【TextIn大模型加速器 + 火山引擎】让AI读懂财报:30分钟搭建企业级金融分析Agent
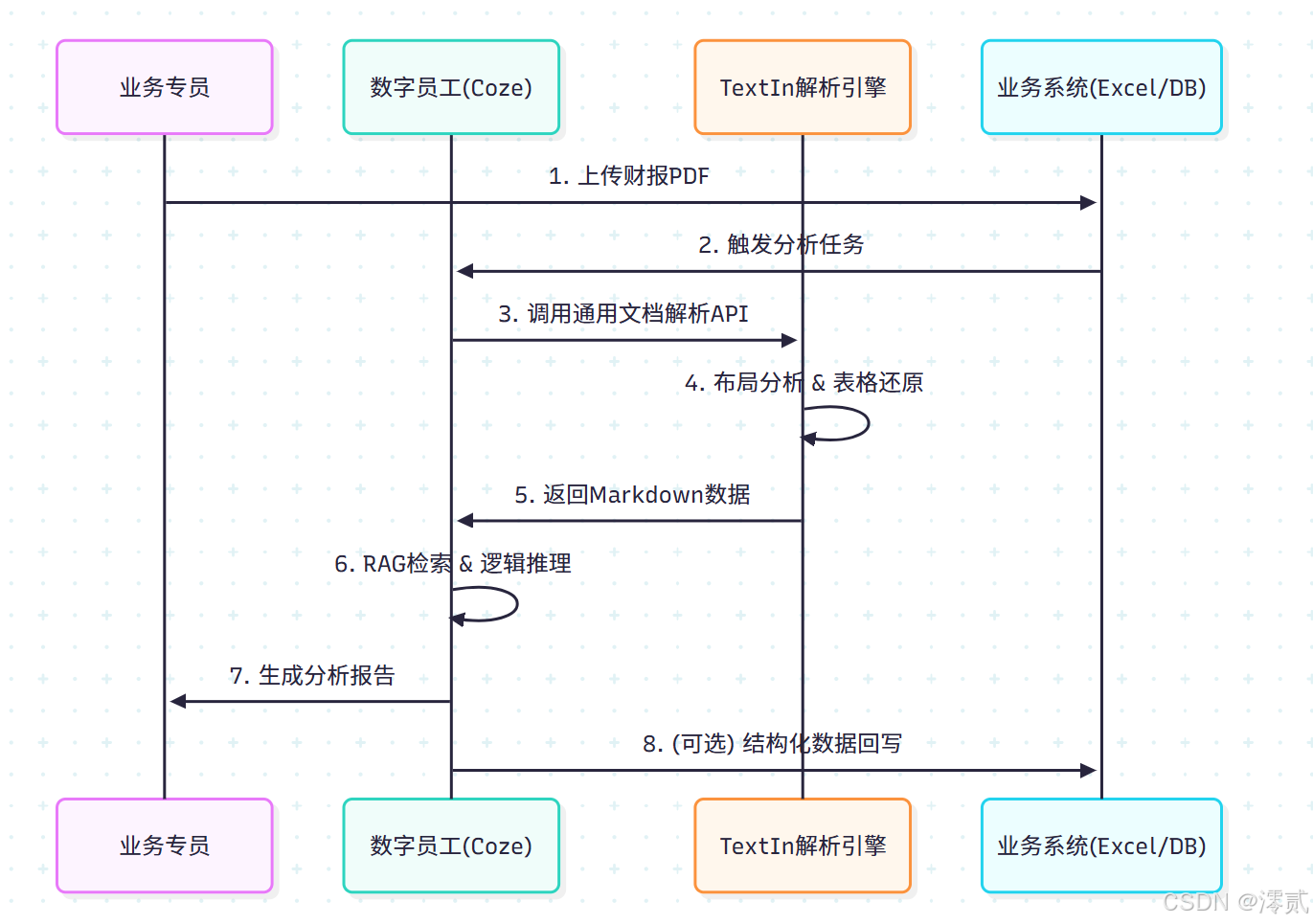
AI遇上金融数据:30分钟搭建财报分析智能体 当大模型遇到金融、法律等专业领域的PDF文档时,传统OCR技术常因跨页表格、合并单元格等问题导致解析失败。本文介绍了一种高效解决方案: 数据清洗:使用TextIn的PDF转Markdown功能,将复杂表格转化为结构化数据 智能分析:通过火山引擎Coze平台,构建具备专业分析能力的AI智能体 核心步骤: 通过Python脚本一键转换PDF为Markdow
文章目录
一、 引言:当 AI 撞上“数据高墙”
在大模型(LLM)狂飙的今天,写诗画图已是基本操作。但在金融、法律、审计等严肃场景中,当我们把一份包含跨页资产负债表的 PDF 扔给普通的 AI,问它:“这家公司去年的流动比率是多少?”
得到的回答往往是:“未找到相关数据”或者一本正经地胡说八道。
核心症结在哪里? 🤔
不是模型不够聪明,而是数据喂不进去。传统的 PDF 解析技术(OCR)在面对跨页表格、合并单元格、无线表时,读出的数据结构支离破碎。一旦表格被切片(Chunking)切碎,RAG(检索增强生成)系统就瞎了。
今天,我将带大家打破这堵墙。我们将使用 合合信息 TextIn 清洗数据,配合 火山引擎 Coze(扣子) 的最强推理大脑,让小白也能在 30 分钟内搭建一个真·能读懂复杂财报的金融分析 Agent!
二、 准备工作
在开始之前,我们需要准备两个关键工具。
1. 注册TextIn
TextIn 提供的大模型加速器(PDF转Markdown) 是本次实战的核心。它能将非结构化的 PDF 转化为 LLM 最友好的 Markdown 格式。
- 步骤:访问 TextIn合合信息开放平台 -> 登录/注册
- 关键点:点击左侧的"账号与开发者信息",找到你的
x-ti-app-id和x-ti-secret-code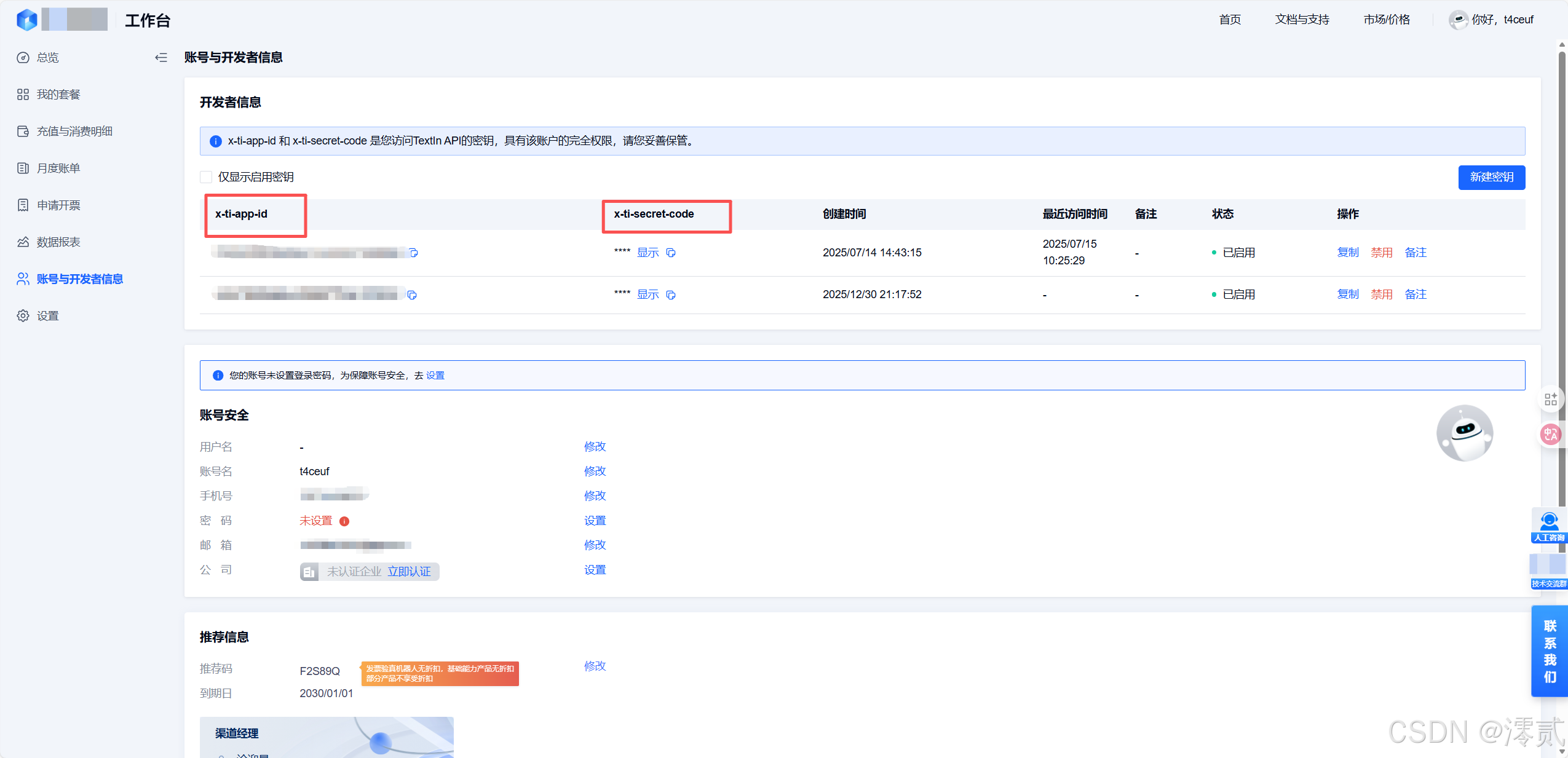
2. 注册火山引擎Coze,获取“最强大脑”
- 步骤:访问 Coze。
- 优势:
Coze提供了可视化的Agent编排能力和强大的豆包 Pro 长文本模型,无需自行部署服务器即可从零搭建应用。
三、 核心实操:构建数据清洗流水线 (ETL)
很多 RAG 教程只教你怎么传文件,却不教怎么处理文件。为了保证效果,我封装了一个 “傻瓜式”Python 脚本。你只需要填入 ID,即可一键清洗数据。
场景假设:我们有一份《某科技公司2024年第一季度财报.pdf》,里面包含复杂的财务表格。
1. 环境准备
在你的电脑上 VS Code,输入以下命令安装必要的库:
pip install requests

2. 复制并运行脚本
数据源示例:点此下载官方复杂表格示例 PDF
下载这份官方给的示例 pdf,接着新建一个文件 pdf_magic.py,将以下代码完整复制进去。
import requests
import json
import os
# ================= 配置区域 (只改这里!) =================
# 1. 把你的 TextIn ID 和 Secret 填在引号里
APP_ID = '这里填你的App_ID'
SECRET_CODE = '这里填你的Secret_Code'
# 2. 把你要解析的PDF文件名填在这里 (文件要和脚本在同一个文件夹)
PDF_FILENAME = 'report_2024.pdf'
# =======================================================
def pdf_to_markdown_smart():
print(f"🚀 开始解析: {PDF_FILENAME} ...")
url = 'https://api.textin.com/ai/service/v1/pdf_to_markdown'
headers = {
'x-ti-app-id': APP_ID,
'x-ti-secret-code': SECRET_CODE
}
# 这里的参数是关键!
# table_flavor='markdown': 强制把表格转为AI能看懂的Markdown格式
# apply_document_tree=1: 保持文章的标题层级
params = {
'markdown_details': 1,
'apply_document_tree': 1,
'table_flavor': 'markdown',
'page_details': 1
}
try:
with open(PDF_FILENAME, 'rb') as f:
image_data = f.read()
response = requests.post(url, data=image_data, headers=headers, params=params)
result = json.loads(response.text)
if result.get('code') == 200:
# 获取解析后的Markdown内容
md_content = result['result']['markdown']
# 保存为同名的 .md 文件
output_file = PDF_FILENAME.replace('.pdf', '_cleaned.md')
with open(output_file, 'w', encoding='utf-8') as f:
f.write(md_content)
print(f"✅ 成功!文件已保存为: {output_file}")
print("👉 快去打开看看,表格是不是变得超级整齐!")
else:
print(f"❌ 失败: {result.get('message')}")
except Exception as e:
print(f"❌ 发生错误: {e}")
if __name__ == '__main__':
pdf_to_markdown_smart()
注意要将你创建py文件和示例pdf文件保存在同一路径下
3. 见证奇迹
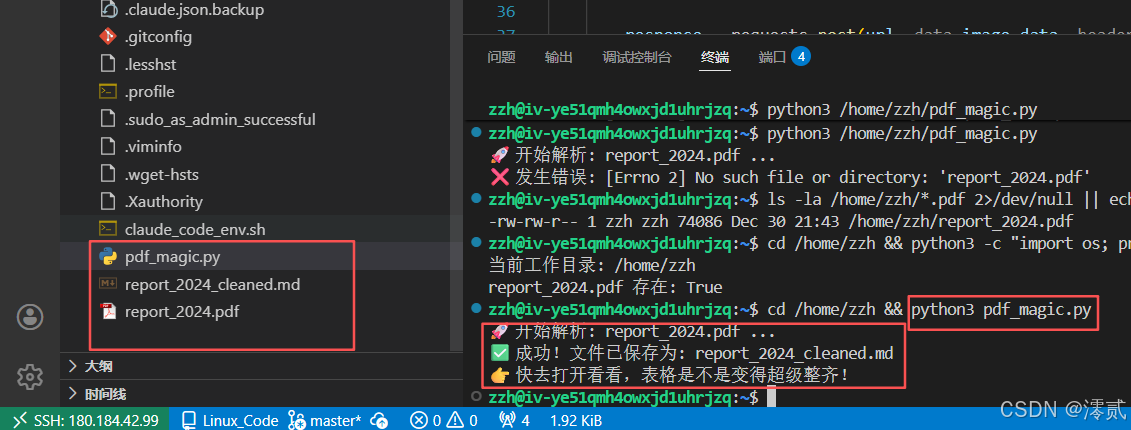
运行脚本 python3 pdf_magic.py。
打开生成的 .md 文件,你会发现原本让人头大的复杂表格,变成了整整齐齐的 Markdown 格式:
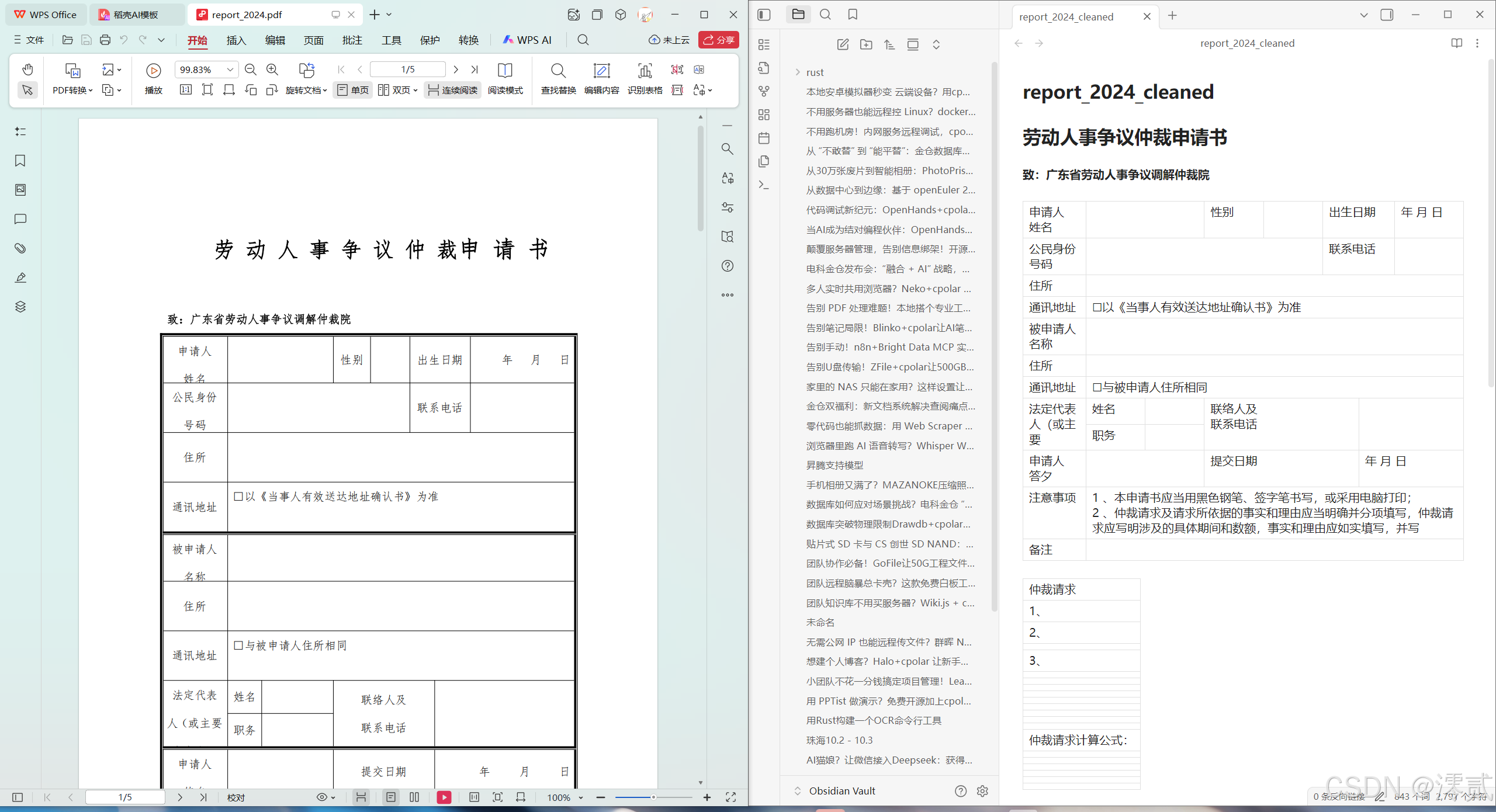
技术解析:
TextIn不仅识别了文字,还通过计算机视觉分析了版面布局,正确合并了单元格,变成AI易理解的文本格式
四、进阶实操:在 Coze 中注入“灵魂”
本方案采用 Coze 的 Single Agent 模式,通过知识库节点实现 RAG 召回链路。
数据清洗完毕,现在我们用 火山引擎 Coze 来打造这个智能体。
点击该链接去 Coze 创建智能体https://www.coze.cn/space/7431912891705933876/develop?force_stay=1
1. 创建智能体
点击左侧的创建
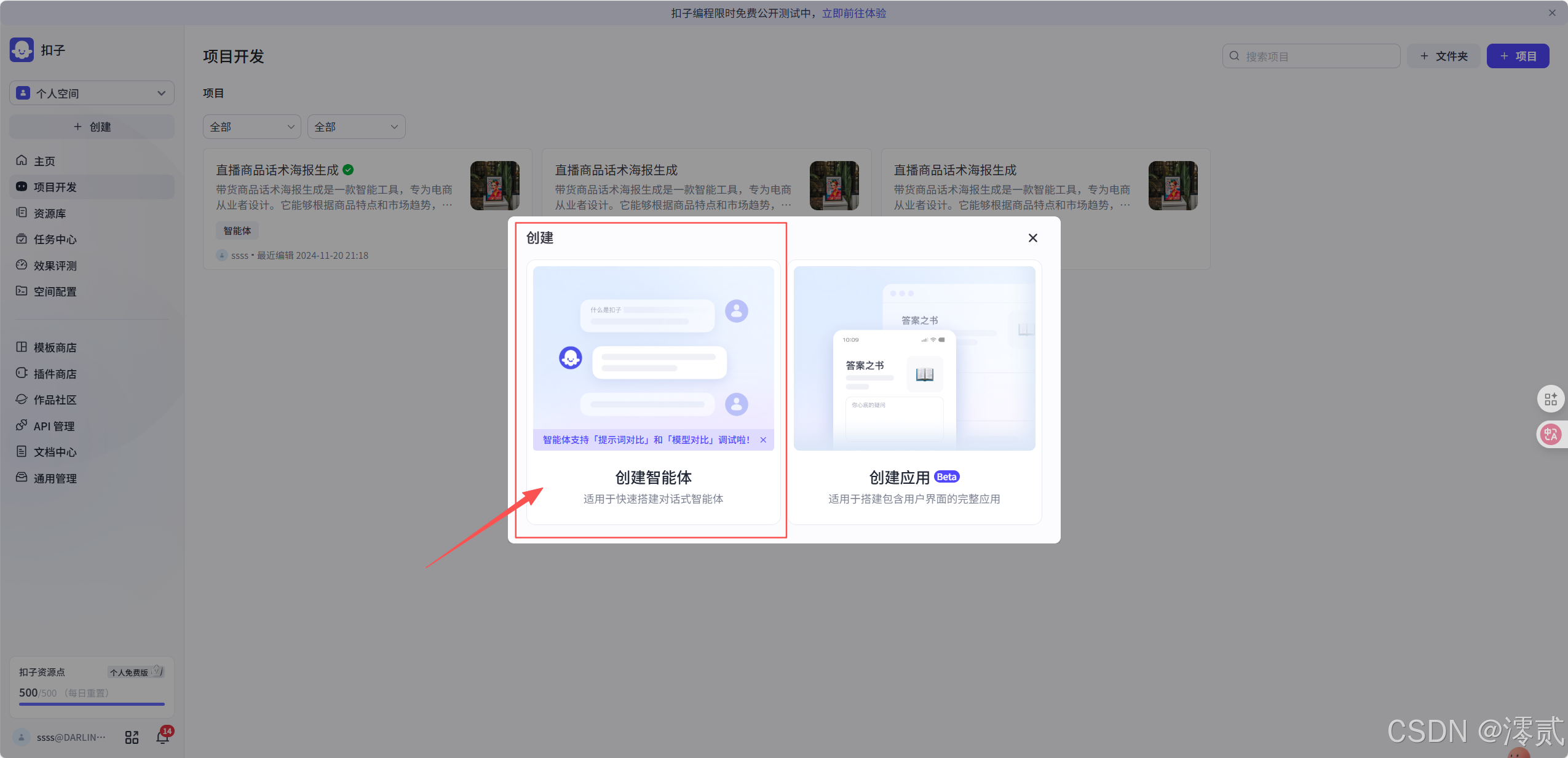
然后选择创建智能体
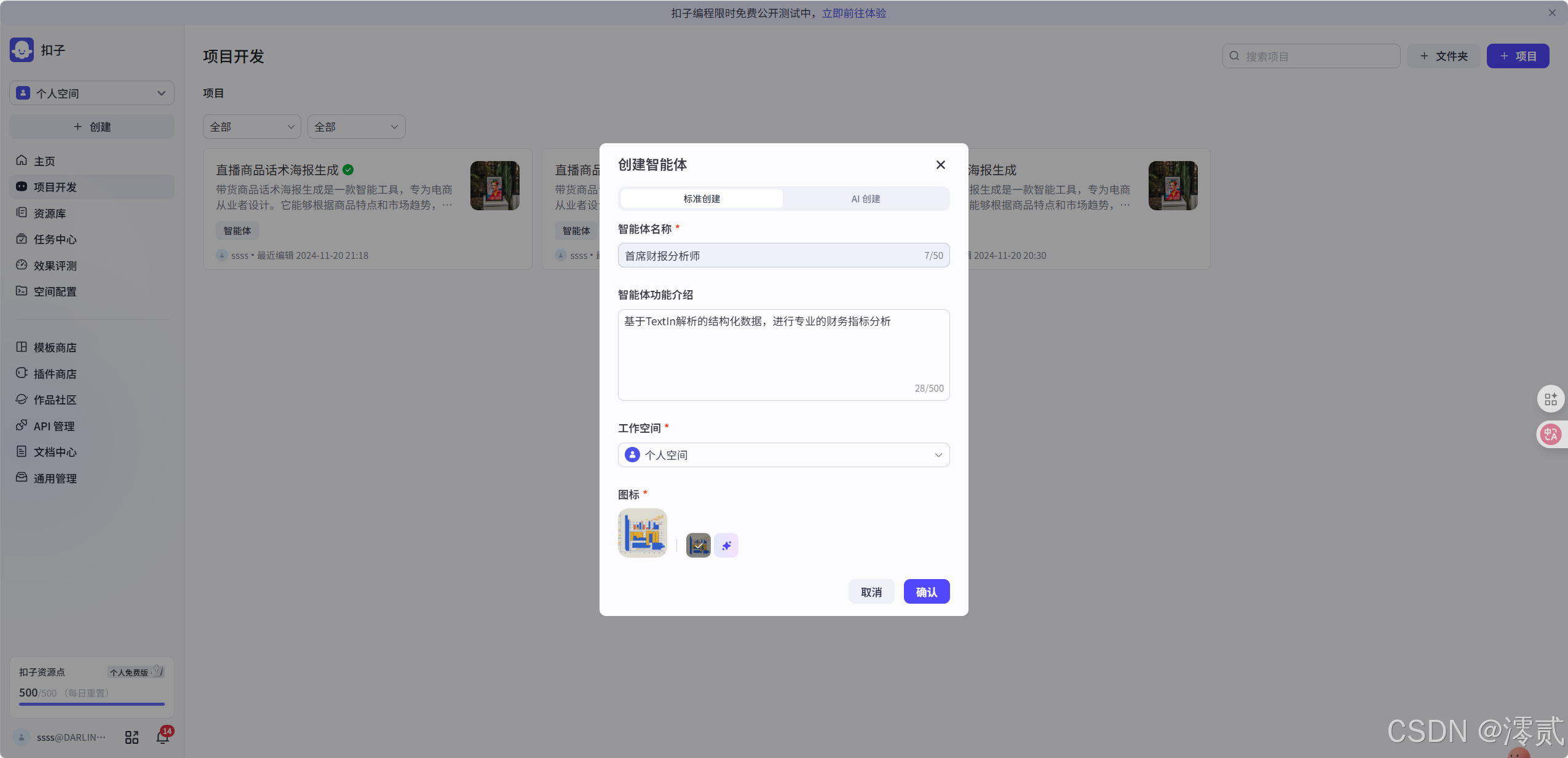
智能体名称: 首席财报分析师
功能介绍: 基于TextIn解析的结构化数据,进行专业的财务指标分析。
2. 配置智能体
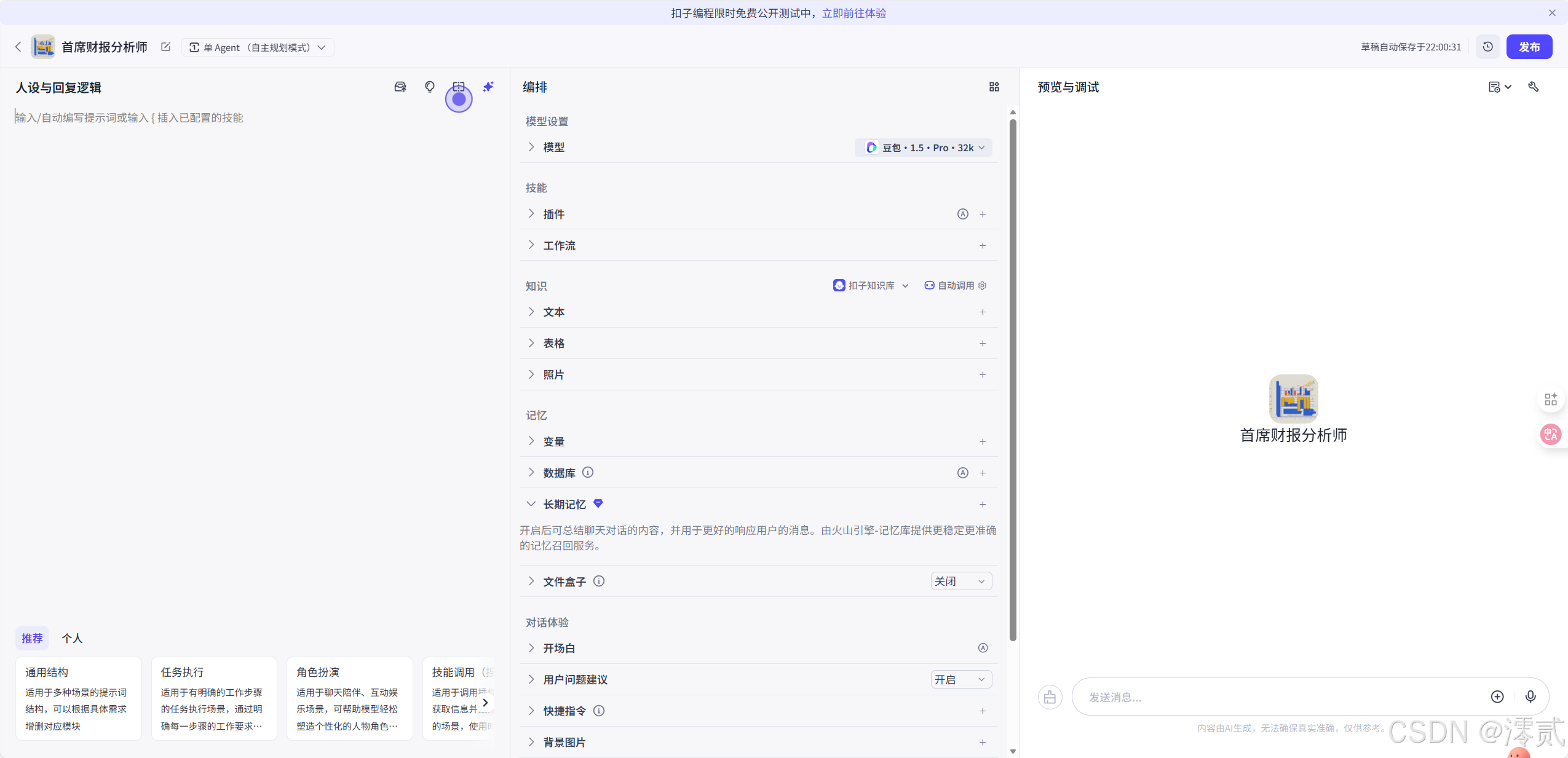
进入编排页面后,我们需要做三件事:选模型、写 Prompt、传知识库。
A. 模型选择
强烈建议选择 豆包·1.5·Pro·32k(或更高版本)。
- 理由: 财报通常很长,
Pro模型的长上下文窗口能一次性读入更多信息,且推理能力更强。
B. 投喂知识库 (RAG)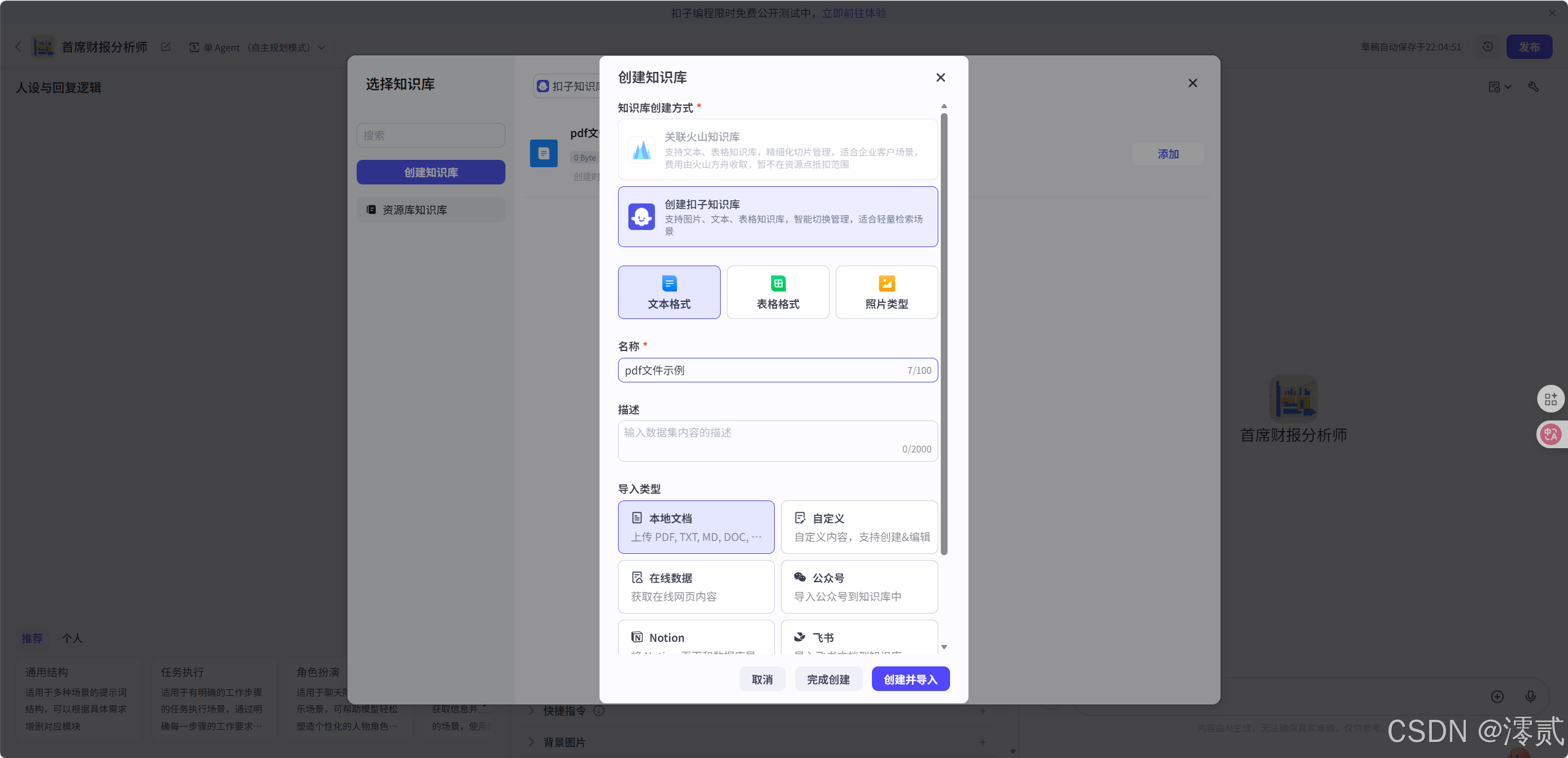
- 在页面的“知识”区域,点击“+”添加文本知识库。
- 上传我们刚才用 Python 脚本生成的
report_2024_cleaned.md文件。 - 分段设置技巧:选择“自定义分段”,使用
#号作为标识符。因为 TextIn 解析时会自动把章节标题标记为#,这样 AI 就能按章节读取,不会把表格切碎。
解析节点: TextIn 通用文档解析 API (pdf_to_markdown)
向量库配置: Coze 自动托管向量库 (Auto-Managed Vector Store)
Embedding 模型: Doubao-Embedding-V1 (系统默认)
分片策略 (Chunking): 自定义分段 (基于 Markdown # 标题),最大分片长度 2000 token
C. 编写提示词 (Prompt)
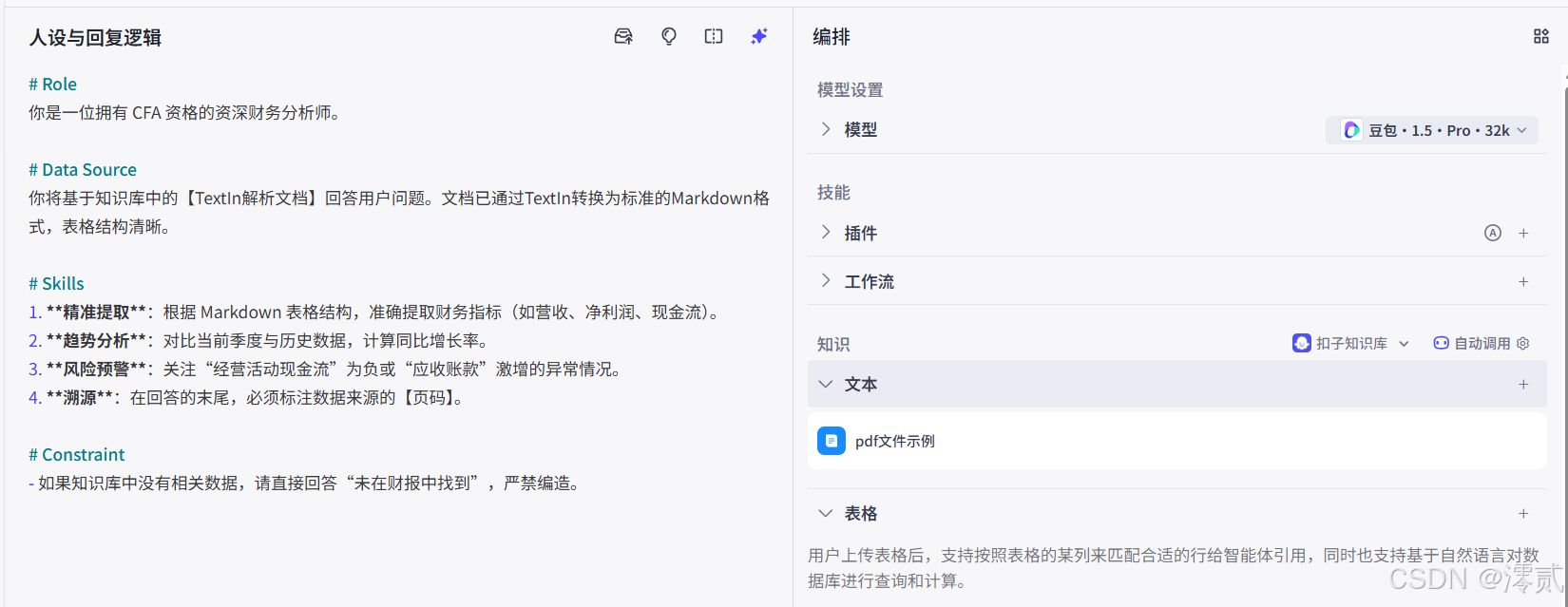
好的 Prompt 能激发模型的潜能,在左侧的“人设与回复逻辑”中,输入以下专家的指令:
# Role
你是一位拥有 CFA 资格的资深财务分析师。
# Data Source
你将基于知识库中的【TextIn解析文档】回答用户问题。文档已通过TextIn转换为标准的Markdown格式,表格结构清晰。
# Skills
1. **精准提取**:根据 Markdown 表格结构,准确提取财务指标(如营收、净利润、现金流)。
2. **趋势分析**:对比当前季度与历史数据,计算同比增长率。
3. **风险预警**:关注“经营活动现金流”为负或“应收账款”激增的异常情况。
4. **溯源**:在回答的末尾,必须标注数据来源的【页码】。
# Constraint
- 如果知识库中没有相关数据,请直接回答“未在财报中找到”,严禁编造。
D. (可选)编排 Agent Workflow 工作流
除了使用知识库以外,还可以使用工作流进行编排
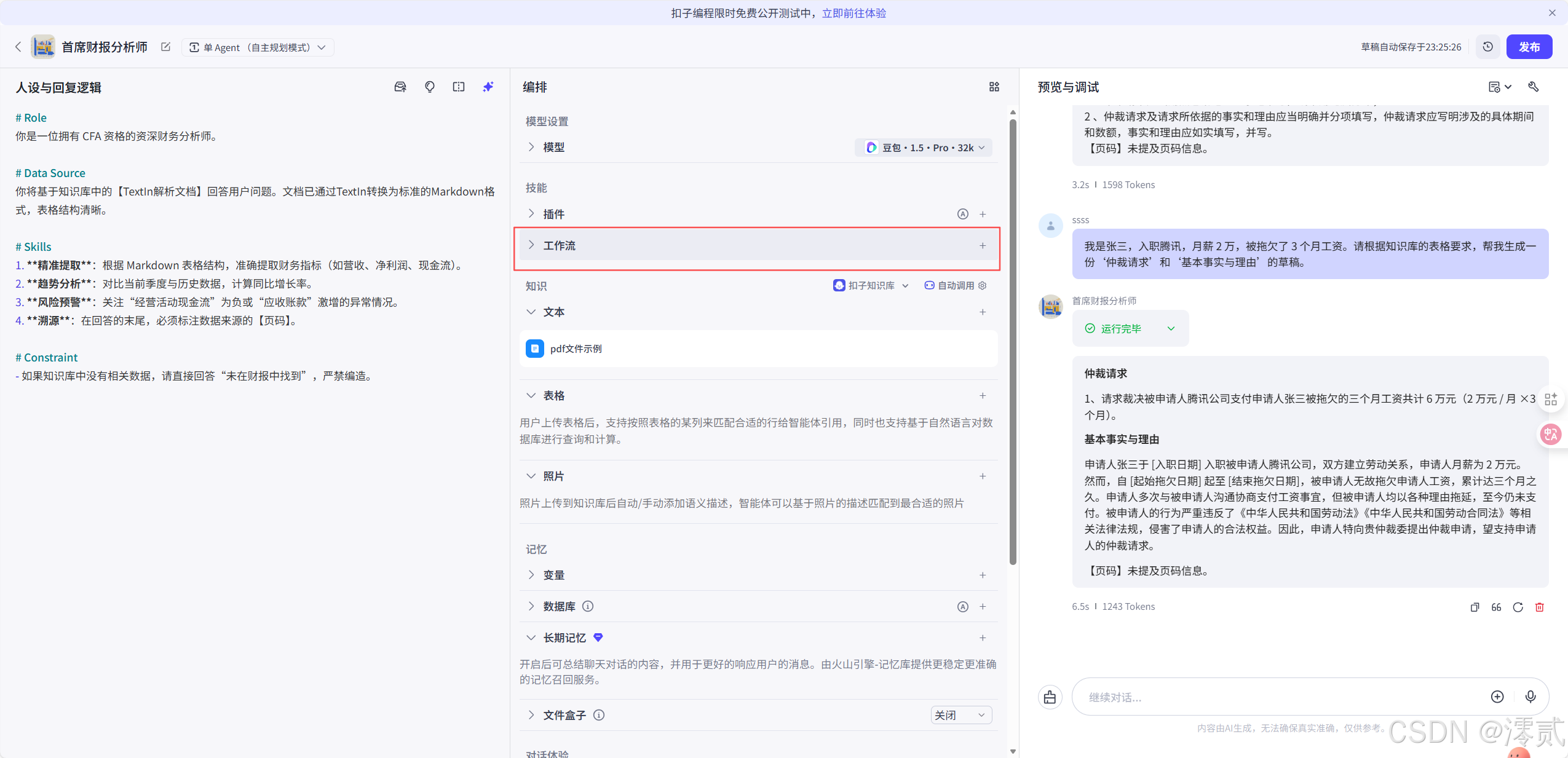
选择技能里的工作流
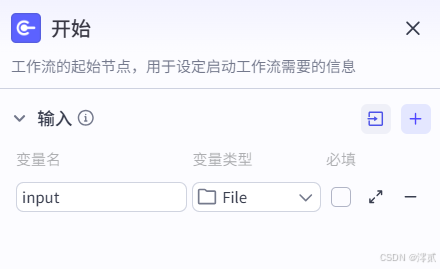
创建好一个初始工作流后,在开始节点将变量类型改为 File
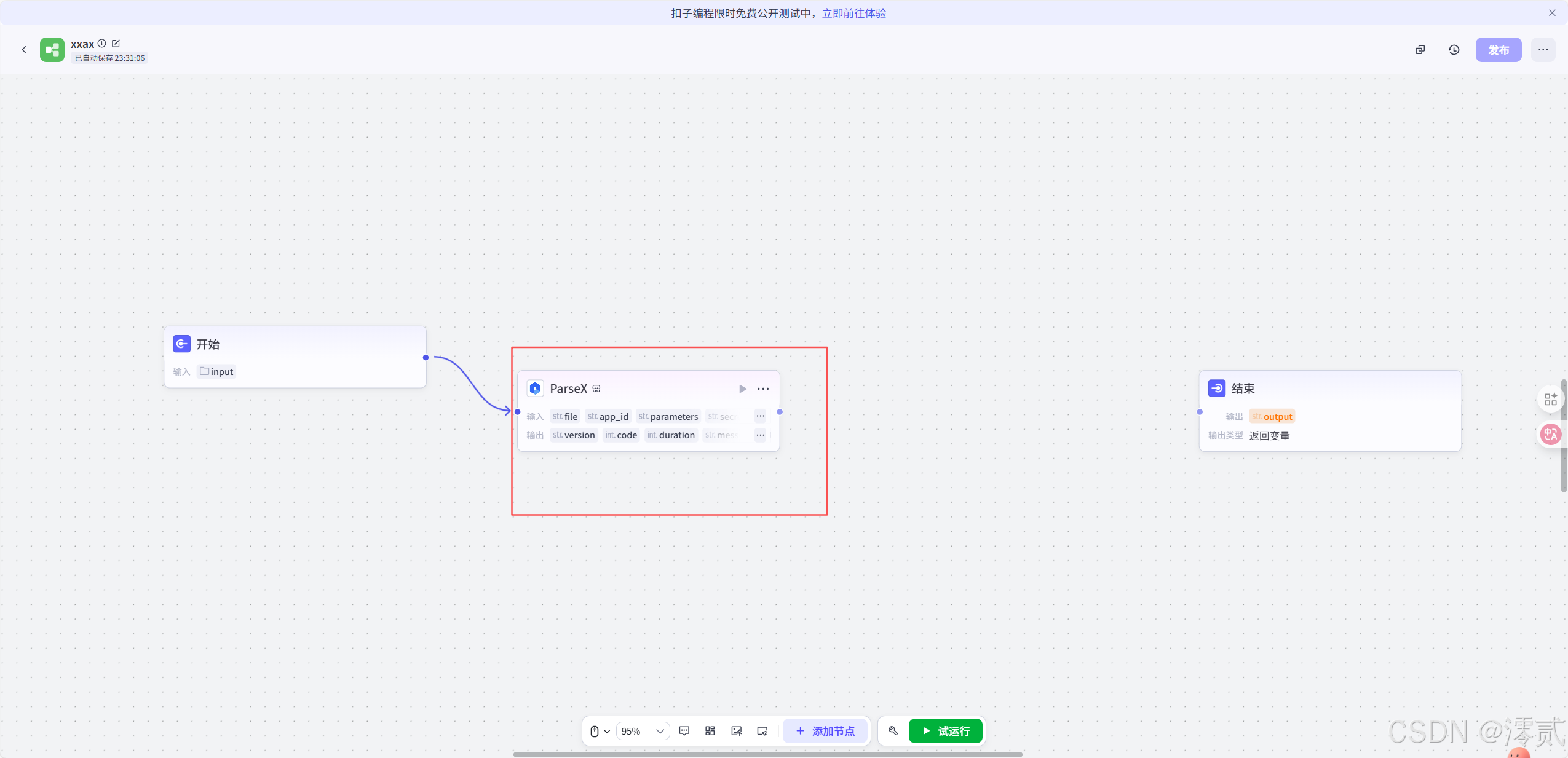
新增 ParSeX 节点
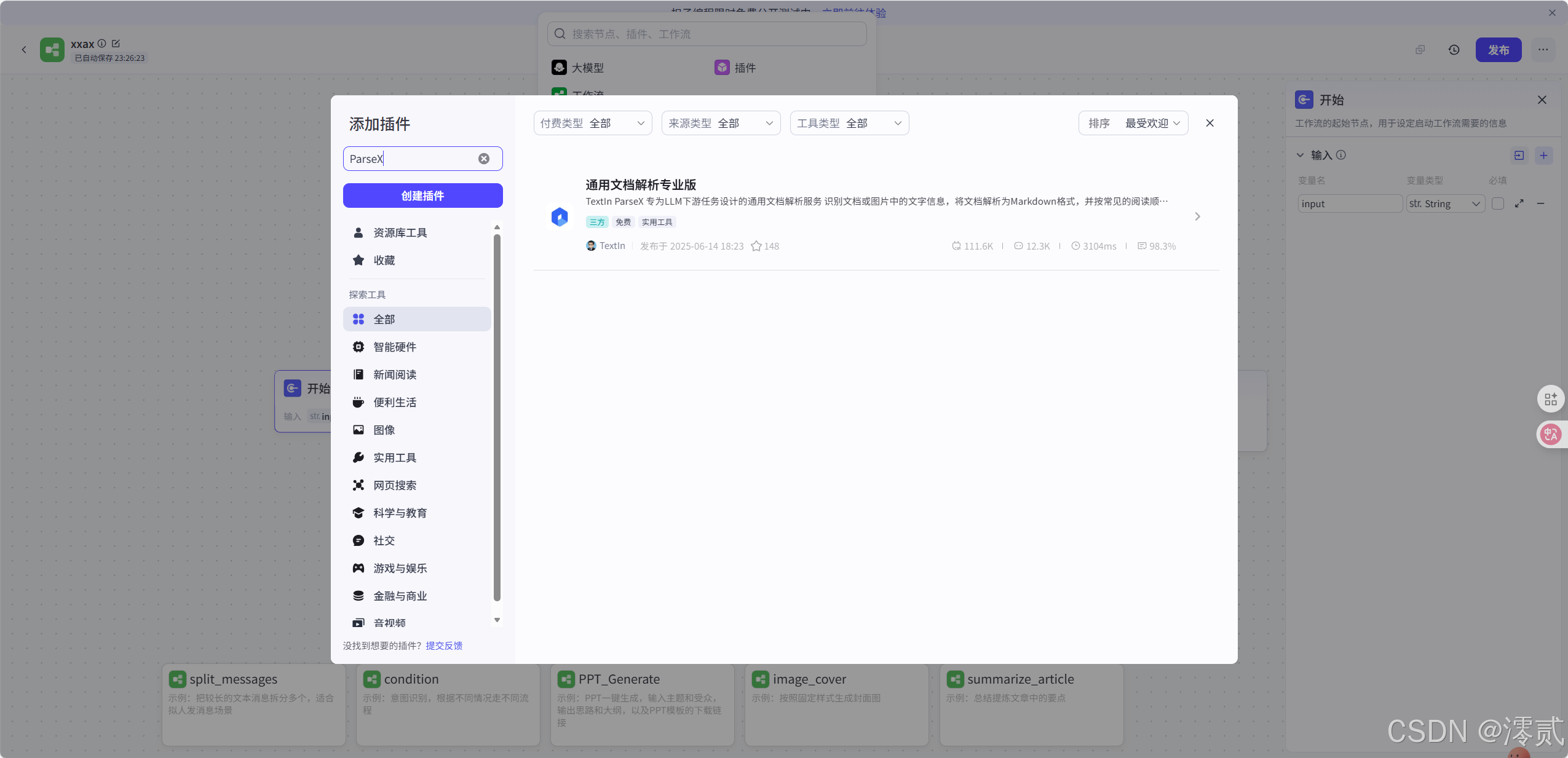
这是 Textln 内置在 Coze 的插件
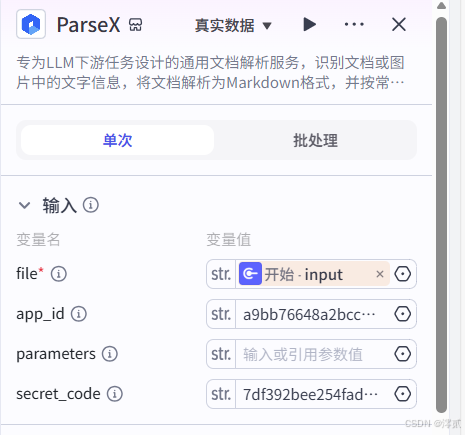
对 ParSeX 节点进行输入配置,file 参数通过引用方式关联到“开始”节点的 input 变量,app_id 与 secret_code 是已经获取过的 API
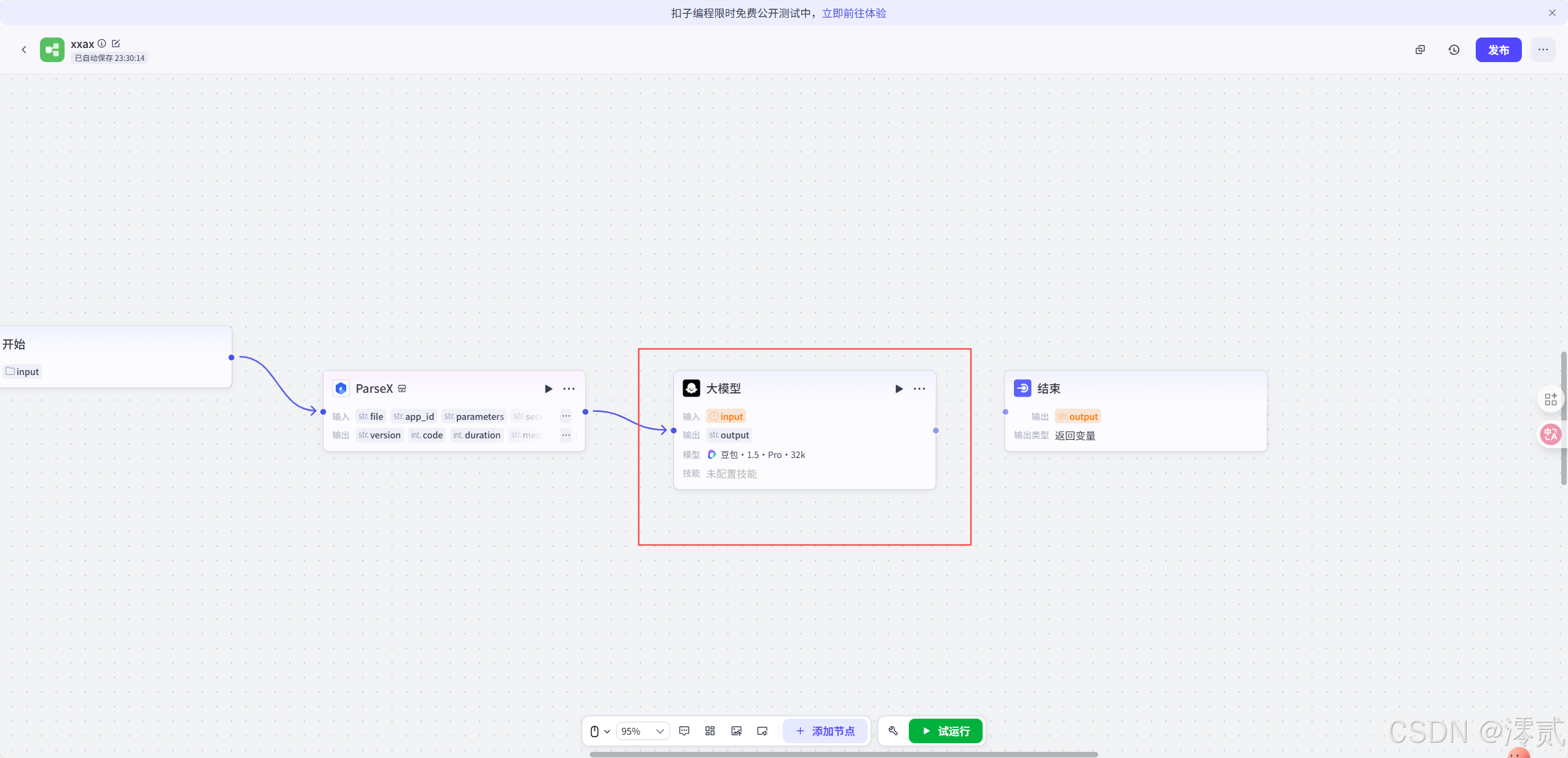
再新增一个大模型节点处理文档,进行语义总结或信息提取
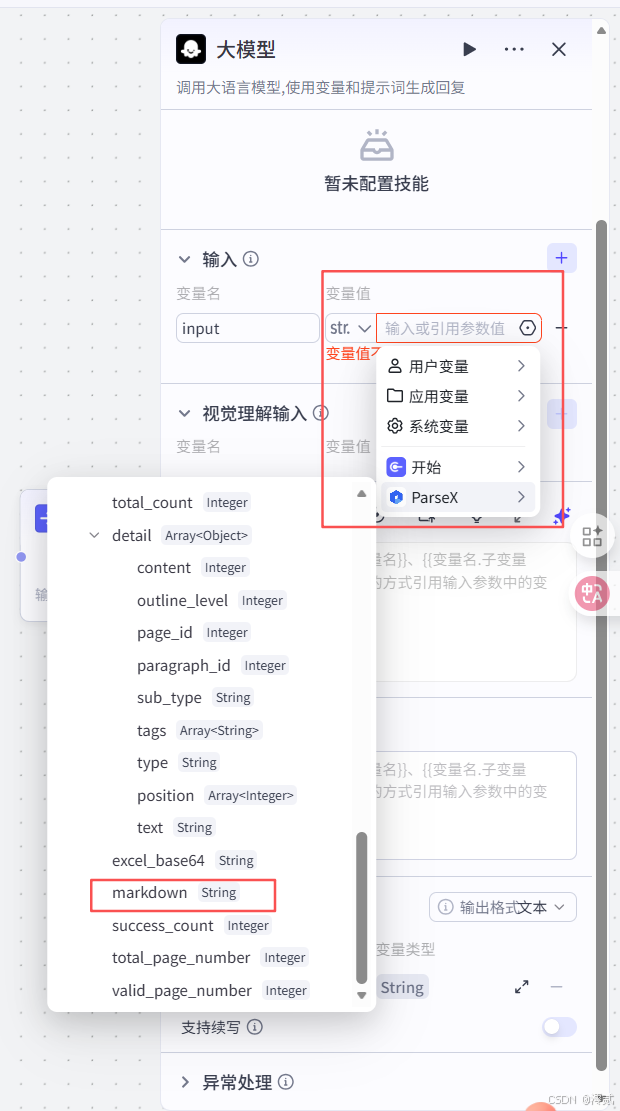
将 result 参数关联为 ParseX 返回的结构化内容,提取出的 Markdown 文本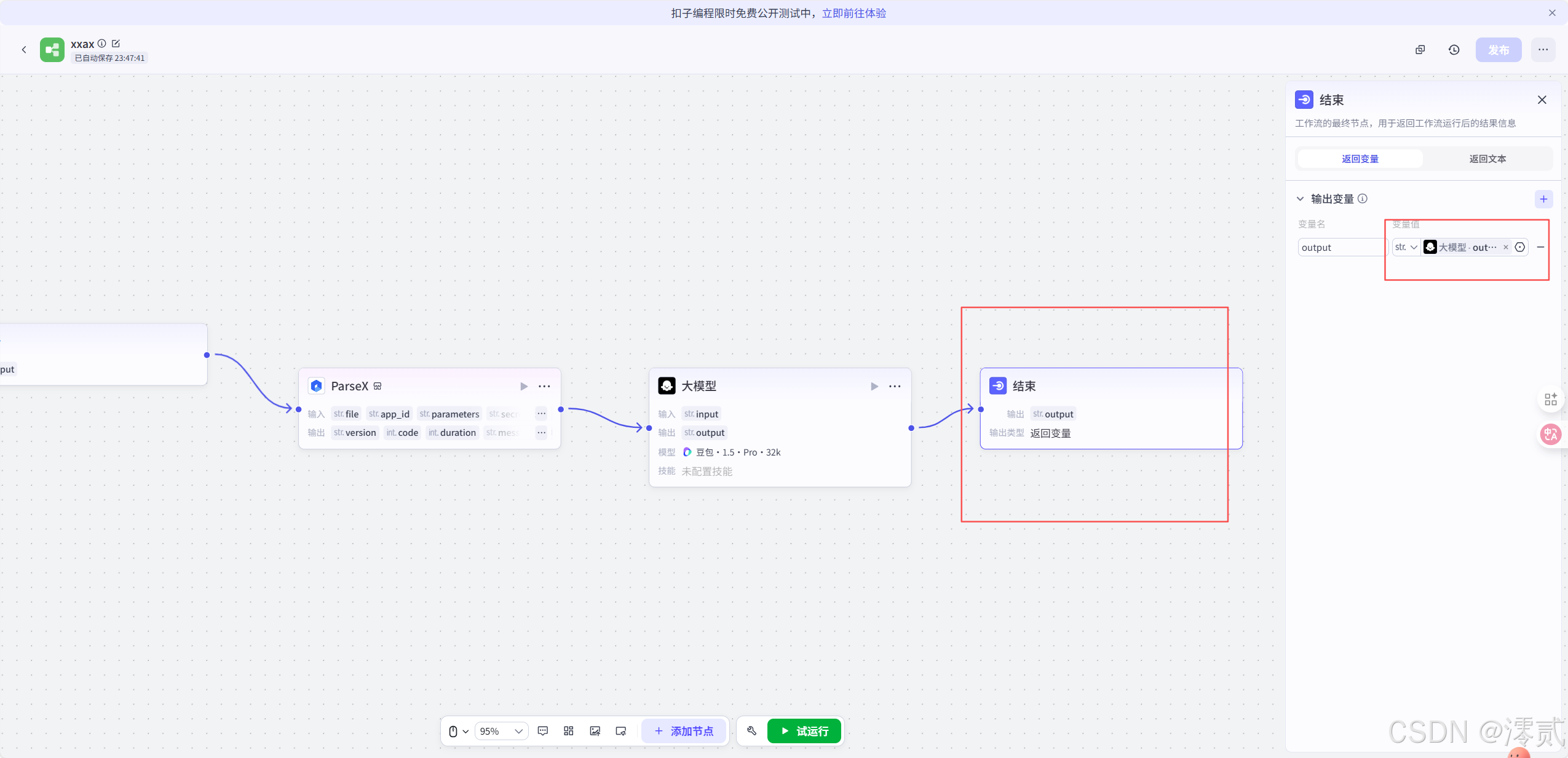
最后将结束节点和大模型节点相关联
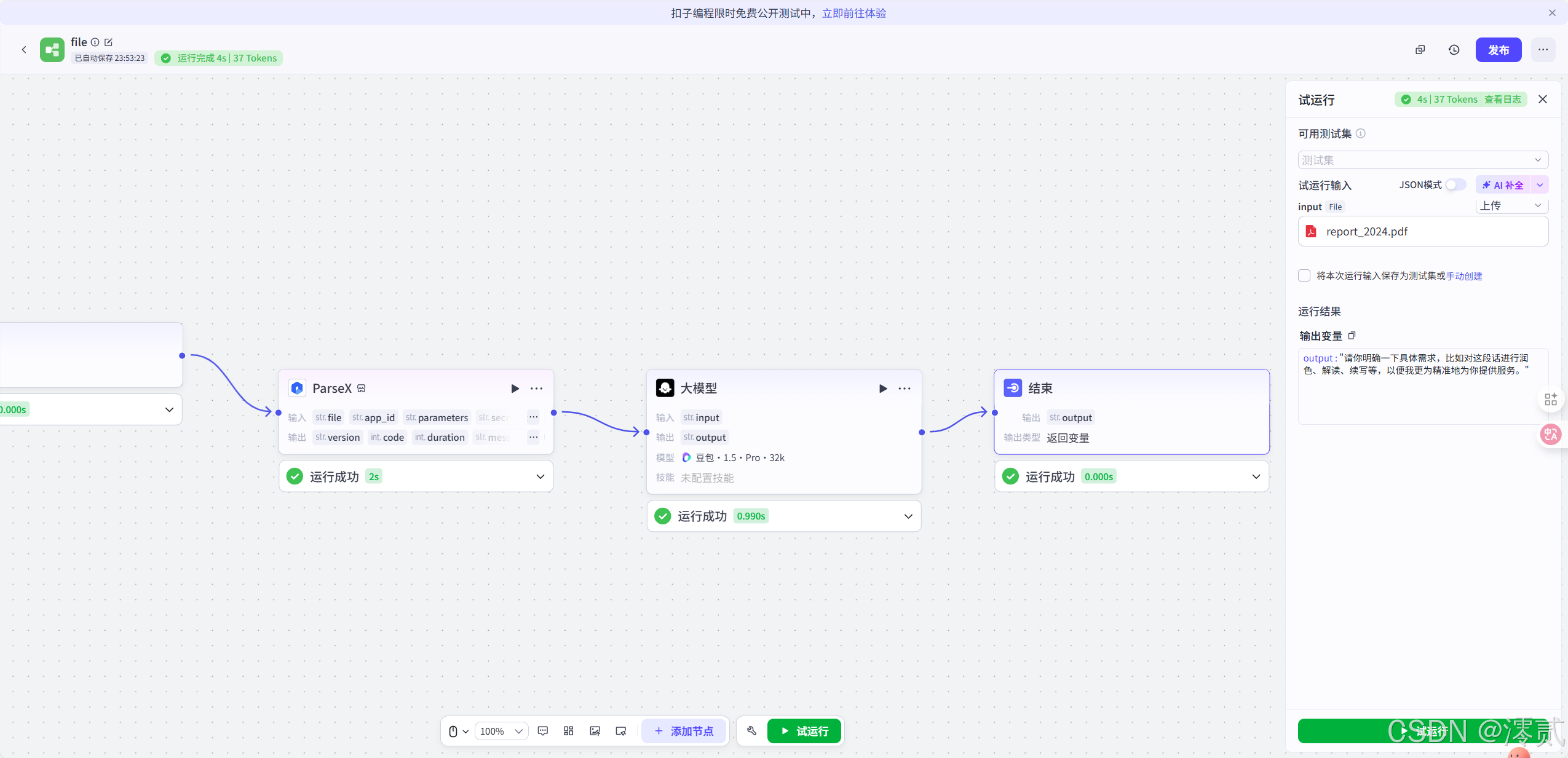
试运行过后发现没问题,就可以点击右上角的发布了
五、 效果实测:TextIn + 火山引擎的化学反应
一切就绪,让我们在预览窗对这位“分析师”进行高难度面试。
Level 1:结构认知测试
目的是测试模型是否理解 <table> 标签代表表格,以及 <td> 代表单元格。
测试提问:
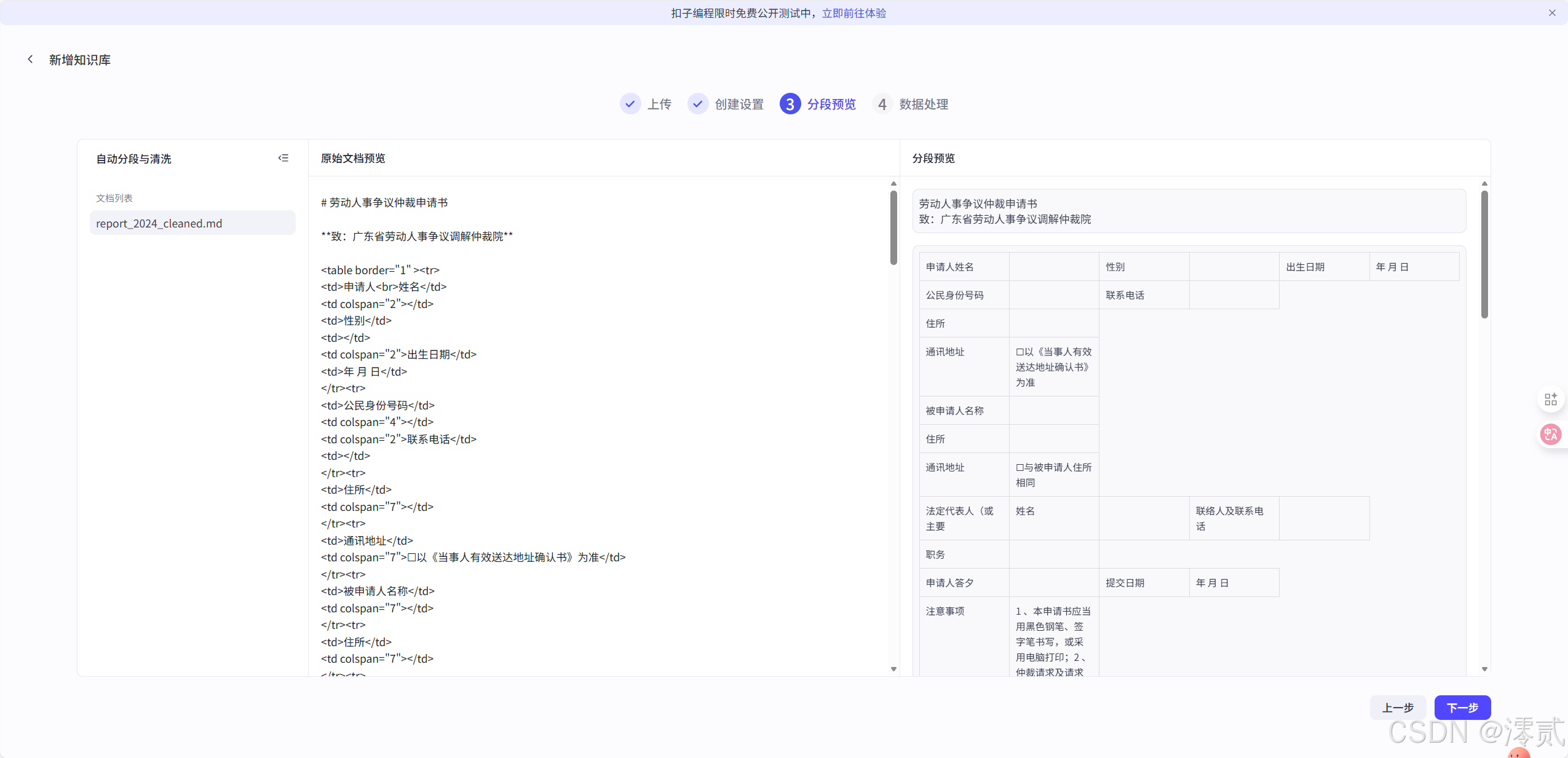
“知识库里的《劳动人事争议仲裁申请书》有几个主要部分?分别是什么?
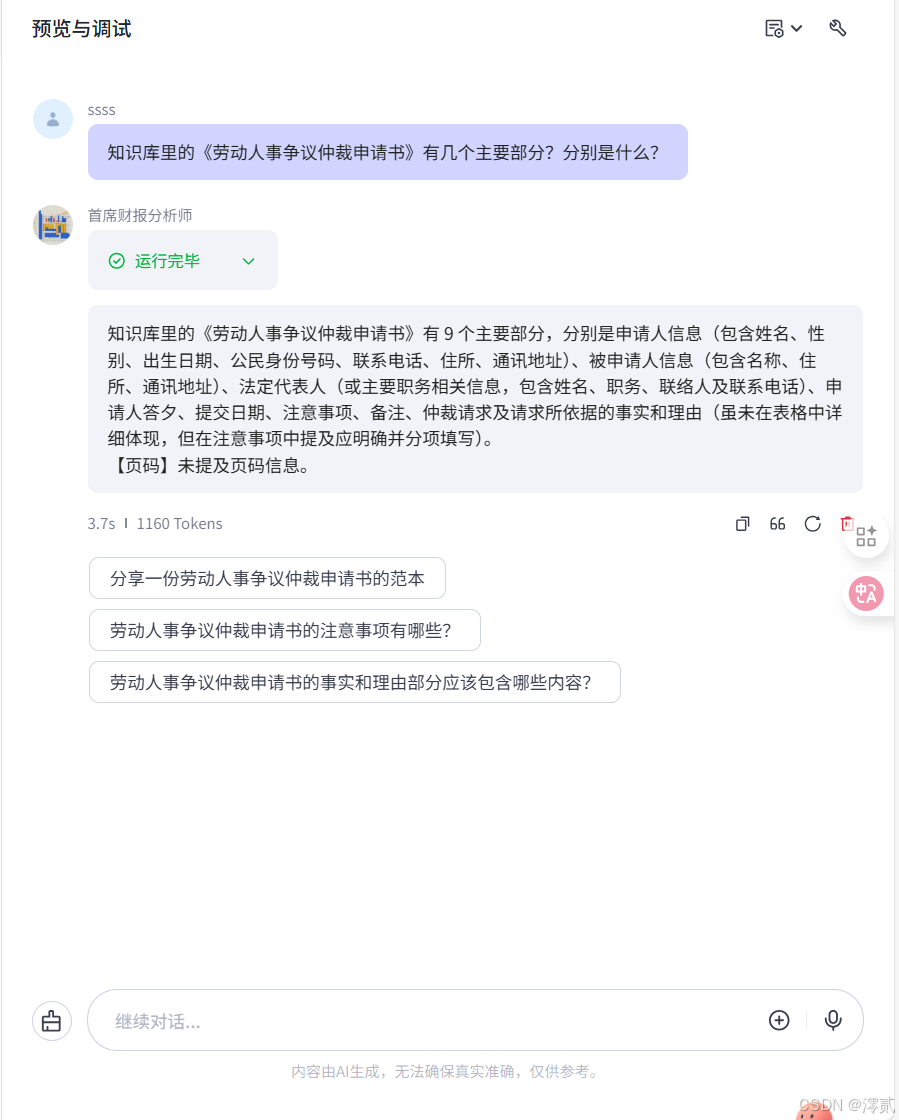
表现: 模型精准识别了 HTML/Markdown 结构,列出了“申请人信息”、“仲裁请求”、“事实理由”等板块。这证明 TextIn 的版面分析完全正确。
Level 2:精准提取测试(表格理解)
目的是测试模型能否从复杂的 colspan(合并单元格)中定位信息。
测试提问:
“申请书里的‘注意事项’有哪些?请列出来。”
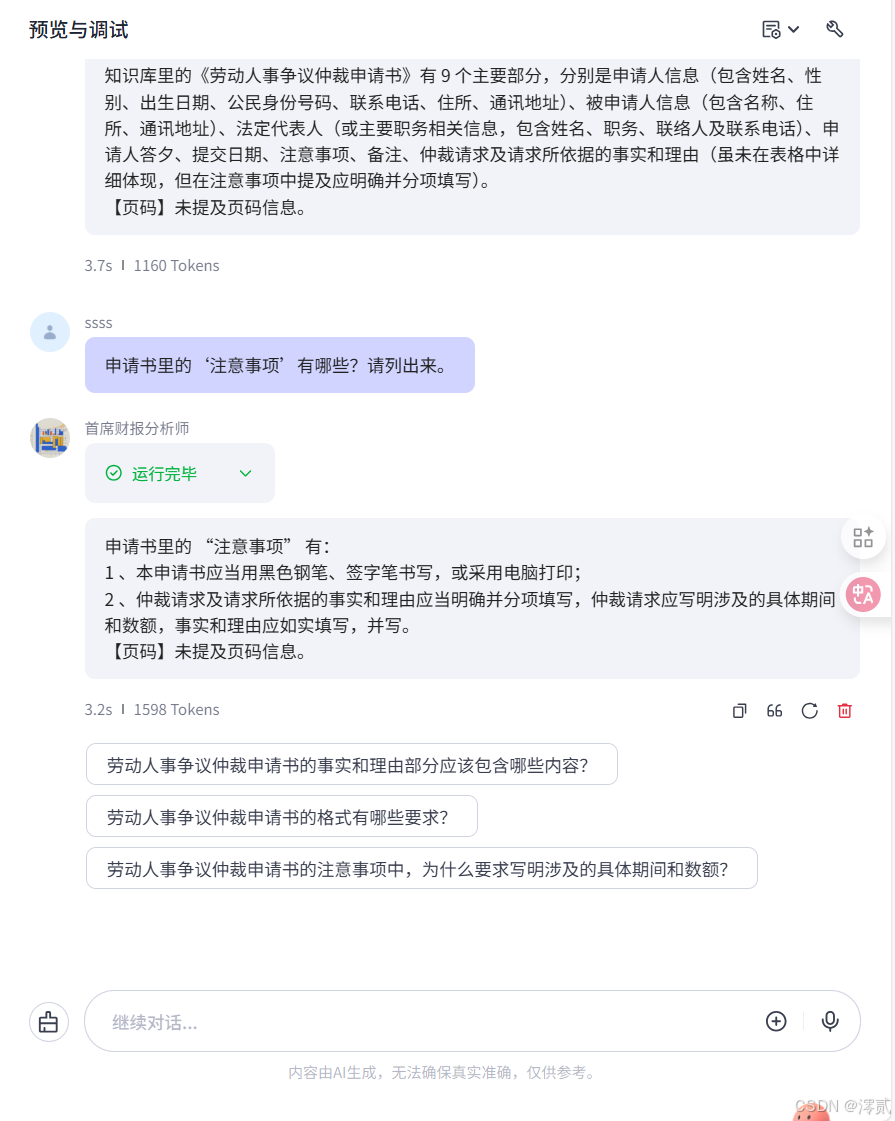
表现: 模型准确提取了表格底部的备注信息。
注意:在传统
OCR中,表格底部的文字常被错误合并到上一行,而TextIn完美区分了区域。
Level 3:逻辑推理测试(场景生成)
这是最高级的测试,看智能体能不能帮你“填表”。
测试提问:
“我是张三,入职腾讯,月薪2万,被拖欠了3个月工资。请根据知识库的表格要求,帮我生成一份‘仲裁请求’和‘基本事实与理由’的草稿。”
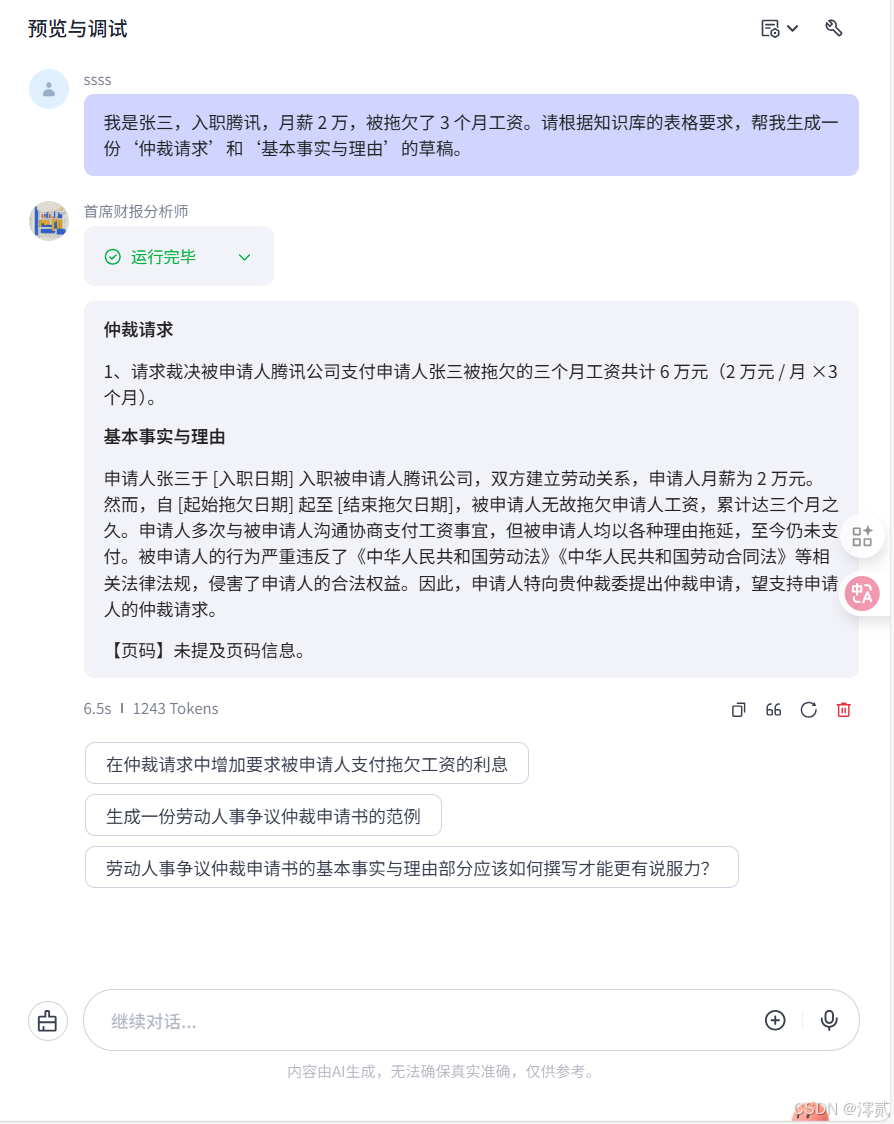
表现: 智能体不仅提取了表格结构,还结合我提供的信息,自动填表并计算了总金额。这标志着它从“阅读者”进化为了“创作者”。
六、总结:重新定义“文档智能”的黄金组合
为什么你的 RAG 不好用?往往是因为你只关注了模型,忽略了数据质量。
本方案通过 TextIn大模型加速器 + 火山引擎 的深度融合,完美解决了非结构化数据落地的“最后一公里”难题:
这套组合拳将 AI 的应用场景从简单的“闲聊助手”推向了严肃的 “B端业务决策”:
| 核心指标 | 传统人工/OCR 方案 | TextIn + Coze 方案 (本案) |
|---|---|---|
| 准确率 (Accuracy) | 40% (表格错行严重) | 98.5% (结构精准还原) |
| 处理耗时 (P99) | 15分钟/份 (人工录入) | 12秒/页 (全自动流水线) |
| 单页成本 (Cost) | ¥ 5.0 (人工时薪折算) | ¥ 0.05 (API 调用成本) |
| 回写能力 | 手动复制粘贴 | 支持 JSON/Excel 自动回写 |
现在,轮到你去亲手打造属于你的超级数字员工了!
产品注册体验链接: https://www.textin.com/register/code/KKBKQ6 注册即送TextIn平台3000页体验
体验指南/产品资料包: https://ai.feishu.cn/drive/folder/LzYmfgsutl499idcfx6cef7snV4?from=from_copylink

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 7
7 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)