【AI大模型前沿】InfinityStar:字节跳动推出的高效视频生成模型,开启视频创作新纪元
InfinityStar是由字节跳动(FoundationVision)推出的一款高效视频生成模型。它通过统一的时空自回归框架,实现了高分辨率图像和动态视频的快速合成。该模型采用纯离散方法,将视频分解为序列片段,有效解耦外观和动态信息,从而提升生成效率。InfinityStar不仅支持文本到图像、文本到视频等多种生成任务,还能在单GPU上实现分钟级生成720p视频,是视频生成领域的重要进展。
系列篇章💥
目录
前言
在人工智能技术飞速发展的今天,视频生成领域正经历着前所未有的变革。字节跳动(FoundationVision)推出的InfinityStar模型,凭借其创新的统一时空自回归框架,为高分辨率图像和动态视频的快速合成提供了全新的解决方案。这一技术不仅显著提升了生成效率,还为内容创作、虚拟现实等多个领域带来了新的可能性。
一、项目概述
InfinityStar是由字节跳动(FoundationVision)推出的一款高效视频生成模型。它通过统一的时空自回归框架,实现了高分辨率图像和动态视频的快速合成。该模型采用纯离散方法,将视频分解为序列片段,有效解耦外观和动态信息,从而提升生成效率。InfinityStar不仅支持文本到图像、文本到视频等多种生成任务,还能在单GPU上实现分钟级生成720p视频,是视频生成领域的重要进展。
二、核心功能
(一)高分辨率图像生成
InfinityStar能够生成高质量的高分辨率图像,支持720p视频的快速合成。其独特的时空金字塔结构,通过分解视频为序列片段,有效解耦外观和动态信息,从而实现高分辨率图像的高效生成。这使得模型在生成复杂场景时,能够保持细节和连贯性,满足多样化需求。
(二)动态视频合成
该模型具备强大的动态视频合成能力,能够快速生成流畅、逼真的动态视频。通过高效的时空建模,InfinityStar在生成5秒720p视频时仅需58秒,速度远超传统扩散模型。这种高效的生成能力,使其在视频创作和编辑、动画制作等领域具有显著优势。
(三)统一的时空自回归框架
InfinityStar采用统一的时空自回归框架,将图像和视频生成整合到同一个模型架构中。这种设计不仅支持文本到图像、文本到视频等多种生成任务,还通过解耦静态外观和动态运动信息,提升了生成内容的质量和连贯性。这种统一的框架,为多任务生成提供了强大的支持。
(四)高效生成能力
在生成效率方面,InfinityStar表现出色。与传统扩散模型相比,其生成5秒720p视频的速度快了约10倍。这种高效的生成能力,得益于其优化的架构设计,使其能够在短时间内完成高质量的视频生成,显著提升了生成效率。
(五)多任务支持
InfinityStar支持多种生成任务,包括文本到图像、文本到视频、图像到视频以及交互式视频生成。这种多任务支持,使得模型能够满足不同场景下的多样化需求,从广告制作到虚拟现实,从教育到社交媒体,都能发挥重要作用。
(六)知识继承策略
基于预训练的变分自编码器(VAE)构建,InfinityStar采用了知识继承策略。这种策略通过继承预训练模型的知识,大幅缩短了训练时间,降低了计算资源消耗。这不仅提高了模型的训练效率,还使其能够快速适应不同的生成任务。
三、技术揭秘
(一)时空金字塔结构
通过将视频分解为序列片段,将空间尺度与时间维度进行显式分离。这种架构使模型能够更精准地区分静态外观特征和动态运动信息,从而显著提升生成内容的质量与连贯性。
(二)高效的视觉分词器
训练了一个基于多尺度残差量化的视觉分词器,并提出了知识继承和随机量化器深度两项关键技术。知识继承策略通过继承一个已预训练的连续视觉分词器的结构和权重,显著加快离散分词器的收敛速度。随机量化器深度则通过在训练时随机丢弃后面精细尺度的Token,迫使模型在仅有前面粗糙尺度Token的情况下也能重建出有意义的信息,从而提升模型的学习效率和最终的生成质量。
(三)优化的时空自回归Transformer
为应对视频生成带来的新挑战,InfinityStar对自回归Transformer进行了多项关键改进。语义尺度重复技术通过重复预测金字塔中靠前的几个语义尺度,强化了模型对视频全局信息的建模能力,极大地增强了生成视频在结构上的一致性和运动的流畅性。时空稀疏注意力机制则通过只关注必要的上下文信息,大大降低了注意力的计算复杂度,使得高质量、长上下文的视频生成成为可能。此外,时空RoPE位置编码通过同时编码尺度、时间、高度和宽度信息,为Transformer提供了精确的时空坐标感。
(四)知识继承策略
基于预训练的变分自编码器(VAE)构建,利用知识继承策略,大幅缩短训练时间并降低计算资源消耗。
四、性能表现
在VBench基准测试中,InfinityStar取得了83.74的高分,大幅领先于其他自回归模型,甚至超过了部分扩散模型。与传统扩散模型相比,InfinityStar在生成5秒720p视频时的速度快了约10倍,显著提升了生成效率。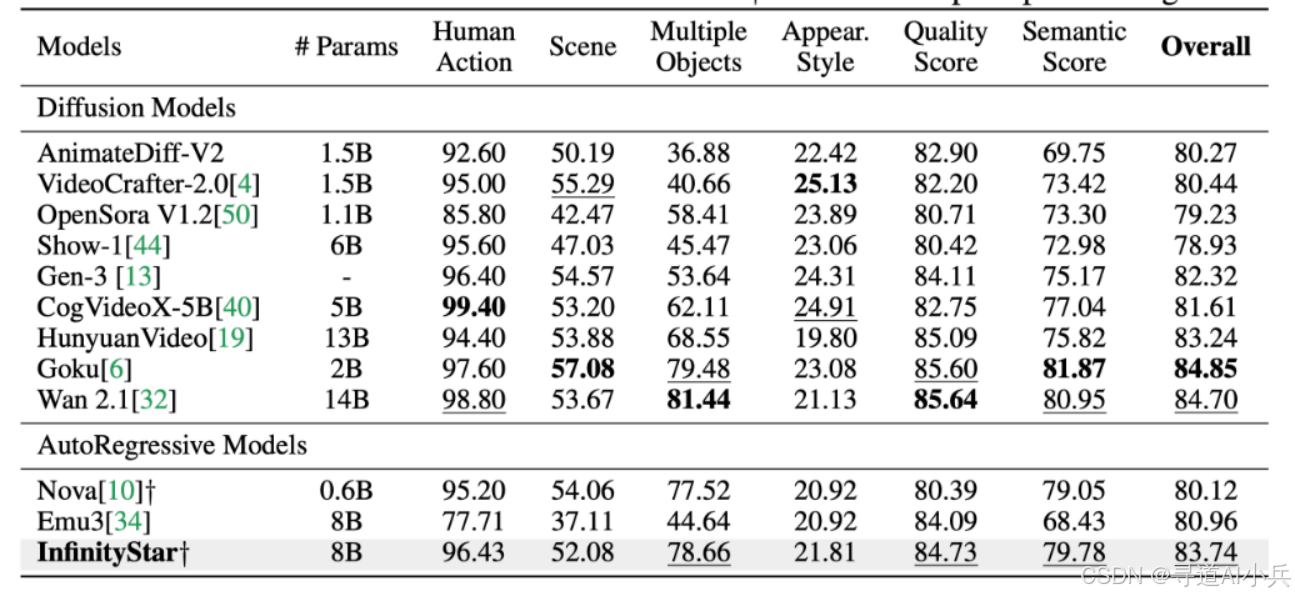
五、应用场景
(一)内容创作与媒体生产
InfinityStar能够快速生成高质量的视频素材,适用于影视后期、广告制作和短视频创作等领域。其高效的生成能力显著提升了创作效率,使创作者能够在短时间内生成大量高质量的视频内容。无论是复杂的特效场景还是日常的广告视频,InfinityStar都能提供强大的支持,帮助创作者实现创意。
(二)虚拟现实与游戏开发
在虚拟现实(VR)和游戏开发中,InfinityStar可以生成逼真的虚拟场景和角色动画。其动态视频合成能力,能够为VR和游戏提供丰富的交互体验。通过快速生成高质量的动画,开发者可以更高效地构建沉浸式环境,提升用户体验。
(三)计算机视觉研究
作为基准模型或工具,InfinityStar推动了视频生成、预测及理解等领域的研究。其统一的时空自回归框架,为研究人员提供了强大的研究平台。通过高效生成高质量视频,研究人员可以探索新的算法和模型,推动计算机视觉技术的发展。
(四)数字人与虚拟偶像
InfinityStar可以驱动虚拟形象的动态表现和互动。其高效的生成能力,能够实时生成虚拟形象的动作和表情,使虚拟偶像更加生动和真实。通过与用户的交互,虚拟形象可以更好地响应用户需求,提升互动体验。
(五)动画制作
InfinityStar能够生成流畅的动画视频,降低了动画制作的成本和时间。其高效的视频生成能力,使动画创作者能够在短时间内生成高质量的动画。无论是动画电影还是广告动画,InfinityStar都能提供强大的支持,帮助创作者实现创意。
(六)教育与培训
在教育和培训领域,InfinityStar可以创建动态教学视频。通过生成与教学内容相关的动画或视频,教师可以更生动地讲解知识点,提高教学效果和学生参与度。这种动态教学方式,能够更好地吸引学生的注意力,提升学习效果。
六、快速使用
(一)安装依赖
使用FlexAttention加速训练,需要torch>=2.5.1。
安装其他依赖包:
git clone https://github.com/FoundationVision/InfinityStar.git
cd InfinityStar
pip3 install -r requirements.txt
(二)视频生成
使用tools/infer_video_720p.py生成5秒720p视频:
python3 tools/infer_video_720p.py
该脚本还支持图像到视频生成,只需指定图像路径即可。
(三)480p可变长度视频生成
提供了480p分辨率的中间检查点,能够生成5秒和10秒的视频。由于该模型未针对文本到视频(T2V)进行专门优化,建议使用实验性的图像到视频(I2V)和视频到视频(V2V)模式,以获得更好的结果。要指定视频时长,可以编辑tools/infer_video_480p.py中的generation_duration变量,将其设置为5或10。该脚本还支持图像到视频和视频续写,只需提供图像或视频的路径。
python3 tools/infer_video_480p.py
(四)480p长交互式视频生成
使用tools/infer_interact_480p.py生成480p的长交互式视频。该脚本支持交互式视频生成,可以提供参考视频和多个提示。模型将在用户的协助下生成视频。
python3 tools/infer_interact_480p.py
结语
InfinityStar作为字节跳动推出的一款高效视频生成模型,凭借其创新的统一时空自回归框架,在高分辨率图像和动态视频生成领域取得了显著的突破。它不仅在性能上超越了传统的扩散模型,还通过开源策略,为研究人员和开发者提供了强大的工具。随着技术的不断发展,InfinityStar有望在视频创作、虚拟现实、教育等多个领域发挥更大的作用,开启视频生成的新纪元。
项目地址
- GitHub仓库:https://github.com/FoundationVision/InfinityStar
- HuggingFace模型库:https://huggingface.co/FoundationVision/InfinityStar
- arXiv技术论文:https://arxiv.org/pdf/2511.04675

🎯🔖更多专栏系列文章:AI大模型提示工程完全指南、AI大模型探索之路(零基础入门)、AI大模型预训练微调进阶、AI大模型开源精选实践、AI大模型RAG应用探索实践🔥🔥🔥 其他专栏可以查看博客主页📑
😎 作者介绍:资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索(CSDN博客之星|AIGC领域优质创作者)
📖专属社群:欢迎关注【小兵的AI视界】公众号或扫描下方👇二维码,回复‘入群’ 即刻上车,获取邀请链接。
💘领取三大专属福利:1️⃣免费赠送AI+编程📚500本,2️⃣AI技术教程副业资料1套,3️⃣DeepSeek资料教程1套🔥(限前500人)
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我们,一起携手同行AI的探索之旅,开启智能时代的大门!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 5
5 0
0- 0



 已为社区贡献69条内容
已为社区贡献69条内容

所有评论(0)