GPU虚拟化技术(核心目标、主流技术路径、关键技术等)
选择GPU虚拟化方案,本质上是根据场景在性能、隔离性、灵活性、成本追求极致性能与完整功能,且不介意独占 →GPU直通。需要在多用户间安全共享,且要求接近原生性能 →API转发(vGPU/MIG)。需要极致的灵活性、动态调度和云原生集成,可接受一定的性能损失 →全虚拟化或先进的容器化方案。对于大多数企业级AI云平台和虚拟桌面基础设施而言,以NVIDIA vGPU/MIG为代表的API转发模式是目前公
GPU虚拟化技术是一项核心基础设施技术,它允许将物理GPU的计算能力安全、高效地分割并分配给多个虚拟机或容器,从而在云平台、数据中心和虚拟桌面等场景中实现GPU资源的灵活共享与隔离。
要全面理解这项技术,我们可以从目标与挑战、三大主流技术路径、以及关键考量这几个维度来深入解析。
一、 GPU虚拟化的核心目标与独特挑战
其核心目标是解决一对矛盾:GPU的高价值、稀缺性与用户对算力灵活、隔离、弹性的需求。
-
挑战根源:GPU并非为多租户共享而生。它与操作系统和驱动深度绑定,拥有独立的显存空间和复杂的命令队列。传统的CPU虚拟化技术(如Intel VT-x)无法直接套用。
二、 三大主流技术路径详解
根据虚拟化层介入的深度和位置,主要分为以下三类,其工作原理和特性对比如下:
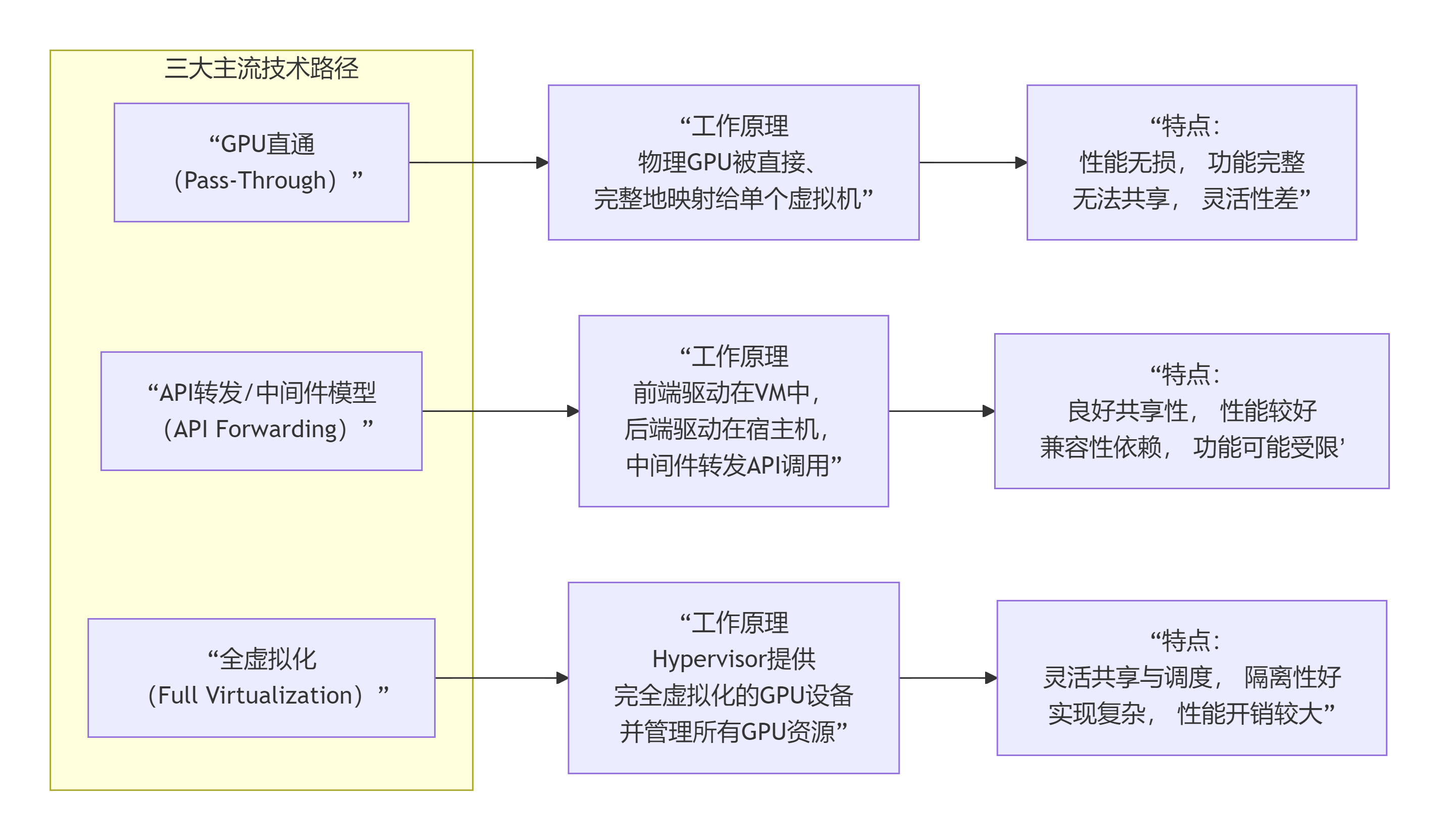
路径1:GPU直通
这是最直接、性能无损的方式,但牺牲了共享能力。
-
工作流程:
-
分配:管理员将整块物理GPU通过PCIe Passthrough技术直接挂载给一个特定的虚拟机。
-
接管:该虚拟机获得GPU的完全控制权,安装原生驱动程序,就像独占一台物理主机。
-
隔离:其他虚拟机无法感知或访问此GPU。
-
-
优势:零性能损耗,支持所有GPU功能。
-
劣势:“一卡一机”,GPU资源无法被多个租户共享,利用率可能低下。
-
典型应用:对性能有极致要求的高性能计算任务、专业图形工作站。
路径2:API转发(半虚拟化)
这是目前应用最广泛、最成熟的共享方案,在性能与灵活性间取得了最佳平衡。
-
工作流程:
-
前后端分离:在虚拟机中安装一个精简的前端驱动,在宿主机上运行完整的后端驱动。
-
拦截与转发:前端驱动拦截虚拟机内的图形或计算API调用(如DirectX, OpenGL, CUDA),通过一个高效的通信通道(通常是共享内存)转发给后端驱动。
-
执行与返回:后端驱动在物理GPU上执行这些命令,并将结果通过同一通道返回给虚拟机。
-
-
优势:
-
良好的资源共享:一块物理GPU可以同时服务多个虚拟机。
-
接近原生的性能:通信开销很小,尤其对于计算密集型任务。
-
强隔离性:每个虚拟机的GPU上下文独立,互不干扰。
-
-
劣势:依赖于特定的驱动程序和Hypervisor支持,新功能支持可能存在延迟。
-
行业标杆:NVIDIA GRID vGPU 和 vComputeServer 是该模式的典范。它们将物理GPU划分为多个逻辑的
vGPU实例,每个实例具有固定的显存和计算核心配额,并拥有独立的驱动程序,提供给虚拟机使用。
路径3:全虚拟化
这是最灵活但也最复杂的模式,提供了完全的软件定义能力。
-
工作流程:Hypervisor模拟出一个标准的虚拟GPU设备(如VirtIO-GPU)。虚拟机使用通用的驱动程序与此虚拟设备通信。Hypervisor负责接收所有命令,进行调度、资源管理,并最终映射到物理GPU上执行。
-
优势:
-
极高的灵活性:虚拟GPU的型号与物理GPU解耦,便于迁移和管理。
-
细粒度调度:可在时间片层面进行调度,实现更精细的QoS控制。
-
-
劣势:实现极其复杂,且由于软件模拟层较厚,性能开销通常最大。
-
代表技术:开源方案如 Intel GV-GPU,以及商业云服务商自研的虚拟化方案。
三、 关键技术考量与发展趋势
-
GPU资源切分粒度:
-
时间片切分:多个虚拟机分时共享GPU计算核心,适用于工作负载波动大的场景。
-
空间切分:将GPU的流多处理器和显存进行物理分区,实现更稳定的性能隔离。NVIDIA Ampere架构及之后GPU支持的MIG技术是空间切分的巅峰,能将一块A100/H100 GPU最多划分为7个完全隔离、具备独立内存和缓存的计算实例。
-
-
容器化与云原生集成:
-
以Kubernetes为代表的容器编排平台已成为AI算力的标准操作平台。GPU虚拟化技术通过与K8s设备插件集成,实现了容器级别的GPU共享和调度。NVIDIA的Kubernetes Device Plugin 和 NVIDIA Container Toolkit 是这一领域的标准。
-
-
挑战与未来:
-
主要挑战:性能开销、功能完整性(新API、新硬件的支持速度)、许可与成本(如NVIDIA vGPU软件的许可费用不菲)。
-
发展趋势:硬件辅助虚拟化(如SR-IOV)将虚拟化逻辑下沉到GPU硬件本身,以进一步降低开销。同时,异构计算虚拟化(GPU与CPU、DPU协同)和支持更复杂的多任务调度是重要方向。
-
总结:如何选择?
选择GPU虚拟化方案,本质上是根据场景在 性能、隔离性、灵活性、成本 之间做权衡:
-
追求极致性能与完整功能,且不介意独占 → GPU直通。
-
需要在多用户间安全共享,且要求接近原生性能 → API转发(vGPU/MIG)。
-
需要极致的灵活性、动态调度和云原生集成,可接受一定的性能损失 → 全虚拟化或先进的容器化方案。
对于大多数企业级AI云平台和虚拟桌面基础设施而言,以NVIDIA vGPU/MIG为代表的API转发模式是目前公认的最佳实践,它较好地平衡了性能、隔离、管理和成本。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 22
22 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)