda/envs/lmdeploy2/lib/python3.10/site-packages/huggingface_hub/utils/_validators.py", line 114, in _inner_fn
return fn(*args, **kwargs)
File "/root/.conda/envs/lmdeploy2/lib/python3.10/site-packages/huggingface_hub/hf_api.py", line 2731, in dataset_info
hf_raise_for_status(r)
File "/root/.conda/envs/lmdeploy2/lib/python3.10/site-packages/huggingface_hub/utils/_http.py", line 475, in hf_raise_for_status
raise _format(HfHubHTTPError, str(e), response) from e
huggingface_hub.errors.HfHubHTTPError: 429 Client Error: Too Many Requests for url: https://hf-mirror.com/api/datasets/wikitext/revision/b08601e04326c79dfdd32d625aee71d232d685c3 (Request ID: Root=1-695492ae-41f313f3605bdbc122848656;d75c0051-fb67-4cde-89c6-272983e62bca)
注意如上述一直失败,最好重新开个开发机。
4.1.2 部署量化模型
lmdeploy serve api_server /root/internlm2-7b-4bit 量化服务部署成功后,可通过OpenAI兼容接口进行调用:
from openai import OpenAI
client = OpenAI(api_key='YOUR_API_KEY', # A dummy api_key is required
base_url='http://0.0.0.0:23333/v1')
model_name = client.models.list().data[0].id
response = client.chat.completions.create(
model=model_name,
messages=[{
'role': 'user',
'content': [{
'type': 'text',
'text': "上海有什么?" # 这里将外层单引号改为双引号
}],
}],
temperature=0.8,
top_p=0.8,
max_tokens=100)
print(response)

量化服务部署成功后,可通过OpenAI兼容接口进行调用:
from openai import OpenAI
client = OpenAI(api_key='YOUR_API_KEY', # A dummy api_key is required
base_url='http://0.0.0.0:23333/v1')
model_name = client.models.list().data[0].id
response = client.chat.completions.create(
model=model_name,
messages=[{
'role': 'user',
'content': [{
'type': 'text',
'text': "上海有什么?" # 这里将外层单引号改为双引号
}],
}],
temperature=0.8,
top_p=0.8,
max_tokens=100)
print(response)
通过以上流程,即可在有限显存环境下成功部署并调用大语言模型服务。
4.2 Key-Value(KV) Cache 量化
4.2.1 KV Cache量化的作用
上面的模型量化就像把厚重的纸质书扫描成电子版(📚→💾),让书本体积大幅缩小,原来只能放1000本的书架现在能存4000本。
KV Cache量化则像增加阅览座位(🪑→🪑🪑🪑),原来只能同时服务8位读者,现在能接待32位。
通过 LMDeploy 应用 kv 量化非常简单,只需要设定 quant_policy 参数。
LMDeploy 规定 qant_policy=4 表示 kv int4 量化,quant_policy=8 表示 kv int8 量化。
两者结合:既用电子书节省空间,又增加座位服务更多读者,让整个图书馆在有限场地内实现最高效运营——这就是量化技术的完美协同。
def compare_quantization_effects():
"""对比三种量化的不同效果"""
# 场景1:只有Weight量化(模型瘦身)
print("🔵 场景1: 仅Weight量化")
pipe_weight_only = pipeline(
"/root/internlm2-7b-4bit", # 量化后的模型
backend_config=PytorchEngineConfig(
model_format='awq',
quant_policy=0, # 关闭KV量化
max_batch_size=8
)
)
# ✅ 效果:小显存能跑大模型
# ❌ 限制:并发数仍然受限
# 场景2:只有KV量化(服务扩容)
print("🟢 场景2: 仅KV量化")
pipe_kv_only = pipeline(
"/root/share/model_repos/internlm2-7b", # 原始模型
backend_config=PytorchEngineConfig(
model_format='hf',
quant_policy=4, # 开启KV量化
max_batch_size=32
)
)
# ❌ 限制:需要足够显存加载原始模型
# ✅ 效果:高并发、高吞吐
# 场景3:双重量化(最佳效果)
print("🚀 场景3: Weight + KV双重量化")
pipe_both = pipeline(
"/root/internlm2-7b-4bit", # 量化模型
backend_config=PytorchEngineConfig(
model_format='awq',
quant_policy=4, # 开启KV量化
max_batch_size=32,
cache_max_entry_count=0.6
)
)
# ✅ 效果:小显存 + 高并发这个配置的含义是:
✅ 模型权重:使用4-bit量化版本
✅ KV Cache:使用INT8量化
✅ 计算精度:保持FP16(默认)
实际工作流程:
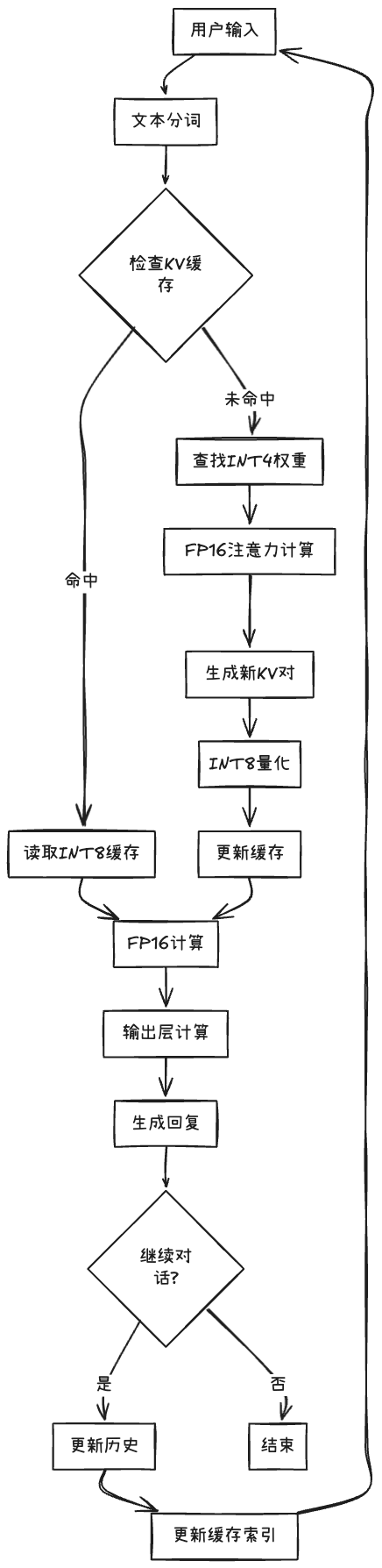

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 18
18 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)