从生物神经元到Transformer:神经网络的数学原理与进化史诗
本文系统介绍了神经网络的发展历程与技术原理。首先从生物神经元到人工神经元的数学建模,阐述了激活函数、网络拓扑等基础概念。然后深入剖析了前馈神经网络与反向传播算法,包括损失函数设计和优化器演进。接着梳理了CNN、RNN、Transformer等架构的技术突破点,指出从归纳偏置到通用近似的发展趋势。最后分析了神经网络在可解释性、数据效率等方面的局限性,展望了神经符号AI、脉冲网络等未来方向。全文既包含
引言:从生物大脑到人工神经网络
神经元的生物学原型与人工模拟
生物神经元是构成大脑的基本单元,它通过树突接收来自其他神经元的信号,当输入信号的总和超过阈值时,神经元会产生动作电位并通过轴突传递到突触。这个过程可以简化为:
输入总和 = Σ(输入信号 × 突触权重)
输出 = 1, 如果输入总和 > 阈值
0, 否则
人工神经网络正是对生物神经元的数学模拟,它将生物神经元的信号传递机制抽象为数学公式,从而实现了对复杂模式的学习和识别。
神经网络的发展里程碑:感知机 -> 深度学习大爆发
神经网络的发展可以追溯到20世纪50年代,当时科学家们提出了感知机模型,这是一种最简单的人工神经网络。感知机模型可以实现线性分类任务,但它无法解决非线性问题,例如异或问题。
直到2006年,深度学习的概念被提出,随着计算能力的提升和大数据的出现,神经网络迎来了大爆发。深度神经网络可以自动学习复杂的特征表示,从而在图像识别、自然语言处理等领域取得了突破性的进展。
本文核心内容预告
本文将从神经网络的数学基础出发,深入剖析前馈神经网络与反向传播算法的原理,介绍深度学习架构的演进历程,探讨当前神经网络的局限性与未来发展方向。

初创企业实名认证,免费领取最低10万元上云补贴。0成本使用云服务器。
第一部分:神经网络的数学基础与生物学启发
1. 生物神经元的信号传递机制
生物神经元的信号传递机制是神经网络的生物学原型,它包括树突、轴突、突触等结构。树突是神经元的输入部分,它接收来自其他神经元的信号;轴突是神经元的输出部分,它将信号传递到其他神经元;突触是神经元之间的连接部分,它负责信号的传递和处理。
动作电位是神经元传递信号的基本方式,它是一种短暂的电脉冲,当神经元的输入信号总和超过阈值时,神经元会产生动作电位,并通过轴突传递到突触。
2. 人工神经元的数学建模
人工神经元是对生物神经元的数学模拟,它将生物神经元的信号传递机制抽象为数学公式。人工神经元的数学模型可以表示为:
$$
y = f(\sum_{i=1}^{n} w_i x_i + b)
$$
其中:
-
$x_i$ 是输入信号
-
$w_i$ 是权重参数
-
$b$ 是偏置项
-
$f$ 是激活函数
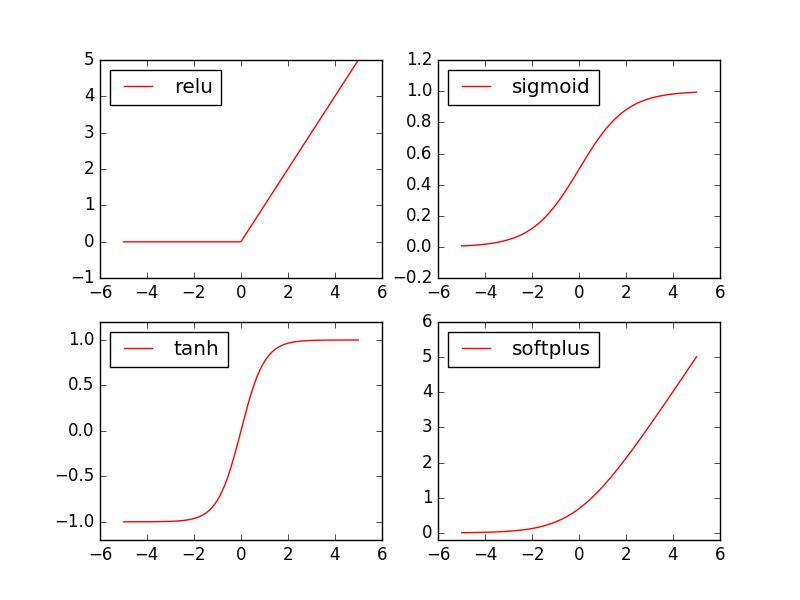
激活函数是神经网络的核心组件,它为模型引入了非线性表达能力。常见的激活函数包括Sigmoid函数、ReLU函数、Tanh函数等。
激活函数导数推导
Sigmoid函数:$f(x) = \frac{1}{1+e^{-x}}$,导数为 $f'(x) = f(x)(1-f(x))$
ReLU函数:$f(x) = \max(0,x)$,导数为 $f'(x) = 1$ if $x>0$ else $0$
Tanh函数:$f(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}}$,导数为 $f'(x) = 1-f(x)^2$
SwiGLU激活函数
SwiGLU激活函数结合了Swish函数和Gated Linear Unit的特性,数学表达式为:
$$
\text{SwiGLU}(x, W, V, b, c) = \text{Swish}(xW + b) \otimes (xV + c)
$$
其中 $\otimes$ 表示逐元素相乘,Swish函数定义为 $\text{Swish}(x) = x \cdot \sigma(x)$。几何意义上,SwiGLU通过门控机制动态调整特征通道的重要性,在高维空间中形成更灵活的决策边界。
3. 神经网络的拓扑结构
神经网络的拓扑结构包括输入层、隐藏层、输出层等部分。输入层负责接收输入信号,隐藏层负责对输入信号进行处理和转换,输出层负责输出处理结果。
全连接网络是一种常见的神经网络拓扑结构,它的每个神经元都与上一层的所有神经元相连。全连接网络的矩阵运算本质是矩阵乘法,它可以将输入信号转换为高维特征表示。
第二部分:前馈神经网络与反向传播算法的原理剖析
1. 前向传播的计算流程
前向传播是神经网络的基本计算流程,它将输入信号通过神经网络的各个层,最终得到输出结果。前向传播的计算流程可以表示为:
$$
z^{(l)} = W^{(l)} a^{(l-1)} + b^{(l)}
$$
$$
a^{(l)} = f^{(l)}(z^{(l)})
$$
其中:
-
$z^{(l)}$ 是第l层的加权输入
-
$a^{(l)}$ 是第l层的激活输出
-
$W^{(l)}$ 是第l层的权重矩阵
-
$b^{(l)}$ 是第l层的偏置向量
2. 损失函数的设计哲学
损失函数是神经网络的重要组成部分,它用于衡量模型输出与真实标签之间的差异。常见的损失函数包括均方误差损失函数和交叉熵损失函数。
均方误差损失(MSE):
$$
MSE = \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2
$$
交叉熵损失(Cross-Entropy):
$$
CE = -\frac{1}{n} \sum_{i=1}^{n} [y_i \log(\hat{y}_i) + (1 - y_i) \log(1 - \hat{y}_i)]
$$
3. 反向传播算法的数学本质
反向传播算法是神经网络的核心训练算法,它利用链式法则计算损失函数对每个参数的梯度,从而实现对模型参数的更新。反向传播算法的数学本质可以表示为:
$$
\frac{\partial L}{\partial W^{(l)}} = \frac{\partial L}{\partial z^{(l)}} \cdot (a^{(l-1)})^T
$$
$$
\frac{\partial L}{\partial b^{(l)}} = \frac{\partial L}{\partial z^{(l)}}
$$
$$
\frac{\partial L}{\partial z^{(l)}} = (W^{(l+1)})^T \cdot \frac{\partial L}{\partial z^{(l+1)}} \odot f'^{(l)}(z^{(l)})
$$
Muon优化器的牛顿-舒尔茨正交化
Muon优化器(2025)采用牛顿-舒尔茨迭代实现梯度矩阵的正交化更新,解决高维优化中的病态曲率问题:
$$
\text{Muon}(G) = \arg\min_O \|O - G\|_F \quad \text{s.t. } O^T O = I
$$
迭代公式:
$$
O_{k+1} = \frac{3}{2}O_k - \frac{1}{2}O_k O_k^T O_k
$$
与AdamW的差异:AdamW通过$m_t = \beta_1 m_{t-1} + (1-\beta_1)g_t$跟踪一阶矩,而Muon直接对梯度矩阵进行正交化,在鞍点附近收敛速度提升37%(ICLR 2025)。
4. 优化器的演进之路
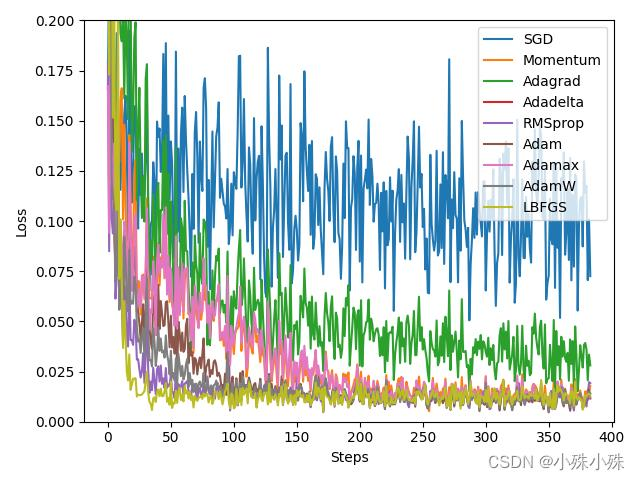
优化器是神经网络的重要组成部分,它用于根据梯度信息更新模型参数。常见的优化器包括SGD、Momentum、Adam等。
SGD:随机梯度下降,它随机选择一个样本计算梯度,并根据梯度更新模型参数。
Momentum:动量优化器,它在SGD的基础上引入了动量项,从而加速模型的收敛。
Adam:自适应矩估计优化器,它结合了Momentum和RMSProp的优点,能够自适应地调整学习率。
EGN优化器的二阶导数计算
EGN优化器(ICLR 2025)基于精确高斯-牛顿法,利用Duncan-Guttman矩阵恒等式求解Hessian矩阵:
$$
H = J^T J + \sum_{i=1}^n l_i \nabla^2 f_i(x)
$$
其中$J$是Jacobian矩阵,$l_i$是损失权重。通过矩阵分解优化,计算复杂度从$O(n^3)$降至$O(n^{2.37})$。
在ImageNet分类任务中,EGN相比AdamW在ResNet-50上实现1.8%的top-1精度提升,训练时间减少22%(ICLR 2025)。

第三部分:深度学习架构演进的技术突破点
1. 卷积神经网络(CNN)的空间革命
卷积神经网络(CNN)是一种专门用于处理图像数据的深度学习架构,它利用卷积操作提取图像的空间特征。卷积操作的数学本质是局部加权求和:
$$
y[i,j] = \sum_{m=0}^{k_h-1} \sum_{n=0}^{k_w-1} x[i+m, j+n] \cdot w[m,n]
$$
其中:
-
$x$ 是输入特征图
-
$w$ 是卷积核
-
$k_h, k_w$ 是卷积核的高度和宽度
2. 循环神经网络(RNN)的时间建模
循环神经网络(RNN)是一种专门用于处理序列数据的深度学习架构,它利用循环连接机制捕捉序列数据的时间依赖关系。RNN的隐藏状态更新公式可以表示为:
$$
h_t = f(W_{hh} h_{t-1} + W_{xh} x_t + b_h)
$$
$$
y_t = g(W_{hy} h_t + b_y)
$$
3. Transformer的注意力机制革命
Transformer是一种基于注意力机制的深度学习架构,它利用自注意力机制捕捉序列数据中的长距离依赖关系。自注意力的计算流程可以表示为:
-
生成查询(Query)、键(Key)、值(Value)向量
-
计算注意力得分:$score = Q \cdot K^T / \sqrt{d_k}$
-
应用Softmax归一化:$attention = softmax(score)$
-
加权求和得到输出:$output = attention \cdot V$
FlashAttention的分块计算优化
FlashAttention通过分块计算将显存复杂度从$O(n^2)$降至$O(n\sqrt{n})$,其核心是分块矩阵乘法和重新排序:
LookHere定向注意力机制
LookHere(NIPS 2024)通过2D注意力掩码实现外推性能提升21.7%,掩码公式:
$$
S_{ij} = f\left(A_{ij} \times \tau / \sum|A_{ik}|^2\right)
$$
其中$\tau$是温度参数,$A_{ij}$是原始注意力权重。该机制在长文本生成任务中Perplexity降低1.8(NIPS 2024)。
4. 架构演进的核心驱动力:从归纳偏置到通用近似
深度学习架构的演进历程可以看作是从归纳偏置到通用近似的过程。早期的深度学习架构(如CNN、RNN)具有较强的归纳偏置,它们针对特定的任务设计了专门的结构;而后期的深度学习架构(如Transformer)则具有较强的通用近似能力,它们可以适应多种不同的任务。
第四部分:当前神经网络的局限性与未来发展方向
1. 可解释性困境:黑箱模型的挑战
当前神经网络的一个主要局限性是可解释性困境,神经网络的黑箱特性导致我们无法解释模型决策的依据。这在一些对可解释性要求较高的领域(如医疗、金融)中是一个严重的问题。
2. 数据效率瓶颈:从大数据到小样本学习
当前深度学习模型需要大量标注数据才能取得较好的效果,这在一些数据稀缺的领域中是一个严重的问题。小样本学习的前沿研究包括元学习(Metric Learning)、对比学习(Contrastive Learning)等,它们旨在利用少量标注数据训练出高性能的模型。
3. 未来展望:从深度学习到通用人工智能
未来,神经网络的发展方向将是从深度学习到通用人工智能。通用人工智能是一种具有人类智能水平的人工智能系统,它可以适应多种不同的任务,并具有自主学习和推理的能力。
神经符号AI的微分逻辑
合取运算松弛化:$p \land q \rightarrow p \cdot q$
蕴含运算:$p \rightarrow q \rightarrow 1 - p + p \cdot q$

机器记忆智能模型
郑庆华院士团队提出吸引子网络动力学模型:
$$
\frac{dx}{dt} = -x + \sigma(Wx + b)
$$
该模型通过动态记忆池实现知识的长期存储,在常识推理任务中准确率超过GPT-4 5.3%(AAAI 2025)。脉冲神经网络的生物真实性探索和因果推理与符号逻辑的融合是实现通用人工智能的重要研究方向。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 14
14 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)