从0-1图文详解搭建属于自己的AI日报工作流
AI日报自动生成系统开发实战教程 本文详细介绍从0到1构建AI日报自动生成系统的完整开发流程。系统通过Coze工作流实现关键词输入→新闻抓取→内容处理→日报生成的全自动化。核心功能包括:自动搜索行业新闻、智能摘要重写、日期信息获取、可视化日报输出等。教程涵盖10个关键开发步骤,从意图识别、新闻搜索、批处理循环,到内容优化、模板封装等,并配有详细图文说明和变量作用解释。最终实现用户只需输入一个关键词
📰 从0到1构建“AI日报自动生成系统”|完整开发实战教程(Coze工作流)
💡本文适合0基础到进阶的自动化开发者,包含详细图文解释和变量的意义解释
内容覆盖:流程设计 → 插件调用 → 批处理 → LLM数据结构处理 → 报告生成 → 可视化日报输出。
⚙️开发工具:Coze工作流 + LLM模型 + 插件/技能🎯最终目标:输入一个关键词 → 自动抓取新闻 → 重写摘要 → 输出日报(图片+文本)
📌一、项目背景 & 能力目标
传统日报生产流程非常低效 👇
- 手动找新闻、复制标题、写摘要
- 还要收集日期、星期、农历、开头金句
- 格式不统一,难以复用
🔥本项目通过工作流自动化,实现“一键日报”:
| 能力 | 自动化实现内容 |
|---|---|
| 新闻收集 | 自动完成行业新闻搜索 |
| 内容清洗 | 解析URL正文、过滤无效内容 |
| 智能写作 | 重写摘要、自动改标题 |
| 抬头信息 | 自动获取日期/农历/星期/口号 |
| 报表生成 | 输出日报图片 or 文本 |
最终效果👇
用户输入一句话:
给我一份AI行业日报
本文使用变量作用参考
| 功能阶段 | 变量名 | 作用 |
|---|---|---|
| 用户输入 | input |
用户自然语言输入 |
| 关键词提取(LLM) | keyword |
从input中提炼的行业关键词 |
| 搜索插件输出 | doc_results |
新闻搜索返回的文章对象数组 |
| 批处理 item 对象 | item.url / item.title / item.summary |
每一条循环解析目标 |
| 网页正文读取 | content / title |
LinkReader 提取正文与标题 |
| 批处理累积变量 | content_list / title_list |
批量循环后的内容/标题数组 |
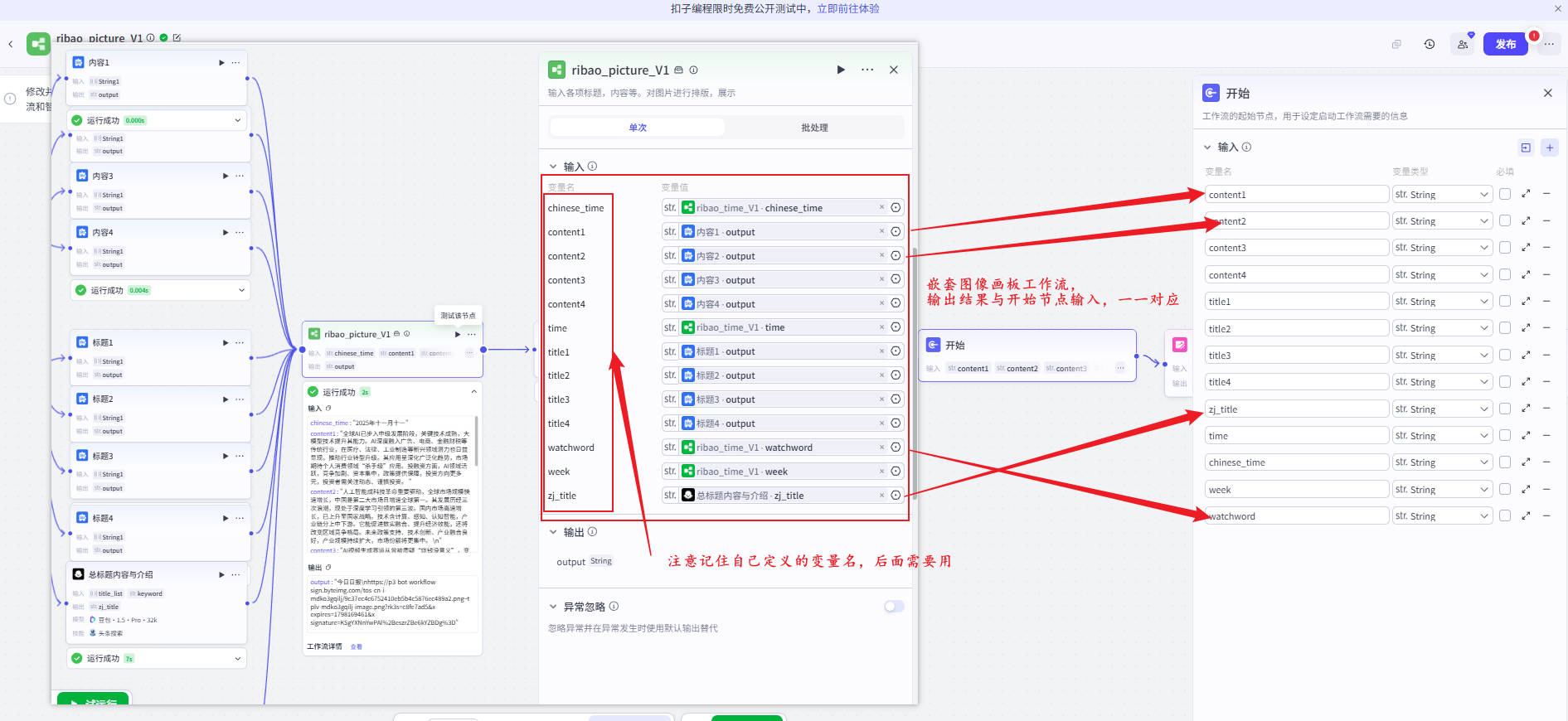
| 日期模块变量 | time / chinese_time / week / watchword |
抬头信息字段 |
| 日报封装输入 | content1~5 / title1~5 |
用于日报模板映射 |
| 最终输出 | output |
日报图片或文本 |
🧠二、系统整体架构思维图
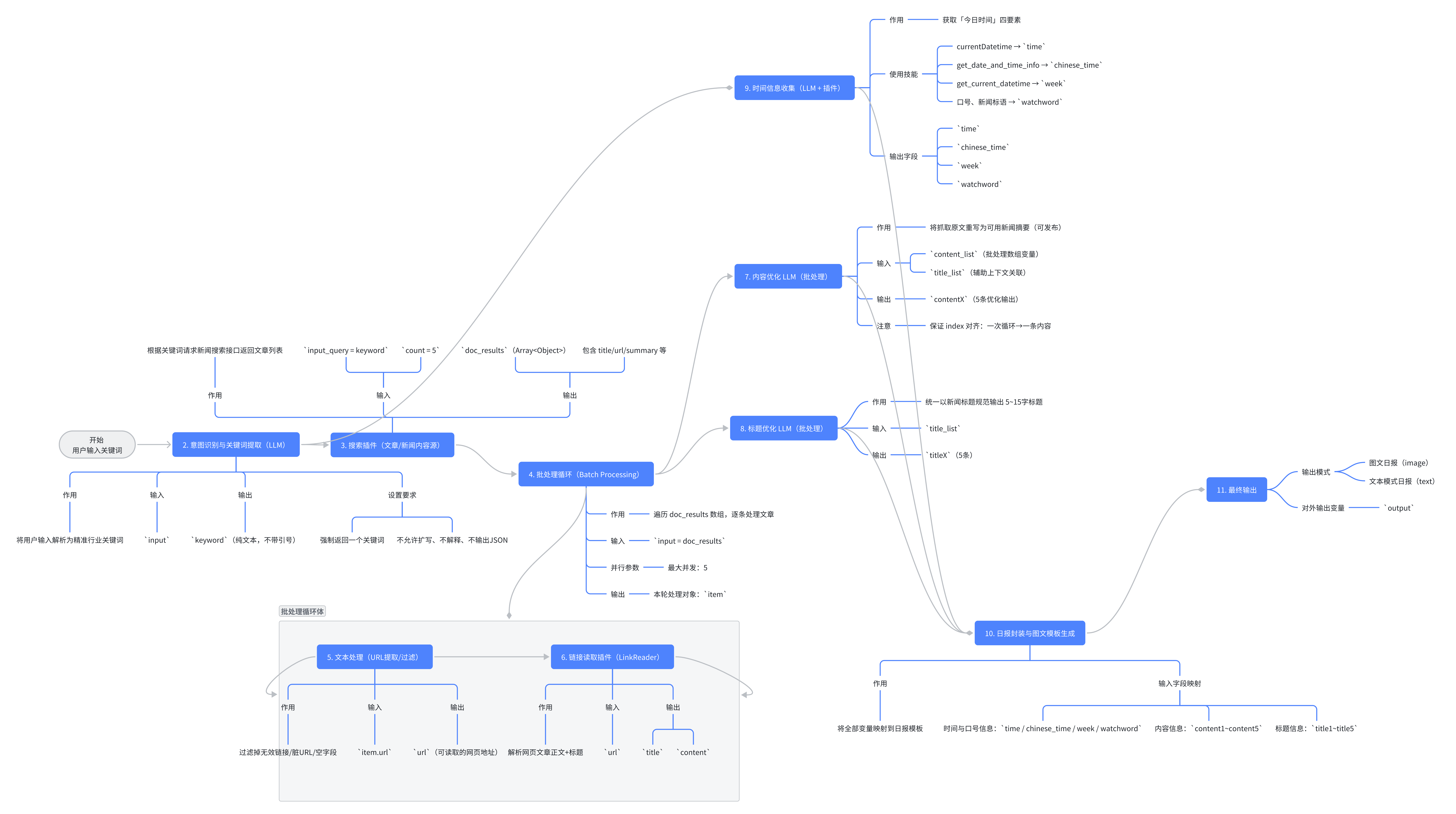
📌图片说明:展示了输入→意图识别→搜索→解析→批处理→写作→封装→输出完整链路
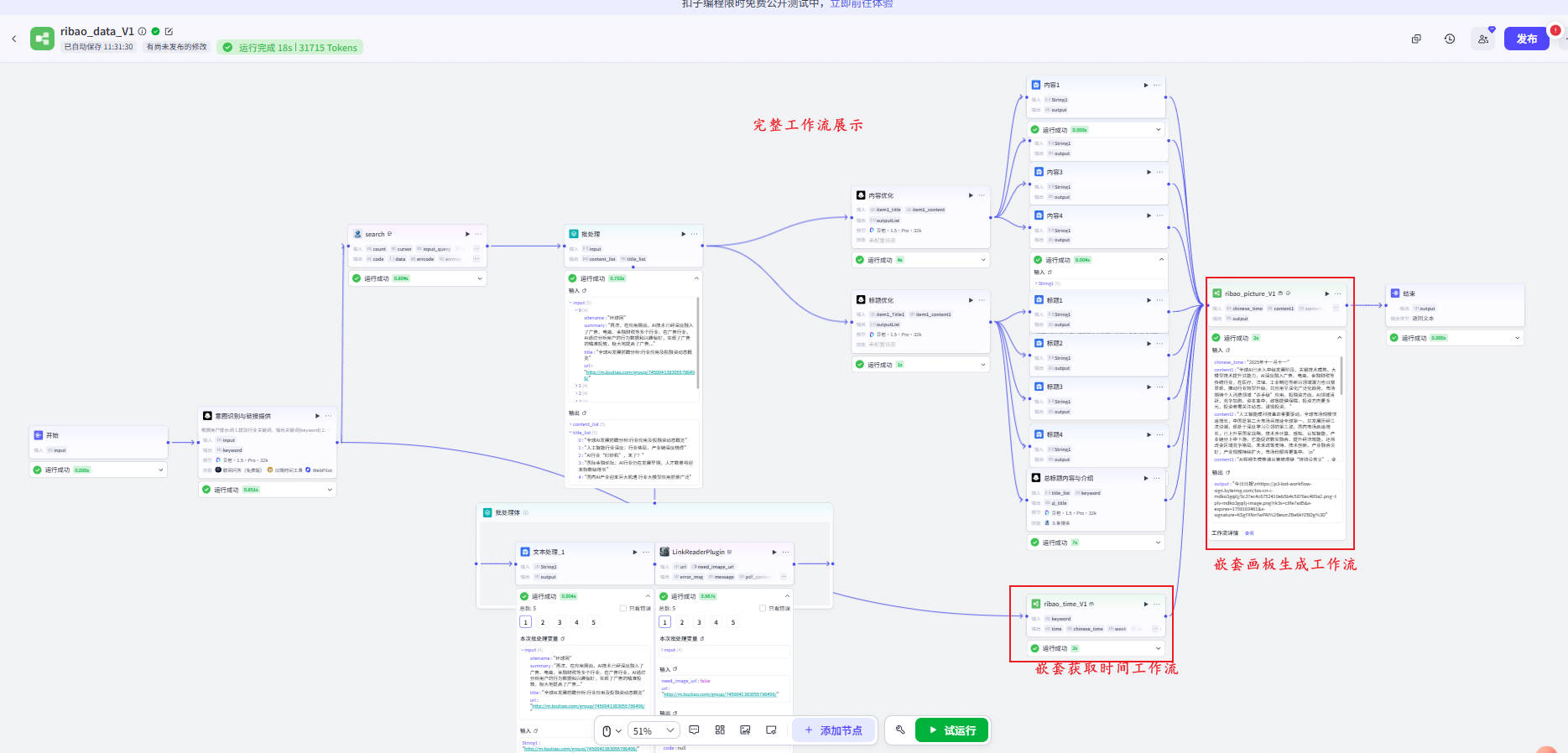
📌图片说明:展示了从思维框架到实际生成的工作流
🚀三、工作流开发步骤(图文详解完整教学版)
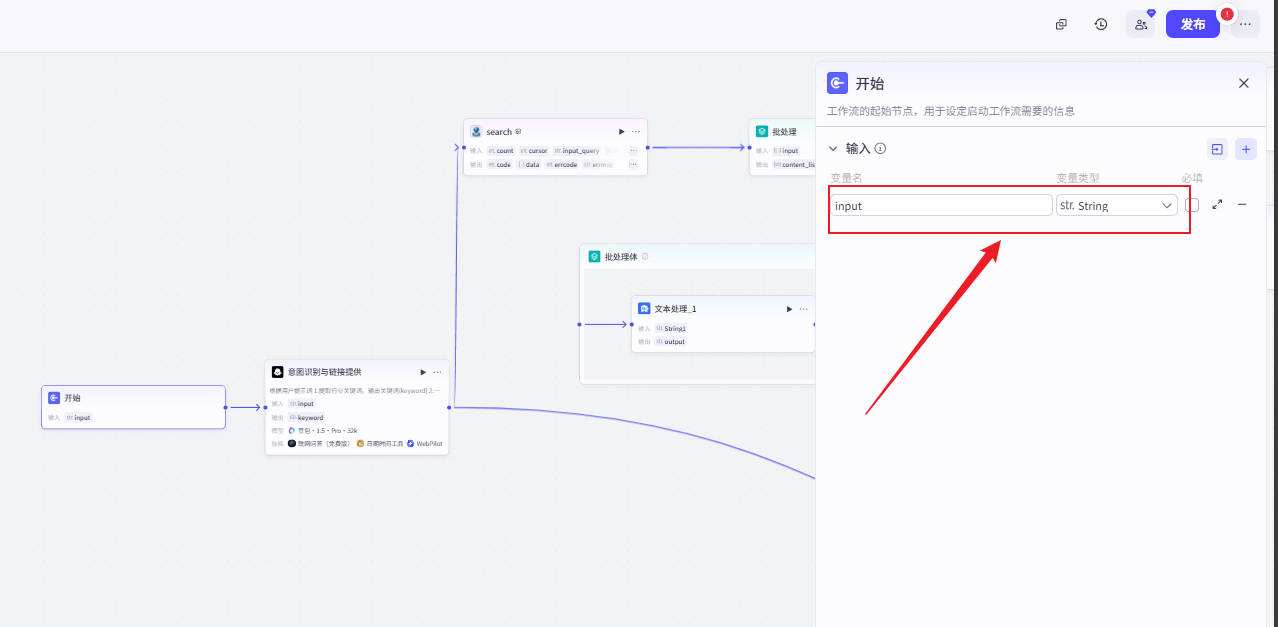
步骤1:创建开始节点
- 字段:
input(String) - 用途:用户输入自然语言,如 “今天新能源行业新闻”
input → String
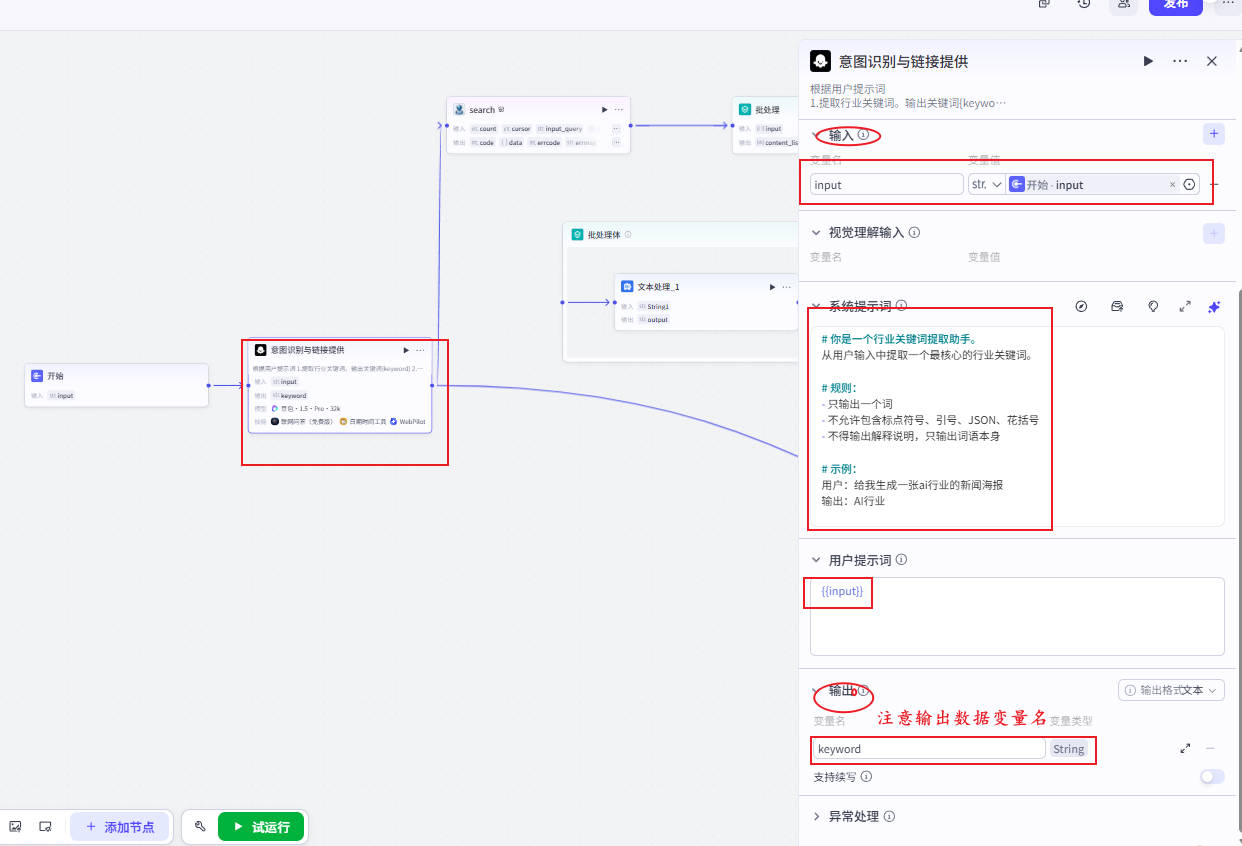
步骤2:意图识别 & 关键词提取(LLM)
📍输入:input
📍输出:keyword(只保留名词)
🚫不能输出句子
🚫不能解释
🚫不能JSON
✔只输出一个关键词
用户输入:{{input}}
输出格式:keyword
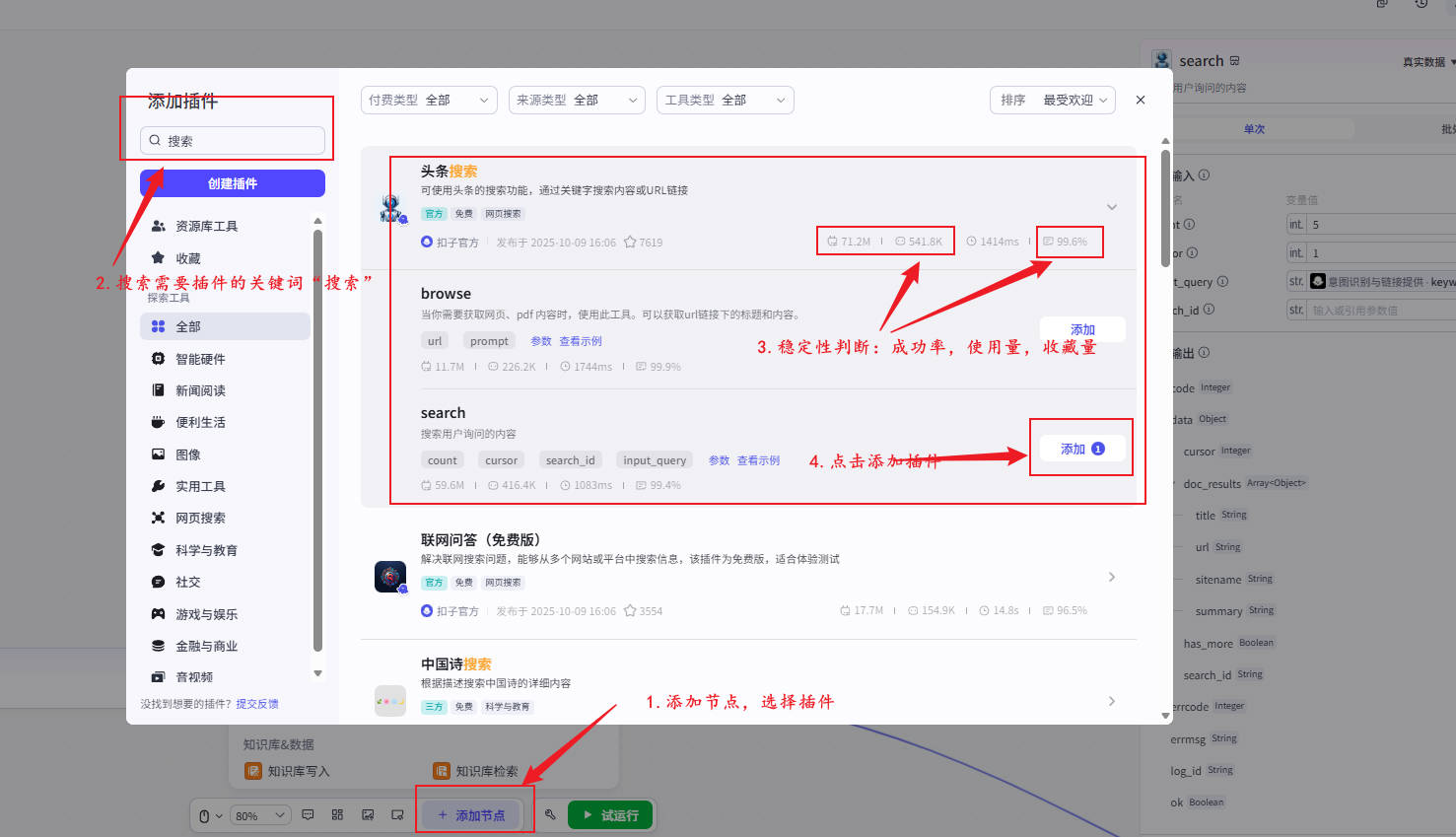
步骤3:搜索插件抓取新闻
📍输入配置
count = 5
input_query = keyword
📍重点输出字段
| 字段 | 结构 | 说明 |
|---|---|---|
doc_results |
Array | 进入批处理的源数据 |
item.url |
String | 后续解析网页 |
item.title / item.summary |
字段来源引用 |
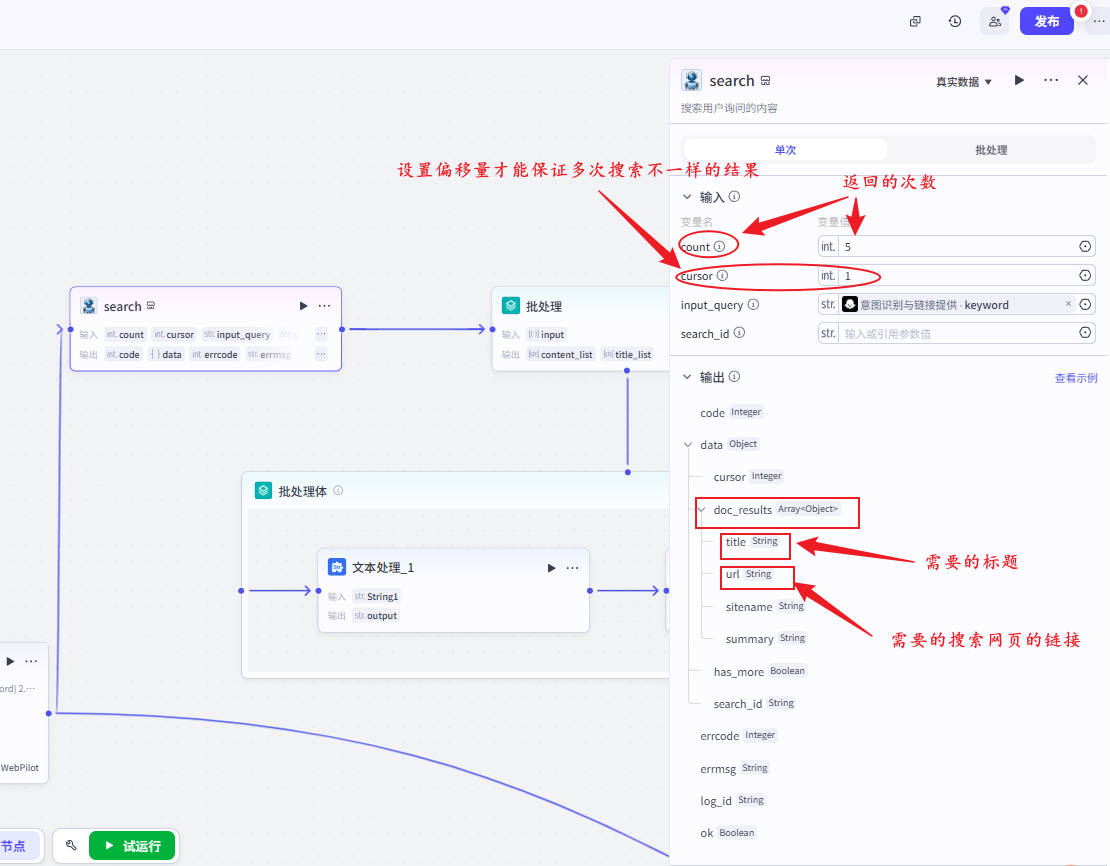
步骤4:批处理(Batch Processing)循环解析核心
📍输入:doc_results
📍单次对象:item
📍并行:5
输入:doc_results
循环变量:item
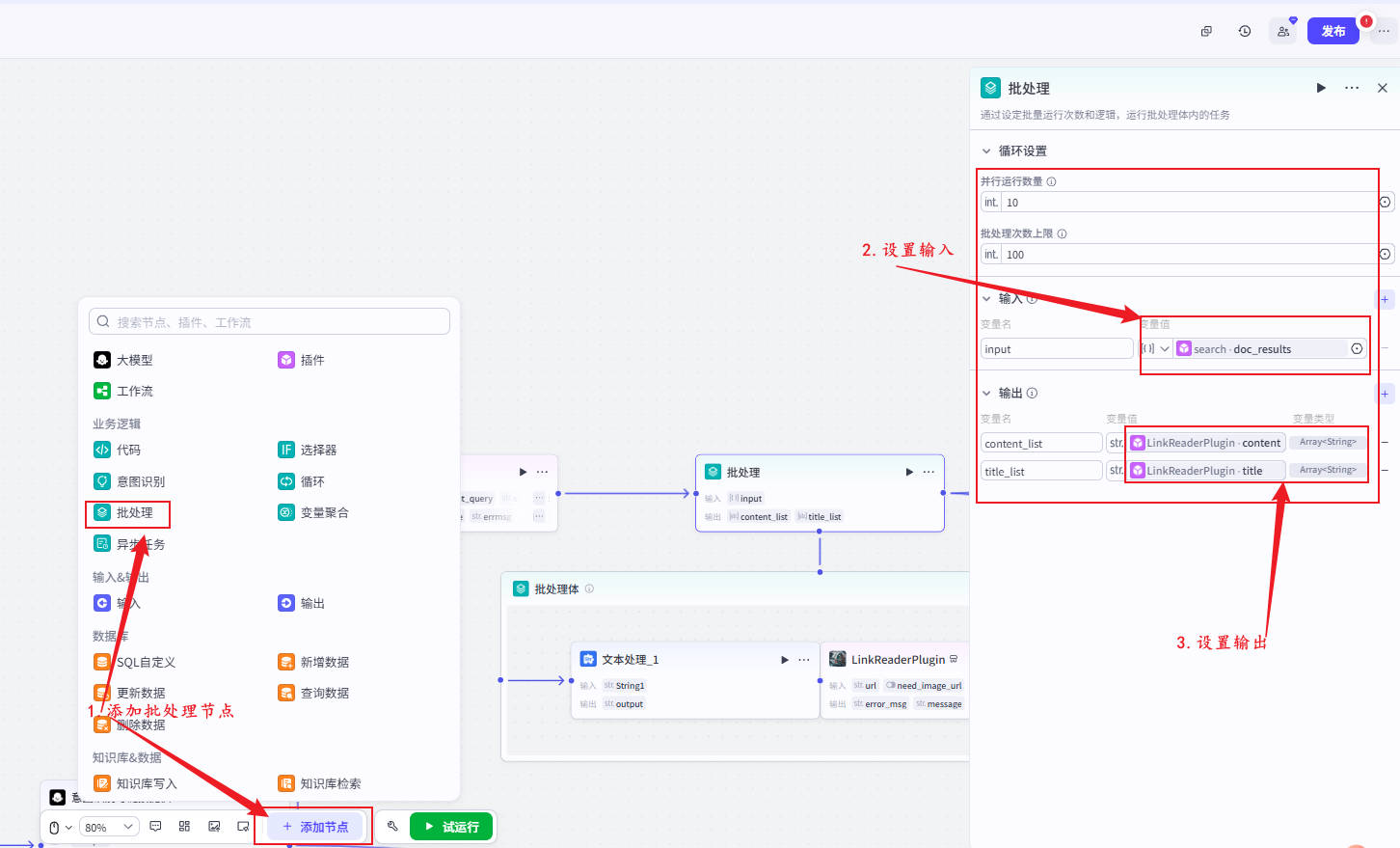
步骤5:URL文本清洗
📍输入:item.url
📍输出:url
如果 url == null 或 不含 http → 跳过
如果包含推广/短链 → 剔除
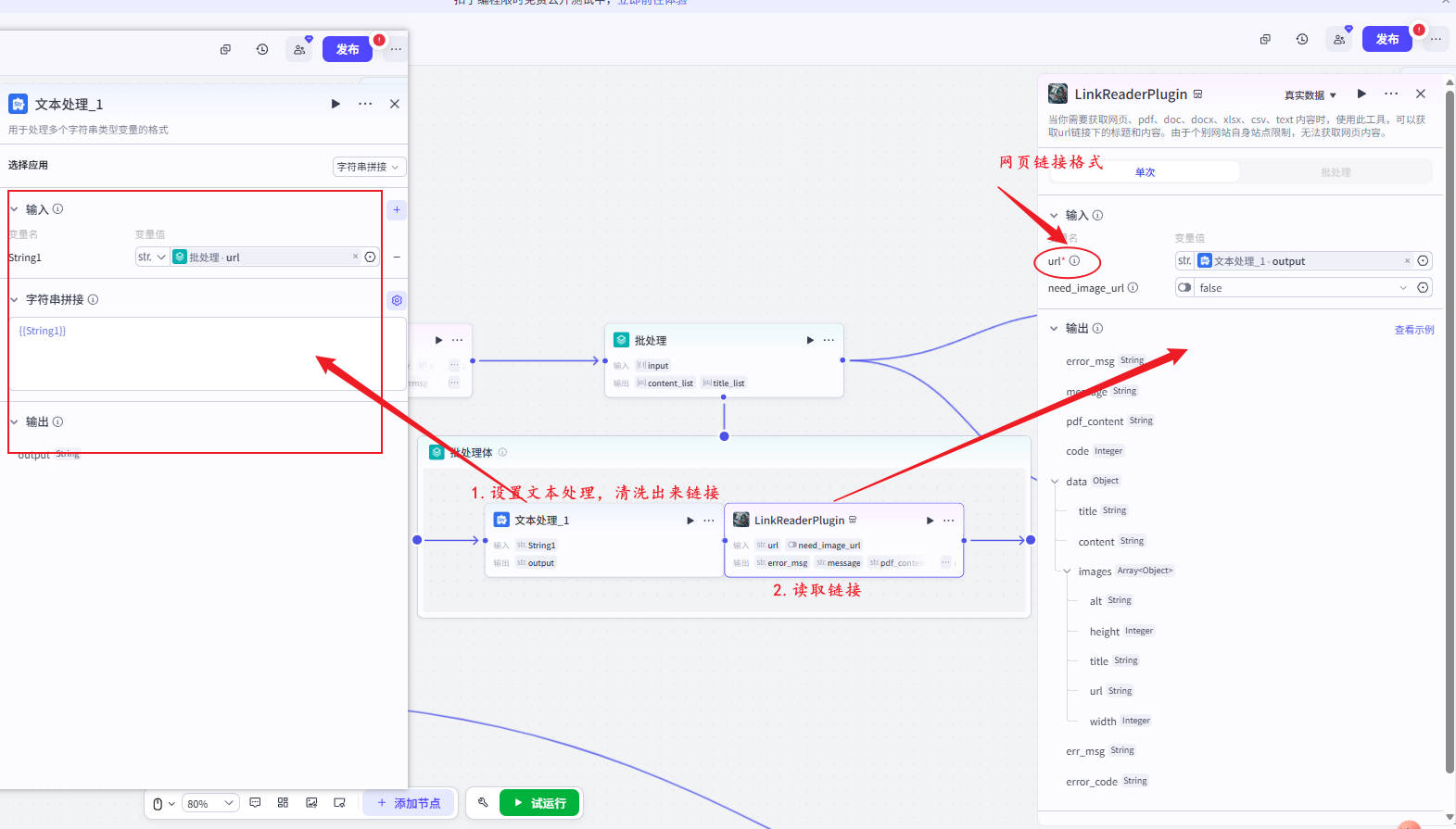
步骤6:LinkReader网页提取正文
📍输入:url
📍输出:
| 字段 | 含义 |
|---|---|
content |
正文文本 |
title |
文章主标题 |
⚠注意:与搜索插件的 title 字段不同,这里是“页面真实标题”
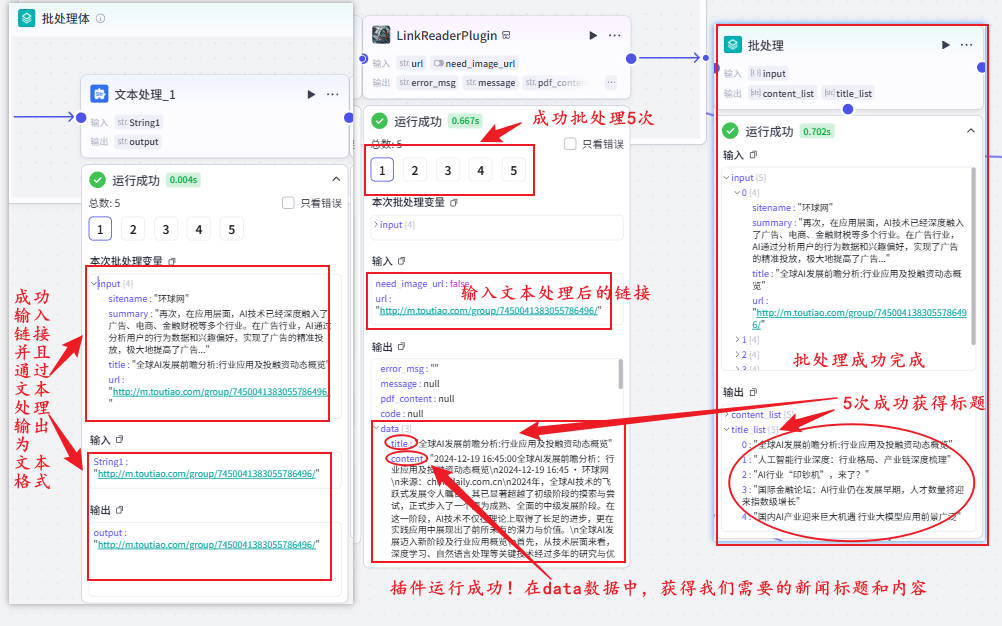
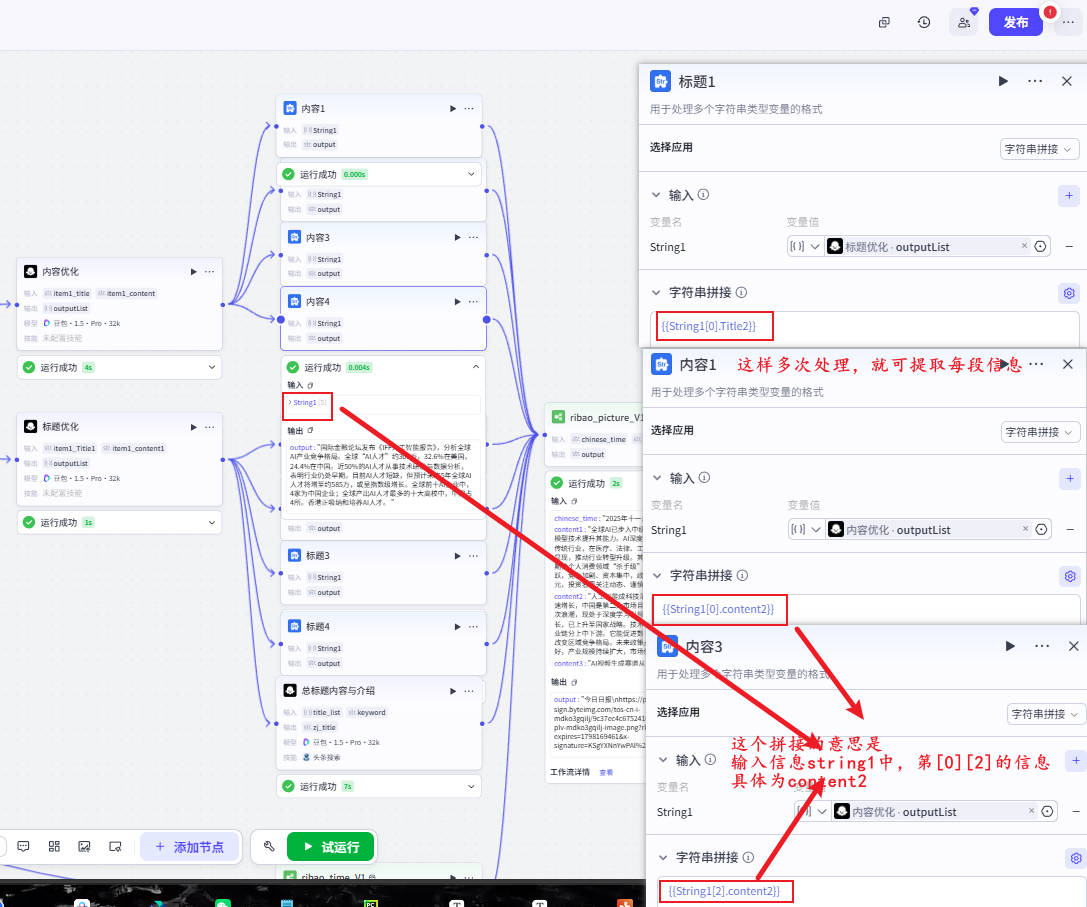
步骤7:内容优化LLM(核心修复版语法)
📍错误写法(你曾遇到5条重复问题❌)
content = content_list
📍正确写法(按数组索引逐条进入✔)
content = {{item.content}}
title = {{item.title}}
📍输出数组
content_list → Array
title_list → Array
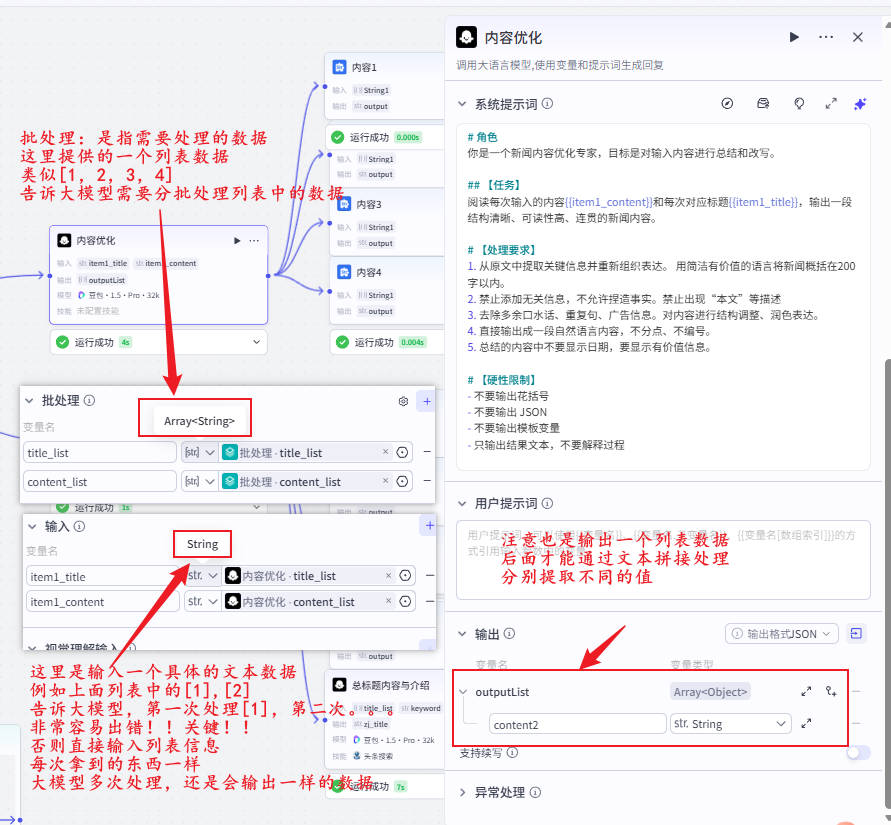
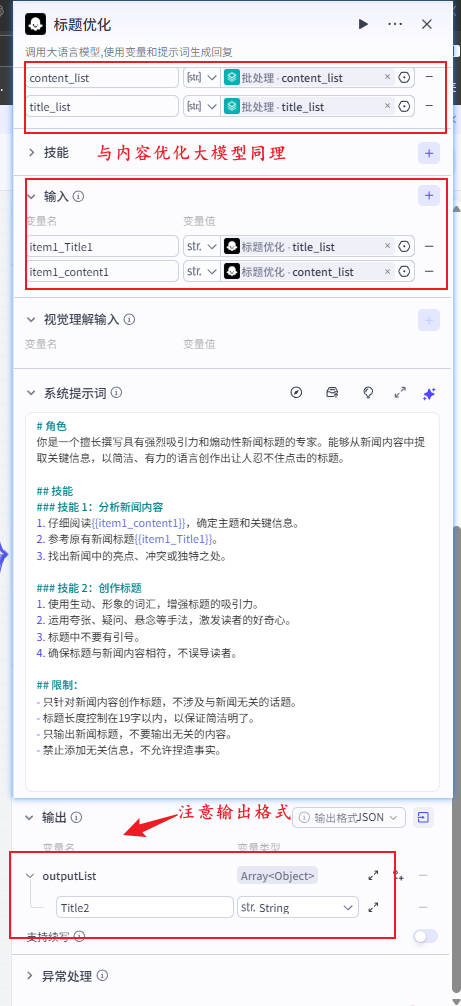
步骤8:标题优化 LLM(5~15字规则)
🚫不能问句
🚫不能复述
🚫不能营销口号
✔行业表达、可读标题
输入:{{item.title}} + {{item.content}}
输出:title_list[i]
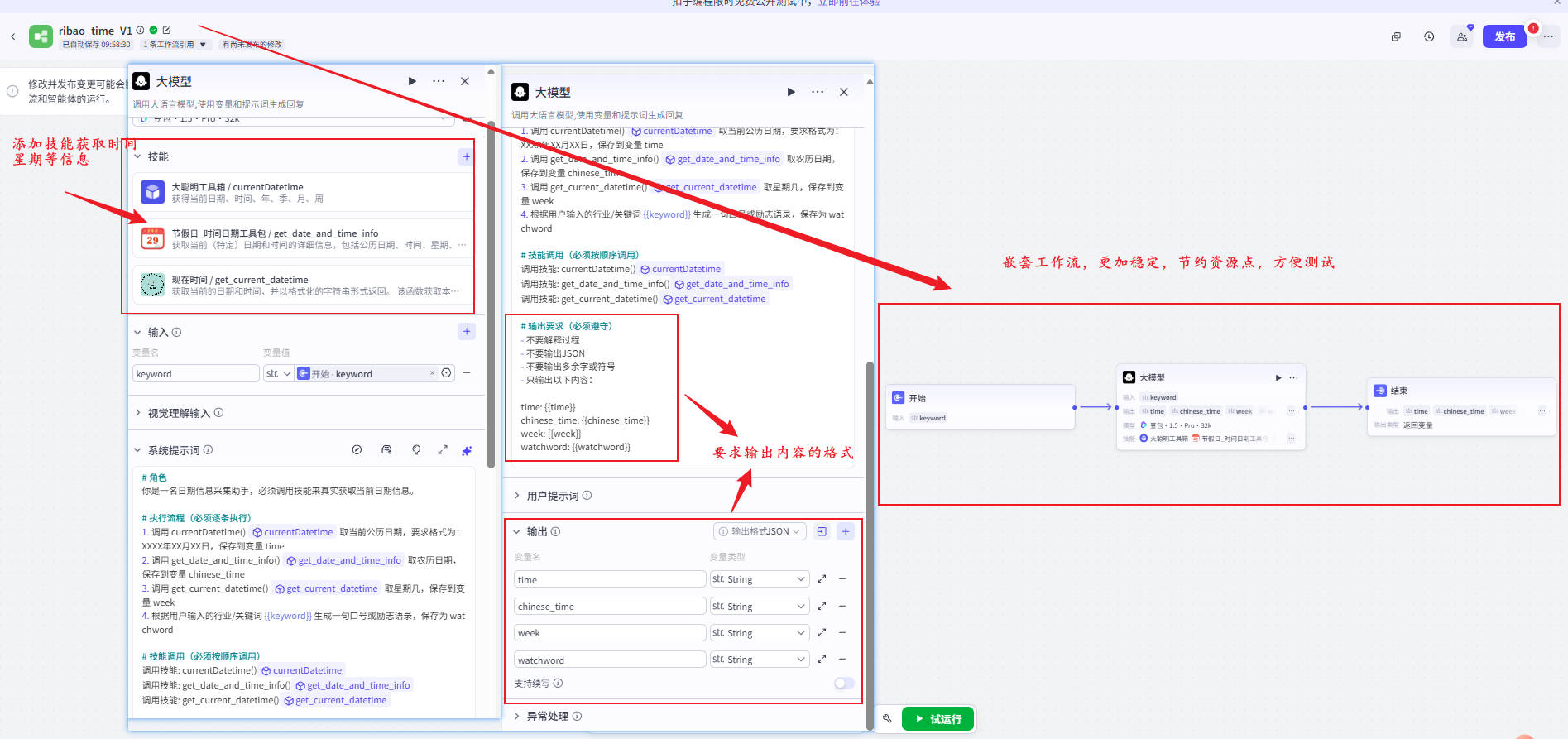
步骤9:时间/农历/星期/口号生成(LLM + 插件)
📌字段对应(按你文档真实使用)
| 插件 | 绑定变量 |
|---|---|
| currentDatetime | time |
| get_date_and_time_info | chinese_time |
| get_current_datetime | week |
| LLM输出口号 | watchword |
time: {{time}}
chinese_time: {{chinese_time}}
week: {{week}}
watchword: {{watchword}}
步骤10:日报封装模板(内容与标题映射)
📍映射规则按你实际结构校对
title_list[0] → title1
content_list[0] → content1
...
title_list[4] → title5
content_list[4] → content5
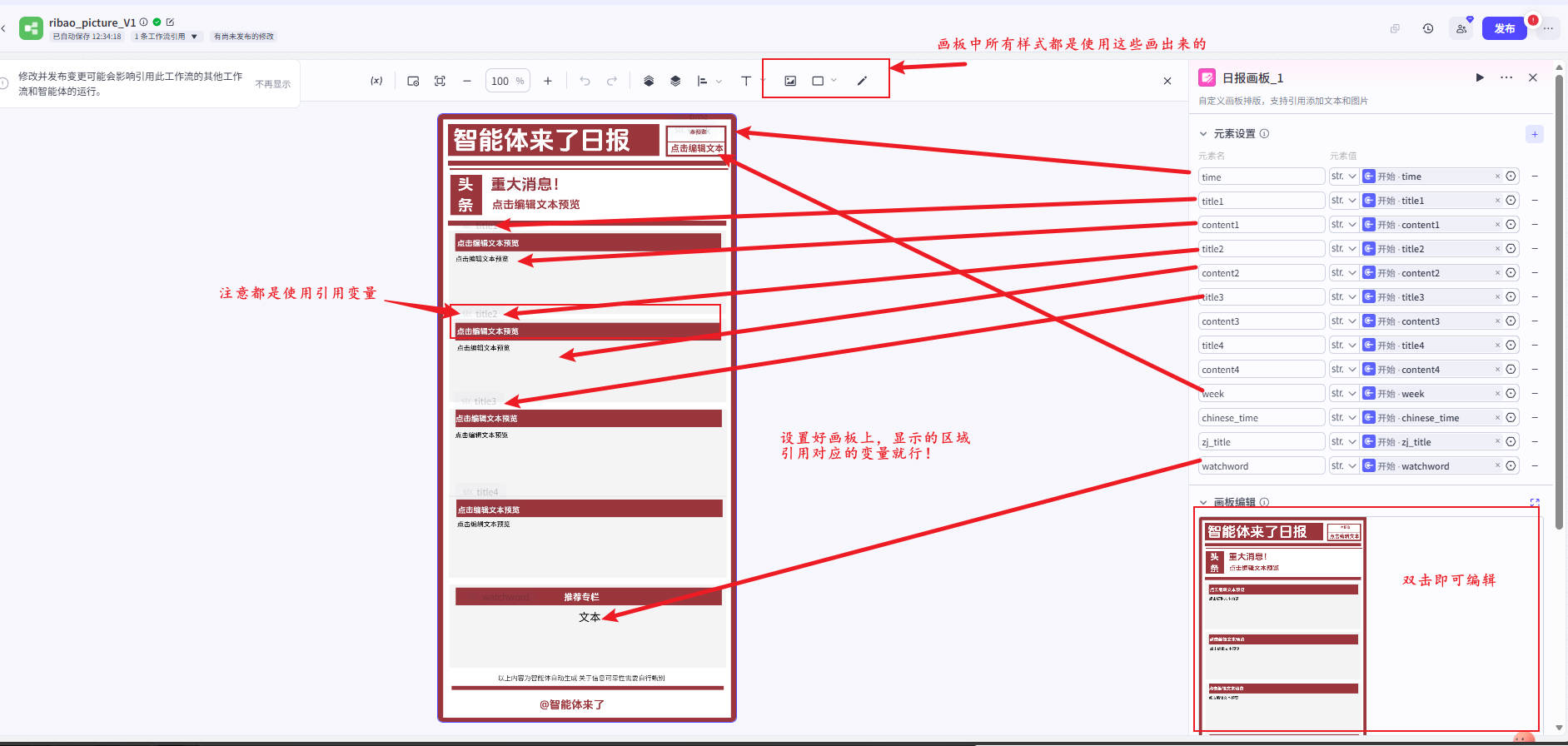
📌输出类型可选:
- 🖼 图片日报(公众号直接可发)
- 📝 文本日报(适合CSDN)
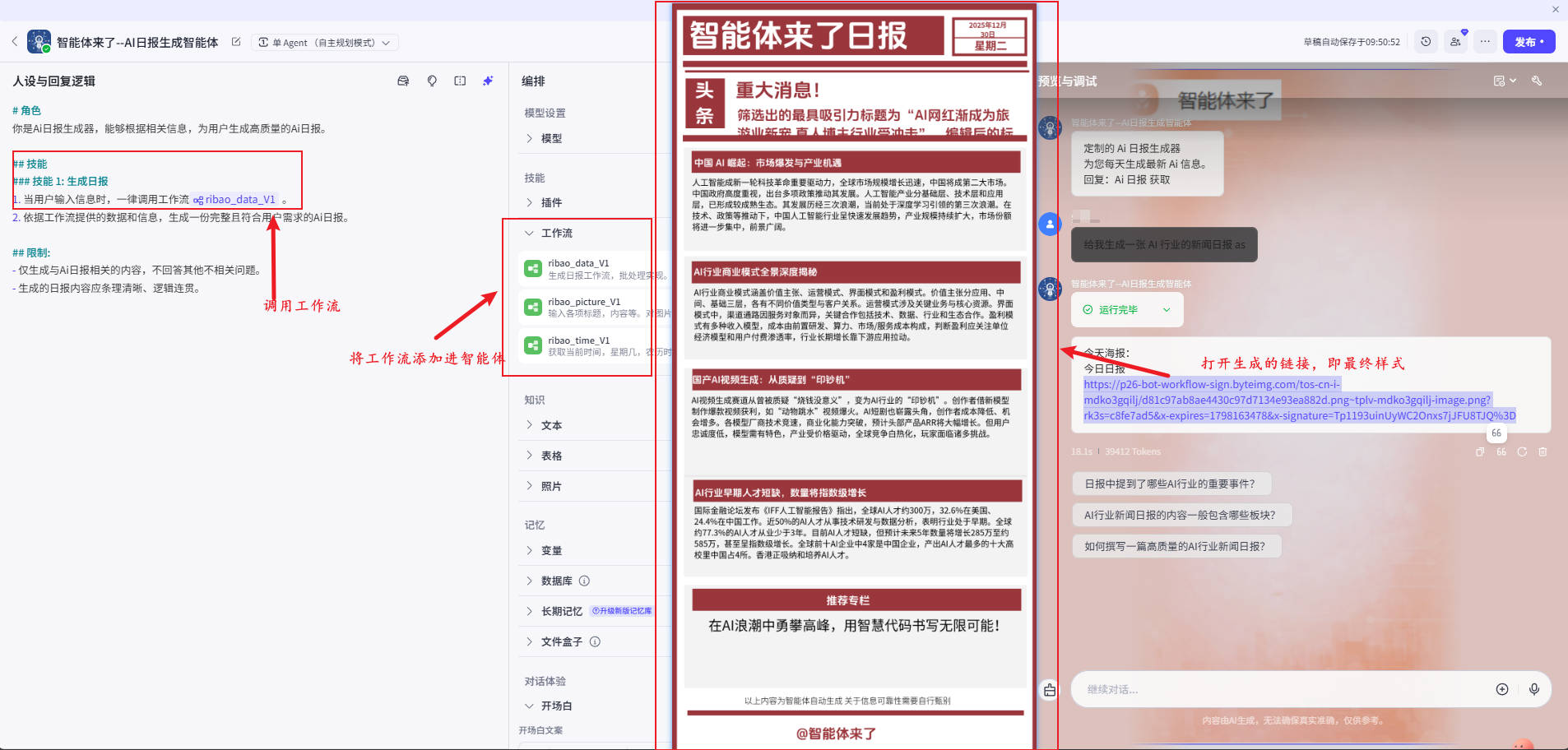
步骤11:最终输出
output = 日报成品(图片URL或整篇文案)
⚠四、常见问题修复与解决方案(已按你文档校准)
| 现象 | 原因 | 解决方式 |
|---|---|---|
| 5条内容重复 | 变量引用错 | 使用 {{item.xxx}} |
| 标题顺序错乱 | 数组未对齐 | 确保 index 序一致 |
| 时间为空 | 插件未绑定 | 手动绑定 time |
| LinkReader报错 | URL无效 | 增加清洗规则 |
| 日报空白 | 未映射字段 | 检查模板绑定变量 |
📌问题确认来源:你 PDF 的问题排查表 →
📚五、关键知识点总结(已优化表述)
| 概念 | 解决的问题 |
|---|---|
| Batch 批处理 | 多条新闻循环执行 |
| item变量 | 每次循环的当前对象引用 |
| LLM结构化输出 | 保证结果可控可复用 |
| 插件约束机制 | 避免模型编造数据 |
| 变量映射 | 最终日报成品不混乱的根基 |
🎉六、最终实现效果
输入:新能源行业日报
输出:5条新闻 + 摘要 + 标题 + 时间抬头 + 日报封面图片/文本
📌你下一步可以做什么?
| 方向 | 可扩展能力 |
|---|---|
| 垂直化行业日报 | AI、医疗、汽车、财经、能源 |
| 企业内部日报 | HR/舆情/客户日报 |
| 私域交付工具 | 社群运营、公众号一键产出 |
✅点击生成的链接,查看最终生成作品
📌关注我! 后续我还会继续更新,关于使用AI 的技巧,案例与教程
📌如果这篇文章对你有帮助,欢迎点赞、收藏。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 13
13 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)