【vLLM-模型特性适配】vllm-ascend开发之FlashComm2
本文介绍了FlashComm2优化方案及其在vllm-ascend中的实现。FlashComm2通过通信前移和All2All+MatMul计算优化大模型TP场景,相比FlashComm1减少了通信量。在vllm-ascend中,通过替换Qwen2/3的关键组件(如Linear和RMSNorm)并添加装饰器,实现了计算图优化,包括新增all_gather、unpad等操作。该方案保持了较好的泛化性,
作者:昇腾实战派
1. 背景及原理
FlashComm2是在FlashComm的基础上结合以存换传(显存换通信)的思路设计的针对大模型TP场景的优化方案,具体可参考官方文档:https://gitcode.com/ascend-tribe/ascend-inference-cluster/blob/main/FlashComm/ascend-inference-cluster-flashcomm2.md
对比下图可以看到,FlashComm2基于FlashComm1(ReduceScatter+AllGather替换AllReduce)做了进一步优化。具体是将通信前移,用All2All+MatMul计算来替换MatMul+ReduceScatter计算。此处All2All的操作可以理解成是把模型从TP并行转为DP并行(head维度切分转为sequence维度切分),由于O Proj的输入由原来的部分head变成了所有head,因此O Proj的权重也必须是完整权重,这里会增加每张卡的显存占用(实际上对于MTE2 Bound的场景也会增加O Proj的MatMul耗时)。
性能收益分析:
FlashComm的通信输入是O Proj的输入,通信量就是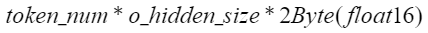
FlashComm2的通信输入是O Proj的输出,通信量是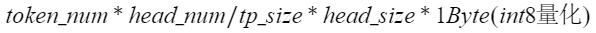
因此FlashComm2的通信量是FlashComm的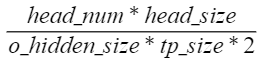
通信量减少带来的性能收益也可以按这个比例预估,不过还需要考虑O Proj MatMul增加的搬运耗时。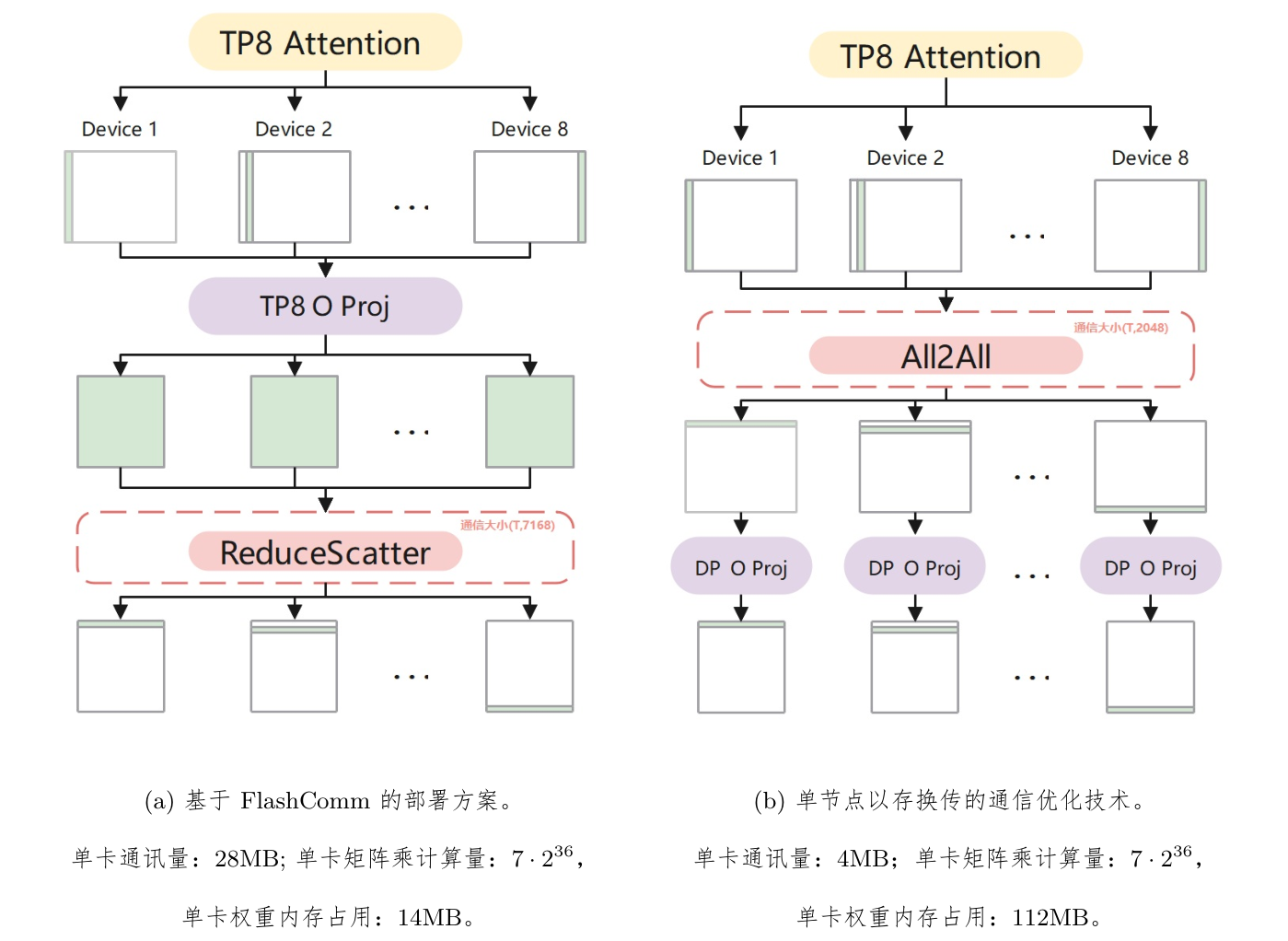
2. vllm-ascend实现
2.1 UML类图
以Qwen2/3为例,vllm原生的结构如下: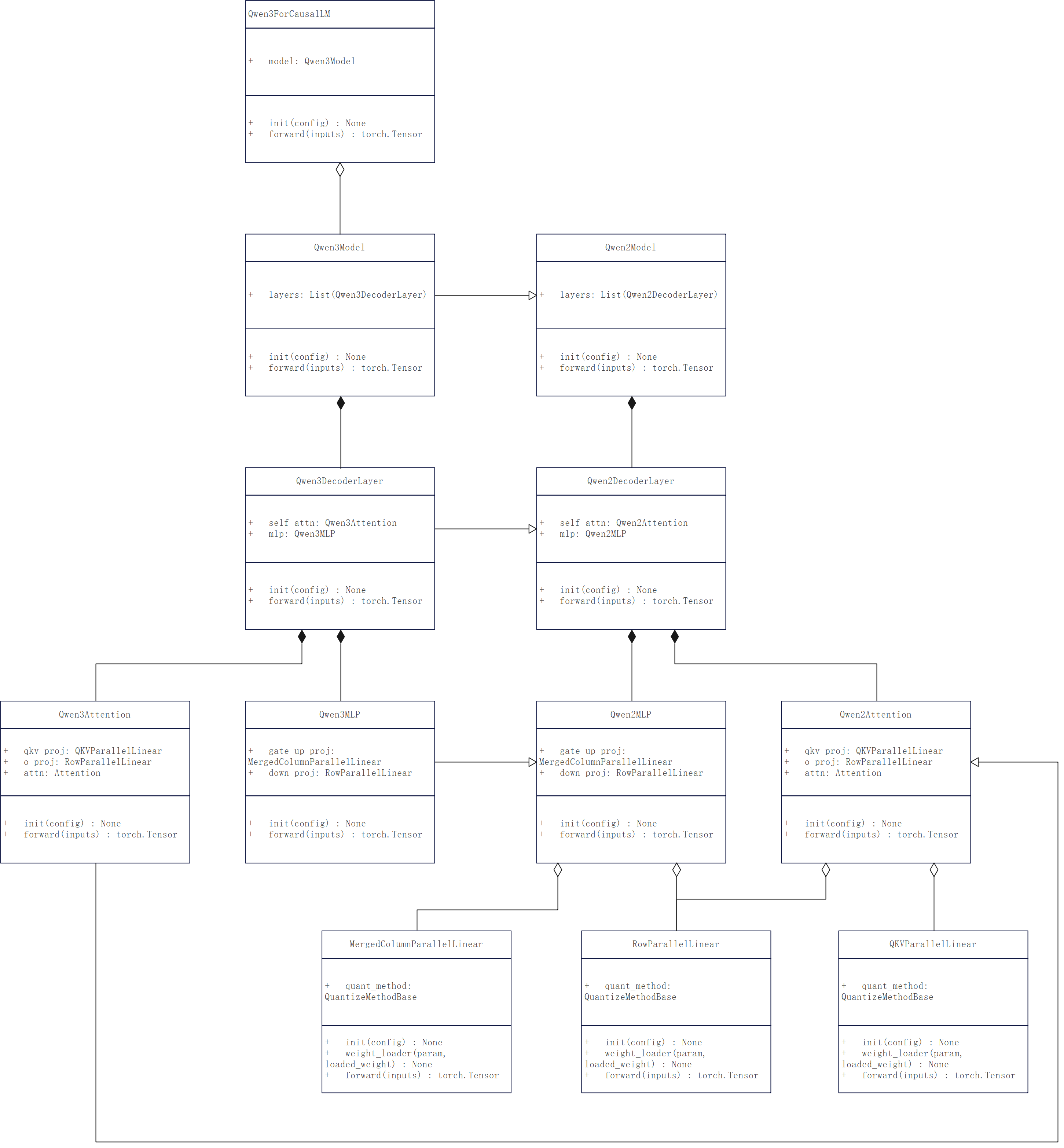
我们需要适配的结构如下,目标是尽量保证泛化,其他模型只需要较少修改就能复用: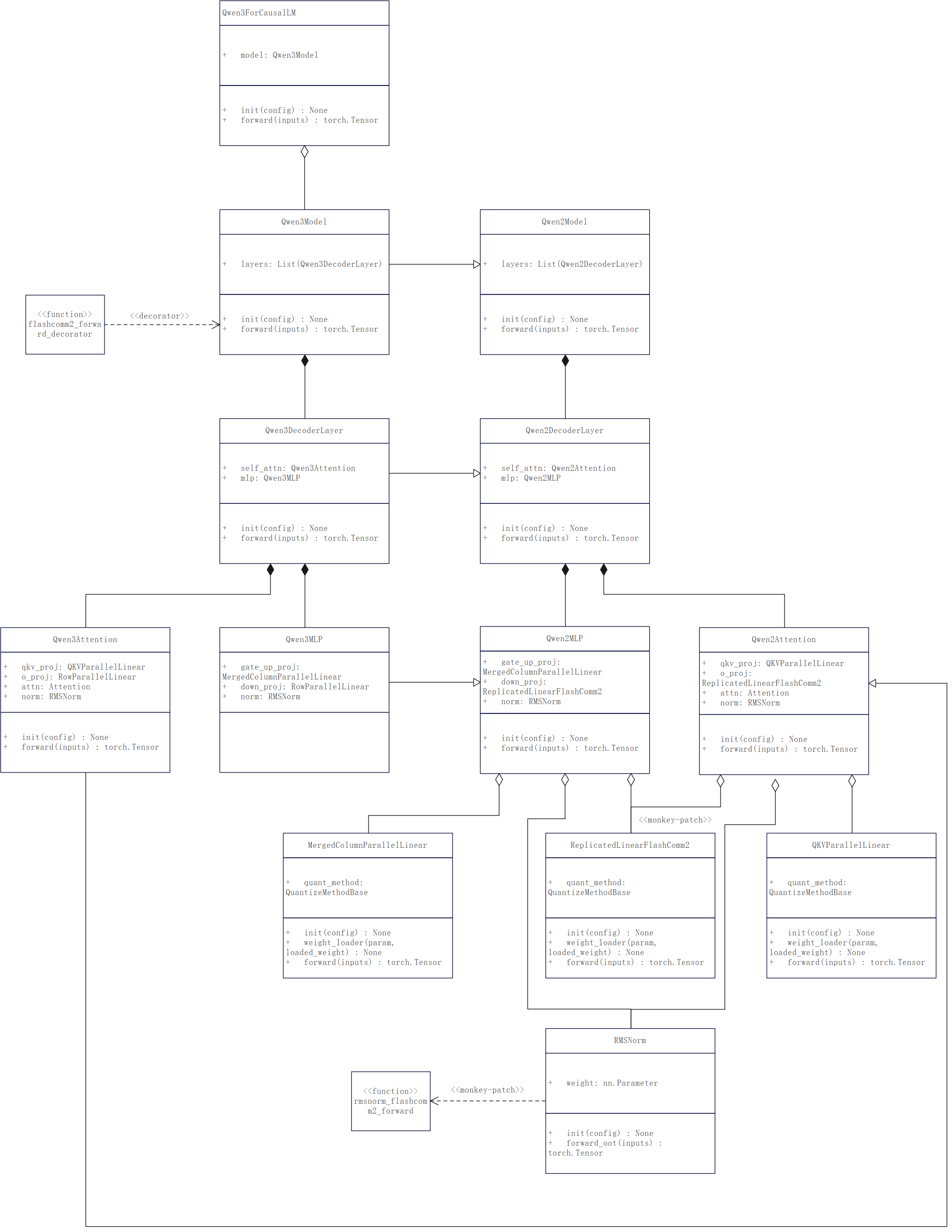
因为Qwen3的核心逻辑是继承自Qwen2的,所以主要修改Qwen2即可:
- 将Qwen2Attention的o_proj替换为自定义Linear:ReplicatedLinearFlashComm2,通过monkey patching方式在CausalLM中替换;
- 将Qwen2MLP的down_proj替换为自定义Linear:ReplicatedLinearFlashComm2,通过monkey patching方式在CausalLM中替换;
- 替换RMSNorm的forward_oot为自定义方法:rmsnorm_flashcomm2_forward,通过monkey patching方式在ops/layernorm.py中替换;
- Model的forward添加装饰器flashcomm2_forward_decorator,用于补充最后一层的all_gather和unpad计算(见2.2);
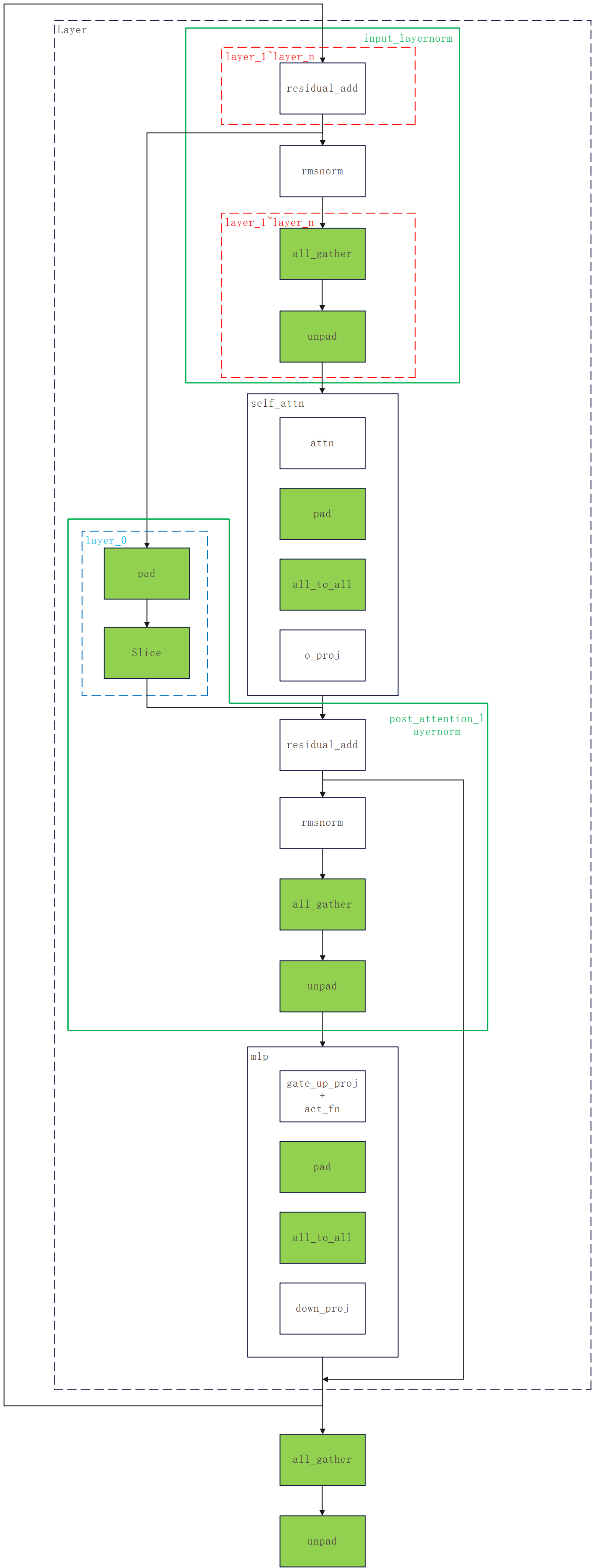
2.2 计算图
下图表示模型(Qwen2/3)的一层layer的计算逻辑:
-
绿色填充的方块表示整个layer新增的计算;
-
绿色实线框中的是两次layernorm的forward计算:rmsnorm之后添加all_gather和unpad,把所有卡上的输入合并,并去除padding部分;
-
蓝色虚线框中的是layer 0中要做的额外计算:第一次处理residual add时,需要把residual在sequence维度等分到所有卡上,所以需要插入pad和slice;
-
红色虚线框中的是从layer 1开始所有layer都要做的计算:第一层需要跳过residual add;all_gather和unpad对应上一层的pad和all_to_all,所以第一层不需要计算,最后一层的all_gather和unpad放到model的最后(layer外)执行;
-
all_to_all前的pad:因为allgather要求每张卡的输入shape一致,all_to_all后输入是在sequence维度切分,因此需要padding使其能被tp size整除;

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)