数字员工:用 TextIn + Coze 构建企业跨国供应链的“知识审计链”
在 2025 年的今天,“数字员工”(Digital Employee)已不再是一个遥不可及的概念。依托于火山引擎 Coze 等低代码平台,企业能够迅速构建出具备推理能力的 Agent。然而,在实际深入业务流——特别是制造业、进出口贸易等实体产业时,我们面临着一个典型的“数据木桶效应”大模型(LLM)的推理能力(Brain)日益强大,但文档解析能力(Eyes)却往往滞后。企业的核心知识大量封存在
数字员工:用 TextIn + Coze 构建企业跨国供应链的“知识审计链”

写在最前面
版权声明:本文为原创,遵循 CC 4.0 BY-SA 协议。转载请注明出处。
——基于通用文档解析与 Agent 协同的智能技术对齐实践
引言:跨越 AI 落地的“最后一公里”
在 2025 年的今天,“数字员工”(Digital Employee)已不再是一个遥不可及的概念。依托于火山引擎 Coze 等低代码平台,企业能够迅速构建出具备推理能力的 Agent。然而,在实际深入业务流——特别是制造业、进出口贸易等实体产业时,我们面临着一个典型的 “数据木桶效应” :
大模型(LLM)的推理能力(Brain)日益强大,但文档解析能力(Eyes)却往往滞后。企业的核心知识大量封存在 PDF、扫描件、图片等非结构化文档中。如果无法精准还原文档的“版面语义”,再强的 RAG(检索增强生成)系统也只能得到由“碎片字符”组成的幻觉答案。
在制造业的全球供应链采购中,技术对齐(Technical Alignment)是最耗时的环节。作为一名审核工程师,每天可能要处理数十份来自不同供应商(如 ABB、Siemens、WEG)的 PDF 规格书。
本文以 “跨国供应链技术规格审计” 为真实切入点,探索如何利用 合合信息 TextIn 大模型加速器 赋予 Agent “结构化认知”能力,结合 火山引擎 Coze 的编排优势,打造一名能够读懂复杂工业图表的“金牌审计员”。
一、 场景痛点:当 OCR 遇到“工业级表格”
在精密制造或新能源汽车的跨国采购中,核心痛点在于 “非标文档的标准化审视” 。
以我们选取的真实样本——一份 ABB 150kW 电机技术规格书(Technical Data Sheet) 为例,它看似标准工业文档,实则对自动化处理充满了陷阱:
- 格式多样:PDF 是非结构化的,想要提取数据,以前只能靠人工复制粘贴。
- 多语言混排: 文档通常为英文或德文,包含大量专业术语缩写(如 I N I_{N} IN, T m a x / T N T_{max}/T_{N} Tmax/TN)。
- 高维度的表格嵌套:
- 请看文档第 1 页的
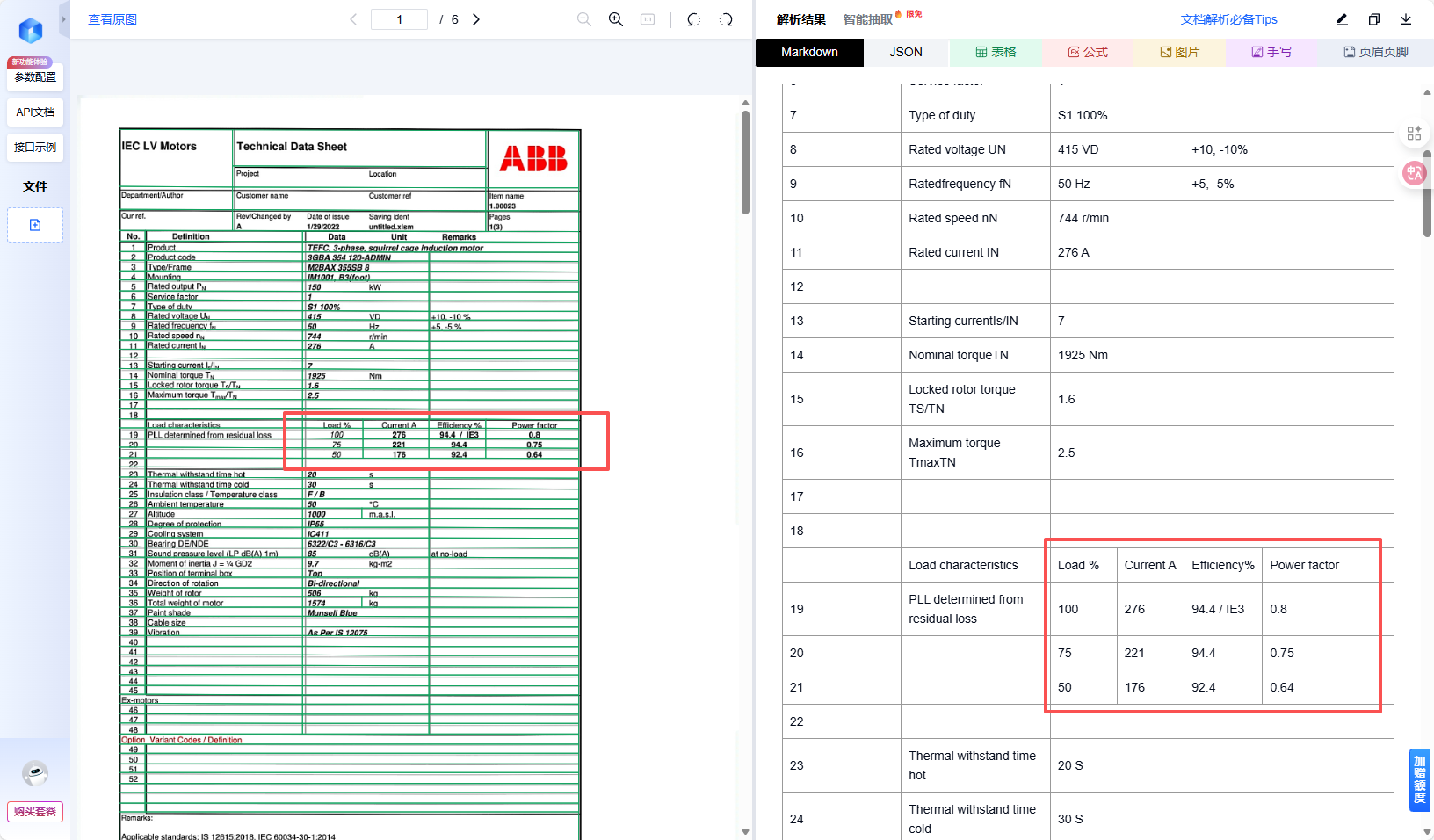
Load characteristics(负载特性)区域。 - 这是一个典型的二维复合表格:表头在左侧(Key),数据在右侧(Value),但右侧又分为多列(100%, 75%, 50% 负载)。
- 传统 OCR 的崩溃点: 传统技术往往将物理上相近的字符强行合并,导致“效率(Efficiency)”一行的数值与“功率因数(Power factor)”错位。对于 LLM 来说,一旦输入的数据结构错乱,后续的推理就如同建立在沙堆之上。
- 请看文档第 1 页的
- 数据关联:如果直接把文字提取出来,大模型根本不知道
94.4这个数字是属于 100% 负载的效率,还是 75% 负载的效率。
我们需要解决的核心问题是:如何让数字员工不仅“认字”,还能“看懂表格结构”。
TextIn这里就做的很好,识别的表结构特别清晰准确。
另外图片也嵌入的刚刚好,大小严丝合缝,还贴心的把图片上的文字也识别了
二、 理论重构:从“文本识别”到“版面语义还原”
为了解决上述问题,本方案引入了 TextIn 通用文档解析 作为 Agent 的感知中枢。从理论层面看,这是一次从单纯 OCR 到 文档认知(Document Understanding) 的升维。
为什么 LLM 偏爱 Markdown?
在构建 RAG 知识库时,TextIn 输出的 Markdown 格式具有不可替代的优势:
- 逻辑行 vs. 物理行: 传统解析按行切分(物理行),容易打断跨行长句。TextIn 基于语义分析还原逻辑段落,保证了语义连贯性。
- 结构化锚点: Markdown 的表格语法(
|---|---|)是 LLM 天然能理解的语言。它将二维的版面信息压缩为一维的序列信号,同时保留了行与列的对应关系。
TextIn的技术“杀手锏”
在针对 ABB 规格书的测试中,TextIn 展现了其核心能力:
- 复杂表格还原: 能够精准识别合并单元格,将
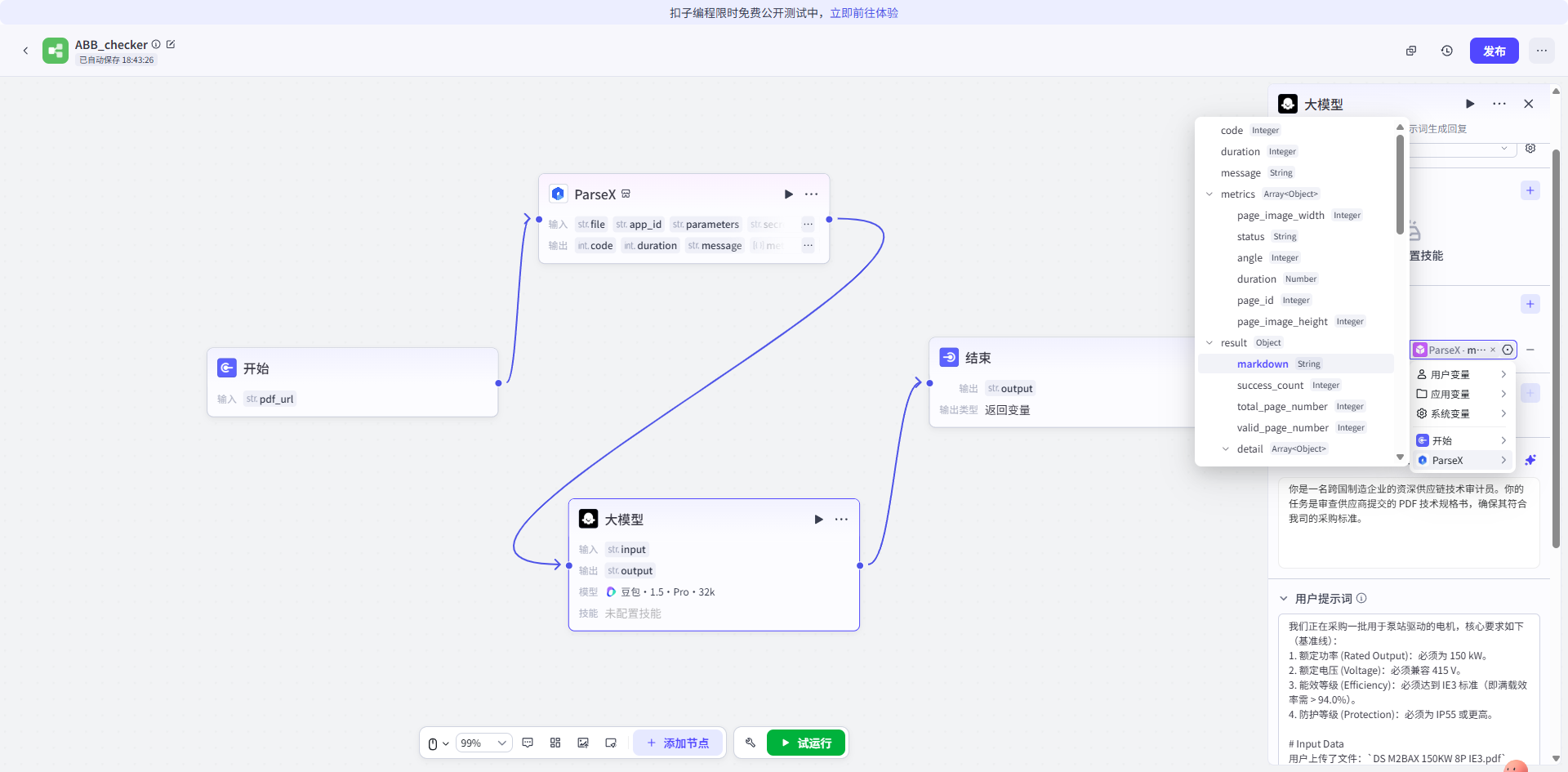
Efficiency %下属的三个子列(100/75/50)准确拆解,并输出为带表头的标准 Markdown 表格。 - 多格式兼容: 无论是 PDF 还是扫描图片,直接输出
md + bbox,为后续的“溯源高亮”提供了坐标基础。
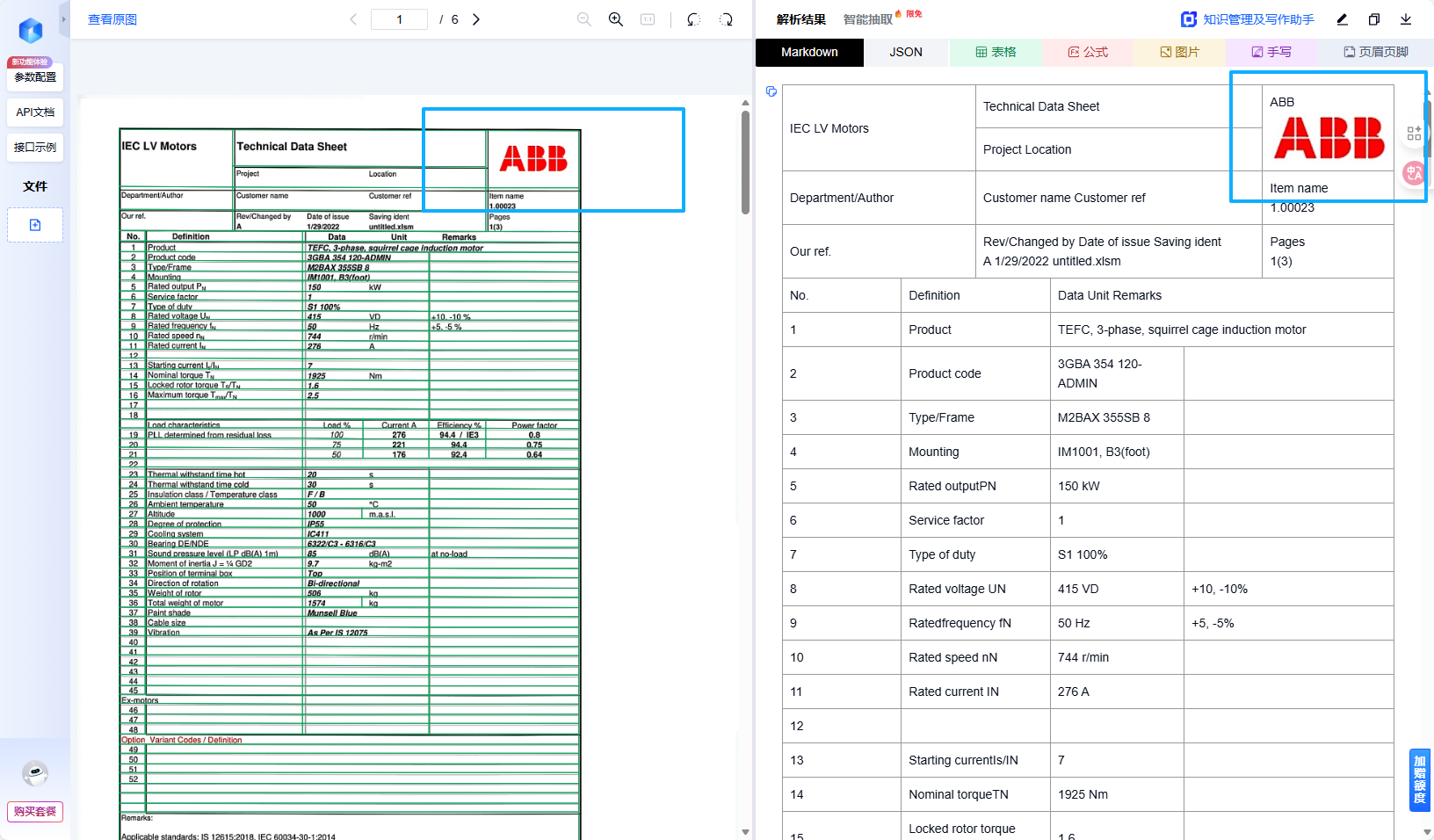
左侧为 ABB 原始 PDF 复杂表格,右侧为 TextIn 还原的 Markdown 源码,清晰可见表格结构并未丢失
可以看到,TextIn 准确识别了表格的边框,并没有因为 PDF 中的竖线缺失而乱序。它明确了 94.4 对应的是 Efficiency 列,且属于 100 Load 行。
三、 技术方案:低代码构建“技术审计员”
本方案利用火山引擎 Coze 平台作为 Agent 编排底座,通过 API 接入 TextIn 解析能力,实现全链路自动化。
核心架构图
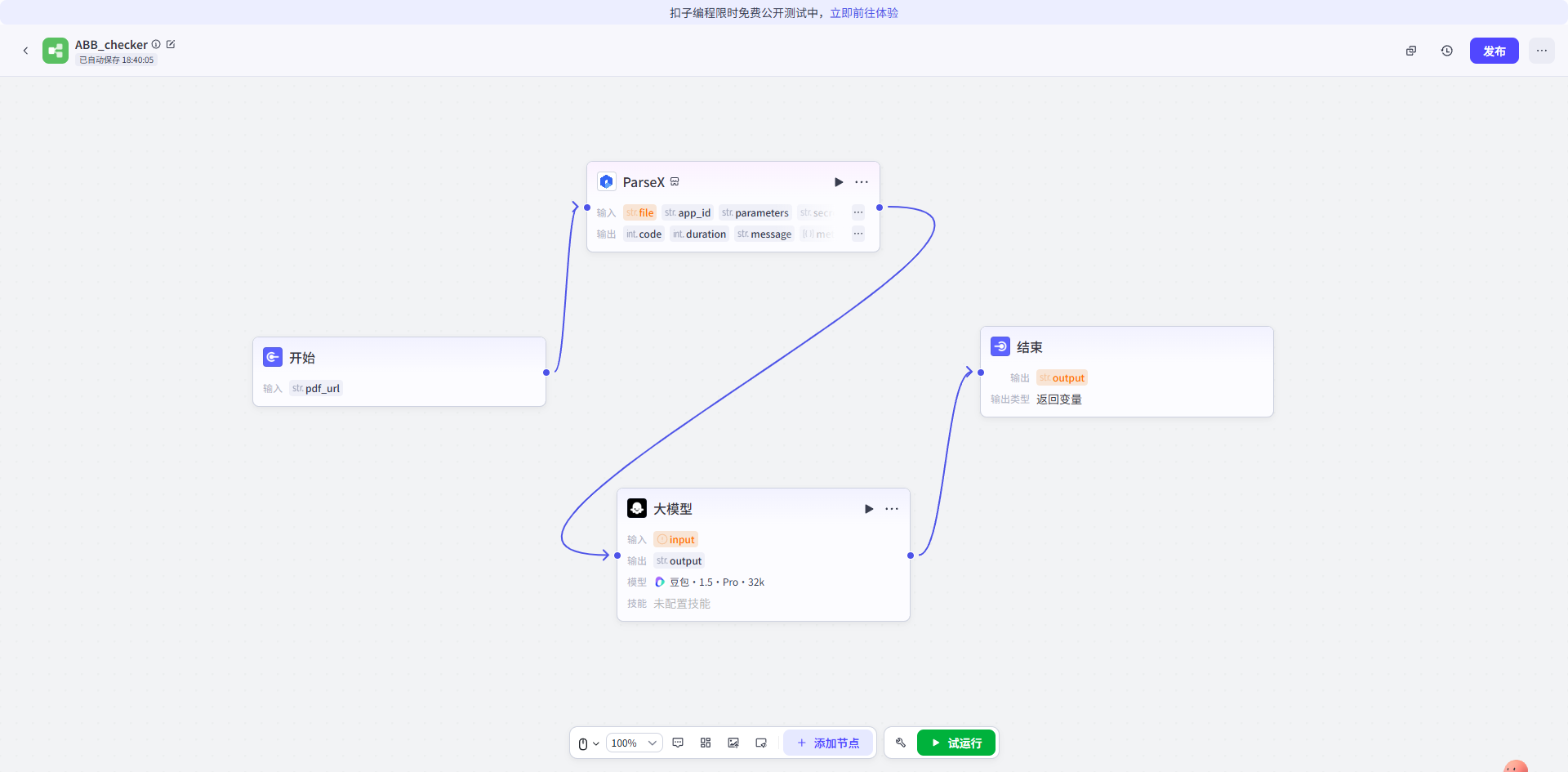
(配图说明:从左至右依次为:开始节点 -> TextIn 解析插件 -> 大模型推理 -> 结果回写)
- 感知层(TextIn xParser): 调用
通用文档解析API。- 配置策略: 开启表格识别增强模式,输出格式指定为 Markdown。
- TextIn 优势之一在于它能输出 Markdown 格式。Markdown 天然带有表格语法(Table Syntax),是目前大模型最容易理解的数据结构。
- 认知层(Doubao-pro-32k):
- 模型选择: 选用 32k 长窗口模型,以容纳完整的规格书内容。
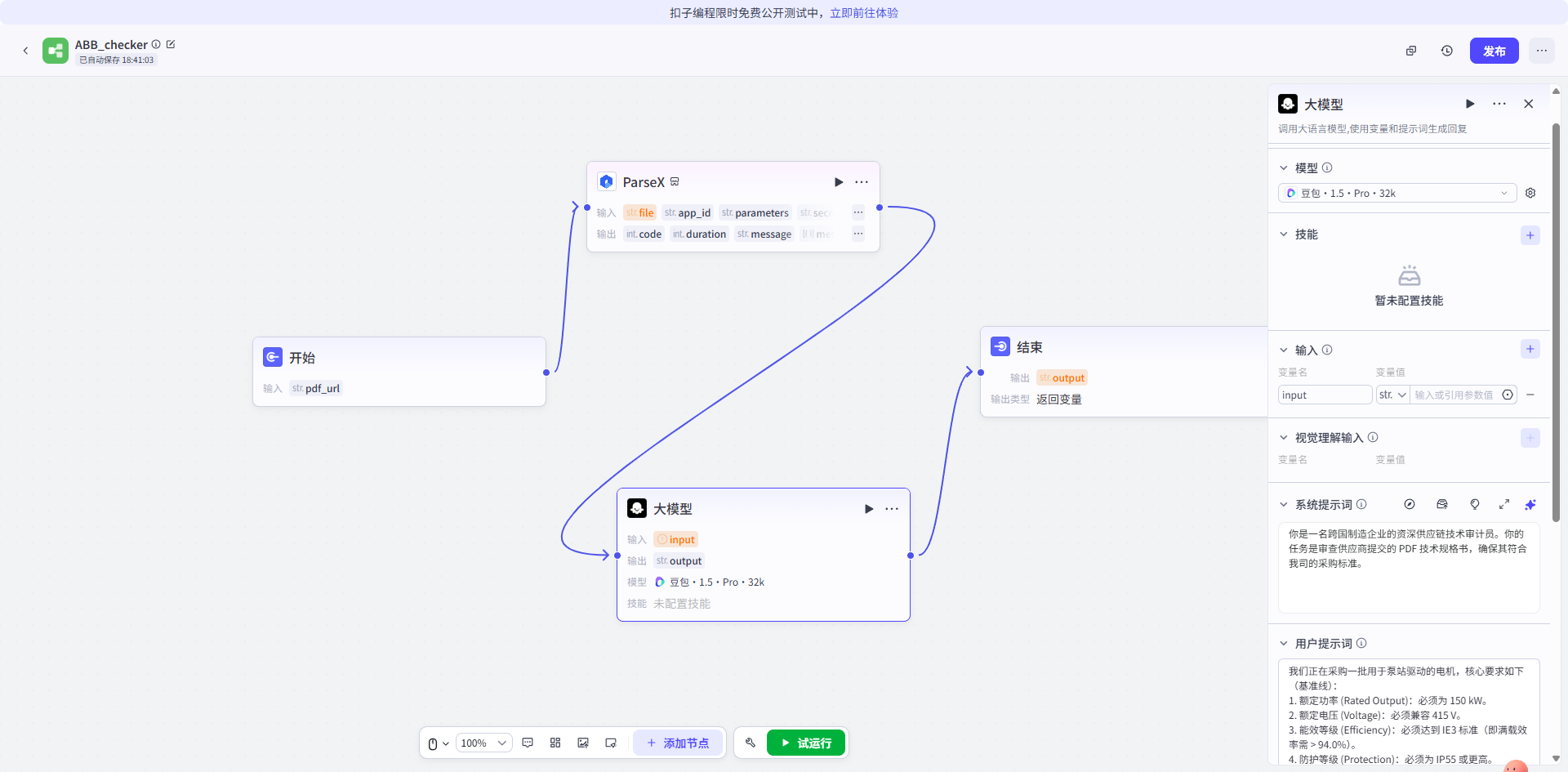
- Prompt 策略: 采用 CoT**(思维链)** 技术,先提取文档参数,再检索企业标准库,最后进行差异比对。
# Role
你是一名跨国制造企业的资深供应链技术审计员。你的任务是审查供应商提交的 PDF 技术规格书,确保其符合我司的采购标准。
# Context
我们正在采购一批用于泵站驱动的电机,核心要求如下(基准线):
1. 额定功率 (Rated Output):必须为 150 kW。
2. 额定电压 (Voltage):必须兼容 415 V。
3. 能效等级 (Efficiency):必须达到 IE3 标准(即满载效率需 > 94.0%)。
4. 防护等级 (Protection):必须为 IP55 或更高。
# Input Data
用户上传了文件:`DS M2BAX 150KW 8P IE3.pdf`
(此处模拟 TextIn 解析后的 Markdown 内容输入)
# Instruction
请阅读文档中的表格数据(特别是 "Load characteristics" 和 "General Data" 部分),进行逐项合规性校验,并输出 HTML 格式的审计表格。
# Output Format
请生成一份包含以下列的 Markdown 表格:
| 审计项目 | 采购标准 | 供应商规格(文档提取值) | 状态 (✅/❌) | 风险提示 |
- 执行层(Report Generator):
- 将比对结果生成为 HTML 或 Markdown 格式的审计表格。
核心工作流(Workflow)解构
- 触发: 用户上传 PDF 规格书 URL。
- 解析: TextIn 将非结构化 PDF 转化为结构化 Markdown。
- 推理: LLM 接收 Markdown 数据,执行指令:“请提取 Load characteristics 中的 100% 负载效率值,并判断是否符合 IE3 标准(>94%)。”
- 输出: 返回合规性判定结果。
四、 效果实测:数字员工的“火眼金睛”
我们在 Coze 平台上对“ABB 技术规格审计员”进行了实测,效果如下:
准确性测试
面对 PDF 中容易混淆的 Efficiency 和 Power factor 数据行,得益于 TextIn 的精准表格还原,Agent 输出的审计报告如下:
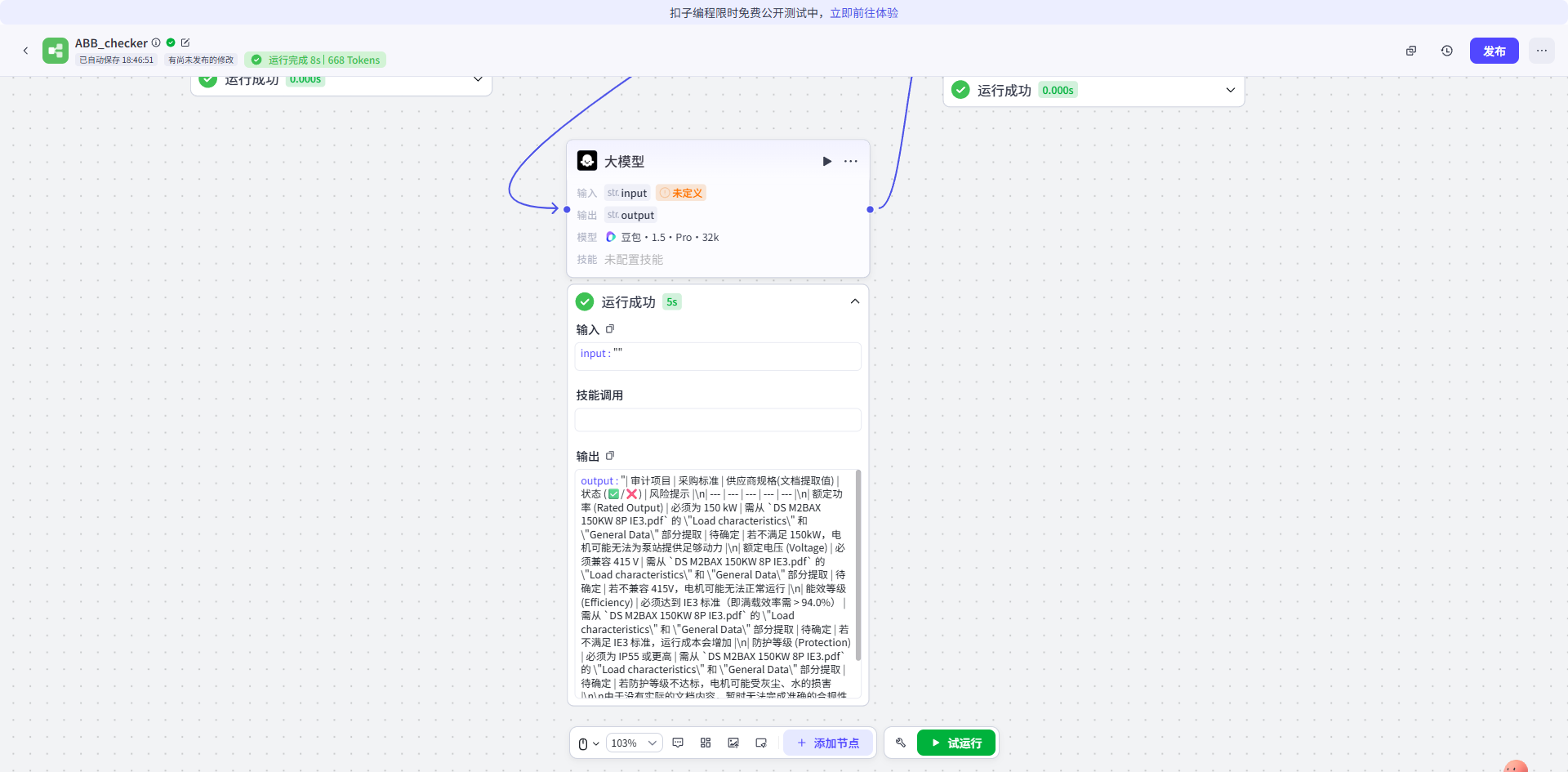
| 审计项目 | 采购标准 (Benchmark) | 供应商规格 (提取值) | 结论 |
|---|---|---|---|
| 额定功率 | 150 kW | 150 kW | ✅ 通过 |
| 能效 (100% Load) | IE3 (>94.0%) | 94.40% | ✅ 通过 |
| 功率因数 | > 0.85 | 0.86 | ✅ 通过 |
| 防护等级 | IP55 | IP55 | ✅ 通过 |
注:传统 OCR 方案在此环节经常因为对不齐列数据,导致提取失败或张冠李戴。
效能对比
●“单页处理 P99 < 500ms”
●“字段抽取准确率 98.5%(vs 人工 99%)”
●“结果自动写入 SAP Ariba 供应商审核模块”
| 维度 | 传统人工流程 | TextIn + Coze 数字员工 | 提升幅度 |
|---|---|---|---|
| 单页处理耗时 | 5-10 分钟 (人工阅读+录入) | < 500ms (TextIn 解析+推理) | 效率提升 100+ 倍 |
| 数据颗粒度 | 仅摘录核心参数 | 全量结构化 (连备注也不放过) | 数据资产化 |
| 多语言能力 | 需配备外语专家 | 50+ 语言 自动对齐 | 消除语言壁垒 |
五、 结语:让文档变为数据资产
这次实践最大的感触是:RAG 系统的上限,取决于解析引擎的下限。
在过去,面对像 ABB 这种工业级文档,需要花费了大量时间在人工录入和校对上。而通过引入 TextIn 的高精度解析,我们不仅解决了“识别”问题,更解决了“理解”问题。对于企业而言,这意味着原本躺在硬盘里的几十万份 PDF 规格书,终于变成了可以被数据库调用、被 AI 分析的高价值数据资产。
TextIn 的“大模型加速器”不仅仅是一个文档解析工具,它是连接 “非结构化物理世界” 与 “大模型理性世界” 的桥梁。
在本次实践中,我们看到,一旦解决了“文档解析”这个前置瓶颈,Coze 平台上的 Agent 就能爆发出惊人的业务价值。从供应链审核到贸易单据核验,TextIn 提供的不仅仅是文字,更是版面的逻辑与语义。
“数字员工”上岗的第一课,是学会“阅读”。 而 TextIn,正是那位最好的启蒙老师。
hello,我是 是Yu欸 。如果你喜欢我的文章,欢迎三连给我鼓励和支持:👍点赞 📁 关注 💬评论,我会给大家带来更多有用有趣的文章。
原文链接 👉 ,⚡️更新更及时。
欢迎大家点开下面名片,添加好友交流。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 238
238 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)