一起来对比解析一下GPU和NPU——它们代表了通用计算加速与专用AI计算两种不同的技术哲学
总结GPU是通用并行计算的王者,尤其在AI训练和复杂科学计算领域不可替代。其强大的生态(CUDA)和灵活性是核心优势。NPU是专用AI推理的效率怪兽,在边缘计算、移动设备和大规模AI服务部署中,凭借其超高的能效比和低延迟,成为必然选择。融合趋势异构计算:现代计算平台(如数据中心、自动驾驶域控制器)通常采用的异构组合。CPU负责通用逻辑控制,GPU负责复杂训练和并行任务,NPU负责高并发、低功耗的推
其差异远不止“谁算AI更快”这么简单。
核心设计哲学:从“多面手”到“特种兵”
理解二者的区别,首先要看它们的“初心”:
-
GPU:图形处理器。初衷是处理高度并行、可预测的图形渲染任务(数百万个像素、顶点)。其设计哲学是成为一个面向大规模并行、规则计算的 “通用并行处理器” 。
-
NPU:神经网络处理器。从诞生之日起就只为一件事:高效执行人工智能算法,尤其是神经网络的前向推理。其设计哲学是成为一个针对 “稀疏、非规则、标量/向量/张量混合计算” 的 “专用AI加速器” 。
一个精炼的比喻:
-
GPU 像一个功能强大的 “多功能厨房” ,有多个猛火灶(大规模并行流处理器),能同时炒很多盘菜(并行任务),也能处理烘焙、炖煮(通用计算)。但当只需要快速热一份预制菜(AI推理)时,整个厨房启动就显得有些大材小用且耗能。
-
NPU 则像一个专为加热特定预制菜设计的 “智能微波炉” 。它的内部结构(计算单元、内存、数据通路)完全为这套流程优化,一键按下,高效快捷,省电省空间。
核心差异对比表
为了让您一目了然,我们先通过一个表格概括其核心差异:
| 维度 | GPU | NPU |
|---|---|---|
| 诞生目标 | 图形渲染,后演变为通用并行计算 | 专为人工智能计算,尤其是神经网络推理 |
| 核心架构 | SIMT:大量通用的流处理器核心,共享大容量、高带宽显存。架构规整,灵活性高。 | 异构计算阵列:集成大量为乘加运算优化的固定功能单元、张量核心,片上内存层次极度优化。 |
| 擅长任务 | 大规模并行、规则计算。 • 图形渲染 • 科学计算 • AI模型训练(复杂度高,需灵活性) • 视频编码 |
低精度、稀疏化、固定模式的AI推理。 • 图像/语音识别 • 自然语言处理 • 推荐系统推断 • 自动驾驶实时感知 |
| 关键指标 | 高吞吐量(TFLOPS)、高显存带宽 | 高能效比(TOPS/W)、低延迟、低功耗 |
| 编程模型 | CUDA, OpenCL 等,灵活但相对复杂 | 专用编译器(如TVM),通常通过框架(TensorFlow, PyTorch)直接调用,对开发者更透明 |
| 典型代表 | NVIDIA A100/H100, AMD MI300 | 华为昇腾, 寒武纪, 谷歌TPU, 苹果神经网络引擎 |
深入解析:架构、效率与适用场景
1. 架构差异:通用流水线 vs. 专用高速公路
-
GPU:像一座拥有数千条简单车道的超级城市环线。每个车道(流处理器)都能处理各种车辆(数据),但需要复杂的交通调度(线程调度、缓存管理)来避免拥堵。它的强大来自于极致的并行吞吐能力。
-
NPU:像一条连接芯片厂和组装厂的点对点封闭式专用货运铁路。铁轨宽度、车站布局(内存层次)、火车车厢(数据流)全部为运输特定原料(矩阵乘加、激活函数)而设计,中间没有红绿灯,效率极高,但只能跑这条固定路线。
2. 效率差异:为何NPU在AI推理上更胜一筹?
NPU在特定任务上的超高能效,源于从硬件层面针对AI的“痛点”进行优化:
-
低精度计算:AI推理通常使用
INT8,INT4甚至更低精度,NPU直接内置大量低精度计算单元,而GPU的通用核心处理低精度时效率不高。 -
稀疏性加速:训练后的神经网络权重和激活值中有大量“0”。NPU硬件能跳过对零的计算,而GPU需要执行“乘零加零”的无用功。
-
数据流优化:NPU采用 “数据流架构” 或 “片上网络” ,使计算单元能直接从邻近的缓存中获取数据,最大限度地减少数据搬运(这是耗能大头),即 “计算靠近数据” 。
-
算子融合:将神经网络中连续的“卷积-批归一化-激活”等操作,在硬件层面融合为一个执行步骤,大幅减少中间结果的读写开销。
3. 场景选择:何时用谁?
这是一个简单的决策树:
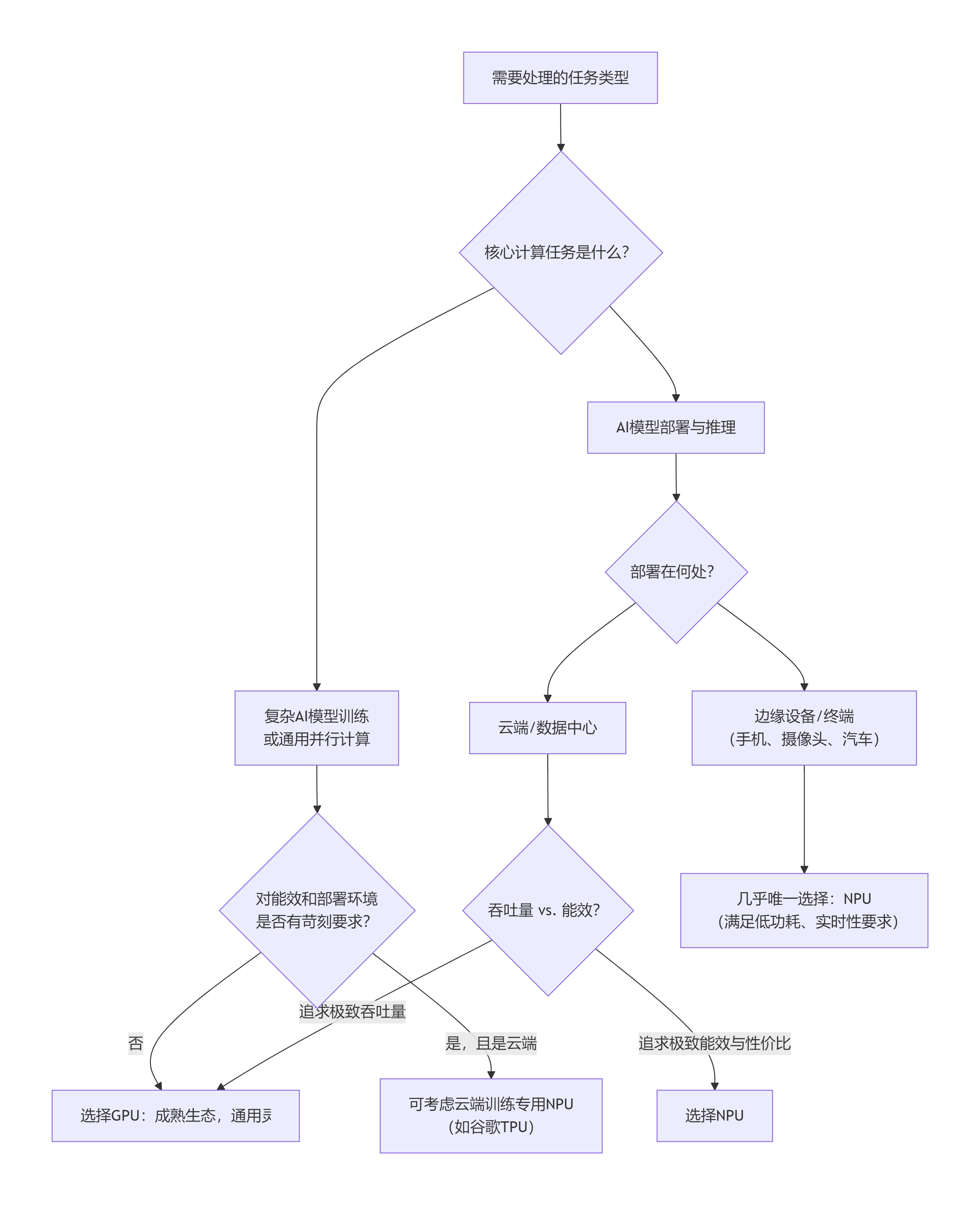
总结与未来趋势
总结:
-
GPU是通用并行计算的王者,尤其在AI训练和复杂科学计算领域不可替代。其强大的生态(CUDA)和灵活性是核心优势。
-
NPU是专用AI推理的效率怪兽,在边缘计算、移动设备和大规模AI服务部署中,凭借其超高的能效比和低延迟,成为必然选择。
融合趋势:
两者并非简单的替代关系,而是走向融合与协作:
-
异构计算:现代计算平台(如数据中心、自动驾驶域控制器)通常采用 “CPU + GPU + NPU” 的异构组合。CPU负责通用逻辑控制,GPU负责复杂训练和并行任务,NPU负责高并发、低功耗的推理任务,各司其职。
-
GPU的NPU化:NVIDIA在其最新GPU中集成了更强的张量核心,并支持稀疏计算,本质是在通用架构中吸收专用优化。
-
NPU的通用化:一些NPU开始支持更灵活的可编程性,以覆盖更广泛的算子。
简单来说:今天,GPU是“AI研发实验室”的主力引擎,而NPU是“AI应用工厂”的自动化产线。 未来,两者的界限会因互相学习而模糊,但分工协作的范式将长期存在。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)