OntoMetric:破解ESG报告难题的“大模型+本体知识图谱”新范式,准确率提升10倍
ESG合规要求日益复杂,但标准深嵌于非结构化文档,传统方法难以为继。本文介绍的OntoMetric框架,创新性地结合本体引导的大语言模型(LLM)抽取与双阶段验证,可将ESG文档自动转化为可验证、可追溯的知识图谱。实验证明,该方法将语义准确率从基线的3-10%提升至65-90%,为自动化合规与可持续金融分析提供了高保真、低成本的解决方案。
摘要
ESG合规要求日益复杂,但标准深嵌于非结构化文档,传统方法难以为继。本文介绍的OntoMetric框架,创新性地结合本体引导的大语言模型(LLM)抽取与双阶段验证,可将ESG文档自动转化为可验证、可追溯的知识图谱。实验证明,该方法将语义准确率从基线的3-10%提升至65-90%,为自动化合规与可持续金融分析提供了高保真、低成本的解决方案。
阅读原文或https://t.zsxq.com/mx9if获取原文pdf和自制中文ppt
全文推文
引言:ESG浪潮下的“报告之痛”
在全球追求可持续发展的浪潮中,环境、社会和公司治理(ESG)已从边缘议题跃升为企业战略和投资者决策的核心。 为了响应监管要求和利益相关方的问责,企业必须遵循如SASB(可持续发展会计准则委员会)、TCFD(气候相关财务信息披露工作组)以及IFRS S2(国际可持续发展准则理事会的气候相关披露)等一系列复杂的披露框架。
然而,这些关键的合规要求——包括数百个指标的定义、计算公式、适用单位和数据依赖关系——却深藏在动辄上百页、冗长且非结构化的PDF文档中。 对企业合规官、分析师和审计师而言,这意味着一场艰巨的“寻宝游戏”:
- 人工处理效率低下且易错:
从业者必须手动通读全文,识别关键指标,追踪段落、表格和交叉引用中隐含的逻辑关系,再将信息录入电子表格。这个过程不仅耗时巨大、扩展性差,而且极易因误解指标的范围、边界或计算逻辑而导致报告不一致。
- 传统自动化方法的局限:
基于关键词匹配或手写规则的传统自动化工具,无法捕捉跨框架、跨章节的复杂语义和组合依赖关系,语义覆盖能力严重不足。
- “失控”的大语言模型(LLM):
虽然LLM拥有强大的文本理解能力,但在无约束条件下直接用于信息抽取时,往往会产生不一致的实体、捏造(幻觉)的关系、缺乏出处来源,导致验证失败率居高不下,无法满足监管所需的严谨性。
- 审计与追溯困难:
手动创建的数据表或数据库常常忽略了版本元数据和指向原文的具体页面引用,这使得内部审查和外部审计变得异常困难,大大降低了报告的透明度、可复现性和可审计性。
面对这些挑战,市场迫切需要一种能够高保真地提取、构建和验证监管要求,同时确保语义精确、结构有效和来源可追溯的可靠方法。
为应对这一难题,来自澳大利亚的学者们提出了一种名为OntoMetric的创新框架。它巧妙地将本体论的符号逻辑与LLM的神经抽取能力相结合,旨在将静态、非结构化的ESG监管文档,转化为经验证、可审计、且为AI和Web应用准备就绪的知识图谱。
OntoMetric框架深度解析:三步构建可信ESG知识图谱
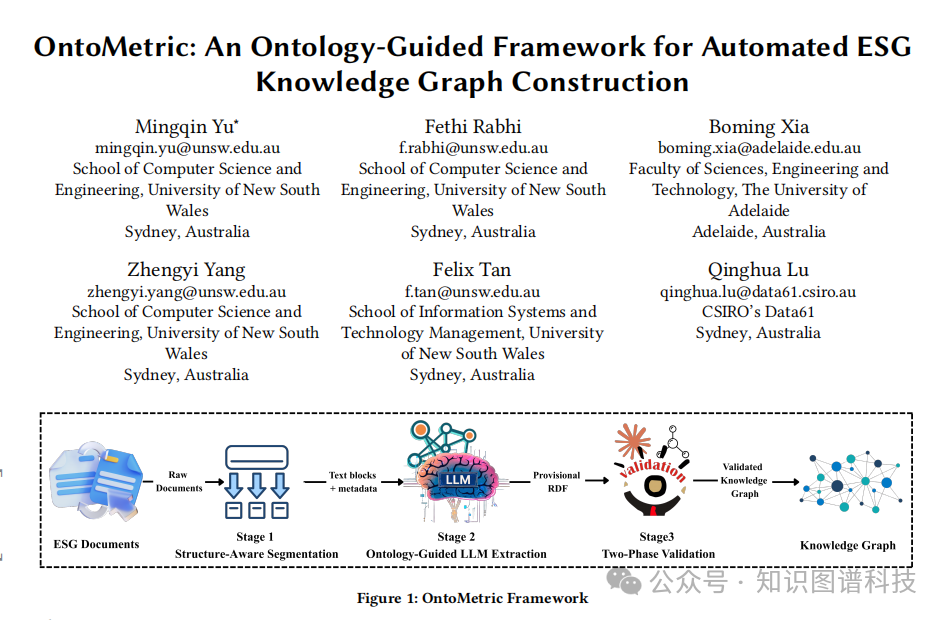
OntoMetric是一个分三阶段运行的、由本体引导的自动化框架,其核心目标是将非结构化ESG文档转化为经过验证且保留溯源信息的知识图谱。 它的模块化设计确保了每个步骤都有可解释的中间产出,并在不同文档间表现出一致的行为,最终生成支持下游应用的AI就绪知识表示。
第一阶段:结构感知分割 (Structure-Aware Segmentation)
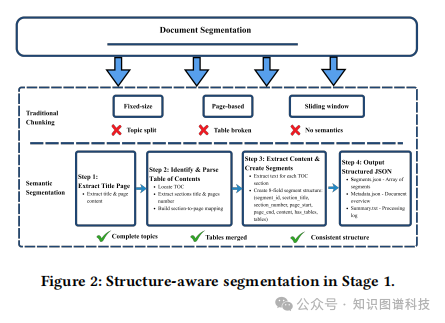
面对冗长的PDF文档,如果将全文一次性输入LLM,不仅会超出上下文窗口限制,还会因信息密度过低而影响抽取效果。 因此,第一步的关键是进行智能分割。
OntoMetric采用“结构感知”的分割策略,利用文档的目录(Table of Contents)结构作为边界,将文档切分成连贯、上下文完整的片段(segments)。 这种方法远优于按固定页数或段落数的粗暴切分,因为它保留了文档的原始逻辑结构和章节上下文,为后续的精准抽取奠定了基础。 同时,每个片段都保留了其在原始文档中的结构元数据,为最终的溯源提供了保障。
第二阶段:本体引导的LLM抽取与语义丰富 (Ontology-Guided LLM Extraction with Semantic Enrichment)
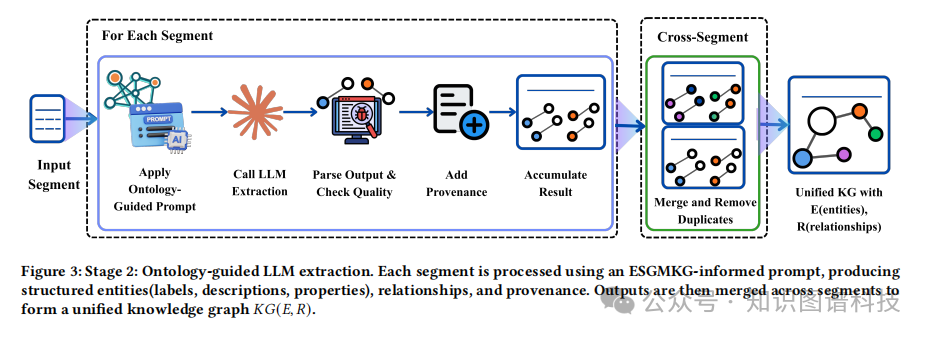
这是OntoMetric框架的“大脑”。它解决了无约束LLM抽取的核心痛点——缺乏结构保证和一致性。 该阶段通过一种精心设计的提示工程(Prompt Engineering)策略,将领域知识(以本体形式)直接嵌入到LLM的指令中。
-
本体约束: 框架使用一个名为ESGMKG的ESG领域本体。该本体预先定义了关键的实体类型(如CalculatedMetric计算指标, Model计算模型等,共5种)、关系谓词(如isCalculatedBy由...计算,共5种)以及结构规则(7条)。 这些本体约束被编码到LLM的Prompt中,指导LLM在阅读文本片段时,严格按照预设的“蓝图”来识别和构建信息。
-
语义丰富: 与传统信息抽取只关注提取实体标识符不同,OntoMetric强调“语义丰富化”。在本体的指导下,LLM不仅要识别出实体,还要从源文本中提取并填充该实体的语义字段,如易于人类理解的标签(labels)、详细的文本描述(descriptions)以及其他结构化属性(structured properties)。 这样做的好处是巨大的:它不再产生一堆冷冰冰、机器可读但人类难懂的ID,而是构建出一个个“信息丰满”的知识节点。
通过这一阶段,OntoMetric将文本片段转化为符合ESGMKG本体模式的、包含丰富语义信息的初步知识图谱。这种AI就绪(AI-ready)的知识表示,为后续的LLM推理、检索增强生成(RAG)和自动化合规分析提供了极高质量的输入。
第三阶段:双阶段验证 (Two-Phase Validation)
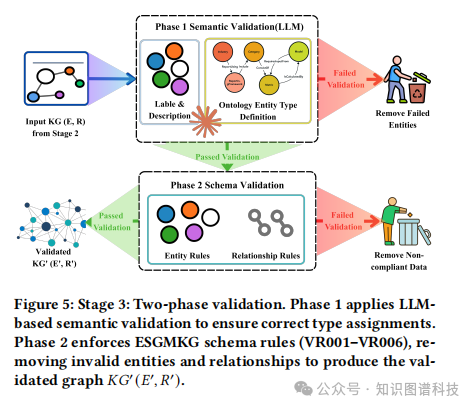
为了达到监管级的可靠性,初步提取的知识图谱必须经过严格的验证。OntoMetric设计了一套独特的“双阶段验证”机制,分别处理两种截然不同的错误类型:语义内容错误(如LLM幻觉)和结构模式违规。
-
第一阶段:基于LLM的语义验证 (LLM-based Semantic Validation)
-
此阶段利用LLM自身的推理能力。验证系统会要求LLM根据ESGMKG本体中对各类实体的自然语言定义,来判断第二阶段抽取的实体内容是否与其类型在语义上匹配。 例如,一个被标记为CalculatedMetric(计算指标)的实体,其描述内容是否真的指向一个需要计算的指标,而不是一个定义或一个组织。由于第二阶段的输出已经包含了丰富的语义描述,这使得LLM能够更准确地进行“事实核查”。
-
-
第二阶段:基于规则的模式验证 (Rule-based Schema Validation)
-
在通过语义验证后,系统会启动六个独立的规则验证器(VR001–VR006),对知识图谱的结构完整性、属性有效性和关系正确性进行检查。 这套规则检查覆盖三个层面:
- 实体完整性:
检查实体是否有唯一的ID,必需字段是否都已填充。
- 属性有效性:
检查指标代码、单位、模型输入等属性值是否符合预设格式或范围。
- 关系正确性:
确保实体间的关系谓词是预先批准的,且关系链接符合本体规定(例如,CalculatedMetric必须链接到Model)。
-
至关重要的是,在整个流程中,系统始终保留并传递着每个实体和关系到源文档的段落级和页面级出处(Provenance)。这意味着最终知识图谱中的任何一个信息点,都可以一键追溯到其在原始PDF中的权威来源,为审计和合规审查提供了无与伦比的透明度。
惊人的实证结果:准确性、合规性与成本效益的飞跃
为了验证OntoMetric的真实效果,研究团队在一系列真实的ESG标准上进行了系统性评估,包括SASB商业银行、SASB半导体、TCFD、IFRS S2以及澳大利亚的AASB S2,总计228页文档和60个处理片段。 结果令人瞩目,清晰地展示了本体引导方法相对于基线(无约束LLM抽取)的压倒性优势。
1. 质量与准确率的大幅提升
- 语义准确率 (Semantic Accuracy):
OntoMetric达到了65%–90%的语义准确率,而基线方法仅有3%–10%。这意味着OntoMetric抽出的绝大部分内容在语义上是正确的。
- 模式合规性 (Schema Compliance):
OntoMetric的输出有80%–90%符合预定义的本体模式,结构非常可靠。
- 关系保留率 (Relationship Retention):
基线方法在识别实体间关系方面几乎完全失败(保留率仅0-3.1%),而OntoMetric成功保留了63%–90%的有效关系。
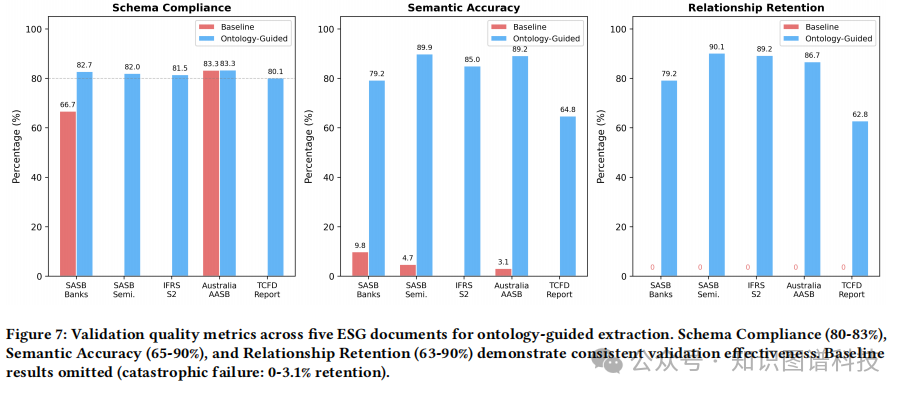
图7:五份ESG文档的验证质量指标对比
下图以条形图形式展示了OntoMetric(本体引导)方法在模式合规性、语义准确率和关系保留率上的表现,并与基线方法的灾难性结果形成对比。
- 模式合规性 (Schema Compliance):
本体引导方法在所有五份文档(SASB银行、SASB半导体、IFRS S2、澳大利亚AASB S2、TCFD报告)上均表现出稳定且高水平的合规性(80-83%)。
- 语义准确率 (Semantic Accuracy):
本体引导方法的准确率在65%至90%之间波动,显著高于基线。
- 关系保留率 (Relationship Retention):
本体引导方法实现了63%到90%的关系保留,而基线方法几乎为零。
(图示描述:一系列条形图,清晰对比了“本体引导”和“基线”两种方法在上述三个指标上的巨大性能差距。)
2. 成本效益的革命性突破
对于企业级应用而言,成本是关键考量因素。OntoMetric不仅质量高,还极具成本效益。
- 单位成本:
每验证一个实体的成本仅为**$0.01–$0.02**。
- 成本浪费率:
基线方法由于产生了大量无效抽取,其成本浪费率高达97%。相比之下,OntoMetric的成本浪费率仅为10%–35%(平均19%),这意味着大部分计算资源都用在了有效的抽取上。
- 综合效率:
综合计算,OntoMetric在获得有效实体方面的效率比基线方法高出48倍以上。
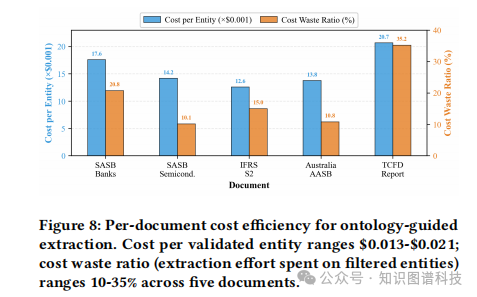
图8:本体引导抽取的单位成本效率
此图显示,在五份不同的ESG文档上,使用OntoMetric框架处理后,每个验证实体的成本稳定在$0.013至$0.021之间,成本浪费率也控制在10%至35%的合理区间。
(图示描述:一个条形图,展示了五份文档各自的“单位实体成本”和“成本浪费率”。)
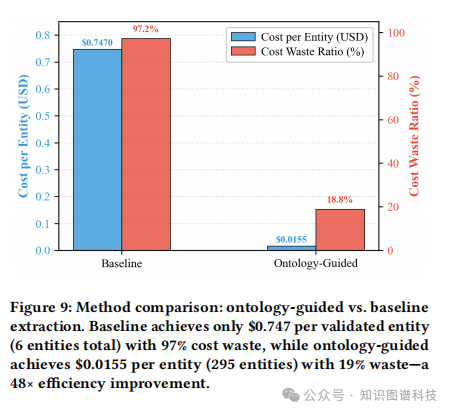
图9:两种方法的成本效率对比
此图直观地对比了两种方法的巨大差异。基线方法平均花费$0.747才能得到一个有效实体,成本浪费率高达97%。而OntoMetric方法仅需$0.0155,成本浪费率仅19%。
(图示描述:一个条形图,并列展示了“基线”和“本体引导”在“单位实体成本”和“成本浪费率”上的悬殊对比。)
结论与展望:开启AI驱动的合规新纪元
OntoMetric的成功并非偶然,它源于三个关键的设计抉择:
- 语义丰富化
,而不仅仅是提取ID,这使得知识图谱能够直接支持下游的AI推理和检索应用。
-
将验证分解为语义和结构两个阶段,有效隔离并处理了两种根本不同的错误模式。
-
在抽取过程中全程捕获和保留出处信息,确保了每一个知识点都可追溯、可审计。
通过将本体的符号约束与LLM的神经理解能力相结合,OntoMetric框架成功地弥合了现有技术鸿沟,证明了构建可靠、可审计的监管科技知识图谱是完全可行的。
这项工作不仅为处理复杂的ESG文档提供了即时可用的解决方案,其核心思想——“本体引导的LLM抽取+双阶段验证”——更是一个可复用的模式,能够被推广到法律、金融、医疗等其他需要高精度信息抽取的监管密集型领域。
未来,基于OntoMetric生成的AI和Web就绪知识图谱,可以通过API或关联数据(Linked Data)的形式发布,为一系列前沿应用提供动力,包括:
- 可持续金融分析工具
- 企业ESG透明度门户
- 自动化合规审计与报告生成系统
这无疑为企事业单位、科研院所和投资者们驾驭复杂的ESG浪潮,提供了一件强大而可靠的“AI利器”。
标签
#知识图谱 #ESG #大语言模型 #自动化合规 #LLM #KnowledgeGraph
欢迎加入「知识图谱增强大模型产学研」知识星球,获取最新产学研相关"知识图谱+大模型"相关论文、政府企业落地案例、避坑指南、电子书、文章等,行业重点是医疗护理、医药大健康、工业能源制造领域,也会跟踪AI4S科学研究相关内容,以及Palantir、OpenAI、微软、Writer、Glean、OpenEvidence等相关公司进展。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 17
17 0
0- 0



 已为社区贡献58条内容
已为社区贡献58条内容

所有评论(0)