【硬核实战】Containerlab + Arista cEOS:部署 EVPN VXLAN 及常见报错深度解析
本文记录了在MacOS上搭建EVPN-VXLAN混合网络实验环境的完整过程。通过UTM+UbuntuServer构建轻量级虚拟化基座,采用Arista cEOS作为Leaf节点、FRR作为Spine节点,实现了异构厂商设备的兼容组网。重点阐述了Containerlab声明式拓扑编排、Underlay/Overlay网络配置、常见问题排查方法,以及使用nsenter工具进行VXLAN报文抓包分析的技
📖 目录
二、 声明式拓扑:Containerlab 的“基础设施即代码”
三、 进阶实战:从 Underlay 到 Overlay 的逻辑跃迁
五、 真相之光:利用 nsenter 洞悉 VXLAN 封装
一、 虚拟化基座:在 macOS 上开启“异构时空”
在 Intel 芯片的 Mac 上运行大规模网络实验,本质上是一场架构兼容性的远征。我们摒弃了笨重的传统 VM,采用 UTM + Ubuntu Server 构建轻量化寄主环境。
1. 镜像生命灌注:Arista cEOS 与 FRR
我试图在实验室构建一个混合架构:用轻量级的 FRR 充当 Spine,配合性能强悍的 Arista cEOS 担纲 Leaf。这本是一场追求开源灵活性与商业稳定性的博弈。
在Leaf节点上,我选择的Arista 的 cEOS (Containerized EOS)。cEOS是真正的 Docker 容器,而不是在容器里跑虚拟机。极致的资源占用使运行 8-10 台 Arista 交换机,内存占用可能还没 2 台思科多。且支持完整的 EVPN-VXLAN 堆栈。
官方支持镜像下载,只要在 Arista 官网注册一个账号(个人邮箱即可),就可以在 Support 页面免费下载 cEOS-lab 镜像。
在Spine节点上,我选择的资源占用更少的FRR。Spine 只做路由反射,不处理复杂的业务逻辑(如 VXLAN 封包)。FRR 的内存占用极低(约 100MB),在 Intel Mac 上你可以轻松开 2 个 Spine 做冗余。 同时FRR的兼容性强: FRR 遵循标准的 RFC 协议。即使你的 Leaf 是 Arista 或 Cisco,FRR 也能完美地作为 Spine 传递 EVPN 路由。
2. cEOS 镜像导入指令
- 注册账号: 访问 Arista 软件下载页面。使用个人或公司邮箱注册,注册通常是自动批准的。
- 寻找镜像: 登录后,在目录中寻找:
Software Download->EOS->cEOS-lab->最新版本 (如 4.31.x 或 4.32.x)。 - 下载文件: 下载名为
cEOS64-lab-4.xx.xF.tar.xz的文件。 - 导入 Ubuntu: 将文件上传到 Ubuntu 虚拟机后,执行导入命令:
# 假设你下载的文件名为 cEOS64-lab-4.35.1F.tar.xz
docker import cEOS64-lab-4.35.1F.tar.xz ceos:4.35.1F二、 声明式拓扑:Containerlab 的“基础设施即代码”
在 Containerlab 的哲学中,拓扑不仅是连线,更是可审计的代码。通过 YAML 文件,我们可以定义一个典型的双核心(Spine)双接入(Leaf)拓扑。
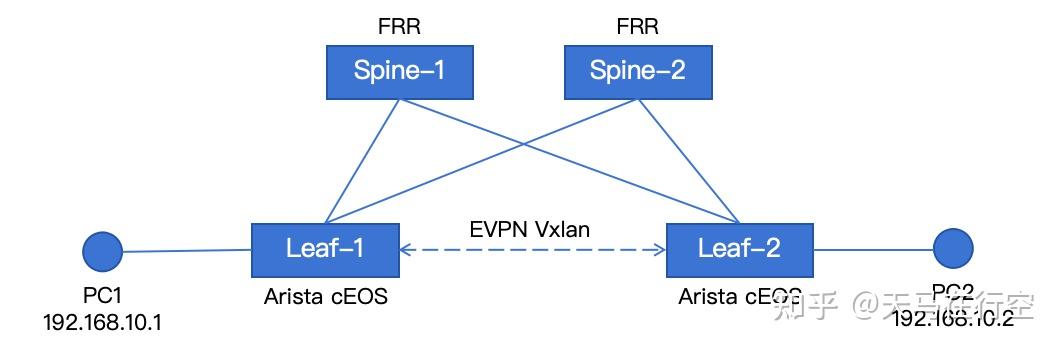
声明式定义:evpn-lab.clab.yml
name: evpn-week2
topology:
nodes:
# 交换机节点
spine1: { kind: linux, image: frrouting/frr:latest, binds: ["./clab-evpn-week2/spine1:/etc/frr"] }
spine2: { kind: linux, image: frrouting/frr:latest, binds: ["./clab-evpn-week2/spine1:/etc/frr"] }
# 定义 Leaf
leaf1: { kind: arista_ceos, image: ceos:4.35.1F }
leaf2: { kind: arista_ceos, image: ceos:4.35.1F }
# 测试主机(模拟连接在交换机下的业务服务器)
pc1: { kind: linux, image: alpine:latest, exec: ["apk add --no-cache iproute2"] }
pc2: { kind: linux, image: alpine:latest, exec: ["apk add --no-cache iproute2"] }
links:
# Leaf1 连接到 Spine1 和 Spine2
- endpoints: ["leaf1:eth1", "spine1:eth1"]
- endpoints: ["leaf1:eth2", "spine2:eth1"]
# Leaf2 连接到 Spine1 和 Spine2
- endpoints: ["leaf2:eth1", "spine1:eth2"]
- endpoints: ["leaf2:eth2", "spine2:eth2"]
# 测试主机连接到 Leaf
- endpoints: ["pc1:eth1", "leaf1:eth3"]
- endpoints: ["pc2:eth1", "leaf2:eth3"]这里细心的朋友会观察到,在spine路由器上,我bind了初始配置文件。这是为什么呢?在 Containerlab 的世界里,配置即声明。初学者最易陷入的第一个陷阱,便是试图在容器运行后通过 docker restart 来加载协议进程。
【核心坑位】:为了使能BGP 功能在FRR上,我需要修改 FRR 的 /etc/frr/daemons 文件(如开启 bgp=yes)并习惯性地执行 docker restart,你会发现交换机瞬间沦为“光杆司令”——所有 Ethernet 接口都会消失。这是因为 clab 的接口注入是单次触发的,原生重启无法重构链路编排。当重启某个docker路由器时,相关的link将被破坏。
【解决方案】:为了打破“修改配置需重启进程,而重启容器又会导致物理网卡丢失”的死锁难题,我们采用了“配置预注入”的策略:在宿主机建立 spine 配置目录,提前将修改好 bgp=yes 的 daemons 文件与 frr.conf(空文件) 放入其中,随后通过 Containerlab 的 binds 指令建立宿主机与容器间的文件映射锚点。这种“部署即就绪”的声明式运维方法,使得 FRR 节点在启动瞬间便能加载完整的 BGP EVPN 协议栈,不仅优雅地绕过了接口丢失的隐患,更确保了实验环境的幂等性与一致性。
操作配置(YAML 片段):

通过 sudo clab deploy -t evpn-lab.clab.yml,一套复杂的 Fabric 环境在秒级内即可在后台静默拉起。
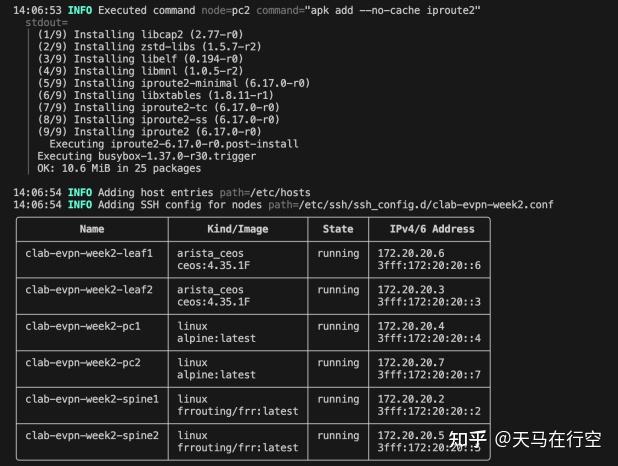
网络拓扑部署成功记录
三、 进阶实战:从 Underlay 到 Overlay 的逻辑跃迁
1. Underlay:Loopback 的互联互通
底层网络(Underlay)的任务是确保所有 VTEP 的 Loopback0 地址能够通过 eBGP 互相学习。这是 VXLAN 隧道建立的物理底座。
Leaf-1 配置举例:
interface Ethernet1
no switchport
ip address 10.0.1.2/30
!
interface Ethernet2
no switchport
ip address 10.0.2.2/30
!
interface Loopback0
ip address 2.2.2.1/32
!
router bgp 65001
router-id 2.2.2.1
neighbor 10.0.1.1 remote-as 65000
neighbor 10.0.1.1 send-community extended
neighbor 10.0.2.1 remote-as 65000
neighbor 10.0.2.1 send-community extended #使能发送extended community,携带vni等信息
network 2.2.2.1/32
!
address-family ipv4
neighbor 10.0.1.1 activate
neighbor 10.0.2.1 activate
network 2.2.2.1/32 # 发布 Loopback 地址,作为 VTEP SourceSpine-1配置举例
interface eth1
description to-leaf1
ip address 10.0.1.1/30
exit
!
interface eth2
description to-leaf2
ip address 10.0.3.1/30
exit
!
interface lo
ip address 1.1.1.1/32
exit
!
router bgp 65000
bgp router-id 1.1.1.1
no bgp ebgp-requires-policy
neighbor 10.0.1.2 remote-as 65001
neighbor 10.0.1.2 description LEAF1
neighbor 10.0.3.2 remote-as 65002
neighbor 10.0.3.2 description LEAF2
!
address-family ipv4 unicast
network 1.1.1.1/32
exit-address-family- 验证点:在 Leaf1 上执行
show ip route,必须看到远端 Leaf 的 Loopback 地址且状态为 BGP。
leaf1#show ip route 2.2.2.2
VRF: default
......
B E 2.2.2.2/32 [200/0]
via 10.0.1.1, Ethernet12. Overlay:EVPN 的“灵魂”注入
真正的魔法始于 address-family evpn。在 Leaf 侧,我们需要建立通往 Spine 的 EVPN 邻居关系,并配置 VNI 映射。在 Overlay 配置中,我们将 VLAN 10 映射到 VNI 10010。
Leaf-1配置举例:
! 定义 VLAN 与 VNI 的绑定
vlan 10
vxlan vni 10010
!
interface Ethernet3
description link-to-pc1
switchport access vlan 10
!
interface Vxlan1
vxlan source-interface Loopback0
vxlan udp-port 4789
vxlan vlan 10 vni 10010
!
router bgp 65001
vlan 10
rd 2.2.2.1:10
route-target both 10:10
redistribute learned
!
address-family evpn
neighbor 10.0.1.1 activate
# 异构组网的关键:显式声明封装类型
neighbor 10.0.1.1 encapsulation vxlan
neighbor 10.0.2.1 activate
neighbor 10.0.2.1 encapsulation vxlan 而在 FRR Spine 上,它的使命是做一个纯粹的信使,不加干涉地反射所有 Type-2(MAC-IP)与 Type-3(IMET)路由。
router bgp 65000
address-family l2vpn evpn
neighbor 10.0.1.2 activate
neighbor 10.0.3.2 activate
exit-address-family- 关键修正:为了解决跨厂商或 eBGP 环境下的属性丢失问题,必须在 Leaf 上的 BGP EVPN 邻居下配置
encapsulation vxlan。这相当于为路由加上了一张“封装入场券”。
Overlay 的成功并非偶然,它是一场控制面路由与数据面封装的完美共振。为了证明实验逻辑的严密性,我们需要从以下三个维度提取“证据”。
(1) 控制面的“选票”:BGP EVPN 路由的准入
首先要确认 Leaf 节点是否不仅“收到了”路由,而且将其视作“最优”。
- 关键 Log 命令:
show bgp evpn route-type imet detail
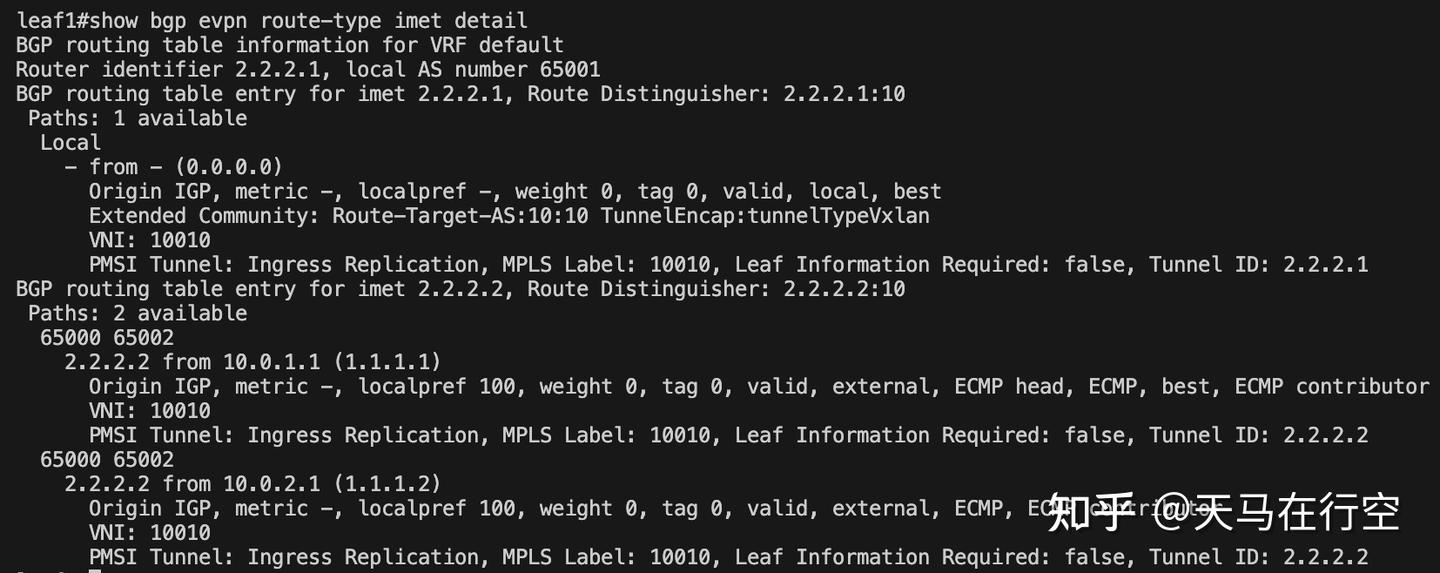
- 验证要点:
- Status:必须出现
valid, external, best。如果不是best,隧道将无法建立。 - VNI:确认 VNI 为
10010。 - Encap:在异构组网中,确认其是否带有
TunnelEncap:vxlan属性(或通过我们强制配置的encapsulation vxlan生效)。
- Status:必须出现
看到 best 这个词,意味着控制面已经投出了赞成票,VTEP 发现过程即将开启。
(2) 桥梁的落成:VTEP 自动发现与洪泛列表
IMET(Type-3)路由的意义在于构建“复制列表”,这是 Overlay 处理广播、组播和未知单播(BUM)的基础。
- 关键 Log 命令:
show vxlan flood vtep

- 验证要点:
- 输出中必须出现对端 Leaf 的 Loopback 地址(例如
2.2.2.2)。 - 状态:确保其位于特定的 VNI 映射下。
- 输出中必须出现对端 Leaf 的 Loopback 地址(例如
如果这里是空的,说明隧道只是“纸上谈兵”,数据包根本找不到对岸的港口。
(3) 身份的同步:MAC 地址表的远程映射
最直观的证据在于,Leaf1 必须通过 EVPN 学习到远端 PC2 的 MAC 地址。
- 关键 Log 命令:
show bgp evpn route-type mac-ip
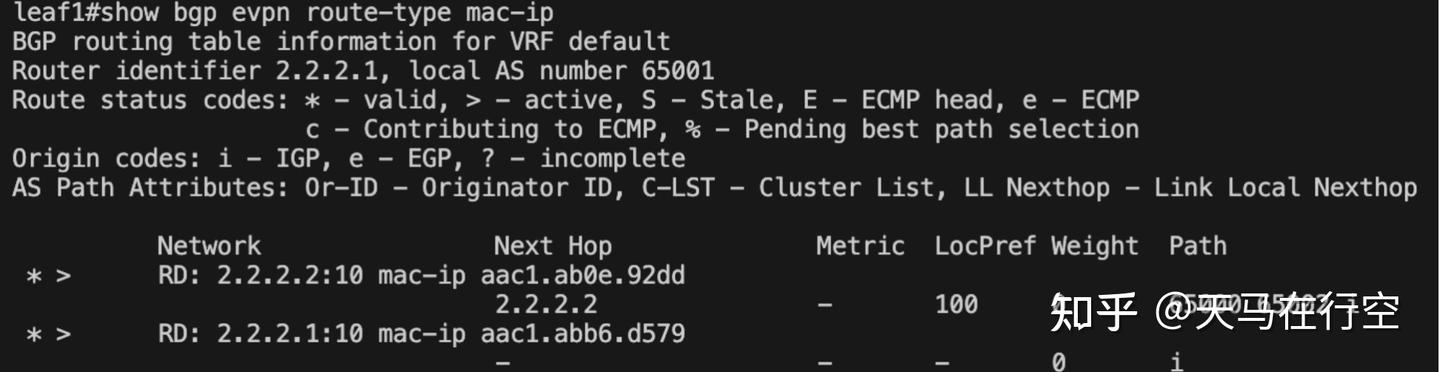
- 验证要点:
- EVPN mac-ip 表需要打印出local和remote学到的两个MAC 地址表项。
当 MAC 地址打印在EVPN mac-ip表,意味着二层网络已经在三层架构之上完成了“灵魂抽离”,两台 PC 仿佛置身于同一台交换机下。
3. 见证:数据平面的华丽蜕变
当控制平面的 BGP 状态机趋于稳态,Leaf 节点的 MAC 地址表将不再仅仅局限于物理链路,而是跨越虚拟隧道实现动态同步。
终端接入
为两台模拟 PC 赋予身份(IP 地址),并唤醒它们的二层接口:
# 在 PC1 上执行
lab@clab-vm:~$ docker exec -it clab-evpn-week2-pc1 ip addr add 192.168.10.1/24 dev eth1
# 在 PC2 上执行
lab@clab-vm:~$ docker exec -it clab-evpn-week2-pc2 ip addr add 192.168.10.2/24 dev eth1发起心跳
在 PC1 上键入 ping 192.168.10.2。这一声清脆的“心跳”,意味着 ARP 请求正以 BGP Type-3 路由的形式通过 Spine 反射,最终精准抵达 Leaf2。
docker exec clab-evpn-week2-pc1 ping 192.168.10.2 四、 踩坑记录与解决方案(Error & Debug)
| 常见错误(Error Message) | 根本原因(Root Cause) | 解决方案(Solution) |
ERRO... failed to Statfs "/proc/0/ns/net" |
上次销毁实验不彻底或 PID 丢失 | 执行 sudo clab destroy -t lab.yml --cleanup 强制清理残留命名空间 |
docker restart 后 Ethernet 接口消失 |
Clab 链路注入是单次行为,原生重启无法重构 veth pair | 禁止原生重启。使用 clab deploy --reconfigure 或通过 binds 预挂载配置 |
show vxlan address-table 结果为空 |
cEOS 转发下放特性:内核接管转发,CLI 视图不回流 | 降维打击。进入 Bash 执行 bridge fdb show 或直接通过抓包验证数据面 |
tcpdump: ... No such device exists |
接口处于独立 Network Namespace,宿主机无法直接嗅探 | 使用 nsenter 潜入容器的网络空间进行嗅探(见下文) |
五、 真相之光:利用 nsenter 洞悉 VXLAN 封装
当 CLI 命令在转发面显示滞后时,抓包是唯一通往真相的路径。
执行内核级抓包
由于 Containerlab 的接口被隔离在 NetNS 中,我们需要通过 nsenter 穿透“时空墙”。
# 第一步:获取 Leaf1 的 PID
PID=$(docker inspect -f '{{.State.Pid}}' clab-evpn-week2-leaf1)
# 第二步:潜入容器命名空间,捕获 UDP 4789 端口报文
sudo nsenter -t $PID -n tcpdump -i eth1 -nvv port 4789 -w /tmp/evpn_vxlan.pcap报文解构:
当我们将生成的 .pcap 文件拖入 Wireshark,那一层层精致的“俄罗斯套娃”式封装将跃然纸上:
- 最外层 (Outer IP):源目地址分别为 Leaf1 与 Leaf2 的 VTEP IP。
- UDP 端口:那个标志性的 4789,宣告着 VXLAN 的统领地位。
- VXLAN 头部:在保留位之后,VNI: 10010 的字样如勋章般闪耀。
- 内层载荷 (Inner Ethernet):剥开重重外壳,露出的正是 PC1 发往 PC2 的原始 ICMP 报文。

💡 总结与感悟
这次练习不仅是 EVPN VXLAN 的打通,更是对云原生网络基础设施的一次深情俯瞰。在 cEOS 极致的控转分离架构下,有时 show 命令的缺失并不代表失败,而是数据面已在更深层的内核空间里稳健运行。掌控感,源于你对每一个字节去向的了然于胸。
🎁 资源回馈
感谢各位读者的阅读!如果你在搭建过程中遇到任何奇葩报错,欢迎在评论区留言交流。
让我们在数字孪生的路上一同筑路前行!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 28
28 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)