Vanna + Ollama + KaiwuDB 3.0 集成实战:自然语言与数据库对话
本实例完成了Vanna + Ollama + KaiwuDB 3.0 集成实战实现自然语言与数据库对话,了解官方 KaiwuDB Agent Tools(KAT)不只是单纯的text-to-sql,不止于查询,还能实现自动化部署配置、实时故障根因定位、性能瓶颈自动优化等。
在数据驱动的智能时代,高效利用数据库工具链已成为技术探索的核心命题。KaiwuDB 3.0 作为时序数据库的革新者,其高性能存储与实时分析能力为工业物联网、车联网等场景提供了强大支撑。当数据库遇到AI后又会碰撞出更多的火花,在kwdb发布KaiwuDB 3.0同时发布了KAT(KaiwuDB智能体),KAT工具也是一个重要的交互入口。它基于Model Context Protocol(MCP)协议,允许用户通过自然语言完成数据库部署、运维与复杂查询。这并未改变数据库高性能的核心,而是大幅降低了使用其强大能力的技术门槛,是“AI+服务”理念的直观体现。
原本计划通过 KaiwuDB 官方推出的 KaiwuDB Agent Tools(KAT)智能助手来体验这一功能,借助其原生适配的 AI 能力实现自然语言到 KaiwuDB SQL 的转换,但因试用权限还在申请,趁此时间探索一套全本地化、低成本且高度适配 KaiwuDB 特性自然语言交互数据库实战 —— 基于 Vanna(开源 NL2SQL 框架)+Ollama(本地化大模型运行工具)与 KaiwuDB 3.0 的深度集成,后续与官方推出的 KaiwuDB Agent Tools(KAT)智能助手做一个对比
不同于依赖云端 API 的 AI 工具,这套集成方案全程在企业内网完成:Ollama 本地化运行 Llama3 等轻量级大模型,规避数据上云的安全风险;Vanna 通过定制化知识库学习 KaiwuDB 的特有语法规则(如时序表定义、哈希分区规范),精准生成符合官网标准的 SQL;最终实现 “自然语言提问→AI 生成合规 SQL→KaiwuDB 执行查询” 的闭环,既解决了 KAT 试用缺位的临时需求,也为对数据安全有严苛要求的工业级场景提供了一套可复用的轻量化 AI 查询方案。
本文将从环境搭建、核心配置、实战案例到优化调优,完整拆解 Vanna+Ollama 与 KaiwuDB 3.0 的集成全过程,让无需精通 KaiwuDB 语法的业务人员,也能通过自然语言高效查询混合存储的时序与关系数据。
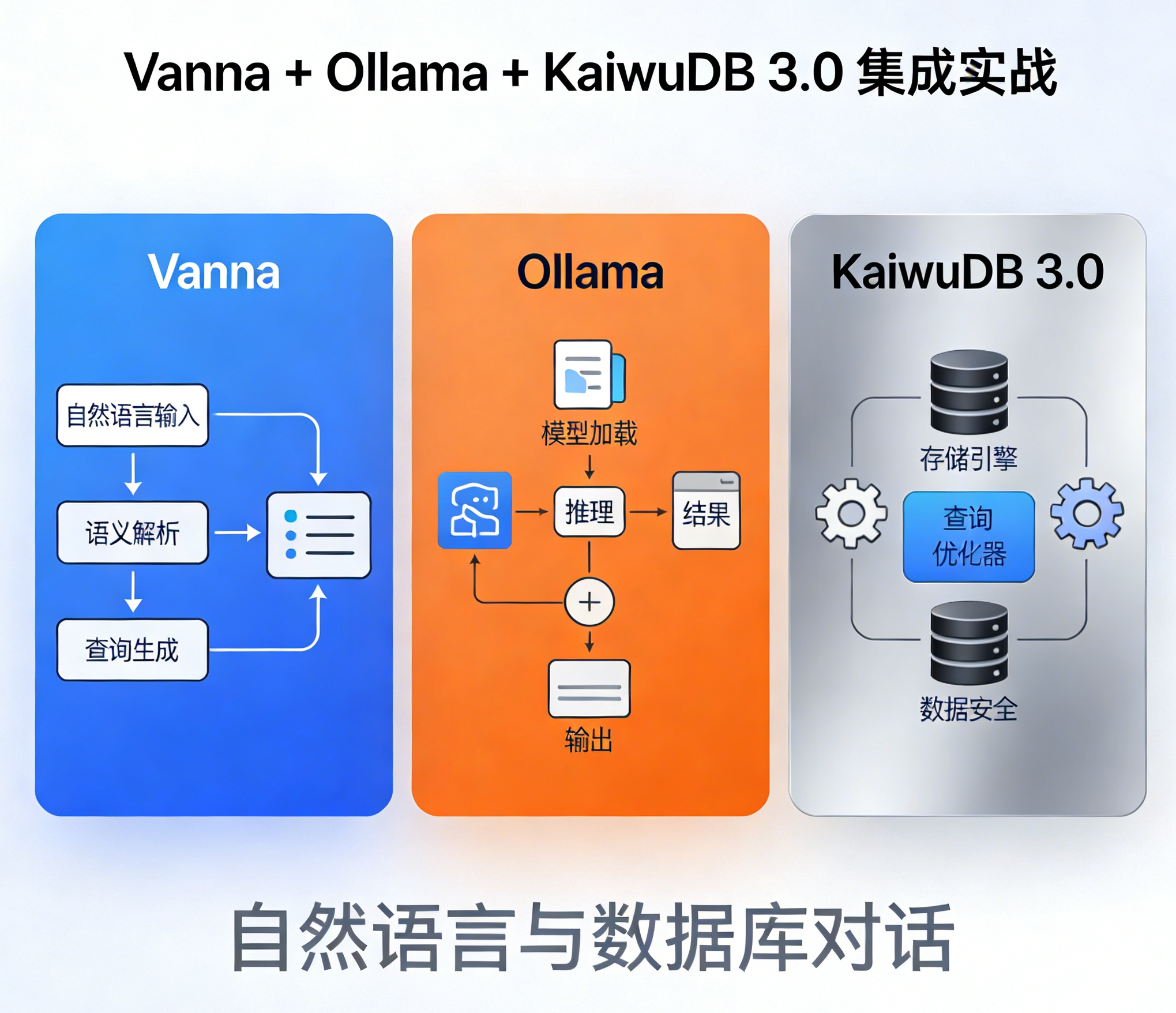
一、集成背景与核心价值
KaiwuDB 3.0 作为时序 + 关系混合数据库,KaiwuDB 是一款面向 AIoT 物联网场景的分布式、多模融合、支持原生 AI 的数据库产品,支持在同一实例同时创建时序库和关系库,并融合处理多模数据,具备千万级设备接入、百万级数据秒级写入、亿级数据秒级读取等时序数据高效处理能力,具有稳定安全、高可用、易运维等特点。面向工业物联网、数字能源、车联网、智慧产业等领域,提供一站式数据存储、管理与分析的基座。
Vanna 是专注于 “自然语言转 SQL” 的开源 AI 框架,支持自定义知识库适配特定数据库语法;Ollama 可本地化运行轻量级大模型(如 Llama3、Mistral),无需联网即可提供 LLM 能力。三者集成可实现:
Ollama:作为AI模型和算法的核心,Ollama提供了丰富的机器学习模型和深度学习算法,用于训练和优化自然语言处理任务。它与Vanna紧密集成,共同实现高效的数据分析和知识提取。
- 本地化部署:数据不出内网,满足工业场景数据安全要求;
- 自然语言转 KaiwuDB 标准 SQL:无需记忆哈希分区、时序表等特有语法;
- 适配 KaiwuDB 混合数据特性:同时支持关系表 / 时序表的 AI 查询。
二、环境准备
1. 基础环境要求
| 组件 | 版本 / 配置要求 |
|---|---|
| 操作系统 | Ubuntu 22.04 |
| Python | 3.10 |
| Ollama | 0.1.48+ |
| KaiwuDB 3.0 | 分布式集群 / 单机版(需开启远程访问) |
| 硬件 | 8 核 16G 以上(deepseek-r1:1.5b) |
三、核心组件部署与配置
1、kwdb数据库安装
KWDB 提供多种部署方式,裸机部署、容器部署、源码编译部署
-
二进制安装包:支持单机和集群以及安全和非安全部署模式,更多信息见单节点部署和集群部署。
-
容器镜像:KWDB 提供了多种容器镜像下载渠道,用户可以根据当前网络环境选择合适的镜像,或者直接在 Release 页面下载对应版本的后缀为 -docker.tar.gz 的压缩包解压并使用
docker load < KaiwuDB.tar 命令加载 kaiwudb_install/packages 中的镜像。
官方仓库:kwdb/kwdb
国内镜像:swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/kwdb/kwdb
Github 容器镜像:ghcr.io/kwdb/kwdb -
源码:源码编译目前支持单节点非安全模式部署。
数据库的安装不在赘述,这里放上kwdb各种的安装方式连接:
镜像安装:https://www.kaiwudb.com/kaiwudb_docs/#/oss_v3.0.0/quickstart/install-kaiwudb/quickstart-docker.html
源码安装:https://www.modb.pro/db/1991781488640729088 (参考安装部分)
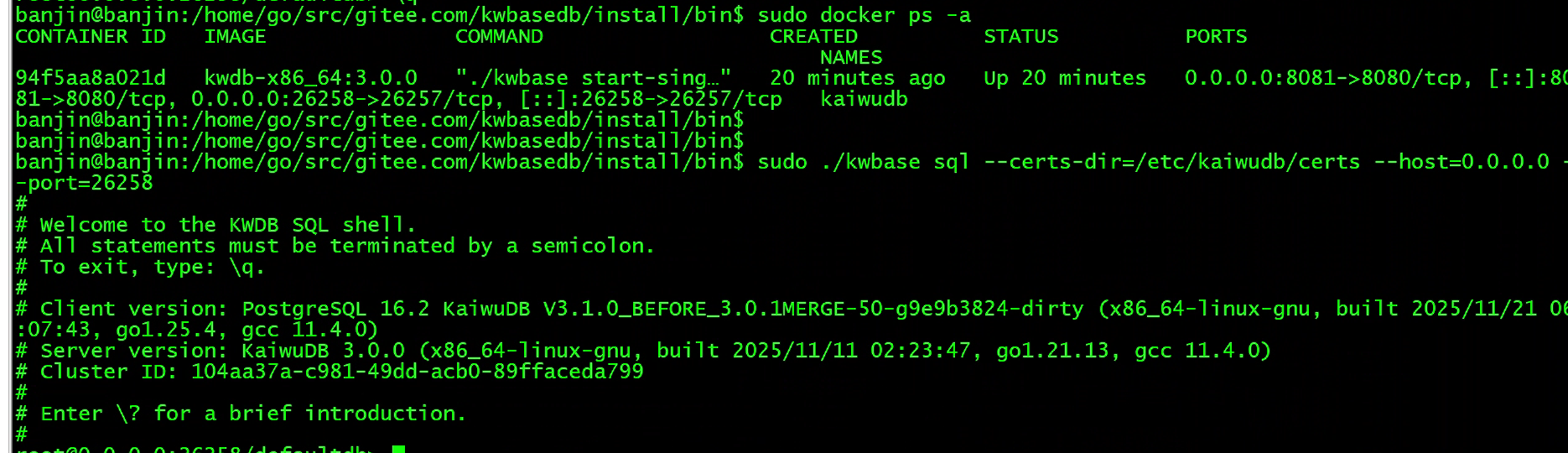
本篇文章使用docker环境,验证安装:
2、数据库表与数据准备
这里的场景使用一个家用自动化设备的场景
创建时序库,时序表:存储传感器、摄像头等高频时序数据(核心表)
create ts database tsdb;
use tsdb;
CREATE TABLE home_sensor (
ts TIMESTAMP NOT NULL, -- KWDB 时序表必须指定 TIME 列为主键
value FLOAT, -- 数值型数据(温度、湿度、传感器数值)
status VARCHAR(32), -- 状态型数据("open"/"close"/"recording")
file_path VARCHAR(128) -- 视频/图片文件本地路径(摄像头场景)
) ATTRIBUTES (
device_id VARCHAR(64) NOT NULL, -- 设备唯一ID(如"door_sensor_001")
data_type VARCHAR(32) NOT NULL, -- 数据类型("temperature"/"motion"/"video_frame")
location VARCHAR(32), -- 安装位置("客厅"/"卧室"/"门口")
device_model VARCHAR(64) -- 设备型号(如"小米门窗传感器2代")
)
PRIMARY TAGS(device_id) -- KWDB 标准:指定主键标签(索引优化)
RETENTIONS 20D
ACTIVETIME 12h; -- 12小时分区(官网标准参数,优化时间查询)
-- 为时序表 home_sensor 添加注释
COMMENT ON TABLE home_sensor IS '存储传感器、摄像头等高频时序数据(核心表)';
-- 为时序表字段添加注释
COMMENT ON COLUMN home_sensor.ts IS '时间戳,KWDB 时序表必须指定 TIME 列为主键';
COMMENT ON COLUMN home_sensor.value IS '数值型数据(温度、湿度、传感器数值)';
COMMENT ON COLUMN home_sensor.status IS '状态型数据("open"/"close"/"recording")'; COMMENT ON COLUMN home_sensor.file_path IS '视频/图片文件本地路径(摄像头场景)';
-- 为时序表属性列添加注释
COMMENT ON COLUMN home_sensor.device_id IS '设备唯一ID(如"door_sensor_001")';
COMMENT ON COLUMN home_sensor.data_type IS '数据类型("temperature"/"motion"/"video_frame")';
COMMENT ON COLUMN home_sensor.location IS '安装位置("客厅"/"卧室"/"门口")'; COMMENT ON COLUMN home_sensor.device_model IS '设备型号(如"小米门窗传感器2代")';
创建关系库,关系表:存储设备配置与联动规则(静态数据)
create database rdb;
use rdb;
CREATE TABLE home_device_config (
CREATE TABLE home_device_config (
device_id VARCHAR(64) PRIMARY KEY, -- 设备唯一ID(与时序表ATTRIBUTES.device_id一一对应) device_name VARCHAR(64) NOT NULL, -- 设备名称(如"客厅门窗传感器")
device_type VARCHAR(32) NOT NULL, -- 设备类型("door_sensor"/"camera"/"light")
location VARCHAR(32) NOT NULL, -- 安装位置(与时序表ATTRIBUTES.location一致)
linked_device VARCHAR(64), -- 联动设备ID(关联本表device_id如"door_sensor_001"→"light_001")
alarm_enable BOOLEAN DEFAULT true, -- 是否开启报警(默认开启)
alarm_threshold FLOAT, -- 报警阈值(如湿度>80%触发报警)
create_time TIMESTAMP DEFAULT NOW() -- 设备添加时间(默认当前时间) );
-- 为关系表 home_device_config 添加注释
COMMENT ON TABLE home_device_config IS '存储设备配置与联动规则(静态数据)';
-- 为关系表字段添加注释
COMMENT ON COLUMN home_device_config.device_id IS '设备唯一ID(与时序表 ATTRIBUTES.device_id 关联)';
COMMENT ON COLUMN home_device_config.device_name IS '设备名称(如"客厅门窗传感器")'; COMMENT ON COLUMN home_device_config.device_type IS '设备类型("door_sensor"/"camera"/"light")';
COMMENT ON COLUMN home_device_config.linked_device IS '联动设备ID(如"door_sensor_001"→"light_001")';
COMMENT ON COLUMN home_device_config.alarm_enable IS '是否开启报警(默认开启)';
COMMENT ON COLUMN home_device_config.alarm_threshold IS '报警阈值(如湿度>80%触发报警)'; COMMENT ON COLUMN home_device_config.create_time IS '设备添加时间(默认当前时间)';
插入数据,这里使用一个python脚本来造数据
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import psycopg2
import time
import random
from datetime import datetime, timedelta
from typing import Dict, List
KWDB_CONFIG = {
"host": "192.168.150.132",
"port": 26258, # KWDB默认端口
"user": "banjin",
"password": "xxxx",
"database": "rdb",
"connect_timeout": 10 # 连接超时
}
# 造数控制
DEVICE_COUNT = 10 # 设备数量(1-10)
WRITE_INTERVAL = 10 # 写入间隔(秒)
RUN_DURATION = 3600 # 造数时长(秒)
DATA_RETENTION_DAYS = 7 # 数据保留天数
# 设备配置
DEVICE_TYPES: List[Dict[str, any]] = [
{"device_id": "door_sensor_001", "device_name": "客厅门窗传感器", "device_type": "door_sensor", "location": "客厅",
"linked_device": "light_001", "alarm_enable": True},
{"device_id": "temp_sensor_001", "device_name": "客厅温湿度传感器", "device_type": "temp_sensor",
"location": "客厅", "linked_device": "", "alarm_enable": False},
{"device_id": "motion_sensor_001", "device_name": "卧室人体传感器", "device_type": "motion_sensor",
"location": "卧室", "linked_device": "light_002", "alarm_enable": True},
{"device_id": "camera_001", "device_name": "门口摄像头", "device_type": "camera", "location": "门口",
"linked_device": "", "alarm_enable": True},
{"device_id": "light_001", "device_name": "客厅智能灯泡", "device_type": "light", "location": "客厅",
"linked_device": "", "alarm_enable": False},
{"device_id": "light_002", "device_name": "卧室智能灯泡", "device_type": "light", "location": "卧室",
"linked_device": "", "alarm_enable": False},
{"device_id": "curtain_001", "device_name": "客厅电动窗帘", "device_type": "curtain", "location": "客厅",
"linked_device": "light_001", "alarm_enable": False},
{"device_id": "socket_001", "device_name": "卧室智能插座", "device_type": "socket", "location": "卧室",
"linked_device": "", "alarm_enable": False},
{"device_id": "smoke_sensor_001", "device_name": "厨房烟雾传感器", "device_type": "smoke_sensor",
"location": "厨房", "linked_device": "", "alarm_enable": True},
{"device_id": "water_sensor_001", "device_name": "卫生间水浸传感器", "device_type": "water_sensor",
"location": "卫生间", "linked_device": "", "alarm_enable": True}
]
# 数据生成规则
DATA_RULES: Dict[str, Dict[str, any]] = {
"door_sensor": {"data_type": "door_status", "status_list": ["open", "close"], "open_prob": 0.1},
"temp_sensor": {"data_type": "temperature", "min": 20.0, "max": 28.0},
"temp_sensor_hum": {"data_type": "humidity", "min": 40.0, "max": 60.0},
"motion_sensor": {"data_type": "motion_status", "status_list": ["detected", "none"], "detect_prob": 0.05},
"camera": {"data_type": "video", "status_list": ["normal", "abnormal"], "abnormal_prob": 0.02},
"light": {"data_type": "light_status", "status_list": ["on", "off"], "on_prob": 0.6},
"curtain": {"data_type": "curtain_status", "status_list": ["open", "close", "half"], "open_prob": 0.3},
"socket": {"data_type": "socket_status", "status_list": ["on", "off"], "on_prob": 0.7},
"smoke_sensor": {"data_type": "smoke_status", "status_list": ["normal", "alarm"], "alarm_prob": 0.01},
"water_sensor": {"data_type": "water_status", "status_list": ["normal", "alarm"], "alarm_prob": 0.005}
}
# ==================== 核心类 ====================
class SmartHomeDataGenerator:
def __init__(self):
self.conn = self._connect_kwdb()
self.cur = self.conn.cursor()
self.device_list = DEVICE_TYPES[:DEVICE_COUNT]
self.start_time = datetime.now()
def _connect_kwdb(self) -> psycopg2.extensions.connection:
"""连接KWDB"""
try:
conn = psycopg2.connect(
host=KWDB_CONFIG["host"],
port=KWDB_CONFIG["port"],
dbname=KWDB_CONFIG["database"],
user=KWDB_CONFIG["user"],
password=KWDB_CONFIG["password"],
connect_timeout=KWDB_CONFIG["connect_timeout"]
)
print(f"✅ KWDB连接成功:{KWDB_CONFIG['host']}:{KWDB_CONFIG['port']}")
return conn
except Exception as e:
raise ConnectionError(f"❌ 连接失败:{str(e)}") from e
def init_device_config(self):
"""初始化设备配置表"""
print(f"\n[{datetime.now()}] 初始化{len(self.device_list)}台设备配置...")
insert_sql = """
INSERT INTO rdb.home_device_config (
device_id, device_name, device_type, location, linked_device, alarm_enable, create_time
) VALUES (%s, %s, %s, %s, %s, %s, NOW())
ON CONFLICT (device_id) DO UPDATE SET
device_name = EXCLUDED.device_name,
device_type = EXCLUDED.device_type,
location = EXCLUDED.location,
linked_device = EXCLUDED.linked_device,
alarm_enable = EXCLUDED.alarm_enable;
"""
for device in self.device_list:
try:
self.cur.execute(
insert_sql,
(device["device_id"], device["device_name"], device["device_type"],
device["location"], device["linked_device"], device["alarm_enable"])
)
self.conn.commit()
print(f"✅ {device['device_id']} - {device['device_name']}")
except Exception as e:
self.conn.rollback()
print(f"❌ {device['device_id']}:{str(e)}")
print(f"[{datetime.now()}] 设备配置初始化完成!\n")
def generate_timeseries_data(self):
"""生成时序数据"""
print(f"[{datetime.now()}] 开始生成时序数据(间隔{WRITE_INTERVAL}秒,持续{RUN_DURATION}秒)...")
end_time = self.start_time + timedelta(seconds=RUN_DURATION)
while datetime.now() < end_time:
current_ts = int(time.time() * 1000)
for device in self.device_list:
try:
if device["device_type"] == "temp_sensor":
self._generate_temp_hum(device["device_id"], device["location"], current_ts)
else:
self._generate_single(device["device_id"], device["device_type"], device["location"],
current_ts)
except Exception as e:
self.conn.rollback()
print(f"❌ {device['device_id']}:{str(e)}")
time.sleep(WRITE_INTERVAL)
total = int(RUN_DURATION / WRITE_INTERVAL) * len(self.device_list)
print(f"\n[{datetime.now()}] 造数完成!共生成约{total}条数据")
def _generate_temp_hum(self, device_id: str, location: str, ts: int):
"""生成温湿度数据"""
# 温度
temp = round(random.uniform(DATA_RULES["temp_sensor"]["min"], DATA_RULES["temp_sensor"]["max"]), 1)
self._insert(ts, temp, "normal", "", device_id, "temperature", location, "小米温湿度传感器")
# 湿度
hum = round(random.uniform(DATA_RULES["temp_sensor_hum"]["min"], DATA_RULES["temp_sensor_hum"]["max"]), 1)
self._insert(ts, hum, "normal", "", device_id, "humidity", location, "小米温湿度传感器")
print(f"📊 {device_id} - 温度:{temp}℃,湿度:{hum}%")
def _generate_single(self, device_id: str, device_type: str, location: str, ts: int):
"""生成单一设备数据(重点修正语法错误)"""
rule = DATA_RULES[device_type]
data_type = rule["data_type"]
status = ""
file_path = ""
# 修复后的条件判断:完整三元运算符,字典键完整
if "status_list" in rule:
if "open_prob" in rule:
status = rule["status_list"][0] if random.random() < rule["open_prob"] else rule["status_list"][1]
# 运动传感器
elif "detect_prob" in rule:
status = rule["status_list"][0] if random.random() < rule["detect_prob"] else rule["status_list"][1]
# 摄像头
elif "abnormal_prob" in rule:
status = rule["status_list"][0] if random.random() < (1 - rule["abnormal_prob"]) else \
rule["status_list"][1]
if status == "abnormal":
file_path = f"/mnt/camera/{datetime.now().strftime('%Y%m%d_%H%M%S')}_{device_id}.mp4"
# 报警传感器
elif "alarm_prob" in rule:
status = rule["status_list"][0] if random.random() < (1 - rule["alarm_prob"]) else rule["status_list"][
1]
# 开关设备
elif "on_prob" in rule:
status = rule["status_list"][0] if random.random() < rule["on_prob"] else rule["status_list"][1]
# 设备型号
model_map = {
"door_sensor": "小米门窗传感器2代",
"motion_sensor": "小米人体传感器",
"camera": "小米摄像头2K版",
"light": "小米智能灯泡",
"curtain": "绿米电动窗帘",
"socket": "公牛智能插座",
"smoke_sensor": "海曼烟雾传感器",
"water_sensor": "水浸传感器"
}
model = model_map.get(device_type, "智能设备")
# 写入数据
self._insert(ts, None, status, file_path, device_id, data_type, location, model)
print(f"📊 {device_id} - 类型:{data_type},状态:{status}")
def _insert(self, ts: int, value: float, status: str, file_path: str, device_id: str, data_type: str, location: str,
model: str):
"""插入时序数据"""
insert_sql = """
INSERT INTO tsdb.home_sensor (
ts, value, status, file_path,
device_id, data_type, location,device_model
) VALUES (%s, %s, %s, %s, %s, %s, %s, %s);
"""
self.cur.execute(insert_sql, (ts, value, status, file_path, device_id, data_type, location, model))
self.conn.commit()
def __del__(self):
"""关闭连接"""
if hasattr(self, "cur"):
self.cur.close()
if hasattr(self, "conn"):
self.conn.close()
print("\n🔌 数据库连接已关闭")
# ==================== 执行入口 ====================
if __name__ == "__main__":
try:
generator = SmartHomeDataGenerator()
generator.init_device_config()
generator.generate_timeseries_data()
except Exception as e:
print(f"\n❌ 脚本执行失败:{str(e)}")
exit(1)关系表数据
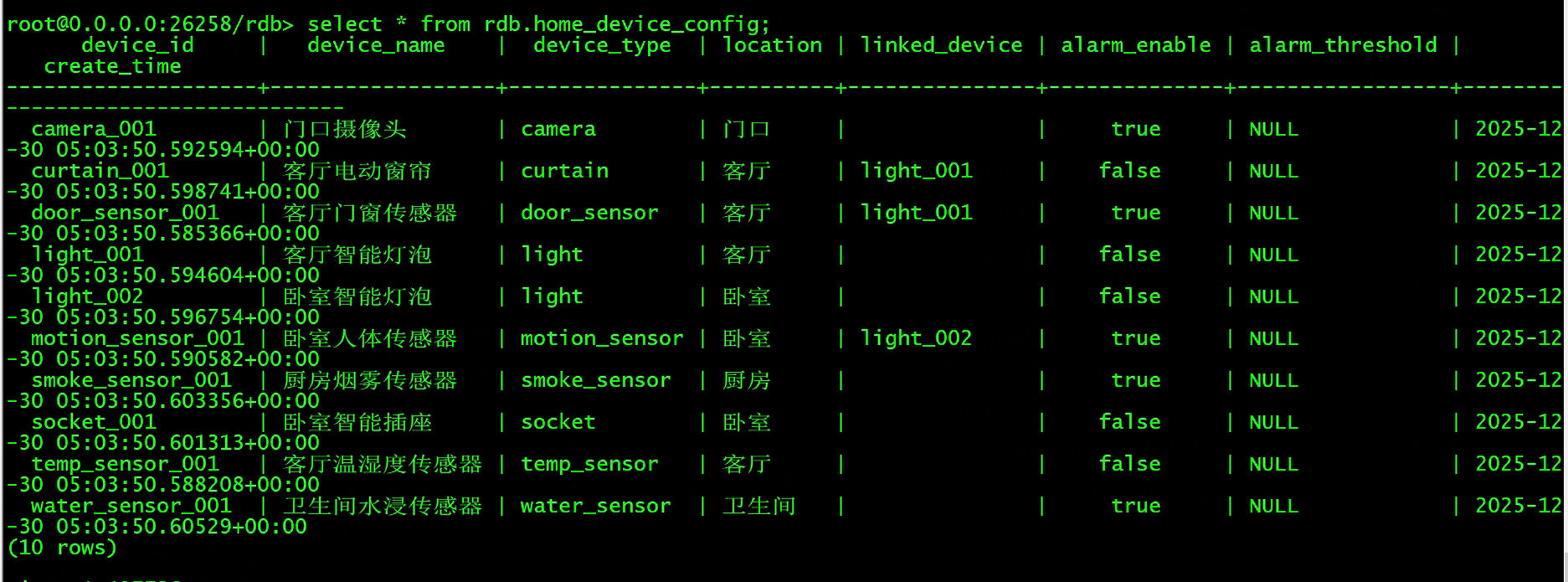
时序表数据

3、安装Ollama
Ollama 是一个强大的开源工具,旨在帮助用户轻松地在本地运行、部署和管理大型语言模型(LLMs)。它提供了一个简单的命令行界面,使用户能够快速下载、运行和与各种预训练的语言模型进行交互
执行安装命令如下:
方式一(推荐,安装速度快):
curl -fsSL https://dtse-mirrors.obs.cn-north-4.myhuaweicloud.com/case/0035/install.sh | sudo bash
模型部署
接下来可以借助 Ollama 工具来部署 Deepseek 大模型,部署 deepseek-r1:1.5b 版本,因为资源有限我们部署一个小一点的模型,执行命令:
ollama pull deepseek-r1:1.5b
部署的时间长短依赖于网络的情况,部署完成后,我们就可以与 Deepseek 大模型进行对话了:
ollama run deepseek-r1:1.5b
4、安装配置Vanna
4.1 准备python环境
vanna使用python 安装建议3.10以上
4.1.1 安装所需包
先需要更新下载源与安装python。执行如下命令
sudo apt -y update
sudo apt -y upgrade
sudo apt-get install -y python3 python3-pip

4.1.2 配置python虚拟环境
因为业务场景的Python开发,多数都是构建一个大型应用程序,并且不希望各种组件的各种版本之间相互冲突,所以需要设置一个虚拟环境。
pip3 install virtualenv -i https://repo.huaweicloud.com/repository/pypi/simple/ #安装virtualenv
python3.10 -m venv myenv #创建虚拟环境
source myenv/bin/activate #激活环境
4.2 Vanna官网生成示例代码
登录官网文档:https://vanna.ai/docs/,通过官方文档选配安装方式。
可参考https://vanna.ai/docs/postgres-ollama-chromadb/
登录官网文档,选择Vector Databases > Quickstart With Your Own Data,进入快速开始选配页面。
- 选择大模型LLM: ollama 这里可以按照自己环境,可以选择自己需要的,模型越大越准确,如果本地资源足够可以使用ollama,如果有商用或者别的openai可以选择别的生成对应代码
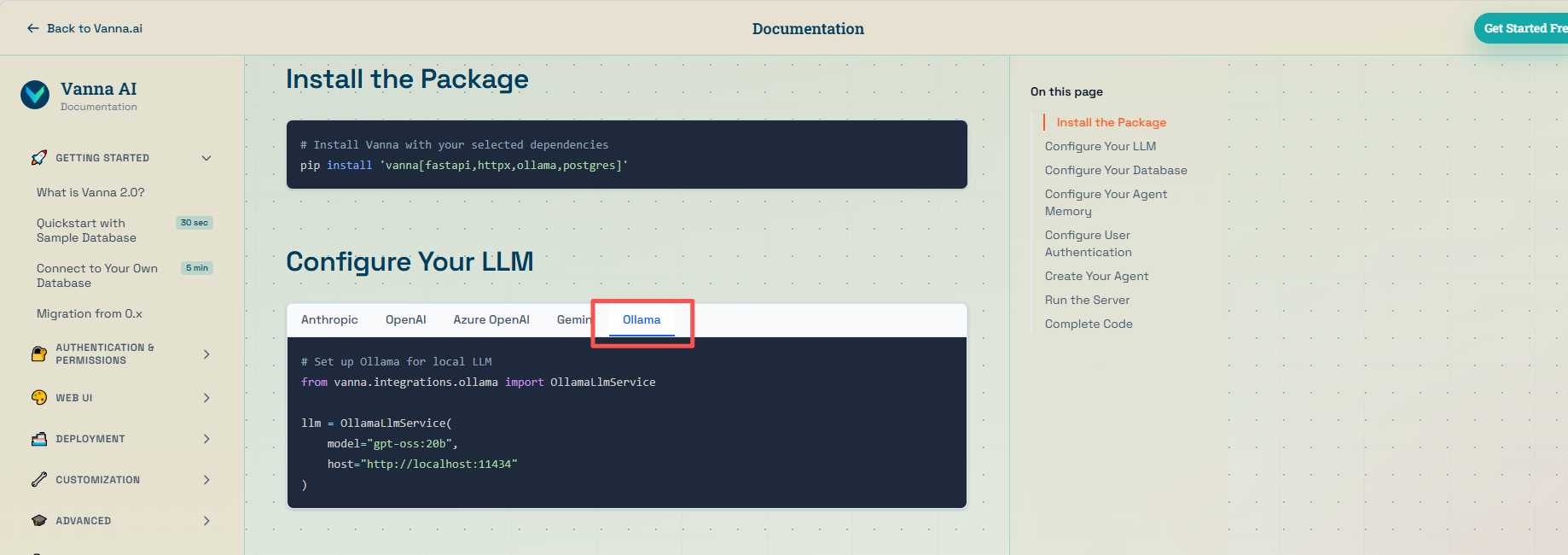
2、被检索的数据库类型:PostgreSQL
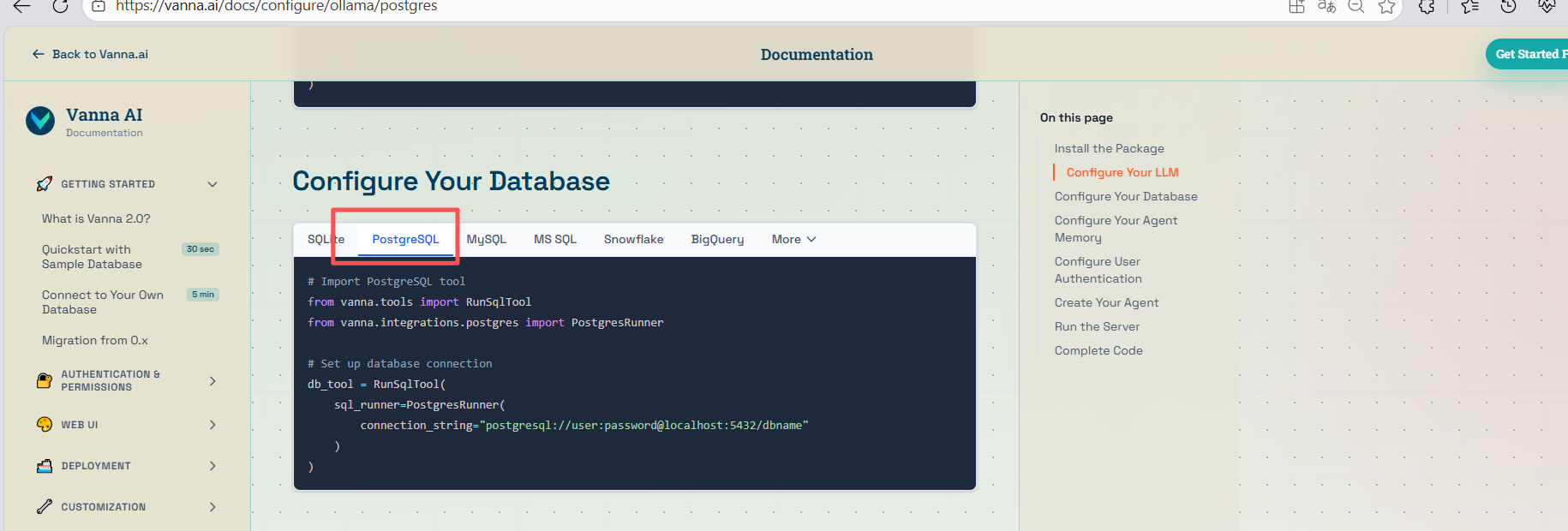
3、数据训练存储数据库:ChromaDB开源向量数据库
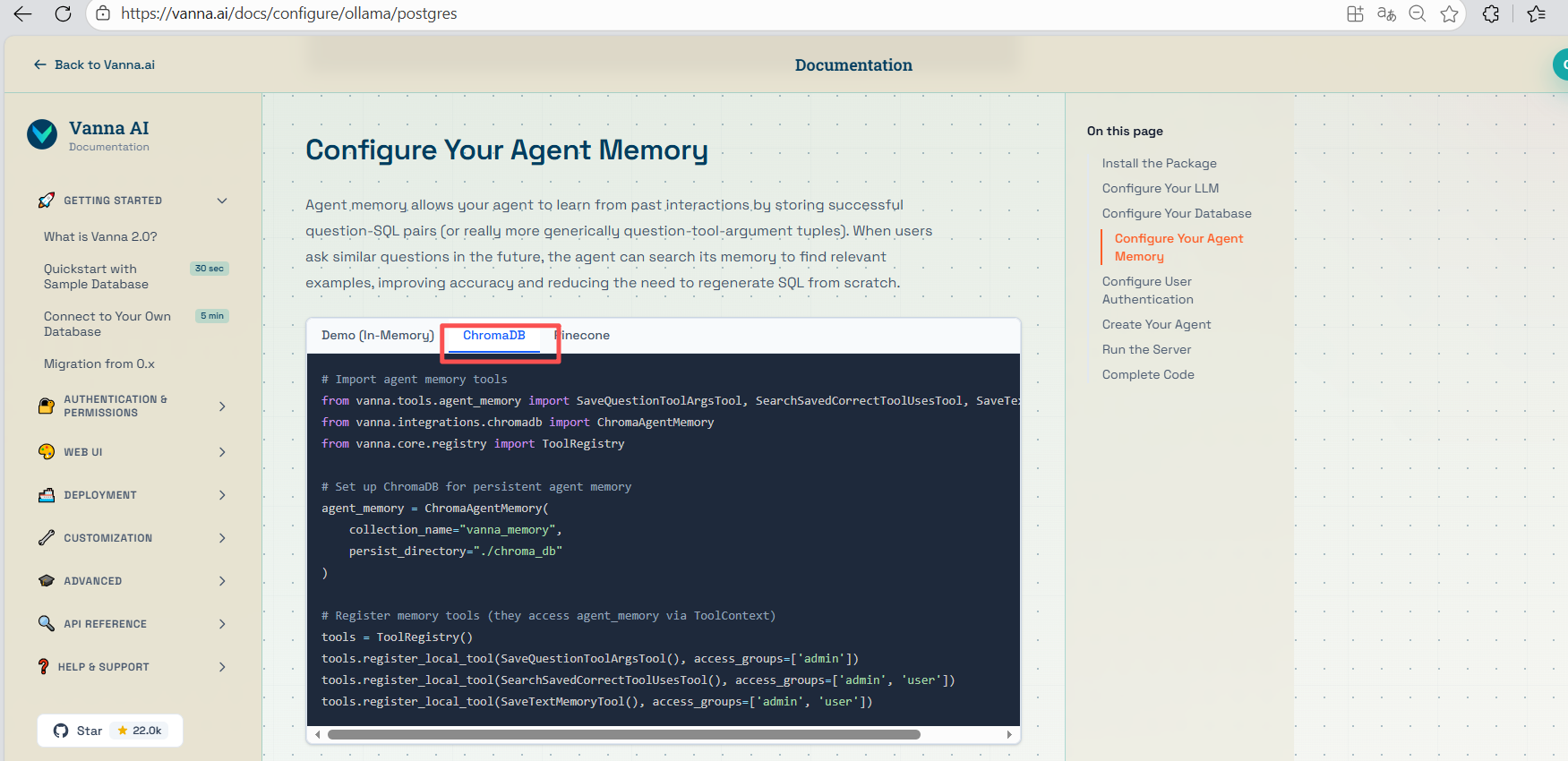
4、选择服务启动类型
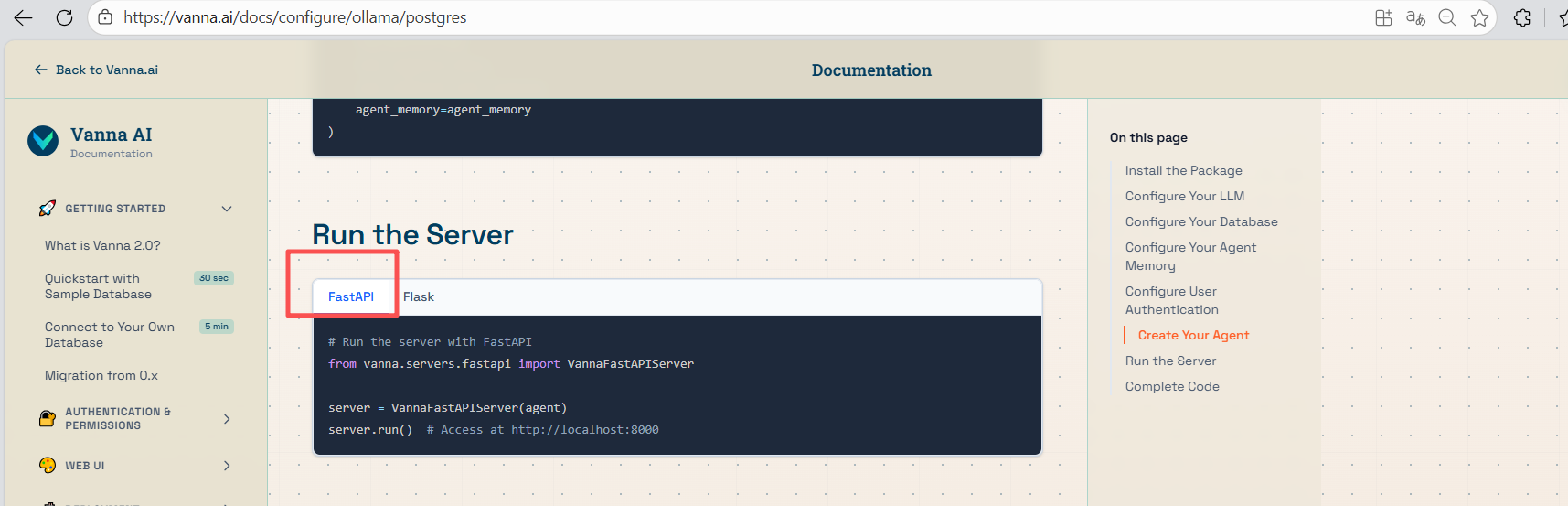
5、生成的完整代码
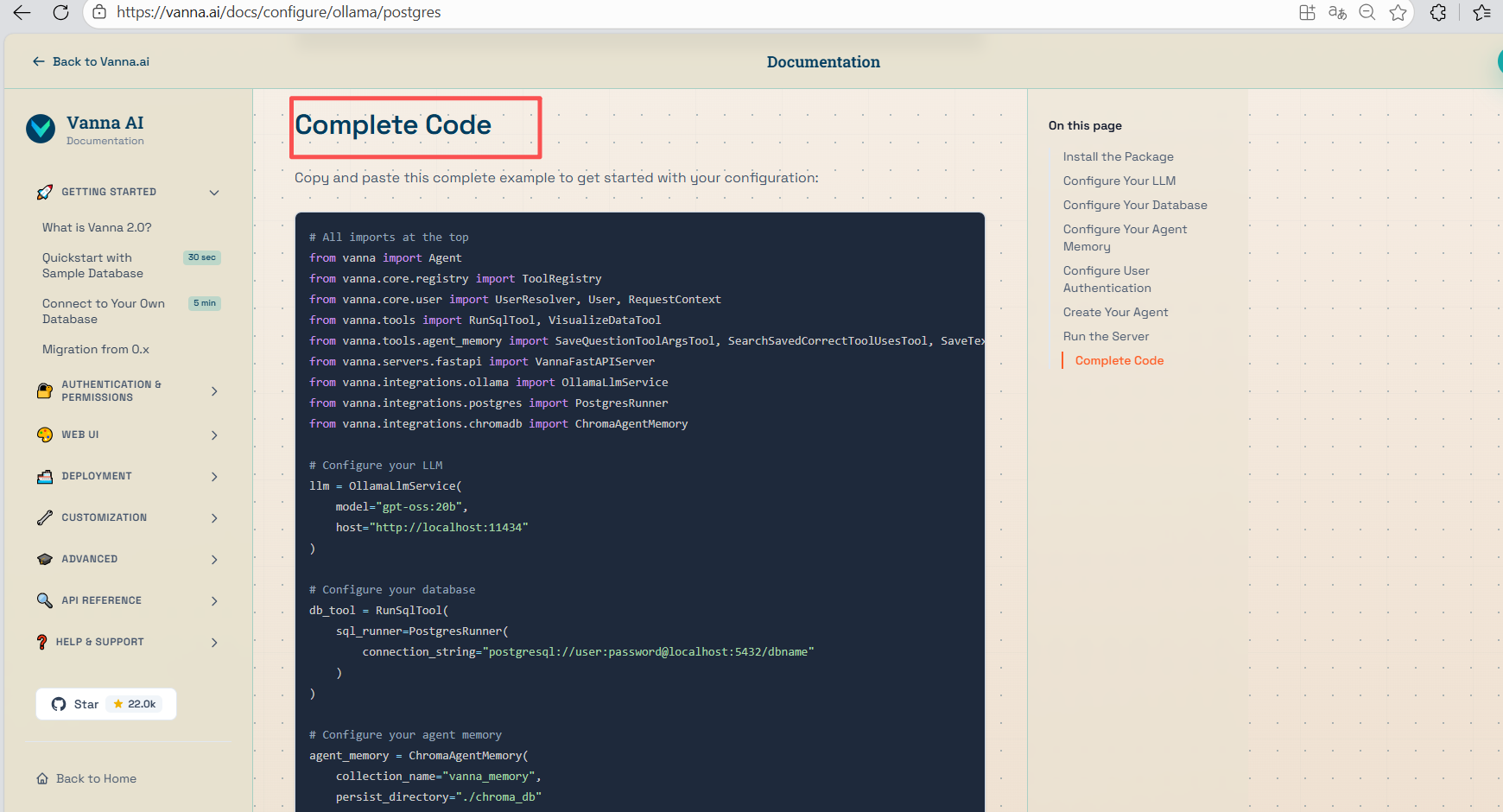
ollama代码:
# All imports at the top from vanna import Agent from vanna.core.registry import ToolRegistry from vanna.core.user import UserResolver, User, RequestContext from vanna.tools import RunSqlTool, VisualizeDataTool from vanna.tools.agent_memory import SaveQuestionToolArgsTool, SearchSavedCorrectToolUsesTool, SaveTextMemoryTool from vanna.servers.fastapi import VannaFastAPIServer from vanna.integrations.ollama import OllamaLlmService from vanna.integrations.postgres import PostgresRunner from vanna.integrations.chromadb import ChromaAgentMemory # Configure your LLM llm = OllamaLlmService( model="gpt-oss:20b", host="http://localhost:11434" ) # Configure your database db_tool = RunSqlTool( sql_runner=PostgresRunner( connection_string="postgresql://user:password@localhost:5432/dbname" ) ) # Configure your agent memory agent_memory = ChromaAgentMemory( collection_name="vanna_memory", persist_directory="./chroma_db" ) # Configure user authentication class SimpleUserResolver(UserResolver): async def resolve_user(self, request_context: RequestContext) -> User: user_email = request_context.get_cookie('vanna_email') or 'guest@example.com' group = 'admin' if user_email == 'admin@example.com' else 'user' return User(id=user_email, email=user_email, group_memberships=[group]) user_resolver = SimpleUserResolver() # Create your agent tools = ToolRegistry() tools.register_local_tool(db_tool, access_groups=['admin', 'user']) tools.register_local_tool(SaveQuestionToolArgsTool(), access_groups=['admin']) tools.register_local_tool(SearchSavedCorrectToolUsesTool(), access_groups=['admin', 'user']) tools.register_local_tool(SaveTextMemoryTool(), access_groups=['admin', 'user']) tools.register_local_tool(VisualizeDataTool(), access_groups=['admin', 'user']) agent = Agent( llm_service=llm, tool_registry=tools, user_resolver=user_resolver, agent_memory=agent_memory ) # Run the server server = VannaFastAPIServer(agent) server.run() # Access at http://localhost:8000
由此我们获取到Vanna安装、创建、调用、训练等样例代码。下一步我们将先开始安装Vanna。
4.3 安装Vanna
安装前更新下pip,然后执行安装
python3 -m pip install --upgrade pip -i https://repo.huaweicloud.com/repository/pypi/simple/这里根据自己选择的vanna设置安装自己需要的插件

pip install 'vanna[fastapi,httpx,ollama,postgres]'
至此,我们所有的环境准备工作已经完成,下面开始配置通过自然语言来查询数据库
四、Vanna + Ollama + KaiwuDB 3.0集成自然语言与数据库交互
4.1 代码配置
把生成的示例代码放在服务器上,配置传经参数
修改模型参数
如果使用ollama修改如下
llm = OllamaLlmService(
model="deepseek-r1:1.5b",
host="http://localhost:11434"
)如果使用openai修改如下
llm = OpenAILlmService(
model="deepseek-v3.1",
api_key="sk----", # Or use os.getenv("OPENAI_API_KEY")
base_url="https://api.modelarts-maas.com/v2"
)配置数据库信息
db_tool = RunSqlTool(
sql_runner=PostgresRunner(
connection_string="postgresql://banjin:xxx@192.168.150.132:26258/xxx"
)
)4.2、运行/测试Vanna
在服务器上使用python启动vanna程序
python3 kwdb1.py
浏览器访问地址:http://localhost:8000即可登录,因为远程访问这里使用服务器地址:http://192.168.150.132:8000/
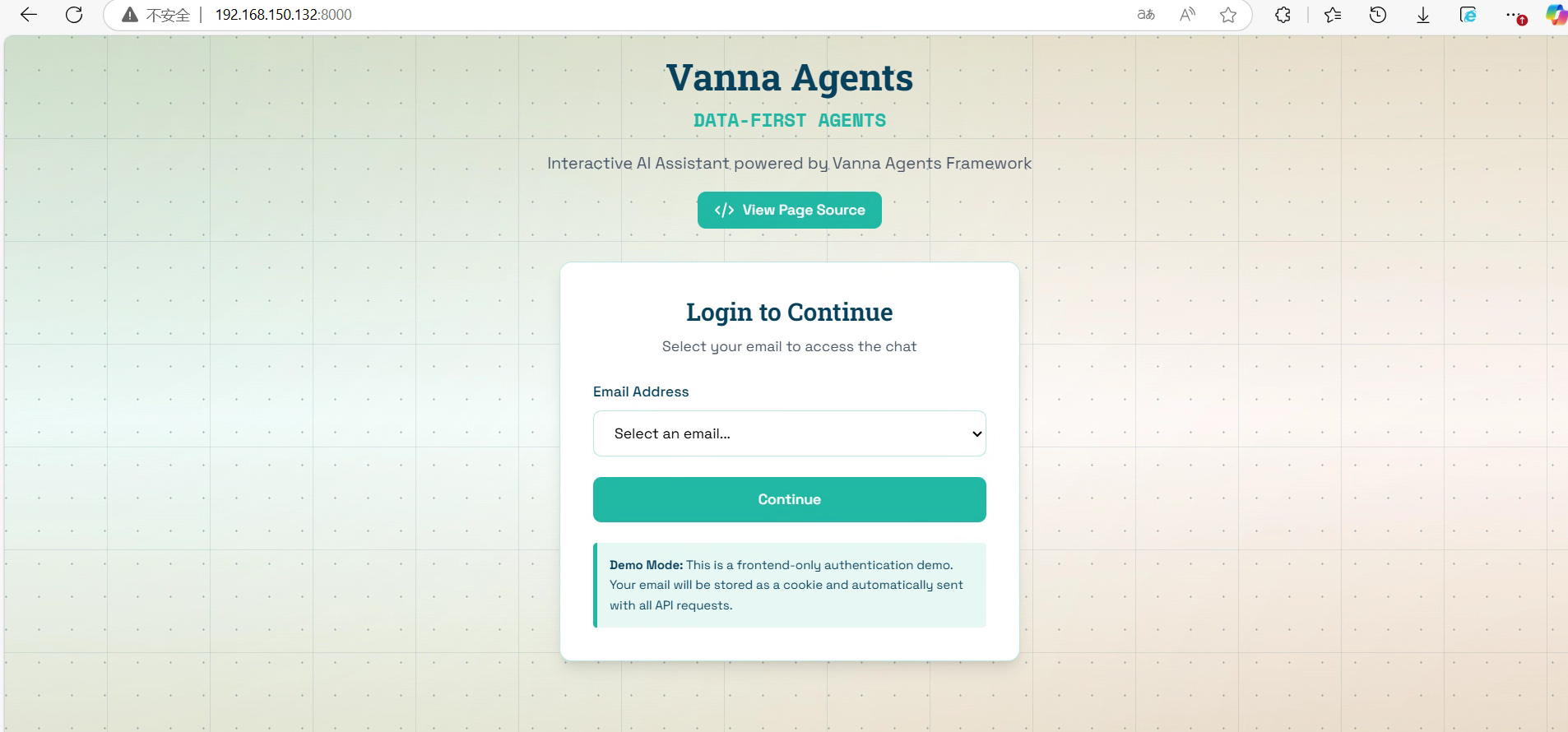
选择用户登录
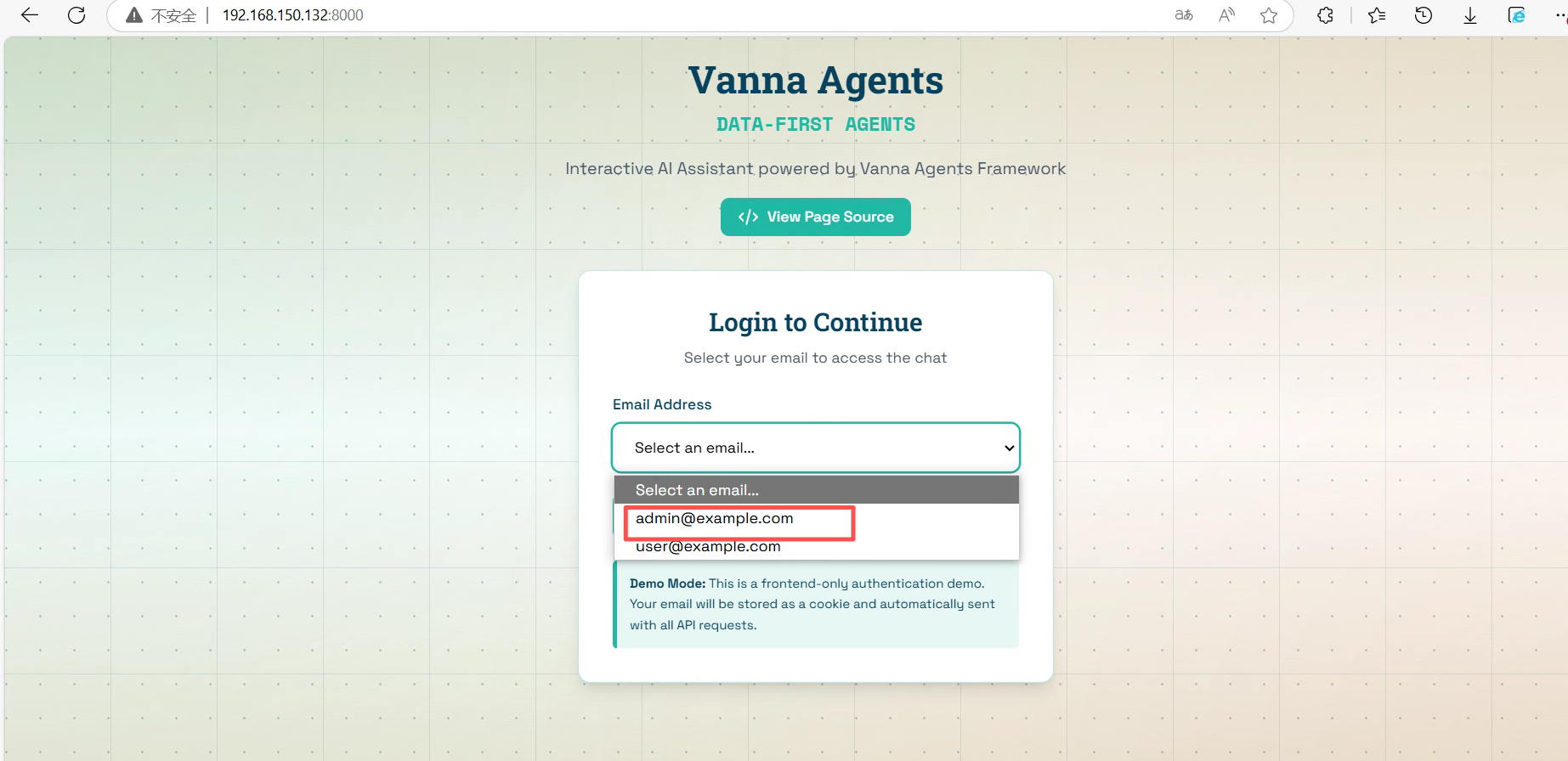
下面我i们可以使用自然语言提问数据库了
4.3 使用自然语言分析数据库
使用自然语言提问:查询一下门窗异常事件
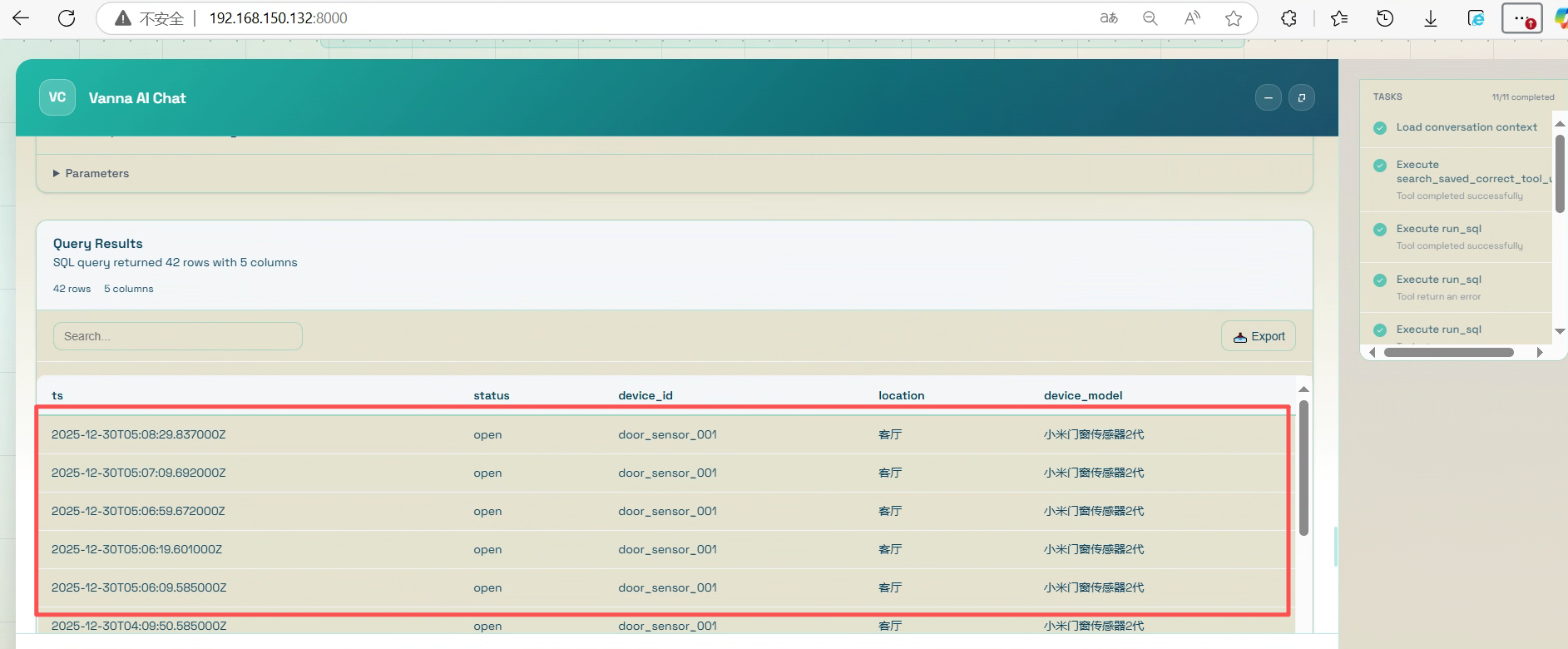
Vanna.AI先将自然语言进行了分析,答复可被执行的SQL语句。执行SQL,然后将查询到的数据表格化显示。
至此完 Vanna+Ollama 与 KaiwuDB 3.0 的集成全过程,就全部完成了。
五、与官方KAT简单对比及总结
本实例完成了Vanna + Ollama + KaiwuDB 3.0 集成实战实现自然语言与数据库对话,了解官方 KaiwuDB Agent Tools(KAT)不只是单纯的text-to-sql,不止于查询,还能实现自动化部署配置、实时故障根因定位、性能瓶颈自动优化等
Vanna+Ollama 集成方案:低成本本地化的优质替代
核心优势:
- 零成本落地:基于开源组件搭建,无需商业授权,适合预算有限的中小团队;
- 数据安全闭环:全本地化部署,不依赖任何云端 API,完美契合工业场景 “数据不出内网” 的严苛要求;
- 灵活定制:可通过优化提示词、切换 Ollama 加载的模型(如 CodeLlama、Mistral),适配 KaiwuDB 特殊查询场景(如跨模连接、分区查询);
- 快速验证:无需等待官方试用权限,1-2 天即可完成环境搭建与测试,快速解决 “业务人员不会写 KaiwuDB SQL” 的痛点。
核心局限:
- 功能覆盖有限:仅聚焦 NL2SQL 查询,无法实现 KAT 的自动化部署、故障诊断、AI 预测等高级功能;
- 适配精度依赖人工:对 KaiwuDB 特有语法(如
TIMESERIES TABLE、TTL冷热数据管理)的适配,需手动编写提示词优化,易出现 SQL 生成偏差; - 无官方支持:遇到组件兼容性、模型优化等问题,需依赖社区资源或自行排查,落地效率受技术能力限制。
官方 KAT:KaiwuDB 原生智能运维的终极方案
核心优势:
- 原生深度适配:作为 KaiwuDB 3.0 内置智能体,完美联动多模架构、流计算、数据分发等核心特性,SQL 生成精度接近 100%;
- 全生命周期管理:不止于查询,还能实现自动化部署配置、实时故障根因定位、性能瓶颈自动优化,大幅降低 DBA 工作量;
- 原生 AI 赋能:支持 DB4AI(数据库赋能 AI)与 AI4DB(AI 赋能数据库)双向融合,可直接通过自然语言发起数据预测、模型训练任务;
- 官方级保障:享受浪潮官方技术支持与迭代服务,适配 KaiwuDB 后续版本升级,长期稳定性更有保障。
核心局限:
- 试用门槛高:需通过官方渠道申请试用权限,企业级功能可能涉及商业授权,成本高于开源方案;
- 部署灵活性稍弱:虽支持本地化部署,但核心功能(如模型管理、数据流集成)依赖 KaiwuDB 官方生态,定制化难度高于开源组件。
vanna+Ollama 集成方案是 KAT 试用缺位时的 “最优替代解”,想快速体验自然语言查询的朋友可以参考,而 KAT 作为官方原生智能体,凭借 “深度适配、全功能覆盖、官方保障” 的核心优不过两者也并非完全对立,而更应该看作是针对不同需求的两套相互适配的解决方案,当我们的业务规模的不断的扩大,对于我们对运维的要求也就不断的提高,对于我们对AI的能力的要求也就不断的提高时,就将我们的项目迁移至KAT或采用混合的架构将会是更为的稳妥的技术路径。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 15
15 1
1- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)