生成式AI大模型备案进行时:监管机制下的产业合规路径
摘要:我国AI产业正从野蛮生长转向合规化发展,大模型备案制度成为行业规范化的重要门槛。该制度通过算法压力测试和数据全生命周期监管,淘汰劣质产品,确保技术安全。备案与登记分层治理,前者面向公众应用,后者针对企业API调用。备案流程严格,需通过内容测试、敏感词拦截等多项审核,强化企业风控能力。这一过程虽提高了准入门槛,但有助于净化市场环境,为合规企业提供信用背书。
最近,全国的AI 产业布局释放出一个极其清晰的信号:AI野蛮生长的时代结束了,合规化、场景化的博弈已经开始。如果说“人工智能 +”是产业扩张的冲锋号,那么大模型备案就是悬在每一个企业心头的枷锁,它既是合规的底线,也是行业规范化的开始。
大模型的合规红线
很多初创的AI企业在面对《生成式人工智能服务管理暂行办法》时,往往只看到了罚款和停止提供服务这些惩罚性措施,但都忽略了备案背后的深层逻辑。算法背后隐藏的“黑箱”一旦失控,其破坏力远超传统互联网应用。因此,监管层的思路很明确:不是要扼杀技术创新,而是要通过备案制度对算法进行“压力测试”,使其能被掌握变得更加安全。
为什么这么说?因为大模型不再是简单的工具,它具备了舆论导向和社会动员的能力。这种能力一旦失控,在数据隐私泄露或意识形态偏差上出现哪怕微小的差错,都可能引发巨大的社会隐患。因此,备案制度的本质,是通过高标准的技术门槛,强行淘汰那些只会投机取巧、毫无风控能力的劣质产品。
这种压力测试直接体现在数据安全与社会舆论安全的维度上。大模型的训练数据是基础,若其中混杂着隐私泄露或意识形态风险,那么催生出的算法模型就会变成“慢性毒药”,不知道什么时候会被爆发出来。所以备案制度强制要求企业建立数据全生命周期的监管机制,实际上是在逼企业构建底层的安全护栏。但对于那些只想靠套壳赚快钱的团队来说,这道门槛高得足以让他们知难而退;而对于真正有技术积累的企业,备案号反而成了最有力的信用背书。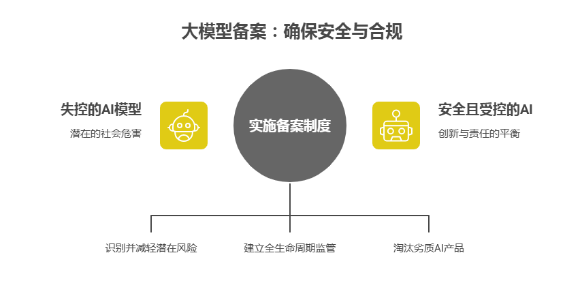
谁需要备案?谁只需登记?
在实操中,很多企业对“备案”和“登记”的边界感到模糊,但这恰恰是监管智慧的体现——分层治理,精准施策。
所谓“备案”,针对的是那些直接面向公众、具备舆论属性且直接向公众提供生成文本、图片等内容的自研大模型,比如独立的聊天机器人、内容生成平台。这些是信息的源头,必须接受最严格的审视,承担主体责任。
而“登记”,则更多面向的是企业。通过API 接口调用了已备案的通用大模型能力,来做电商客服或法律咨询。这种情况下,它不需要从头去训模型,但需要对自己的应用场景进行登记,确保不滥用接口。这就像盖楼,地基就是大模型必须经过国家的验收,而装修就是第三方应用则需要报备调整后的模样,确保不破坏整体。
大模型备案流程
如果你以为备案只是填几张表、交几份文件,那就大错特错了。从目前国家对备案执行标准来看,这更像是一场针对大模型全方面的检查和测试,检验其是否对社会有不良导向。
企业申请大模型备案,需要先向当地的网信部门去报备申请,经当地的网信部门审核企业资质合规后,企业会得到一份备案表。接下来企业需要结合当地要求准备填写附件材料,一般需要《附件1:安全评估报告》、《附件2:模型服务协议》、《附件3:语料标准规则》、《附件4:拦截关键词列表》、《附件5:评估测试题》,有些地区还需要《附件6开源语料相关说明材料》和《附件7语料采集记录表》。
属地初审的审核标准非常具体且硬核:你需要准备2000 道生成题去测试证明模型产出的是有价值的内容;还需要500 道拒答题,证明它面对诱导时能“守口如瓶”,对违规内容解决回答;还要500 道非拒答题来测试它对敏感话题的“分寸感”,不能所有问题都不回答且要符合社会核心价值观。这一步测试调试模型的环节中最让企业头疼的是网信部门要求正常内容被误拦截的概率必须极低。
此外,对于那个不少于10000 个词条的拦截关键词库,也不是一成不变的。它要求企业具备实时更新能力,以应对网络黑话、变体字等层出不穷的风险。从材料准备到属地审核,再到中央网信办的复审,每一个环节都在筛选掉那些风控能力薄弱的玩家。这个过程虽然痛苦,但客观上确实净化了市场环境,让真正有安全实力的企业脱颖而出。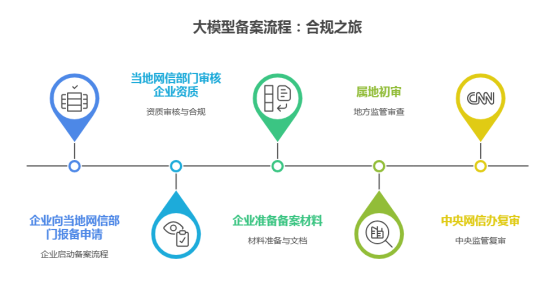
如果没有备案的规范,产品上线后可能会因为出现安全事故一夜崩塌;同样的,没有产业的落地,备案就成了无源之水。所以对于企业来说,进行备案是必选的,如果您对备案有疑问或者有需要询问的地方,欢迎随时私信留言帮助您解决问题。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 17
17 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)