【TextIn大模型加速器 + 火山引擎】一次真实的 Agent 落地体验
在芯片制造、工业设备、消费电子这些行业里,产品说明书 / 技术规格书几乎是绕不开的一环。但只要你真正参与过,就会知道——真正让人头疼的,从来不是“翻译”本身,而是:多语言版本并行文档频繁迭代合规与版本一致性要求极高一点点改动,就可能引发大规模返工这次我完整体验并落地了一套 基于 TextIn 文件处理能力的芯片技术文档自动化流程,场景非常典型,但也极其真实:
文章目录
前言
在芯片制造、工业设备、消费电子这些行业里,产品说明书 / 技术规格书几乎是绕不开的一环。
但只要你真正参与过,就会知道——
真正让人头疼的,从来不是“翻译”本身,而是:
- 多语言版本并行
- 文档频繁迭代
- 合规与版本一致性要求极高
- 一点点改动,就可能引发大规模返工
这次我完整体验并落地了一套 基于 TextIn 文件处理能力的芯片技术文档自动化流程,场景非常典型,但也极其真实:
芯片行业多语言产品说明书的翻译、校对与版本同步
最终的结果是:
- 从原来 3–5 天的人工流程,压缩到约 1 小时
- 多语言版本差错率下降约 80%
- 人工从“搬砖校对”,变成“抽样审核 + 关键章节把关”
一份芯片说明书使用场景
在聊技术之前,先把 业务链路说清楚。
否则很容易陷入“为了用大模型而用大模型”的伪智能。
1. 这是一个非常典型的芯片行业场景
业务形态是 B2B + B2C 混合型:
-
上游
- 芯片制造商
- 工业设备厂商
-
下游
- 海外客户
- 终端用户
- 开发者
- 高校 / 研究机构
- 售后与现场工程师
2. 文档类型复杂到什么程度?
这次处理的,是一份 80+ 页的芯片技术规格说明书,典型特征包括:
- PDF / Word / 扫描件混用
- 图文混排
- 跨页表格
- 严格的章节编号、图号、引用关系
- 行业术语、寄存器说明、参数表
真正的痛点并不是“翻译慢”,而是:
- 原始文档结构极其复杂
- 不同语言版本之间版本号和内容不同步
- 中文改了,英文、日文、德文没跟上
- 改动点难以被准确定位和标注
TextIn 体验中心
TextIn 体验中心针对芯片说明书这类复杂文档,提供了一套以通用文档解析和智能文档抽取为核心的大模型加速能力,能够处理 PDF、Word 及扫描件等多种格式,完整保留图文混排、表格和章节编号等结构信息,并输出可直接用于翻译、版本比对和字段抽取的结构化结果,从而将原本不可控的文档转化为可计算、可复用的资产。

同时,体验中心还覆盖了水印去除、自动切边与增强、图像矫正、手写内容擦除以及篡改检测、图像质量检测等关键图像处理与检测能力,为后续 OCR 和大模型处理提供稳定可靠的输入。
在此基础上,平台进一步整合了文档格式转换、票据识别、通用文字与表格识别,以及 DocFlow 文档自动化、智能合同审查、知识管理助手和多类卡证识别等企业级应用,帮助企业从单点能力验证,快速升级到可落地、可扩展的完整文档自动化流程。
TextIn xParse:把说明书还原成“结构化资产”
这次体验中,我使用的是 TextIn xParse 的通用文档解析能力,作为整个 Agent 流程的第一步。
1. 解析体验
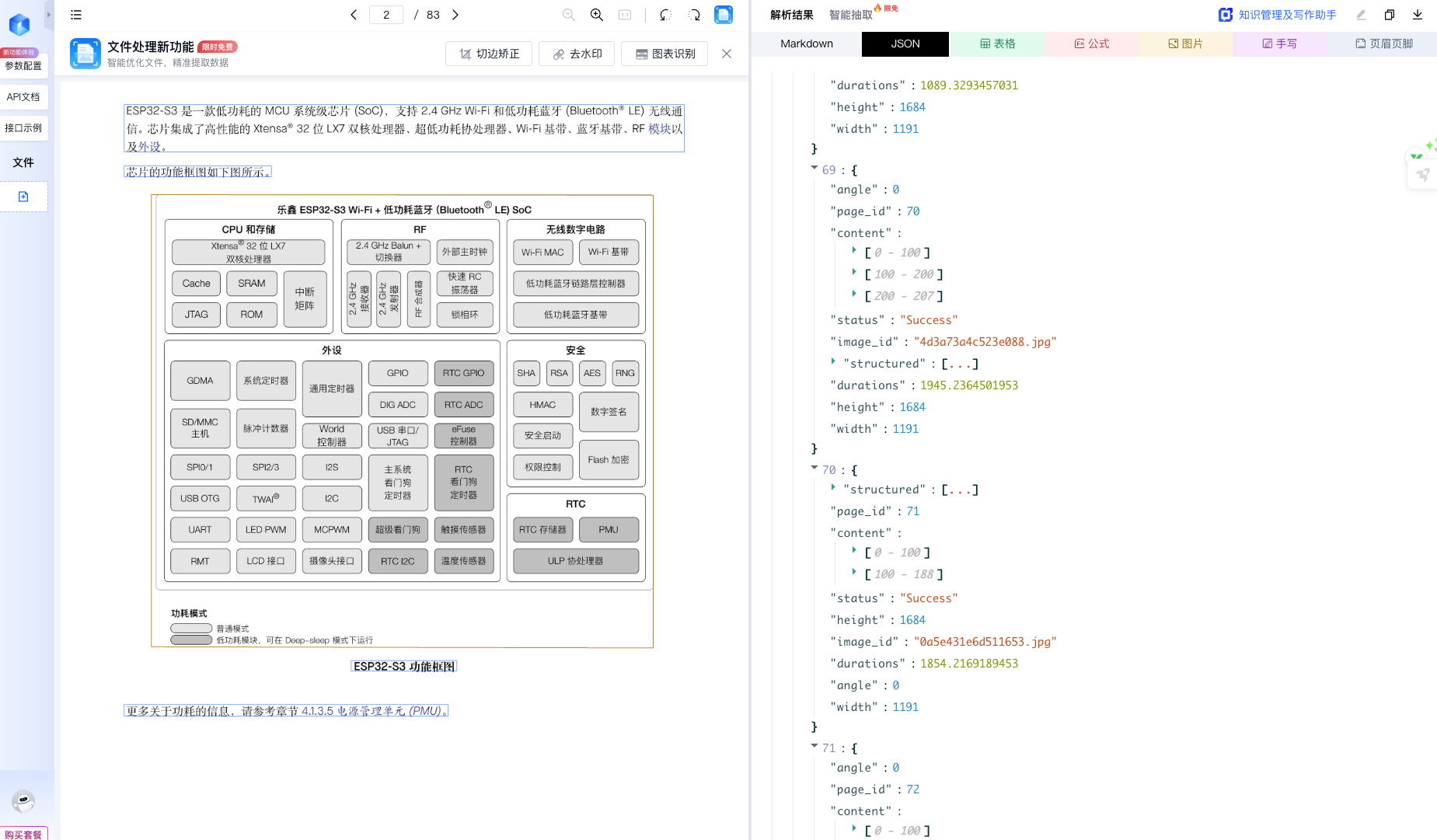
我上传了一份 80 多页的芯片技术文档:
- 解析耗时:约 20 秒
- 无需预处理
- 无需手工标注
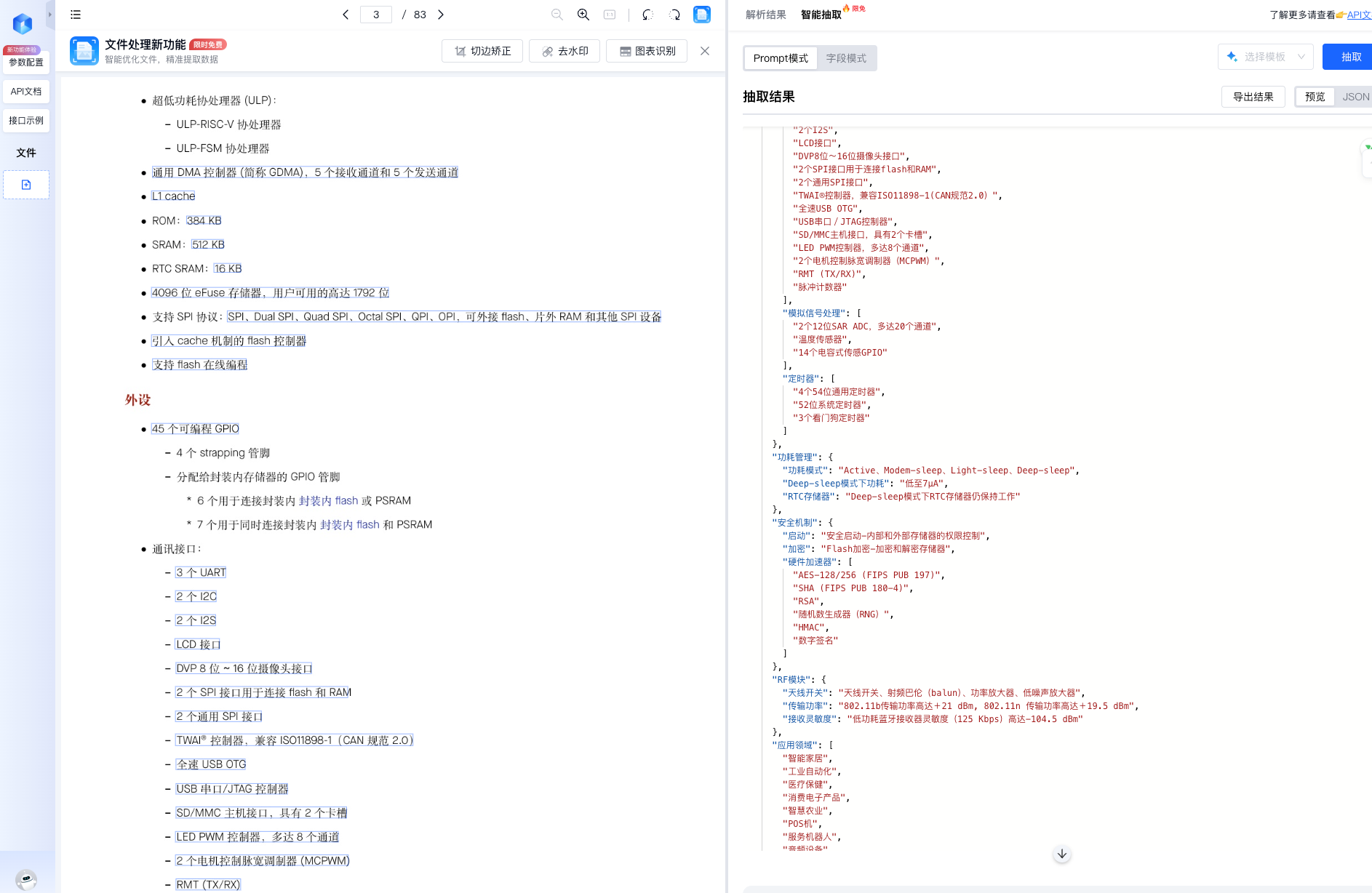
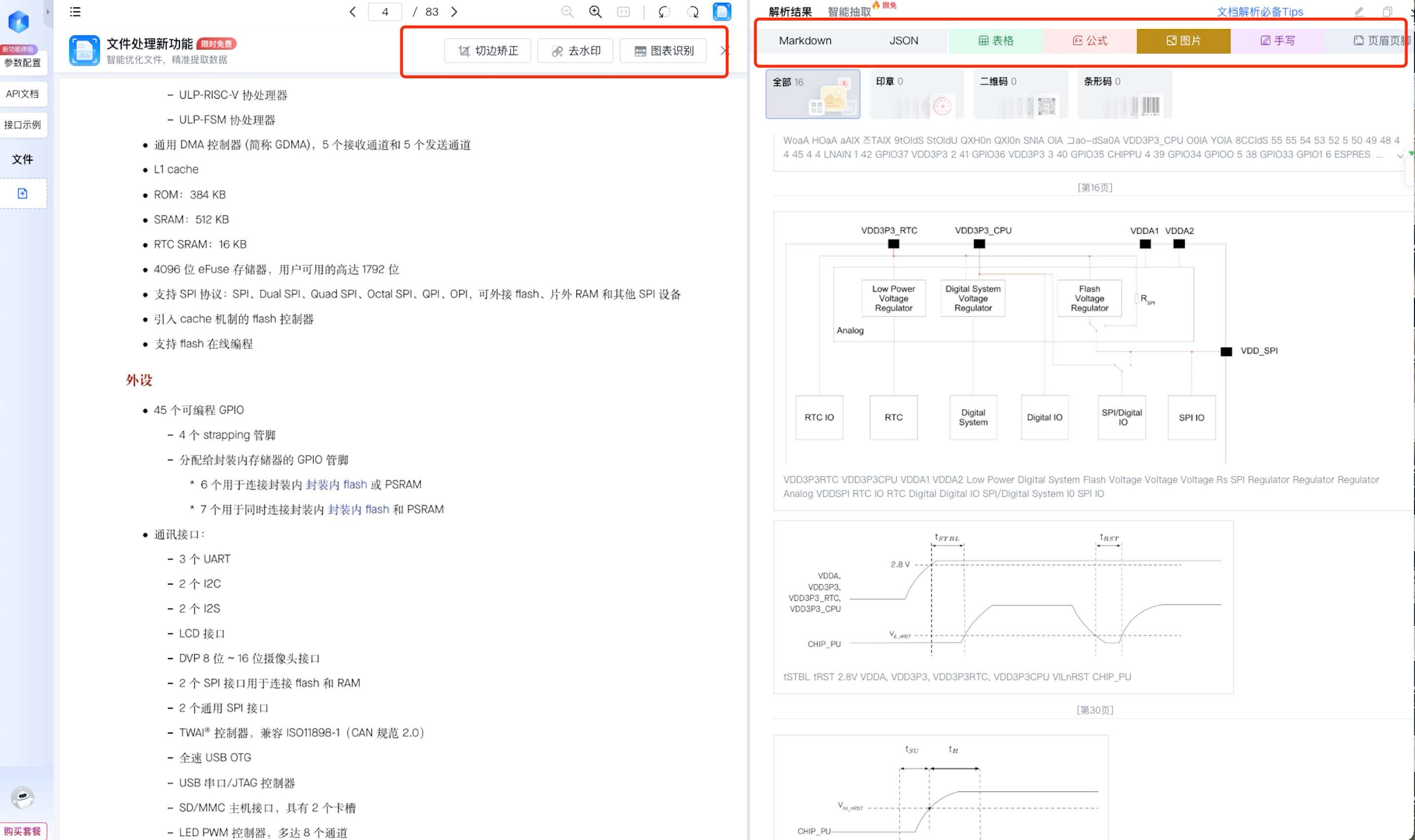
2. 解析结果,非常“开发者友好”
解析输出的核心结果是 Markdown 格式文档,这一点对工程人员来说非常重要:
- 章节结构完整保留
- 标题层级清晰
- 表格、列表、编号可直接计算和比对
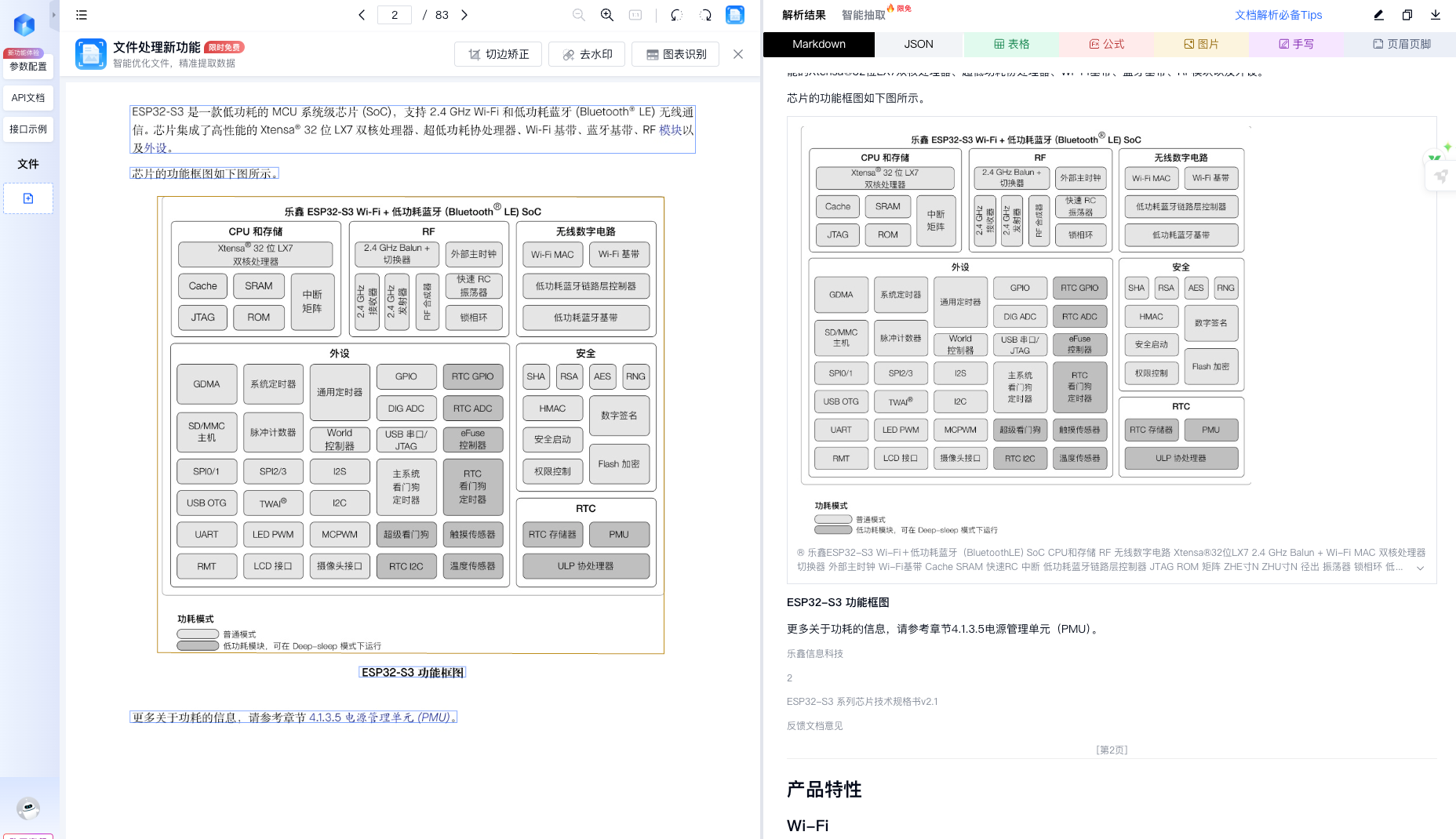
除此之外,系统还会:
-
自动拆分并识别:
- 表格

- 图片
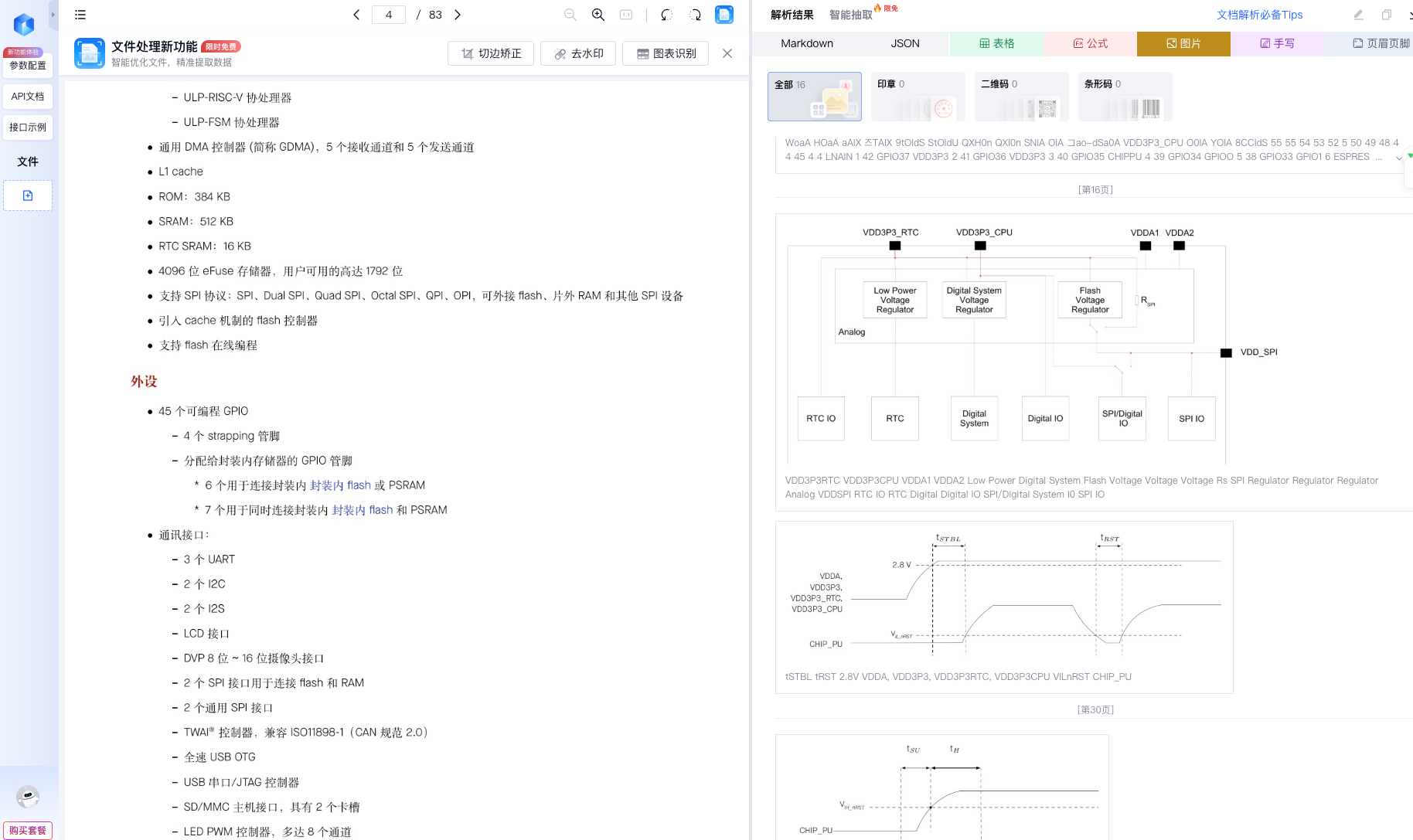
- JSON 数据
-
提供结构化数据输出,方便后续:
- 翻译
- 版本 Diff
- 自动标注
3. 对开发者极其友好的 API 设计
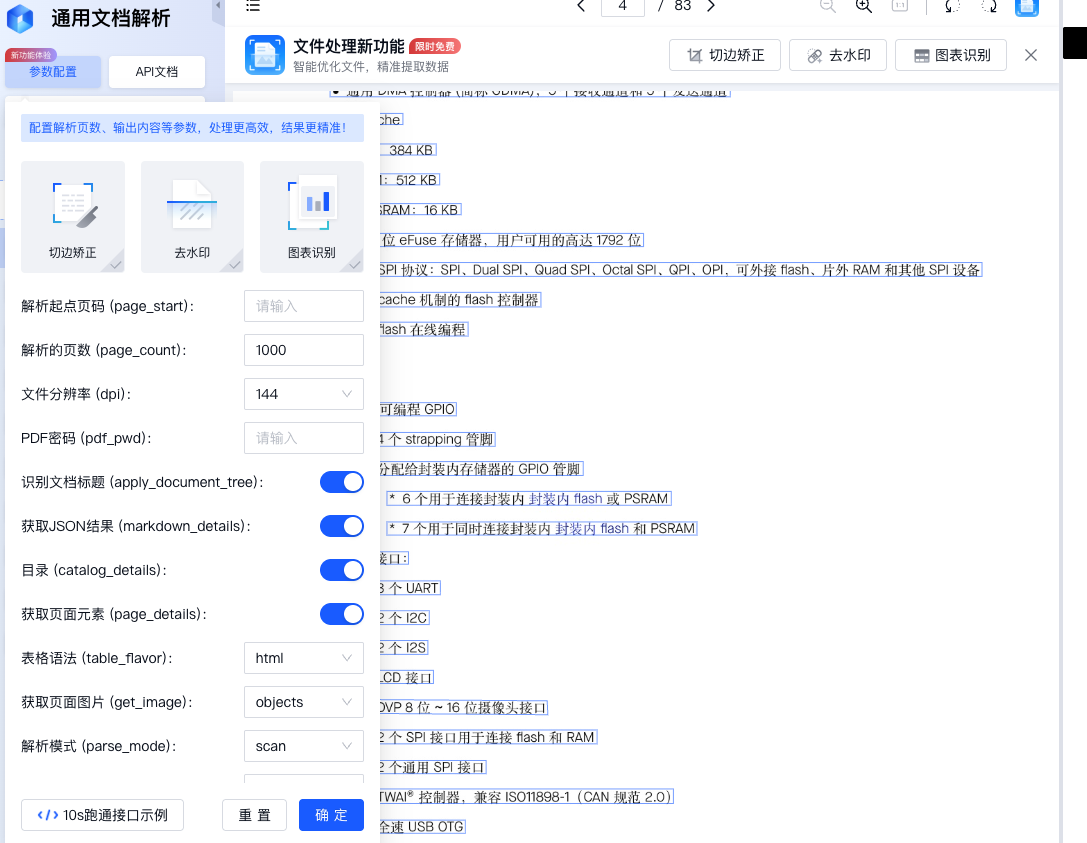
TextIn 提供了完整的接口示例,并支持多语言 SDK:
PythonJavaScriptJavaGoC#Shell
每个示例都实现了完整流程:
- 参数自动加载
- 认证处理
- 请求构建与发送
- 响应结构化展示
这意味着:
你只需要选一门最熟的语言,几分钟就能跑通整个流程。
集成 TextIn 产品的 API
如果想要在项目中集成 TextIn 产品的 API,不要慌,问题不大,返回上一页,选择集成 API 即可。
同样地,我们将文件上传至系统,然后点击“调用接口”的选项,系统就会自动处理并返回调用结果,这个过程既快捷又高效。如果在使用过程中遇到任何疑问或不清楚的地方,可以点击“查看文档”选项,就获取详细的操作指南和说明。
智能抽取 API
智能抽取 API 已更新至 v3:
https://api.textin.com/ai/service/v3/entity_extraction
支持的文件格式:png, jpg, jpeg, pdf, bmp, tiff, webp, doc, docx, html, mhtml, xls, xlsx, csv, ppt, pptx, txt, ofd;
支持schema模式的结构化信息抽取,通过定义字段结构进行精确抽取。
TextIn 产品优势
我总结一下 TextIn 这款产品的优势优势所在:
高精度识别:TextIn 产品采用先进的深度学习技术,具备高精度的识别能力,能够准确识别各种复杂场景下的文档内容。
丰富的识别类型:TextIn 产品支持多种类型的文档识别,包括通用文字、表格、印章等,满足用户多样化的需求。
灵活可定制:TextIn 产品提供灵活的 API 接口和 SDK,方便用户根据自身需求进行定制开发。
安全可靠:TextIn 产品采用严格的数据加密和权限控制机制,确保用户数据的安全性和隐私性。
效果指标
1. 时间对比(以 99 页说明书为例)
| 阶段 | 传统人工流程 | Agent 自动化流程 |
|---|---|---|
| 文档解析 | 人工检查 | 自动(分钟级) |
| 校对 | 1–2 天 | 自动 + 抽检 |
| 版本比对 | 半天 | 几分钟 |
| 总耗时 | 约 3 天 | 约 1 小时 |
2. 准确率变化
-
行业术语错误率:
下降约 90% -
版本遗漏问题:
几乎消失 -
人工角色转变为:
- 抽样检查
- 关键章节复核
3. 成本变化
| 项目 | 原方式 | 新方式 |
|---|---|---|
| 人力成本 | 高 | 显著降低 |
| 重复沟通 | 多 | 极少 |
| 返工成本 | 高 | 接近 0 |
| 流程复用性 | 低 | 高 |
总结
这次体验下来,我最大的感受只有一句话:
真正有价值的,不是“翻译能力”,而是“文档生命周期自动化”。
TextIn xParse + Agent 流程,本质上解决了三件长期被忽略的事:
- 把复杂说明书,变成“可计算的结构化资产”
- 把行业经验沉淀进系统,而不是依赖个人
- 把一次性工作,变成可复用、可扩展的流水线
对于芯片、工业、医疗、能源这些 “文档即产品一部分” 的行业来说,这种能力带来的不是效率提升,而是 交付模式的变化。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)