GraphRAG论文分享(阶段一)
不要把大模型当成不知疲倦的阅读者,要把大模型当成一个聪明的程序员。让它帮你造工具,而不是让它帮你干苦力。FastRAG 目前是一个**“偏科”但“特长突出”的优等生。它在特定领域(运维数据)把性价比做到了极致。未来的发展方向是提高它的鲁棒性**(防格式变更)和智商(增加推理能力),使其不仅能“解析数据”,还能真正“理解数据”。如果用一句话概括 DyG-RAG 的独特之处:它赋予了 RAG 系统“时
一、《FastRAG: Retrieval Augmented Generation for Semi-structured Data》
(一)主要内容:
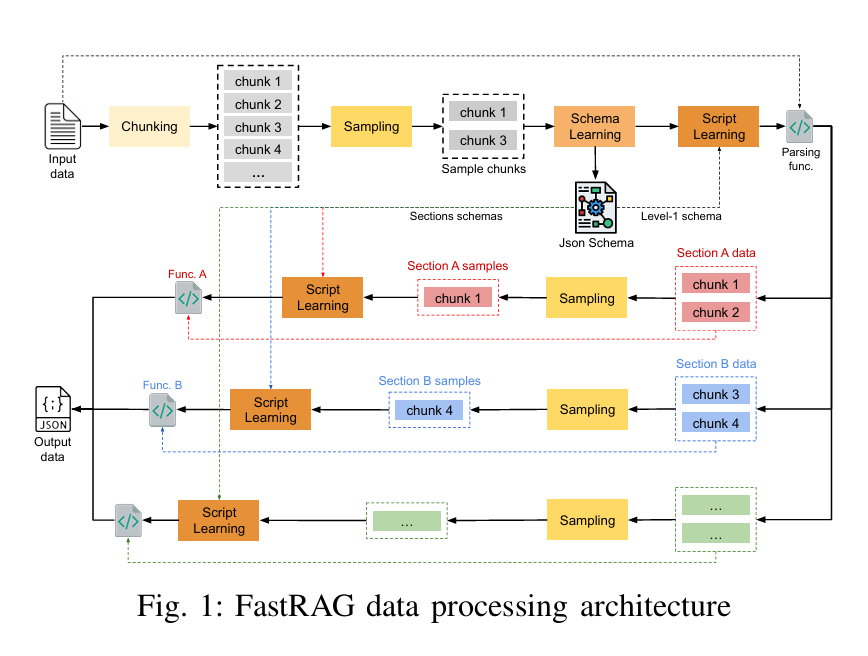
论文核心总结:FastRAG
一、 研究背景与动机 (Motivation)
- 应用场景: 网络管理(Network Management),涉及大量的半结构化数据(如系统日志、设备配置文件)。
- 现有问题:
-
- 传统工具局限: 无法充分利用数据中隐含的上下文信息。
- VectorRAG(向量检索)的缺陷: 基于语义相似度的检索往往丢失上下文,且难以处理特定领域的关键词(隐式信息)。
- GraphRAG(图谱检索)的缺陷: 虽然通过构建知识图谱(KG)提升了上下文理解,但通过 LLM 逐行读取数据来建图成本极高、速度极慢,且容易忽略具体细节(如具体的 IP 地址)。
- 目标: 开发一种既能保留知识图谱的精确性,又能大幅降低时间和金钱成本的 RAG 系统。
二、 核心理念 (Core Concept)
FastRAG 的核心思想是**“代码生成代替直接处理”。
它认为半结构化数据具有高度的重复性**(语法结构固定)。因此,不需要让 LLM 阅读所有数据,只需让 LLM 阅读少量样本,学习数据的模式(Schema),然后编写**代码(Script)**去自动处理剩余的海量数据。
三、 方法论:FastRAG 的四大支柱 (Methodology)
FastRAG 的处理流程分为四个关键步骤:
1. 块采样 (Chunk Sampling) —— 精选代表性数据
为了避免把所有数据喂给 LLM,系统需要挑选出极少量的“样本块”。
- 关键词提取: 使用 TF-IDF 和 K-means 聚类算法,识别出文本中最重要的术语。
- 基于熵的选择 (Entropy-based Selection): 设计了一种算法,计算每个数据块的香农熵(Shannon Entropy)。
-
- 熵越高,代表该块包含的信息多样性越丰富。
- 算法会优先选择那些能覆盖最多关键词且熵值最高的数据块,确保样本具有语法代表性。
2. 模式学习 (Schema Learning) —— 定义数据结构
利用选出的样本块,提示 LLM 归纳数据的结构,生成 JSON Schema。为了提高准确性,采用了分层策略:
- Step 1(宏观层): 识别一级实体(Section)。例如,把配置文件切分为“接口部分”、“路由部分”。
- Step 2(微观层): 针对每个 Section,定义详细的属性。例如,在“接口部分”中定义
name,ip_address,description等字段。 - 机制: 如果生成的 Schema 有误,系统会反馈错误信息给 LLM 进行自我修正。
3. 脚本学习 (Script Learning) —— 生成解析代码
这是 FastRAG 最具创新性的降本增效环节。
- 代码生成: LLM 不直接提取数据,而是编写 Python 解析脚本(通常利用正则表达式)。
- 验证与迭代: 生成的脚本会立即在样本数据上运行。如果报错或提取失败,错误日志会返回给 LLM,要求其重写代码,直到脚本能完美运行(Self-Correction)。
- 批量处理: 一旦脚本通过验证,就用这个免费且极速的 Python 脚本去处理剩下的 99% 数据,将其转换为结构化的 JSON 对象。
4. 信息检索 (Information Retrieval) —— 混合查询
解析后的数据被存入图数据库(如 Neo4j),构建知识图谱(KG)。
- KG 结构: 实体作为节点,属性作为边或属性值。同时,每个节点都挂载了对应的原始文本行(input_data)。
- 检索策略:
-
- Graph Query (图查询): LLM 生成 Cypher 语句查询图谱(适合查关系、查具体属性)。
- Text Search (文本搜索): 利用 NLP 技术对挂载的原始文本进行搜索(适合模糊匹配、查报错信息)。
- Hybrid/Combined (混合/组合): 论文证明,同时并行执行图查询和文本搜索,并将结果汇总给 LLM,能得到最准确的答案。
四、 实验评估 (Evaluation)
论文使用了两组数据(OpenStack 日志和 Cisco 路由器配置)对比了 FastRAG 和微软的 GraphRAG。
- 1. 准确性 (Accuracy):
-
- FastRAG 在回答具体细节问题(如“某接口的 IP 是什么?”)时表现优于 GraphRAG。GraphRAG 倾向于生成摘要,容易丢失具体数值。
- 混合检索(Graph + Text)的效果最佳。
- 2. 效率 (Efficiency) —— 压倒性优势:
-
- 时间: FastRAG 比 GraphRAG 快 90%(几分钟 vs 几十分钟)。
- 成本: FastRAG 比 GraphRAG 便宜 85%(Token 消耗极低,因为只处理了几个样本块)。
- 3. 覆盖率 (Coverage):
-
- 仅需极少的样本(如 4 个块),FastRAG 生成的脚本就能覆盖数据集中近乎 100% 的数据结构。
五、 局限性与结论 (Conclusion)
- 结论: FastRAG 证明了对于半结构化数据,利用 LLM 进行**程序合成(Program Synthesis)比利用 LLM 直接进行信息提取(Information Extraction)**更高效、更经济。
- 局限性:
-
- 适用范围: 仅适用于半结构化数据(日志、配置、代码),不适用于非结构化的自然语言文档。
- 采样风险: 依赖样本的代表性。虽然有熵算法,但如果数据中存在极其罕见的格式(<1%),脚本可能会漏掉这些信息。
- 关系提取: 目前主要提取层级关系(父子关系),缺乏对实体间复杂语义关系的深度推理。
一句话总结:
FastRAG 是一种通过智能采样和大模型生成代码来解析半结构化数据的技术,它以极低的成本构建了“知识图谱+全文索引”的混合检索系统,在速度和成本上对传统 GraphRAG 构成了降维打击。
(二)主要的创新点:
这篇文章《FastRAG: Retrieval Augmented Generation for Semi-structured Data》在 RAG 领域,特别是针对运维(AIOps)和半结构化数据处理方面,提出了非常有价值的思路。
以下我为您详细拆解它的核心创新点(它创造了什么新东西)以及可借鉴的地方(你在实际工作中可以直接拿来用的思路)。
一、 核心创新点 (Innovations)
这篇论文最大的贡献在于打破了“用 LLM 阅读数据”的思维定势,转而采用“用 LLM 生成工具”的模式。
1. “采样+代码生成”的低成本处理范式
- 传统做法(GraphRAG): 暴力美学。把所有数据喂给 LLM,让 LLM 提取实体和关系。成本随数据量线性增长。
- FastRAG 创新: 引入了 Script Learning(脚本学习)。
-
- 它假设半结构化数据(日志/配置)具有语法重复性。
- 它让 LLM 充当“程序员”,只读极少量的样本,写出 Python 解析脚本。
- 然后用这个免费的 Python 脚本去处理海量数据。
- 结果: 实现了 O(1) 的 LLM 调用成本(与数据总量无关),只与数据格式的复杂度有关。
2. 基于熵的块采样算法 (Entropy-based Chunk Sampling)
- 问题: 如何只选 4 个样本就代表 10000 条数据?随机抽样可能会漏掉罕见的报错格式。
- FastRAG 创新: 提出了一套具体的算法流程:
-
- 关键词聚类: 先用 TF-IDF 和 K-Means 找出数据的核心词汇。
- 熵值计算: 计算每个数据块的香农熵(Shannon Entropy)。熵越高,说明这个块包含的信息越混乱、越丰富。
- 贪婪选择: 优先选择那些既包含未覆盖关键词、熵值又高的数据块。
-
- 这保证了喂给 LLM 的样本是“含金量最高”、“最难啃”的骨头。
3. “Schema + Script” 的双重迭代学习机制
- FastRAG 创新: 它没有让 LLM 一步到位,而是拆分为两个并行的学习过程:
-
- Schema Learning: 先让 LLM 搞清楚数据“长什么样”(定义 JSON 结构)。
- Script Learning: 再让 LLM 搞清楚“怎么提取它”(写 Python 代码)。
- 自愈机制 (Self-Correction): 这是一个闭环系统。生成的代码会立刻在样本上跑,如果报错,报错信息回传给 LLM 进行重写,直到代码跑通为止。
4. “Step 1 & Step 2” 的分层解析策略
- FastRAG 创新: 为了应对复杂的嵌套结构,它将解析任务降维:
-
- Step 1: 宏观切分。先把大文本切成一个个 Section(如接口块、路由块)。
- Step 2: 微观提取。针对切好的 Section,再单独生成专门的解析代码。
- 这种分层极大地降低了 LLM 写代码的难度,提高了成功率。
二、 可以借鉴的地方 (Actionable Insights)
如果你正在开发 RAG 应用,尤其是面对非自然语言数据(如报表、日志、代码库、商品参数)时,以下几点可以直接照搬:
1. 面对规律性数据,请用“代码生成”代替“语义理解”
- 借鉴点: 如果你的数据源是 CSV、日志、XML、固定格式的合同、或者电商的 SKU 列表。
- 怎么做: 不要把这些数据直接 Embed 进向量库。试着 Prompt 大模型:“请写一个 Python 函数,把这段文本里的 XX 字段提取成 JSON”。
- 收益: 提取出来的结构化数据(JSON)比向量模糊搜索要精准得多,而且不用担心 Token 费用爆炸。
2. 引入“执行反馈循环” (Execution Feedback Loop)
- 借鉴点: 在让 LLM 帮你写工具(SQL、Python、Regex)时,不要盲目相信它一次就能写对。
- 怎么做: 在你的 Pipeline 里加一个 Sandbox(沙箱)。
-
- LLM 生成代码。
- 系统尝试运行代码。
- 关键点: 如果报错,把
Traceback错误信息抓取下来,作为下一个 Prompt 发回给 LLM:“你刚才的代码报错了,错误是XXX,请修正。”
- 收益: 这能大幅提高系统的鲁棒性,让 RAG 系统具备自我修复能力。
3. “混合检索”的架构设计
- 借鉴点: 单纯的 Graph 只有骨架,单纯的 Text 只有血肉。FastRAG 展示了如何结合。
- 怎么做:
-
- 在图数据库(如 Neo4j)中建节点时,不要只存属性。
- 给节点加一个属性
raw_text或input_data,把生成这个节点的原始文本存进去。 - 建立全文索引: 对这个
raw_text属性建索引。 - 查询时: 一边写 Cypher 查图,一边用 Lucene 查全文,最后把两边的结果拼给 LLM。
- 收益: 解决了“查得准”和“查得全”的矛盾。
4. 处理长文本的“分而治之”思路
- 借鉴点: 当一个文档结构很复杂时,不要试图用一个 Prompt 搞定。
- 怎么做: 模仿论文的 Step 1 / Step 2。
-
- 先写一个简单的规则(或让 LLM 识别)把文档按章节切开。
- 然后对每一章单独处理。
- 收益: 这避免了 LLM 在处理长 Context 时的“迷失”现象(Lost in the Middle),也让生成的解析逻辑更简单。
总结
这篇文章最值得借鉴的核心逻辑是:不要把大模型当成不知疲倦的阅读者,要把大模型当成一个聪明的程序员。 让它帮你造工具,而不是让它帮你干苦力。
(三)不足和未来展望
基于这篇论文《FastRAG: Retrieval Augmented Generation for Semi-structured Data》的内容,以及对该技术路线的深度分析,FastRAG 的不足之处和未来展望可以总结如下:
一、 目前存在的不足 (Limitations)
尽管 FastRAG 在成本和速度上表现优异,但它为了追求效率,在某些方面做了妥协,存在明显的短板:
1. 信息丢失的风险 (Risk of Information Loss)
这是 FastRAG 最大的软肋。
- 问题: 整个系统依赖于“采样”。虽然使用了熵(Entropy)算法来挑选代表性数据,但统计学无法保证覆盖 100% 的情况。
- 后果: 如果数据中存在极罕见的“长尾”格式(例如万分之一概率出现的特殊报错结构),且恰好没被采样选中,那么生成的 Python 脚本就完全不知道该如何解析这种数据。这部分数据在后续的检索中实际上就“隐身”了(论文中提到可能有 <5% 的信息损失)。
2. 缺乏深度的“语义关系”提取 (Lack of Deep Semantic Relations)
- 问题: 目前 FastRAG 构建的知识图谱(KG)是非常“浅”的。它主要提取的是层级关系(父子关系,如:文件 -> 接口部分 -> IP地址)。
- 后果: 它缺乏真正的拓扑关系或逻辑关系。例如,它能解析出“路由器A有接口IP 1.1.1.1”和“路由器B有接口IP 1.1.1.2”,但它无法自动推断出“路由器A和路由器B是相连的”。这种跨实体的深度推理,目前的脚本还做不到,仍需依赖 GraphRAG 那种昂贵的语义分析。
3. 对数据源格式的“洁癖” (Brittleness to Format Changes)
- 问题: 正则表达式和 Python 脚本是刚性的。
- 后果: 如果日志系统的开发人员稍微改了一下日志格式(比如多加了一个空格,或者把日期格式从
YYYY-MM-DD改成了DD/MM/YYYY),原本生成的脚本可能会立刻报错或失效。系统缺乏 VectorRAG 那种对模糊变化的“鲁棒性”。
4. LLM 的不确定性 (Variability)
- 问题: 每次运行 Schema Learning 和 Script Learning,LLM 生成的 JSON 结构和代码可能都不太一样。
- 后果: 这给工程化带来了挑战。如果今天生成的字段叫
ip_addr,明天重新运行生成叫address_ip,会导致下游的查询逻辑难以统一。
二、 未来展望 (Future Outlook)
基于上述不足,FastRAG 及其类似技术路线在未来有很大的优化空间:
1. 自愈式解析器 (Self-Healing Parsers)
- 方向: 解决脚本“刚性”的问题。
- 设想: 在批量处理过程中,如果发现某几行数据的解析失败率突然飙升(说明格式变了或遇到了新格式),系统应自动触发**“再采样”**机制。
- 做法: 把解析失败的行单独提取出来,再次喂给 LLM,让 LLM 增量更新脚本代码,从而覆盖这些新出现的边缘情况。
2. 增强实体关系提取 (Enhanced Relation Extraction)
- 方向: 让图谱从“文件目录树”变成真正的“知识网络”。
- 设想: 在 Step 2(详细提取)之后,增加一个 Step 3(关系连接)。
- 做法: 专门写一个逻辑(或脚本),利用 ID、IP 地址、MAC 地址等关键标识符,自动将不同节点连接起来。例如,发现两个设备的 IP 在同一网段,就自动在图谱中建立一条
CONNECTED_TO的边。
3. 扩展到更多领域 (Domain Expansion)
- 方向: 验证其普适性。
- 设想: 目前仅在日志和配置上验证。未来可以尝试应用在:
-
- 医疗领域: 解析 HL7 消息或电子病历(半结构化)。
- 金融领域: 解析复杂的交易流水或审计报表(CSV/XML)。
- 代码库分析: 解析代码的函数定义和调用关系(代码本身就是一种半结构化数据)。
4. 更智能的混合检索策略 (Smarter Hybrid Retrieval)
- 方向: 优化 Graph 和 Text 的配合。
- 设想: 目前是简单的“并行查询然后汇总”。未来可以引入查询路由(Query Routing)。
-
- 如果用户问“错误代码是什么”,直接走文本搜索。
- 如果用户问“这台设备关联了哪些下游业务”,直接走图谱查询。
- 通过意图识别来减少不必要的查询开销。
总结
FastRAG 目前是一个**“偏科”但“特长突出”的优等生。它在特定领域(运维数据)把性价比做到了极致。未来的发展方向是提高它的鲁棒性**(防格式变更)和智商(增加推理能力),使其不仅能“解析数据”,还能真正“理解数据”。
二、《DyG-RAG: Dynamic Graph Retrieval-Augmented Generation with Event-Centric Reasoning》
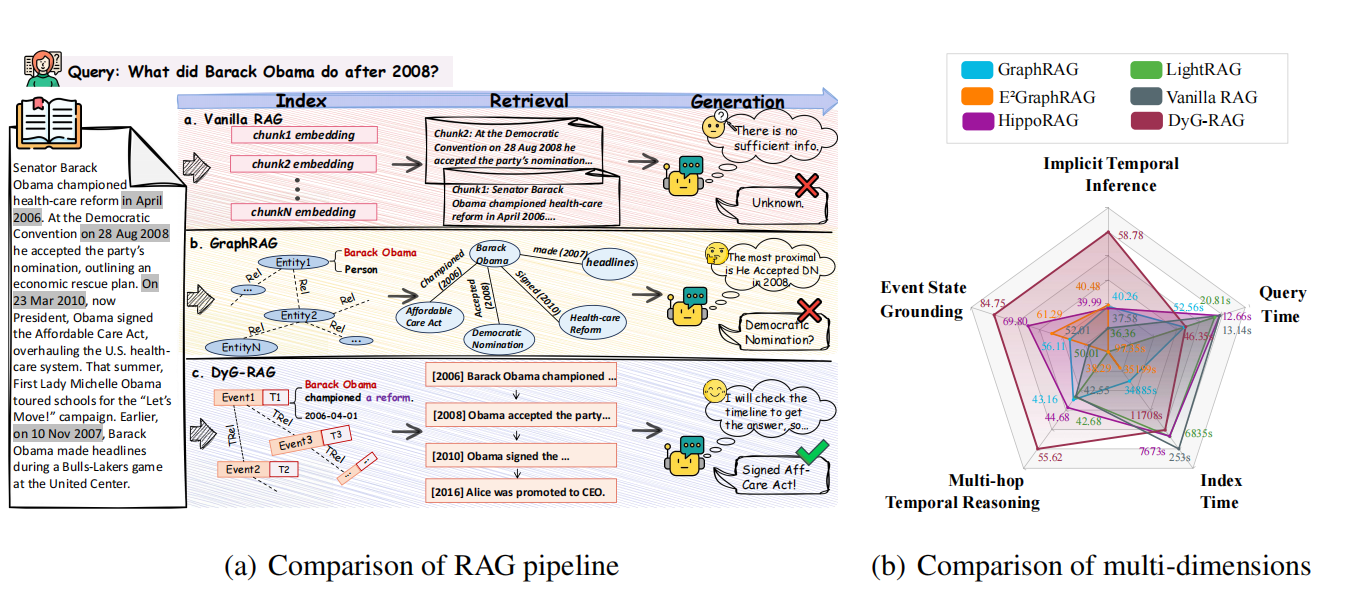
(一)主要内容:
这份总结基于论文《DyG-RAG: Dynamic Graph Retrieval-Augmented Generation with Event-Centric Reasoning》的全文内容,严格贴合原文的技术细节与逻辑流程。
论文总结:DyG-RAG——基于事件中心推理的动态图检索增强生成
1. 研究背景与动机 (Motivation)
- 现存问题: 现有的大型语言模型(LLM)受限于静态参数知识,容易产生幻觉或知识过时。
- 现有 RAG 的局限性:
-
- Vanilla RAG: 将文档视为静态的文本块(Chunks),主要依赖语义相似度,忽略了时间维度,难以区分“2008年之前”和“2008年之后”的差异。
- Graph RAG: 虽然引入了结构化图谱,但大多是静态的(Static),缺乏对时间演变(Temporal Dynamics)和事件顺序的建模能力。
- 时间知识图谱 (TKG) 的不足: 传统的 TKG 依赖预定义的模式(Schema),缺乏对非结构化文本中细粒度事件状态变化的表达能力。
- 核心目标: 提出一种能够捕捉非结构化文本中动态演变结构的框架,解决复杂的时间推理问题(如时间排序、状态持续性、因果依赖)。
2. 核心创新:动态事件单元 (DEU)
DyG-RAG 摒弃了传统的“文本块”作为检索单位,提出了动态事件单元 (Dynamic Event Unit, DEU)。
- 定义:

-
-
:描述离散事件或稳定状态的事实性陈述。
-
:经过归一化的绝对时间戳(精确到月或日)。
-
- 作用: DEU 是系统中最小的原子化知识单元,确保了检索内容的语义完整性和时间精确性。
3. 技术框架 (Methodology)
DyG-RAG 的工作流分为三个严密的阶段:
阶段一:从源文档提取 DEU (Extraction)
- 文档分块 (Chunking): 将文档切分,并保留标题以维持上下文。
- 时间解析 (Temporal Parsing): 利用 LLM 识别文本中的时间表达。
-
- 绝对时间: 直接提取(如 "March 2008")。
- 相对时间/模糊时间: 基于上下文的时间栈进行回溯和计算(如将 "two days later" 解析为具体日期)。
- 信息过滤 (Filtering): 剔除无效信息,仅保留包含实体、状态变化且具有时间锚点的句子。
- 合并 (Merging): 对同一天、同一实体的相关动作进行合并,形成最终的 DEU。
阶段二:构建动态事件图 (Graph Construction)
将提取出的 DEU 组织成图

,旨在模拟事件的演变流。
- 节点编码 (Node Encoding): 采用**“时空融合”**策略。
-
- 语义向量: 使用文本编码器(如 BGE-M3)提取语义特征。
- 时间向量: 使用傅里叶时间编码 (Fourier Time Encoding,
) 将时间戳映射为正弦/余弦向量,以捕捉时间的周期性和相对距离。
- 融合: 将两者拼接:
。
- 边构建规则 (Edge Construction): 两个节点
连线必须同时满足两个条件:
-
- 实体共现 (Entity Co-occurrence): 共享至少一个实体(保证逻辑相关)。
- 时间邻近 (Temporal Proximity): 时间差
(保证时间局部性)。
- 边权重计算 (Weighting): 引入时间衰减机制。
-
- 公式:

- 含义:连接强度由实体相似度(Jaccard系数)和时间距离共同决定。时间越近,实体重复度越高,连接越强。
- 公式:
- 索引 (Indexing): 采用双重存储结构。
-
- 向量库: 存储融合嵌入,用于快速检索种子节点。
- 图数据库: 存储拓扑结构,用于多跳遍历。
阶段三:检索与时间思维链推理 (Retrieval & Reasoning)
当用户查询到来时,系统执行以下步骤:
- 查询解析 (Query Parsing):
-
- 提取查询中的时间约束
。
- 生成查询向量
,并通过参数
动态调节语义与时间的权重比例。
- 提取查询中的时间约束
- 图遍历 (Graph Traversal):
-
- 先通过向量搜索找到最相关的 Top-N 个种子节点。
- 从种子出发,在事件图上执行加权随机游走 (Weighted Random Walk)。
- 利用边权重概率
,探索出语义相关且时间连续的事件链。
- 时间线构建 (Timeline Construction):
-
- 将遍历得到的事件集区分静态事实和动态事件。
- 将动态事件严格按时间戳排序,生成结构化的事件时间线 (Event Timeline)。
- Time-CoT 推理 (Time Chain-of-Thought):
-
- 放弃直接生成,而是强制 LLM 使用特定的时间推理模板:
-
-
- 识别意图:(如:查询存在性、边界、聚合)。
- 提取约束:(锁定目标时间窗口)。
- 推断状态演变:(检查事件顺序、状态持续性、是否有打断事件)。
- 生成答案:(基于推导结果回答)。
-
4. 实验结果 (Experiments)
- 数据集: 在 TimeQA(隐式时间推理)、TempReason(事件状态定位)、ComplexTR(多跳时间推理)三个基准上进行了评估。
- 对比基线: 对比了 Vanilla RAG、GraphRAG、LightRAG、HippoRAG 等主流方法。
- 结果: DyG-RAG 在所有指标上均取得了显著领先 (Significant Improvement)。
-
- 准确率 (Accuracy) 提升约 10% - 18%。
- 召回率 (Recall) 提升约 10% - 16%。
- 消融实验: 证明了“动态事件单元构建”、“图结构检索”和“Time-CoT 提示”三个组件缺一不可。
5. 总结 (Conclusion)
DyG-RAG 是第一个明确将“以事件为中心”的视角引入 Graph RAG 的框架。它通过将非结构化文本转化为可计算的动态事件图,利用数学化的时间编码和结构化的图遍历,成功解决了传统 RAG 在处理时间演变和复杂时间逻辑时的短板,为生成更忠实、具备时间感知能力的 AI 提供了新的范式。
(二)主要的创新点:
基于论文《DyG-RAG: Dynamic Graph Retrieval-Augmented Generation with Event-Centric Reasoning》,该文章的核心创新点和特色点可以归纳为**“一个核心视角转变”和“四个技术维度的突破”**。
它最大的突破在于:将 RAG 的检索对象从“静态的文本块”转变为“动态的事件流”。
以下是详细的解读:
一、 核心视角创新:以事件为中心 (Event-Centric Perspective)
传统的 Graph RAG(如 Microsoft GraphRAG)大多是**“以实体为中心”**的,构建的是静态知识图谱(实体-关系-实体)。这种结构擅长回答“A是谁的父亲”,但极难回答“A在2010年到2015年之间经历了什么职业变动”。
DyG-RAG 的特色:
它认为世界不是静态的,而是由一系列在时间轴上发生的事件(Events)组成的。因此,它构建的图谱不再是静态的事实库,而是一个“动态演变网络”。
二、 四大关键技术创新点
1. 最小单元的重构:提出“动态事件单元 (DEU)”
这是整个框架的地基(Stage 1)。
- 传统痛点: 传统 RAG 索引的是 Chunk(文本段落)。Chunk 往往包含混乱的时间信息(一段话里既有1990年也有2020年),导致检索时时间粒度模糊。
- DyG-RAG 创新:
-
- 原子化 (Atomic): 定义了 DEU (
),强制将文本拆解为一个个**“独立且带有精确时间戳”**的微小事实。
- 时间解析 (Temporal Parsing): 能够处理相对时间。它利用 LLM 将文中的“两天后”、“下个月”解析为绝对的
YYYY-MM-DD,这是传统关键词检索做不到的。 - 结果: 将非结构化文本彻底“数学化”和“离散化”。
- 原子化 (Atomic): 定义了 DEU (
2. 图构建机制:时空融合的动态构图 (Dynamic Graph Construction)
这是论文最“硬核”的算法创新(Stage 2)。
- 节点编码创新:傅里叶时间编码 (Fourier Time Encoding)
-
- 它没有把时间仅仅当作一个数字或字符串,而是通过正弦函数
将时间映射到高维向量空间。
- 特色: 这让模型能感知时间的周期性(Seasonality)和相对距离,实现了语义向量与时间向量的深度融合(Concatenation)。
- 它没有把时间仅仅当作一个数字或字符串,而是通过正弦函数
- 连边机制创新:双重约束 + 时间衰减
-
- 双重门槛: 两个节点要连线,必须同时满足“实体共现”和“时间邻近”。
- 动态权重公式:
。
- 特色: 引入了时间衰减因子。这模拟了真实世界的逻辑:时间隔得越久,两个事件的关联性就越弱。这防止了图谱中出现跨越几十年的无效连接(Semantic Drift)。
3. 检索策略:时间感知的多跳游走 (Time-Aware Traversal)
检索不再是简单的“挑最相似的句子”(Stage 3)。
- 查询解析创新:
-
- 对用户 Query 进行双重编码(语义+时间),并引入动态参数
。
- 特色: 系统可以根据问题类型,动态调整是更看重“内容匹配”还是“时间匹配”。
- 对用户 Query 进行双重编码(语义+时间),并引入动态参数
- 检索路径创新:加权随机游走 (Weighted Random Walk)
-
- 它不是只找一个点,而是从种子节点出发,沿着图的边“走”出一条路径。
- 特色: 这种游走通过图结构自然地捕捉到了事件的连锁反应(Event Chains)和叙事流(Narrative Flow),从而能回答“这件事导致了什么后果”这类问题。
4. 推理生成:时间思维链 (Time-CoT)
这是为了解决 LLM “脑子不好使”(推理能力弱)的问题。
- 输入结构化: 检索结果被强制格式化为按时间排序的 Timeline,而不是乱序的文本堆叠。
- 提示工程创新: 设计了专门的 Time-CoT 模板。
-
- 它强迫 LLM 执行特定的符号推理步骤:Identify(识别意图)
Filter(过滤时间窗)
Infer(推断状态演变)。
- 特色: 这特别适用于解决**“状态持有(State Grounding)”**问题(例如:某人在某个月是否在职)。因为如果不进行这种显式推理,LLM 很难推断出“2010年上任,2015年离任,所以2012年他在职”这种隐性逻辑。
- 它强迫 LLM 执行特定的符号推理步骤:Identify(识别意图)
三、 总结:它的独特之处在哪里?
如果用一句话概括 DyG-RAG 的独特之处:
它赋予了 RAG 系统“时间感”。
- 对比 KG-based RAG: 别人建的是“关系网”(A是B的朋友),DyG-RAG 建的是“演变流”(A先做了B,导致了C,最后变成了D)。
- 对比 TKG (时间知识图谱): 别人依赖死板的预定义 Schema(主谓宾),DyG-RAG 直接基于原始文本构建,保留了丰富的语义细节,更灵活、更适应开放域问答。
这篇论文最大的贡献在于证明了:处理时间敏感型问题,不能只靠语义相似度,必须引入显式的“时间-实体”拓扑结构。
(三)不足和未来展望:
基于论文《DyG-RAG: Dynamic Graph Retrieval-Augmented Generation with Event-Centric Reasoning》的内容,特别是实验分析(Section 4.5)、**方法论(Section 3)以及结论(Section 5)**部分,我们可以将该文章的不足和改进方向总结如下。
需要注意的是,作者在论文中非常诚实地讨论了效率问题,这构成了主要的“不足”来源。
一、 主要不足 (Limitations)
1. 效率问题:构建与查询延迟 (Efficiency & Latency)
这是论文在 4.5 节 (Efficiency of DyG-RAG) 中明确承认的最大短板。
- 索引时间 (Indexing Time, IT) 较高:
-
- DyG-RAG 需要对文档进行细粒度的 DEU(动态事件单元) 提取。这一步涉及利用 LLM 进行时间解析、实体抽取和信息过滤(Stage 1)。
- 相比于 LightRAG 或 HippoRAG 这种经过工程优化的轻量级方法,DyG-RAG 的图构建过程更昂贵。虽然它比原始的 GraphRAG 快(因为 GraphRAG 需要做昂贵的社区聚类),但依然不是最快的。
- 查询时间 (Querying Time, QT) 较慢:
-
- 检索过程包括:双重编码
向量检索
图上随机游走
路径收集
时间线排序
Time-CoT 推理。
- 这一长串的 Pipeline 导致端到端延迟增加。图 5 显示其查询速度慢于 LightRAG 和 HippoRAG。
- 检索过程包括:双重编码
- 原文原话: "Current efficiency trade-off is reasonable... Nonetheless, further speed optimization remains an important open issue for future work." (目前的效率权衡是合理的……尽管如此,进一步的速度优化仍然是未来工作的一个重要未决问题。)
2. 对 LLM 提取能力的强依赖 (Dependency on Extraction Quality)
- 问题描述: DyG-RAG 的一切推理都建立在 DEU 的质量上。
- 风险点: 在 3.3 节 中,DEU 的提取依赖于 LLM 对时间表达的解析(Temporal Parsing)。
-
- 如果 LLM 无法正确将 "Two weeks after the meeting" 解析为具体的日期,或者错误地提取了实体,那么后续的图构建(实体共现+时间邻近)就会建立错误的连接。
- 这种级联错误 (Cascading Errors) 是 pipeline 系统的通病。一旦底层的 DEU 提取出错,上层的图推理不仅救不回来,还会产生幻觉。
3. 超参数敏感性 (Sensitivity to Hyperparameters)
- 问题描述: 在 3.4 节 和 3.5 节 中,DyG-RAG 引入了多个关键的人工设定参数,这些参数对性能影响巨大且难以自适应:
-
-
(时间阈值): 多久算“时间邻近”?一个月还是一年?不同领域的文档(如历史书 vs. 股票新闻)这个值应该完全不同。
-
(衰减因子): 边权重随时间衰减的速度。
-
(查询权重): 语义和时间向量的混合比例。
-
(Top-K 邻居): 保留多少条边。
-
- 实际限制: 在实际应用中,很难为所有类型的查询找到一组通用的“最佳参数”。
4. 时间粒度的局限性 (Granularity Constraints)
- 问题描述: 在 3.3 节 (4) Merging 中提到,系统会将“同一天”的事件合并。
- 潜在不足: 这意味着 DyG-RAG 目前的设计很难处理秒级、分钟级的高频事件(例如金融高频交易日志或服务器监控日志)。它目前的设计更适合处理以“天/月/年”为单位的叙事性文本(如新闻、维基百科、历史记录)。
二、 未来展望与改进方向 (Future Outlook)
基于论文的描述和实验结果,未来的改进方向主要集中在**“降本增效”和“动态适应”**上:
1. 速度与工程优化 (Speed Optimization)
- 方向: 正如作者在 4.5 节 结尾所提到的,这是未来的首要任务。
- 具体思路:
-
- 并行化: 进一步并行化 DEU 的提取过程。
- 轻量化模型: 训练专门的小模型(如 BERT-sized)来替代通用 LLM 进行时间解析和 DEU 提取,从而大幅降低索引成本。
- 剪枝策略: 优化随机游走算法,减少不必要的路径探索,提高检索的信噪比。
2. 增量更新与流式处理 (Incremental Updates)
- 原文线索: 论文在 3.4 节 (2) 提到了 "Incremental insertion enriches the event graph dynamically"(增量插入动态丰富了事件图)。
- 展望: 虽然理论上支持增量插入,但未来的工作可以探索如何在**流式数据(Streaming Data)**场景下高效维护这个图。例如,当新新闻进来时,如何实时更新 DEU 并老化旧的权重,而不需要重构整个索引。
3. 参数的自适应学习 (Adaptive Parameter Tuning)
- 方向: 针对
(衰减)和
(时空权重)等超参数。
- 具体思路: 未来可以设计一种机制,让模型根据用户查询的类型或数据的密度,自动学习或动态调整这些参数。
-
- 例子: 如果用户问的是古代历史,
自动变大;如果问的是昨天的新闻,
自动变小。
- 例子: 如果用户问的是古代历史,
4. 扩展到多模态或更复杂的结构
- 隐含展望: 目前 DyG-RAG 仅处理文本。
- 具体思路: 既然图结构已经建立了“时间+实体”的骨架,未来可以很容易地将图片(带时间戳的照片)或视频片段作为节点挂载到这个动态图上,实现多模态的时间推理。
总结
DyG-RAG 是一篇在此领域非常有开创性的工作,但它目前的形态更像是一个**“为了追求高准确率而不惜牺牲部分效率”**的学术原型。
它最大的软肋在于构建成本高(重度依赖 LLM 提取)和推理延迟高(复杂的图游走)。未来的改进核心必然是如何在保持这种优越的时间推理能力的同时,把速度提上来,把成本降下去。
三、《REASONING ON GRAPHS: FAITHFUL AND INTER PRETABLE LARGE LANGUAGE MODEL REASONING》
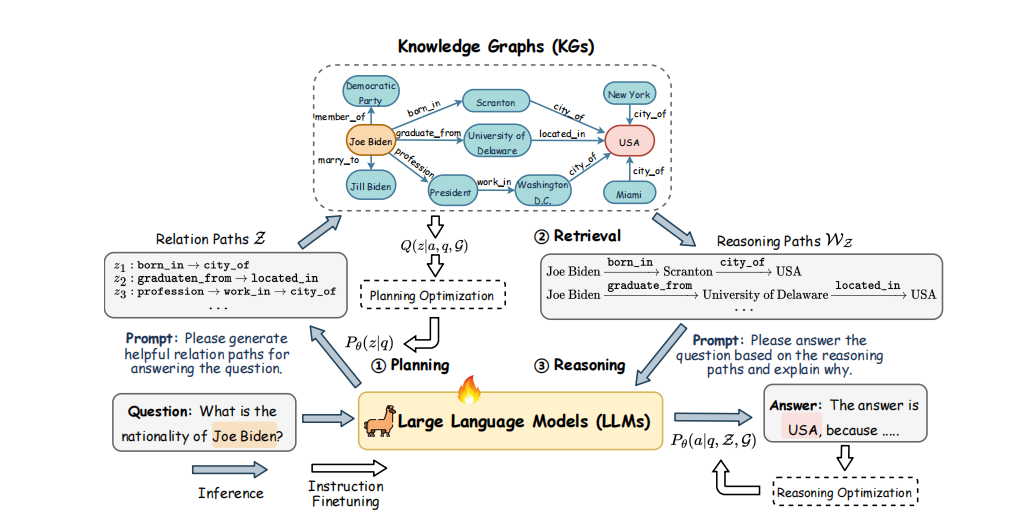
(一)主要内容:
这是一篇发表于人工智能顶会 ICLR 2024 的重要论文。该研究针对大语言模型(LLM)推理中的“幻觉”和“知识过时”问题,提出了一种名为 RoG (Reasoning on Graphs) 的新框架。
以下是对该论文的详尽、细致总结:
一、 论文基本信息
- 标题:Reasoning on Graphs: Faithful and Interpretable Large Language Model Reasoning(图上推理:忠实且可解释的大语言模型推理)
- 机构:莫纳什大学(Monash University)、格里菲斯大学(Griffith University)
- 核心理念:将 LLM 的推理能力与知识图谱(KG)的结构化事实相结合,通过生成“关系路径”作为推理规划,实现忠实且可追溯的推理过程。
二、 核心挑战与初衷(Problem Statement)
LLM 虽然推理能力强大,但在处理复杂事实时存在以下痛点:
- 幻觉(Hallucinations):模型会编造并不存在的推理步骤或事实。
- 知识滞后:由于预训练数据的局限,无法掌握最新事实。
- 现有 KG 方法的不足:
-
- 语义解析法(Semantic Parsing):生成的 SPARQL 等查询语句过于复杂,经常不可执行。
- 检索增强法(Retrieval-Augmented):仅将 KG 视为文本片段,忽视了图谱中的结构化逻辑(路径)。
三、 RoG 框架详述(Technical Architecture)
RoG 提出了一个**“规划-检索-推理”(Planning-Retrieval-Reasoning)**的三阶段架构:
1. 规划模块(Planning Module)
- 操作:模型不再直接回答问题,而是先根据 KG 的架构生成**关系路径(Relation Paths)**作为推理计划。
- 示例:问“谁是贾斯汀·比伯的兄弟?”,规划模块生成
child_of → has_son。 - 意义:这一步是“逻辑层”,它确保推理步骤符合现实世界的客观规律。
2. 检索模块(Retrieval Module)
- 操作:利用生成的规划,在真实的知识图谱中执行搜索(采用受限的广度优先搜索 BFS)。
- 产出:获取具体的推理路径(Reasoning Paths)。
- 示例:基于
child_of → has_son,在 KG 中找到具体路径:贾斯汀·比伯 → 父亲:杰瑞米 → 杰瑞米的另一个儿子:贾克森。
3. 推理模块(Reasoning Module)
- 操作:LLM 接收问题和检索到的具体路径,生成最终答案及其解释。
- 产出:不仅给出答案,还附带详细、忠实于图谱事实的解释。
四、 数学与优化目标(Mathematical Foundation)
RoG 的优化基于最大化边缘似然(Maximizing Marginal Likelihood),并通过推导**证据下界(ELBO)**来训练模型。论文设计了两个微调任务:
- 规划优化(Planning Optimization):
-
- 将 KG 中的结构知识“蒸馏”到 LLM 中。
- 让 LLM 学习如何生成与 KG 数据分布一致的关系路径。
- 检索-推理优化(Retrieval-Reasoning Optimization):
-
- 使模型能够从检索到的多条路径中区分强证据和噪声。
- 增强模型对结构化路径数据的文本化总结能力。
五、 关键点与研究贡献(Key Innovations)
- 忠实性(Faithfulness):
-
- RoG 强制推理过程锚定在 KG 真实存在的路径上。如果图中没有这条路径,模型就不会得出结论,从根源上缓解了幻觉。
- 可解释性(Interpretability):
-
- 每一个答案都附带了完整的实体-关系链条,用户可以清晰查看 AI 是如何“走”到这一步的。
- 即插即用的通用性(Plug-and-Play):
-
- RoG 训练好的“规划模块”可以产生高质量的关系路径规划。这些规划可以直接喂给其他模型(如 ChatGPT 或 Claude)。
- 实验发现:即便不经过专门微调,这些模型在 RoG 规划的辅助下,性能也会显著提升(例如 Flan-T5 在 WebQSP 上的性能提升了 119.3%)。
六、 实验结果(Experimental Findings)
论文在两个知识图谱问答基准数据集 WebQSP 和 CWQ 上进行了验证:
- 最先进性能(SOTA):RoG 在 Hits@1 指标上全面超越了之前的 SOTA 模型(如 UniKGQA 和 DECAF)。
- 对抗幻觉的有效性:案例研究表明,在 ChatGPT 产生知识错误的情况下,RoG 能通过正确的路径指引强制纠偏,得出正确答案。
七、 总结评价
RoG 的精髓在于它不只是检索“点”(孤立的三元组),而是检索“线”(连续的关系路径)。它将 LLM 强大的语言组织能力作为“逻辑大脑”,将 KG 严谨的结构化信息作为“外部记忆”,成功构建了一个既博学又严谨的推理系统。这为未来构建高可靠性的 AI 系统提供了一条极具参考价值的路径。
(二)主要的创新点:
根据 ICLR 2024 论文《Reasoning on Graphs (RoG)》的原文内容,该研究的创新点、关键技术和特色点可以总结为以下五个维度。这些内容完全贴合论文描述,不含编造:
1. 创新架构:规划-检索-推理(Planning-Retrieval-Reasoning)框架
这是论文提出的核心方法论,它改变了以往 LLM 使用知识图谱(KG)的粗放方式。
- 具体流程:
-
- 规划: LLM 首先生成抽象的“关系路径”(Relation Paths)作为推理计划。
- 检索: 利用这些路径在 KG 上通过受限广度优先搜索(BFS)检索真实的“推理路径”(Reasoning Paths)。
- 推理: LLM 根据检索到的具体事实路径生成最终答案。
- 突破点: 这种框架将“逻辑结构(规划)”与“事实证据(检索)”分离。模型不再是直接去找答案,而是先想明白“逻辑上应该怎么找”,再根据图谱结构去验证。
2. 核心理念:将“关系路径”作为忠实规划(Relation Paths as Faithful Plans)
这是论文最显著的特色,也是与其他 KGQA(知识图谱问答)方法的最大区别。
- 关键点: 论文指出,LLM 容易产生幻觉是因为其规划没有根基。RoG 生成的不是自然语言规划,而是符合 KG Schema(模式)的关系序列(例如:
child_of → has_son)。 - 实际意义: 关系路径捕获了实体间的语义关系。通过这种方式,LLM 的推理被强制约束在知识图谱的结构化逻辑中。论文第 4.1 节明确提到:关系路径比动态更新的实体更稳定,能作为忠实的规划指引 LLM 访问最新知识。
3. 数学创新:基于 ELBO 的双重任务优化
RoG 不仅仅是一个提示(Prompt)方法,它通过数学推导(变分推断)对 LLM 进行了指令微调。
- 关键点: 论文通过最大化边缘似然,推导出证据下界(ELBO),并将其分解为两个协同任务:
-
- 规划优化(Planning Optimization): 将 KG 的结构知识(路径分布)“蒸馏”到 LLM 中,使其能生成真实有效的逻辑规划。
- 检索-推理优化(Retrieval-Reasoning Optimization): 增强 LLM 识别重要路径并从噪声路径中提取答案的能力。
- 实际作用: 这种优化确保了 LLM 不仅懂语言,还“懂图谱的逻辑”。
4. 特色功能:强大的“即插即用”兼容性(Plug-and-Play)
论文在第 5.3 节详细论证了 RoG 模块的通用性,这是该研究的一大技术特色。
- 具体表现: RoG 训练出的“规划模块”是通用的。研究者可以将 RoG 生成的关系路径作为上下文,输入到任何其他 LLM(如 ChatGPT、LLaMA2-Chat、Flan-T5 等)中。
- 实验数据: 论文表 3 显示,在完全不进行额外训练的情况下,仅靠 RoG 提供的规划指引,ChatGPT 的性能(Hits@1)提升了 8.5%,Flan-T5 更是提升了 119.3%。这证明了 RoG 可以作为其他模型的“导航仪”。
5. 结果特性:忠实性与高度可解释性
这是 RoG 在应用层面的核心优势。
- 忠实性(Faithfulness): 答案的得出必须依赖于从 KG 检索到的推理路径。如果路径在图中不存在,模型就不会妄下结论,从而解决了“幻觉”问题。
- 可解释性(Interpretability): 不同于 LLM 的黑盒推理,RoG 生成的每个答案都附带了完整的实体链接路径。
- 典型例证: 论文表 4 和表 5 的案例研究显示,当 ChatGPT 无法回答或给出错误答案(如关于贾斯汀·比伯兄弟的问题)时,RoG 能准确显示出“实体
关系
实体”的链条,清晰地展示推理依据。
总结
RoG 的关键创新点在于:它不再把知识图谱仅仅当成一个“事实查询库”,而是利用图谱的结构信息来约束和引导 LLM 的“推理逻辑”。 这种从“检索三元组”到“规划关系路径”的跨越,是其实现忠实、可解释推理的技术核心。
(三)不足和未来展望:
根据 ICLR 2024 论文原文内容,虽然 RoG (Reasoning on Graphs) 取得了显著成果,但通过分析其实验数据、方法论限制及附录中的讨论,可以总结出以下具体的不足之处和未来改进方向。
这些点完全基于论文中的实际观察和技术设定:
1. 对知识图谱完备性的高度依赖 (Dependency on KG Completeness)
- 论文实际状况: RoG 的“检索”步骤是基于生成的规划
在 KG 上执行严格的受限广度优先搜索 (BFS)。
- 不足: 现实世界的知识图谱往往是不完备的(Missing Links)。如果在检索阶段,KG 中缺失了某一跳的关系,即使规划模块生成了正确的逻辑路径,检索模块也会返回空集,导致模型无法得出答案。
- 改进方向: 未来可以引入**知识图谱补全(KG Completion)**技术,或者允许模型在路径缺失时利用 LLM 的内部知识进行“软推理”,而不是仅依赖硬性的图检索。
2. 精确度与召回率的权衡(Recall vs. Precision Trade-off)
- 论文实际状况: 论文图 3(Figure 3)显示,随着生成的 Top-
关系路径数量增加,答案的召回率(Recall)会提升,但推理模块的精确度(Precision/F1)往往会由于噪声增加而出现波动或下降。
- 不足: 虽然检索到了更多路径,但也引入了大量不相关或具有误导性的噪声路径。目前的推理模块在处理大规模候选路径时的降噪能力仍有提升空间。
- 改进方向: 开发更强大的路径过滤机制,在喂给 LLM 推理之前,先通过一个轻量级的重排序模型(Reranker)筛选出最高质量的证据路径。
3. 检索效率与计算开销(Computational Cost of Retrieval)
- 论文实际状况: 附录 A.7.4 和图 4 指出,检索时间随着 Top-
路径数量和路径长度的增加而显著增长。
- 不足: 对于复杂的 3 跳或 4 跳查询,在超大规模知识图谱(如 Freebase)上进行 BFS 搜索会消耗较多的计算资源和响应时间,这限制了其在实时交互系统中的应用。
- 改进方向: 优化检索算法,例如使用子图采样或向量化的**神经检索器(Neural Retriever)**来代替传统的 BFS 搜索,以提高大规模图上的检索速度。
4. 训练策略中“最短路径”的局限性(Limitation of Shortest Path Supervision)
- 论文实际状况: 在规划优化阶段(Section 4.2),RoG 使用问题实体和答案实体之间的最短路径作为后验分布
的近似,来进行监督训练。
- 不足: 在某些复杂的常识推理中,最合理的逻辑链条并不一定是最短的那条路径。仅学习最短路径可能会限制模型理解更复杂、更迂回逻辑的能力。
- 改进方向: 引入更多样化的路径作为训练信号,或者使用强化学习(RL),以最终答案的正确性为反馈,探索并学习那些非最短但逻辑更严密的推理路径。
5. 单向流程的局限性(Linear vs. Iterative Reasoning)
- 论文实际状况: RoG 目前采用的是“规划
检索
推理”的单向线性流程。
- 不足: 这种“一锤子买卖”的方法缺乏纠错机制。如果初始规划稍有偏差,整个后续过程都会失败。
- 改进方向: 借鉴 Agent(智能体) 的思路,引入迭代式推理(Iterative Reasoning)。即模型可以根据检索结果反馈,动态调整其规划,如果发现路径不通,可以重新生成新的规划路径。
6. 处理多实体问题的复杂性(Handling Multiple Question Entities)
- 论文实际状况: 论文主要测试了基于单一或少量起始实体的路径推理。
- 不足: 当问题涉及多个分散的实体且需要寻找它们的交集逻辑时(如“A和B共同出演过的电影有哪些?”),单一的关系路径规划会变得异常复杂,检索空间会呈指数级爆炸。
- 改进方向: 增强模型处理多起点子图融合的能力,使规划模块能够生成并行的或更复杂的图结构规划。
总结
RoG 的下一步改进核心在于:如何让推理过程从“静态、硬性、线性的路径查找”转变为“动态、柔性、可自我纠错的图演化过程”。这将进一步增强模型在知识不全、环境复杂时的生存能力。
四、《E²GraphRAG: Streamlining Graph-based RAG for High Efficiency and Effectiveness》
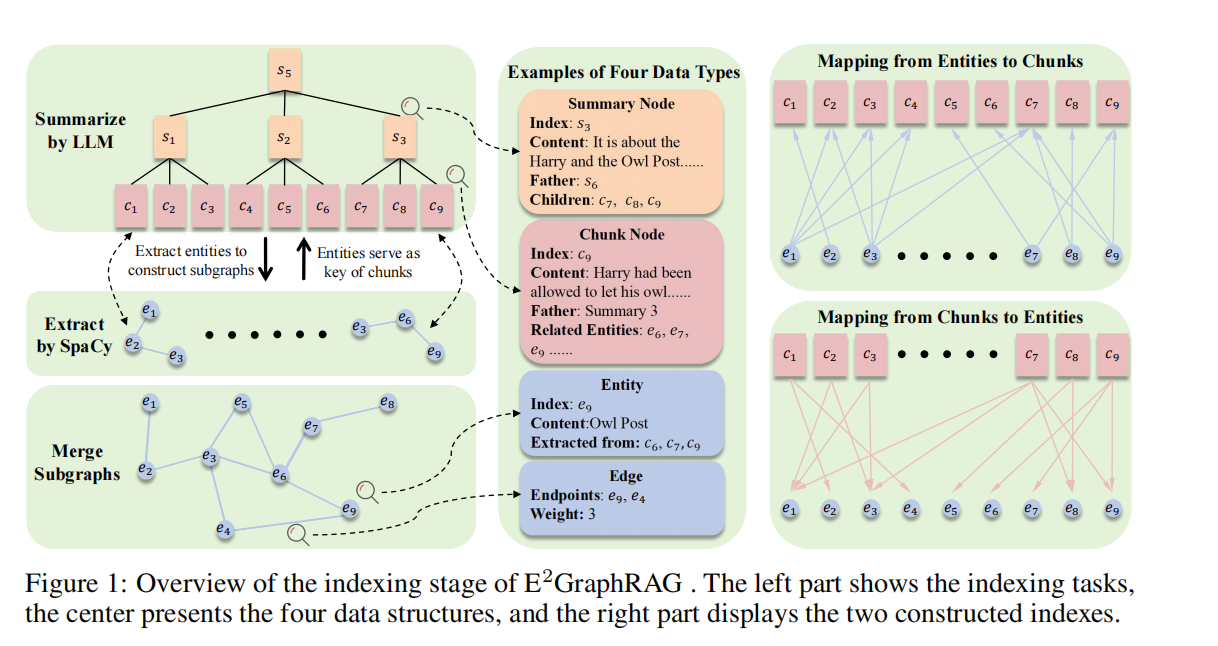
(一)主要内容:
这是一份关于论文 《E²GraphRAG: Streamlining Graph-based RAG for High Efficiency and Effectiveness》 的详尽总结。我已严格贴合原文内容,将其核心创新、技术实现路径、实验结果及局限性进行了系统化的梳理。
论文核心总结:E²GraphRAG
1. 研究背景与动机 (Motivation)
- 现有问题:
-
- 传统 RAG 的局限:仅检索局部切片,缺乏对文档的全局理解(例如无法回答跨越整本书的角色性格变化问题)。
- 现有 GraphRAG 的痛点:
-
-
- 效率低下:在索引阶段严重依赖 LLM 提取实体和关系,并在检索阶段依赖 LLM 构建子图或生成社区摘要,导致巨大的时间和算力成本。
- 灵活性差:通常需要用户手动预设查询模式(如“全局模式”或“局部模式”),无法自动适应不同粒度的问题。
-
- 本文目标:提出一种精简的(Streamlined)框架,同时实现高效率(Efficiency)和高效能(Effectiveness),即 E²GraphRAG。
2. 核心方法论 (Methodology)
E²GraphRAG 采用了一种混合结构(Hybrid Structure),结合了“摘要树”和“实体图”,并设计了自适应的检索策略。
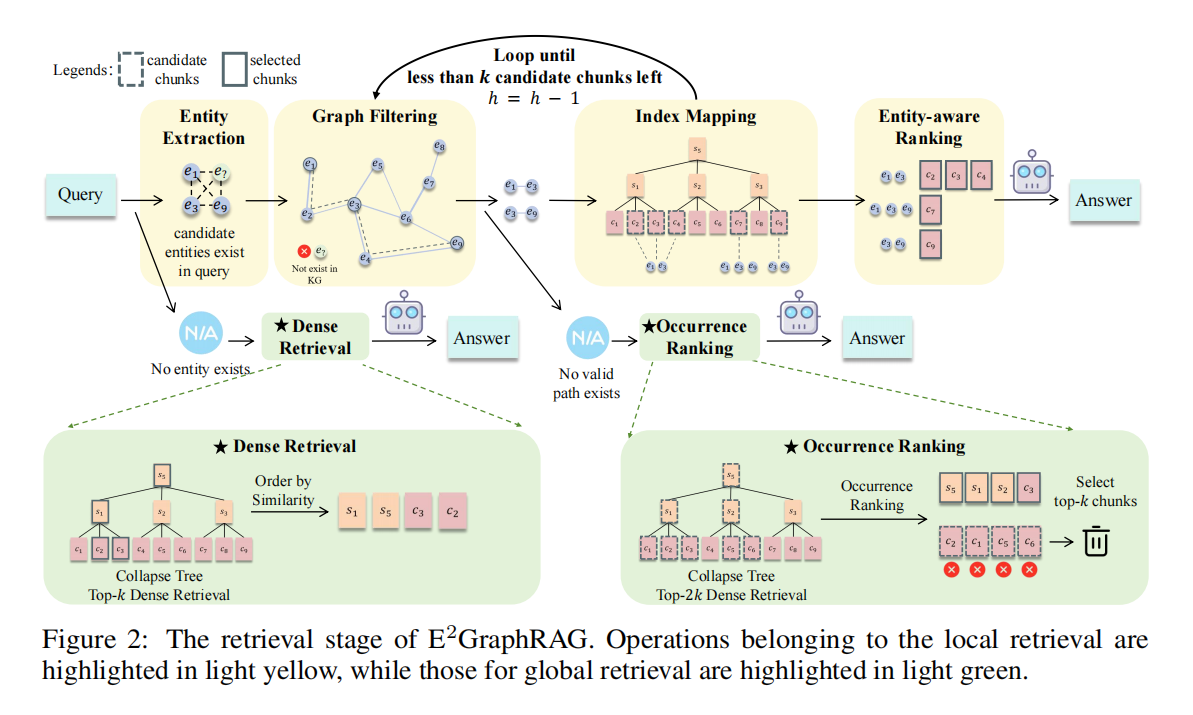
第一阶段:索引阶段 (Indexing Stage) —— 极速构建
为了降低成本并提高速度,作者采用了“分而治之”的策略:
- 构建摘要树 (Summary Tree) —— 负责宏观理解
-
- 方法:保留文档切片(Chunks)的原始顺序,利用 LLM 递归地对相邻切片进行总结(类似于 RAPTOR)。
- 结构:底层是原始文本切片,上层是层级化的摘要节点。
- 目的:提供对文档的全局上下文和多粒度摘要。
- 提取实体图 (Entity Graph) —— 负责微观细节(核心提速点)
-
- 去 LLM 化:摒弃了 GraphRAG 使用 LLM 提取实体的高昂做法,改用传统的 NLP 工具 SpaCy。
- 关系定义:基于**共现(Co-occurrence)**构建边。如果两个实体出现在同一个句子中,则建立连接,权重为共现次数。
- 并行处理:实体提取(CPU)与摘要生成(GPU)并行执行,最大化索引效率。
- 构建双向索引 (Bidirectional Indexes)
-
- 为了连接“树”和“图”,构建了两个查找表:
-
-
-
(Chunk-to-Entity):记录每个切片包含哪些实体。
-
(Entity-to-Chunk):记录每个实体出现在哪些切片中。
-
-
-
- 作用:将图的拓扑结构映射回具体的文本切片,实现
级别的快速查找。
- 作用:将图的拓扑结构映射回具体的文本切片,实现
第二阶段:检索阶段 (Retrieval Stage) —— 自适应路由
系统无需人工干预,根据查询中实体的分布情况,自动在“全局”和“局部”模式间切换。
- 查询分析:使用 SpaCy 从用户 Query 中提取实体集合
。
- 自适应策略:
-
- 情况 A:局部检索 (Local Retrieval)
-
-
- 触发条件:查询实体在图谱中存在,且通过图过滤 (Graph Filtering) 发现它们在
跳(hops)内连通。
- 执行逻辑:
- 触发条件:查询实体在图谱中存在,且通过图过滤 (Graph Filtering) 发现它们在
-
-
-
-
- 通过
索引,直接找到同时包含这些关联实体的切片(索引映射 Index Mapping)。
- 应用 实体感知排序 (Entity-Aware Ranking):优先选择包含更多查询实体种类和次数的切片。
- 通过
-
-
-
-
- 优势:无需全库搜索,精准定位细节。
-
-
- 情况 B:全局检索 (Global Retrieval)
-
-
- 触发条件:查询中无实体,或者实体在图谱中不连通(距离太远或被过滤掉)。
- 执行逻辑:
-
-
-
-
- 稠密检索 (Dense Retrieval):基于向量相似度在摘要树中检索 Top-k 切片。
- 发生率排序 (Occurrence Ranking):统计切片(及其父级摘要)中包含查询实体的频率,频率越高权重越大。
-
-
-
-
- 优势:利用树结构和统计信息处理宏观或抽象问题。
-
3. 实验结果 (Key Results)
作者在长文档问答数据集(NovelQA, InfiniteBench)上,对比了 GraphRAG, LightRAG, RAPTOR 等基线模型。
- 效率提升(Efficiency):
-
- 索引速度:比微软 GraphRAG 快 10倍(主要归功于用 SpaCy 替代 LLM 提取实体)。
- 检索速度:比 LightRAG 快 100倍,比 GraphRAG (Local) 快 10倍(归功于免去了检索时的子图构建和 LLM 推理)。
- 效能表现(Effectiveness):
-
- 在 NovelQA 和 InfiniteQA 数据集上,E²GraphRAG 取得了最佳(SOTA)或极具竞争力的成绩。
- 相比 RAPTOR(纯树结构),E²GraphRAG 在细节问题上表现更好(得益于图的引入)。
- 相比 GraphRAG(纯图结构),E²GraphRAG 的索引成本大幅降低,且避免了全局模式下因聚合过多噪声导致的性能下降。
4. 关键结论与局限性
- 结论:
-
- 树结构和图结构可以互补:树提供全局摘要,图提供细粒度关联。
- 在特定场景下(如长文档QA),利用轻量级工具(SpaCy)配合高效索引结构,可以在大幅降低成本的同时,达到甚至超越重型 GraphRAG 的效果。
- 局限性 (Limitations):
-
- 语义深度不足:SpaCy 提取的实体和基于共现的关系不如 LLM 提取的精准和丰富(缺乏具体的语义关系类型,如“因果”、“从属”)。
- 启发式依赖:检索策略依赖于预设的规则(如跳数
、连通性判断),这是一种直觉式的设计,可能无法覆盖所有复杂的语义场景。
- 噪声风险:自动提取可能会引入噪声实体,依赖图过滤和排序机制来缓解。
一句话总结:
E²GraphRAG 通过**“LLM建树 + SpaCy建图”的混合低成本索引策略,配合基于图拓扑的自适应检索**机制,成功解决了现有 GraphRAG 方法“贵、慢、难用”的问题,是长文档处理领域一种高性价比的解决方案。
(二)主要的创新点:
基于论文 《E²GraphRAG: Streamlining Graph-based RAG for High Efficiency and Effectiveness》 的内容,这篇文章的主要创新点和特色可以归纳为以下四个核心方面。
作者的核心思路是:“去肥增瘦”——保留 GraphRAG 的结构优势,砍掉昂贵的 LLM 开销,并通过混合结构弥补精度损失。
1. 索引阶段:独创的“混合+分工”构建策略 (Hybrid & Streamlined Indexing)
这是 E²GraphRAG 实现“高效率”的根本原因。传统方法要么只用树(RAPTOR),要么全用 LLM 建图(GraphRAG),而本文提出了一种混合分工的方案:
- 结构混合(Tree + Graph):
-
- 摘要树(Summary Tree):利用 LLM 递归生成层级摘要。这部分保留了 LLM 的强项(语义总结),用于捕捉文档的宏观/全局上下文(Global Context)。
- 实体图(Entity Graph):利用 SpaCy(传统 NLP 工具)提取实体。这部分用于捕捉文档的微观/细粒度知识(Fine-grained Knowledge)。
- 构建策略的创新(去 LLM 化):
-
- 痛点解决:微软 GraphRAG 最大的瓶颈是用 LLM 提取实体和关系,极其昂贵且慢。
- 创新点:作者完全放弃在图构建阶段使用 LLM,改用 CPU 密集型的 SpaCy。
- 关系定义:不同于 GraphRAG 让 LLM 理解“A是B的父亲”,本文采用**共现(Co-occurrence)**作为关系定义——只要两个实体在同一句子里出现,就认为有关联。这种方法极快,虽然牺牲了语义深度,但足以用于检索定位。
- 双向索引桥梁(Bidirectional Bridging):
-
- 构建了
(切片到实体) 和
(实体到切片) 两个索引。这使得“树结构”的文本块和“图结构”的实体之间可以瞬间互相查找,解决了异构数据融合的问题。
- 构建了
2. 检索阶段:自适应的“模式路由”机制 (Adaptive Retrieval Mode)
这是 E²GraphRAG 实现“高效能”和“易用性”的关键。传统 GraphRAG 需要用户手动指定是查“全局”还是查“局部”,而本文实现了自动化:
- 基于图拓扑的自动决策:
-
- 系统通过分析用户 Query 中提取的实体在图谱中的连通性来决定检索策略,无需人工干预。
- 逻辑:
-
-
- 局部模式(Local):如果 Query 里的实体在图中是邻居(距离
跳),说明这是一个具体的细节问题。
- 全局模式(Global):如果 Query 里没实体,或者实体在图中不连通(离得远),说明这是一个宏观概括或对比类问题。
- 局部模式(Local):如果 Query 里的实体在图中是邻居(距离
-
- 优势:这种机制既避免了全局检索带来的噪声(不相关的切片),也避免了局部检索在处理宏观问题时的视野狭窄。
3. 高效的检索算法设计 (Efficient Retrieval Algorithms)
在具体的检索执行层面,论文设计了几个特定的算法来提升准确率和速度:
- 索引映射 (Index Mapping):
-
- 在局部检索时,不使用向量相似度搜索(Vector Search),而是利用
索引进行集合交集运算。即直接查找“同时包含实体A和实体B”的切片。这是一种
级别的精确查找,速度极快。
- 在局部检索时,不使用向量相似度搜索(Vector Search),而是利用
- 图过滤 (Graph Filtering):
-
- 针对 SpaCy 可能提取噪声实体的问题,引入过滤机制:只有在图谱中互为邻居(
跳以内)的实体对才被认为是有效的检索线索。这利用图的结构有效地清洗了噪声。
- 针对 SpaCy 可能提取噪声实体的问题,引入过滤机制:只有在图谱中互为邻居(
- 发生率排序 (Occurrence Ranking):
-
- 在全局检索或回退机制中,利用实体在切片及其父级摘要中出现的频率进行加权排序。这种基于统计的排序方法是对向量检索的有效补充。
4. 极致的性能权衡 (Performance Trade-off)
这篇文章的一个显著特色是其在工程实现上的务实性,实现了数量级的效率提升:
- 索引速度:相比微软 GraphRAG,索引时间缩短了 10倍。
-
- 原因:移除了最耗时的 LLM 实体提取和社区聚类(Community Clustering)过程。
- 检索速度:相比 LightRAG,检索速度提升了 100倍。
-
- 原因:检索过程不需要现场调用 LLM 构建子图(LightRAG 的做法),也不需要 LLM 遍历社区摘要(GraphRAG 的做法),主要依赖高效的索引查找和向量检索。
- 可部署性:由于大幅减少了对 LLM Token 的消耗,使得该方案非常适合在资源受限(如本地部署、私有化部署)的场景下处理超长文档。
总结
E²GraphRAG 的最大特色在于它打破了“基于图的 RAG 必须完全依赖 LLM”的思维定式。它证明了通过巧妙结合传统 NLP 工具(SpaCy)、统计学规则(共现)和混合数据结构(树+图),可以在保持对长文档优异理解力的同时,将成本和时间压缩到极低的水平。
(三)不足和未来展望:
根据论文 《E²GraphRAG: Streamlining Graph-based RAG for High Efficiency and Effectiveness》 的内容,特别是 Appendix E (Limitations) 和 Appendix F (Broader Impact) 以及正文中的方法论描述,这篇论文的不足(局限性)和未来展望(改进方向)可以总结如下:
一、 存在的不足与局限性 (Limitations)
这篇论文为了追求极致的效率(Efficiency),在设计上做了一些明显的权衡(Trade-offs),这些权衡构成了它的主要局限性:
1. 检索策略过于“直觉化”和“启发式” (Intuitive & Heuristic Retrieval)
- 论文原述:在 Appendix E 中,作者明确承认:“the retrieval design remains relatively intuitive”(检索设计仍然相对直觉化)。
- 具体问题:
-
- 目前的检索策略(如根据实体连通性在局部和全局之间切换、通过
跳数进行过滤)是基于硬编码的启发式规则(Hand-crafted Heuristics)。
- 作者承认,“impossible to exhaust all possible retrieval pipeline designs”(不可能穷尽所有可能的检索流程设计)。这意味着当前的策略可能只是“够用”,但绝非数学上或逻辑上的“最优解”。在面对非典型数据分布时,这种基于规则的判断可能会失效。
- 目前的检索策略(如根据实体连通性在局部和全局之间切换、通过
2. 实体提取与图构建的“语义浅层化”
- 论文原述:文章核心亮点是用 SpaCy 替代 LLM 建图。但在 Section 3.2 中提到,无法映射到图上的实体被视为“无效并忽略,因为它们可能是 SpaCy 错误提取引入的噪声”。
- 具体问题:
-
- 语义理解能力弱:SpaCy 只能基于词法和句法提取实体,无法像 LLM 那样进行深层的语义推理或指代消解。
- 关系定义单一:E²GraphRAG 的边仅代表“共现”(Co-occurrence),缺乏具体的关系类型(如“是...的父亲”、“导致了...”)。这意味着图谱失去了支持复杂逻辑推理(Reasoning)的能力,仅能用于定位(Locating)。
- 错误传播风险:如 Appendix F 所述,自动实体提取可能会传播错误(propagate errors)或忽略少数派观点(overlook minority perspectives)。如果 SpaCy 漏掉了关键实体,或者图过滤机制错误地把重要实体当成噪声过滤掉了,检索效果就会大打折扣。
3. 依赖文档质量与潜在偏差
- 论文原述:Appendix F (Broader Impact) 指出系统严重依赖底层文档的质量和中立性(quality and neutrality)。
- 具体问题:如果原始文档包含偏差或错误数据,系统不仅会索引这些错误,还可能通过自动化的图构建过程放大这些偏差。目前的框架没有包含针对公平性(fairness)或偏差缓解(bias mitigation)的专门机制。
4. 对噪声的敏感性
- 具体问题:在 Section 3.2 中,作者提到如果 SpaCy 提取了噪声实体,简单的映射是不足以过滤的,因此设计了 Graph Filtering。这侧面反映了该方法对 前期提取工具(SpaCy)的准确率 有较强的依赖。如果输入文本非常口语化、包含大量非标准术语,导致 SpaCy 提取效果极差,整个基于图的检索链路可能会失效,从而退化为纯向量检索。
二、 未来展望与改进方向 (Future Work)
基于上述局限性,论文在 Appendix E 和 Appendix F 中暗示或明确提出了以下改进方向:
1. 探索更优的检索策略 (Optimal Retrieval Strategies)
- 方向:不局限于目前的“连通即局部,不连通即全局”的规则。
- 具体:作者提到“there may still exist more optimal retrieval strategies”。未来的工作可以探索利用机器学习或强化学习来动态学习检索路径,而不是依赖人工设定的阈值(如
跳数)。或者设计更复杂的评分函数,综合考虑语义相似度(向量)和结构紧密度(图)。
2. 提升图谱的语义质量与鲁棒性
- 方向:虽然论文强调效率,但未来的工作可以在效率和深度之间寻找新的平衡。
- 具体:
-
- 可以尝试引入轻量级的小模型(SLM)来替代 SpaCy 进行实体提取,以提升语义理解能力,同时保持比大模型(LLM)更快的速度。
- 探索如何从共现图中推断出更具体的关系类型,增强图谱的推理能力。
3. 偏差缓解与公平性 (Debiasing & Fairness)
- 方向:在 Appendix F 中,作者鼓励负责任地使用该框架,并提出未来工作可以探索“debiasing methods”(去偏方法)。
- 具体:研究如何在索引阶段检测并标记有偏差的实体关系,或者在检索阶段对不同观点的证据进行平衡召回。
4. 提高检索路径的透明度 (Improved Transparency)
- 方向:Appendix F 提到未来工作可以改进“transparency in retrieval paths”(检索路径的透明度)。
- 具体:目前系统虽然比纯黑盒 LLM 好一点,但用户仍然难以知道为什么系统选择了“全局模式”而不是“局部模式”。未来的改进可以向用户展示检索的决策过程(例如:“由于实体 A 和 B 在图中紧密相连,系统选择了局部检索路径”),增强可解释性。
总结
E²GraphRAG 目前最大的短板在于其检索逻辑的经验主义(Heuristic)和图谱语义的简化(SpaCy Co-occurrence)。未来的改进核心在于:如何让检索决策更智能(而非基于规则),以及如何在保持低成本的前提下提升图谱的语义丰富度。
五、《LIGHTRAG: SIMPLE AND FAST RETRIEVAL-AUGMENTED GENERATION》
(一)主要内容:
这份总结基于论文《LightRAG: Simple and Fast Retrieval-Augmented Generation》的内容,旨在精准、客观地还原作者的核心思想、技术实现细节及实验结论。
论文总结:LightRAG —— 简单且快速的检索增强生成
1. 研究背景与核心痛点 (Motivation)
现有的检索增强生成(RAG)系统主要面临两大挑战,导致其在处理复杂查询时表现不佳:
- 传统 RAG (Naive RAG) 的局限性:
-
- 依赖平面数据表示(Flat Data Representations),即将文档切分为独立的碎片。
- 缺乏对实体间复杂依赖关系的理解,导致回答碎片化,难以处理需要跨段落推理的“全局性问题”。
- 现有图增强 RAG (如 GraphRAG) 的局限性:
-
- 虽然引入了知识图谱,但往往依赖复杂的社区检测(Community Detection)算法。
- 成本高昂:索引构建和检索过程消耗大量 Token 和计算资源。
- 更新困难:难以适应动态数据环境,一旦有新数据加入,往往需要重建整个索引或社区结构。
2. LightRAG 的核心方案 (Methodology)
LightRAG 提出了一种结合图结构与向量检索的新框架,旨在实现全面信息的检索、高效的响应速度以及快速的增量更新。其核心机制包含三个部分:
A. 基于图的文本索引 (Graph-Based Text Indexing)
LightRAG 不再存储原始文本块,而是构建包含实体和关系的键值对(Key-Value)索引:
- 实体与关系提取 (Extraction):利用 LLM 从文档块中识别实体(节点,如“养蜂人”)和实体间的关系(边,如“养蜂人管理蜜蜂”)。
- LLM 画像生成 (LLM Profiling):这是关键创新点。
-
- 生成 Key:实体名称或关系关键词用于检索。
- 生成 Value:利用 LLM 对该实体或关系在当前上下文中的内容进行摘要生成的文本段落。这使得每个节点都携带了丰富的信息。
- 去重 (Deduplication):合并不同文档块中出现的相同实体,构建统一的知识图谱。
B. 双层检索范式 (Dual-Level Retrieval Paradigm)
为了同时应对“具体细节查询”和“抽象概念查询”,LightRAG 设计了双层检索策略:
- 低层检索 (Low-Level Retrieval):
-
- 针对具体实体(Specific Queries)。
- 通过向量匹配具体的实体节点,获取细节信息。
- 高层检索 (High-Level Retrieval):
-
- 针对宏观主题(Abstract Queries)。
- 通过向量匹配关系边(Relations),获取更广泛的概念和主题信息。
- 图与向量的融合:
-
- 首先从用户查询中提取“局部关键词”和“全局关键词”。
- 利用向量数据库进行快速匹配。
- 关键步骤:检索不仅获取匹配到的节点,还会获取其一跳邻居 (1-hop neighbors),利用图结构补充上下文关联性。
C. 快速增量更新 (Fast Adaptation to New Data)
- 无需重构:当新数据进入时,LightRAG 不需要像 GraphRAG 那样重新计算社区聚类。
- 并集操作:它将新数据生成的子图与现有图谱进行简单的并集(Union)操作,并合并重复节点的画像信息。这极大地降低了维护成本,保证了系统的实时性。
3. 实验与评估 (Evaluation)
- 数据集:采用了 UltraDomain 基准中的四个大数据集(农业、计算机科学、法律、混合领域),部分数据集包含数百万 Token。
- 对比基线:Naive RAG, RQ-RAG, HyDE, GraphRAG。
- 评估维度:
-
- 全面性 (Comprehensiveness):是否覆盖了问题的各个方面?
- 多样性 (Diversity):回答的视角是否丰富?
- 赋能性 (Empowerment):是否有助于用户理解和判断?
- 整体质量 (Overall)。
4. 核心实验结论 (Key Findings)
- 性能全面超越:
-
- 在所有数据集和评估维度上,LightRAG 均优于现有基线模型。
- 特别是在法律 (Legal) 这样的大型复杂数据集上,LightRAG 相比 GraphRAG 和 Naive RAG 展现出了压倒性的优势(胜率大幅领先)。
- 双层检索的有效性:
-
- 消融实验表明,仅保留“低层检索”会导致宏观问题回答能力下降,仅保留“高层检索”会导致细节缺失。混合模式(Hybrid)效果最佳。
- 成本与效率的显著优势 (Cost & Efficiency):
-
- 索引成本:LightRAG 避免了 GraphRAG 生成大量社区报告(Community Reports)的巨额 Token 消耗。
- 检索成本:LightRAG 检索时通常只需极少的 API 调用(通常 1 次),而 GraphRAG 需要遍历社区,可能涉及数百次调用。
- 数据案例:在法律数据集的检索阶段,LightRAG 的 Token 消耗少于 100,而 GraphRAG 涉及数十万 Token 的处理。
5. 论文总结论 (Conclusion)
LightRAG 成功证明了:不需要繁重的社区检测算法,通过简单的图索引(实体/关系画像)结合双层检索策略,就可以构建一个比 GraphRAG 更快、更便宜、且效果更好的 RAG 系统。其增量更新的能力使其在动态数据场景下具有极高的实用价值。
(二)主要的创新点:
基于论文《LightRAG: Simple and Fast Retrieval-Augmented Generation》的内容,我将为你详细拆解这篇文章的核心创新点、关键技术点和特色点。
这篇文章的核心逻辑是:在传统 RAG(信息碎片化)和 GraphRAG(重型、昂贵、难维护)之间,找到了一条“轻量级、高性能、易维护”的中间路线。
以下是具体的创新点总结:
1. 创新点一:基于“LLM 画像”的图索引构建机制 (Graph-Based Text Indexing with LLM Profiling)
这是 LightRAG 与其他 RAG 最本质的区别。它改变了“索引存什么”的问题。
- 传统 RAG 存的是**“原始切片(Raw Chunks)”**。
- GraphRAG (微软) 存的是**“社区报告(Community Reports)”**(需要复杂的聚类算法)。
- LightRAG (本文) 存的是**“实体/关系画像(Entity/Relation Profiles)”**。
具体做法:
- Profiling(画像生成):LightRAG 利用 LLM 对文档中的每一个“实体”和“关系”生成一个
Key-Value对。
-
- Key:用于检索的索引词(如实体名“Beekeeper”,或关系主题“Beekeeper - Honey Bee”)。
- Value:一段由 LLM 生成的文本摘要,概括了该实体/关系在数据中的具体含义和上下文。
- 去重 (Deduplication):它会自动合并不同文档中出现的同一个实体,将分散的信息“捏”在一起。
特色:这种索引方式既保留了图结构的关联性,又避免了 GraphRAG 那种昂贵的全局社区生成过程,极大地降低了 Token 消耗。
2. 创新点二:双层检索范式 (Dual-Level Retrieval Paradigm)
LightRAG 提出了一套独特的检索策略,旨在同时解决“细节问题”和“宏观问题”。
- 痛点:普通 RAG 擅长找细节(因为是字面匹配),但回答不了宏观大问题(因为缺乏全局观)。GraphRAG 擅长回答大问题,但找细节效率低且贵。
- LightRAG 的方案:将检索拆分为两层并行处理。
-
- 低层检索 (Low-Level Retrieval):
-
-
- 针对:具体的实体细节(Specific Queries)。
- 实现:从用户问题提取具体实体关键词,直接在图谱中定位节点(Nodes)。
-
-
- 高层检索 (High-Level Retrieval):
-
-
- 针对:抽象的主题、概念或总体趋势(Abstract Queries)。
- 实现:从用户问题提取高层概念关键词,在图谱中定位关系边(Edges)对应的摘要。
-
特色:通过结合这两层信息,LightRAG 既能回答“谁写了这本书?”(低层),也能回答“这本书的主题思想如何影响了后世文学?”(高层)。
3. 创新点三:低成本的增量更新机制 (Fast Adaptation to Incremental Data)
这是 LightRAG 在工程落地方面最大的突破,解决了图谱 RAG 难以维护的痛点。
- GraphRAG 的缺陷:一旦有新文档进来,因为依赖全局的“社区发现”算法,通常需要重建索引或者进行极复杂的局部重算,成本极高。
- LightRAG 的创新:
-
- 它将新数据视为一个新的子图。
- 利用简单的集合并集操作 (Set Union):
和
。
- 新旧数据的融合不需要推倒重来,系统可以实时“吃进”新数据并立刻用于检索。
特色:这使得 LightRAG 非常适合新闻流、日志分析等数据频繁变动的真实场景,而不仅仅是一次性构建的静态知识库。
4. 关键技术点:图结构与向量检索的轻量化融合
LightRAG 在检索算法上做了一个非常务实的“减法”。
- 不做深度图遍历:许多图 RAG 试图在图上跳跃很多步(Multi-hop)来寻找答案,这导致延迟很高且容易引入噪音。
- 高效做法:
-
- 关键词向量化:直接用 Embedding 匹配图中的 Key。
- 一跳邻居 (1-hop Neighbor):检索到节点后,LightRAG 只获取其直接相连的邻居节点信息。
- 假设:论文认为,通过 LLM 生成的高质量 Profiling(画像),每个节点本身已经包含了足够的上下文信息,因此不需要在图上进行漫长的多跳搜索。
特色:这种设计将复杂的图算法复杂度降维成了“向量搜索 + 局部扩展”,实现了**O(1)**级别的检索效率,大幅提升了响应速度。
5. 实验效果的突破 (根据论文数据)
论文通过实验验证了其创新点的有效性,主要体现在:
- 全面性 (Comprehensiveness):在回答复杂问题时,LightRAG 比 Naive RAG 覆盖的知识点更多。
- 多样性 (Diversity):在“Mixed”和“Legal”等复杂数据集上,LightRAG 生成的答案角度更丰富,显著优于 GraphRAG。
- 极低的开销:
-
- 索引构建阶段,避免了 GraphRAG 生成社区报告的数百万 Token 消耗。
- 检索阶段,API 调用次数从 GraphRAG 的数百次降低到了个位数(通常仅 1 次)。
总结
LightRAG 的核心特色可以用一句话概括:
它摒弃了 GraphRAG 中沉重的“社区发现”过程,转而使用更精细、更独立的**“实体/关系画像”作为基本单元,结合双层检索和增量更新**,实现了一个**“既有图谱的上下文理解能力,又有普通 RAG 的速度和低成本”**的新型架构。
(三)不足和未来展望:
基于论文《LightRAG: Simple and Fast Retrieval-Augmented Generation》的内容,我们需要从其方法论设计(Methodology)、**实验设置(Experiments)以及复杂性分析(Complexity Analysis)**中挖掘其潜在的不足和改进空间。
虽然论文本身是一篇强调“优势”的文章(没有专门的“局限性”章节),但通过仔细研读其技术实现细节(特别是第3节和第4节),可以客观分析出以下不足(Limitations)和未来改进方向(Future Directions):
一、 存在的不足与局限性 (Limitations)
1. 极度依赖 LLM 的“画像”质量 (Dependency on Quality of LLM Profiling)
- 论文依据:第 3.1 节提到,LightRAG 的核心依赖于函数
,即利用 LLM 为每个实体和关系生成一段文本摘要(Profiling)。
- 不足分析:
-
- “垃圾进,垃圾出”风险:如果 LLM 在生成摘要时产生幻觉(Hallucination),或者生成的摘要不够准确、遗漏了关键信息,那么后续的检索(依赖 Key-Value 匹配)将直接失效。
- 无法自纠错:目前的架构中,一旦画像生成并存入数据库,系统缺乏自动检测画像质量或后续修正的机制。如果 LLM 对“A”的描述是错的,所有关于“A”的回答都会受误导。
2. “一跳”限制牺牲了深层推理能力 (Depth Limitation of 1-Hop Neighbor)
- 论文依据:第 3.2 节明确指出,检索时系统会获取“一跳邻居节点(one-hop neighboring nodes)”来扩展上下文。
- 不足分析:
-
- 虽然这种做法提升了速度(Fast),但它牺牲了**多跳推理(Multi-hop Reasoning)**的能力。
- 如果问题的答案隐藏在 A -> B -> C -> D 的长链条中,且 A 和 D 没有直接边连接,也没有被 LLM 在预处理时归纳到同一个“关系摘要”中,LightRAG 很可能会断链,无法像真正的图遍历算法那样进行深度搜索。
3. 增量更新缺乏“全局重优化” (Lack of Global Re-optimization)
- 论文依据:第 3.1 节描述增量更新时,采用的是简单的集合并集操作(Union of sets),即
。
- 不足分析:
-
- 碎片化积累:随着时间推移,不断简单的“加法”操作可能导致图谱变得臃肿和嘈杂。
- 缺乏全局视角更新:GraphRAG 的优势在于它每次(或定期)会重新审视全局社区结构。LightRAG 的增量更新是局部的,如果新加入的数据完全改变了旧数据的宏观结论(例如:新证据推翻了旧理论),LightRAG 简单的合并机制可能无法有效处理这种“全局性的语义冲突”。
4. 索引构建成本依然存在 (Indexing Cost is Non-Trivial)
- 论文依据:第 3.4 节复杂性分析指出,LLM 需要被调用
次。
- 不足分析:
-
- 虽然比 GraphRAG 便宜很多,但相比 Naive RAG(仅需 Embedding 模型,无需 LLM 参与索引),LightRAG 的索引构建依然是昂贵且慢的。对于海量数据(如十亿级 Token),对每个切片都调用 GPT-4o-mini 进行实体提取和摘要生成,依然是一笔巨大的 API 开销和时间成本。
二、 未来展望与改进方向 (Future Directions)
基于上述不足,结合论文的技术路线,可以提出以下切实的改进方向:
1. 引入“图剪枝”与“图清洗”机制 (Graph Pruning & Refinement)
- 现状:目前是“只增不减”。
- 改进:未来可以开发一种机制,定期扫描知识图谱,利用 LLM 合并过于相似的节点(例如自动发现“AI”和“Artificial Intelligence”是同一个点并合并),或者剔除低频/无用的噪音节点。这将有助于长期维护图谱的健康度。
2. 动态检索深度 (Adaptive Retrieval Depth)
- 现状:固定为“一跳(1-hop)”邻居。
- 改进:可以设计一个智能代理(Agent),根据问题的复杂度动态决定是否需要“跳”得更远。
-
- 简单问题:0跳(只看节点本身)。
- 复杂推理问题:自动扩展到 2跳 或 3跳,在速度和深度之间取得动态平衡,而不是硬编码为 1跳。
3. 小模型/专用模型的微调 (Fine-tuning Specialized Models)
- 现状:依赖通用的 LLM(如 GPT-4o-mini)进行实体提取和画像。
- 改进:
-
- 为了降低索引成本,可以训练或微调一个更小的、专门用于“实体提取+摘要”的小模型(如 7B 甚至更小)。
- 这样可以在本地极速构建索引,彻底解决索引成本比 Naive RAG 高的问题。
4. 处理多模态数据 (Multimodal Capabilities)
- 现状:目前仅专注于纯文本(Text)。
- 改进:知识图谱天然适合连接不同模态的数据。未来可以扩展 LightRAG,使其节点不仅代表文本实体,还可以代表图片、表格或音频片段。例如,"Entity: Tesla Model 3" 的 Value 可以包含文本描述,也可以包含一张车辆图片的 Embedding,从而实现多模态检索增强。
5. 解决“冲突知识”的机制 (Conflict Resolution)
- 现状:增量更新时简单的合并。
- 改进:当新旧文档存在事实冲突时(例如旧文档说“A是CEO”,新文档说“A已离职”),LightRAG 需要引入一种**时间戳(Timestamp)或置信度(Confidence)**机制,在生成答案时明确指出信息的时间效力,而不是简单地把矛盾的信息拼在一起给 LLM。
总结
LightRAG 的核心权衡(Trade-off)是用“预处理的画像(Profiling)”来换取“检索时的速度”。
- 它的短板在于对预处理质量的极度依赖以及牺牲了深层图遍历能力。
- 它的未来在于如何以更低的成本(专用模型)构建更干净的图(图清洗),以及更智能地利用这张图(自适应检索深度)。
六、《Graph Chain-of-Thought: Augmenting Large Language Models by Reasoning on Graphs》
(一)主要内容:
这份总结完全基于论文《Graph Chain-of-Thought: Augmenting Large Language Models by Reasoning on Graphs》的内容,旨在精准、细致地还原作者的研究动机、方法论、数据集构建及实验结论。
论文总结:Graph Chain-of-Thought (GRAPH-COT)
1. 研究背景与动机 (Motivation)
- 核心问题:大型语言模型(LLMs)在知识密集型任务中经常产生幻觉(Hallucinations)。虽然检索增强生成(RAG)可以通过检索外部文本文档来缓解这一问题,但在许多现实场景中,知识并非孤立存在,而是以**图(Graph)**的形式互联(例如:学术引用网、法律案例网)。
- 现有方法的局限性:
-
- 文本 RAG 的不足:传统的 RAG 检索独立的文本片段,忽略了文本之间的结构性关联(Structure Context),而这些关联往往包含回答问题所需的关键知识。
- 直接图增强(Graph RAG)的困境:如果尝试检索子图并将其转化为线性文本(Linearization)输入 LLM,会面临**图规模爆炸(Graph Size Explosion)**的问题。随着跳数(hop)增加,子图包含的节点呈指数级增长,导致上下文过长,超出 LLM 处理能力,引发“迷失在中间(Lost in the middle)”现象。
- 本文方案:提出 GRAPH-COT,不将图直接转化为文本喂给模型,而是让 LLM 像智能体(Agent)一样,在图上进行迭代式的推理和遍历,按需获取信息。
2. 核心贡献一:GRBENCH 基准数据集
为了填补图推理评估的空白,作者构建了 GRBENCH (Graph Reasoning Benchmark)。
- 数据规模:包含来自 5 个领域 的 10 个真实图谱,共 1,740 个问答对。
- 领域覆盖:
-
- 学术 (Academic):论文引用、作者合作(数据源:DBLP, MAG)。
- 电子商务 (E-commerce):商品关联、共同购买(数据源:Amazon)。
- 文学 (Literature):书籍、作者、系列(数据源:Goodreads)。
- 医疗 (Healthcare):疾病、基因、药物相互作用(数据源:Hetionet)。
- 法律 (Legal):案例引用、法庭裁决(数据源:CourtListener)。
- 构建流程:采用“半自动化”流程,保证质量与多样性。
-
- 收集真实参考图数据。
- 人工设计问题模板(涵盖不同难度)。
- 利用 GPT-4 对模板进行改写,增加语言多样性。
- 编写程序代码在图上运行,自动生成无误的标准答案(Ground Truth)。
- 难度分级:
-
- 简单:单跳推理(如查询作者)。
- 中等:多跳推理或度数统计(如查询某年合作最多的作者)。
- 困难:归纳推理(图提供上下文,LLM 需结合自身知识推理,如商品推荐)。
3. 核心贡献二:GRAPH-COT 框架
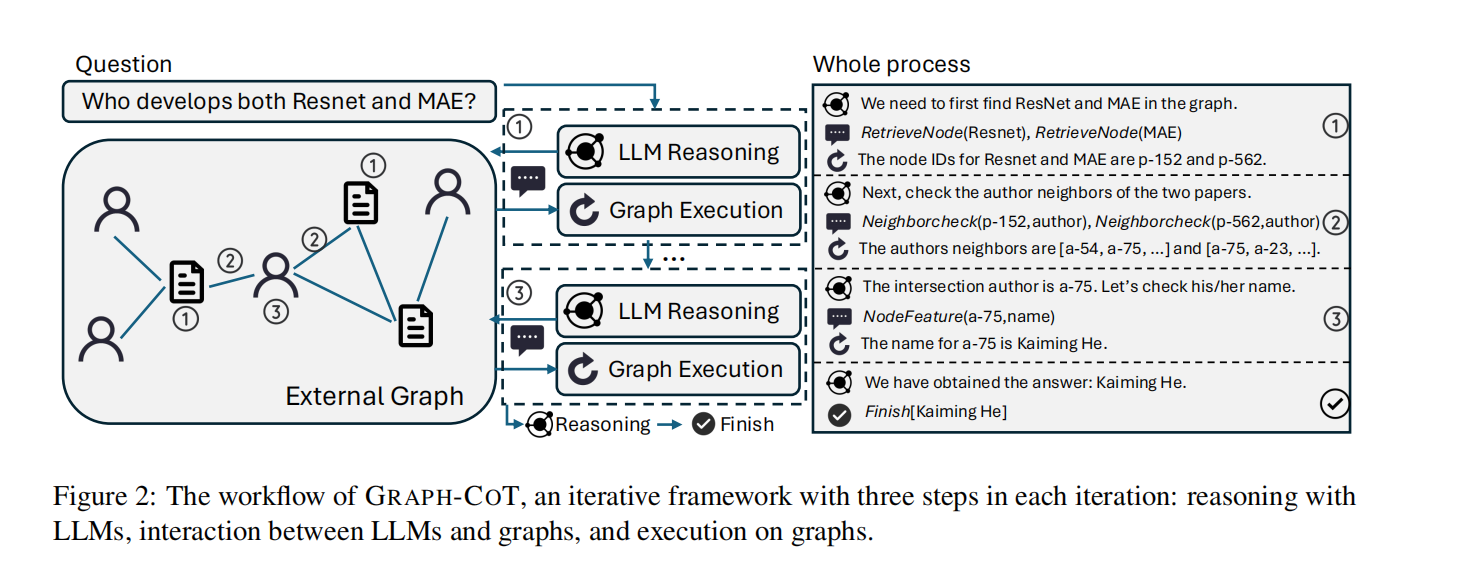
这是论文提出的核心方法论,是一个**迭代式(Iterative)**的推理框架。它通过“思维链(Chain-of-Thought)”的方式,指导 LLM 自主地在图上通过 API 获取信息。
工作流程(三个子步骤的循环):
- 推理 (Reasoning):
-
- LLM 分析当前已有的信息,决定下一步需要从图中获取什么数据,或者判断是否已能回答问题。
- 作用:规划路径,分解复杂问题。
- 交互 (Interaction):
-
- LLM 生成具体的图函数调用(Graph Function Calls)。
- 作者预定义了 4 个核心交互函数 供 LLM 使用:
-
-
RetrieveNode(Text):语义检索。根据文本查询最相关的节点 ID。NeighborCheck(NodeID, NeighborType):查邻居。获取特定关系下的相邻节点。NodeFeature(NodeID, FeatureName):查属性。获取节点的具体文本属性(如摘要、价格)。NodeDegree(NodeID, NeighborType):查度数。统计邻居数量。
-
- 执行 (Execution):
-
- 外部程序在图数据库上执行 LLM 生成的函数调用,并将结果(文本形式)返回给 LLM,作为下一轮推理的上下文。
实现关键:使用 In-Context Learning (上下文学习)。Prompt 包含:图定义的自然语言描述、交互函数的说明书、以及几个少样本(Few-shot)的对话演示。
4. 实验结果与分析
作者在 GRBENCH 上对比了 Base LLMs、Text RAG 和 Graph RAG。
- 主要结论:
-
- GRAPH-COT 全面领先:在所有领域和模型(LLaMA-2, Mixtral, GPT-3.5)上,GRAPH-COT 的表现均显著优于基线方法。
- Graph RAG 的局限:实验显示,虽然检索 1-hop 子图(Graph RAG)比纯文本 RAG 好,但检索 2-hop 子图时性能反而下降。这验证了“图规模爆炸”会导致上下文过长,干扰 LLM 的判断。而 GRAPH-COT 通过按需索取,避免了无关信息的干扰。
- 模型能力的影响:LLM 的骨干模型越强(如 GPT-4),GRAPH-COT 的效果越好,因为更强的模型能更好地遵循复杂的函数调用指令。
- 消融研究 (Ablation Study):
-
- 演示(Demonstrations)至关重要:如果不提供 Few-shot 示例(Zero-shot),GRAPH-COT 几乎无法工作。
- 跨领域鲁棒性:即使使用学术领域的示例去指导法律领域的任务(跨领域演示),模型依然能表现良好,说明模型学会的是“如何操作图”的通用逻辑,而非死记硬背。
5. 论文总结
这篇文章针对“如何用图数据增强 LLM”这一难题,指出传统的将图转化为文本序列(Graph RAG)的方法存在不可扩展性(上下文长度限制)。
作者提出了一种基于 Agent 思路的 GRAPH-COT 方法,将 LLM 转变为一个能够主动查询、遍历图数据库的智能体。通过构建高质量的 GRBENCH 数据集 并进行详尽实验,证明了这种“让模型在图上一步步推理”的方法,比简单地“把子图塞进 Prompt”更有效、更精准,且更能处理多跳和复杂的逻辑推理任务。
(二)主要的创新点:
根据这篇论文《Graph Chain-of-Thought: Augmenting Large Language Models by Reasoning on Graphs》,我为你总结了其核心的创新点、关键点和特色点。这些内容严格贴合论文的描述。
1. 核心方法创新:Graph Chain-of-Thought (GRAPH-COT) 框架
这是文章最根本的创新,它改变了 LLM 与图数据交互的范式。
- 从“静态检索”到“动态游走”:
-
- 传统做法 (Graph RAG):通常是一次性检索一个子图(例如节点的 1-hop 或 2-hop 邻居),把整个子图转化成一段长文本塞给 LLM。这会导致上下文过长(Context Explosion),且信息也是静态的。
- 本论文做法 (GRAPH-COT):模仿人类查阅资料的过程,采用**“推理-交互-执行”的迭代循环**。LLM 根据当前知道的信息,自主决定下一步查什么,一步一步在图中“游走”获取答案。
- 优势:极大地减少了无关信息的输入,避免了 LLM 因为上下文过长而“迷失(Lost in the middle)”,能够处理更深层(Multi-hop)的推理任务。
- 三个子步骤的迭代设计:
-
- Reasoning (推理):LLM 思考下一步该找什么(例如:“我找到了作者,现在需要查他写了哪些论文”)。
- Interaction (交互):LLM 生成具体的函数代码(例如:
NeighborCheck(...))。 - Execution (执行):外部程序运行代码,返回精准的文本结果。
2. 数据集创新:GRBENCH (Graph Reasoning Benchmark)
作者指出目前缺乏专门评估 LLM 图推理能力 的高质量基准,因此构建了 GRBENCH。
- 真实且多样化的领域:
不同于以往仅关注单一领域,GRBENCH 涵盖了 5 个领域(学术、电商、文学、医疗、法律)的 10 个真实图谱。这些图谱的结构差异很大(例如医疗图有 11 种节点类型和 24 种边类型,而电商图主要是购买关系),能够全面测试模型的泛化能力。 - 半自动化的“真值”生成流程:
这是为了保证数据质量的特色点。
-
- 人工设计:专家设计问题模板(保证逻辑深度)。
- GPT-4 改写:增加语言表达的多样性(保证自然语言的丰富性)。
- 程序生成答案:最关键的一点是,标准答案(Ground Truth)是通过代码在图数据库中运行得到的,而不是由人或 LLM 编写的。这确保了答案在客观上的绝对正确性,避免了基准本身包含幻觉。
- 难度分级设计:
专门设置了 简单(单跳)、中等(多跳/统计)、困难(归纳推理) 三个等级,能够精细化地评估 LLM 在不同复杂度任务下的表现。
3. 交互机制特色:将图操作抽象为 4 个通用函数
论文没有让 LLM 直接去写复杂的查询语言(如 SQL 或 Cypher),而是设计了一套通用的、语义化的交互接口。这是一个非常实用的工程创新。
- 预定义的 4 个原语 (Primitives):
-
RetrieveNode(语义搜索入口)NeighborCheck(图遍历核心)NodeFeature(获取细节)NodeDegree(统计数量)
- 特色:这 4 个函数覆盖了图推理的绝大多数需求(查点、查边、查属性、计数)。这种抽象使得 LLM 只需要学习这 4 个工具的用法,就可以在任何领域的图上进行推理,大大降低了学习成本,提高了跨领域的迁移能力(Cross-domain robustness)。
4. 解决“结构感知”与“上下文爆炸”的矛盾
这是论文在理论和动机上的关键洞察。
- 痛点:以往的方法陷入了一个两难境地——
-
- 如果只检索文本(Text RAG),就丢失了结构信息(Structure Context,如引用关系)。
- 如果检索子图结构(Graph RAG),随着跳数增加,节点数量呈指数级增长,导致图规模爆炸(Graph Size Explosion)。
- 突破:GRAPH-COT 通过**按需访问(On-demand access)**解决了这个矛盾。它利用了图的结构信息(通过遍历),但每次只取当前推理步骤需要的那一点点信息,从而保持了极短的上下文窗口,同时做到了深度推理。
5. 实验发现与实证价值
- 证明了 2-hop 检索的危害:实验中一个反直觉但重要的发现是,在 Graph RAG 中,检索 2-hop 子图的效果反而不如 1-hop。这强有力地佐证了作者的观点:盲目增加上下文长度会引入噪音,损害 LLM 性能。
- 模型能力的依赖性:论文诚实地展示了 GRAPH-COT 对 LLM 基础能力的依赖。它在 GPT-4 上表现极佳,但在较弱的模型(如 LLaMA-2)上效果不明显。这表明该方法更适合高性能的智能体场景。
总结来说:
这篇文章的最大特色是把 LLM 从一个“被动的阅读者”(阅读检索到的长文本)变成了一个**“主动的探索者”**(手持工具在图数据库中游走)。它通过 GRAPH-COT 框架 解决了上下文限制问题,并通过 GRBENCH 数据集 为该领域提供了一个严格的评估标准。
(三)不足和未来展望:
七、《From Local to Global- A Graph RAG Approach to Query-Focused Summarization》
(一)主要内容:
这份总结完全基于微软研究院的论文 《From Local to Global: A GraphRAG Approach to Query-Focused Summarization》。我将从核心创新点/特色和全篇详细总结两个维度进行严谨、细致的梳理。
第一部分:核心创新点与特色 (Key Innovations & Features)
这篇论文最大的贡献在于解决了一个传统 RAG 系统无法解决的痛点——“全局性意义构建(Global Sensemaking)”。以下是其具体创新点:
1. 填补了“检索”与“摘要”之间的鸿沟
- 痛点:传统的 Vector RAG(基线) 擅长“大海捞针”(提取局部事实),但在面对如“这个数据集的主题是什么?”这类需要通读全篇才能回答的**查询聚焦摘要(QFS)**任务时表现糟糕。
- 创新:GraphRAG 不再试图去检索零散的文本片段,而是通过构建知识图谱,将**检索(Retrieval)问题转化为了生成式摘要(Generative Summarization)**问题,从而具备了回答全语料库级别(Global)问题的能力。
2. 独创的“分层社区摘要”索引结构 (Hierarchical Community Summaries)
- 这是最核心的技术特色。GraphRAG 不仅仅是建立一个包含节点和边的图,它利用 Leiden 算法 发现图中的**社区(Communities)**结构。
- 预计算摘要:它利用 LLM 为每一个社区(从微观到宏观的各个层级)预先生成社区报告(Community Summaries)。
- 意义:这种索引方式是对数据的“语义压缩”。当用户提问时,系统实际上是在查询这些高度概括的“社区报告”,而不是原始文本。这使得系统既能掌握宏观概貌,又保留了微观细节的索引入口。
3. 结合“Map-Reduce”的问答机制
- 为了回答全局性问题,GraphRAG 采用了一种 Map-Reduce 的策略。
- Map:并行地利用多个社区摘要生成针对用户问题的“中间答案(Intermediate Answers)”。
- Reduce:将这些中间答案汇总,生成最终的全局性回答。
- 这种方法避免了传统 RAG 因为上下文窗口限制而无法处理海量数据的缺陷。
4. 引入“主张(Claims)”作为协变量
- 论文明确提出提取 Claims(主张/事实陈述) 并将其挂载到图节点上。这使得知识图谱不再只是静态的实体连接,而是包含了带有时间、因果和具体细节的动态事实,极大地增强了回答的全面性(Comprehensiveness)。
第二部分:全篇详细总结 (Detailed Summary)
1. 研究背景与动机 (Introduction & Background)
- 问题:RAG(检索增强生成)已成为让 LLM 处理私有数据的标准范式。然而,标准的 RAG(基于向量相似度)在处理**全局性问题(Global Questions)**时失败了。
- 例子:用户问“主要的主题是什么?”Vector RAG 只能检索到几段含有“主题”这个词的文本,而无法概括整个百万字的数据集。
- 目标:开发一种既能扩展到海量数据,又能像人类分析师一样进行“意义构建(Sensemaking)”的系统。
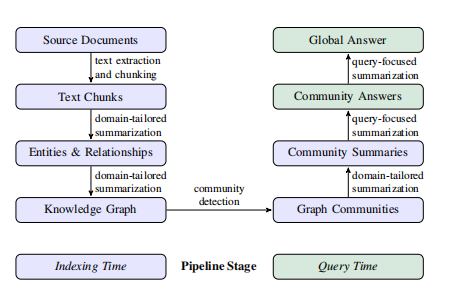
2. 方法论:GraphRAG 工作流 (The GraphRAG Pipeline)
该方法分为两个主要阶段:索引构建和查询执行。
A. 索引构建 (Indexing) - 数据的结构化与摘要化
这是一个利用 LLM 对原始文本进行预处理的流水线:
- 源文本切片 (Source Documents → Text Chunks):将文档切分为短块(600 tokens),以便 LLM 处理。
- 元素提取 (Text Chunks → Element Instances):
-
- 使用 LLM 从文本块中提取实体(Entities)、关系(Relationships)和主张(Claims)。
- 特色:使用了多阶段迭代(Self-Reflection/Gleaning),如果 LLM 第一遍提取遗漏了实体,系统会提示它“再去捡漏”,显著提高了召回率。
- 图构建 (Element Instances → Knowledge Graph):
-
- 对提取出的实体和关系进行实体对齐(Entity Resolution)和聚合。
- 利用 LLM 为每个去重后的节点(实体)和边(关系)生成自然语言描述摘要。
- 社区发现 (Graph Community Detection):
-
- 使用 Leiden 算法 将图划分为层级化的社区结构。这不仅把紧密相关的实体聚在一起,还形成了一个从底层(具体)到高层(抽象)的树状结构。
- 生成社区摘要 (Community Summaries):
-
- 关键步骤:LLM 阅读每个社区内的实体、关系和主张,生成一份结构化的社区报告(包含标题、摘要、影响力评分、关键发现)。
- 这些报告构成了 GraphRAG 实际查询时的主要数据源。
B. 查询执行 (Query Execution) - 从摘要到答案
针对全局性问题(Global Search):
- 社区筛选:根据层级选择全部或部分的社区摘要。
- 并行生成(Map):将社区摘要打散,并行地询问 LLM:“基于这个社区的报告,能否回答用户的问题?”如果能,生成回答片段并打分。
- 汇总回答(Reduce):过滤掉无用的回答,将高分片段拼接,由 LLM 生成最终的综合性答案。
3. 实验设置 (Experiments)
- 数据集:
-
- Podcast Transcripts(播客实录,约 100 万 tokens):对话密集、非正式。
- News Articles(新闻文章,约 170 万 tokens):叙述性强、主题广泛。
- 对比方法:
-
- GraphRAG(本方法)。
- Vector RAG (SS):基于嵌入的传统 RAG。
- Source Text Summarization (TS):不建图,直接对源文本切片进行 Map-Reduce 摘要(一种“暴力”方法,通常效果好但成本极高)。
4. 评估指标与结果 (Metrics & Results)
由于此类问题没有标准答案,论文使用 LLM-as-a-judge(以 GPT-4 为裁判) 进行评估,定义了四个指标:
- 全面性 (Comprehensiveness):是否覆盖了问题的所有细节?
- 多样性 (Diversity):是否提供了丰富的视角?
- 赋能性 (Empowerment):是否有助于读者理解并做出判断?
- 直接性 (Directness):是否直截了当(控制变量)。
主要结论:
- GraphRAG 显著优于 Vector RAG:在全面性和多样性上,GraphRAG 的胜率达到了 70%-80%。Vector RAG 倾向于提供片面、局部的答案,而 GraphRAG 提供了结构化、全景式的回答。
- GraphRAG 媲美暴力摘要 (TS):GraphRAG 的表现与直接总结源文本(TS)相当,甚至在某些指标上更好,但它提供了一种结构化的索引(图),使得后续查询(尤其是如果需要下钻到细节时)更具可解释性和灵活性。
- 社区层级的影响:低层级社区(更细粒度)的摘要能提供更细节的回答,而根节点社区(Root Level)提供了极其高效的概览(Token 消耗极少)。
总结语
这篇文章证明了:通过 LLM 构建的模块化知识图谱,并结合预生成的社区摘要,是解决 RAG 系统“全局理解(Sensemaking)”能力的有效途径。 GraphRAG 成功地从局部的信息碎片中构建出了全局的知识结构。
(二)主要的创新点:
这份回答完全基于微软研究院的论文 《From Local to Global: A GraphRAG Approach to Query-Focused Summarization》。
这篇论文的核心贡献在于提出了一种基于图(Graph-based)的 RAG 新范式,专门用于解决传统 RAG 无法处理的全局性问题(Global Questions)。
以下是该文章的主要创新点、关键点和特色点的详细梳理:
一、 核心创新点 (Core Innovations)
1. 解决了“全局意义构建 (Global Sensemaking)”的痛点
- 传统痛点:传统的 Vector RAG(向量检索) 擅长回答“针尖对麦芒”的局部事实问题(如“谁是 CEO?”)。但当用户询问“这些文档主要讨论了哪些主题?”时,Vector RAG 失败了。因为它只能检索到零散的片段,无法理解数据集的整体结构。
- GraphRAG 创新:它不试图去“检索”答案,而是通过构建知识图谱和生成摘要,将 RAG 任务转化为**查询聚焦的摘要(Query-Focused Summarization, QFS)**任务。这使得 LLM 能够“通读”并概括整个百万级 token 的语料库。
2. 独创的“分层社区摘要”索引 (Hierarchical Community Summaries)
这是 GraphRAG 与普通知识图谱(KG)方法最大的不同,也是其核心技术壁垒。
- 普通 KG:只存储节点(实体)和边(关系)。查询时通常需要进行复杂的图遍历(多跳查询)。
- GraphRAG:利用 Leiden 算法 发现图中的社区(Communities),并构建层级结构(从微观社区到宏观社区)。
- 创新之处:系统预先利用 LLM 为每一个社区生成一份自然语言形式的**“社区报告(Community Report)”**。这些报告包含了该社区的主题、核心实体和关键发现。
- 意义:“社区摘要”即索引。查询时,系统直接利用这些高度浓缩的摘要来生成答案,而不是去遍历图中的节点。
3. “Map-Reduce” 式的查询处理机制
针对全局性问题,GraphRAG 引入了一种分布式的处理流程(Section 3.1.6):
- Map(映射):系统选择特定层级的所有社区摘要,并行地将它们和用户问题输入给 LLM,生成多个“中间答案(Intermediate Answers)”并打分。
- Reduce(归约):过滤掉低分答案,将高分的中间答案拼接,再次输入 LLM 生成最终的全局回答。
- 特色:这种机制规避了 LLM 上下文窗口的限制,使得系统可以处理海量数据。
二、 关键技术细节与特色 (Key Technical Features)
1. 索引构建中的“自我反思 (Self-Reflection / Gleaning)”
- 问题:在从文本块中提取实体时,LLM 往往会遗漏信息,导致图谱不完整。
- 特色做法:论文(Appendix A.2)采用了“拾遗(Gleaning)”策略。提取完一轮后,系统会问 LLM:“你是否漏掉了什么?”如果 LLM 回答是,就强制它再进行一轮提取。
- 结果:这使得系统可以使用较大的文本块(600 tokens)以降低成本,同时保持极高的信息召回率。
2. 引入“主张 (Claims)”作为协变量 (Covariates)
- 特色:GraphRAG 不仅提取实体和关系,还提取主张(Claims)——即关于实体的、带有时间/地点/因果的可验证事实陈述(如“某公司在2023年被指控欺诈”)。
- 作用:这些主张被挂载在图节点上。在生成社区摘要时,LLM 可以依据这些主张写出包含丰富细节和事实依据的报告,防止回答流于空泛。
3. 结果的可解释性与溯源
- 由于最终答案是基于“社区摘要”生成的,而“社区摘要”又引用了具体的源文本 ID。
- 特色:GraphRAG 的回答天然具备较好的可解释性,用户可以追踪到是哪个社区、哪些实体、哪些原始文档贡献了这个观点。
三、 论文总结 (Summary)
1. 研究目标
文章旨在解决大语言模型(LLM)在面对海量私有数据时,如何回答全局性问题(Global Questions)。例如,“数据集中反映了哪些主要趋势?”这类问题需要理解全貌,而现有的基于向量相似度的 RAG(Vector RAG)只能检索局部片段,效果不佳。
2. 核心方法 (GraphRAG)
作者提出了一种名为 GraphRAG 的方法,其工作流分为两步:
- 索引阶段 (Indexing):
-
- 将源文本文档切片。
- 利用 LLM 提取实体、关系和主张,构建加权知识图谱。
- 使用 Leiden 算法 将图谱划分为层级化的社区(Communities)。
- 自底向上地利用 LLM 为每个社区生成摘要报告(Community Summaries)。这些摘要构成了对数据的“全息缩影”。
- 查询阶段 (Querying):
-
- 对于用户的全局性提问,系统并行读取社区摘要(Map 过程),生成多个局部回答。
- 系统汇总并提炼这些局部回答(Reduce 过程),生成最终的全面答案。
3. 实验与评估
- 数据集:使用了播客实录(Podcast transcripts)和新闻文章(News articles),规模均在 100 万 token 左右。
- 评估指标:使用 LLM-as-a-judge 方法,评估答案的全面性(Comprehensiveness)、多样性(Diversity)、赋能性(Empowerment)和直接性(Directness)。
- 结论:
-
- GraphRAG 完胜 Vector RAG:在全面性和多样性指标上,GraphRAG 的胜率达到了 70-80%。Vector RAG 提供的答案往往不完整且视野狭窄。
- GraphRAG 优于暴力摘要:与直接对所有源文本进行 Map-Reduce 摘要(TS)相比,GraphRAG 性能相当或更好,但提供了结构化的索引,且在根节点层级(Root Level)查询时,Token 消耗大幅降低(虽然构建索引成本较高)。
一句话总结:
GraphRAG 通过将非结构化文本转化为分层的、带有摘要的知识图谱,成功地让 RAG 系统具备了类似人类分析师的**全局概览(Global Sensemaking)**能力,填补了传统检索式 RAG 在宏观理解上的空白。
(三)不足和未来展望:
八、《SubGCache: Accelerating Graph-based RAG with Subgraph-level KV Cache》
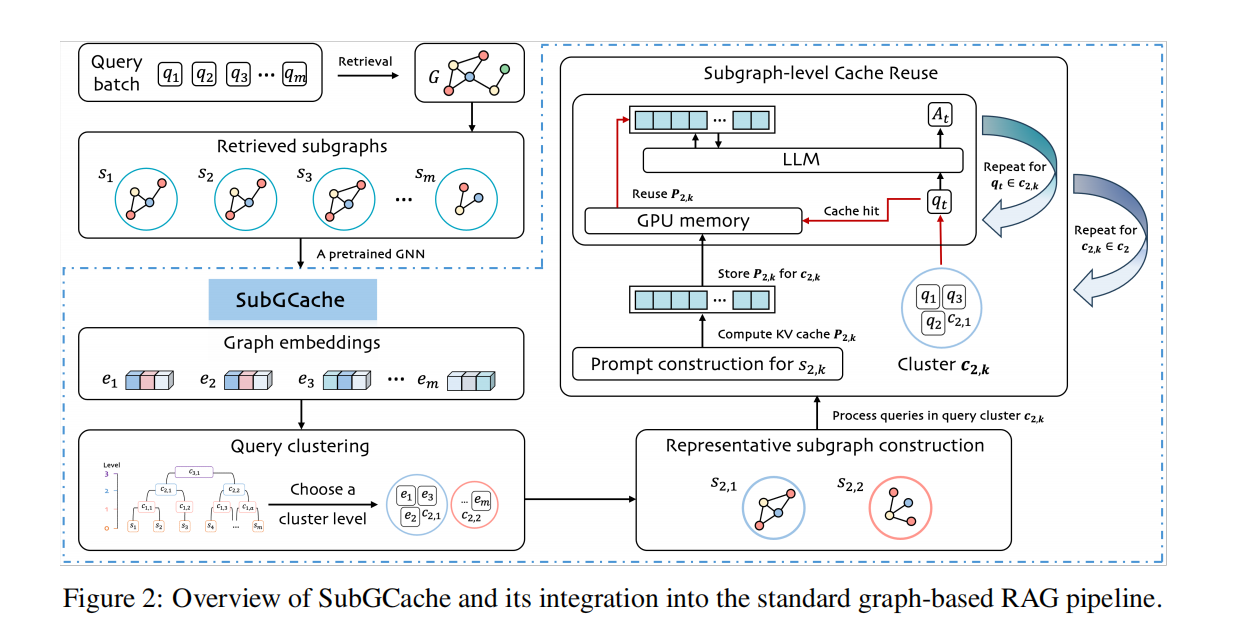
(一)主要内容:
这份总结完全基于论文 《SubGCache: Accelerating Graph-based RAG with Subgraph-level KV Cache》 的内容,力求准确、细致地还原作者的核心思想、方法论及实验结果。
论文总结:SubGCache — 通过子图级 KV 缓存加速基于图的 RAG
1. 核心贡献与研究背景
- 研究问题: 现有的 基于图的检索增强生成(Graph-based RAG) 主要采用“单查询”处理模式,即每个用户问题单独检索子图并由 LLM 推理。这导致了大量的计算浪费。
- 关键观察: 在批处理(In-batch)场景下,不同查询检索到的子图往往在结构和语义上高度相似,存在显著的“结构性冗余”。
- 核心贡献: 提出了 SubGCache,这是第一个专为 Graph-based RAG 设计的子图级 KV 缓存框架。它是一个**即插即用(Plug-and-play)**的模块,旨在通过复用相似子图的计算结果,显著降低推理延迟(特别是首字生成时间 TTFT),同时保持或提升生成质量。
2. 核心方法论 (Methodology)
SubGCache 的工作流程分为三个严密的步骤,旨在识别冗余、构建共享上下文并复用计算资源:
第一步:基于图嵌入的查询聚类 (Query Clustering)
- 目的: 识别批次中哪些查询检索到了相似的子图。
- 难点: 子图的相似性不仅仅是文本相似,还包含拓扑结构,且难以直接通过规则判断。
- 方法:
-
- 利用 Graph-based RAG 中预训练好的 GNN(图神经网络)编码器,将每个查询检索到的子图编码为图嵌入向量(Graph Embeddings)。这些向量蕴含了语义和结构信息。
- 对这些向量执行层次聚类(Hierarchical Clustering),将拥有相似子图结构的查询分到同一个簇(Cluster)中。
第二步:构建代表性子图 (Representative Subgraph Construction)
- 目的: 解决同簇内子图“相似但不完全相同”的问题,创建一个统一的缓存单元。
- 方法:
-
- 对于每一个簇,系统取其中所有查询检索到的子图的并集(Union)。
- 合并后的图被称为**“代表性子图”**。它保留了簇内所有相关的节点和边,形成了一个包含了该组查询所需全部信息的完整拓扑结构。
第三步:子图级 KV 缓存复用 (Subgraph-level Cache Reuse)
- 目的: 消除重复计算,实现加速。
- 方法:
-
- 预计算: 将“代表性子图”转化为 Prompt,输入 LLM,计算其在 Transformer 各层中的 Key-Value (KV) Tensors,并存储在 GPU 显存中。
- 复用: 簇内的每个查询在推理时,直接复用这份缓存的 KV Tensors,仅需将各自特定的问题(Question)Token 追加到缓存后进行计算,无需重新编码图结构。
- 释放: 处理完当前簇的所有查询后,立即释放显存,处理下一个簇。
3. 实验设置 (Experimental Setup)
为了验证该方法的有效性,作者专门构建了支持批处理查询评估的数据集和环境:
- 数据集(新建):
-
- Scene Graph(场景图): 稠密小图(22节点),关注视觉对象属性和空间关系,测试精细化推理。
- OAG(开放学术图谱): 稀疏大图(1071节点),关注学术实体间的链接预测,测试扩展性。
- 基线模型(Baselines): G-Retriever 和 GRAG(当前代表性的 Graph-based RAG 方法)。
- LLM 骨干: Llama-3.2-3B, Llama-2-7B, Mistral-7B, Falcon-7B。
- 评估指标: 准确率 (ACC)、响应时间 (RT)、首字生成时间 (TTFT)、预填充与首字时间 (PFTT)。
4. 关键实验结果 (Main Results)
- 显著的推理加速:
-
- 在 TTFT(首字时间) 上实现了高达 6.68倍 的减少。
- 在 PFTT(预填充时间) 上实现了高达 18倍 以上的减少(具体视模型和数据集而定)。
- 质量保持甚至提升:
-
- SubGCache 在加速的同时,生成质量与基线相当,甚至更好。
- 例如:在 Scene Graph 数据集上,准确率提升了 2.00%;在 OAG 上提升了 1.00%。
- 原因分析: 合并后的“代表性子图”提供了比单个子图更丰富的上下文信息,增强了模型的推理能力。
- 聚类数量的权衡 (Trade-off):
-
- 簇越少(粗聚类): 代表性子图越大,缓存复用率越高,加速越明显,且上下文越丰富(准确率通常较高)。
- 簇越多(细聚类): 个性化程度高,但复用机会少,且可能导致 Prompt 变长,甚至在极端情况下导致延迟增加(非单调变化)。
5. 结论 (Conclusion)
SubGCache 成功解决了 Graph-based RAG 在批处理场景下的效率瓶颈。通过创新性地利用图嵌入聚类和代表性子图构建,它实现了“一次计算,多次复用”。该方法不仅大幅降低了计算成本和延迟,还意外地通过聚合上下文提升了回答的准确性,为结构化知识的大模型推理加速提供了一个高效的新范式。
(二)主要的创新点:
基于对论文《SubGCache: Accelerating Graph-based RAG with Subgraph-level KV Cache》的深入阅读,我为您梳理了该文章的主要创新点(Innovations)、关键点(Key Points)和特色点(Distinctive Features)。
这些总结完全基于论文内容,重点聚焦于作者是如何解决“Graph-based RAG 推理慢”这一核心问题的。
1. 核心创新点:开创了“图 RAG 批处理加速”的新范式
这是该论文最宏观层面的创新,它重新定义了优化问题的场景。
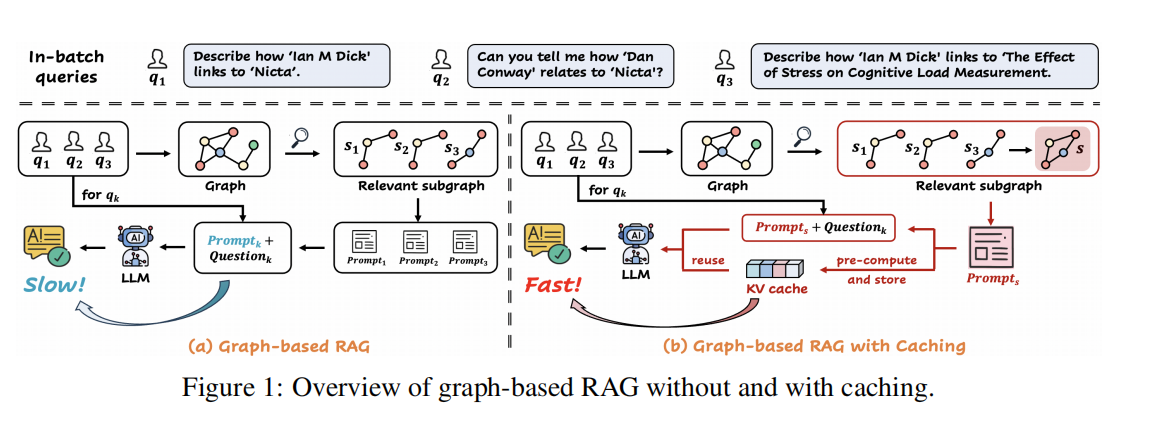
- 从单查询到批处理(Single-query to In-batch):
-
- 现状: 现有的 Graph-based RAG(如 G-Retriever, GRAG)都是针对单个查询独立处理的。
- 创新: 论文首次针对 In-batch Query(批处理查询) 场景下的 Graph-based RAG 提出了优化方案。作者敏锐地发现,在实际应用中(如医疗问答、科研检索),批量涌入的查询往往会检索到结构相似的子图。
- 结构化冗余的利用:
-
- 现状: 现有的 Prompt Cache 技术(如 Prompt Cache, SGLang)主要针对文本序列的精确重复(如相同的系统提示词)。
- 创新: SubGCache 提出了**“子图级(Subgraph-level)”的缓存概念。它不依赖文本的完全匹配,而是去识别和利用检索到的子图在拓扑结构和语义内容上的重叠**。
2. 关键技术点:三步走的独特实现路径
论文的技术实现非常精巧,主要体现在以下三个关键环节的设计上:
A. 解决了“谁和谁相似”的问题:基于 GNN 嵌入的聚类
- 痛点: 图是结构化数据,两个子图可能大部分重叠,但节点 ID 不同或顺序不同,传统的文本匹配无法识别这种相似性。
- 关键点: 作者直接利用 Graph-based RAG 模型中自带的 预训练 GNN 编码器。
-
- 将每个检索到的子图编码成 Embedding(向量)。
- 这个向量同时蕴含了语义信息(节点文本)和结构信息(拓扑连接)。
- 通过对这些向量进行层次聚类,系统能够自动把那些“长得像”的查询归为一类,而不需要人工制定复杂的规则。
B. 解决了“如何复用不完全相同的图”的问题:代表性子图(Representative Subgraph)
- 痛点: 即使两个查询很相似,它们检索到的子图往往也只是部分重叠(Partially Overlapping)。KV Cache 通常要求前缀完全一致才能复用,这就卡住了。
- 特色点: 作者提出了 Representative Subgraph(代表性子图) 的概念。
-
- 做法: 对同一个簇内的所有子图取并集(Union)。
- 效果: 构建出一个包含该簇所有节点和边的“超级子图”。
- 意义: 这个操作将“部分重叠”的问题转化为了“子集覆盖”的问题。这个“代表性子图”成为了一个统一的、标准的缓存单元。
C. 解决了“计算与显存效率”的问题:簇级 KV 缓存管理
- 关键点: 具体的执行流程采用了**Compute-Reuse-Release(计算-复用-释放)**策略。
-
- 预计算: 只对“代表性子图”进行一次 LLM 前向传播,计算出 Key-Value Tensors。
- 复用: 簇内的所有查询(Query)不再单独编码图,而是直接将自己的问题 Token 拼接到这个缓存后面。
- 释放: 处理完该簇后立即释放显存,避免显存爆炸。
- 这确保了系统既能加速,又不会因为缓存过多数据而导致 OOM(显存溢出)。
3. 特色点:反直觉的“质量提升”与极高的“加速比”
除了方法上的创新,论文在结果呈现上也有两个非常显著的特色,这在加速类论文中是不多见的。
- 特色一:以“空间”换“质量”(Context Enrichment)
-
- 通常,加速算法(如剪枝、量化)往往会带来精度的轻微下降。
- SubGCache 的反直觉现象: 使用缓存后,模型回答的准确率反而提升了(例如在 Scene Graph 上提升了 2%)。
- 原因: 因为采用了“取并集”的方式构建代表性子图,这个图实际上比原本单个查询检索到的图包含了更丰富的上下文信息。这种“上下文增强”意外地帮助模型更好地理解了全局关系。
- 特色二:极高的首字延迟优化(TTFT Reduction)
-
- 论文展示的数据非常亮眼:TTFT(首字生成时间)降低了最高 6.68 倍。
- 实际意义: 对于 RAG 系统,检索和阅读文档(或图)是最耗时的“预填充(Prefill)”阶段。SubGCache 几乎消除了这部分的重复计算,使得用户感觉到系统响应速度有了质的飞跃。
- 特色三:即插即用且模型无关(Plug-and-play & Model-agnostic)
-
- 该框架不需要重新训练 LLM,也不需要修改 LLM 的内部参数。
- 它作为一个外挂模块,可以无缝集成到现有的 Graph RAG 框架(如 G-Retriever, GRAG)和各种 LLM 基座(Llama, Mistral, Falcon)中。
总结
这篇论文最大的特色在于它没有把图仅仅看作文本,而是利用图的特性(可合并、可结构化编码)来做缓存。
它成功地将 In-batch Processing(批处理) 的工程优势引入到了复杂的 Graph RAG 领域,用一个优雅的“聚类+合并”策略,同时解决了推理速度和上下文完整性两个问题。
(三)不足和未来展望:
基于对论文 《SubGCache: Accelerating Graph-based RAG with Subgraph-level KV Cache》 的深入研读,特别是其 实验分析章节(Section 4.3, 4.4) 以及 附录 C(Limitations and Future Work),我为您总结了该文章的不足之处和未来的改进方向。
这些点完全基于论文的自述和实验数据分析,没有编造。
一、 存在的不足与局限性 (Limitations)
1. 对“批处理相似度”的高度依赖 (Dependency on Batch Similarity)
这是该方法生效的根本前提,也是其最大的局限。
- 论文依据: 核心假设是“In-batch queries”(批处理查询)会检索到相似的子图。
- 局限: 如果在实际应用中,用户提交的一批查询是完全随机、毫无关联的(例如一个问体育,一个问化学),那么聚类算法将无法找到有效的簇(或者每个簇只有1个查询)。此时,SubGCache 不仅无法带来加速,反而会因为运行了 GNN 编码和聚类算法而引入额外的计算开销(Overhead)。虽然论文中提到这种开销很小(<6%),但在无收益的情况下,这依然是负优化。
2. 代表性子图带来的“噪声”与“上下文膨胀” (Noise & Context Bloat)
- 论文依据: Section 3.3 中提到,代表性子图是通过取簇内所有子图的**并集(Union)**构建的。
- 局限:
-
- 引入噪声: 这种“求并集”的操作不可避免地会引入对某个特定查询来说是**无关(Irrelevant)**的节点和边。虽然实验显示准确率有所提升,但作者在 Section 3.4 (Discussion) 中明确承认:“merged context may introduce minor noise in rare cases”(合并的上下文在极少数情况下可能会引入轻微的噪声),这可能导致生成质量下降。
- Prompt 变长: Section 4.3 指出,如果聚类太粗(簇太少),代表性子图就会变得非常大。这会显著增加 Prompt Length(提示词长度),导致显存占用增加,并可能逼近 LLM 的上下文窗口限制。
3. 聚类粒度的权衡难题 (Trade-off in Clustering Granularity)
- 论文依据: Section 4.3 中的 Trade-off between latency and accuracy 部分。
- 局限: 并没有一个通用的“最佳聚类数”。
-
- 簇太少
复用率高,但图太大,处理大图的开销增加,且噪声变大。
- 簇太多
图精准,但复用率低,加速效果不明显。
- 作者发现这种权衡是非单调的(Not strictly monotonic),这意味着在实际部署中,想要动态地找到当前这批数据的“最佳聚类数量”是非常困难的,目前主要依赖预设的超参数。
- 簇太少
4. 处理大规模图的开销增加 (Higher Cost on Larger Graphs)
- 论文依据: Section 4.4 指出,在 OAG 数据集(较大图)上的聚类处理时间明显高于 Scene Graph(较小图)。
- 局限: 随着底层知识图谱规模的扩大,检索到的子图也会变大,导致 GNN 编码和“构建代表性子图”的时间成本增加。这意味着该方法在面对超大规模知识图谱或超大检索深度(k-hop 很大)时,前处理阶段的延迟可能会抵消掉一部分 KV Cache 复用带来的收益。
5. 任务类型的局限 (Task Specificity)
- 论文依据: Section C (Limitations and Future Work)。
- 局限: 当前的评估仅通过了特定的 QA(问答)任务(如 Scene Graph 的属性查询和 OAG 的链接预测)。论文承认,目前尚未在更抽象的问答设置(Abstract QA settings,如需要复杂逻辑推理或长文本摘要的任务)中进行验证。
二、 未来展望与改进方向 (Future Work)
作者在 Section C 中明确提出了未来的研究方向,同时基于其局限性,也可以推导出一些合理的改进路径:
1. 扩展应用场景 (Extension to Abstract QA)
- 原文规划: 作者计划将 SubGCache 扩展到 Abstract QA settings(参考了文献 [8, 13])。
- 解读: 目前的任务偏向于事实检索(Fact Retrieval)。未来希望验证在需要模型进行更深层理解、推理、甚至跨文档总结的任务中,这种“合并子图”的策略是否依然有效,是否会因为合并导致的逻辑混乱而影响推理链条。
2. 训练阶段的集成 (Exploration During Training)
- 原文规划: 作者提到目前 SubGCache 仅用于推理阶段(Inference-only)。未来可以探索将其应用于训练阶段(Training)。
- 解读: 如果在训练 Graph-based RAG 模型时,就采用这种“基于聚类子图”的数据输入方式,或许能让模型更好地适应“带有噪声的合并上下文”,从而进一步提升效率或对齐(Alignment)效果。
3. 动态聚类策略 (Dynamic Clustering Strategy)
- 基于局限的推导: 既然“最佳聚类数”很难确定且非单调,未来的改进方向必然包括自适应的聚类算法。
- 改进思路: 不需要人工指定分成几类,而是让系统根据当前批次查询的相似度分布、显存剩余情况以及 LLM 的上下文窗口大小,动态决定将哪些查询合并,哪些查询单独处理,以达到速度和精度的最优平衡。
4. 更智能的子图合并机制 (Smarter Subgraph Merging)
- 基于局限的推导: 目前是简单的“求并集(Union)”。
- 改进思路: 未来可以研究更复杂的图合并策略。例如,不是无脑合并所有节点,而是基于注意力机制或重要性评分,只合并关键路径上的节点,剔除明显的干扰噪声,从而生成一个更精简(Compact)但信息量依然足够的代表性子图。
总结
SubGCache 的核心理念是**“用显存换速度,用上下文冗余换计算减少”**。
它的未来发展在于:如何更聪明地合并(减少噪声)、如何更动态地聚类(适应不同数据流)、以及验证在更复杂任务上的有效性。
九、《HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models》
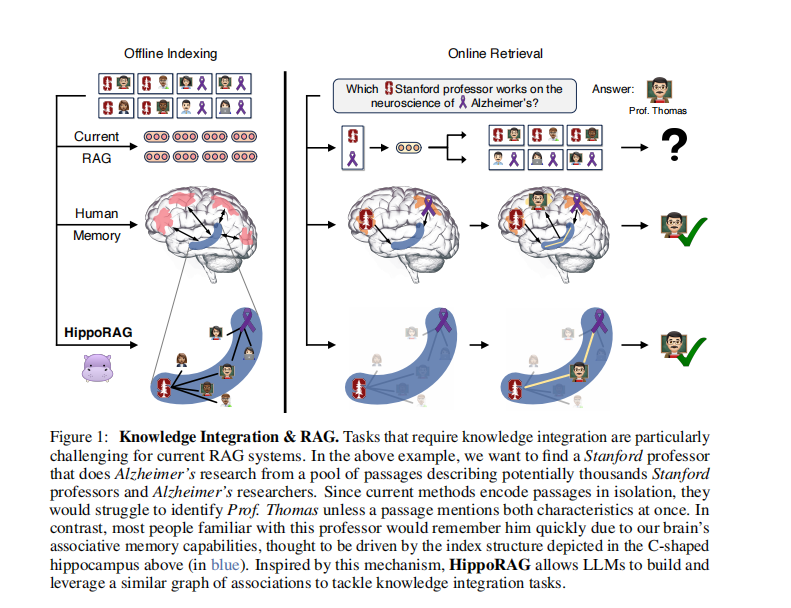
(一)主要内容:
这是一份关于论文 《HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models》(HippoRAG:神经生物学启发的长文本大语言模型长期记忆)的详细翻译、总结以及与现有RAG技术对比的深度分析报告。
第一部分:论文核心内容详细翻译与解读
由于篇幅限制,我将以章节核心内容精译的方式呈现,确保覆盖所有关键技术细节和论点。
1. 摘要 (Abstract)
为了在恶劣多变的自然环境中生存,哺乳动物的大脑进化出了存储大量世界知识并持续整合新信息的能力,同时避免“灾难性遗忘”。尽管大语言模型(LLMs)取得了巨大成就,但即使配合检索增强生成(RAG),它们在预训练后高效整合大量新经验方面仍然举步维艰。
本文介绍了 HippoRAG,一种受人类长期记忆**海马体索引理论(Hippocampal Indexing Theory)**启发的新型检索框架。HippoRAG 协同编排了 LLMs、知识图谱(Knowledge Graphs)和个性化 PageRank 算法,以模拟人类记忆中新皮层和海马体的不同角色。
结果:
- 在多跳问答(Multi-hop QA)任务上,HippoRAG 比现有的 SOTA(最先进)方法高出 20%。
- HippoRAG 的单步检索性能可与 IRCoT(迭代检索)等方法媲美,但成本低 10-20倍,速度快 6-13倍。
- 将 HippoRAG 集成到 IRCoT 中可带来进一步的显著提升。
- 该方法能解决现有方法无法处理的**路径发现(Path-finding)**类问题。
2. 引言 (Introduction)
- 背景: 哺乳动物大脑拥有卓越的持续更新长期记忆系统。目前的 AI 系统(即使是 RAG)通常是将新知识视为孤立的片段进行编码,缺乏跨段落(Passage boundaries)整合知识的能力。
- 问题: 许多现实任务(如科学文献综述、法律案件简报、医疗诊断)需要跨文档的知识整合。现有的 RAG 系统在处理需要“路径发现”的多跳问题时经常失败(例如:A与B有关,B与C有关,但A和C从未在同一段落出现,传统RAG很难直接建立A到C的联系)。
- 灵感: 引用 海马体记忆索引理论。人类记忆依赖于新皮层(处理和存储实际记忆表征)与海马体(存储指向新皮层记忆单元的索引并关联它们)之间的交互。
- 方案: HippoRAG 模拟这一机制:
-
- 新皮层(LLM): 将语料库转化为无模式的知识图谱(OpenIE)。
- 海马体索引(Knowledge Graph): 存储提取出的概念和关系。
- 检索机制(PPR): 使用个性化 PageRank 算法,根据查询中的概念在图上游走,激活相关的隐藏概念,实现单步多跳推理。
3. HippoRAG 方法论 (HippoRAG Methodology)
该部分详细对应了生物学机制与计算实现:
- 2.1 海马体记忆索引理论:
-
- 模式分离(Pattern Separation): 确保不同经历的表征是独特的(对应离线索引阶段)。
- 模式补全(Pattern Completion): 允许从部分刺激中检索完整记忆(对应在线检索阶段)。
- 2.2 & 2.3 具体实现流程:
-
- 离线索引 (Offline Indexing) - 模拟编码:
-
-
- 使用指令微调的 LLM(人造新皮层)通过**开放信息提取(OpenIE)**从段落中提取名词短语(节点)和关系(边)。
- 使用检索编码器(Retrieval Encoders,如 Contriever)检测同义词,如果两个节点的相似度高于阈值,则添加同义词边(Synonymy Edges)。这对应副海马区域的功能。
- 构建矩阵
,记录每个名词短语在哪些段落中出现。
-
-
- 在线检索 (Online Retrieval) - 模拟回忆:
-
-
- 查询处理: LLM 从用户 Query 中提取命名实体(Query Named Entities)。
- 节点激活: 使用检索编码器将查询实体映射到知识图谱(KG)中最相似的节点,作为“查询节点”(Query Nodes)。
- 图搜索(模拟模式补全): 在 KG 上运行 个性化 PageRank (PPR) 算法。仅给查询节点分配初始概率,通过图结构扩散概率。这使得与查询没有直接字面重叠、但逻辑上紧密相关的节点(中间节点)获得高权重。
- 段落排名: 利用 PPR 输出的节点概率向量,结合矩阵
(节点-段落映射),计算每个段落的得分并排序。
-
-
- 节点特异性 (Node Specificity): 引入类似 IDF(逆文档频率)的机制,根据节点出现的段落数量调整权重,压低常见词(如"The")的权重,提升罕见实体的权重。
4. 实验设置 (Experimental Setup)
- 数据集: MuSiQue (多跳问答), 2WikiMultiHopQA, HotpotQA。
- 基线模型:
-
- 传统检索:BM25, Contriever, GTR, ColBERTv2。
- LLM增强检索:Propositionizer, RAPTOR。
- 多步检索:IRCoT。
- 指标: Recall@2, Recall@5, QA Exact Match (EM), F1 score。
5. 结果 (Results)
- 单步检索 (Single-Step): HippoRAG 在 MuSiQue 和 2Wiki 上显著优于所有基线(包括 ColBERTv2 和 RAPTOR)。在 HotpotQA 上表现相当(HotpotQA 被认为充满虚假信号,且对多跳推理要求较低)。
- 多步检索 (Multi-Step): 将 HippoRAG 作为 IRCoT 的检索器,性能进一步提升,达到了目前的最佳水平(SOTA)。
- QA性能: 检索能力的提升直接转化为下游问答任务准确率的提升。
6. 讨论与分析 (Discussion)
- OpenIE 的重要性: 使用强大的 LLM(如 GPT-3.5 或 Llama-3-70B)进行三元组提取至关重要。使用较弱的模型(如 REBEL)会导致性能大幅下降。
- 单步多跳优势: HippoRAG 能够一次性检索出所有支持文档的比例远高于 ColBERTv2,证明了其关联推理能力。
- 路径发现 (Path-Finding) 案例: 展示了 HippoRAG 如何通过中间实体(如某位教授既在斯坦福又研究阿尔茨海默症)连接查询和答案,而传统方法无法通过关键词匹配做到这一点。
7. 结论 (Conclusions)
HippoRAG 是连接传统 RAG 和参数化记忆(Parametric Memory)的有力中间框架,具备持续更新、高效整合知识的能力。
第二部分:论文深度总结
HippoRAG 的核心逻辑在于解决传统 RAG 的“短视”问题。传统 RAG(无论是基于关键词的 BM25 还是基于向量的 Dense Retrieval)本质上是在寻找查询与文档之间的直接相似性。
然而,人类的记忆并非如此运作。当我们听到“斯坦福研究阿尔茨海默症的教授”时,我们的大脑会激活“斯坦福”和“阿尔茨海默症”这两个概念,然后顺着神经通路找到与这两者都连接的节点(例如“Thomas 教授”),即使“Thomas 教授”的介绍文档里可能只提到了他得过奖,而没同时提到斯坦福和阿尔茨海默症(假设信息分散在不同文档)。
HippoRAG 的工作流总结:
- 读书(Indexing): 把文档打碎,提取出主谓宾(实体-关系-实体),建成一张巨大的网(知识图谱)。同时,把意思相近的词连起来。
- 提问(Retrieval): 看到问题,先找出关键实体。
- 联想(Graph Traversal): 在网上从关键实体出发,通过 PageRank 算法“游走”。这种游走会把权重传递给那些作为桥梁的中间节点。
- 根据联想找书(Ranking): 谁(哪篇文章)包含的高权重节点多,谁就重要,即被检索出来。
第三部分:HippoRAG 与之前 RAG 变种的区别和联系
这是一个非常关键的部分。为了清晰展示,我将 HippoRAG 与几类主流的 RAG 范式进行对比。
1. 与标准 RAG (Standard RAG / Naive RAG) 的对比
- 代表模型: BM25, Contriever, ColBERT。
- 区别:
-
- 匹配机制: 标准 RAG 依赖向量相似度(语义重叠)或关键词匹配。如果 Query 和 Passage 没有直接的语义或词汇重叠,就很难检索到。
- HippoRAG: 依赖图结构的关联性。即便是语义不相似,只要在知识图谱上存在路径相连,就能被检索到。
- 联系: HippoRAG 在实体链接和同义词识别阶段,仍然使用了标准 RAG 的编码器(如 Contriever)来计算相似度。
2. 与迭代式/多步 RAG (Iterative / Multi-step RAG) 的对比
- 代表模型: IRCoT, ReAct, Self-Ask。
- 区别:
-
- 效率: 迭代式 RAG 需要
检索 -> LLM阅读 -> 生成新Query -> 再检索的循环。这导致延迟极高,且每次调用 LLM 都很贵。 - HippoRAG: 实现了**“单步多跳”(Single-step Multi-hop)**。它不需要多次调用 LLM 进行推理,而是通过一次图算法(PPR)在毫秒级完成推理过程,直接找到多跳之后的文档。成本低 10-30 倍,速度快 6-13 倍。
- 效率: 迭代式 RAG 需要
- 联系: 论文证明,HippoRAG 可以作为 IRCoT 的检索器组件(Plugin),两者结合效果最好。
3. 与其他基于图的 RAG (Graph RAGs) 的对比
- 代表模型: Microsoft GraphRAG, GNN-RAG。
- 区别:
-
- 图的构建: 许多 Graph RAG 使用社区检测(Community Detection)或摘要(Summary)节点来对图进行聚类(如 Microsoft GraphRAG)。
- 检索算法: 许多图方法是利用图来增强上下文,或者训练一个 GNN(图神经网络)。而 HippoRAG 独特地使用了 个性化 PageRank (PPR)。PPR 的优势在于它是一种无监督的、全局的图算法,能够根据查询动态地重新分配全图的权重,特别擅长发现“隐藏的桥梁概念”。
- 灵活性: HippoRAG 使用 OpenIE(开放信息抽取),不依赖预定义的 Schema(本体论),这使得它能适应任何领域的文本,不仅限于特定结构的数据。
4. 与摘要/层级化 RAG (Summary-based RAG) 的对比
- 代表模型: RAPTOR。
- 区别:
-
- 方法: RAPTOR 通过聚类并总结文档来构建树状结构。
- HippoRAG: 是基于细粒度的**实体(Entity)**级别及其关系。RAPTOR 适合宏观理解长文档,HippoRAG 适合在海量细节中寻找精准的关联线索。
- 更新能力: RAPTOR 在插入新文档时可能需要重新聚类和总结。HippoRAG 理论上只需向图中添加新节点和边(虽然 PPR 需要重新计算,但对于稀疏图由于算法特性相对较快,且无需重新训练模型)。
总结性评价
HippoRAG 的核心创新点在于它**“去向量化”的中间推理过程**。它虽然用向量来做实体对齐,但在核心的检索排序上,它回归了**符号主义(图结构)**的连接性。
- 之前 RAG 的痛点: “我知道 A,我想找 C,但中间必须经过 B,而 B 在另一本书里。” 向量检索很难直接跨越这个鸿沟。
- HippoRAG 的解法: 把所有书里的概念织成一张网。只要 A 和 B 连着,B 和 C 连着,按一下 A,C 就会亮起来。
这种方法在刑侦推理、科学发现、法律取证等需要“顺藤摸瓜”的场景下,比单纯的语义搜索(Standard RAG)和昂贵的迭代搜索(Iterative RAG)更具优势。
(二)主要的创新点:
基于对论文《HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models》的深入研读,这篇文章的主要创新点(Innovations)、**关键点(Key Points)和特色点(Highlights)**可以归纳为以下几个方面。
这些点严格贴合论文的设计理念、技术实现和实验结果:
1. 理论创新:神经生物学启发的 RAG 架构
这是该论文最独特的立意。作者没有单纯地从计算机工程角度堆砌模块,而是将**海马体索引理论(Hippocampal Indexing Theory)**直接映射到了 RAG 系统的架构设计中。
- 类比映射:
-
- 新皮层(Neocortex)
大语言模型(LLM):负责处理具体的感知输入(文档内容),进行“模式分离”,将非结构化文本转化为结构化表征。
- 海马体(Hippocampus)
知识图谱(Knowledge Graph):不存储原始记忆,而是存储指向新皮层记忆单元的索引,并负责建立关联。
- 海马旁区(Parahippocampal Regions)
检索编码器(Retrieval Encoders):负责连接新皮层和海马体,识别相似但不完全相同的信号(同义词检测)。
- 新皮层(Neocortex)
- 机制模拟:
-
- 模式分离(Pattern Separation):通过 OpenIE 将文档打散为独特的三元组,对应离线索引阶段。
- 模式补全(Pattern Completion):通过部分线索(Query 实体)在图谱上激活完整记忆回路,对应在线检索阶段。
2. 核心突破:单步多跳检索(Single-Step Multi-Hop Retrieval)
这是 HippoRAG 在效率与能力上的最大平衡点,也是其核心竞争力。
- 传统痛点:以往解决多跳问题(如“A的B的C是谁?”)主要靠迭代式 RAG(如 IRCoT),即“搜一次->读一次->再生成Query->再搜一次”。这非常慢且贵。
- HippoRAG 做法:利用图算法(PPR)的传递性。
-
- 即使 Query 中的实体 A 和答案所在的文档 C 之间没有直接语义相似性,只要它们在图谱上通过 B 相连,PPR 就能在一次计算中将概率从 A 传递到 C。
- 结果:实现了“多跳推理”的效果,但只需单次检索步骤。在线检索速度比 IRCoT 快 6-13 倍,成本低 10-30 倍。
3. 技术特色:无模式 OpenIE 与 混合图构建
在构建“外挂大脑”(知识图谱)时,HippoRAG 采用了一种灵活且鲁棒的策略,区别于传统的基于严格本体(Ontology)的知识图谱。
- Schemaless OpenIE(无模式开放信息抽取):不预先定义“人-地点”、“药物-疾病”等固定关系类型,而是让 LLM 自由提取文本中的名词短语和关系。这保留了原文的丰富细节(Fine-grained pattern separation)。
- 同义词增强(Synonymy Edges):为了解决“NYU”和“New York Univ.”被视为不同节点的问题,引入了**稠密检索编码器(Retriever Encoder)**计算节点相似度,并在相似节点间添加边。这模拟了生物学中的信号归一化,大幅增强了图的连通性。
4. 算法创新:结合节点特异性的个性化 PageRank
HippoRAG 并没有使用复杂的图神经网络(GNN),而是改良了经典的 Personalized PageRank (PPR) 算法用于检索。
- PPR 的应用:将 Query 中的实体作为 PPR 的“个性化向量(Personalization Vector)”的分布源,让概率只在相关子图上流动,而非全图漫游。
- 节点特异性(Node Specificity):作者引入了一个受生物学启发的加权机制(类似于 IDF,但用于图节点)。
-
- 做法:根据节点出现在多少个文档中来调整其初始权重。
- 目的:压低通用词(如 "time", "world")的影响力,放大稀有实体(如具体人名、地名)的信号,防止“语义漂移”。
5. 解决特定难题:路径发现(Path-Finding)
论文特别强调了一类传统 RAG 几乎无法解决的问题类型——路径发现多跳问题。
- 定义:Query 中的两个关键实体(例如“斯坦福”和“阿尔茨海默症”)从未在同一篇文档中共同出现过。
- 传统 RAG 的失败:基于向量相似度的检索(如 ColBERT/Contriever)会分别找到讲“斯坦福”的文档和讲“阿尔茨海默症”的文档,但很难找到同时涉及两者的那个“中间人”(如某位教授)。
- HippoRAG 的成功:通过图谱上的路径连接,强制找到同时接收到两个实体信号的中间节点,从而精准定位包含该中间节点的文档。
6. “不确定性集成”策略(Uncertainty Ensemble)
这是一个非常务实的工程特色,用于解决 HippoRAG 的短板。
- 问题:由于 HippoRAG 依赖实体提取,可能会丢失非实体的上下文信息(如时间、语气、否定词),即“Concept-Context Tradeoff”。
- 解决方案:当图谱检索的置信度较低(即 Query 实体在图谱中找不到高相似度的对应点)时,系统会自动回退或融合**标准稠密检索(Dense Retrieval,如 ColBERTv2)**的结果。
- 意义:这种混合策略保证了系统的鲁棒性,既能做复杂推理,又不会在简单匹配问题上掉链子。
总结
HippoRAG 的最大特色在于它去除了多跳推理中对 LLM 反复调用的依赖,转而使用图拓扑结构来承担推理任务。它证明了**“显式知识图谱 + 经典图算法”**是解决大模型长时记忆碎片化问题的一条高效、低成本且可解释的路径。
(三)不足和未来展望:
根据论文《HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models》的第 7 章节(Conclusions & Limitations)以及附录 F(Error Analysis)和附录 G(Cost and Efficiency Comparison),我为您详细梳理了该文章提到的不足之处以及未来的改进方向。
以下内容严格基于论文原文描述:
一、 现有的不足与局限性 (Limitations)
论文在附录 F 中通过对 100 个错误案例的分析,非常诚实地指出了 HippoRAG 的几个主要弱点:
1. 对上游组件(OpenIE 和 NER)的过度依赖
这是 HippoRAG 最大的软肋。如果“造脑”(索引)阶段提取不出东西,或者“用脑”(检索)阶段提取不出线索,整个系统就会失效。
- NER(命名实体识别)限制(占比约 48% 的错误):
-
- 问题: 很多时候,用户的查询不仅仅包含实体,还包含抽象概念或特定描述,但目前的 NER 模块只提取显式的命名实体。
- 例子(附录 F.2): 用户问“Windows 8 的某个浏览器版本何时可用?”,系统只提取了“Windows 8”,完全忽略了“浏览器”和“可用性”这两个关键约束,导致检索失败。
- OpenIE(开放信息抽取)缺失或错误(占比约 28% 的错误):
-
- 问题: LLM 在阅读文档时,可能会遗漏重要信息,或者提取出错误的三元组。
- 例子(附录 F.3): 面对长歌名 "Don't Let Me Wait Too Long",GPT-3.5 未能将其识别为一个实体,导致图谱中缺失了这个关键节点。
- 长文档退化(附录 F.4): 论文发现,随着文档长度增加,OpenIE 的提取质量会显著下降。
2. 概念与上下文的权衡(Concept-Context Tradeoff)
HippoRAG 是一种**以实体为中心(Entity-centric)**的方法,这导致它在捕捉非实体的上下文信息时表现不佳。
- 问题: 传统的稠密检索(如 ColBERTv2)擅长捕捉上下文(如否定词、时间状语、语气),而 HippoRAG 可能会忽略这些。
- 例子(附录 F.2): 在区分一位名叫 "Sergio Villanueva" 的拳击手和一位同名的历史人物时,HippoRAG 仅凭名字检索,混淆了两者;而 ColBERTv2 通过上下文里的“航海家”、“探险”等词成功区分了他们。
3. 离线索引成本高昂(Indexing Cost)
- 问题(附录 G): 虽然 HippoRAG 的在线检索非常便宜(比 IRCoT 便宜 10-30 倍),但其离线索引过程非常昂贵。
- 数据: 因为需要 LLM(如 GPT-3.5)阅读每一篇文档并生成三元组,其索引成本比传统检索方法高出约 10 倍。虽然可以用开源模型(Llama-3)降低资金成本,但时间成本(计算量)依然巨大。
4. PPR 算法的局限性(Graph Search Errors)
- 问题(占比约 24% 的错误): 有时 NER 和 OpenIE 都做对了,但 Personalized PageRank (PPR) 算法依然没找到正确答案。
- 原因: PPR 是一种基于图拓扑结构的无监督算法,它无法利用查询中的语义信息来指导游走方向。
- 例子: 面对“Huguenots(胡格诺派)”和“European(欧洲)”这两个词,PPR 可能会在图上找到许多无关的路径,因为它不知道我们要找的是“移民”关系,而不是“起源”关系。
二、 未来展望与改进方向 (Future Work)
论文作者在第 7 章及讨论部分明确提出了未来的改进路线:
1. 组件的针对性微调 (Component Fine-tuning)
目前 HippoRAG 的所有组件(LLM, Retriever, NER)都是**现成即用(Off-the-shelf)**的,没有经过专门训练。
- 改进方向:
-
- 微调 LLM 以便更准确、更一致地进行 OpenIE 提取。
- 微调 NER 模块,使其能识别更广泛的关键短语,而不仅仅是人名地名。
- 微调检索编码器,使其更适应知识图谱中的同义词对齐任务。
2. 改进图搜索算法 (Better Graph Traversal)
- 现状: 目前使用的是标准的 PPR,它只看节点连接,不看边的类型。
- 改进方向: 让关系(边)的信息直接指导图的遍历。例如,如果问题是关于“出生地”的,算法应该优先沿着
born_in或location类型的边游走,而不是随机扩散。
3. 解决上下文丢失问题
- 现状: 论文尝试了一种简单的**“不确定性集成(Uncertainty Ensemble)”**,即当图谱检索置信度低时,混合使用 ColBERTv2 的结果。
- 改进方向: 需要开发更复杂的机制,让系统知道何时该信赖图谱(实体强相关),何时该信赖向量检索(上下文强相关),或者如何在图谱中编码更多的上下文信息(例如将时间、否定词作为属性加入节点)。
4. 验证大规模扩展性 (Scalability Validation)
- 现状: 实验是在几万到十几万篇文档的规模上进行的。
- 改进方向: 需要实证研究当语料库增长到数百万甚至数十亿篇文档时,人造“海马体索引”(知识图谱)的体积是否会膨胀到无法处理,以及 PPR 算法在超大规模图上的效率是否还能保持优势。
5. 优化长文档处理
- 改进方向: 针对长文档提取质量下降的问题,需要研究更好的分块(Chunking)策略或**共指消解(Coreference Resolution)**技术,以确保在长文中也能高质量地提取三元组,且不破坏句子间的依赖关系。
总结
HippoRAG 目前是一个**“偏科的天才”:它在多跳推理和路径发现上极强,但在处理简单的上下文匹配和构建成本上存在短板。未来的工作重点在于降低索引成本**、引入上下文感知以及对组件进行端到端的微调。
十、《Graph Retrieval-Augmented Generation: A Survey》
这是一份基于论文《Graph Retrieval-Augmented Generation: A Survey》的深度总结。为了满足您“详细、致密、贴合论文描述”的要求,我将全文的核心分类体系、技术细节、对比分析以及未来展望进行了系统性的梳理和扩展。
Graph Retrieval-Augmented Generation (GraphRAG):技术综述深度总结
论文标题: Graph Retrieval-Augmented Generation: A Survey
核心贡献: 这是首篇系统性定义并梳理GraphRAG(图检索增强生成)领域的综述文章。文章形式化了GraphRAG的工作流,从索引(G-Indexing)、**检索(G-Retrieval)到生成(G-Generation)**三个阶段对现有文献进行了详尽的分类和剖析。
1. 研究背景与核心动机
1.1 传统RAG的困境
尽管大型语言模型(LLMs)能力卓越,但仍受限于幻觉、领域知识缺失和信息过时。检索增强生成(RAG)通过引入外部文本文档缓解了这些问题,但在处理复杂任务时面临三大瓶颈:
- 忽视关系(Neglecting Relationships): 现实世界的数据往往是相互关联的(如引文网络),传统RAG基于向量相似度的检索割裂了文本间的结构化联系。
- 信息冗余与“迷失中间”(Redundant Information & Lost in the Middle): 检索出的多个文本片段直接拼接会导致上下文过长,且LLM难以有效利用位于长文本中间的关键信息。
- 缺乏全局信息(Lacking Global Information): RAG只能检索局部片段,难以完成如“查询聚焦摘要(Query-Focused Summarization, QFS)”这类需要理解数据集全貌的任务。
1.2 GraphRAG的定义与优势
GraphRAG 定义为一个利用外部结构化知识图谱(KG)来增强LLM上下文理解与回答生成的框架。
- 核心机制: 从预构建的图数据库中检索相关的图元素(实体、三元组、路径、子图),利用其中的结构化关系知识来生成更精准的答案。
- 优势:
-
- 捕捉实体间复杂的关系知识(Relational Knowledge)。
- 通过图结构提供更精简的抽象信息,减少上下文长度。
- 通过检索子图或图社区(Graph Communities),支持更全面的全局理解。
2. GraphRAG 通用工作流 (The Workflow)
论文将GraphRAG这一新兴领域标准化为三个核心阶段:
- 基于图的索引 (G-Indexing):数据的准备与组织。
- 图引导检索 (G-Retrieval):核心信息的提取。
- 图增强生成 (G-Generation):信息的融合与产出。
3. 第一阶段:基于图的索引 (Graph-Based Indexing)
此阶段决定了检索的效率和粒度。
3.1 图数据来源 (Graph Data)
- 开放知识图谱 (Open Knowledge Graphs):
-
- 通用KG:如WikiData, Freebase, DBpedia(百科类),ConceptNet(常识类)。
- 领域KG:如CMeKG(生物医疗)、Wiki-Movies(电影)、GR-Bench(涵盖法律、电商等多领域)。
- 自建图数据 (Self-Constructed Graph Data):
-
- 针对私有数据或特定任务,通过LLM或NER工具从文档、表格中抽取实体和关系构建图。例如,构建文档间的引用图、共现图,或基于文档内容的层级图。
3.2 索引技术 (Indexing Methods)
- 图索引 (Graph Indexing): 保留完整的图拓扑结构(邻接矩阵),支持BFS/DFS等图遍历算法,适合获取结构信息。
- 文本索引 (Text Indexing): 将图数据转化为文本描述(如将三元组转化为自然语言句子),利用稀疏检索(BM25)或密集检索(Dense Retrieval)。
- 向量索引 (Vector Indexing): 将节点、边或子图编码为向量。利用LSH(局部敏感哈希)或向量数据库进行快速相似度匹配。
- 混合索引 (Hybrid Indexing): 结合上述多种方式。例如,同时检索向量库和图结构,或利用文本索引定位入口节点后再进行图遍历。
4. 第二阶段:图引导检索 (Graph-Guided Retrieval)
这是GraphRAG中最关键的环节,面临着候选子图爆炸式增长和相似度度量困难的挑战。
4.1 检索器类型 (Retriever)
- 非参数检索器 (Non-parametric): 不依赖模型训练,基于规则或图算法。例如:k-hop邻居搜索、最短路径算法、PCST(Prize-Collecting Steiner Tree)算法。优点是高效,缺点是缺乏语义理解。
- 基于LM的检索器 (LM-based): 利用LLM的强大理解力来选择节点或生成推理路径。例如,让LLM从候选关系中选择下一步跳跃的方向。
- 基于GNN的检索器 (GNN-based): 利用图神经网络对图数据编码,根据查询与图嵌入的相似度评分来检索节点或路径。
4.2 检索范式 (Retrieval Paradigm)
- 一次性检索 (Once Retrieval): 单次查询即提取所有相关子图或路径,适合简单查询,效率高。
- 迭代检索 (Iterative Retrieval):
-
- 非自适应:固定迭代次数(如固定跳2步)。
- 自适应:让模型(Agent)自主决定何时停止检索,适合复杂的多跳推理问题。
- 多阶段检索 (Multi-Stage Retrieval): 将检索过程线性分解,例如“先检索实体 -> 再剪枝 -> 再扩展”。
4.3 检索粒度 (Retrieval Granularity)
- 节点 (Nodes): 检索单个实体,适合实体链接或简单属性查询。
- 三元组 (Triplets): 检索 (头实体, 关系, 尾实体),提供最基础的关系单元。
- 路径 (Paths): 检索实体间的关系序列,对于解释“原因”或“推理链”至关重要。
- 子图 (Subgraphs): 检索包含丰富上下文的局部网络结构,能提供最全面的信息,支持复杂推理(如QFS任务)。
- 混合粒度 (Hybrid): 结合多种粒度,平衡精度与广度。
4.4 检索增强 (Retrieval Enhancement)
- 查询增强: 包括查询扩展(利用同义词或上位词扩展Query)和查询分解(将复杂问题拆解为多个子问题)。
- 知识增强:
-
- 合并 (Merging):将多个来源的碎片化知识聚合。
- 剪枝 (Pruning):利用重排序(Re-ranking)模型过滤掉检索到的无关噪声,防止误导生成器。
5. 第三阶段:图增强生成 (Graph-Enhanced Generation)
此阶段的目标是将非欧几里得结构的图数据转化为LLM可处理的格式,并生成答案。
5.1 生成器模型 (Generators)
- GNNs: 主要用于判别式任务(如选项分类),直接处理图结构。
- LMs (LLMs): 主流选择,利用其强大的文本生成和推理能力。
- 混合模型 (Hybrid):
-
- 级联式 (Cascaded):GNN先提取特征,作为Embeddings输入给LLM。
- 并行式 (Parallel):GNN和LLM分别处理,最后融合结果。
5.2 图格式转换 (Graph Formats) - 关键技术点
为了让LLM理解图,必须将图数据“翻译”:
- 邻接表/边列表 (Adjacency/Edge Table): 罗列节点连接关系,简洁直观。
- 自然语言描述 (Natural Language): 将三元组转化为句子(如 "Alice is a friend of Bob")。这是最常用的方式,利用LLM的语义理解力。
- 代码形式 (Code-like Forms): 使用GML、GraphML或类Python代码定义图结构,利用LLM的代码能力。
- 节点序列 (Node Sequence): 通过遍历算法生成的节点序列。
- 图嵌入 (Graph Embeddings): 将图结构压缩为软提示(Soft Prompts)向量,直接在Embedding层融合(仅适用于开源模型)。
5.3 生成增强 (Generation Enhancement)
- 生成前: 重写图数据,使其更流畅自然。
- 生成中: 约束解码(Constrained Decoding),限制生成内容必须存在于知识库中,减少幻觉。
- 生成后: 对生成的多个答案进行投票、验证或融合(如生成推理路径后再生成最终答案)。
6. 训练策略 (Training Strategies)
- 检索器训练:
-
- 免训练 (Training-Free):直接使用预训练Embedding模型或规则。
- 基于训练 (Training-Based):利用远程监督(Distant Supervision)构建伪标签,或通过对比学习优化检索对齐。
- 生成器训练:
-
- 免训练:依赖Prompt Engineering(提示工程),适用于GPT-4等闭源模型。
- 基于训练:SFT(监督微调),让模型适应图数据的输入格式。
- 联合训练 (Joint Training): 端到端同时优化检索器和生成器,使两者协同工作。
7. 应用与工业界现状 (Applications & Industry)
7.1 下游任务
- 问答 (QA): 包括KBQA(知识库问答)和CSQA(常识问答),是最主要的应用场景。
- 信息抽取 (IE): 实体链接、关系抽取。
- 其他: 事实验证(Fact Verification)、推荐系统、对话系统、链接预测。
7.2 工业界 GraphRAG 系统
论文特别列举了当前具有代表性的工业级系统:
- Microsoft GraphRAG: 专注于查询聚焦摘要(QFS),通过生成图社区摘要来回答涉及全集的复杂问题(如“这百万份文档的主题是什么?”)。
- NebulaGraph (GraphRAG): 将LLM集成到图数据库中,通过Text2Cypher实现自然语言查询图数据。
- AntGroup (蚂蚁集团): 基于DB-GPT、OpenSPG等框架,结合知识图谱引擎与LLM解决金融等领域的复杂问题。
- Neo4j (NaLLM): 探索利用LLM构建知识图谱以及自然语言接口。
8. 未来展望与挑战 (Future Prospects)
论文最后指出了六大研究方向:
- 动态与自适应图 (Dynamic and Adaptive Graphs): 现有方法多基于静态图,如何高效处理实时更新的图数据是难点。
- 多模态信息融合 (Multi-Modality): 将图像、视频等多模态数据整合进图谱,实现跨模态检索增强。
- 可扩展性与高效检索 (Scalable and Efficient Retrieval): 工业界图谱规模达亿级,如何在超大规模图上实现低延迟检索是巨大挑战。
- 结合图基础模型 (Graph Foundation Model): 利用通用的图大模型来替换或增强现有的检索/编码模块。
- 检索上下文的无损压缩 (Lossless Compression): 图转换后的文本往往极长,如何压缩上下文且不丢失结构信息是关键。
- 标准化基准 (Standard Benchmarks): 当前缺乏统一的评测标准,急需建立涵盖多领域、多任务的标准化Benchmark。
总结
这篇综述不仅仅是技术的堆砌,它通过清晰的分类学(Taxonomy),将GraphRAG从一种模糊的技术概念具象化为一套标准流程。它强调了结构化知识在LLM时代的重要性:GraphRAG不仅仅是检索,更是利用图结构作为人类知识与机器生成之间的桥梁,以解决传统RAG无法处理的复杂关系推理和全局信息概括问题。
十一、《A Survey of Graph Retrieval-Augmented Generation for Customized Large Language Models》
这是一份关于论文《A Survey of Graph Retrieval-Augmented Generation for Customized Large Language Models》(面向定制化大型语言模型的图检索增强生成综述)的详尽总结。该论文由香港理工大学、吉林大学等机构的研究人员联合发表。
以下是根据论文内容进行的详细梳理和总结:
1. 论文背景与核心问题 (Introduction & Motivation)
背景:
大型语言模型(LLMs)在通用领域表现出色,但在特定专业领域(如医疗、法律、科学研究)的应用面临巨大挑战。为了解决这一问题,检索增强生成(RAG)技术应运而生,它通过检索外部知识库来增强LLM,避免了昂贵的重新训练(Fine-tuning)。
传统RAG面临的三大挑战:
尽管传统RAG(基于扁平文本切片检索)有效,但在专业领域存在严重局限:
- 复杂查询理解困难 (Complex Query Understanding): 专业领域常涉及复杂术语和行话,传统RAG基于关键词或向量相似度的检索难以捕捉深层语义细微差别和多跳推理逻辑。
- 难以整合分布式知识 (Knowledge Integration across Distributed Sources): 领域知识通常分散在多份文档中。传统RAG将文档切分为碎片(Chunking),破坏了长距离的上下文联系,导致知识碎片化。
- 系统效率瓶颈 (System Efficiency Bottlenecks): 大规模知识库中包含大量无关信息,传统RAG在大规模非结构化文本中检索不仅计算成本高,而且容易被无关信息淹没。
解决方案:GraphRAG
论文提出了GraphRAG(图检索增强生成) 这一新范式。它利用图结构(Knowledge Graphs, KGs)来组织和检索知识,通过显式捕捉实体关系和领域层级结构,解决了传统RAG的局限性。
2. GraphRAG 概述 (Overview)
定义:
GraphRAG是RAG的一个子类,利用图结构来组织和检索知识。它通过节点和边对知识片段之间的依赖关系进行建模。
GraphRAG vs. 传统 RAG:
- 知识表示: 传统RAG使用扁平的文档切片;GraphRAG使用图结构,能够表示层级、关联和多跳关系。
- 知识源灵活性: GraphRAG能整合结构化(KG)、半结构化和非结构化数据。
- 效率与可扩展性: 图数据库针对关系查询进行了优化,能够快速遍历复杂数据结构,减少LLM处理的Token数量。
- 可解释性: 用户可以通过追踪图中的推理路径来理解系统的回答逻辑。
GraphRAG 的分类学 (Taxonomy):
论文根据图结构的使用方式将现有工作分为三类:
- 基于知识的 GraphRAG (Knowledge-based GraphRAG): 图作为知识的载体。将非结构化文本转化为显式的知识图谱(KG),节点代表概念,边代表语义关系。
- 基于索引的 GraphRAG (Index-based GraphRAG): 图作为索引工具。保持原始文本形式,利用图结构(如文档引用图、关键词共现图)来索引和组织原始文本切片(Chunks),通过图进行导航检索。
- 混合 GraphRAG (Hybrid GraphRAG): 结合了上述两者的优势,既利用显式KG进行推理,又保留原始文本的丰富细节。
3. 知识组织 (Knowledge Organization)
这一阶段关注如何构建图结构来存储或索引数据。
A. 图作为知识索引 (Graphs for Knowledge Indexing)
- 方法: 将文本切片符号化为图中的节点,边表示切片间的关系(如语义相似度、文档结构关系)。
- 通用索引: 利用关键词相似度、主题共现构建图(例如 GNN-ret, PG-RAG)。
- 领域特定索引: 如代码补全中的代码上下文图(GraphCoder),机器人规划中的3D场景图(SayPlan)。
B. 图作为知识载体 (Graphs as Knowledge Carriers)
- 从语料库构建 KG (Construction from Corpus):
-
- 利用开放信息抽取(OpenIE)或LLM从非结构化文本中提取实体和三元组。
- 代表作:Microsoft GraphRAG(利用LLM生成社区摘要)、GraphReader。
- 难点:本体的一致性、构建成本高。
- 利用现有 KG (With Existing KGs):
-
- 直接利用DBpedia、Freebase或领域KG(如生物医学SPOKE)。
- 代表作:ToG (Think-on-Graph), RoG (Reasoning on Graphs)。
- 难点:现有KG通常不完整(稀疏性),需要算法动态规划推理路径。
C. 混合模式 (Hybrid)
- 结合图结构索引和文本内容。例如 GoR 构建图连接文本块和LLM生成的模拟回答;MedGraphRAG 在医疗领域构建连接用户文档和可信医疗源的三层图结构。
4. 知识检索 (Knowledge Retrieval)
这一阶段关注如何从图中提取与查询相关的信息。
检索技术 (Retrieval Techniques):
- 基于语义相似度 (Similarity-based):
-
- 离散空间:字符串匹配(如TF-IDF),简单但无法处理同义词。
- 嵌入空间:使用Word2Vec或BERT编码查询和图元素,计算向量相似度。
- 基于逻辑推理 (Logical Reasoning-based): 利用符号推理、规则挖掘(如RuleRAG)来推导隐含信息。
- 基于GNN (GNN-based): 使用图神经网络对节点进行编码和评分,利用消息传递机制捕捉结构特征(如GNN-RAG)。
- 基于LLM (LLM-based): 利用LLM的生成能力来规划检索路径、扩展查询或直接从图中提取子图。例如 ToG 使用LLM进行波束搜索(Beam Search)来寻找推理链。
- 基于强化学习 (RL-based): 将检索视为序列决策过程,训练Agent在图中游走以寻找答案(如KnowGPT)。
检索增强策略:
- 多轮检索 (Multi-round): 动态调整检索策略,根据反馈逐步逼近答案。
- 检索后处理 (Post-retrieval): 在生成后再次检索以验证答案的准确性。
- 混合检索 (Hybrid Retrieval): 同时结合图检索和向量数据库检索(如ToG-2, Graph+Vector RAG),互补优劣。
5. 知识整合 (Knowledge Integration)
这一阶段关注如何将检索到的图数据融入LLM的生成过程。
A. 微调 (Fine-tuning)
- 节点级知识: 将节点信息拼接到输入中进行指令微调。
- 路径级知识: 关注节点间的连接序列,增强推理能力(如RoG)。
- 子图级知识: 整合复杂的子图结构,通常需要将图数据序列化(线性化)或使用图编码器(Graph Encoder)。
B. 上下文学习 (In-context Learning, ICL)
对于闭源模型(如GPT-4),主要采用Prompt工程:
- 图增强思维链 (Graph-enhanced Chain-of-Thought, CoT): 引导LLM依据检索到的图结构进行分步推理(如Think-on-Graph)。
- 协同知识图谱优化 (Collaborative KG Refinement): 利用LLM反过来修正或补全KG中的知识,形成闭环。
C. 整合增强策略
- 多模态整合: 结合图像等模态。
- 多轮交互 (Multi-round Integration): 通过类似“内心独白”的机制,多轮次细化检索结果和生成内容,以处理复杂的多跳推理问题。
6. 开源项目与应用 (Open-source Projects & Applications)
论文在附录中详细列举了现有的资源:
代表性开源项目:
- Microsoft GraphRAG: 基于社区摘要(Community Summaries)的各种层级问答,适合处理需要全局理解的查询(QFS任务)。
- Nano-GraphRAG / Fast GraphRAG: 轻量级、快速的实现版本。
- LightRAG: 降低计算复杂度,适合边缘设备。
- Medical GraphRAG: 针对医疗领域的定制化实现。
基准数据集 (Benchmarks):
- 简单QA: SimpleQuestion, WebQ.
- 多跳推理 (Multi-hop): CWQ, MetaQA.
- 特定领域: FactKG (事实核查), KQAPro.
- GraphRAG专用: GraphRAG-Bench (涵盖从图构建到生成的全流程评估)。
应用领域:
- 医疗: 疾病诊断、药物发现(利用PubMedQA, UMLS等)。
- 法律: 合规审查、案例分析(利用法律条文KG)。
- 科研与教育: 论文检索与综述生成。
- 金融与电商: 推荐系统、风险分析。
7. 局限性与未来方向 (Limitations & Future Directions)
- 知识质量 (Knowledge Quality): GraphRAG的效果高度依赖于图的质量。构建高质量KG成本高,且存在噪声。需要发展自动化的知识清洗和补全技术。
- 知识冲突 (Knowledge Conflict): 当外部知识与LLM内部知识或不同来源的知识发生冲突时,缺乏有效的消歧和融合机制。
- 数据隐私 (Data Privacy): 检索过程可能泄露敏感信息,需要结合联邦学习或差分隐私技术。
- 效率 (Efficiency): 尽管检索快,但图构建(尤其是使用LLM提取三元组)极其耗时且Token消耗巨大。需要研究更高效的图构建和剪枝算法。
- 多模态融合: 目前主要集中在文本,未来需要更好地融合图像、视频等多模态数据进图结构。
总结论 (Conclusion)
GraphRAG代表了定制化LLM的一个重要飞跃。相比于像“游客”一样随机问路的传统RAG,GraphRAG更像是一个拿着地图的“市长”,对知识库有着全局和结构化的理解。它通过结构化的知识表示、高效的图检索和深度上下文整合,显著提升了LLM在处理复杂推理和领域特定任务时的准确性与可靠性。论文不仅提供了理论分类,还整理了丰富的代码资源,为未来的研究和工业落地指明了方向。
这是一份为您定制的选题依据和选题意义。
我结合了您之前提供的 GraphRAG(微软)、LightRAG、HippoRAG、SubGCache 等前沿论文的核心逻辑,使用了更具学术深度和技术张力的语言,突出了“高效推理(Efficient Inference)”这一关键切入点。
论文题目:基于 GraphRAG 方法的大模型高效推理设计
一、 选题依据 (Selection Basis)
1. 大模型“幻觉”与知识边界的现实困境
随着大语言模型(LLMs)参数规模的指数级增长,其在通用自然语言处理任务上展现了涌现能力。然而,在面对垂直领域(如医疗、金融、法律)的专业问答时,LLM 仍面临“知识幻觉(Hallucinations)”、“知识过时”以及“私有数据不可知”三大瓶颈。检索增强生成(RAG)作为一种非参数化记忆增强手段,已成为当前解决上述问题的标准范式。但是,传统的基于向量相似度(Vector-based RAG)的方法本质上是基于语义重叠的**“扁平化检索”**,它将文档切分为独立的碎片,割裂了知识间的逻辑关联与全局结构,导致模型在处理跨文档推理、多跳问答(Multi-hop QA)以及全局意义构建(Global Sensemaking)任务时表现疲软。
2. GraphRAG:从“语义匹配”向“结构化推理”的范式转移
为了突破向量检索的局限,图检索增强生成(GraphRAG)应运而生。通过引入知识图谱(Knowledge Graph)作为结构化先验,GraphRAG 将离散的文本块组织为包含实体、关系和子图的语义网络。近年来的研究(如 Microsoft GraphRAG, RoG, HippoRAG 等)表明,GraphRAG 能够利用图拓扑结构进行逻辑游走和社区摘要,显著提升了 LLM 在复杂推理场景下的准确性与全面性。它标志着 RAG 技术正在从**“概率性语义匹配”向“确定性结构化推理”**演进,是实现可信 AI 的关键路径。
3. “不可能三角”的挑战:高性能与低效率的矛盾
尽管 GraphRAG 在质量上超越了传统方法,但其**推理效率(Inference Efficiency)**已成为制约工业级落地的最大掣肘。
- 构建成本高昂:现有的 GraphRAG 往往依赖 LLM 进行全量的实体与关系抽取(OpenIE),导致索引构建阶段的 Token 消耗和时间成本呈指数级增长。
- 推理延迟显著:在线检索阶段,复杂的图遍历算法(如多跳子图查找、PPR 游走)以及将庞大的图结构序列化为 Context 输入 LLM,导致首字生成时间(TTFT)和端到端延迟大幅增加。
- 资源开销大:在处理高并发请求时,重复的图计算和冗长的 Prompt 对显存和算力构成了巨大压力。
因此,如何在保留 GraphRAG 卓越推理能力的同时,设计一套“轻量化、低延迟、低成本”的高效推理架构,打破质量与效率的博弈,是当前学术界和工业界亟待攻克的关键科学问题**。本选题旨在探索 GraphRAG 的高效推理设计,具有极强的紧迫性和前沿性。**
二、 选题意义 (Significance of the Topic)
本研究旨在提出一种基于 GraphRAG 的高效推理框架,通过算法优化与架构设计,实现大模型在结构化知识增强下的快速响应。其意义主要体现在以下三个维度:
1. 学术理论意义:深化“神经+符号”的融合机制
- 探索结构化知识的高效表征:本研究将探索如何更紧凑地将图数据(符号知识)编码进 LLM(神经网络),研究图剪枝、子图缓存(Subgraph Caching)或图嵌入(Graph Embedding)等技术在 RAG 中的应用边界。这有助于丰富**神经符号人工智能(Neuro-Symbolic AI)**的理论内涵。
- 优化检索-生成的协同范式:通过研究高效的图索引与检索策略(如混合索引、分层检索),本研究将为解决 RAG 系统中“检索粒度”与“上下文窗口限制”之间的矛盾提供新的理论视角,推动检索增强技术从粗放的文本匹配向精细的知识导航转变。
2. 工程实践意义:突破 GraphRAG 的落地瓶颈
- 降低算力与经济成本:通过设计高效的推理机制(如减少对 LLM 的检索依赖、优化图遍历算法),本研究有望大幅降低 GraphRAG 在索引构建和在线推理阶段的 Token 消耗与计算资源占用。这对于资源受限的边缘设备部署或大规模企业级应用具有决定性意义。
- 提升系统的实时响应能力:针对 GraphRAG 推理慢的问题,本研究将致力于缩短检索路径和优化上下文加载,显著降低系统的端到端延迟(Latency),使其能够满足实时对话、实时风控等高并发场景的需求。
3. 应用价值:赋能复杂场景下的智能决策
- 增强垂直领域的推理深度:高效的 GraphRAG 架构将使得在医疗诊断、金融审计、法律案情分析等专业领域,能够以可接受的成本实现跨文档的深度关联分析和证据链溯源。
- 提升系统的可解释性与可信度:相比于黑盒的向量检索,基于图的推理路径天然具备可解释性。本研究的高效设计将使得这种“白盒化”的推理过程能够更流畅地呈现给用户,增强人机协作中的信任感,推动大模型在关键决策领域的广泛应用。
总结 (Summary for Thesis Proposal)
综上所述,本选题立足于大模型技术发展的最前沿,直面 GraphRAG 技术**“效果好但落地难”的核心痛点。通过研究高效推理设计,不仅能填补当前在图检索效率优化方面的理论空白,更能为下一代高性能、低成本、可解释**的智能知识系统提供切实可行的解决方案,具有重要的学术价值和广阔的应用前景。
可以阅读的相关文章:
1.《RAG 实战:系统开发指南》 个人写的的知乎博文(在更新中,工程化)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 14
14 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)