LLM - 从 MCP 到 Skills:2025 年 AI Agent 的工程实践全景解析
摘要: AI Agent技术正从概念走向落地,通用Agent虽功能全面但成功率低,垂直场景Agent(如Coding Agent)表现更优。MCP协议解决了Agent与工具/数据的连接问题,而Skills层通过可复用的“技能包”提升了任务执行的稳定性。上下文工程通过精准控制信息输入(写入、选择、压缩、隔离)优化决策质量。未来Agent将演变为以LLM为核心、工具为外设的云端计算环境,需结合工程化方
文章目录
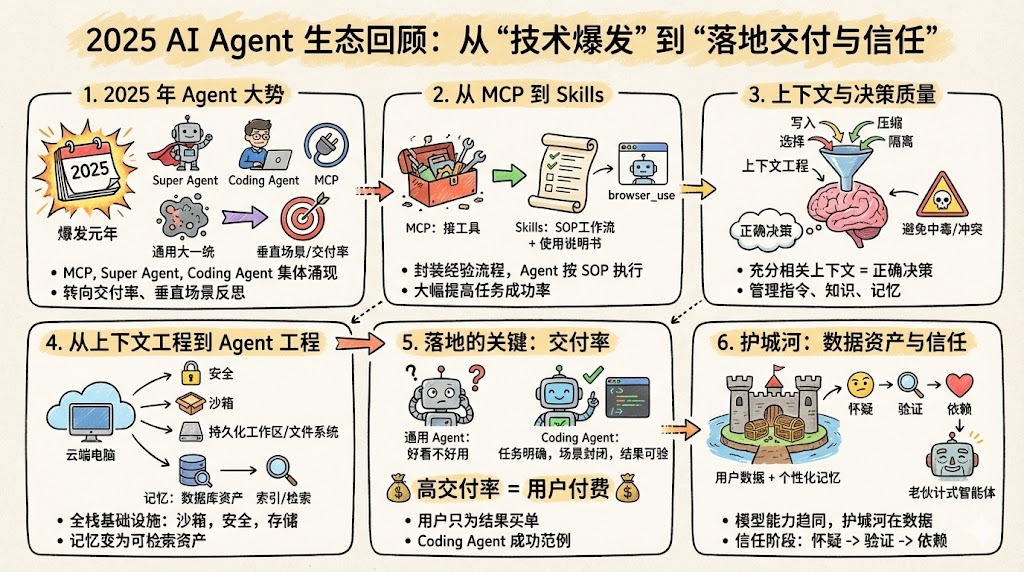
一、引言:从“什么都会”到“能做成事”
2024 下半年开始,围绕 AI Agent 的技术与产品节奏明显加快:Anthropic 推出 computer use 与 MCP server,各家开启“给 Agent 一台云端电脑”的实践;2025 年,又在 o1、DeepSeek-R1、Manus、各式 Coding Agent 与专用 Agent 平台的推动下,Agent 赛道真正从概念走向了落地竞争。
一线实践暴露出一个共同问题:
- 通用 Agent 看上去什么都能做,但真正“从头做到尾”的成功率并不高。
- 相反,Coding Agent 这种垂直场景 Agent 的交付率却持续上升,用户愿意为其付费,复用率和留存都相对稳健。
这背后折射出的,是一条清晰的演进主线:
MCP 解决“接上世界”的问题,Skills 解决“如何干成活”的问题;上下文工程解决“模型怎么理解当前局面”,Agent 工程解决“整套系统如何稳定地交付结果”。
接下来,从工程视角拆解这条路径,并给出可落地的实践方法与架构图文说明。
二、MCP 之后:为什么一定会走到 Skills
2.1 MCP:让 Agent 真正“有手有脚”
MCP(Model Context Protocol)的核心价值在于提供了一套通用协议,让模型可以统一地访问各种工具、数据源、服务和文件系统。
对工程团队来说,MCP 带来的直接收益是:
- 工具接入标准化:统一的 Schema、统一的调用方式,避免每家都造一套 Tooling SDK。
- 上下文渠道统一:无论是数据库、HTTP API 还是本地文件,最终都通过 MCP 封装为“上下文与工具能力”。
用一张简化结构图来描述 MCP 视角下的 Agent:
+-------------------------+
| LLM / Agent |
+-------------------------+
|
| MCP 调用
v
+-------------------------+
| MCP Client |
+-------------------------+
|
| MCP 协议
v
+-------------------------+
| MCP Servers / Tools |
| - Web 浏览器工具 |
| - 文件系统工具 |
| - 第三方 API |
+-------------------------+
在这个阶段,Agent 已经“有了双手双脚”,可以访问浏览器、读写文件、调第三方系统。
但现实很快暴露一个问题:
工具很多、能力很强,但怎么组合工具才能干成一个复杂任务,完全靠每次推理临时“想”,成功率和稳定性都不足。
2.2 Skills:从“工具列表”到“可执行经验”
Skills 的出现,就是为了解决“有一堆工具,却没有可靠 SOP”的问题。
典型的 Skills 形态,可以简单抽象为:
skill-name/
├── SKILL.md # 说明书:用途、前置条件、输入输出、步骤说明
├── scripts/ # 可编排的脚本、工作流定义
├── examples/ # 典型用法和样例
└── resources/ # 相关模板、配置、辅助数据
核心理念是:
- 用 人类可读的文档 + 可执行的脚本/工作流,把经验沉淀为可复用的“技能包”。
- Agent 调用技能时,既可以“参考说明书”,也可以“直接执行一整套 pipeline”。
和纯 MCP Tooling 的对比,可以用一张简化对照表来理解:
| 维度 | MCP 工具层 | Skills 层 |
|---|---|---|
| 抽象级别 | 原子工具(读、写、请求一次 API) | 复合任务(完整 SOP:多步、多工具) |
| 用户心智 | “我有很多 API” | “我有很多能直接完成任务的技能” |
| 复用方式 | 每次都要重新规划调用顺序 | 一次规划,多次复用 |
| 维护成本 | 每个工具单独演进 | 改一次 Skill,可统一升级整条流程 |
在实际工程实践中,如果不引入 Skills 层,你会遇到典型问题:
- 复杂任务中,LLM 需要在每轮推理中重新“发现”调用顺序,一不小心就“迷路”。
- 任务稍有变化,整套 Prompt + 工具调用逻辑需要完全重写,维护成本极高。
- 团队难以把“一个工程师摸索出的好用流程”分享给整个系统和其他 Agent。
三、上下文工程:从“多给点信息”到“精确地给对信息”
3.1 为什么上下文工程是 Agent 成败的分水岭
只有在尽可能充分的上下文中,大模型才更有可能做出正确的决策。
但现实恰恰相反:
- 一味堆上下文,容易导致“语境中毒”“注意力涣散”“上下文冲突”等问题。
- Token 成本飙升、推理延迟增加,工程和产品体验都不可接受。
这就是“上下文工程”存在的根本理由——它不是“多给点信息”,而是回答一个更精确的问题:
在当前步骤,应该给模型哪一小块上下文,才能最大化决策质量、最小化干扰和成本?
3.2 上下文的四个核心构件
可以将 Agent 运行时涉及的上下文拆成四个主要构件:
- 指令(Instructions)
- 系统 Prompt、角色设定、约束条件、任务目标。
- 知识(Knowledge)
- 长期知识库、文档、代码库、RAG 索引等。
- 工具反馈(Tool Feedback)
- 最近几轮工具调用结果、浏览器 DOM、文件快照等。
- 记忆(Memory)
- 用户偏好、历史任务、长期状态与配置。
在工程实践中,常见的失败模式包括:
- 指令与知识冲突,导致模型“分不清谁更重要”。
- 工具反馈过载,把整个 DOM 或日志全量塞进上下文。
- 长期记忆没有筛选,旧信息和当前任务高度无关。
3.3 四大上下文策略:写入、选择、压缩、隔离
借用 LangChain 总结的视角,可以把上下文工程的核心策略归纳为四类:
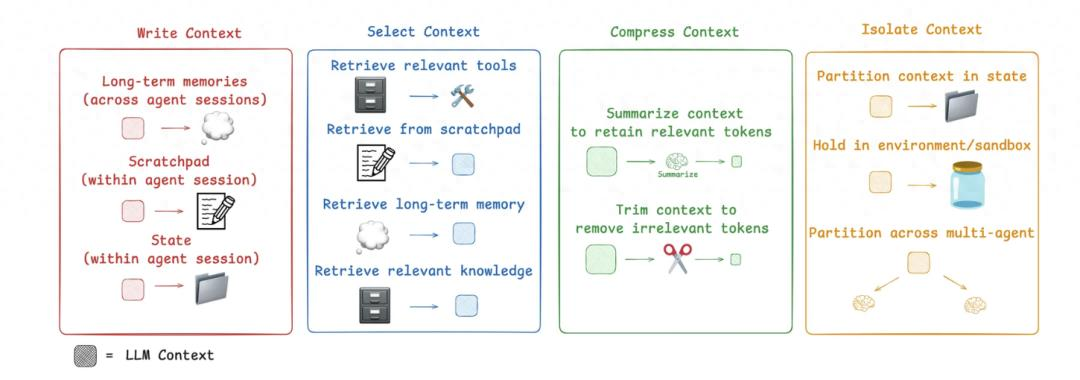
- 写入(Write)
- 将关键信息写入到“可持久化空间”,例如 Scratchpad、Memory、外部存储,避免完全依赖短期对话历史。
- 选择(Select)
- 通过检索(向量搜索、关键字索引等)只选取与当前步骤最相关的知识/记忆。
- 压缩(Compress)
- 对长文档、长日志进行摘要、截断、结构化提取,把冗余细节去掉。
- 隔离(Isolate)
- 将不同任务或阶段的上下文隔离在不同“通道”/Agent 中,避免互相污染。
可以用一张“上下文流转示意图”来展示这一过程:
+-------------------+
| 永久存储层 |
| - 文档/代码库 |
| - 用户记忆数据库 |
+---------+---------+
^
| 写入 / 同步
|
+---------+ 检索 | 压缩 +--------------------+
| LLM +<----------+<----------------+ 上下文编排器 |
+----+----+ | +---------+----------+
^ | 选择/过滤 |
| 临时上下文 v | 隔离不同通道
+----+----------------------+ +-----------+----------+
| 指令 / 工具反馈 /近期对话 | | 多 Agent / 多任务通道 |
+---------------------------+ +----------------------+
在具体实现中,可以采用以下实用策略:
- 为每一类上下文分配最大 Token 配额,超过阈值时优先做压缩而不是硬截断。
- 指令层保持稳定,不在每轮对话中反复拼接完整指令,而是存储在系统级别。
- 对工具反馈设置“时间窗口”,只保留最近 N 步的结果,并在必要时做结构化提炼(如提取关键字段)。
四、架构:从上下文工程走向 Agent 工程
4.1 核心思路:给 Agent 一台“云端电脑”
当引入 MCP、浏览器工具、文件系统、第三方 API 等能力后,Agent 已经不再是“一个纯粹的 Chat Bot”,而是:
一套以 LLM 为“决策引擎”、工具为“外设”、持久化存储为“硬盘”的云端个人计算环境。
可以用下面这一张高层架构图来把整个系统串起来:
+--------------------------------------------------------------+
| 用户入口层 |
| - Web / App / CLI / IDE 插件 |
+--------------------------+-----------------------------------+
|
v
+--------------------------------------------------------------+
| Orchestrator (编排层) |
| - 会话管理 (Session) |
| - 任务分解与路由 (Task Routing) |
| - Agent/Skill 调度 |
+---------+---------------------------+------------------------+
| |
v v
+---------------------+ +-------------------------------+
| Core Agents | | Skills Registry |
| - 主控 Agent | | - SKILL.md 元数据 |
| - 子任务 Agents | | - Scripts / Workflows |
+--------+------------+ +-------------------------------+
|
v
+--------------------------------------------------------------+
| Context & Memory 层 |
| - 指令模板库 (Prompts) |
| - 长期记忆库 (User Memory DB) |
| - 文档/代码索引 (RAG) |
+----------------------------+---------------------------------+
|
v
+--------------------------------------------------------------+
| 工具与环境层 |
| - MCP Client |
| - Browser / computer use |
| - File System / DB / API |
| - 沙箱执行环境 (Sandbox) |
| - 工作区 (Workspace / FS Snapshot) |
+--------------------------------------------------------------+
几个关键工程理念:
- 上层是“编排与决策(Orchestrator + Agents + Skills)”,下层是“能力与环境(MCP 工具 + 沙箱 + 工作区)”。
- Context & Memory 层是两者的“缓冲与连接器”,既管理上下文,又沉淀长期状态。
- 工程实践中,真正困难的是编排层 + Context & Memory 层的设计,而不只是“怎么多接几个工具”。
4.2 沙箱、工作区与冷启动:Agent 工程的三大关键点
从工程角度看,“给 Agent 一台云端电脑”至少涉及三个核心问题:
-
沙箱(Sandbox)
- 目标:让 Agent 可以“放开手脚”读写文件、开浏览器、跑脚本,但不把真实环境搞崩。
- 实践要点:
- 使用容器/虚拟机隔离环境,限定网络访问范围与权限。
- 对文件系统进行挂载控制,只暴露特定目录。
-
工作区(Workspace)
- 目标:为一次任务提供一个独立的“文件系统 + 进程空间”,所有中间产物可重复访问。
- 实践要点:
- 用统一的 Workspace ID 标识一次任务,从日志、文件、记忆中交叉索引。
- 对高价值中间产物(如总结、结构化数据)进行提炼并写入 Memory。
-
冷启动与快照(Warm Pool & Snapshot)
- 目标:避免每次任务都从“空容器 + 空浏览器”启动,降低延迟和成本。
- 实践要点:
- 维护一组预热好的环境池,包含常用工具、浏览器实例等。
- 支持任务级别的“工作区快照”,对于长流程任务可以暂停/恢复。
可以用一幅“任务生命周期图”来说明 Agent 在工程系统中的运行流程:
[收到任务]
|
v
[创建/分配 Workspace]
|
v
[加载必要上下文 (指令 + 记忆 + 文档索引)]
|
v
[主控 Agent 规划 -> 调用 Skills / 子 Agent]
|
v
[通过 MCP 在 Sandbox 中执行工具操作]
|
v
[写回中间产物到 Workspace + Memory]
|
v
[评估是否完成 / 是否需要人工确认]
|
v
[输出结果,关闭或挂起 Workspace]
五、交付率工程:为什么 Coding Agent 赢了
5.1 三个前提:明确、封闭、可验证
纵观目前“真正跑起来、有人付费用”的 Agent 产品,Coding Agent 是最典型的一类。
结合实践经验,可以总结其高交付率背后有三个共同前提:
- 任务明确
- “修这个报错”“实现这个接口”“优化这段逻辑”,目标清晰,评判标准相对客观。
- 场景封闭
- 在 IDE 或特定项目目录内,世界是相对有限的,环境可控。
- 结果可验证
- 编译通过、测试通过、运行输出正确,是否成功几乎可以自动判断。
对于工程团队,这三个前提意味着:
- 可以做针对性的上下文工程:只喂当前文件 + 相关依赖 + 报错日志。
- 可以构建很清晰的 Skills:
- “定位报错 → 搜索根因 → 提交修复 patch → 运行测试 → 回传结果”。
- 可以引入自动评估环节,形成闭环微调或反馈优化。
5.2 借鉴 Coding Agent 的“交付工程”
如果把 Coding Agent 的经验抽象出来,用于其他垂直场景(如数据分析、营销自动化、运维自动化等),可以参考以下工程策略:
- 缩小世界:尽量通过 Workspace、权限、资源限制,构建“可控小宇宙”。
- 定义清晰任务模板:为常见任务设计固定的 Prompt 模板 + Skills 工作流。
- 设计可验证指标:就算无法像编译/测试那样完全客观,也要设计明确的“验收标准”和评分机制。
- 内置回滚与人工干预:对于高风险操作,引入“执行前 Review”“执行后回滚点”等机制。
实践中,如果你发现一个 Agent 场景交付率长期上不去,很大概率是:
任务边界不清晰 + 场景开放度太高 + 系统没有可执行的 Skills SOP。
六、记忆与数据资产:真正的长期护城河
6.1 模型会同质化,记忆不会
随着基础模型愈发强大且趋于同质,单纯“换个模型”带来的差异越来越小。
在这样的背景下,有两个东西会成为真正的长期护城河:
- 结构化的任务与技能库(Skills)
- 积累的用户记忆与数据资产(Memory + 内容库)
以内容创作为例:
- Agent 不仅执行写作任务,还会沉淀:
- 用户写作风格偏好。
- 共用的素材库、选题池、过往作品。
- 不同平台的发文策略、互动数据。
- 这些东西在底层数据库/文件系统中形成一个难以迁移的资产池,即使用户更换前端界面或模型内核,也很难“平移”。
6.2 信任阶梯:从怀疑到依赖
原文中提到,用户与 Agent 的关系大致会经历三个阶段:
- 怀疑期
- “你真的能帮我干活吗?”
- 典型行为:小范围试用,手动复核。
- 验证期
- “有些任务你做得还不错,但我会盯着你。”
- 典型行为:交给 Agent 处理特定任务,持续观察交付质量。
- 依赖期
- “这事直接扔给它处理就行,我只管看结果。”
- 典型行为:Agent 成为日常工作流的一部分,用户会为其付费,甚至围绕它重构自己的工作方式。
在工程实践中,可以主动设计一些“信任加速器”:
- 为关键操作提供“模拟执行模式”(dry-run),先展示计划和预期结果再真正执行。
- 为每次任务生成清晰的“操作日志”和“复盘摘要”,便于用户追踪。
- 将高频成功任务自动沉淀为可见的 Skills,让用户感知系统在学习和进步。
七、面向工程实践者的落地建议
如果你正在负责或准备构建一个 Agent 系统,结合以上内容,可以考虑从以下几个具体步骤开始:
- 从一个垂直场景切入
- 优先选择任务目标明确、结果可验证、环境可控的场景(如内部知识助手、简单运维、固定流程的内容生产等)。
- 先把 SOP 写成人类可读文档,再抽象为 Skills
- 不要一开始就指望 LLM“自己想出流程”。
- 先由人写出 SKILL.md 与步骤,再逐步转成半自动/全自动工作流。
- 搭建最小可用的上下文工程框架
- 为指令、知识、工具反馈、记忆四块分别设计存储与配额。
- 引入基础的检索(Select)与摘要(Compress)能力。
- 把 Workspace 和 Sandbox 当作一等公民
- 为每个任务分配独立 Workspace ID,所有日志、文件、记忆都和这个 ID 关联。
- 对高风险操作必须在沙箱中先演练。
- 尽早设计“记忆与资产”策略
- 明确哪些数据要长期保存、如何索引、如何用于个性化。
- 在产品界面让用户感知这些积累,形成“资产沉淀”的心理预期。
结语:从“能做什么”到“给你做成什么”
2025 年的 Agent 进化,表面上是 MCP、Skills、computer use、各类 Coding Agent 的百花齐放,实质上是工程范式的转变:
- 从“拼 Prompt 拼工具”到“系统化的上下文工程”。
- 从“做个 Chat Bot”到“给 Agent 配一台云端电脑”。
- 从“炫技式 Demo”到“围绕交付率和信任阶梯去设计工程与产品”。
对于工程实践者而言,真正值得投入精力的不是“再做一个什么都能聊的通用 Agent”,而是:
在一个具体领域,真正把 MCP + Skills + 上下文工程 + Agent 工程打磨到能稳定交付结果,并在长期记忆与数据资产上形成难以替代的护城河。
当这条路走通之后,“Agent 是不是会取代多少岗位”不再是重点——重点在于:
你的系统是否已经做好准备,让这些 Agent 成为可靠的工程组件和业务伙伴,而不是一时的演示玩具。


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 21
21 0
0- 0



 已为社区贡献65条内容
已为社区贡献65条内容

所有评论(0)