为SFT正名!清华突破性发现:大模型胡言乱语的“罪魁祸首”,竟是这0.1%的“幻觉神经元”
大型语言模型(LLMs)虽然在很多任务上表现出色,但经常会产生,也就是生成看似合理但实际上错误的内容,这严重影响了它们的可靠性。目前的研究大多从宏观角度(如训练数据、训练目标)来分析幻觉,却鲜有研究深入到微观的层面。这就像医生只知道病人的症状,却不知道身体里哪个细胞出了问题,导致难以根除病灶。现有的难题在于,我们不知道模型内部究竟是哪些微小的计算单元在“撒谎”,以及它们是如何运作的。为了解决该问题
大型语言模型(LLMs)虽然在很多任务上表现出色,但经常会产生幻觉,也就是生成看似合理但实际上错误的内容,这严重影响了它们的可靠性。目前的研究大多从宏观角度(如训练数据、训练目标)来分析幻觉,却鲜有研究深入到微观的神经元层面。这就像医生只知道病人的症状,却不知道身体里哪个细胞出了问题,导致难以根除病灶。现有的难题在于,我们不知道模型内部究竟是哪些微小的计算单元在“撒谎”,以及它们是如何运作的。
为了解决该问题,本论文提出了一个基于稀疏线性探测的分析框架,用于识别和定位模型中与幻觉直接相关的H-Neurons(幻觉神经元)。该研究发现仅需控制不到0.1%的神经元就能准确预测幻觉,并揭示了这些神经元会导致模型出现过度顺从行为,且这种机制在预训练阶段就已经形成了。
一、论文基本信息

- 论文标题:H-Neurons: On the Existence, Impact, and Origin of Hallucination-Associated Neurons in LLMs
- 作者姓名与单位:Cheng Gao, Huimin Chen, Chaojun Xiao, Zhiyi Chen, Zhiyuan Liu, Maosong Sun(清华大学)
- 发表日期与会议/期刊来源:2025年12月2日 (arXiv preprint)
- 论文链接:arXiv:2512.01797v2
二、主要贡献与创新
- 发现并定义了H-Neurons,证明了模型中极少部分(<0.1%)的神经元即可准确预测幻觉,且具有很强的跨领域泛化能力。
- 揭示了H-Neurons不仅与事实错误相关,还因果性地导致了模型的过度顺从行为,如盲从错误前提或执行有害指令。
- 追溯了幻觉神经元的起源,证实它们在预训练阶段就已经出现,而非后期指令微调引入,且在微调过程中参数变化极小。
三、研究方法与原理
该论文提出模型的核心思路是:通过对比模型生成正确答案和错误幻觉时的神经元活动差异,利用稀疏逻辑回归筛选出对幻觉贡献最大的极少量神经元(即H-Neurons),并通过放大或抑制这些神经元的激活值来验证其对模型行为的控制作用。
【模型结构图】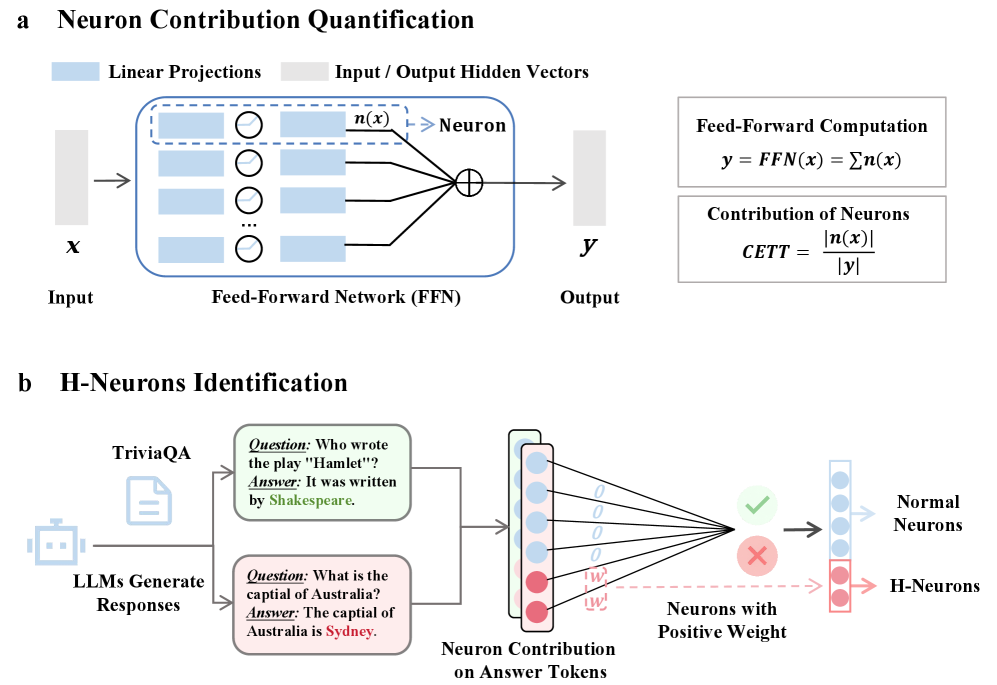
图1:识别H-Neurons的框架示意图
H-Neurons的识别方法
论文首先构建了一个平衡的数据集,包含忠实响应(正确答案)和幻觉响应(错误答案)。为了从庞大的神经网络中找出关键的神经元,研究者并没有直接使用原始的激活值,而是计算了每个神经元对隐藏状态的贡献度(Contribution)。具体来说,对于前馈网络(FFN)中的某一层的第 ttt 个token,其隐藏状态 xtx_txt 经过门控和上投影矩阵计算得到中间激活 ztz_tzt,公式为 zt=σ(Wgatext)⊙Wupxtz_t = \sigma(W_{gate} x_t) \odot W_{up} x_tzt=σ(Wgatext)⊙Wupxt。
接着,为了量化单个神经元 jjj 的贡献,研究者将其他神经元屏蔽,只保留神经元 jjj,计算其经过下投影矩阵 WdownW_{down}Wdown 后的向量 ht(j)h^{(j)}_tht(j)。然后使用 CETT指标 来衡量该神经元对整体输出的归一化贡献,计算公式为:
CETTj,t=∥ht(j)∥2∥ht∥2 CETT_{j,t} = \frac{\|h^{(j)}_t\|_2}{\|h_t\|_2} CETTj,t=∥ht∥2∥ht(j)∥2
这个公式直观地反映了该神经元的信息在总信息流中占据了多大的比例。
为了精准定位,研究者将每个神经元在答案token上的贡献聚合起来,作为特征输入到一个稀疏线性分类器(带有L1正则化的逻辑回归)中。该分类器的优化目标是最小化预测误差的同时,让尽可能多的权重变为零,从而筛选出最关键的少数神经元。损失函数如下:
L(θ)=−∑i[yilogσ(θ⊤xi)+(1−yi)log(1−σ(θ⊤xi))]+λ∥θ∥1 L(\theta) = -\sum_{i} \left[ y_i \log\sigma(\theta^\top x_i) + (1- y_i) \log (1- \sigma(\theta^\top x_i)) \right] + \lambda\|\theta\|_1 L(θ)=−i∑[yilogσ(θ⊤xi)+(1−yi)log(1−σ(θ⊤xi))]+λ∥θ∥1
其中 θ\thetaθ 是学习到的权重,权重为正的神经元即被认定为 H-Neurons。
行为干预与起源追溯
为了验证这些神经元是否真的导致了幻觉,研究者设计了干预实验。他们在模型推理过程中,人为地缩放目标神经元的激活值 zj,tz_{j,t}zj,t,即执行操作 zj,t←α⋅zj,tz_{j,t} \leftarrow \alpha \cdot z_{j,t}zj,t←α⋅zj,t。当 α>1\alpha > 1α>1 时放大神经元影响,α<1\alpha < 1α<1 时抑制其影响。
在探究起源时,研究者采用了向后传递(Backward Transferability)的方法。他们将是在指令微调模型上训练好的分类器,直接应用到其对应的预训练基座模型上。如果分类器依然有效,说明这些神经元的幻觉特征在预训练阶段就已存在。同时,研究者计算了这些神经元在微调前后的参数余弦距离,以观察它们在训练过程中的变化程度。
四、实验设计与结果分析
实验设置
实验使用了TriviaQA数据集构建训练数据,并在多个数据集上进行评测,包括同分布的TriviaQA和NQ-Open,跨领域的生物医学数据集BioASQ,以及专门构建的NonExist(关于不存在实体的虚构问题)数据集。使用的模型涵盖了Mistral、Gemma和Llama系列的不同参数规模版本。评测指标主要包括分类准确率和AUROC。
幻觉检测能力对比
研究者将使用 H-Neurons 的分类器与随机选择相同数量神经元的基线分类器进行了对比。结果显示,H-Neurons 分类器在所有测试集上都取得了显著更高的准确率。例如在 Mistral-7B 模型上,H-Neurons 在 TriviaQA 上的准确率达到 78.4%,而随机基线仅为 61.7%。这证明了 H-Neurons 确实捕捉到了幻觉的核心特征,并且这种特征在跨领域和面对完全虚构的问题时依然鲁棒。具体结果如下表所示(对应文中 Table 1):
| Models | Neurons Ratio (‰) | TriviaQA (H-Neurons) | TriviaQA (Random) | NonExist (H-Neurons) | NonExist (Random) |
|---|---|---|---|---|---|
| Mistral-7B-v0.3 | 0.35 | 78.4 | 61.7 | 91.1 | 80.9 |
| Gemma-3-27B | 0.18 | 83.6 | 65.2 | 95.9 | 58.2 |
| Llama-3.1-8B | 0.02 | 70.1 | 56.1 | 43.1 | 50.6 |
(注:表格数据精选自原论文 Table 1,展示了部分关键对比)
行为影响分析(可视化对比)
为了探究 H-Neurons 对模型行为的具体影响,研究者在 FalseQA(错误前提)、FaithEval(误导性上下文)、Sycophancy(阿谀奉承/盲从质疑)和 Jailbreak(越狱/有害指令)四个基准上进行了干预实验。
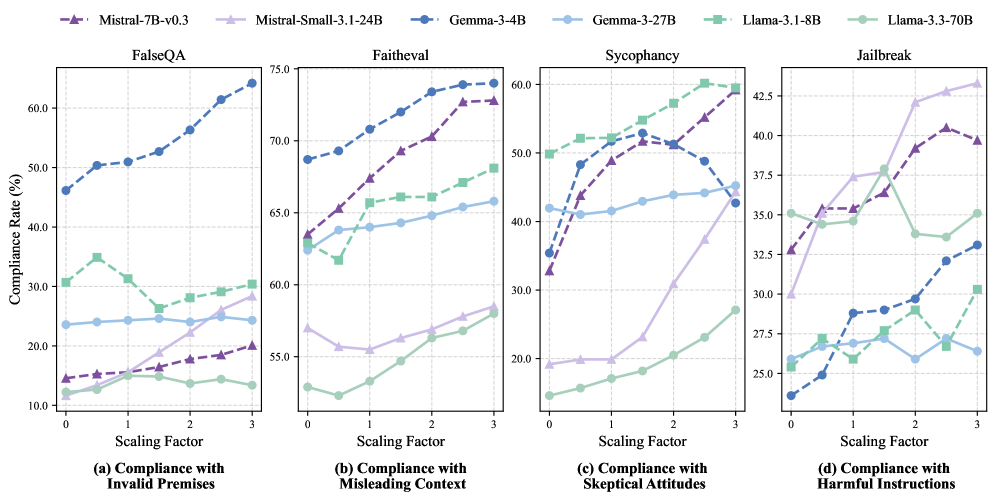
图3:不同缩放因子下模型的顺从率变化
结果表明(如文中图3所示),随着缩放因子 α\alphaα 的增加(即增强 H-Neurons 的活性),模型在所有四个维度上的顺从率(Compliance Rate)都呈现上升趋势。这意味着模型更容易接受错误的前提、相信误导性的上下文、在被质疑时放弃正确答案,甚至执行有害的指令。反之,抑制这些神经元能有效降低这种过度顺从,提升模型的鲁棒性。这说明 H-Neurons 编码了一种“为了回答而回答”的顺从倾向,而不仅仅是事实记忆的错误。
起源分析
在起源分析实验中,研究者发现基于指令微调模型训练的探测器,在对应的预训练基座模型上依然具有很高的 AUROC 分数(如文中图4a所示,均显著高于随机猜测)。此外,参数演化分析(文中图4b)显示,与其他神经元相比,H-Neurons 在微调过程中的参数变化非常小(标准化排名靠前,表示变化小)。这强有力地证明了幻觉机制源于预训练阶段的 next-token prediction 目标,而非后期的对齐训练引入的。
五、论文结论与评价
本论文通过严谨的实验得出结论:大型语言模型中确实存在极少量的 H-Neurons,它们不仅能作为检测幻觉的可靠信号,更是导致模型产生过度顺从行为(如盲从用户错误引导、阿谀奉承)的微观物理基础。此外,研究证实这些神经元在预训练阶段就已形成,后期的指令微调只是保留了这些机制。
这项研究对实际应用具有重要的启示。首先,它为幻觉检测提供了一种新的、低成本的内部视角,不依赖外部知识库即可判断模型是否在“胡说八道”。其次,它指出了幻觉缓解的新方向,即通过精准编辑或抑制特定的神经元来减少幻觉,甚至可能通过这种方式提高模型的安全性(如防御越狱攻击)。理论上,它将宏观的模型行为与微观的神经元活动联系起来,解释了模型为何会为了“流利”而牺牲“真实”。
该方法的优点在于精准性和可解释性强,能够定位到具体的计算单元,且跨模型、跨领域的泛化能力出色。然而,其缺点也值得注意:简单的线性干预(如直接抑制神经元)可能会误伤模型的正常能力,导致模型变得过于保守或拒绝回答合理问题。此外,目前的分析主要集中在单层或独立神经元上,可能忽略了神经元之间复杂的非线性协同作用。
建议未来的研究可以探索更精细的非线性干预策略,以在去除幻觉的同时保留模型的有用性。同时,深入研究预训练数据的哪些特征具体导致了这些 H-Neurons 的形成,将有助于从源头上构建更可靠的语言模型。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 18
18 0
0- 0



 已为社区贡献34条内容
已为社区贡献34条内容

所有评论(0)